Регулярные выражения. Часть 4. Просмотр вперед и назад, оптимизация
Завершаем нашу серию статей. Рассматриваем просмотры вперед и назад, а также некоторые хитрости для упрощения работы с регулярными выражениями.
Привет! Добро пожаловать в заключительную главу нашего марафона по регулярным выражениям! В первой и второй частях мы описывали символьные классы, разбирались с повторениями. В прошлый раз совершили настоящий прорыв: научились не просто находить совпадения, но и разделять их на части с помощью групп.
Мы почти решили нашу сквозную задачу — поиск слов, начинающихся на «к» и заканчивающихся на «а». Наше лучшее решение пока выглядит так:
(?:^|[^а-яё])(к[а-яё-]+а)(?:[^а-яё]|$)Оно работает, но с оговоркой. Мы научились изолировать нужное слово в захватывающую группу, но само совпадение по-прежнему «цепляет» соседние символы — пробелы и знаки препинания. Мы как бы просим движок: «Найди слово, при этом можешь съесть и его окружение». Элегантно? Не совсем.
Существует более совершенный подход, который позволяет описывать контекст, вообще не делая его частью совпадения. Сегодня мы познакомимся с вершиной мастерства владения регулярками, поговорим о производительности и подведем итоги.
Взгляд в будущее и прошлое
Представьте, что движок работает с регулярными выражениями как человек: смотрит на шаблон, забегая вперед и возвращаясь назад, вместо того, чтобы последовательно поглощать символ за символом, как гусеница.
Именно так работают утверждения нулевой ширины (zero-width assertions), более известные как lookarounds (просмотры или заглядывания). Такие конструкции позволяют движку «бросить взгляд» вперед или назад от текущей позиции в строке. При этом удается проверить, соответствует ли текст определенному шаблону, и на основе этого принять решение — продолжать поиск или нет. Самое главное: текст, на который «посмотрели», не становится частью итогового совпадения — курсор движка не перемещается.
Таких конструкций четыре — и они делятся на две пары: просмотры вперед (Lookahead) и назад (Lookbehind), каждый из которых может быть позитивным и негативным.
Позитивный просмотр вперед
Конструкция (?=) говорит движку: «Посмотри вперед. Продолжи работать, только если за этой точкой следует текст, соответствующий шаблону внутри скобок».
Классический пример — валидация пароля. Допустим, нам нужен пароль длиной не менее восьми символов, который обязательно содержит хотя бы одну цифру. Без lookahead решить такую задачу сложновато. С ним — элементарно:

Давайте разберем этот, на первый взгляд, пугающий шаблон.
^— якорь начала строки.(?=.*\d)— вот и наша магия, позитивный просмотр вперед. Он, не сдвигая курсор с начала строки, «смотрит» вправо и проверяет, есть ли где-то дальше.*хотя бы одна цифра\d. Если да, утверждение истинно, и движок продолжает работу. Если нет, вся строка считается не соответствующей шаблону. Важно: эта проверка не «съедает» символы..{8,}— если проверка пройдена, основной шаблон продолжает работу с того же места, где остановился (то есть с начала строки). Требуется наличия не менее восьми любых символов.$— якорь конца строки.
Негативный просмотр вперед
Конструкция (?!) — полная противоположность предыдущей. Она говорит движку: «Посмотри вперед. Продолжи работать, только если за этой точкой нет текста, соответствующего шаблону внутри скобок».
Предположим, нам нужно найти все формы слова «кот», за которыми не следует союз «и». Примеры: «кот.», «кот,», «кот!», но не «кот и кошка». Вы, наверное, уже быстро написали в уме:
\bкот\b(?!\s+и\b)И это правильно… но не для всех движков. Кириллические буквы в тексте — сразу загорается сигнал повышенной сложности! Переписываем выражение так, чтобы оно работало всегда и везде:
![Тестирование регулярного выражения [^а-яё]кот(?=[^а-яё])(?!\s+и[^а-яё]) — найдены все совпадения с целым словом кот, но после которых нет союза «и».](https://lh7-qw.googleusercontent.com/docsz/AD_4nXew9rthVkTTER0ecrBfZqQTLLZvckiKQmsZZKyso0xKRzVSSbPhDlG6hgss5ZGo3Ad-69z0WbuOmts1UW__RRu7OHVQfdSpb9WdstVzke-DKKzJLfMwOeX_f5nI2Eb5-6VrzWB_4A?key=3sNIFXgMsw7LnktCV0MkxQ)
Разбираем полет.
[^а-яё]в начале строки — некоторый аналог\b. Аналог неполный, но сейчас и так сойдет: задача требует анализа подстроки справа от кота, поэтому слева просто обозначим некириллический символ, пусть и «проглатывая» его. Чтобы упростить выражение в скобках, мы также берем во внимание используемый алфавит: английских слов нет — не указываем еще один диапазон.(?=[^а-яё])— то же, что и в предыдущем случае, только смотрим вправо и при этом не «съедаем» наблюдаемый символ. Вот это уже очень хороший аналог\b.(?!\s+и[^а-яё])— наконец, главный негативный просмотр вперед. После слова «кот» мы проверяем, не идет ли пробел и союз «и». Если идет — совпадение отбрасывается.
Также не подсвечивается пятая строка со словом котейка — срабатывает наша граница слова.
Позитивный просмотр назад
Конструкция (?<=) говорит движку: «Продолжай поиск, только если этому месту предшествует текст, соответствующий шаблону».
Рассмотрим небольшую практическую задачку: найдем все цены в долларах, при этом сам значок $ в результаты попадать не должен.
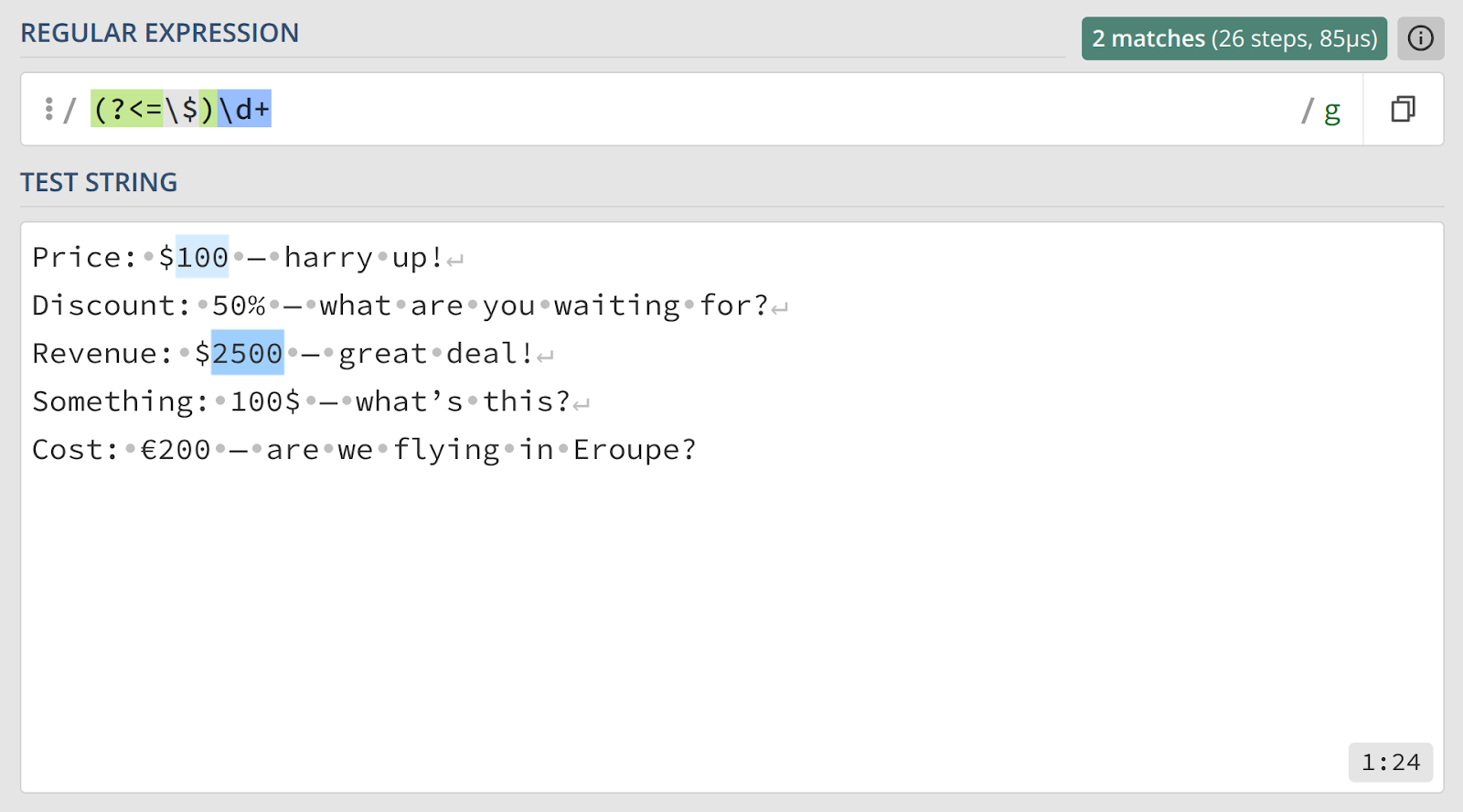
Алгоритм несложен.
(?<=\$)— позитивный просмотр назад. Перед тем как искать цифры, движок проверяет, надо ли вообще это делать. Стои́т ли непосредственно перед текущей позицией символ доллара? Обратите внимание,$нужно экранировать, так как это метасимвол.\d+— если проверка успешна, ищем одну или несколько цифр.
Но вот незадача! Вариант написания, когда знак доллара стоит после числа, в нашу выборку не попадает. Исправим ситуацию: добавим или‑или — мы уже знаем как:

Теперь можем парсить прайс‑листы и предложения магазинов!
Негативный просмотр назад
Даем движку команду наоборот: «Продолжай поиск, только если этому месту не предшествует текст из шаблона».
Задача: найти слово Error, перед которым не идет подстрока Warning: . Решение теперь уже совсем несложное, тем более не придется обрабатывать нелатинские символы:

Нужно ли разбирать, что мы сделали?
(?<!Warning: )— негативный просмотр назад. Проверяем, что до этого места нет строкиWarning:.\bError\b— ищем целое словоError.
Обратите внимание: включен флаг i — логично, наверное, выхватить все сообщения с ошибкой.
Финал задачи о словах
Теперь у нас есть все, чтобы написать идеальное, элегантное и абсолютно точное выражение для поиска слов, начинающихся на «к» и заканчивающихся на «а». Вспомним требования:
- слово начинается на «к», заканчивается на «а»;
- внутри — русские буквы или дефис;
- это должно быть отдельное слово: граница — начало или конец строки, либо не буква кириллицы.
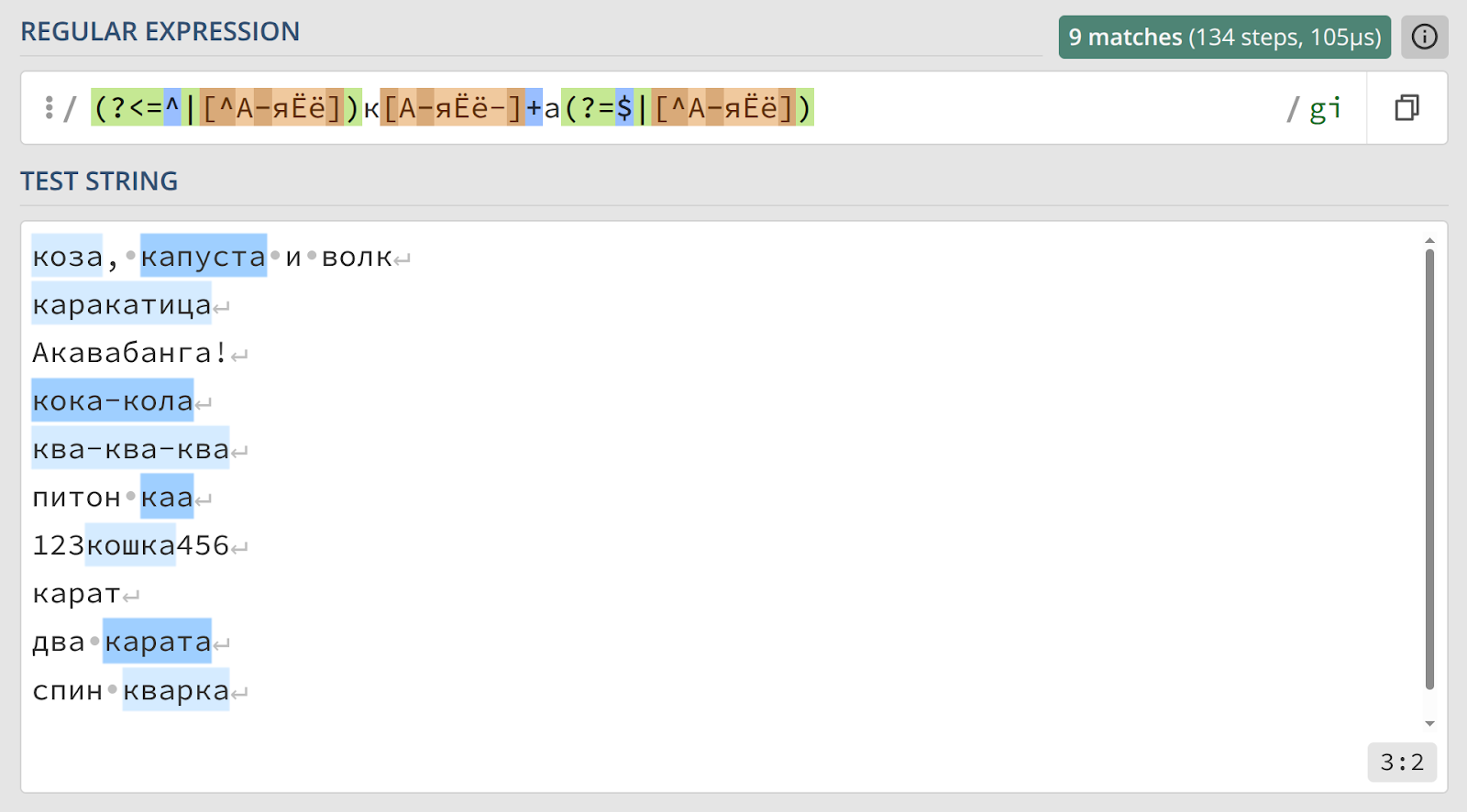
Давайте насладимся его красотой и разберем по частям.
(?<=^|[^А-яЁё])— позитивный просмотр назад. Мы требуем, чтобы перед нашим словом было либо начало строки^, либо любой символ, не являющийся русской буквой.к[А-яЁё-]+а— тело нашего слова, оно осталось неизменным.(?=$|[^А-яЁё])— позитивный просмотр вперед. Мы требуем, чтобы сразу после нашего слова шел либо конец строки$, либо любой символ, не являющийся русской буквой.
Это решение лучше всех предыдущих, потому что описывает контекст, не включая его в результат. Находится только слово — никаких лишних пробелов, никаких групп для извлечения. Обратите внимание, в финальной версии мы учли и регистр букв. Чисто, точно, профессионально!
Месть регулярок
Регулярные выражения коварны: у них есть подводные камни и особенности, сказывающиеся на производительности — как движка, так и человека.
Ускоритель
Неправильно составленный шаблон на больших объемах текста может не просто работать медленно, а привести к состоянию, известному как катастрофический возврат (catastrophic backtracking).
Движок регулярных выражений — усердный, но не всегда умный. Получив неоднозначную инструкцию, он будет пробовать абсолютно все возможные варианты, пока не найдет совпадение или не переберет все комбинации. В настоящее время очень сложно найти движок, который повиснет при попытке разобрать несколько десятков иксов по шаблону (x+)+y. Но вдруг кому повезет?
Так или иначе, для по-настоящему сложных шаблонов на больших объемах текста приходится задумываться об оптимизации. Для этого существуют ревнивые квантификаторы и атомарные группы. Они запрещают множественный перебор, допуская только один тест.
Ревнивые (possessive) квантификаторы *+, ++, ?+, {n,m}+ работают как и жадные, но с одним отличием: захватив символы, они никогда их не отдают и не позволяют испробовать другие варианты. Это как сказать движку: «Хватай как можно больше и беги!»
Атомарные группы (?>) действуют похоже, но на уровне целой группы. Как только движок успешно находит совпадение для выражения внутри (?>), он «замораживает» полученный результат. Все пути для возврата внутрь этой группы обрубаются.
Используйте эти конструкции, когда вы точно знаете, что однажды найденная подстрока шаблона не должна меняться. Разумеется, подобные подходы актуальны для больших объемов данных и нетривиальных задач.
Комментарии
Оставленное в покое регулярное выражение сразу начинает ползти в сторону эльфийского языка. Взглянув на него через неделю или месяц, можно обнаружить что оно превратилось в совершенно непонятное заклинание. Не отчаивайтесь, спасение есть!
Большинство современных диалектов поддерживают флаг x (Extended), который кардинально меняет восприятие регулярок движком. В этом режиме:
- все пробельные символы, включая разделители строк, игнорируются;
- символ
#начинает однострочный комментарий.
Такая особенность позволяет разбивать монструозные однострочные шаблоны на логические блоки с пояснениями. Рассмотрим для примера выражение для поиска URL-адресов:
\b(https?|ftp|file)://[-A-Z0-9+&@#/%?=~_|!:,.;]*[-A-Z0-9+&@#/%=~_|]А вот оно же, но в режиме x:
\b # Граница слова
(https?|ftp|file) # Протокол (http, https, ftp, file)
:// # Разделитель
[-A-Z0-9+&@#/%?=~_|!:,.;]* # Домен и путь
[-A-Z0-9+&@#/%=~_|] # Последний символ не может быть разделителемВторой вариант можно читать, понимать и поддерживать.
Даже если какой‑то движок не предоставляет такую возможность, всегда можно выкрутиться. Для примера, реализуем требуемый функционал на чистом POSIX Shell. Создадим несложную функцию smart_re, которая принимает на вход единственный аргумент — многострочное регулярное выражение с комментариями:
smart_re()(
printf '%s\n' "$1" | sed 's/#[^#]*$//' | tr -d '[:space:]'
)
Далее где‑то в скрипте:
RE_URL="$(smart_re '
\b # Граница слова
(https?|ftp|file) # Протокол (http, https, ftp, file)
:// # Разделитель
[-A-Z0-9+&@#/%?=~_|!:,.;]* # Домен и путь
[-A-Z0-9+&@#/%=~_|] # Последний символ не может быть разделителем
')"
После выполнения кода выше, переменная RE_URL будет содержать искомый шаблон, готовый к использованию всеми утилитами. Подобный лайфхак можно повторить на любом языке программирования.
Нелинейные структуры
Регулярные выражения заставят вас плакать при попытке применить их к документу с нелинейной логикой.
Вернемся к тезису из первой статьи: не парсить HTML/XML регулярками. Почему?
HTML — не регулярный язык, его структура древовидная. Регулярные выражения не умеют считать вложенность. Вы можете написать шаблон для поиска <p>…</p>, но он сломается на <p>…<div>…</div>…</p>. Для таких задач существуют специализированные, надежные инструменты — DOM-парсеры, которые понимают структуру документа.
Используйте регулярки для того, в чем они сильны: поиск, валидация и извлечение данных из линейного текста с предсказуемыми паттернами.
Заключение
Мы прошли большой путь: от простого hello, world до хитроумных просмотров назад. Познали и жадность, и ревность. Мы научились не только описывать текст, но и его контекст, структуру и даже оптимизировать процесс поиска. Регулярные выражения из пугающей абракадабры превратились в понятный и мощный инструмент.
Однако главный секрет мастерства — практика. Используйте регулярные выражения так часто, как это возможно. Что угодно: grep, sed, awk, Python, JavaScript, сервисы вроде Regex101, текстовые редакторы — что ближе к вашей деятельности, то и применяйте для тренировки. Экспериментируйте, отлаживайте и смотрите, как движок работает с шаблонами и что выдает.
Читайте документацию. Всегда помните о диалектах и ограничениях в различных реализациях. Особенно это касается сервисов для «простых» пользователей — например, в Google Doc нельзя указать захваченную группу в поле для замены. То, что работает в JavaScript, может иметь другой синтаксис в Python или PHP.
Начинайте с простого. Разбейте сложную задачу на маленькие подзадачи и решайте или отлаживайте их по одной, постепенно наращивая шаблон.
Надеемся, наш цикл статей поможет новичкам преодолеть «регекспофобию» и увидеть всю красоту и мощь этого удивительного языка.