
Каталог преднастроенных моделей с готовым API
Полный список моделей смотрите в панели управления. Выберите модель и получите свой выделенный endpoint.
Как развернуть LLM из Foundation Models Catalog
- Выберите модельВ выборе помогут теги, система поиска и ссылки на описание моделей в Hugging Face.
- Получите рекомендуемую конфигурациюЗадайте ключевые параметры работы модели: тип данных, максимальную длину контекста, количество одновременных запросов. Система предложит рекомендуемую конфигурацию инфраструктуры и релевантные бенчмарки выбранной модели.
- Задайте параметры Inference-сервисаВыберите параметры масштабирования: фиксированное количество инстансов или автоматическое масштабирование под нагрузку. Укажите тип диска.
- Создайте Inference-сервисВы получите endpoint для работы с моделью, пример curl-запроса для тестирования, API-ключ для авторизации.




Как работает Selectel Foundation Models Catalog
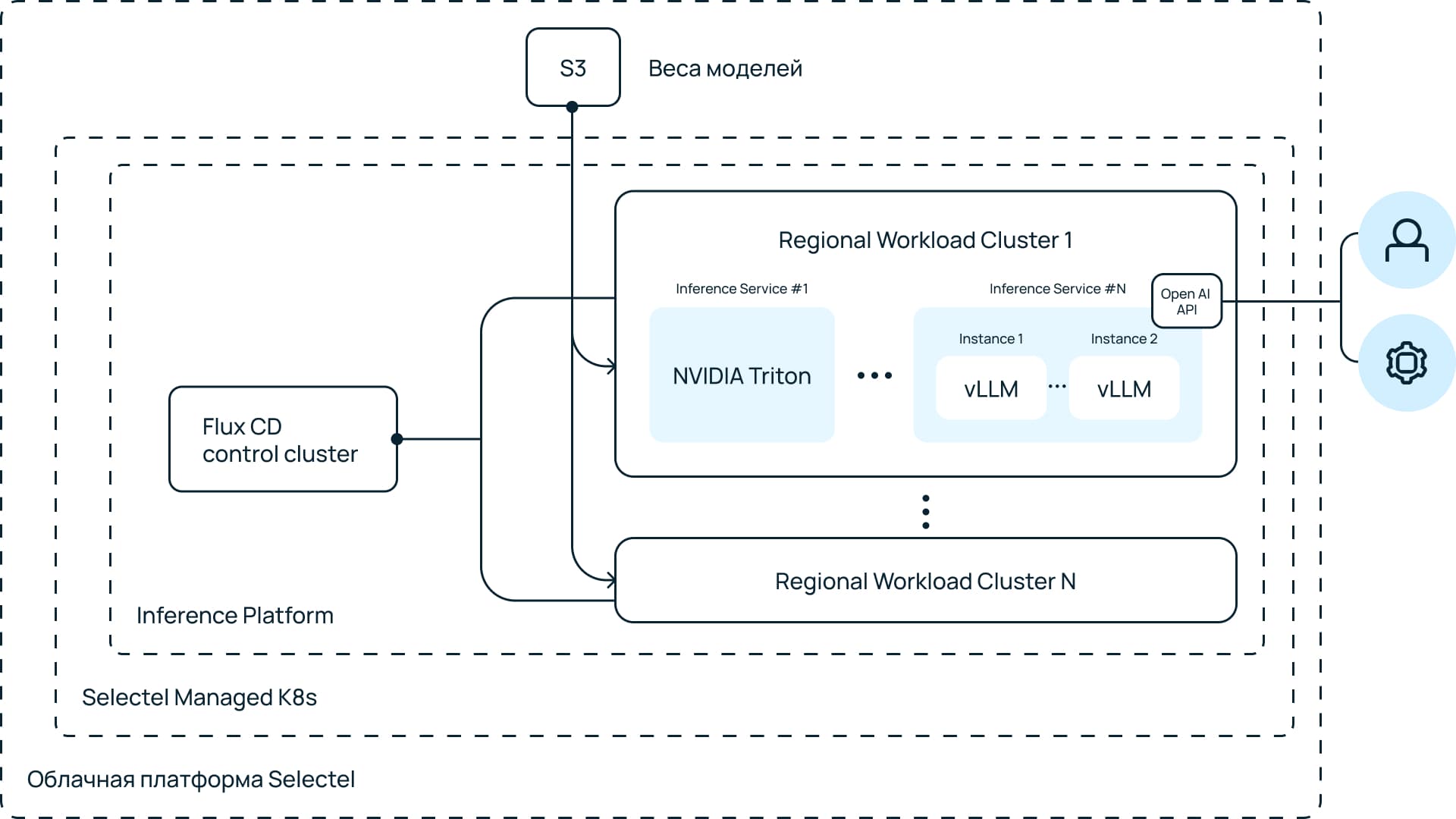
Selectel Foundation Models Catalog позволяет быстро подключать крупные языковые и мультимодальные модели через готовый API. Вы выбираете подходящую модель из каталога, а платформа сама разворачивает ее на подходящей инфраструктуре и выдает endpoint с токеном доступа. Интеграция и бизнес-логика остаются на вашей стороне.
Преимущества запуска моделей через Foundation Models Catalog
Снижение нагрузки на ML‑команды
Получите ссылку на endpoint для использования в своих сервисах без деплоя сложной инфраструктуры.
Размещение в российских дата-центрах
6 дата-центров уровня Tier III в Москве и Санкт-Петербурге. Облачная платформа Selectel включена в реестр российского ПО (№ 9884 от 25.03.2021).
API для интеграций
Модели легко интегрировать в ваши проекты и сервисы. Доступ к foundation models получите через публичный API, совместимый с OpenAI API. Можно использовать curl-запросы или чат-бот из AI-маркетплейса.
Прогнозируемые затраты на проект
Стоимость рассчитывается исходя из фактического времени потребления ресурсов (CPU, GPU, RAM, объем дисков). Бюджет проекта не зависит от неконтролируемого потребления токенов.
Быстрый старт на проверенной инфраструктуре
Мы заранее протестировали модели на разных конфигурациях и зафиксировали бенчмарки. Вам остаётся только выбрать подходящий вариант и сразу начать работу.
Модель работает в приватном endpoint
Ваши Inference-сервисы используют выделенную специально под них вычислительную инфраструктуру. Один Inference-сервис — одна или несколько нод кластера K8s.
Разные GPU всегда в наличии
У нас большой запас GPU в наличии: NVIDIA А2, А30, А100, А2000, А5000, Tesla Т4 и GTX 2080. Это значит, что вы сможете быстро выбрать конфигурацию с видеокартой под любую задачу.
Масштабирование под нагрузку
Inference-сервис сам подстраивается под изменения нагрузки: при росте запросов добавляются новые ресурсы, при снижении — лишние отключаются.
Сценарии использования Foundation Models Catalog
Протестировать LLM-модель под свой проект
Быстро развернуть несколько моделей и сравнить, какая лучше справляется с вашими задачами.Подобрать инфраструктуру для ожидаемой нагрузки
Оценить бенчмарки модели на разных конфигурациях Inference-сервиса и подобрать необходимую.Создать Inference-сервис под динамические изменяющиеся нагрузки
Настроить параметры автоматического масштабирования вычислительных мощностей и подключить Inference-сервис к собственной системе через OpenAI API.

Разворачивайте модели на безопасной инфраструктуре
ГОСТ Р 57580
Инфраструктура соответствует требованиям Центрального банка России
ISO
Работаем в соответствии с регламентами ISO/IEC 27001, ISO/IEC 27017, ISO/IEC 27018
152-ФЗ до УЗ-1
Используйте на проектах, где собираются и обрабатываются персональные данные
PCI DSS
Можем хранить банковские данные без ограничений со стороны регуляторов
IAM-система
Разграничивайте доступ к ресурсам и данным, определяйте роли
Запустите LLM в облаке Selectel
FAQ
- Что такое Foundation Models Catalog?
- Что такое Foundation Models?
- Как рассчитывается стоимость продукта Foundation Models Catalog?
- Какие ограничения есть при работе с Foundation Models?
- Можно ли развернуть свою модель?
- Можно ли развернуть модель в частной инсталляции?