Регулярные выражения. Упражнения. От основ до мастерства
Мы завершили серию из четырех статей, посвященную регулярным выражениям. Чтобы пройденный материал закрепился, подготовили практические упражнения.

Этот сборник из 18 задач поможет вам закрепить знания, полученные из теоретической части курса, который включал в себя материалы по следующим темам.
1. Основы и применяемые инструменты.
2. Символьные классы, якоря и квантификаторы.
3. Захватывающие и незахватывающие группы.
4. Просмотр вперед и назад, а также несколько советов.
Упражнения расположены по принципу «от простого к сложному» и охватывают все ключевые моменты: от поиска литералов и квантификаторов до продвинутых техник с группами и контекстными проверками.
В первой части — задания. Каждое из них — небольшой практический кейс, который потребует от вас составить регулярное выражение. Чтобы вам было проще, для каждого случая мы подготовили небольшой экспериментальный текст.
Вторая часть — ответы. Ниже вы сможете сравнить свои варианты с предложенными, а также прочитать подробные объяснения.
Удачи!
Часть 1: Основы и базовый синтаксис
Начнем с самых азов — задачи основаны на материале из первой статьи.
1. Поиск года
Задание
Найдите все годы в историческом тексте.
Текст для проверки
The document was dated 1812. It mentions events from 1789 and 1805. The author, born in 1770, lived for 67 years. The total cost was 1200 gold coins. Chapter 5 describes the battle.
2. Символьные классы
Задание
Напишите регулярное выражение, которое найдет все гласные буквы в русском тексте.
Текст для проверки
Ау, я иду! Эхо унесло её крик в ущелье. Оаэ, ау! Это было странное эхо.
3. Необязательные символы
Задание
Вы обрабатываете текст, который сочетает как американское, так и британское написание. Напишите регулярное выражение, которое находит и «color», и «colour».
Текст для проверки
The color of the flag is red. My favourite colour is blue. This is a colorful painting. What color do you prefer?
4. Группировка альтернатив
Задание
Найдите в тексте полные приветствия «Добрый день» и «Добрый вечер».
Текст для проверки
Добрый день, коллеги! Начинаем наше совещание. Добрый вечер. Завтра утром будет хорошая погода, а вот вечер обещает быть дождливым.
5. Поиск фразы
Задание
Напишите регулярное выражение, которое найдет в тексте все словосочетания про… регулярные выражения. При составлении решения учитывайте, что регистр букв разный, а кое‑где встречаются двойные пробелы.
Текст для проверки
Регулярные выражения — это мощный инструмент. Каждое регулярное выражение представляет собой шаблон для поиска. Изучать регулярные выражения интересно.
Часть 2: Управление поиском
Мы освоили базовый синтаксис. Теперь перейдем к более тонкому управлению процессом поиска. Задачи в этом разделе основаны на материале второй статьи и познакомят вас с якорями, жадностью, встроенными классами и обработкой границ слов.
6. Валидация всей строки
Задание
Найдите строки, которые включают слово «SUCCESS» и ничего больше.
Текст для проверки
SUCCESS
ATTEMPT FAILED, BUT… SUCCESS
IN_PROGRESS
SUCCESS!
7. Жадность и лень
Задание
Извлеките содержимое всех тегов <b> из фрагмента HTML. Напишите регулярное выражение, которое правильно обрабатывает несколько тегов в одной строке.
Текст для проверки
This is <b>important</b> and this is <b>also important</b>.
8. Встроенные классы символов
Задание
В лог-файле события записываются с меткой времени в формате ГГГГ-ММ-ДД ЧЧ:ММ:СС. Напишите лаконичное регулярное выражение для поиска таких меток.
Текст для проверки
[2023-10-26 15:30:01] User ‘admin’ logged in.
[2023-10-26 15:31:15] Service ‘nginx’ restarted.
Invalid entry: 2023/10/26 15:32:00
[2023-10-26 15:35:45] WARNING: Disk space low.
9. Исключающие наборы
Задание
Найдите знаки препинания. Вместо того, чтобы перечислять их все, напишите регулярное выражение, которое находит любой символ, но не букву, цифру или пробел.
Текст для проверки
Hello, world! How are you? I’m fine, thank you. (And you?)
10. Извлечение доменов
Задание
У вас есть список email-адресов. Напишите регулярное выражение, которое позволит извлечь из каждого адреса только доменное имя (часть после символа @).
Текст для проверки
test.user@example.com
info@company.net
support@help-desk.org
Часть 3: Сила групп и обратных ссылок
Находить нужные фрагменты текста мы научились. Сделаем следующий шаг: будем их деконструировать, извлекать нужные части и даже ссылаться на них внутри самого шаблона. Задачи этого блока основаны на третьей статье и посвящены группам.
11. Проверка парных конструкций
Задание
Найдите правильно сформированные простые HTML-теги, такие как <h1>…</h1> или <strong>…</strong>.
Текст для проверки
<p>This is a paragraph.</p>
<b>This is bold.</b>
<h1>This is a header.</h2>
<i>This is italic but not closed.
12. Извлечение кодов
Задание
Из строк ниже нужно извлечь числовой код товара. Напишите выражение, которое создает захватывающую группу только для требуемых данных, но не для текстового префикса.
Текст для проверки
Артикул: 00789
Код товара: 98123-A
Артикул: 55443
13. Читаемость с именованными группами
Задание
Вам нужно разобрать (распарсить) структурированную строку лога, чтобы получить дату, событие и имя пользователя. Напишите читаемое регулярное выражение, используя именованные группы.
Текст для проверки
Дата: 2023-10-26; Событие: Вход; Пользователь: admin;
Часть 4: Контекст и профессиональные техники
Мы подошли к заключительной теме. Задачи этого финального блока, основанные на четвертой статье, потренируют вас работать с самым мощным и неинтуитивным инструментом — утверждениями нулевой ширины, или lookarounds. Они позволяют описывать контекст, в котором должно (или не должно) находиться совпадение, не включая сам контекст в результат.
14. Позитивный просмотр вперед
Задание
Найдите все слова, за которыми сразу следует двоеточие, но не включайте его в само совпадение.
Текст для проверки
User: admin
Status: success
Action: login.
Note the final dot.
15. Позитивный просмотр назад
Задание
Извлеките все числовые значения валют, которым предшествует знак фунта £, не включая в результат сам знак и другие посторонние символы.
Текст для проверки
The price is £50. The dollar price is $60. Another item costs £25.50.
16. Негативный просмотр вперед
Задание
Найдите все упоминания слова «отчет», за которыми не следует слово «готов».
Текст для проверки
Ежедневный отчет сформирован. Статус: отчет готов. Пожалуйста, проверьте последний отчет. Отчет за вчерашний день.
17. Негативный просмотр назад
Задание
Найдите все вхождения «error», если этому слову не предшествует «warning: » — обратите внимание на пробел после слова. Поиск должен работать независимо от регистра букв.
Текст для проверки
System Error: 404.
Warning: Error: 503.
An unexpected error occurred.
Log entry: [Error]
18. Границы слов в кириллице
Задание
Найдите все отдельные вхождения слова «задача» в тексте. Учтите, что стандартный маркер границы слова \b может некорректно работать с кириллицей в некоторых движках.
Текст для проверки
Это простая задача. Главная задача — решить все подзадачи. Усложним задачу: задача1.
Ответы и объяснения
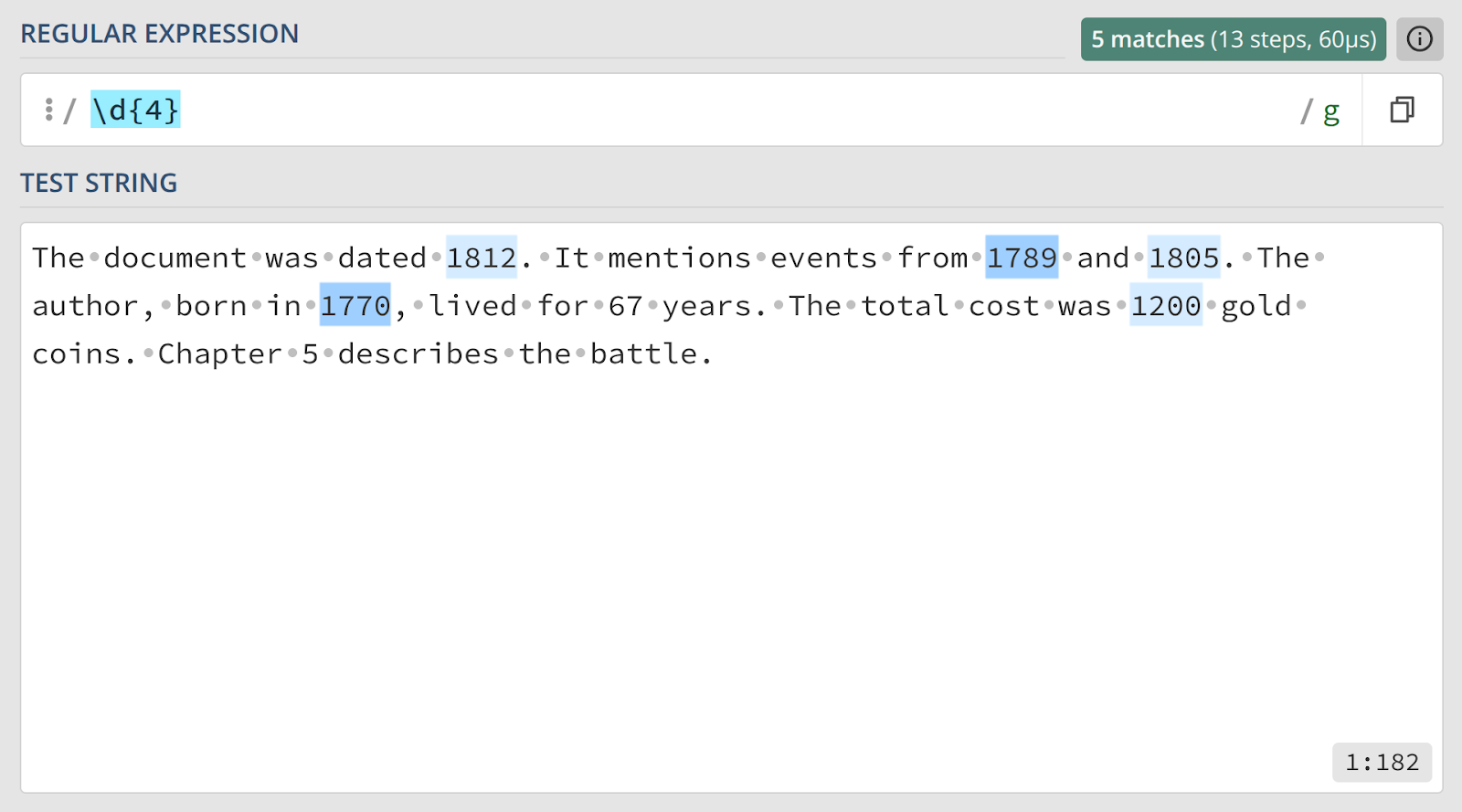
1. Поиск года
Правильный ответ
Объяснение
Этот шаблон использует две важные концепции.
\d— встроенный класс символов, который соответствует любой одной цифре от 0 до 9. Использование\dкороче и понятнее, чем запись[0-9].{4}— квантификатор, который указывает, что предшествующий ему элемент (в нашем случае\d) должен встретиться ровно четыре раза.
Таким образом, выражение \d{4} читается как «найди последовательность, состоящую ровно из четырех цифр». Числа 67 и 5 в результирующую выборку не попадут, так как не содержат четырех цифр.
2. Символьные классы
Правильный ответ
![Тестирование регулярного выражения: [АаЕеЁёИиОоУуЫыЭэЮюЯя] — все гласные русского языка найдены.](https://lh7-qw.googleusercontent.com/docsz/AD_4nXeGyX-B3blRGLiO_yO4ZudCIoPiw7V4nSpOzzFzSqe8gVSDCy5r2uqA_o5jGJ9HuSCTHEEsCqmQEwyHoUypqL_V1lWKn0eJHfgUFC6QrnRbac7yPwDye_gr8Zgzj0dyKzNR5ViMKg?key=KMcmNJeP2j3uewzhKHuHtA)
Объяснение
Здесь мы комбинируем символьный класс и квантификатор.
[АаЕеЁёИиОоУуЫыЭэЮюЯя]— символьный класс. Квадратные скобки позволяют задать набор символов, любой из которых может находиться в данной позиции. Мы перечислили все гласные буквы русского алфавита.+— квантификатор, который означает «один или более раз». Он эквивалентен записи{1,}.
Можно было бы использовать флаг i. Однако мы помним, что нелатинские буквы некоторые движки правильно не обрабатывают, поэтому явно прописываем заглавные буквы в символьном классе.
3. Необязательные символы
Правильный ответ
![Тестирование регулярного выражения: \bcolo[u]?r\b — и «color» и «colour» найдены. Ненужное слово «colorful» — нет.](https://lh7-qw.googleusercontent.com/docsz/AD_4nXcGyhEI6dqFxLV9gOQbHhl_VwgXExnhQmmA3zF1IMhCp-Ya1Gn9B9KM6X5wrAgt7NJ8-PF5l3vW8Zpz5RdNYu84XDuRxTBac1svsuF1baDv32rfMNdHAKi8JtORVOj3gM52QlEK?key=KMcmNJeP2j3uewzhKHuHtA)
Объяснение
Эта задача демонстрирует, как обрабатывать необязательные части в шаблоне.
coloиr— это литералы, которые должны присутствовать в строке.u?— необязательная часть. Квантификатор?означает «ноль или одно повторение» предшествующего символа и является сокращением для{0,1}.\b— граница слова. Мы ее используем, чтобы в выборку не попадали слова, содержащие в себе «color» или «colour» — например, «colorful».
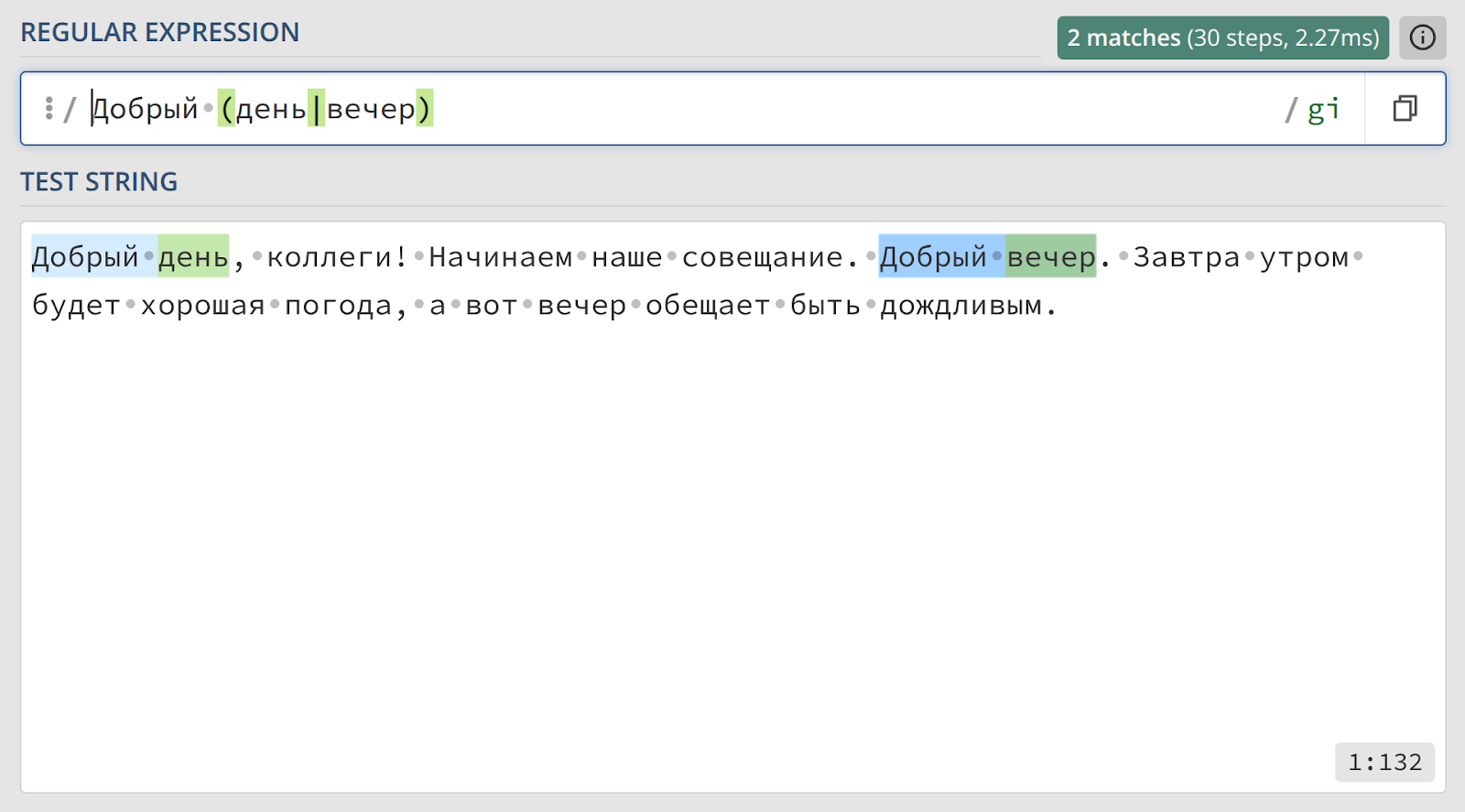
4. Группировка альтернатив
Правильный ответ
Объяснение
Эта задача иллюстрирует важность группировки при использовании оператора альтернативы.
|(вертикальная черта) позволяет выбрать один из нескольких вариантов. Наивная попытка —Добрый день|вечер— сработает неправильно. Она будет интерпретироваться как «найдиДобрый деньили найдивечер».()— группирующие скобки. Они позволяют ограничить область действия оператора. В выраженииДобрый (день|вечер)скобки указывают, что альтернатива|применяется только к словам «день» и «вечер».
5. Поиск фразы
Правильный ответ
![Тестирование шаблона: [Рр]егулярн\S\+\s+выражени\S* — все фразы про регулярные выражения найдены.](https://lh7-qw.googleusercontent.com/docsz/AD_4nXcuNdX_1dY--XrE3WH2gDa4MUxMDiWCueo1uMX_FoCEv5yZj03e9HOyJPNpdFfJAS-tDxb3gQCdkYFvpQWcCl_KqL8vUgQDUO97tzn-j4j_r7HMnapPstu0nYHa_P4bUURlMewb_w?key=KMcmNJeP2j3uewzhKHuHtA)
Объяснение
Неизменяемую часть регулярного выражения мы записываем как есть, а вариативные окончания обозначаем как «любой символ, не являющийся пробелом».
Далее мы обозначаем промежуток между словами, которые в действительности может состоять и не из одного пробельного символа. Поскольку некоторые движки некорректно работают с кириллицей, на чем мы неоднократно останавливались в наших статьях, то чтобы сделать поиск независимым от регистра символов, недостаточно использовать флаг i — приходится прописывать символьный класс.
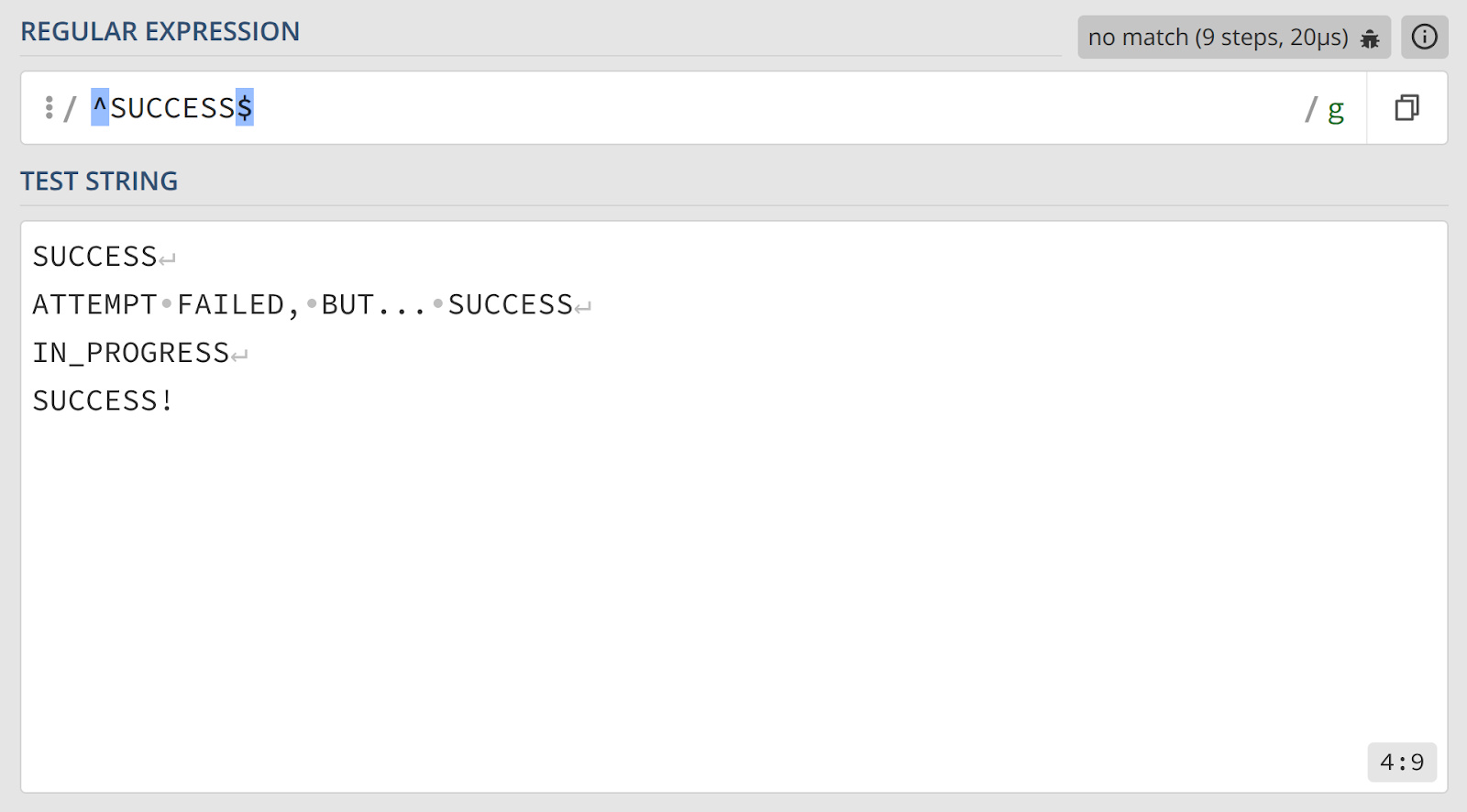
6. Валидация всей строки
Правильный ответ
Объяснение
По умолчанию регулярное выражение находит совпадение, если оно является частью строки. Для строгой валидации, когда вся строка должна соответствовать шаблону, используются якоря.
^— якорь начала строки утверждает, что совпадение должно начинаться с самого первого символа текста.$— якорь конца строки требует, чтобы совпадение заканчивалось на самом последнем символе.
7. Жадность и лень
Правильный ответ

Объяснение
Это классический пример, демонстрирующий разницу между «жадным» и «ленивым» поведением квантификаторов.
<b>и</b>— литералы, обозначающие открывающий и закрывающий теги. Обратите внимание, что в некоторых реализациях слэши/могут использоваться для задания самого регулярного выражения. В таких случаях его надо экранировать:\/..*— это жадный квантификатор. Он пытается захватить как можно больше символов. Если бы мы написали<b>.*</b>, выражение нашло бы один большой фрагмент от первого<b>до самого последнего</b>, а результат был бы<b>important</b> and this is <b>also important</b>..*?— знак вопроса включает ленивый режим. Теперь захватывается минимально возможное количество символов, чтобы удовлетворять шаблону. В нашем случае.*?остановится на первом же найденном</b>и позволяет правильно извлечь каждый тег по отдельности:<b>important</b>и<b>also important</b>.
8 . Встроенные классы символов
Правильный ответ
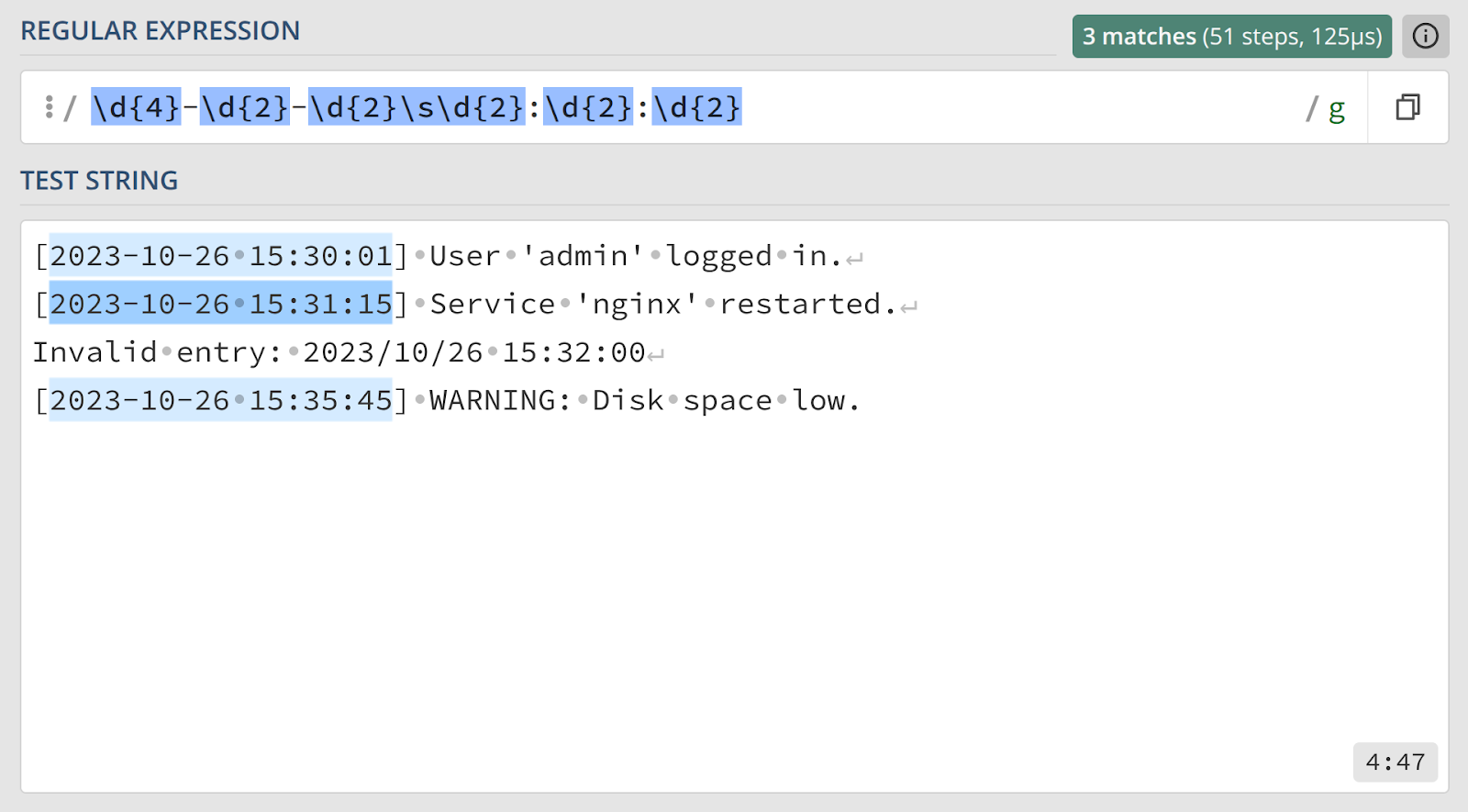
Объяснение
Эта задача решается с помощью комбинации уже знакомых нам квантификаторов и встроенных классов символов.
\d— класс для любой цифры, он намного проще читается, чем[0-9].{4}и{2}— квантификаторы длины в четыре и два символа.\s— класс для любого пробельного символа (пробел, табуляция и т. д.). Он разделяет дату и время.-и:— литералы, которые должны присутствовать в строке.
Вариант \d\d\d\d-\d\d-\d\d\s\d\d:\d\d:\d\d может кому‑то показаться легче для восприятия. Он тоже вполне корректен и имеет право на жизнь.
9. Исключающие наборы
Правильный ответ

Объяснение
Иногда проще описать символы, которые не нужно находить. Для этого используются негативные (или инвертированные) символьные классы.
- Циркумфлекс
^внутри квадратных скобок[]— если он стоит на первом месте! — работает как отрицание идущих за ним символов. A-z— диапазон для всех букв латинского алфавита в верхнем и нижнем регистре. Мы могли бы написать иa-zA-Z, иA-Za-z. Однако поскольку диапазон не прерывается, а у заглавных букв числовой код меньше чем у строчных, то обозначение диапазона можно сократить доA-z.0-9— диапазон для всех цифр.\s— встроенный класс для пробельных символов.
Внимательный читатель воскликнет: «Но ведь можно написать [^\w\d\s] — и это будет проще!» Да, но только далеко не каждый движок разрешит вставлять в квадратные скобки обозначения, предваренные обратной чертой. Решение же с прямым указанием диапазонов — универсальное.
10. Извлечение доменов
Правильный ответ
![Тестирование регулярного выражения: (?:@)([A-z0-9.-]+) — все доменные имена найдены и захвачены в группу.](https://lh7-qw.googleusercontent.com/docsz/AD_4nXfe95Uk4JOUZ8XjLJS-PRcvke66MrTuhvPo6qZr8FNuQPKpE0dUYj9umRKlbAGfgqDKG-fiAlUBgbx4SbajrJDPns6ZImasxjJZG43SCk3-5Lfhk4jsK1LqeYgJo9fXzcv7FxaYkQ?key=KMcmNJeP2j3uewzhKHuHtA)
Объяснение
Здесь мы используем захватывающую группу для извлечения данных и незахватывающую для уточнения поиска.
@— опорная точка для поиска, но которая нам не нужна в итоговом результате, поэтому мы не включаем ее в группу.()— круглые скобки создают захватывающую группу. Все, что будет найдено внутри, движок сохранит в отдельную «ячейку памяти».[A-z0-9.-]+— символьный класс, описывающий возможные в доменных именах символы — буквы, цифры, точки и дефис. Завершает выражение квантификатор+— один или более раз.
Когда движок применяет этот шаблон, полное совпадение будет, например, @example.com. Однако в первой захваченной группе, которую обычно можно получить программно как match, будет содержаться только часть, соответствующая выражению внутри скобок — example.com. Это фундаментальный прием для парсинга данных.
11. Проверка парных конструкций
Правильный ответ
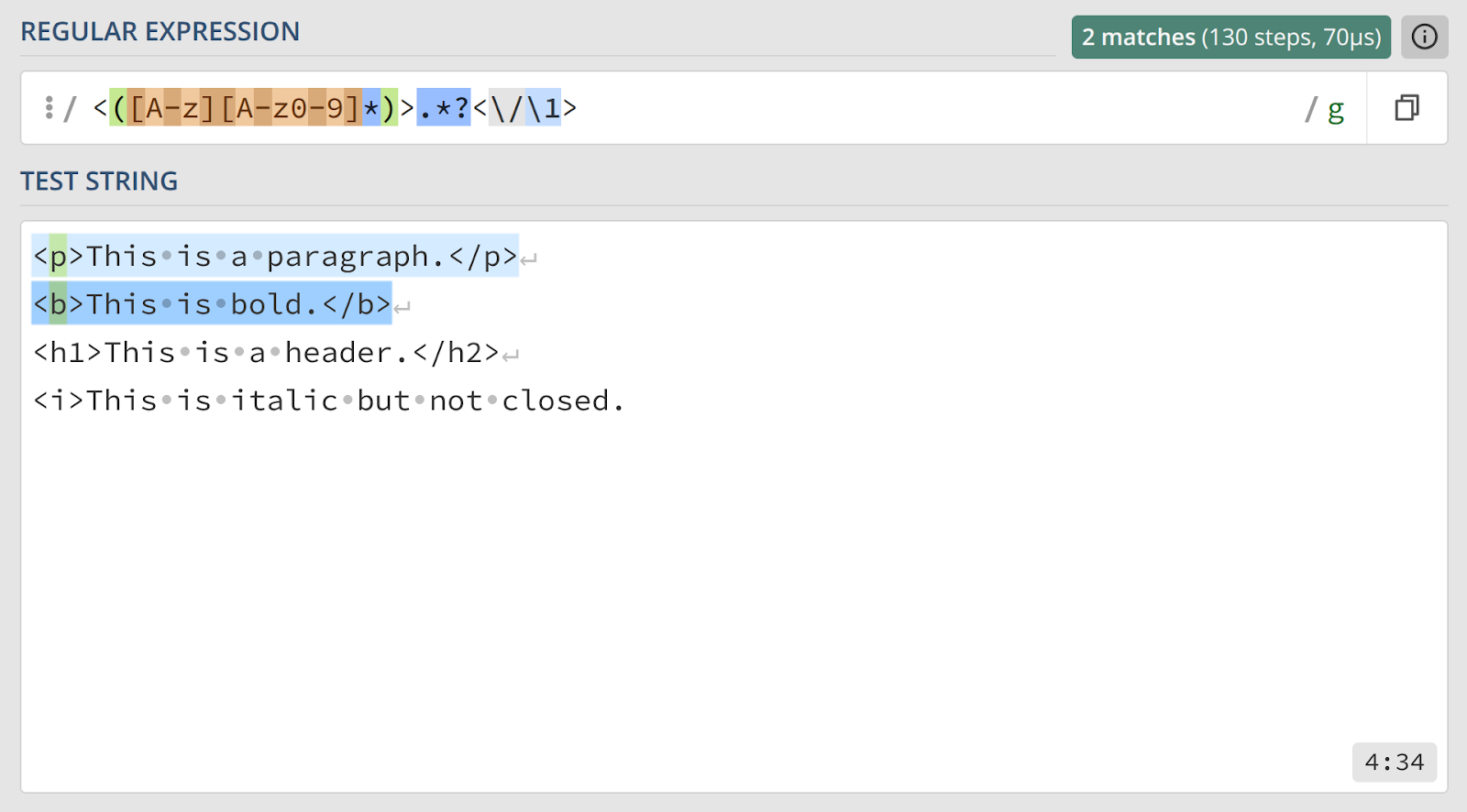
Объяснение
Эта задача использует идею обратных ссылок для указания уже найденных подстрок.
<и>— литералы, угловые скобки.([A-z][A-z0-9]*)— первая захватывающая группа, описывающая имя тега. Она требует, чтобы тег начинался с буквы([A-z]), за которой могут следовать буквы или цифры([A-z0-9]*). Это более строгая проверка, чем просто\w+..*?— ленивый квантификатор, который находит содержимое тега.<\/— литералы, начало закрывающего тега. Обратите внимание, мы вынуждены использовать экранирующий обратный слэш.\1— обратная ссылка. Она требует, чтобы имя в закрывающем теге в точности совпадало с именем, захваченным в первой группе.
12. Извлечение кодов
Правильный ответ
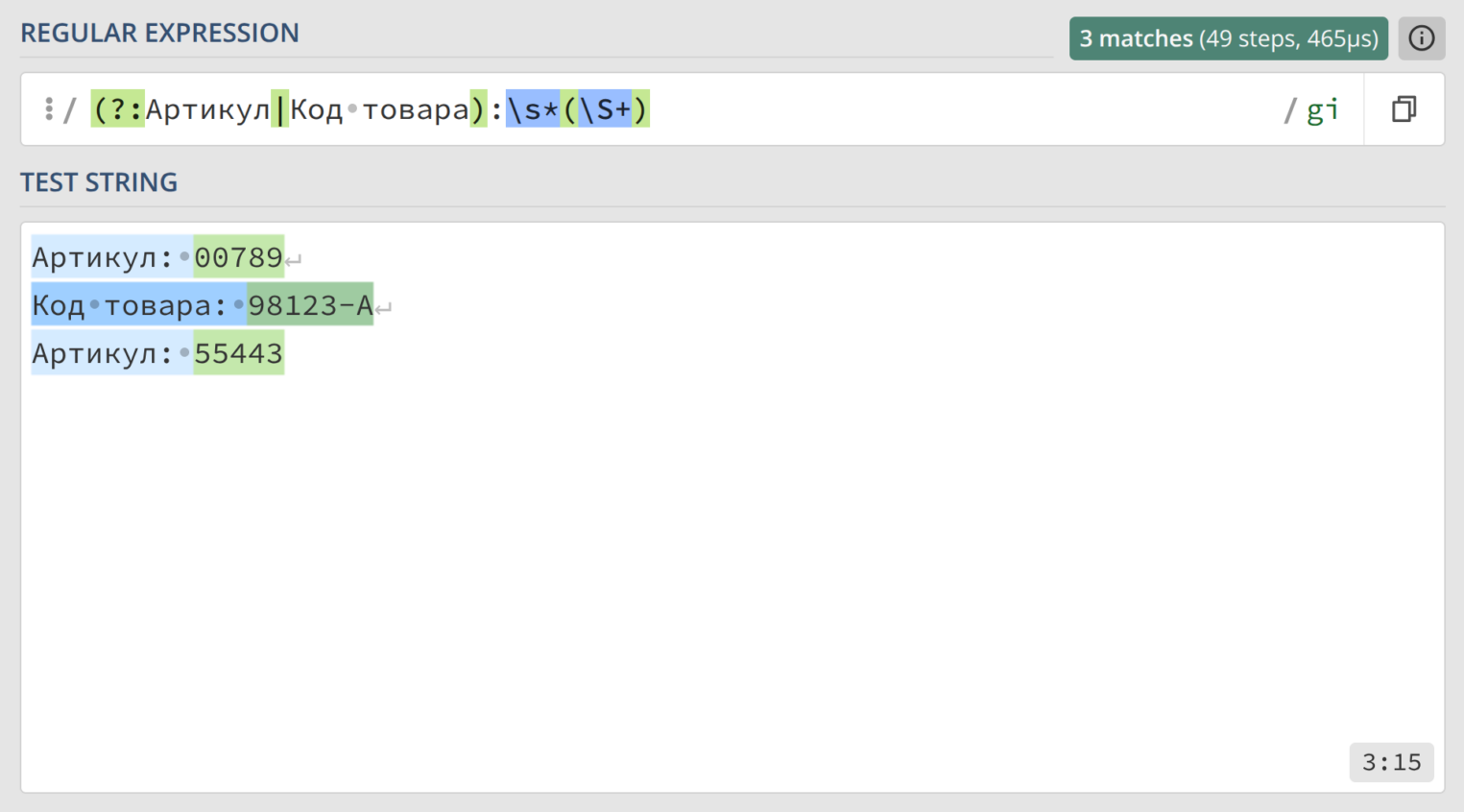
Объяснение
Когда скобки нужны только для группировки, а не для захвата, используются незахватывающие группы.
(?:Артикул|Код товара)— это незахватывающая группа. Синтаксис(?:)выполняет ту же функцию группировки, что и обычные скобки, но не сохраняет найденный фрагмент, а на группу нельзя сослаться — она не получает номер. Мы использовали ее для объединения вариантов префикса.:\s*— двоеточие и ноль или более пробелов.(\S+)— обычная захватывающая группа. Мы видим, что код товара может быть разным, но не содержит пробел. Воспользуемся такой особенностью данных.
Поскольку первая группа является незахватывающей, то последняя группа получает номер 1. На нее можно сослаться во внешнем инструменте для дальнейшей обработки полученного результата.
13. Читаемость с именованными группами
Правильный ответ

Объяснение
Для сложных шаблонов числовые индексы групп \1, \2 становятся неудобными. Решение — именованные группы.
- Конструкция
(?<name>)создает захватывающую группу и присваивает ей имя. Например,(?<date>.*?)создает группу с именемdate. date,event,user— понятные имена, которые описывают суть извлекаемых данных..*?— ленивый квантификатор, для захвата текста между разделителями.
Преимущество именованных групп огромно. Во‑первых, выражение становится самодокументируемым. Во‑вторых, в коде можно обращаться к результатам по имени (например, match.groups['user']), а не по номеру. Это делает программы надежнее и устойчивее к изменениям — можно добавлять или менять порядок групп в шаблоне, не ломая логику обработки результатов.
14. Позитивный просмотр вперед
Правильный ответ

Объяснение
Для проверки условия, которое должно выполняться после текущей позиции, используется позитивный просмотр вперед.
\b\w+\b— находит любое целое слово.(?=)— синтаксис позитивного просмотра вперед. Эта конструкция «заглядывает» вправо от текущей позиции и проверяет, соответствует ли шаблону текст внутри нее. Самое главное — она не «потребляет» символы и не включает их в итоговое совпадение.(?=:)— в нашем случае, просмотр вперед проверяет, что сразу после границы слова\bидет двоеточие.
15. Позитивный просмотр назад
Правильный ответ
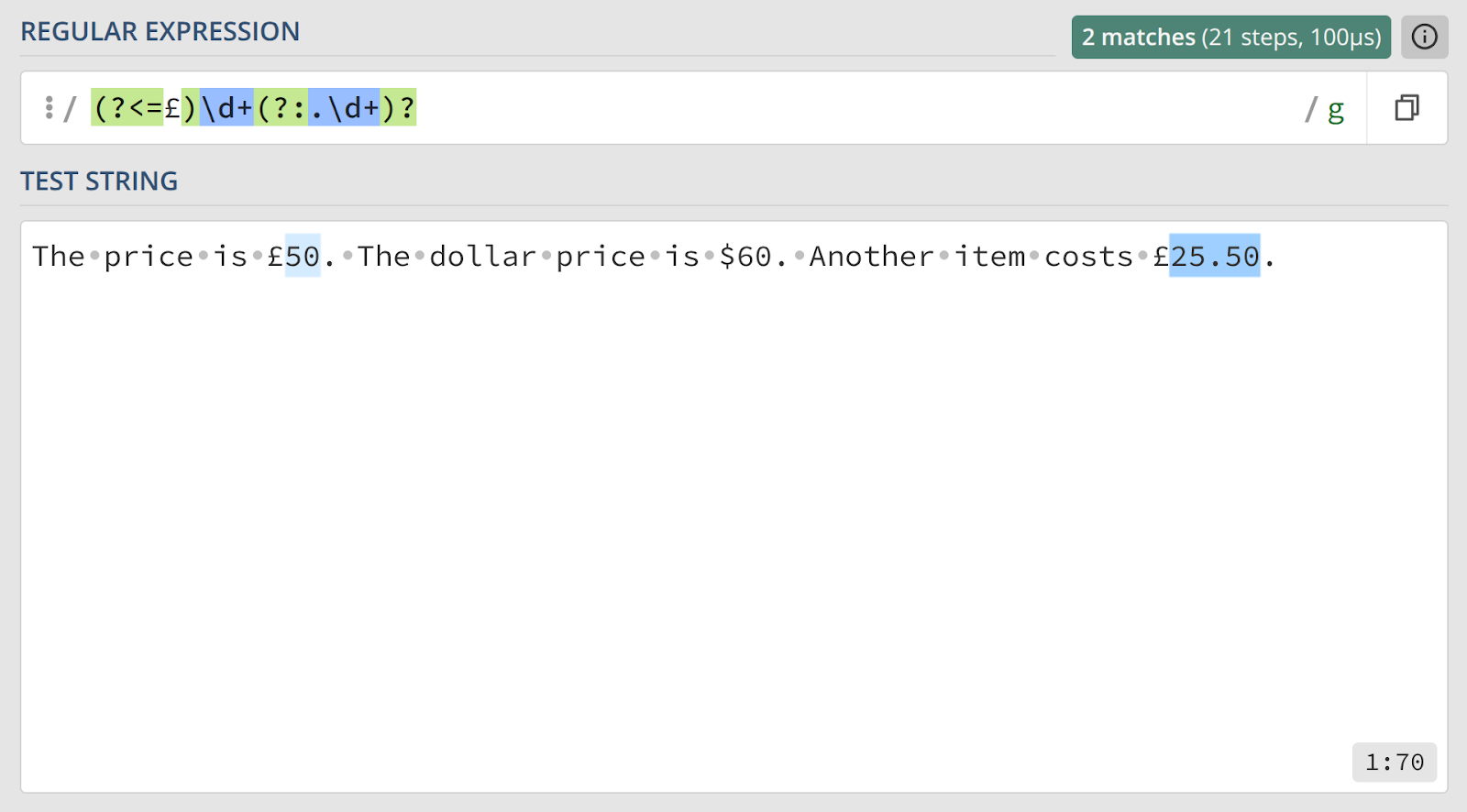
Объяснение
Для проверки условия, которое должно выполняться до текущей позиции, используется позитивный просмотр назад.
(?<=)— синтаксис позитивного просмотра назад. Он «оглядывается» влево от текущей позиции. Поиск основного шаблона продолжится, только если текст слева соответствует выражению£.\d+(?:.\d+)?— основной шаблон, который ищет последовательность из целой или десятичной дроби, разделитель которой в данном случае — запятая. Обратите внимание: мы избегаем формирования лишней группы.
16. Негативный просмотр вперед
Правильный ответ
![Тестирование регулярного выражения: [Оо]тчет(?!\s+готов) — найдены все вхождения слова «отчет». Исключение — место, где после него идет слово «готов».](https://lh7-qw.googleusercontent.com/docsz/AD_4nXfcWY2xog2cEZcKSgYlW-tOIluFdmMIrWkVKYfoXe4ta3nDL_yyyJnTgYY_K_Se50PYrWdDmO7yleDYBlOWBtHB003-OQ2Ga7arinBJOh6B3hsqJxF78EHIEGcRlqLpAzB97XYyLg?key=KMcmNJeP2j3uewzhKHuHtA)
Объяснение
Чтобы исключить совпадения на основе последующего контекста, применяется негативный просмотр вперед.
[Оо]тчет— искомое слово. Обратите внимание, раз мы имеем дело с нелатинскими буквами, то флаг i для игнорирования регистра может не работать — явно прописываем возможность появления заглавной буквы.(?!\s+готов)— синтаксис негативного просмотра вперед. Он как бы говорит: «Продолжай, только если за этой точкой нет текста, который соответствует шаблону внутри скобок».
17. Негативный просмотр назад
Правильный ответ
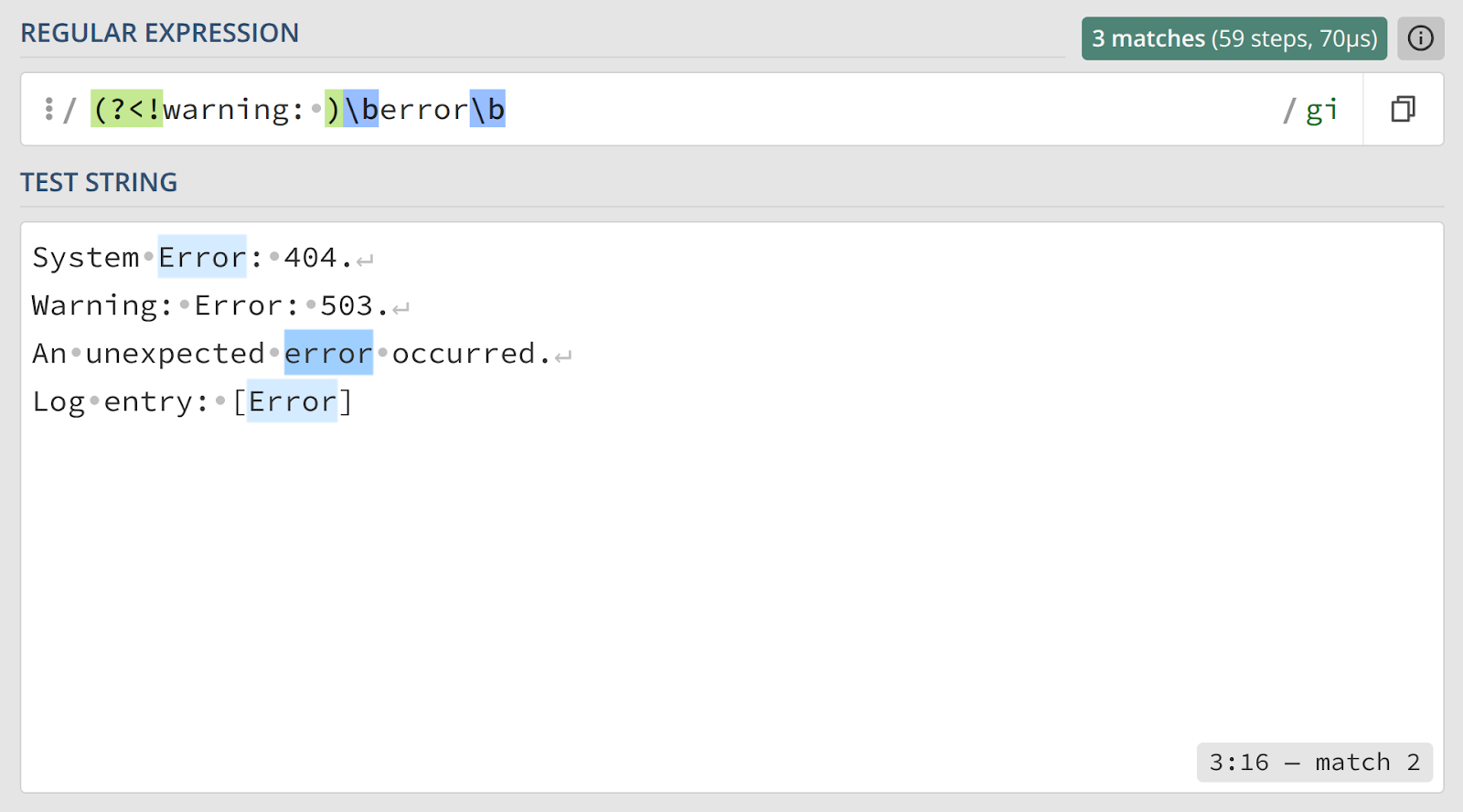
Объяснение
Для фильтрации результатов на основе предыдущего контекста используется негативный просмотр назад.
(?<!Warning: )— синтаксис негативного просмотра назад. Он говорит движку: «Продолжай, только если этому месту не предшествует текст из шаблона». Перед тем как искать слово «error», мы «оглядываемся» и проверяем, нет ли строки «warning: » (с пробелом).\berror\b— искомое целое слово «error». Использование\bгарантирует, что мы не найдем его как часть другого слова.
18. Границы слов в кириллице
Правильный ответ
![Тестируем регулярное выражение: (?≺=^|[^А-яЁё])задача(?=[^А-яЁё]|$) — и строчные, и заглавные буквы найдены.](https://lh7-qw.googleusercontent.com/docsz/AD_4nXdX2N0PEHnMUDP50Bw--b659R_seordy4GuXla33Zcr8j-IQyNEEqdnLUr0CbpOyvPRvFJLVT3fGUMJQbTD-YmJknlp6Blk-SV1aROpyIwkHcFev7jxmyEaw00yrzDRAzJ33B_a?key=KMcmNJeP2j3uewzhKHuHtA)
Объяснение
Не во всех движках маркер \b корректно определяет границу слова для всего диапазона Unicode — например, для кириллицы. Чтобы универсально решать подобные задачи, необходимо определять границы слова вручную. Слово считается отдельным, если оно окружено чем-то, что не является русской буквой.
[А-яЁё]— символьный класс, описывающий используемый алфавит.- задача — искомое слово.
(?<![А-яЁё] и (?![А-яЁё])— левая и правая границы. Все, что не буква из используемого алфавита (точнее говоря, символьного класса), — не включается в результат.
На этом все. Удачи в покорении новых высот!