Регулярные выражения. Часть 3. Захватывающие и незахватывающие группы
Продолжаем изучение. На очереди — группы, их виды, примеры применения. Поговорим также об использовании групп внешними инструментами.

Привет! В первой и второй частях мы с вами заложили фундамент: научились описывать как отдельные символы, так и их последовательности, в том числе повторения. Познакомились с «диалектами» регулярок, жадностью квантификаторов и якорями. Как в хорошем сериале, мы остановились на самом интересном месте — столкнулись с задачей, которую имеющимися инструментами решить до конца не получилось.
Так уж вышло, что выход третьей части несколько задержался. Исправляем упущение. Сегодня поговорим о группах — захвате, ссылках и управлением сложностью.
Незавершенное дело
Давайте освежим в памяти последний момент. Нашей целью был поиск всех отдельных слов в русском тексте, которые начинаются на «к» и заканчиваются на «а». После некоторых усилий мы создали вот такое выражение:
(^|[^а-яё])к[а-яё-]+а([^а-яё]|$)Оно действительно находит нужные слова. Но есть нюанс. Посмотрим на работу нашего шаблона в действии. Для этого, как и в предыдущих двух частях, воспользуемся сервисом regex101.com.
![Тестирование регулярного выражения: (^|[^а-яё])к[а-яё-]+а([^а-яё]|$) — все необходимые подстроки совпадают.](https://lh7-qw.googleusercontent.com/docsz/AD_4nXe_cy_OwQ9C5Qr3zhbuVwZDgky1scXl5z96ofcX27ufVqIFXOqrf8gbPKG4fOGeuznY4A-_m6axytDOWHBWvEQ-vvejELA5QIYMDV0XUrjLlekuHwwYy4VejhqdrIlF8La8CfWEyQ?key=nR4Pi9GgzMSRhXtNc34Tuw)
Проблема очевидна: в результат поиска попадают не только сами слова, но и символы, которые их окружают — пробелы, запятые, начало и конец строки.
Почему так происходит?
Движок регулярных выражений работает последовательно, «потребляя» символы один за другим. Чтобы убедиться, что «коза» — это отдельное слово, ему нужно проверить, что перед ним стоит не буква (в нашем случае пробел) и после него — тоже. Наш шаблон, точнее, его части (^|[^а-яё]) и ([^а-яё]|$), как раз и описывают эти граничные условия. Движок находит их, убеждается, что они соответствуют требованию, и включает их в итоговое совпадение. Он честно выполняет то, о чем просят.
Получается, мы используем окружение для проверки, но не хотим видеть его в финальном результате. А что, если бы мы могли сказать движку: «Вот эту часть шаблона, пожалуйста, найди, но не показывай»?
Именно для этого и существуют группирующие скобки (). Мы уже сталкивались с ними в первой части, когда объединяли варианты через оператор |. У скобок есть и вторая, куда более мощная функция.
Захватывающие группы и магия обратных ссылок
Круглые скобки в регулярных выражениях выполняют две задачи. Первая — это группировка, она позволяет применить оператор или квантификатор не к одному, а к целой последовательности символов. Вторая, и ключевая для нас сегодня, — это захват (capturing).
Представьте, что у каждой пары скобок есть крошечная фотокамера. В момент, когда движок находит в тексте фрагмент, соответствующий выражению внутри скобок, она делает снимок и сохраняет его в памяти. Эти кадры, то есть захваченные подстроки, становятся доступны для дальнейшего использования.
Каждая захватывающая группа получает свой порядковый номер. Последовательность начинается с единицы и определяется положением открывающей скобки в шаблоне, слева направо.
Например, в выражении (a(b(c)))d будет три группы:
- первая захватит
abc(внешние скобки), - вторая —
bc(вложенные), - третья — лишь
c(внутренние).
Сами по себе «снимки» полезны уже тем, что после нахождения совпадения мы можем программно извлечь только интересующие нас части. Но есть и кое-что поинтереснее. На захваченные группы можно указывать прямо внутри самого регулярного выражения. Для этого существуют обратные ссылки (backreferences), которые выглядят как \1, \2, \3 и так далее, где цифра — это номер захватывающей группы. Такая конструкция приказывает движку: «Найди здесь точно такой же текст, который был захвачен группой с номером N».
Это фундаментальный сдвиг в нашем подходе. До сих пор мы работали со статичными шаблонами: a всегда означало букву «а», \d — всегда цифру. Обратная ссылка — это динамический элемент. Ее значение определяется не заранее, а в процессе поиска — тем, что попало в соответствующую группу в текущей строке. Мы переходим от простого описания текста к заданию отношений между его частями.
Практический пример 1: поиск повторяющихся слов
Классическая задача, которая элегантно решается с помощью обратных ссылок, — это поиск повторяющихся слов в тексте — например, два одинаковых предлога во фразе «Я пошел в в магазин». Нам нужно найти слово, за которым после одного или нескольких пробелов следует точно такое же слово.
\b(\w+)\s+\1\bРазберем этот шаблон по частям.
\b— граница слова, она гарантирует, что мы начнем поиск с начала слова.(\w+)— наша первая (и единственная) захватывающая группа. Она ищет и «фотографирует» последовательность из одной или более «словесных» букв (буквы, цифры, знак подчеркивания).\s+— один или несколько пробельных символов.\1— а вот и магия. Эта конструкция ищет точную копию текста, который был захвачен первой группой(\w+).\b— еще одна граница слова, чтобы убедиться, что второе слово закончилось.
Посмотрим, как это работает на практике.
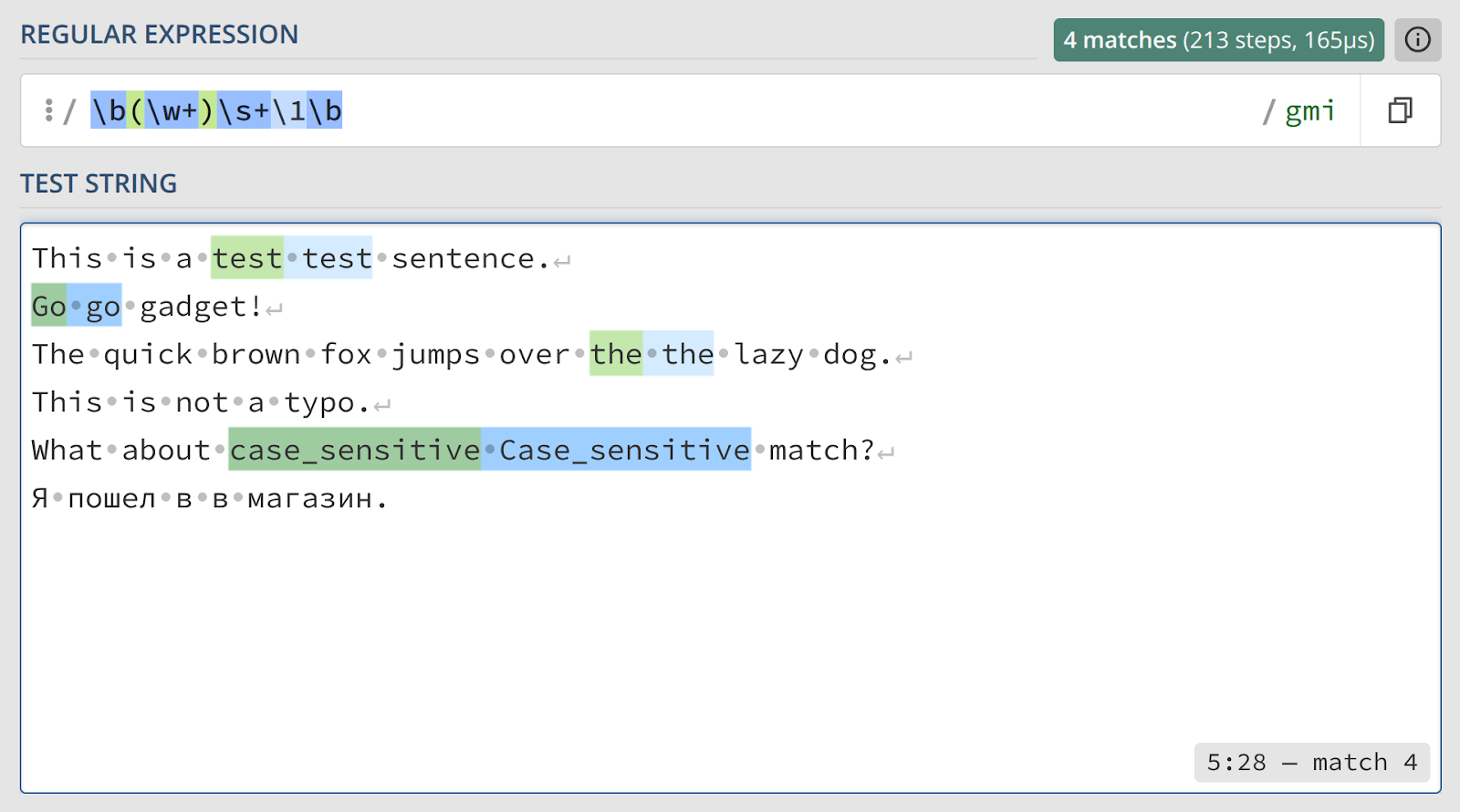
Посмотрим на получившийся результат.
test test— группа(\w+)захватывает «test», а\1успешно находит его второе вхождение.Go go— мы использовали флагi(case-insensitive), поэтому регистр не имеет значения.the the— также находится.- Совпадений нет.
case_sensitive Case_sensitive— без флага i не сработало бы.- Упс! Да что ж такое?! Двойной предлог в не нашелся!
Да, мы уже говорили в предыдущей части о том, что стандартные маркеры — например, сло́ва \w и его границы \b — всегда работают корректно исключительно с символами из набора ASCII. Здесь многое зависит от конкретной реализации движка. К примеру, в простом текстовом редакторе Xed все вхождения находятся правильно:
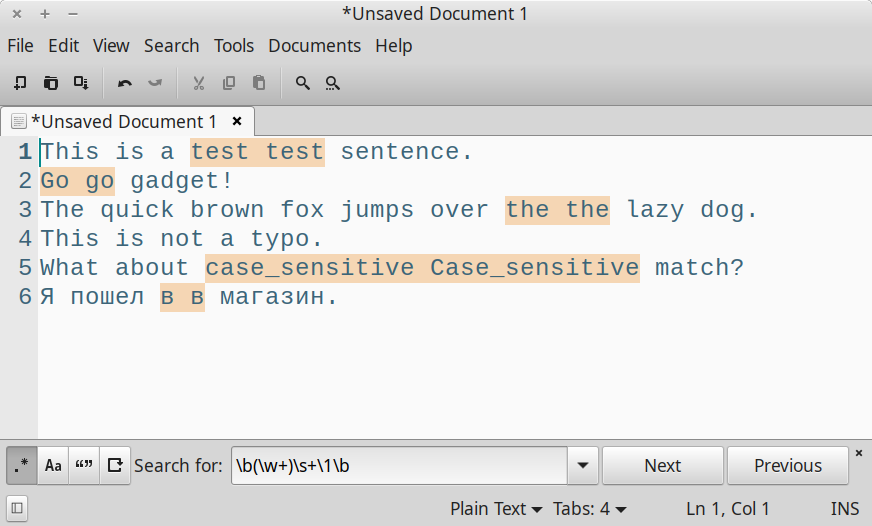
В некоторых реализациях можно указывать \p для символов Unicode.
Такое ограничение не означает, что надо забыть о простых маркерах вроде \b, \w и других. Во многих задачах требуется разбирать текст с английскими терминами — например, лог какого-нибудь сервиса. Упрощенные обозначения удобны в использовании — их вполне целесообразно применять. Но не обожгитесь, когда будете работать с текстом, в котором круг символов не ограничивается латиницей, а движок понимает только ASCII‑набор!
Адаптируем наш пример так, чтобы он работал универсально, независимо от возможностей конкретного движка.
(^|\W)([a-zA-Zа-яА-ЯЁ0-9_]+)\s+\2(\W|$)Выражение стало сложнее, разберем его по частям.
(^|\s)— это наша первая захватывающая группа. Она описывает левую границу: начало строки^или|пробельный символ\s.([a-zA-Zа-яА-ЯЁ0-9_]+)— а это вторая захватывающая группа. Она ищет и «фотографирует» последовательность из одной или более букв, цифр или знаков подчеркивания — наше слово.\s+— один или несколько пробельных символов-разделителей.\2— снова магия. Эта конструкция ищет точную копию текста, который был захвачен второй группой([a-zA-Zа-яА-ЯЁ0-9_]+). Обратите внимание, мы используем\2, а не\1, так как группа с самим словом теперь вторая по счету.(\s|$)— третья захватывающая группа, описывающая правую границу: пробел или конец строки$.
Снова посмотрим, как это работает на практике.
![Тестирование регулярного выражения: (^|\W)([a-zA-Zа-яА-ЯЁ0-9_]+)\s+\2(\W|$) — кириллические слова находятся корректно.](https://lh7-qw.googleusercontent.com/docsz/AD_4nXdpC3J0jruzBDwzyhy7FsD6y8uaCm9Yx6lnFCCJxvLJm8rw81IT7v1nP-4j_iI_u0aS7EuWWjFzbUDRTVTemL7LfOxQFoaEUtsqtrHYblktDjChKvltwQm6nCtJoxZSwUk_bnqc8w?key=nR4Pi9GgzMSRhXtNc34Tuw)
Подход, когда явно прописываются допустимые символы, универсально решает проблему с кириллицей.
Практический пример 2: валидация простых парных тегов
В первой статье мы предупреждали, что парсить HTML/XML с помощью регулярок — плохая затея. Это правда, потому что структура такой разметки древовидная и требует контекстного анализа. Здесь нужны другие инструменты — например, XPath. Однако для очень простых и ограниченных задач, вроде поиска парных тегов одного уровня, вполне сгодятся и обратные ссылки.
Предположим, нам нужно найти все закрытые теги — например, <p>…</p> или <b>…</b>, — но при этом отбросить некорректные — такие, как <h1>…</h2>.
Сконструируем такой шаблон:
<([a-z]+)>.*?<\/\1>Снова препарируем выражение.
<— литерал, открывающая угловая скобка.([a-z]+)— первая захватывающая группа. Она находит и запоминает имя тега, состоящее из одной или нескольких латинских букв.>— литерал, закрывающая угловая скобка..*?— любое количество любых символов (кроме переноса строки), но в ленивом режиме. Нам важно, чтобы поиск остановился на первом же подходящем закрывающем теге, а не на последнем в строке.</— литералы, начало закрывающего тега.\1— снова обратная ссылка. Она требует, чтобы здесь стояло то же самое имя тега, что было захвачено в группу 1.>— финальная закрывающая угловая скобка.
Проверим конструкцию на тестовых данных.

Выражение работает, как и ожидалось.
- Группа
1захватываетp,\1успешно находитpв закрывающем теге. - То же происходит и во второй строке: захватывается
b, а\1находитb. - Нет совпадения: группа
1захватываетh1, но\1не может найтиh1после</, так как там стоитh2. - Нет совпадения: тег
<i>не закрыт. - Ленивый квантификатор
.*?захватывает два тега<div>…</div>по отдельности. Если бы мы не добавили?, то эта строка была бы захвачена целиком. - Хороший пример, почему регулярные выражения плохо подходят для нелинейных структур: тег
<strong>оказался захвачен только благодаря тому, что тег<div>не закрыт из‑за опечатки.
«Околорегулярные» выражения
Этот раздел будет небольшим, но полезным отступлением.
Важно не путать обратные ссылки в шаблоне \1 с конструкциями для замены ($1 или \1 в зависимости от инструмента). Первое — это часть логики поиска, инструкция для движка регулярных выражений. Второе — условность редактора или функции в коде, которая указывает, куда подставлять найденные значения.
Рассмотрим практическую задачу, чтобы раз и навсегда прояснить эту разницу. Допустим, у нас есть список людей в формате «Фамилия Имя», и мы хотим преобразовать его в формат «Имя Фамилия». Например:
Иванов Пётр
Сидорова Анна
Красин-Волконский ВасилийДля решения этой задачи нам нужно выполнить операцию «найти и заменить». Сохраним данные в файле Users.txt.
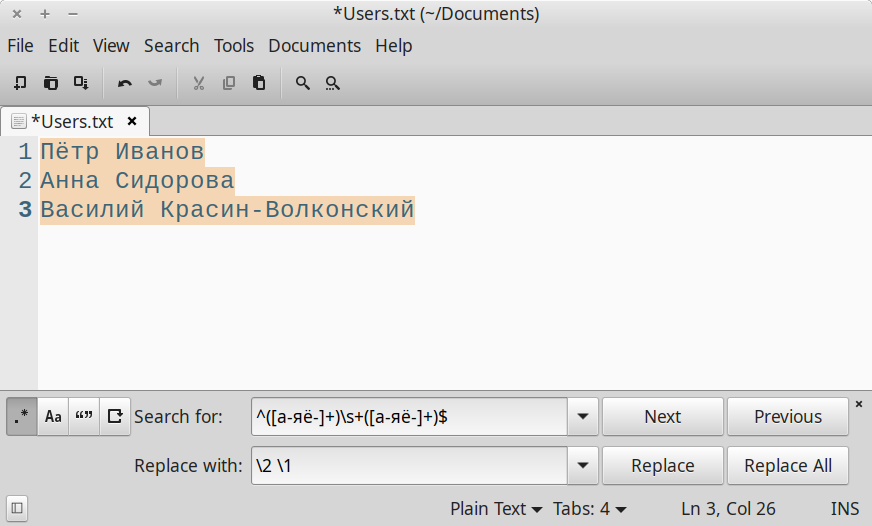
Прежде всего создадим выражение, которое ищет строки из двух разделенных пробелом слов и захватывает каждое из них в отдельную группу:
^([а-яё-]+)\s+([а-яё-]+)$Разберем это несложное выражение.
^и$— якоря начала и конца строки, чтобы обрабатывать ее целиком.([а-яё-]+)— группа №1 захватывает фамилию. Будем использовать дефис для поддержки двойных фамилий.\s+— один или несколько пробелов между словами.([а-яё-]+)— группа №2 захватывает имя.
Обратите внимание на важный момент: в этом шаблоне нет обратных ссылок \1 или \2. Мы не ищем повторяющийся текст. Мы просто захватываем два разных слова в две разные группы, чтобы использовать их во внешнем инструменте.
Напомним также, почему дефис идет последним перед закрывающей квадратной скобкой — так он теряет свое особое значение.
Немного о типографике и Unicode
В подавляющем большинстве случаев в Вебе используются символ, который называется дефис‑минус, его код — 0x002D.
Однако могут встречаться и внешне похожие варианты: настоящий дефис 0x2010, неразрывный дефис 0x2011, среднее тире (en dash) 0x2013 и настоящий минус 0x2212. Перечень символов, похожих на дефис, этими примерами не исчерпывается: есть указатель возможного разрыва для переноса 0x2027, дефисоподбный буллет 0x2043 и национальные дефисы, как в армянском языке 0x058A.
Не исключено, что вам когда‑то придется применять регулярные выражения для работы с самыми разными документами. Если вдруг ваш шаблон непостижимым образом не работает — удостоверьтесь, что нет непривычных для вас символов — таких как всевозможные виды дефисов и неразрывных пробелов.
Мы в наших примерах для упрощения ограничимся единственным вариантом дефиса — тем, для набора которого не приходится задумываться над клавиатурой.
Теперь нам нужно указать, как собрать новую строку из захваченных частей. Мы хотим поменять группы местами. Обозначение — в большинстве случаев \1 или $1 — зависит от инструмента, который будет использоваться. Это может быть как текстовый редактор, так и утилита командной строки. Мы рассмотрим оба случая.
Текстовый редактор
Продолжим испытывать простенький Xed. Все готово для замены — осталось только нажать кнопку:

Проверяем. Вуаля:
Программный способ
Воспользуемся простейшей утилитой для работы с регулярными выражениями — неинтерактивным редактором Sed. Применим для замены команду s и, поскольку выражение очень простое, введем его прямо в терминале Linux:
cat Users.txt | sed -E 's/^([а-яё-]+)\s+([а-яё-]+)$/\2 \1/g' > Reversed.txt
Готово! Можно посмотреть содержимое файла Reversed.txt:
cat Reversed.txt
Оно в точности соответствует ожиданию:
Пётр Иванов
Анна Сидорова
Василий Красин-ВолконскийНесколько слов о том, что включала в себя команда Shell.
cat Users.txt— поместить содержимое файла в стандартный поток вывода.| sed -E— передаем вывод по конвейеру на ввод редактора sed и включаем расширенный (Extended) режим. Под словом «расширенный» можно понимать современный или распространенный — это диалект, который встречается в различных движках, и на который мы опираемся в нашем курсе.s/^([а-яё-]+)\s+([а-яё-]+)$/\2 \1/g— командаsпринимает аргументы, разделенные ASCII-символом, стоящим сразу за ее именемs. Чаще всего используется наклонная черта, но иногда удобно взять, скажем,#— сгодится любой простой печатный символ, который не встречается в аргументах.- Первый аргумент ^([а-яё-]+)\s+([а-яё-]+)$ — наше регулярное выражение.
- Второй аргумент
\2 \1— объясняет, что делать с захваченными группами. Мы ставим вторую группу, затем пробел, наконец первую группу — ничего нового по сравнению с визуальным редактором. - Третий аргумент команды
g— говорит от том, что действовать надо глобально, а не до первого совпадения. > Reversed.txt— сохранение стандартного вывода в файл с полной перезаписью последнего.
Еще раз. В рассмотренном примере \1 и \2 не являются частью регулярного выражения. Мы не ссылаемся в самом шаблоне на повторяющийся текст, не включаем его в поиск при работе движка. Мы во внешнем инструменте внешне похожим способом указываем на подстроки, захваченные соответствующими группами. Как говорится в известных мемах: «Не перепутай!»
Когда захват не нужен
Мы выяснили, что скобки () всегда создают захват. Но что, если они нужны нам только для группировки, а сохранять результат — лишняя работа? Например, в нашем выражении из первой статьи (hello|привет), world скобки лишь для того, чтобы показать: world относится ко всем вариантам приветствия, а запоминать hello или привет нет смысла.
Для таких случаев существуют незахватывающие группы. Их синтаксис отличается тем, что сразу после открывающей скобки идет знак вопроса и двоеточие — (?:шаблон группы). Они работают точно так же, как и обычные скобки, с одним отличием: не создают «снимок» и не получают номера.
Зачем это нужно? Причин две, и обе связаны с профессиональным подходом к написанию кода.
Читаемость и чистота. Когда вы пишете сложный шаблон для извлечения данных, в нем может быть много групп. Некоторые из них — ключевые (например, имя пользователя, дата), а другие — вспомогательные, нужные только для логики. Использование вспомогательных групп избавляет от «мусора» в результатах. Если вам нужна третья по счету значимая часть данных, вы получите к ней доступ как \3, а не как \7 — из‑за того, что перед ней были еще четыре служебные группы.
Производительность. Каждая захватывающая группа требует от движка выделить память и сохранить найденную подстроку. На очень больших текстах и в по‑настоящему сложных выражениях отказ от ненужных захватов может дать небольшое, но заметное ускорение. Что еще важнее — дается явный сигнал движку и другим разработчикам о намерении: «Эта часть шаблона нужна только для структуры, ресурсы на нее тратить не нужно».
По сути, обычные скобки () нарушают принцип единой ответственности, совмещая группировку и захват. Незахватывающие группы (?:) позволяют разделить эти задачи. Это признак зрелого подхода: использовать (?:) по умолчанию и переходить к () только тогда, когда захват действительно необходим.
Наконец, мы можем исправить наш сложный пример из предыдущих статей с использованием этого знания. Исходный вариант:
(h[ea]llo|привет|bonjour)(\s*,\s*|\s+)world!*Здесь создаются две захватывающие группы: одна — для приветствия, другая — для разделителя. Скорее всего, они нам не нужны, если мы просто хотим проверить строку на соответствие. Улучшенный вариант:
(?:h[ea]llo|привет|bonjour)(?:\s*,\s*|\s+)world!*Функционально этот шаблон идентичен первому, но он не создает никаких паразитных захватов. Он чище, эффективнее и ясно показывает: внутренняя структура нужна только для логики, а не для извлечения данных.
![Тестирование регулярного выражения: (?:h[ea]llo|привет|bonjour)(?:\s*,\s*|\s+)world!* — все соответствующие строки подсвечены.](https://lh7-qw.googleusercontent.com/docsz/AD_4nXcBhxC6UHSQCPKWed1gZs3xhqe4OR5F-61B59ysGRh8r6Cgr4APFV154fYIxH-fp2vCcnSU6qU_Nxif8aST9qYJDCWWoh1CgvGSOWdWutv3yz8N0Jr3pcDthlqtqybfiEp83n5kOw?key=nR4Pi9GgzMSRhXtNc34Tuw)
Во всех случаях совпадение есть, но список захваченных групп пуст.
Именованные группы
Использование нумерованных групп \1, \2 имеет забавный побочный эффект: через месяц даже вы сами не сможете вспомнить, что означает группа № 7 в каком‑то монструозном выражении. Если же понадобится добавить новую группу в середину шаблона — эффект можно будет сравнить с приходом тайфуна прямо внутрь регулярки. Вся нумерация «съедет», придется внимательно исправлять и перепроверять обратные ссылки, включая внешний код, который обрабатывает группы.
К счастью, существует элегантное решение — именованные группы. Это современная, читаемая и надежная альтернатива номерам. Они превращают «одноразовые» регулярки в полноценные поддерживаемые компоненты кода.
Синтаксис для определения такой группы — (?<произвольное имя>). Обратите внимание: угловые скобки вокруг имени — реальная часть синтаксиса, а не показатель некой условности. Для обратной ссылки на именованную группу используется конструкция \<имя нужной группы>.
В некоторых диалектах написание может слегка отличаться. Например, в Python используется (?P<произвольное имя>). Для обратной ссылки на группу часто используется конструкция \k<имя нужной группы>.
Главное преимущество такого подхода — самодокументируемость и устойчивость к изменениям. Можно добавлять, удалять и перемещать группы, не боясь при этом сломать ссылки — они привязаны к имени, а не позиции.
Практический пример: парсинг структурированных данных
Вернемся к задаче из первой статьи — извлечение даты и имя пользователя из строки вида:
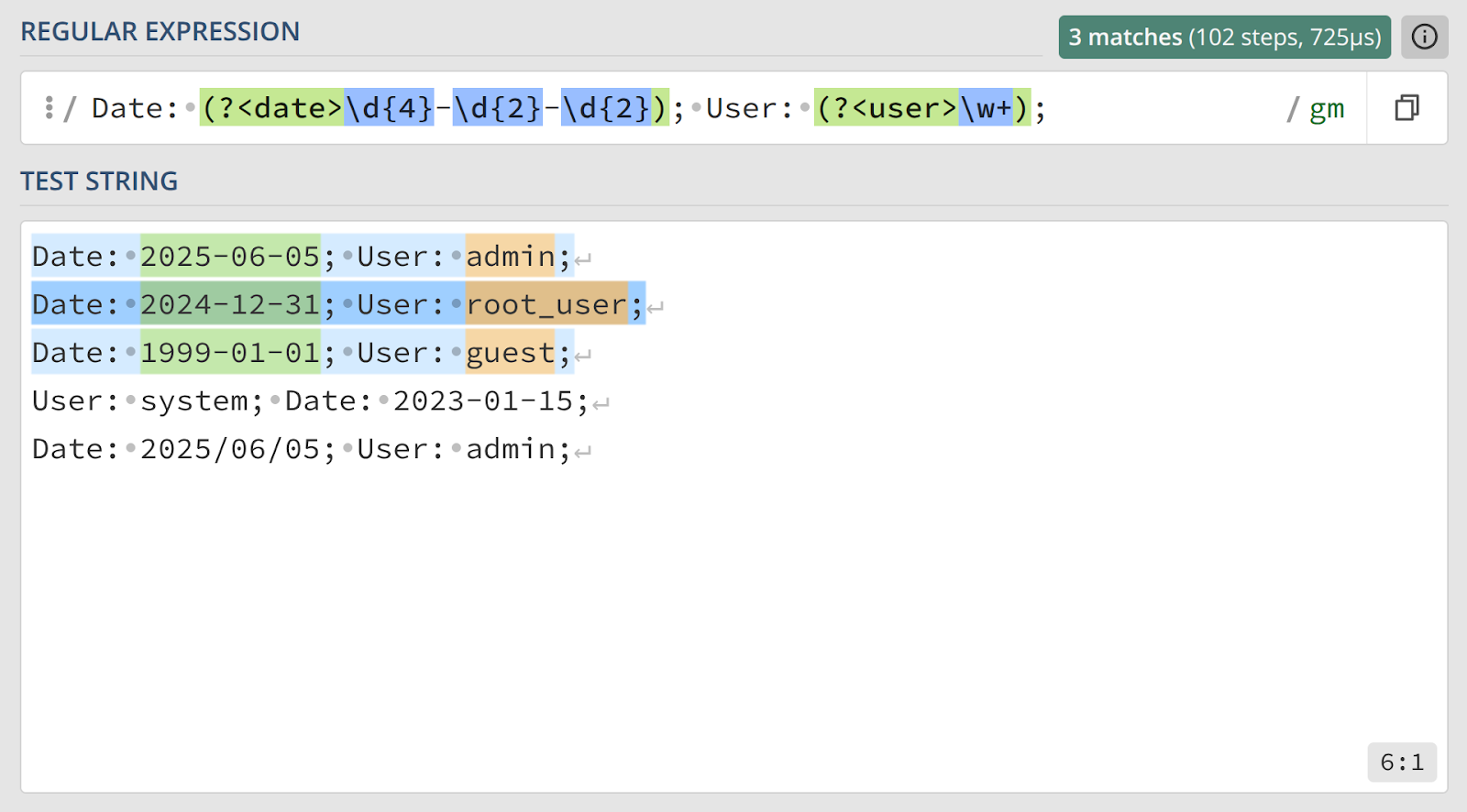
Date: 2025-06-05; User: admin;Решение с нумерованными группами:
Date: (\d{4}-\d{2}-\d{2}); User: (\w+);Чтобы получить имя пользователя, в коде пришлось бы прописывать номера групп — не очень наглядно, да и еще и надо следить за изменениями. Посмотрим на решение с именованными группами:
Date: (?<date>\d{4}-\d{2}-\d{2}); User: (?<user>\w+);Разберем его чуть подробнее.
Date:— литеральная часть.(?<date>\d{4}-\d{2}-\d{2})— именованная группаdate. Она захватывает последовательность, подходящую под форматYYYY-MM-DD.; User:— еще одна литеральная часть.(?<user>\w+)— именованная группаuser, захватывает имя пользователя.;— финальный литерал.
Теперь в коде можно написать user = match.groups['user'] — синтаксис условный, зависит от языка, конечно. И поддерживать не придется, и комментариев не потребуется!
Заключение
Сегодня мы сделали огромный шаг вперед — перешли от простого поиска совпадений к их детальному анализу и деконструкции. Группы — это наш скальпель. Мы научились:
- захватывать нужные части совпадения — с помощью
(); - ссылаться на захваченный текст прямо в шаблоне — благодаря
\1; - игнорировать захват там, где он не нужен — применяя
(?:); - именовать группы для надежности — прибегая к
(?<name>).
Теперь, вооружившись этими знаниями, вернемся к нашей проблеме, которой закончили предыдущий урок — поиску слов, начинающихся на «к» и заканчивающихся на «а». Наш шаблон был таким:
(^|[^а-яё])к[а-яё-]+а([^а-яё]|$)Сложность была в том, что граничные символы попадали в результат. Теперь мы можем это исправить. Идея проста: обернем часть, описывающую само слово, в захватывающую группу, а части, задающие границы, — в незахватывающие.
(?:^|[^а-яё])(к[а-яё-]+а)(?:[^а-яё]|$)Что изменилось?
- Граничные условия
(^|[^а-яё])и([^а-яё]|$)теперь обернуты в(?:). Они по-прежнему участвуют в поиске, движок их «потребляет», но захватов не создается. - Само слово
к[а-яё-]+аобернуто в(). Теперь это первая и единственная захватывающая группа.
Каков будет результат? Полное совпадение по-прежнему будет содержать лишние символы, потому что движок нашел их. Однако теперь в объекте совпадения у нас есть группа № 1, которая содержит только то, что нам нужно — само слово коза. Это огромный прогресс! Мы изолировали искомые данные.
![Тестирование регулярного выражения: (?:^|[^а-яё])(к[а-яё-]+а)(?:[^а-яё]|$) — все требуемые слова найдены, окружающие их символы не захвачены.](https://lh7-qw.googleusercontent.com/docsz/AD_4nXfevMoq_g9Nr3gjW1A6x7mKpMpN4Y5rAw3wuWrJsd42vpL4c-NtS7CMPTz83ku1FgZw58hhpy-Fi_iVqXgpOoWxvZiU3PhODE21-YqeWfQi2o3tp5G2Sipi8U5FFjFZy_k4a7CWvw?key=nR4Pi9GgzMSRhXtNc34Tuw)
И все же, наше решение пока похоже на обходной путь. Мы все еще вынуждены «съедать» символы-границы, чтобы их проверить, хоть и научились их игнорировать в результатах. Это как если бы для проверки спелости яблок приходилось надкусывать и выплевывать. Разве нельзя просто как‑то по‑хитрому взглянуть, чтобы сразу стало ясно: кислое или сладкое?
Что, если бы мы могли просто посмотреть на соседние символы, не включая их в совпадение и даже не сдвигая с них курсор? Что, если бы существовал способ описать контекст, вообще не делая его частью найденного фрагмента?
Такой способ есть. Именно для этого существуют «заглядывания вперед и назад» (lookarounds) — мощный и, пожалуй, самый неинтуитивный инструмент в регулярных выражениях. Но об этом — в следующей части.