Регулярные выражения. Часть 2. Символьные классы, якоря, квантификаторы, флаги
Новички продолжают делать уверенные шаги в освоении регулярных выражений. Говорим о символьных классах, квантификаторах и опциях.

Мы уже отмечали в первой части, что можно выделить несколько уровней владения регулярными выражениями. Некоторые, сталкиваясь со сложностью синтаксиса, предпочитают избегать их в пользу более «понятных» решений — алгоритмических, например. Другие уже освоили базовые принципы и теперь стремятся к глубокому и системному пониманию.
Наш материал ориентирован в первую очередь на вторую группу — тех, кто уже сделал первые шаги и готов пойти дальше к уверенному и осознанному применению.
Особенности синтаксиса и исторический контекст
На первый взгляд может показаться, что регулярные выражения — это простой и прямолинейный инструмент для поиска текста. Однако такое представление является упрощением. Современные регулярные выражения прошли долгий и сложный путь эволюции — от математической абстракции для описания формальных языков до конкретных программных реализаций. В течение этого процесса синтаксис обогатился множеством функциональных дополнений и специфических деталей, которые не всегда кажутся логичными или интуитивно понятными.
К таким синтаксическим особенностям следует относиться как к своего рода историческому наследию, которое необходимо принимать как данность. Некоторые из них требуют целенаправленного запоминания. Такая неконсистентность — итог постепенного наращивания функциональности разными командами разработчиков.
Диалекты регулярных выражений
На сегодняшний день не существует единого, общепринятого и формализованного стандарта для синтаксиса и поведения регулярных выражений. Различные языки программирования и утилиты вносили собственные модификации и расширения в базовый синтаксис, стремясь адаптировать его под свои специфические нужды. В результате сегодня мы имеем дело с примерно десятком основных диалектов (в англоязычной терминологии flavors — привкусы), а также множеством еще более специфичных, узкоспециализированных версий.
Различия между диалектами весьма значительны и проявляются на разных уровнях:
- некоторые продвинутые функции полностью отсутствуют в одной реализации, но являются ключевыми в другой;
- синтаксис для выполнения одной и той же операции может кардинально отличаться;
- конструкции с абсолютно идентичным синтаксисом демонстрируют разное поведение в зависимости от используемого движка регулярных выражений.
Вопрос о причинах подобной фрагментации не раз поднимался на авторитетных ресурсах, таких как StackOverflow. Прошли годы, но ситуация не стала лучше.
Несмотря на досадное многообразие, мы сосредоточимся на изучении базовых, «ванильных» конструкциях — они работают одинаково в большинстве популярных диалектов. Тем не менее настоятельно рекомендуется всегда сверяться с официальной документацией вашего конкретного языка программирования или инструмента.
Онлайн-платформа Regex101 предоставляет возможность выбора и тестирования выражений в нескольких ключевых диалектах. Мы использовали ее в первой части и продолжим работать с ней в этой.
Метасимвол точки: универсальность и риски
Один из наиболее часто используемых, но в то же время потенциально опасных метасимволов — точка (.). В контексте регулярных выражений точка соответствует любому единичному символу, за исключением перевода строки строки (\n).
Следовательно, простая на вид конструкция .* означает что угодно — этому выражению будет соответствовать практически любая строка текста. Действительно, если присмотреться, то это буквально какой угодно символ (кроме переноса строки), повторенный произвольное количество раз (включая ноль).
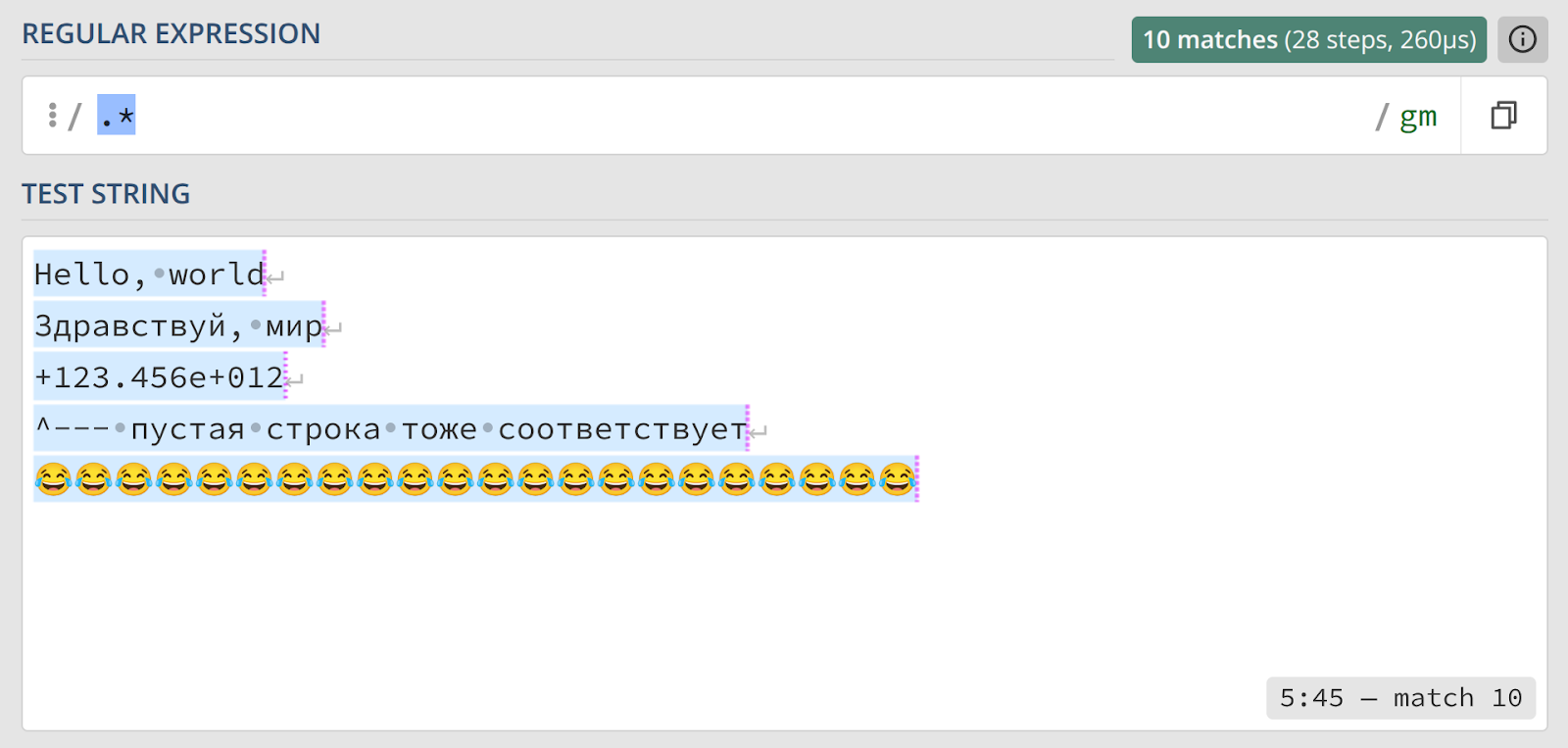
Рассмотрим более практическую задачу: найти все слова, которые начинаются на «к» и заканчиваются на «а». Самый очевидный, но неверный подход — использовать выражение к.*а.
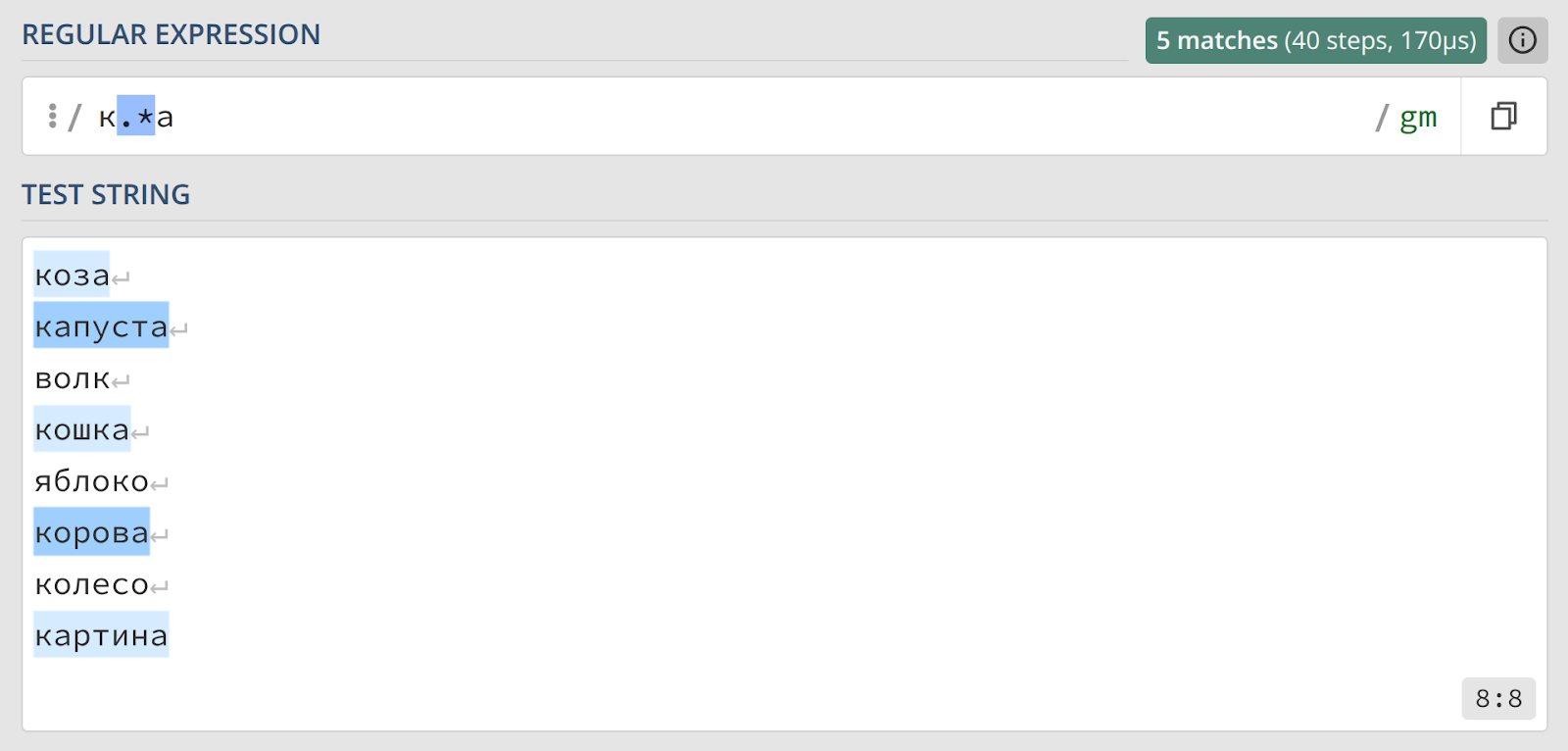
На этом специально подобранном наборе данных кажется, что выражение работает безупречно. Однако стоит поместить его в более реалистичный контекст, как проблема становится очевидной.
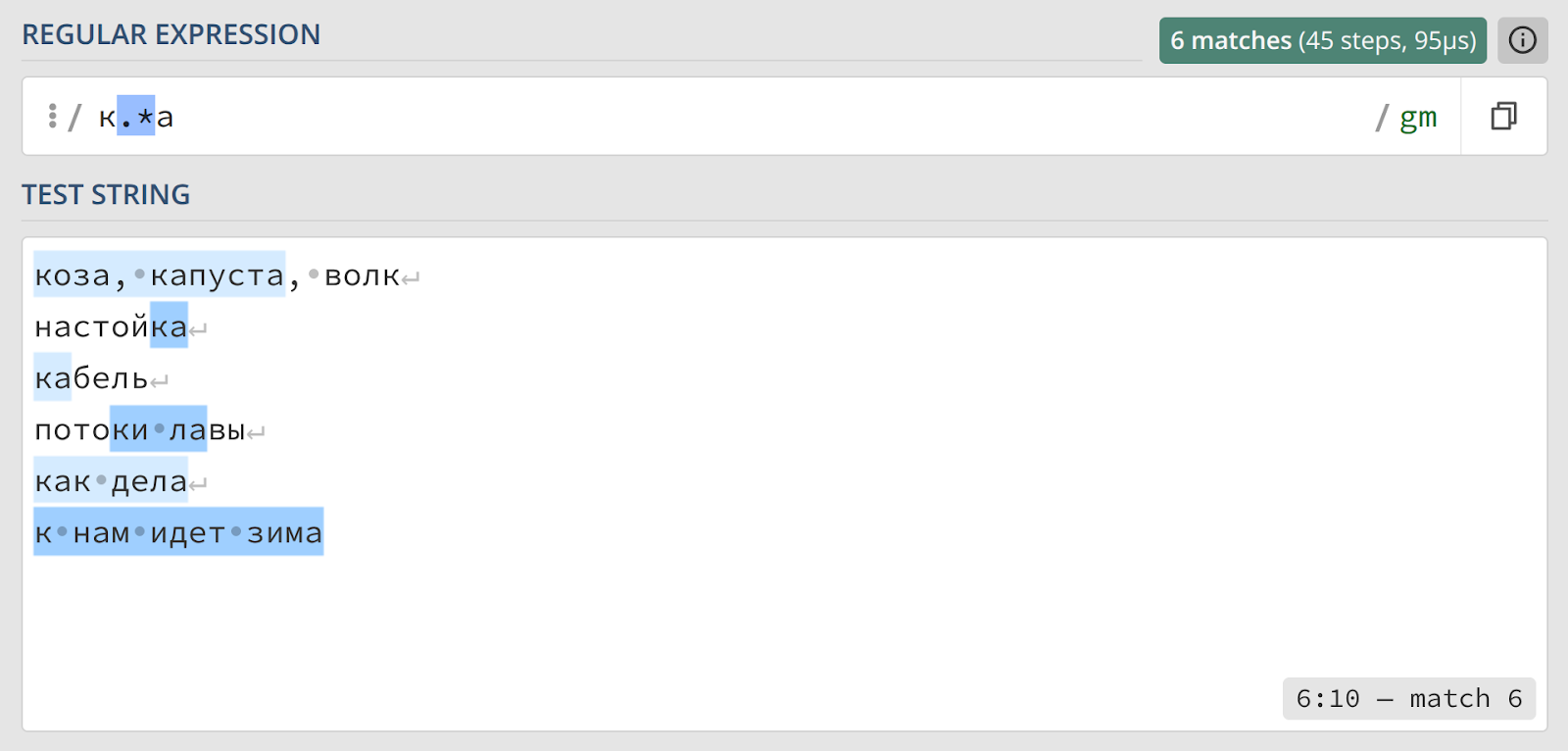
Результат теперь совершенно не тот, что мы хотели получить. Выражение захватило фрагмент «коза, капуста», целое предложение «как дела» и часть фразы «к нам идет зима». Причин происходящего три:
- точка действительно означает любой символ — включая пробелы и знаки препинания, что позволяет ей «перескакивать» через границы слов;
- мы никак не обозначили, что искомая последовательность должна быть отдельным словом;
- квантификатор
*по умолчанию является «жадным».
Жадные и ленивые квантификаторы
В теории алгоритмов и, в частности, регулярных выражениях, реализованы два фундаментальных типа поведения для квантификаторов — жадное (greedy) и ленивое (lazy).
По умолчанию все стандартные квантификаторы *, +, ? и {n,m} являются «жадными». Это означает, что движок регулярных выражений будет стремиться захватить максимально длинную подстроку, удовлетворяющую шаблону.
Рассмотрим классическую ошибку, допускаемую при парсинге строк. Допустим, нам нужно извлечь из фрагмента кода все значения, заключенные в двойные кавычки. Интуитивная попытка будет выглядеть так: ".*".
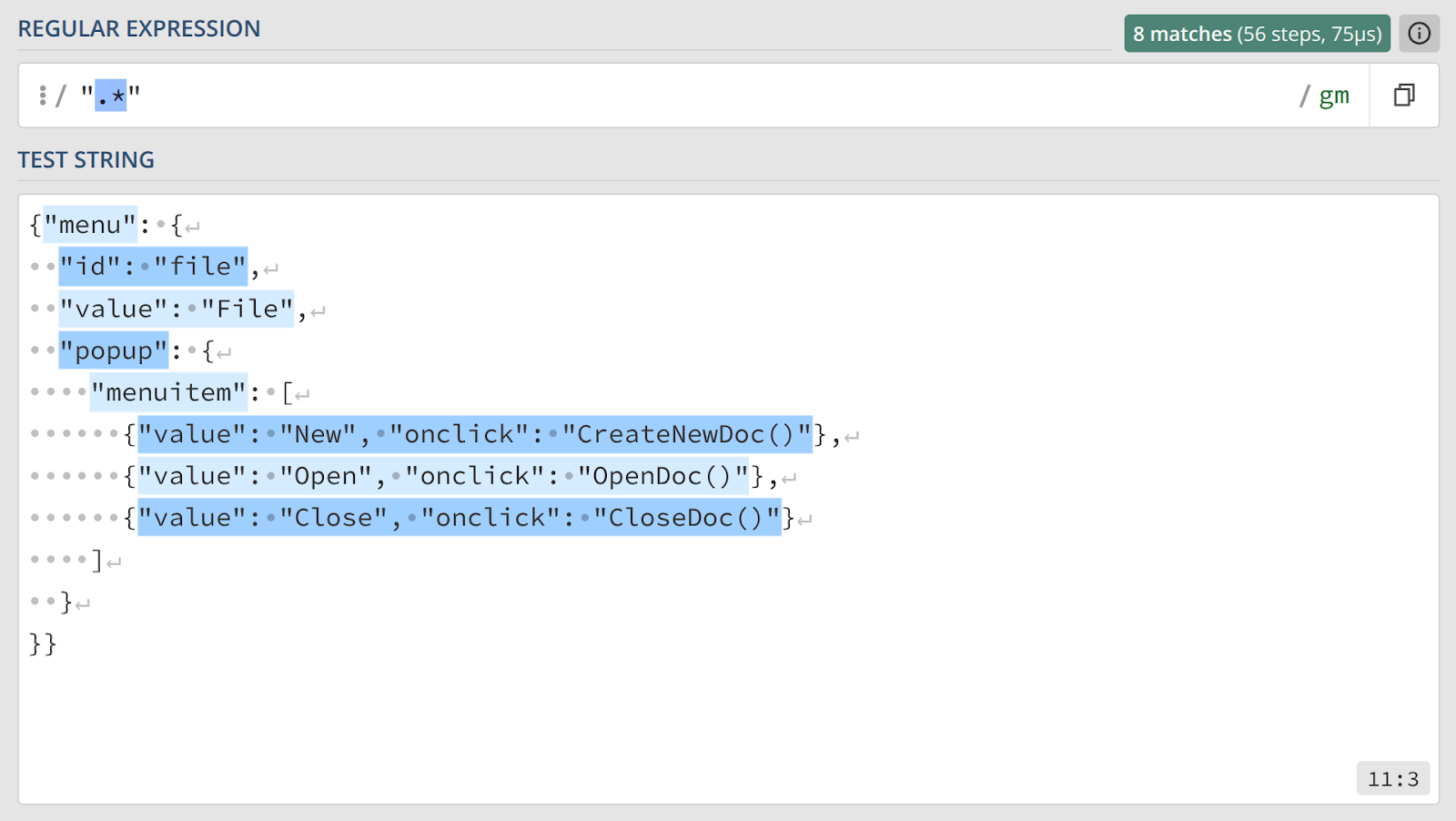
Ситуация аналогична предыдущему примеру. Жадный квантификатор .* начинает поиск после первой кавычки и не останавливается на следующей, а продолжает захватывать все символы, включая другие кавычки. Единственное, что его останавливает — разделитель строк.
Для исправления такого поведения необходимо перевести квантификатор в «ленивый» режим. Для этого добавим знак вопроса (?) сразу после квантификатора:
*?— ленивая звезда (ноль или более повторений, минимально возможное количество);+?— ленивый плюс (одно или более повторений, минимально возможное);??— ленивый знак вопроса (ноль или одно повторение, минимально возможное).
Ленивые квантификаторы действуют по противоположному принципу: они захватывают минимально возможное количество символов, чтобы выражение нашлось, и останавливаются при первом же совпадении.
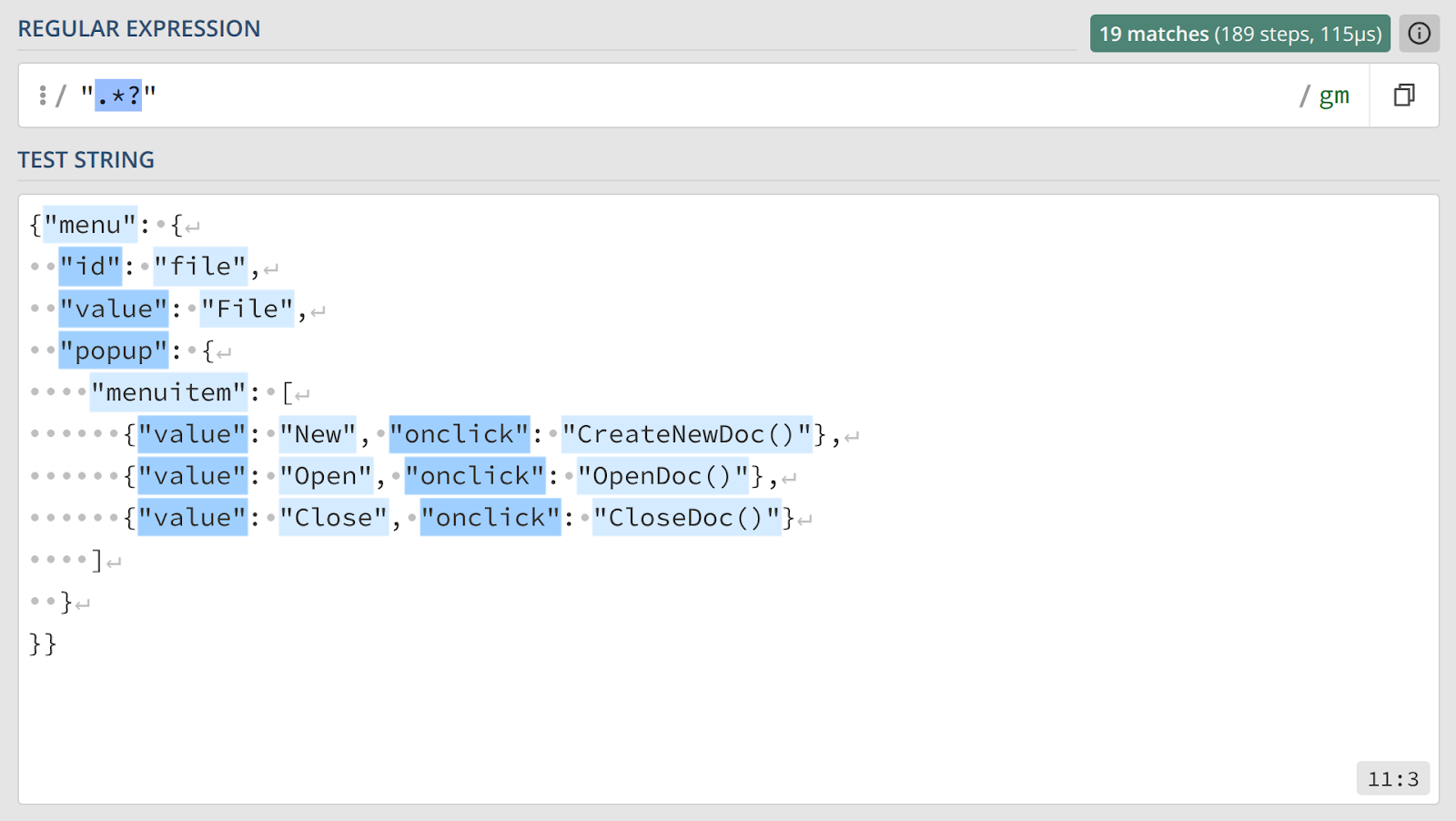
Теперь выражение работает так, как и было задумано, находя каждую пару кавычек по отдельности. На графе выполнения жадного поиска “.*” приоритетным является путь, возвращающий движок к захвату следующего символа, даже если это кавычка.

На графе ленивого поиска “.*?” — путь, который ведет к завершению цикла при обнаружении первого же совпадения с последующим символом (в данном случае, кавычкой).

Этот же принцип применим и к фигурным скобкам. Например, a{2,5}? будет искать от двух до пяти букв «а», но остановится на двух, если таковые попадутся.
Якоря: указатели начала и конца
Как мы видели, регулярные выражения по умолчанию находят совпадения в любой части строки. Такое поведение желательно для задач поиска, но становится серьезной проблемой, когда требуется выполнить точную валидацию данных.
Рассмотрим максимально упрощенный и нереалистичный пример валидации пароля (на самом деле, пароли так не проверяются и вообще не должны храниться в открытом виде). Допустим, валидным значением является исключительно строка password. Если мы напишем регулярное выражение password, то оно действительно найдет совпадение с password. Проблема в том, что для успешной валидации достаточно найти хотя бы одну подстроку, соответствующую шаблону. Таким образом, строки password1234, 123password123 и даже passwordpassword также будут считаться валидными, что абсолютно некорректно.
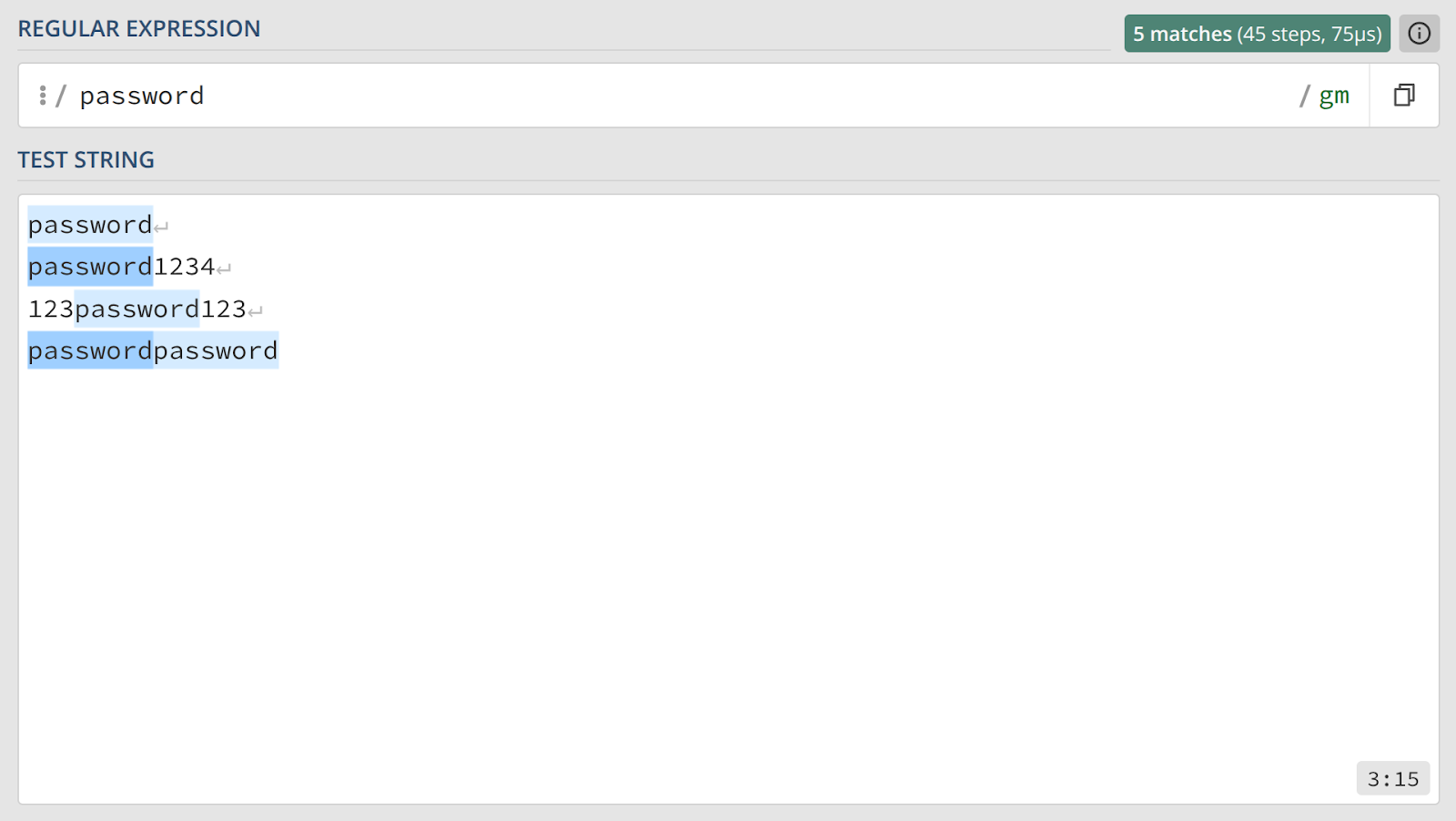
Чтобы гарантировать, что вся строка целиком соответствует нашему шаблону, необходимо явно указать: до и после искомой последовательности не должно быть никаких других символов. Для этой цели существуют два специальных метасимвола, называемых «якорями»:
^— якорь, символизирующий начало строки;$— якорь, символизирующий конец строки.
Применив их, мы получим выражение ^password$, которое будет соответствовать исключительно строке password, без каких-либо префиксов или суффиксов.
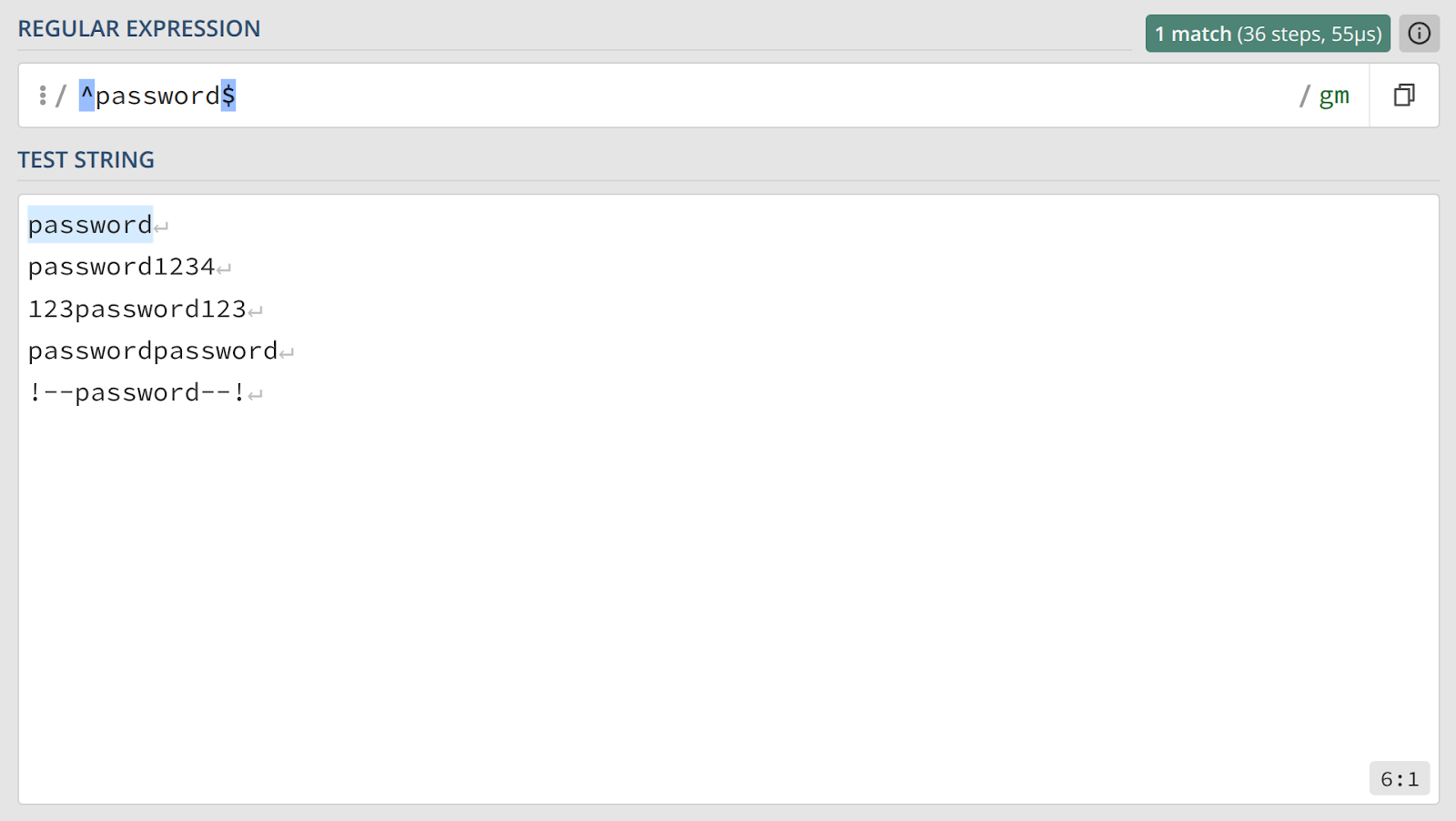
Теперь только первая строка в тестовом наборе дает совпадение.
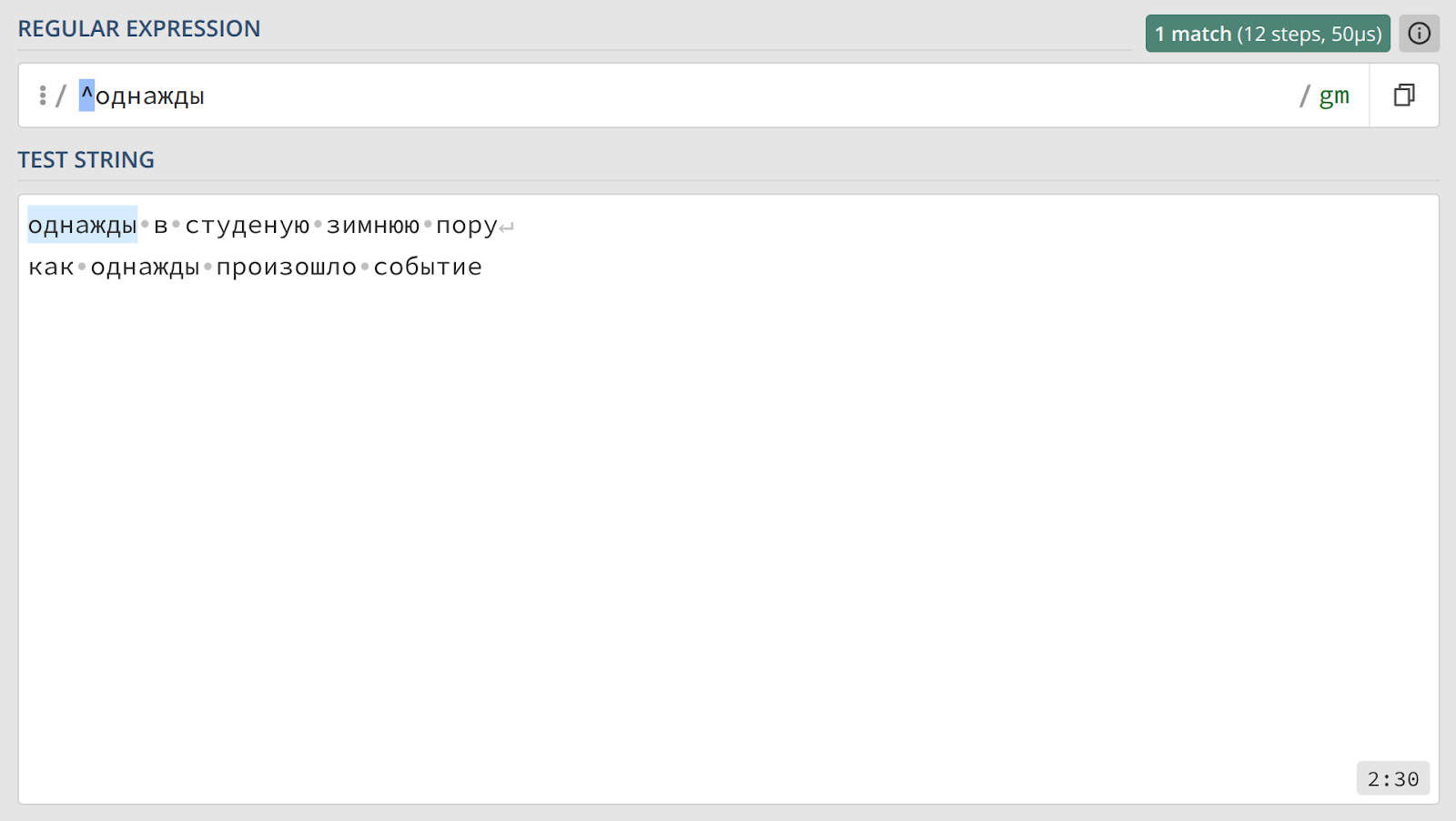
Якоря ^ и $ не обязательно использовать вместе. Выражение ^однажды найдет соответствие только в том случае, если слово «однажды» стоит в самом начале строки.
Выражение и поделом$ сработает, только если эта фраза находится в самом конце строки.
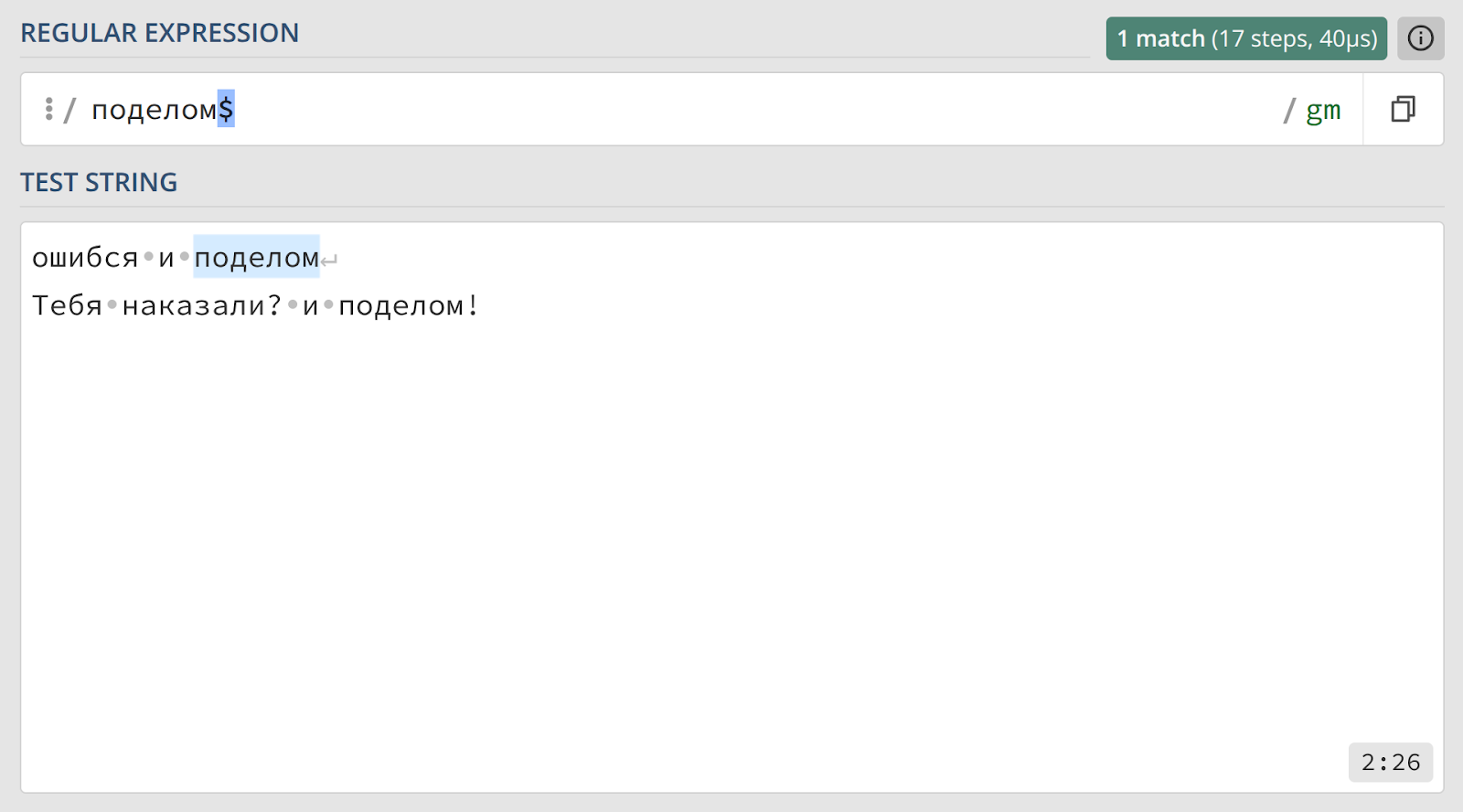
В обоих случаях совпадением будет считаться само слово или фраза, а не вся строка. Чтобы захватить всю строку, которая начинается или заканчивается определенным образом, можно использовать комбинацию с метасимволом точки — например, ^однажды.* или .*и поделом$.
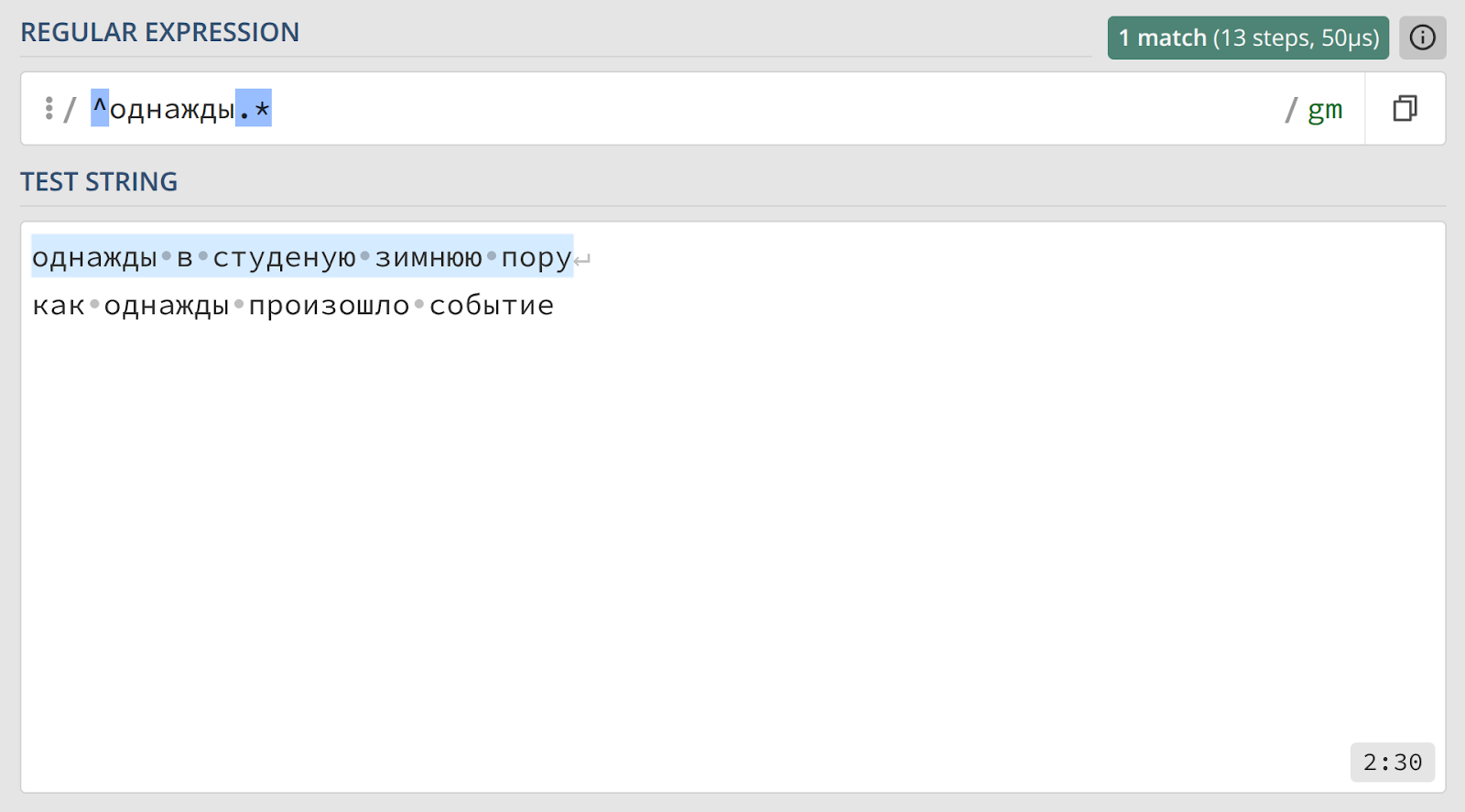
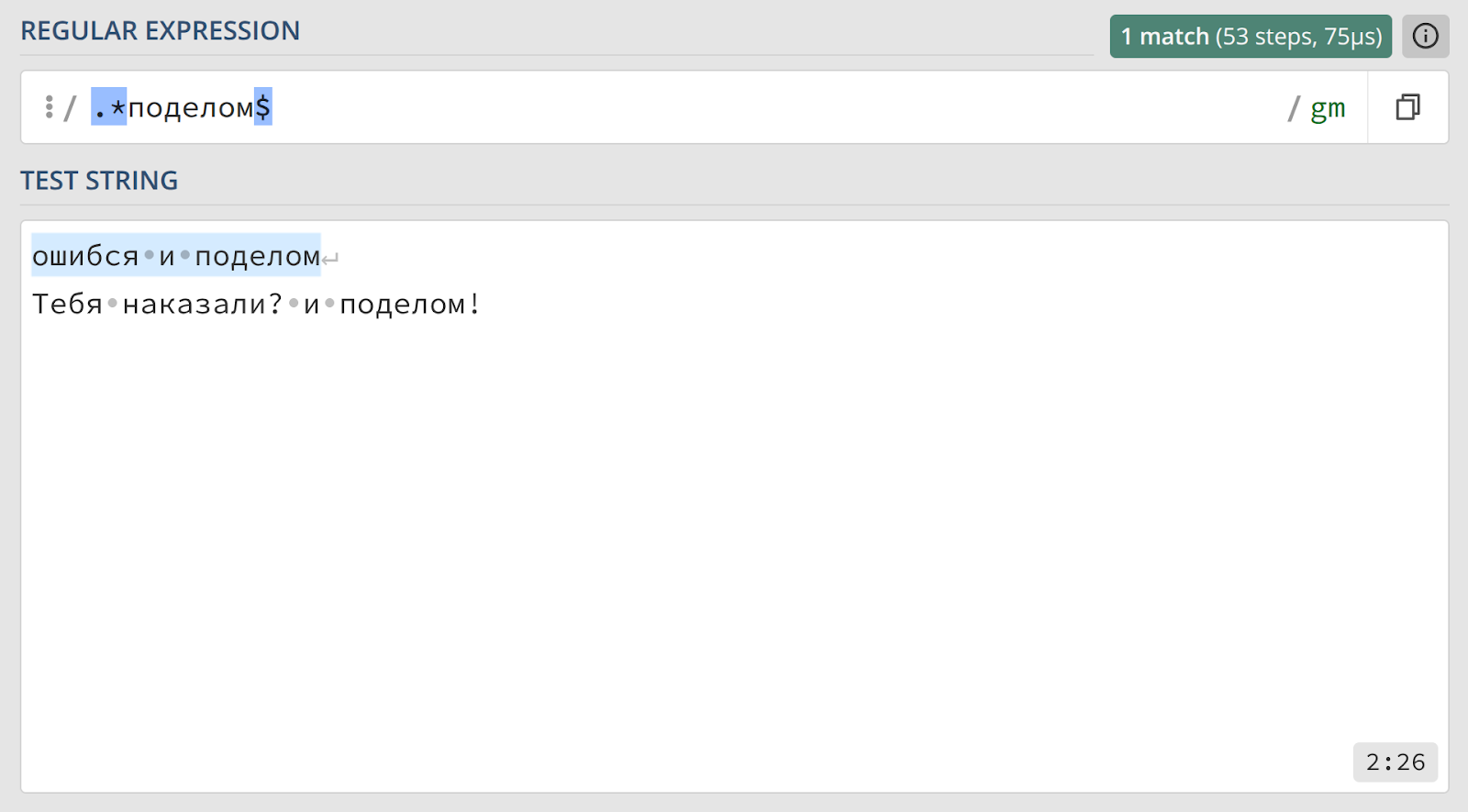
Кроме якорей начала и конца строки, существует метасимвол для обозначения границы слова — \b (от английского boundary). Однако его логика определения «слова» довольно специфична, и мы вернемся к этому позже.
Квадратные скобки: определение наборов символов
Как упоминалось ранее, квадратные скобки [] позволяют определить набор из нескольких символов, любой из которых может встретиться в данной позиции строки. Например, [aeiou] соответствует любой одной гласной букве английского алфавита в нижнем регистре.
![Тестирование регулярного выражения: [aeiou] — подсвечиваются английские гласные в случайном тексте.](https://lh7-qw.googleusercontent.com/docsz/AD_4nXcHxbY9M6lklLfouN-_htJ-wW8rZVwODGVWRyXtHEdL4WLLaSe8d3I1R6xzjUDbfknp9ixdcCNc1gWdscNumrzcYNFr26jFynY3xhGizyyux9e6PTHcQzB7CTo2lJTc3eBO9xGraw?key=whd9QVUwK5gf4gbsMfC3rg)
Выражение [0123456789] соответствует любой одной десятичной цифре.
![Тестирование регулярного выражения: [0123456789] — подсвечиваются все десятичные цифры.](https://lh7-qw.googleusercontent.com/docsz/AD_4nXewxZZPRs0EIKsOfoC1mcQs9-x-CS2gfnFFtmXFZ9lMQQRxHtj5ZmyZI81txLQM2P4RsP6uOT2hIusop85Fbeo4EDTmsvN7MHruGpi6UJokM_gaPQkWH4b84eB9IBDPXtZGT5VhMQ?key=whd9QVUwK5gf4gbsMfC3rg)
Перечислять все символы вручную, особенно для целых алфавитов неудобно — [abcdefghijklmnopqrstuvwxyz]. Упростить задачу можно, если использовать дефис для указания диапазонов, например:
[a-z]— для всех строчных букв латиницы;[0-9]— для всех цифр.
Логично было бы предположить, что для русских букв сработает диапазон [а-я], однако это не совсем так. Диапазоны работают на основе кодов символов в кодировочных таблицах (таких как Unicode). В большинстве кодировок буква «ё» расположена отдельно от основного алфавитного блока, поэтому она не попадает в диапазон [а-я]. Для корректного включения всех букв русского алфавита следует комбинировать диапазон и перечисление: [а-яё].
Можно указывать несколько интервалов и символов в одних скобках. Например, для поиска шестнадцатеричных цифр в нижнем регистре можно использовать [0-9a-fA-F] (обратите внимание, что по этому выражению захватываются не только шестнадцатеричные цифры — например, буква «c» в слове colors).
![Тестирование регулярного выражения: [0-9a-fA-F] — подсвечиваются шестнадцатиричные числа.](https://lh7-qw.googleusercontent.com/docsz/AD_4nXcyQtlrxYVPw0SBFNJkGqE9q74hNDY3qVNoTSR9Jap1a567QZahQMn_TdsBX5K59SP08LYvq2EDAQ62nyIcbLPbag2BZ3BMilW-9Cz1jF1tiE0GINSZ_fOQavuCWD-fE0med7Vp?key=whd9QVUwK5gf4gbsMfC3rg)
Для поиска любой буквы русского или английского алфавита обоих регистров (если не используется флаг нечувствительности к регистру i) выражение будет таким: [a-zа-яёA-ZА-ЯЁ].
Инверсия в наборах
Иногда проще определить набор символов, которые именно не должны встречаться в данной позиции. Для этой цели используется символ ^, который, будучи помещенным сразу после открывающей квадратной скобки, инвертирует набор. Да, это тот же символ, что и якорь начала строки, но внутри [] он приобретает совершенно иное значение — это одна из тех синтаксических особенностей, которые нужно просто запомнить. Несколько примеров:
[^aeiou]— любой символ, кроме перечисленных английских гласных;[^0-9]— любой символ, кроме цифр;[^"]— любой символ, кроме универсальной двойной кавычки.
Экранирование и поведение метасимволов внутри скобок
Внутреннее пространство квадратных скобок — это особый мир со своими правилами. Большинство метасимволов, таких как +, *, ?, .(точка), внутри скобок теряют свое специальное значение и воспринимаются как обычные литералы.
Необходимо всегда помнить про поведение метасимволов в квадратных скобках — это своего рода, подводные камни.
Дефис, если находится между двумя другими символами всегда определяет интервал. Например, выражение [*-+] задает диапазон от * (код 42) до + (код 43), который включает только эти два символа — но не сам дефис‑минус. Чтобы использовать именно сам дефис, его нужно либо экранировать с помощью обратного слэша \- (что работает далеко не во всех реализациях), либо поместить в начало или в конец набора — туда, где он не может сформировать диапазон: [-*+] или [*+-].
Позиция ^ также критична: в начале это инверсия, в любом другом месте — просто символ ^. Забавное, но логичное исключение: в выражении [^-] циркумфлекс ^ означает инверсию, а -(минус) — обычный дефис‑минус. В выражении же [+-^] снова образуется диапазон от + (код 43) до ^ (код 94), который включает в себя цифры, заглавные буквы и другие символы.
Некоторые символы, такие как сами квадратные скобки [ и ], а также обратная косая черта \, всегда требуют экранирования внутри набора: [\[\]\\].
Подытожим.
Если внутрь квадратных скобок нужно поместить символ, имеющий синтаксическое значение — например, ^, - или ] — их следует ставить на неожиданное место. Для ] такая позиция будет сразу после открывающей скобки, для - (минуса) подойдет и открывающая, и закрывающая скобка, а для ^ — любое расположение, только не за открывающей скобкой.
![Тестирование регулярного выражения: [][^-] — подсвечиваются квадратные скобки, циркумфлекс и дефис‑минус.](https://lh7-qw.googleusercontent.com/docsz/AD_4nXfi_LwNwufUOkZ9lpZA3jaiJUqqk6nh5U_ssXnT9jLpYYelsgfYBW7FIF5VRN5JcqKOMfDdL4mXCF1cckQr8LIzBhVtfPjc156IzHDhkK_QSQJyiT-1imOeIbxSDuFcNqRwVuhzYw?key=whd9QVUwK5gf4gbsMfC3rg)
Встроенные классы символов
Для наиболее популярных наборов существуют готовые сокращения (встроенные классы):
\d(digit) — любая цифра, эквивалентно[0-9];\w(word) — любая латинская буква, цифра или знак подчеркивания, эквивалентно[a-zA-Z0-9_];\s(space) — любой пробельный символ: пробел, табуляция, перенос строки.
Встроенный класс \w следует использовать с большой осторожностью при работе с естественными языками — он не включает буквы нелатинских алфавитов, но при этом считает цифры и подчеркивание частью «слова».
Граница слова \b, как уже упоминалось, обозначает позицию между символом из класса \w и символом не из \w (например, пробелом \s или знаком препинания). Начало и конец строки также считаются границами слова. Из-за специфического определения \w, поведение \b с кириллическим текстом или цифрами может быть контринтуитивным.
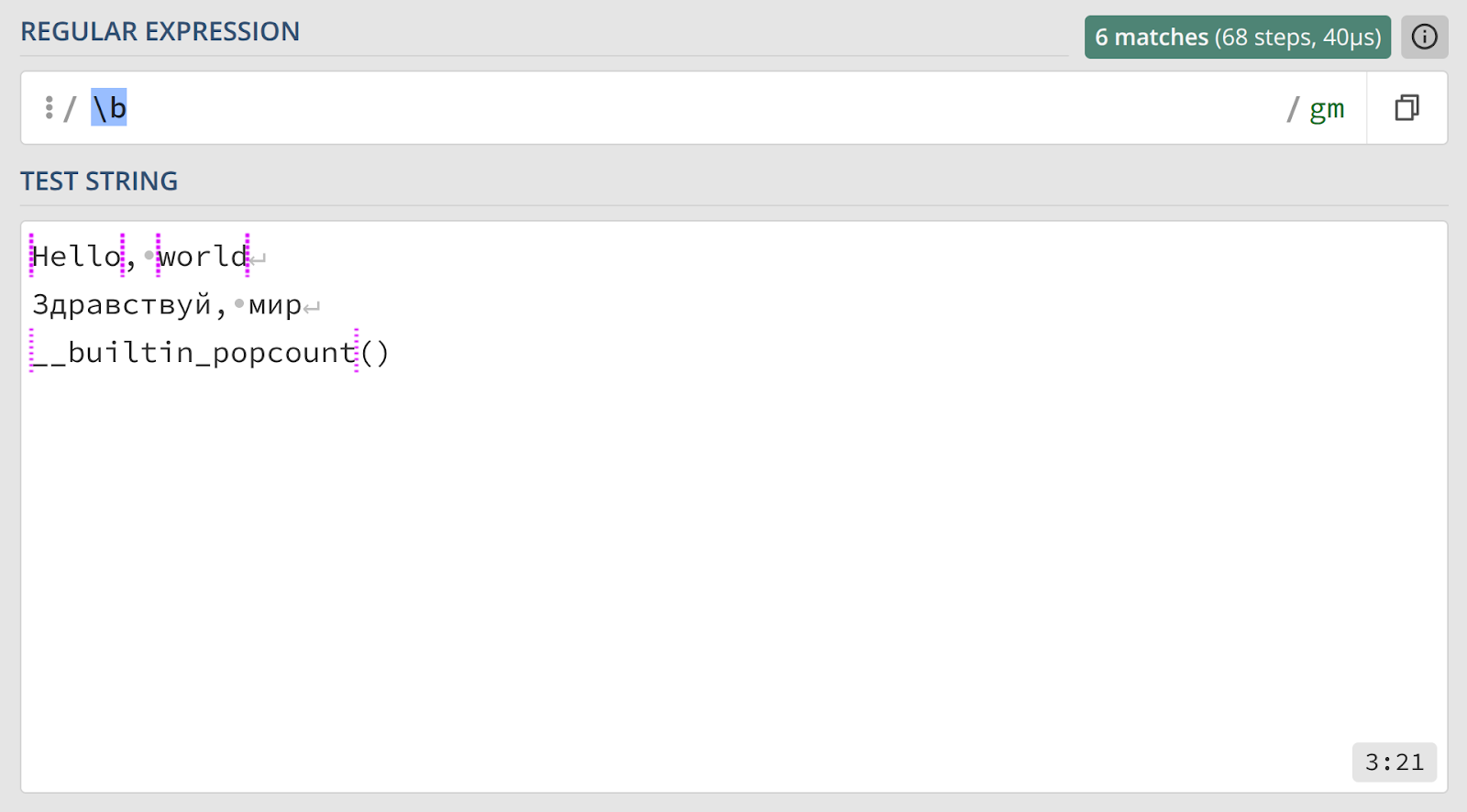
У каждого из этих классов есть инвертированный «двойник»:
\D— любой символ, не являющийся цифрой.\W— любой символ, не входящий в класс\w.\S— любой непробельный символ.\B— позиция, которая не является границей слова.
Также обратите внимание, что неразрывные пробелы — как одинарной, так и половинной ширины — встроенными классами символов \s и \S не обрабатываются.
Применение квантификаторов к наборам
Важно понимать, что вся конструкция с квадратными скобками (например, [a-z]) или встроенный класс (например, \d) рассматривается движком как один атомарный элемент, одна «инструкция». Соответственно, квантификаторы применяются ко всему набору целиком, например:
[A-Z]{4}— последовательность из четырех заглавных латинских букв;[A-Z0-9]{4}— то же, но добавляются четыре цифры;#[0-9a-fA-F]{6}— корректная запись цвета в шестнадцатеричном формате HTML/CSS;\d+— последовательность из одной или более цифр;[-+]?\d+— целое число, которому может предшествовать необязательный знак плюса или минуса;\b[_a-zA-Z]\w+\b— стандартный идентификатор (имя переменной) в C-подобных языках программирования. Он должен быть целым словом (\b), начинаться с буквы или подчеркивания, а далее могут следовать буквы, цифры или подчеркивания"[^"]*"— текст, заключенный в универсальные двойные кавычки.
Опции (флаги) регулярных выражений
Большинство движков позволяют задавать опции (или флаги), которые влияют на поведение всего выражения. Их синтаксис и набор могут отличаться, но четыре из них являются наиболее распространенными. Рассмотрим их подробнее.
- i (case-insensitive) включает режим нечувствительности к регистру символов — например, выражение cat найдет и cat, и Cat, и CAT. Подобное поведение относится только к буквам — спецсимволы, такие как
\sи\S, продолжают работать привычным образом. - g (global) активирует глобальный режим. По умолчанию движок останавливается после нахождения первого совпадения. С флагом
gпоиск продолжается по всему тексту до его конца, и в результат попадают все найденные совпадения. - m (multiline) активирует многострочный режим. Эта опция изменяет поведение якорей
^и$. В обычном режиме^соответствует только началу всего текста, а$— только его концу. В режимеmякорь^также соответствует началу каждой новой строки (сразу после символа\n), а$— концу каждой строки (непосредственно перед символом\n). - s (single line или dotall) изменяет поведение метасимвола точки (
.). Исторически точка соответствует любому символу, кроме переноса строки. Включение опцииs«исправляет» это, заставляя точку соответствовать абсолютно любому символу, даже\n. Опцииsиmне являются взаимоисключающими и могут быть активны одновременно.
Финал: решение исходной задачи
Теперь, вооружившись новыми знаниями, вернемся к нашей задаче: найти все отдельные слова в русском тексте, которые начинаются на «к» и заканчиваются на «а».
Сформулируем требования более конкретно:
- слово должно начинаться с буквы «к»;
- при этом заканчиваться буквой «а»;
- между «к» и «а» может находиться одна или несколько русских букв или дефисов;
- это должно быть именно целое слово, а не часть другого слова.
Поскольку стандартный маркер границы слова \b некорректно работает с кириллицей, нам придется определить их вручную. В нашем случае это будет начало и конец строки, а также любой символ, не являющийся русской буквой.
Разделим выражение на логические компоненты:
- начало границы:
(^|[^а-яё])— либо начало строки, либо символ, не являющийся русской буквой; - первая буква:
к; - середина слова:
[а-яё-]+— одна или более русских букв или дефисов; - последняя буква:
а; - конец границы:
($|[^а-яё])— либо конец строки, либо символ, не являющийся русской буквой.
Определим используемые классы символов:
- русская буква:
[а-яё]. - русская буква или дефис:
[а-яё-]. - символ, не являющийся русской буквой:
[^а-яё].
Соберем все это вместе в одно финальное выражение:
![Тестирование регулярного выражения: (^|[^а-яё])к[а-яё-]+а([^а-яё]|$) — подсвечиваются слова, начинающиеся на «к» и заканчивающиеся на «а», но с соседними символами.](https://lh7-qw.googleusercontent.com/docsz/AD_4nXeeIZSsQ9Avocrbzx8KyQemf5btn5fri0lgDxa2-3pxHmnoWIw9XWz-IRPDP-CagRKI04VrPsHHvjXS4YHllo6DXhUYRTtL3D3vuiX6IHy_ILTqwRVOr2axNzIPKoW4AVlSgxc02Q?key=whd9QVUwK5gf4gbsMfC3rg)
Наше решение работает почти идеально. Единственная оставшаяся проблема заключается в том, что в результат совпадения попадают и сами граничные символы — такие как, пробелы и запятые.
Как избавиться от этого побочного эффекта и захватывать только интересующую нас часть, мы обсудим в следующей статье, где речь пойдет о группирующих конструкциях.