Команда grep в Linux
Инструкция об инструменте поиска, который позволяет найти нужный текст в выводе в консоли.
Что такое команда grep
Расшифровка команды — search globally for lines matching the regular expression, and print them. Команда grep, включенная в проект GNU, считается среди пользователей одной из наиболее популярных и востребованных. Она может помочь решить множество разноплановых задач: найти файл с конкретной строкой в файловой системе или, наоборот, строку в файле, где содержатся определенные символы.
При этом с ее помощью можно не просто находить куски текста, но и с высокой эффективностью фильтровать вывод другой команды.
Кроме этого, данная утилита уже встроена почти в каждый дистрибутив, это упрощает процесс использования. У команды grep есть много полезных опций, которые мы рассмотрим вместе с примерами в этой инструкции.
Синтаксис grep
Основное правило, по которому строится команда grep можно описать следующей схемой:
$ grep [опции] шаблон [<путь к файлу или папке>]
- Опции grep — дополнительные параметры, которые позволяют настраивать разные условия для поиска или вывода, такие как учет регистра или вывод названия файла.
- Шаблон — любая строка или регулярное выражение, используемые для поиска определенного текстового паттерна.
- Путь означает имя файла или папки, где производится поиск. При выполнении grep важно указывать путь, так как этот инструмент способен осуществлять поиск в нескольких файлах или каталогах при использовании рекурсивного режима.
Прописать команду можно другим способом, чтобы применить фильтр к стандартному выводу другой команды:
$ команда | grep [опции] шаблон
Этому можно найти применение при отборе ошибок из логов или поиске информации о выводе другой утилиты.
Осознать, что из себя представляют все комбинации команды, будет проще и понятнее на практике, на примерах конкретных небольших задач. Давайте рассмотрим ключевые сценарии применения grep для поиска в содержимом файлов.
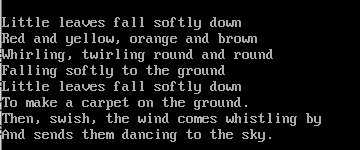
Создадим текстовый файл poem.txt с коротким стихом, по которому будем осуществлять поиск:
Регулярные выражения
Регулярные выражения — инструмент для определения общих шаблонов поиска. Используя их вместе с другими командами, можно значительно расширить спектр возможностей обработки текстовой информации.
Grep использует версию регулярных выражений, аналогичную стандарту POSIX, предоставленную GNU. Практически все виды регулярных выражений схожи, но отличаются в метасимволах или специальных операторах.
Функционал регулярных выражений в grep разделяется на два уровня: базовый и расширенный. Для активации расширенного набора требуется добавить параметр -E.
Регулярное выражение следует помещать в одинарные кавычки, чтобы предотвратить интерпретацию и расширение выражения оболочкой (например, Bash) перед запуском процесса grep.
Использование косых кавычек может вызвать выполнение текста между ними как подпроцесса bash. Если содержимое окажется допустимой командой, то вместо регулярного выражения будет текст, который вернет команда, что приведет к некорректному выводу.
Также возможно использование двойных кавычек, что позволит передавать в регулярное выражение переменные среды, которые будут применены при вызове команды grep.
Базовые выражения
Мы уже знаем, что возможности утилиты grep включают в себя различные типы регулярных выражений. Стандартно используются базовые регулярные выражения (BRE), а для работы с расширенными регулярными выражениями (ERE) нужно явно прописывать настройки. Базовые выражения предоставляют определенный набор символов: ., *, [], [^], ^ и $.
Некоторые из этих символов также называют якорями, так как они “привязывают” совпадение к конкретной части слова или строки.
На практических примерах рассмотрим, как с помощью регулярных выражений расширить возможности поиска.
С помощью циркумфлекса (^) можно найти строки, начинающиеся с конкретного символа, то есть осуществить поиск по совпадению начала строки:
grep ‘^T’ poem.txt
grep выводит:

Если необходимо получить выборку, в которой строки заканчиваются на какое-то выражение, то здесь нужен символ доллара ($):
grep ‘n$’ poem.txt
При запуске команды получим такие строки, где найдено совпадение по концу строки:

С помощью оператора \< можно указать, с чего должно начинаться искомое слово (аналогично оператор \> “привязывает” поисковый шаблон к окончанию слова):
grep ‘\<so’ poem.txt

Также вместо специальных \< и \> можно написать сочетание \b, обозначающее границу начала или конца слова. Чтобы найти слова, начинающиеся на символ d, воспользуемся командой:
grep ‘\bd’ poem.txt

А если нужны слова, заканчивающиеся на d, то применим такую команду:
grep ‘d\b’ poem.txt

Используя только базовый синтаксис, у пользователя не будет возможности указать точное количество этих символов. Поэтому для более сложных запросов нужно использовать расширенные регулярные выражения.
Расширенные регулярные выражения
В расширенном синтаксие в дополнение к базовым поддерживаются следующие символы:
| Символ | Значение |
| + | одно или более повторений предыдущего символа |
| ? | ноль или более повторений предыдущего символа |
| {n, m} | от n до m раз повторение предыдущего символа |
| | | объединение нескольких паттернов |
Попробуем скомбинировать несколько символов для выполнения сложного запроса. Выведем строки, содержащие одно или более вхождений символа ‘l’ или от одного до двух вхождений символа ‘d’:
grep -E ‘l+|d{1,2}’ poem.txt
В результате получим следующее:

Регулярные выражения, используемые в команде grep, — отдельная тема, которая требует внимание. В данной статье мы продемонстрировали всего несколько возможностей.
Классы символов в регулярных выражениях
Класс символов — функция для регулярных выражений, которая помогает задать сразу несколько символов. Осуществляется это с помощью квадратных скобок ([]). Есть два основных способа: перечислить все искомые символы (например, [aeiou] – гласные латинские символы) или указать диапазон (например, [m-r], автоматически расширяющийся до [mnopqr]).
Важно, что в класс символов можно также включить специальные символы. Однако их нельзя использовать в указании диапазона.
Обозначим в квадратных скобках ([]) группу символов, вхождения которых нужно найти:
grep ‘[A-C]’ poem.txt
В результате увидим:

А теперь найдем сочетание из шести букв алфавита, состоящих только из строчных символов. Чтобы задать количество нужно использовать фигурные скобки ({}):
grep -E ‘[a-z]{6}’ poem.txt

В регулярных выражениях имеется значительное количество именованных классов символов, которые широко применяются для различных целей. Вот некоторые из них:
| Класс символов | Значение |
| [:lower:] | строчные буквы от a до z |
| [:upper:] | заглавные буквы от A до Z |
| [:alpha:] | все буквенные символы |
| [:digit:] | все цифры |
| [:alnum:] | все буквенные и цифровые символы |
Теперь изменим предыдущий запрос, используя именованный класс символов:
grep -E ‘[[:lower:]]{6}’ poem.txt
И получим такой же результат:

В руководстве по grep можно найти еще больше классов, которые упростят команды и сделают их понятнее.
Примеры использования команды grep
Начнем с рассмотрения основных практических примеров использования grep.
Поиск без учета регистра
С помощью метки -i можно находить все вхождения фрагмента текста в независимостиот регистра:
grep -i little poem.txt
В результате мы получим:

Обратим внимание, что при поиске обычной строки, без использования регулярных выражений, кавычки можно опустить.
Поиск по всему слову
Параметр -w позволяет возвращать только те строки, в которых выражение будет отдельным словом, а не подстрокой другого слова:
grep -w ‘a’ poem.txt
Результатом будет:

Обратный поиск
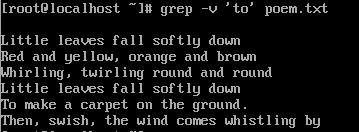
Если необходимо найти все строки без вхождений какой-то последовательности символов, то нужно использовать флаг -v:
grep -v ‘to’ poem.txt
Такой поиск еще называют инвертированным. Вывод будет содержать все строки без вхождения to:
Поиск текста в файле
Найдем все вхождения предлога to в стихе. Для этого применим команду:
grep ‘to’ poem.txt
После выполнения команды получим следующее:

С помощью параметра -e можно указать сразу несколько условий:
grep -e ‘to’ -e ‘Little’ poem.txt
Тогда в результате мы получим все вхождения, содержащие хотя бы одно из перечисленных условий:

Флаг -n добавляет к выводу номер строки с совпадением:
grep -n ‘sky’ poem.txt
Вывод будет таким:

Если в поисковом запросе нужно использовать специальные символы, то нужно явно указывать это с помощью -F. Иначе будет ошибка о неверно заданном регулярном выражении.
grep -F ‘[’ poem.txt
Поиск совпадений в нескольких файлах
Используя маски, в grep можно осуществлять поиск шаблона одновременно в нескольких файлах:
grep Error /var/log/messages*
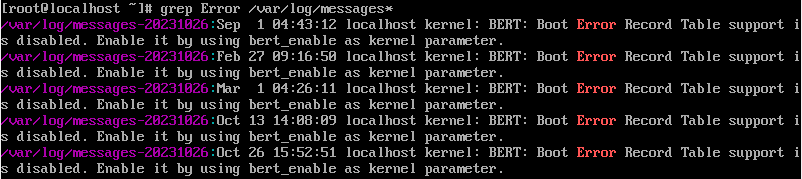
Для удобства пользователей при поиске во множестве файлов, в начале каждой строки указывается название путь до файла.
При необходимости отфильтровать вывод выполненной команды, нужно перенаправить его с помощью оператора |. В таком случае не нужно указывать файл, так как grep осуществит поиск в выводе:
ps aux | grep ‘17:47’
При выполнении этой команды мы получим список конкретных процессов:

Вывод контекста
Иногда очень полезно не только извлекать саму строку с совпадением, но и включать в вывод строки, предшествующие и следующие за ней. Например, если мы стремимся извлечь все ошибки из файла с логами, но предполагаем, что после строки с основной ошибкой может содержаться важная информация, то в таком случае с grep мы можем отобразить дополнительные строки.
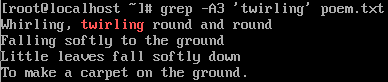
Для этого воспользуемся опций -A с указанием количества строк после нее, которые хотим увидеть в выводе:
grep -A3 ‘twirling’ poem.txt
Если нужно получить строки до найденного вхождения, то тогда поможет аналогичный параметр -B:
grep -B2 ‘wind’ poem.txt

При ситуации, когда нужно получить строки и до, и после, применяем параметр -С:
grep -С1 ‘on’ poem.txt

Рекурсивный поиск в grep
Во всех примерах до этого мы искали в пределах одного файла. Но у этой утилиты есть возможности выполнить рекурсивных поиск в нескольких файлах, находящихся в одном каталоге или подкаталогах.
Попробуем найти все вхождения ‘the’ в каталоге root. Осуществить это поможет опция -r:
grep -r ‘the’ /root
Вывод:

Обычно в папке с файлами присутствуют двоичные файлы, для которых маловероятно проведение поиска. Чтобы их пропустить, нужно добавить опцию -l:
grep -rl ‘the’ /root
Ожидаемо результат изменился:

К части файлов доступ есть только у суперпользователей. И чтобы искать и по ним тоже, нужно запускать grep через sudo. Либо же можно воспользоваться параметром -s, тогда сообщения об ошибках будут скрыты, а файлы пропущены:
grep -rls ‘the’ /root
Выбор файлов для поиска
Путем задания опций –include и –exclude можно контролировать, какие файлы участвуют в поиске, фильтруя, какие включать и какие исключать из процесса.
При желании выполнить отбор по файлам с определенным расширением воспользуемся такой командой:
grep -r --include=’*.log’ ‘grep -E’ /var/log

Аналогично, чтобы исключить все файлы с расширением .journal, применяем параметр –exclude:
grep -r --exclude=’*.journal ‘grep -E’ /var/log

Количество строк
Для некоторых задач может понадобиться не найти все строки с вхождением, а узнать количество совпадений. Для этого нужно применить параметр -c, счетчик:
grep -c ‘ll’ poem.txt
В выводе мы увидим количество подходящих строк:

Вывод имен файлов
Опцией -l в grep можно задать вывод только имен файлов, где найдено хотя бы одно совпадение. Например, при выполнении следующей команды будут показаны названия файлов, в которых обнаружены совпадения с ключевым словом ‘root’:
grep -lr ‘root’ /var/log

Цветный вывод
Изначально, grep не выделяет совпадения цветом, но во многих дистрибутивах установлен алиас, который активирует эту функцию. Однако при использовании команды с sudo эта функция может не работать. Для подключения подсветки вручную, нужна опция –color с параметром always:
grep --color=always ‘ll’ poem.txt

Ограниченный вывод
При поиске в больших файлах вывод может быть очень длинным и нечитабельным. Тогда удобно использовать фиксированное количество строк, применив параметр -m с указанием числа строк:
grep -m2 ‘ll’ poem.txt

Точный вывод строк
Для вывода строк, полностью соответствующих указанному шаблону, а не его части, используйте опцию -x в команде:
grep -x ‘Red and yellow, orange and brown’ poem.txt

Файл шаблонов
Если вы часто используете одни и те же шаблоны, то их можно указать в одном файле. Тогда при поиске с grep достаточно указать путь к этому файлу с флагом -f.
Создадим файл pattern.txt со следующим содержанием:

Теперь найдем подходящие строки, используя этот файл:

Доступ к системной информации с помощью grep
Еще одной полезной функцией grep является возможность просматривать системную информацию.
Например, с помощью следующей команды можно узнать модель вашего компьютера:
grep -i 'Model' /proc/cpuinfo

Также помним, что при помощи grep мы можем отфильтровать вывод команд, это открывает широкие возможности для доступа к системной информации.
Заключение
Команда grep, стандарт в UNIX-подобных системах, предоставляет гибкие и эффективные средства для поиска текстовой информации по шаблонам и регулярным выражениям, обработки файлов и анализа данных через командную строку.
Комбинируя все функциональные возможности этой утилиты, можно решать разные задачи поиска.