Регулярные выражения. Часть 1. Основы и применяемые инструменты
Данная статья помогает новичкам сделать первые шаги в освоении регулярных выражений. Все примеры — простые.
В профессиональной среде IT-специалистов наблюдается четкое разделение во взглядах на регулярные выражения. Существуют два основных подхода: одни разработчики уверенно владеют этим инструментом и способны решать сложные задачи по обработке текста одной лаконичной строкой кода. Другие же воспринимают регулярные выражения как нечто излишне запутанное, стараясь избегать их использования даже в тех случаях, когда они являются наиболее подходящим решением.
Данная статья ориентирована на вторую категорию специалистов и призвана стать руководством для плавного перехода в первую. Ее цель — систематизировать базовые знания и помочь преодолеть психологический барьер, известный как «регекспофобия».
Введение
Регулярное выражение — это, по сути, язык для описания текстовых паттернов. Это как некая маска или трафарет, накладывая который на текст, мы можем определить, соответствует ли строка этому трафарету.
Области применения этого инструмента весьма обширны. Рассмотрим несколько, наиболее часто встречающихся.
- Поиск — самое базовое применение. Представьте, что вам нужно найти в логах все записи с определенным кодом ошибки — например, ERR_CONN_RESET.
- Валидация — проверка корректности вводимых данных. Вам нужно убедиться, что пользователь ввел серийный номер продукта в формате SN-XXXX-XXXX-XXXX, где X — цифра или буква.
- Парсинг — извлечение и структурирование данных. Например, из строки Date: 2025-06-05; User: admin; вы хотите получить отдельно дату и имя пользователя.
- Устрашение — иногда кажется, что это главная цель. Попробуйте взглянуть на регулярное выражение для проверки того, является ли строка валидным почтовым адресом согласно всем стандартам RFC. Предупреждаем, зрелище не для слабонервных!
Два слова о терминах. Полное название «regular expression» в повседневной речи почти не используется. В ходу его англоязычные сокращения regex и regexp. Мы же в этой статье для простоты будем называть их «регулярками».
Важно сразу оговориться: при всей своей мощи регулярные выражения не являются всемогущим артефактом. Они не обладают полнотой по Тьюрингу, а значит, круг решаемых ими задач ограничен. Хрестоматийный пример того, чего делать не стоит, — это попытка парсить HTML/XML. Древовидная структура подобной разметки требует контекстного анализа, для которого регулярки не предназначены. Подробности объясняются на StackOveflow.
Стоит заметить, что энтузиасты находят и совсем уж экзотические применения регекспам. Например, существует рабочий (хоть и невообразимо медленный) способ проверить число на простоту с помощью одного лишь шаблона.
Инструменты
Пытаться понять сложную регулярку «в уме» — занятие неблагодарное. Это все равно что ориентироваться в цифровых джунглях без карты. К счастью, для нас уже потрудились «картографы», создавшие великолепные онлайн-сервисы. Я постоянно использую два из них.
Regexper превращает любую, даже самую запутанную, регулярку в наглядный граф. Например, шаблон для поиска вещественных чисел [+-]?(\d*\.)?\d+ мгновенно становится понятным в виде инфографики:
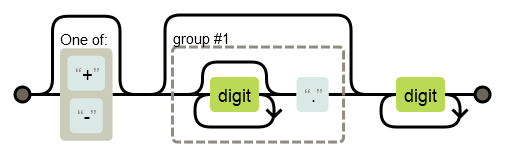
Если вам достался в наследство загадочный паттерн, смело загружайте его в Regexper — это лучший способ быстро ухватить суть. Правда, есть нюанс. Запутанные случаи — дадут запутанный граф. Регулярка для email, упомянутая выше (записанная в одну строчку, конечно) даст граф шириной в 24 621 пикселей.
regex101 — это уже не просто карта, а целая лаборатория для тестирования и отладки. Здесь вы можете в реальном времени проверять свой шаблон на тестовых данных, видеть все совпадения и, что самое главное, понимать, почему что-то работает не так, как ожидалось. В сервисе есть даже пошаговый отладчик!
Hello, world
Хотя язык регулярных выражений не является языком программирования в строгом смысле, мы будем придерживаться традиции и начнем с базового примера. Откроем сервис regex101 и введем следующее выражение:
hello, worldКак видите, регулярное выражение может состоять из обычных символов, а не только из специфических конструкций. Такой шаблон, состоящий исключительно из литералов, найдет только одно точное совпадение — строку «hello, world».
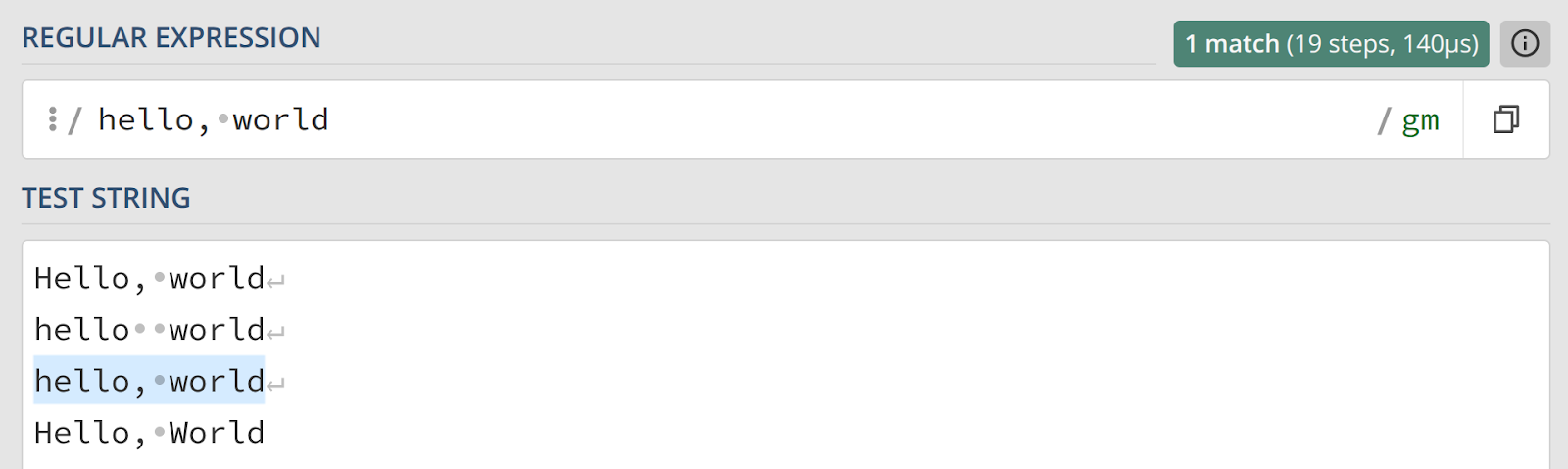
Во многих языках программирования и средах выполнения можно задавать дополнительные опции, которые изменяют поведение механизма. Одна из самых востребованных — опция нечувствительности к регистру (Case Insensitive), которая обычно обозначается флагом i. С этой опцией наш шаблон будет соответствовать и строке «Hello, world», и другим вариациям регистра.
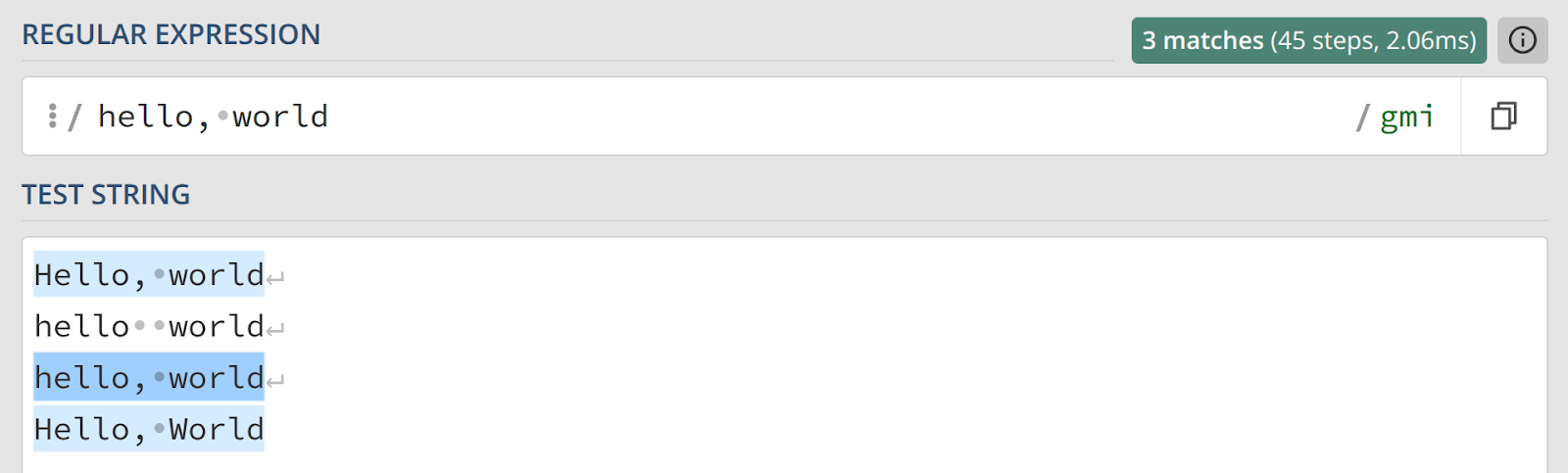
Теперь введем в наш шаблон элемент синтаксиса. В слове «hello» содержатся две буквы «l». Давайте отразим этот факт с помощью языка регулярных выражений:
hel{2}o, worldКонструкция в фигурных скобках {2} называется квантификатором. Она указывает, что непосредственно предшествующий ей символ (в нашем примере — «l») должен встретиться ровно два раза.
Конечно, в данном конкретном случае проще было бы написать ll. Однако квантификаторы становятся незаменимы в более сложных сценариях. Во-первых, символ может повторяться гораздо большее количество раз, например, тысячу. Во-вторых, квантификатор можно применять не только к одному символу, но и к целой группе символов, о чем мы поговорим позже.
Кроме того, квантификаторы позволяют указывать не только точное число повторений, но и диапазон, задавая минимальное и максимальное количество. Например:
hel{2,5}o, worldТакая запись означает, что буква «l» может повторяться от двух до пяти раз включительно.
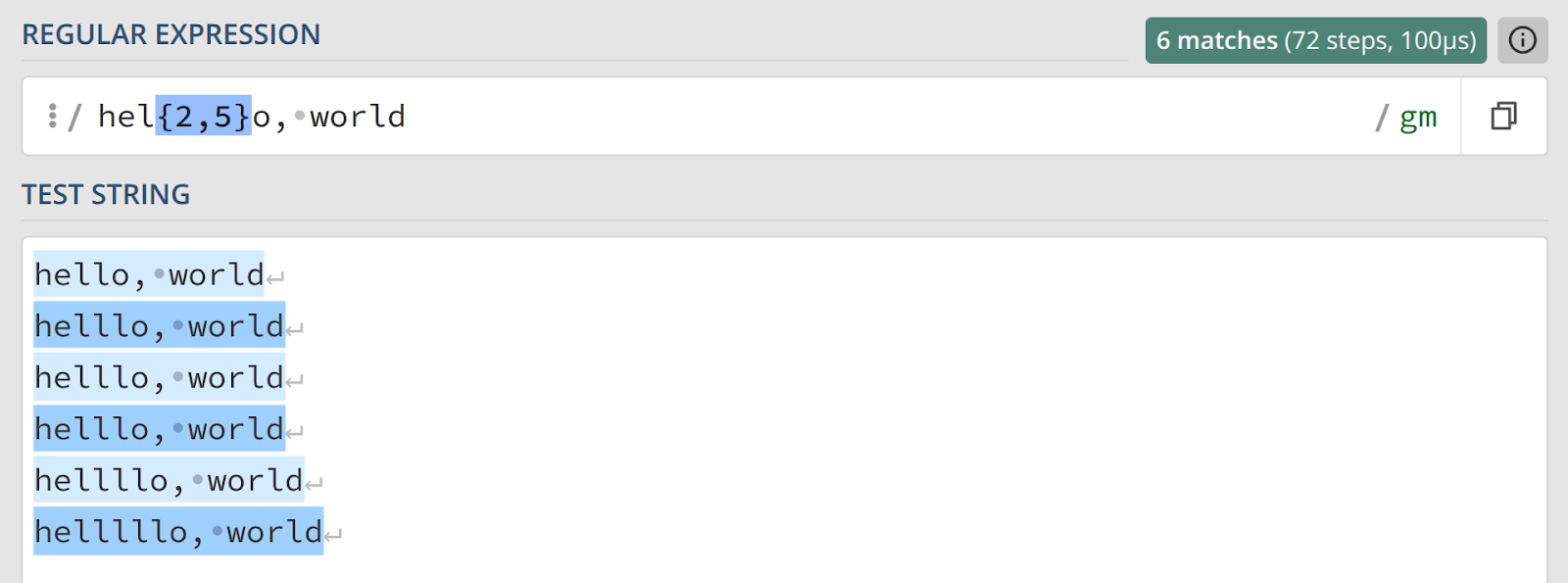
Если же опустить второе число, оставив запятую, это будет означать отсутствие верхнего предела:
hel{2,}o, worldЭто выражение будет соответствовать строкам, в которых буква «l» встречается два и более раза.
Оставим букву «l» и применим этот принцип к более практичной задаче — обработке пробелов. Допустим, нам необходимо найти совпадения, где между запятой и словом «world» может быть не один, а несколько пробелов. Для этого можем указать, что пробел должен встретиться как минимум раз:
hello, {1,}world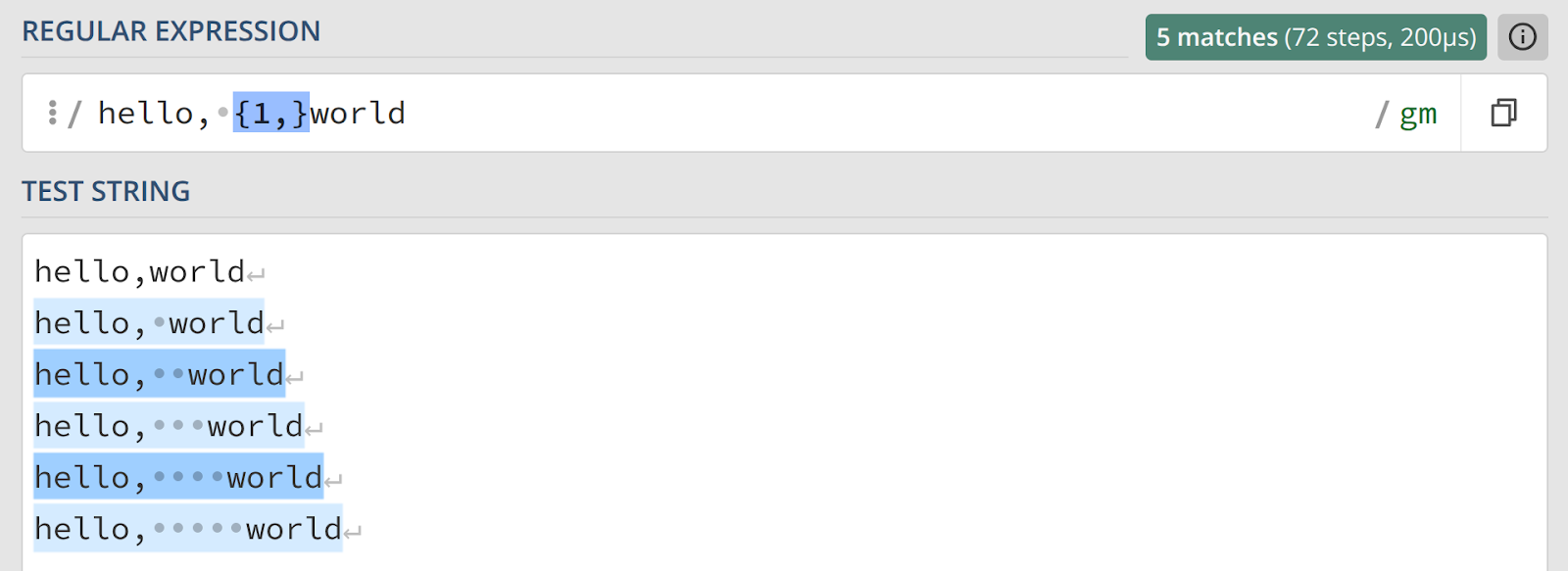
Предположим, поступило требование обрабатывать строки, в конце которых могут стоять восклицательные знаки. Их может не быть вовсе, а может быть любое количество. Для этого используем квантификатор {0,}:
hello, {1,}world!{0,}Теперь представим, что запятая также является необязательной. Вы, возможно, обратили внимание, что на скриншоте, где мы экспериментировали с чувствительностью к регистру, одна строка оказалась невыделенной — именно из‑за отсутствия запятой. Это означает, что она может встречаться либо ноль, либо один раз. Отразим это в шаблоне:
hello,{0,1} {1,}world!{0,}Важно отметить, что если в тестовой строке после совпадения идут символы, не соответствующие шаблону, совпадение не отбраковывается целиком. Движок найдет ту часть строки, которая подходит под шаблон. Иногда это желаемое поведение, а иногда — нет. В нашем последнем выражении hello,{0,1} {1,}world!{0,} строка без пробела не найдет совпадения, так как мы явно указали, что должен присутствовать хотя бы один пробел {1,}.
Спецсимволы
Чтобы сделать выражения более лаконичными и не перегружать их цифрами, для наиболее частых квантификаторов существуют односимвольные аналоги.
| Квантификатор | Сокращение | Описание |
| {0,1} | ? | Символ встречается ноль или один раз. |
| {0,} | * | Символ встречается ноль или более раз. |
| {1,} | + | Символ встречается один или более раз. |
Используя эти сокращения, мы можем переписать наш предыдущий пример значительно короче:
hello,? +world!*Выражение снова стало похоже на исходный текст, но его функциональность значительно возросла.
Но что делать, если нам нужно найти в тексте сам символ ? или +? Для этого существует механизм экранирования (escaping). Поставив перед метасимволом обратную косую черту (\), мы лишаем его специального значения, превращая в обычный литерал. Например, выражение hello\? будет соответствовать строке «hello?», а не «hell» или «hello».
Обратная косая черта может экранировать и саму себя, для чего ее нужно удвоить: \\. В строковых литералах многих языков программирования \ уже является служебным символом, поэтому, чтобы передать в движок регулярных выражений экранированный слэш, в коде приходится писать \\\\. Это тот нюанс, о котором полезно помнить.
Вернемся к нашему примеру «hello, world». Предположим, мы хотим учесть распространенную опечатку и находить также слово «hallo». Для выбора одного символа из нескольких используется конструкция с квадратными скобками []. Выражение h[ea]llo будет соответствовать и строке «hello», и строке «hallo».
![Тестирование регулярного выражения: h[ae]llo — подсвечиваются и hello, и hallo.](https://lh7-qw.googleusercontent.com/docsz/AD_4nXfCQivsvg4CvTMpJFV1xKu45lsxboI-PWOcdUnVg5rlbAJ3I7fcdGize_RZ-0qjR7u7uQz_5gYSai7Yu3I01vJd5WhKYaYLxjJ3WsoOCUQFzcuYr35UfZxDLVUz9zTDEgE5WlHcZw?key=-5KKDyLmOszgW03HAbXSDw)
А как быть, если нужно выбрать одно из нескольких слов целиком, например, «hello» или «привет»? Конструкция [helloпривет] здесь не поможет, так как она будет искать любой один символ из перечисленных в скобках.
Для выбора между альтернативными последовательностями символов используется оператор |. Выражение hello|привет найдет либо одно слово, либо другое. Стоит отметить, что большинство современных движков поддерживают символы Unicode, включая кириллицу и даже эмодзи.
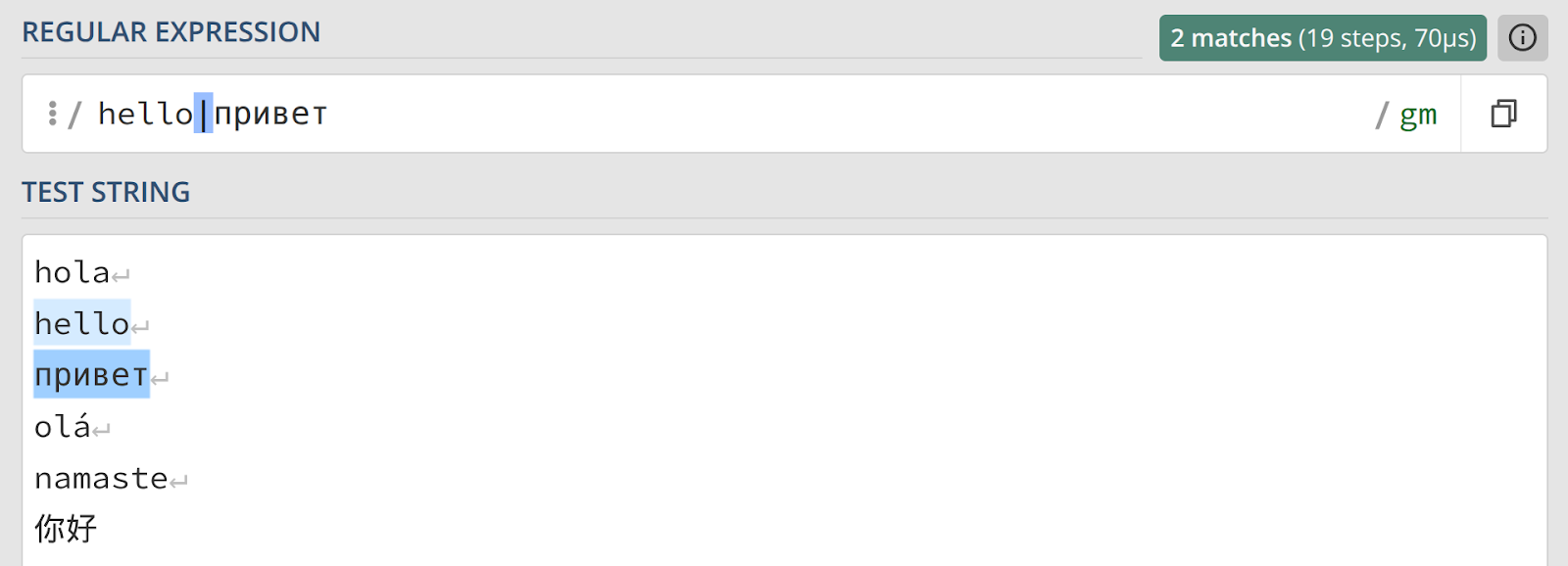
Если написать hello|привет, world, то слово «world» будет частью второй альтернативы, и выражение найдет либо «hello», либо «привет, world».
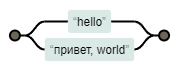
Чтобы ограничить область действия оператора |, используются круглые скобки (). Они группируют часть выражения, позволяя применять операторы к группе целиком. Например:
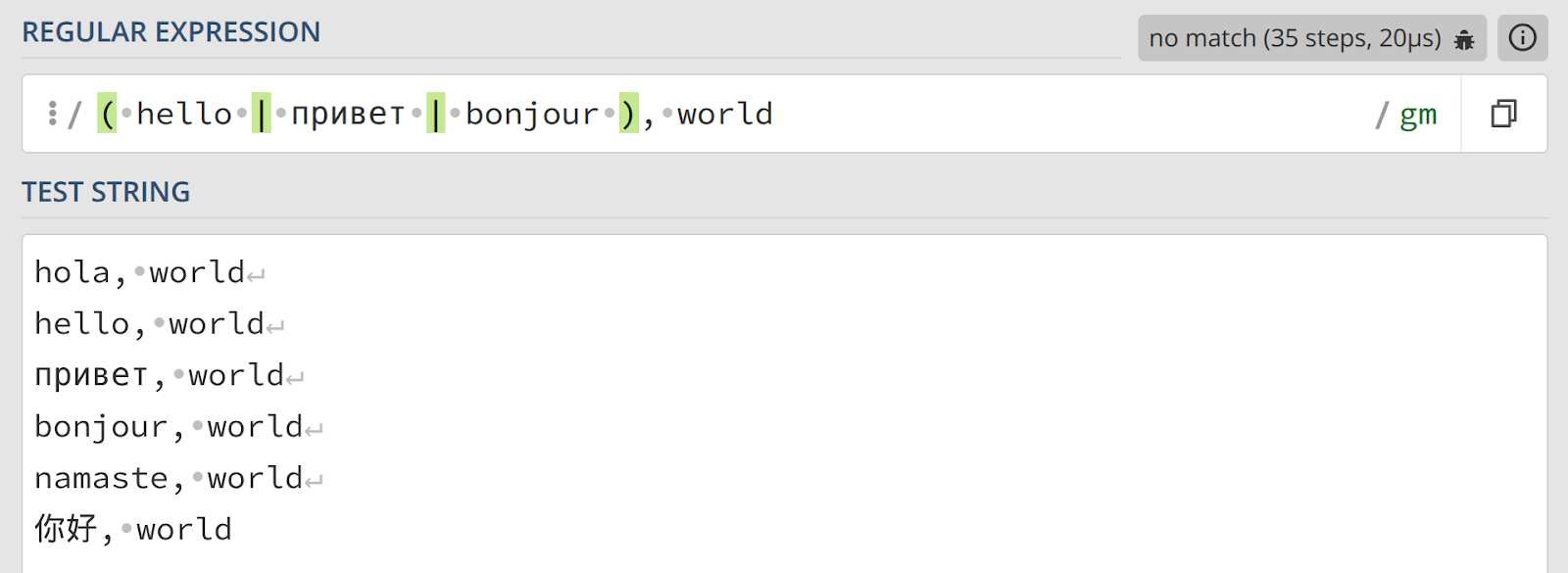
(hello|привет|bonjour), world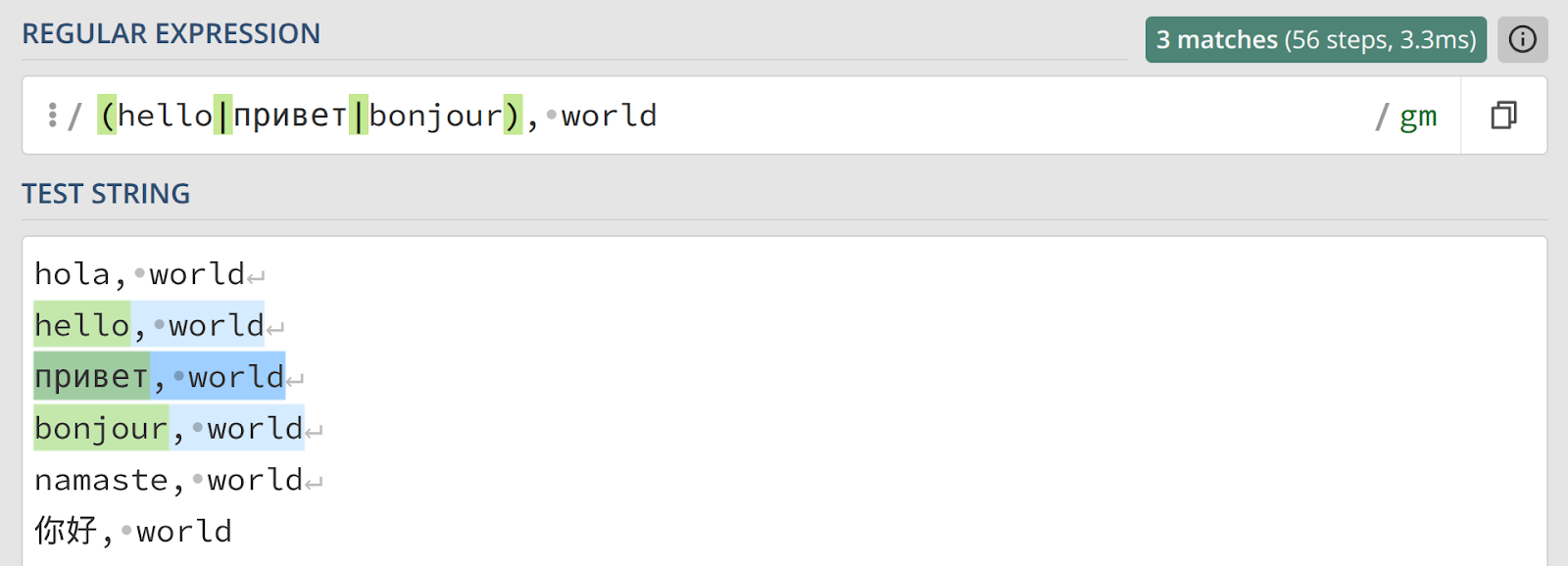
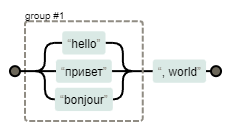
В этом случае «, world» является общей частью для всех трех приветствий. Важно помнить, что пробелы внутри скобок — например, (hello | привет) — являются частью шаблона и будут влиять на результат поиска.
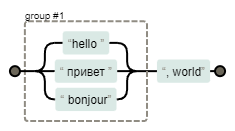
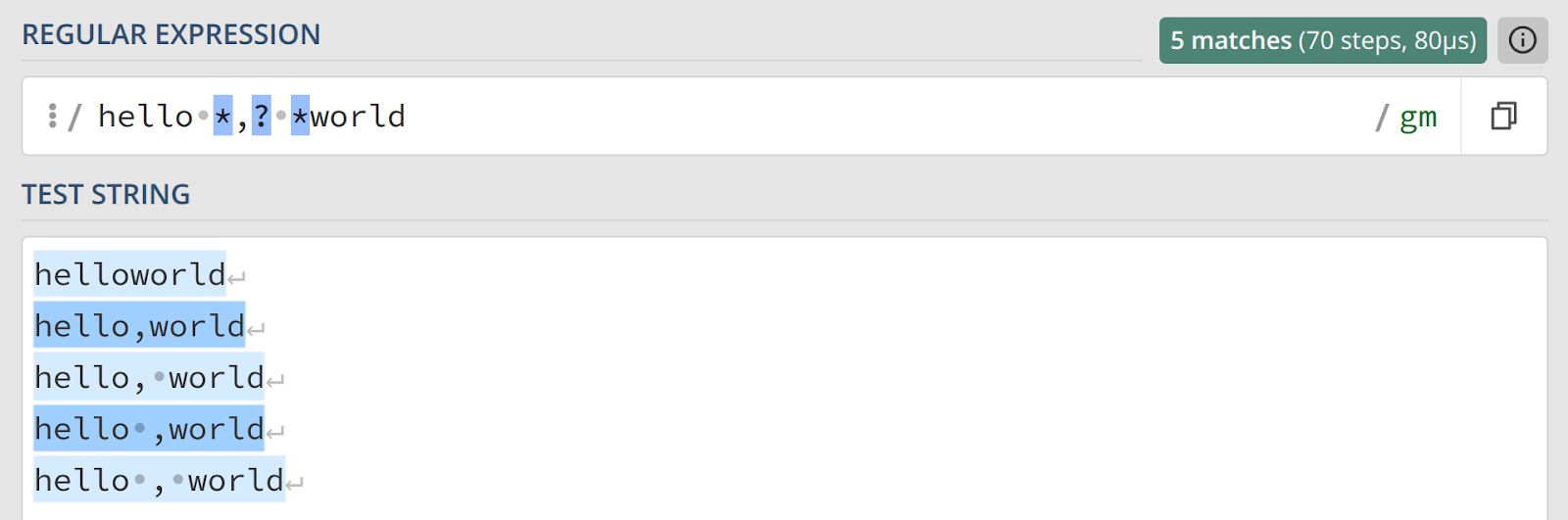
Теперь решим проблему с пробелами вокруг запятой, которую могут ставить не по правилам. Попробуем вариант:
hello *,? *worldОн работает, но имеет существенный недостаток: также находится слитное написание «helloworld», поскольку и пробелы (*), и запятая (?) являются необязательными.

В реальных задачах это распространенная проблема: как указать, что хотя бы один из нескольких опциональных разделителей должен присутствовать?
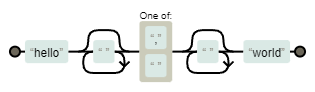
Квадратный способ
hello *[, ] *world — здесь после слова «hello» и необязательных пробелов должен идти один обязательный символ из набора (запятая или пробел), за которым снова могут идти пробелы.
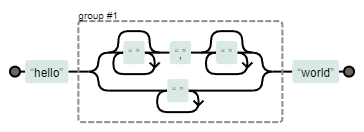
Круглый способ
hello( *, *| +)world — здесь мы используем группу с альтернативой: либо запятая, окруженная нулем или более пробелов, либо один или более пробелов.
Вторая проблема выражения hello *,? *world в том, что пробел в нем выражен неявно, и не сразу очевидно, к чему относится *.
Мы уже знаем, что \ превращает метасимволы в обычные. Но этот механизм работает и в обратную сторону — он может наделять обычные символы специальными свойствами. Например, буква s (от слова space), снабженная слэшем, становится метасимволом \s, который обозначает любой пробельный символ, включая пробел, табуляцию и, в зависимости от настроек, перенос строки. Перепишем наше выражение с его использованием:
hello(\s*,\s*|\s+)worldВыражение стало более читаемым и выглядит профессионально, то есть максимально понятно для тех, кто привык работать с регулярками.
Заглядываем в бездну
Наконец, соберем все наши знания воедино и создадим комплексное выражение, которое обрабатывает все рассмотренные нами случаи:
(h[ea]llo|привет|bonjour)(\s*,\s*|\s+)world!*Это выражение достигло достаточного уровня сложности, чтобы считаться «волшебным».
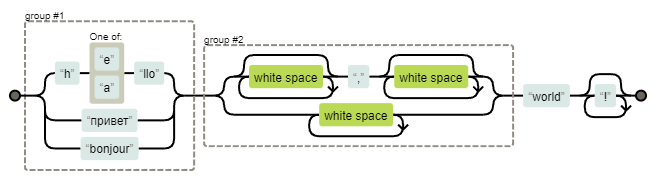
Следует отметить, что в рамках данного введения некоторые концепции были представлены в упрощенной форме. Ряд технических нюансов намеренно опущен, чтобы не усложнять восприятие материала для читателей, только начинающих знакомство с этой темой. Более глубокий и строгий анализ функциональности регулярных выражений будет представлен в следующей публикации.