

Не кладите яйца в одну корзину — базовое правило диверсификации, которое актуально и для IT-инфраструктуры.
Есть отказоустойчивость, за которую отвечает провайдер. Он резервирует сетевые каналы, средства обеспечения бесперебойного электропитания (ДГУ, ИБП и т. д.) и кондиционирования серверных. Также отказоустойчивость может быть «встроена» в готовый сервис — например, в Managed Kubernetes или облачные базы данных. В них стабильность кластеров обеспечивается за счет автохилинга нод и других автоматизаций.
Надежный провайдер — это хорошо, но его наличие не исключает важность повышения отказоустойчивости IT-инфраструктуры на стороне клиента. Так, можно положить все критические сервисы на один сервер и разместить его в дата-центре уровня Tier III. Машинный зал будет стоять насмерть, но сбой может произойти в SSD-диске и не обязательно по вине провайдера. Ни одна сертификация Uptime Institute не спасет.
Впрочем, и здесь провайдер может помочь. Например, предоставить опцию распределения сервисов на несколько локаций для повышения отказоустойчивости. Упадет один сервер — будет работать резервный. Но для этого провайдер должен быть достаточно крупным.
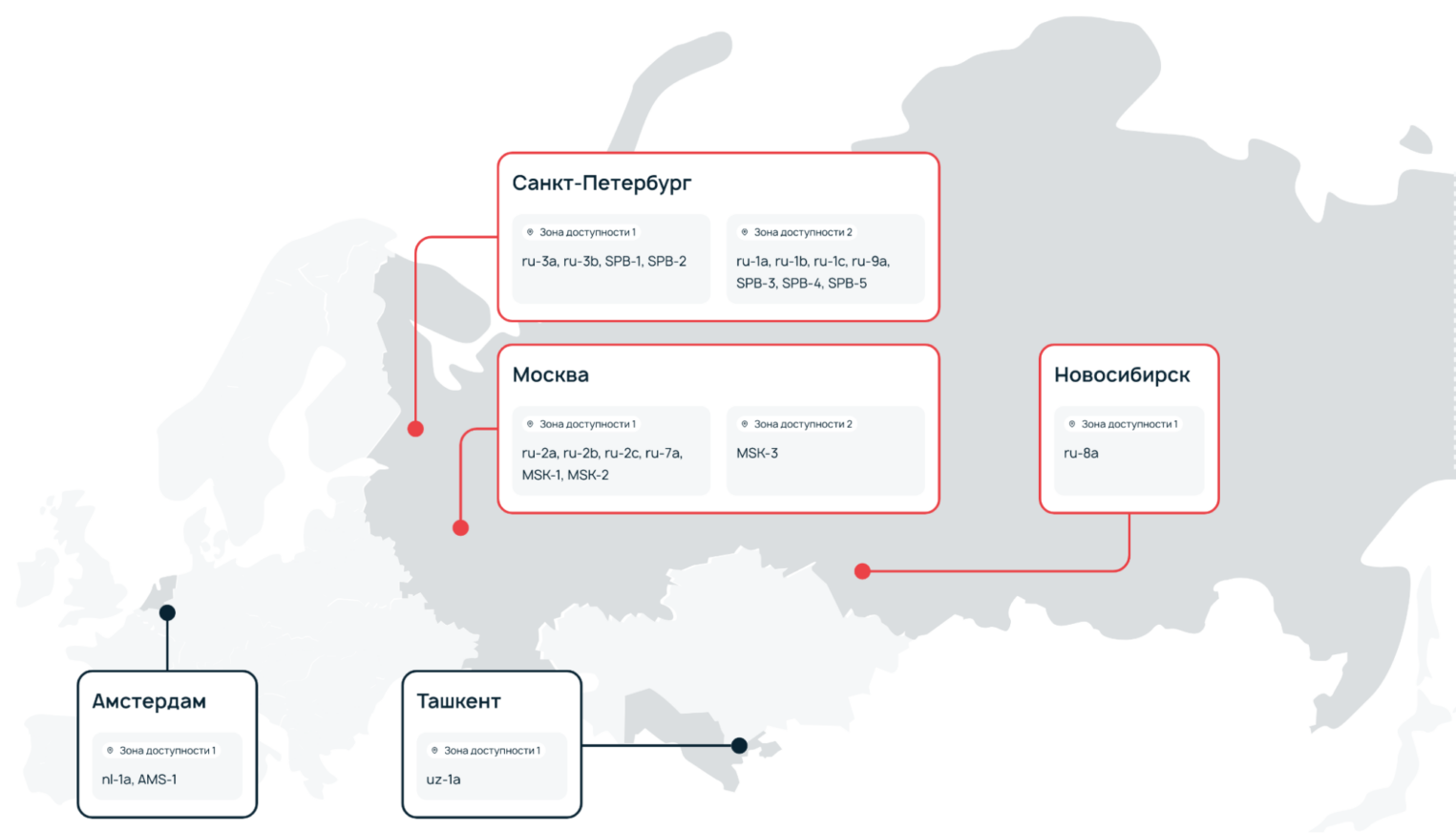
Инфраструктура Selectel расположена в двух странах — Россия и Узбекистан, в 4 регионах — Москва, Санкт-Петербург, Новосибирск, Ташкент, в 6 разных зонах доступности. Это позволяет клиентам Selectel повышать отказоустойчивость на одном или нескольких уровнях инфраструктуры:
- на уровне региона,
- на уровне зоны доступности,
- на уровне пула,
- на уровне серверной стойки (для выделенных серверов) или хоста виртуализации (для облачных серверов).
Выбор уровня зависит от задач, возможностей компании и требований к отказоустойчивости. Рассмотрим каждый из них в порядке уменьшения расстояния между элементами инфраструктуры.
Уровень региона: построение катастрофоустойчивой инфраструктуры
Понятие региона в Selectel совпадает с названием реальных городов, в пределах которых находятся дата-центры компании или партнерские ЦОД.
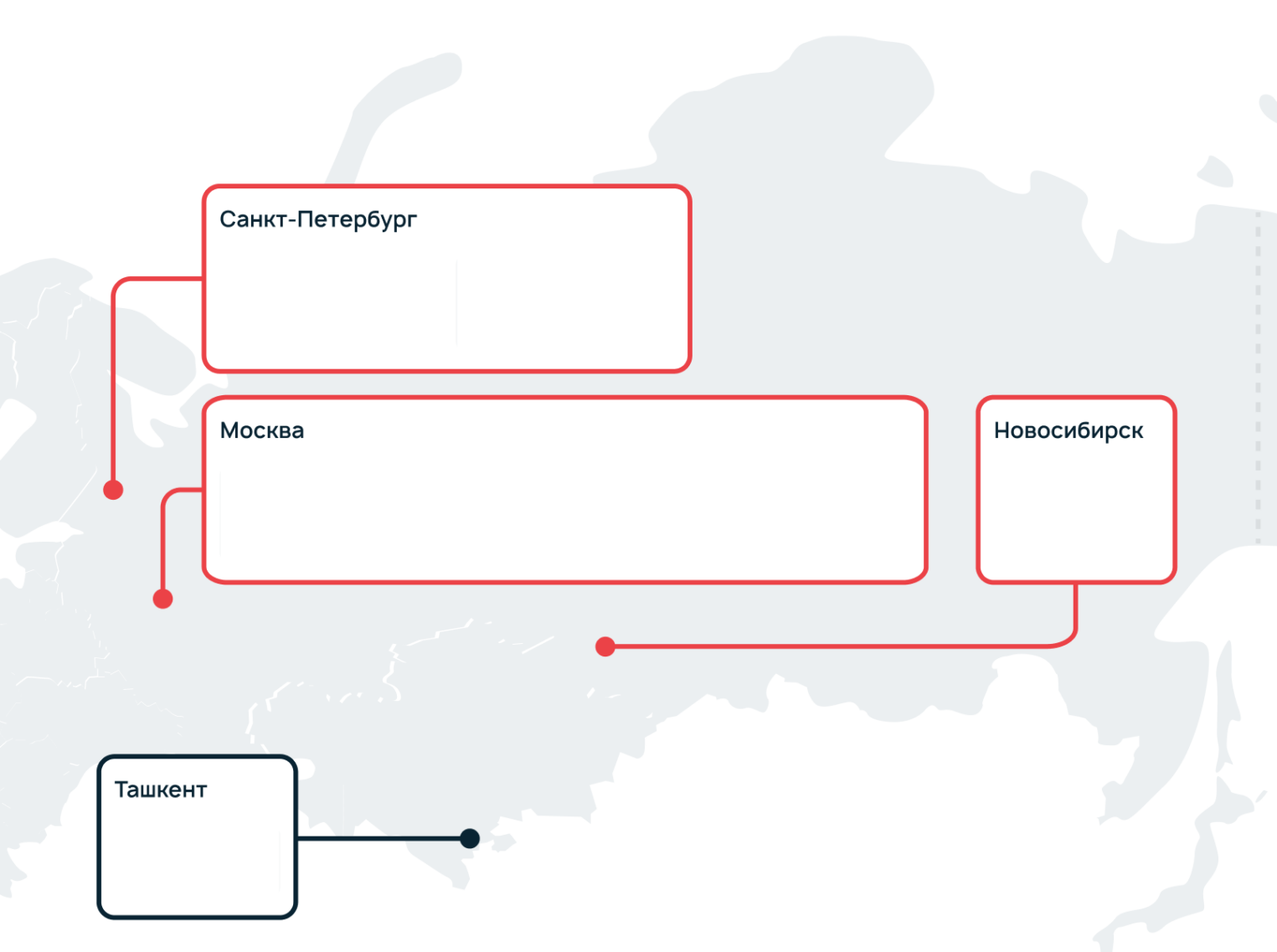
Каждый регион полностью изолирован и автономен. Если в Санкт-Петербурге случится шатдаун, в московском ДЦ «Берзарина» все будет спокойно. Несмотря на географическую удаленность, регионы связаны между собой высокопроизводительными каналами связи. А значит, распределенные части инфраструктуры смогут «общаться» между собой с допустимым латенси.
Что это дает? Высокий уровень отказоустойчивости. Размещение в разных регионах позволит пережить природные и техногенные катастрофы: наводнение, землетрясение, падение метеорита, масштабное отключение интернета или шатдаун. На логике регионального деления построена услуга Disaster Recovery — по сути, это резервная площадка в другом регионе для быстрого развертывания клона «упавшей» инфраструктуры.
Каким компаниям подойдет? Компаниям с особо высокими требованиями к отказоустойчивости и тем, кто развивает мультирегиональный сервис. Например, у вас сервис доставки еды, который работает как в Санкт-Петербурге, так и в Москве. Распределение инфраструктуры по регионам повысит доступность сервисов для конечного пользователя.
Для кого излишне? Для сервисов, клиенты которых привязаны к конкретной географической точке. Если у компании сеть петербургских школ по изучению английского языка, все клиенты — в Санкт-Петербурге, а некоторый даунтайм не критичен, нет смысла резервировать серверы в Москве. Лучше выбрать один из следующих способов повышения отказоустойчивости.
Уровень зоны доступности: золотой стандарт
В одном регионе может быть несколько дата-центров: так, Санкт-Петербург включает в себя ЦОДы в Дубровке (Ленинградская область) и на Цветочной. Между собой эти две зоны доступности связаны волоконно-оптической линией связи, зарезервированной на физическом уровне. При этом инженерные системы у них различны: они обслуживают конкретную группу ДЦ и зарезервированы в привязке к ней.
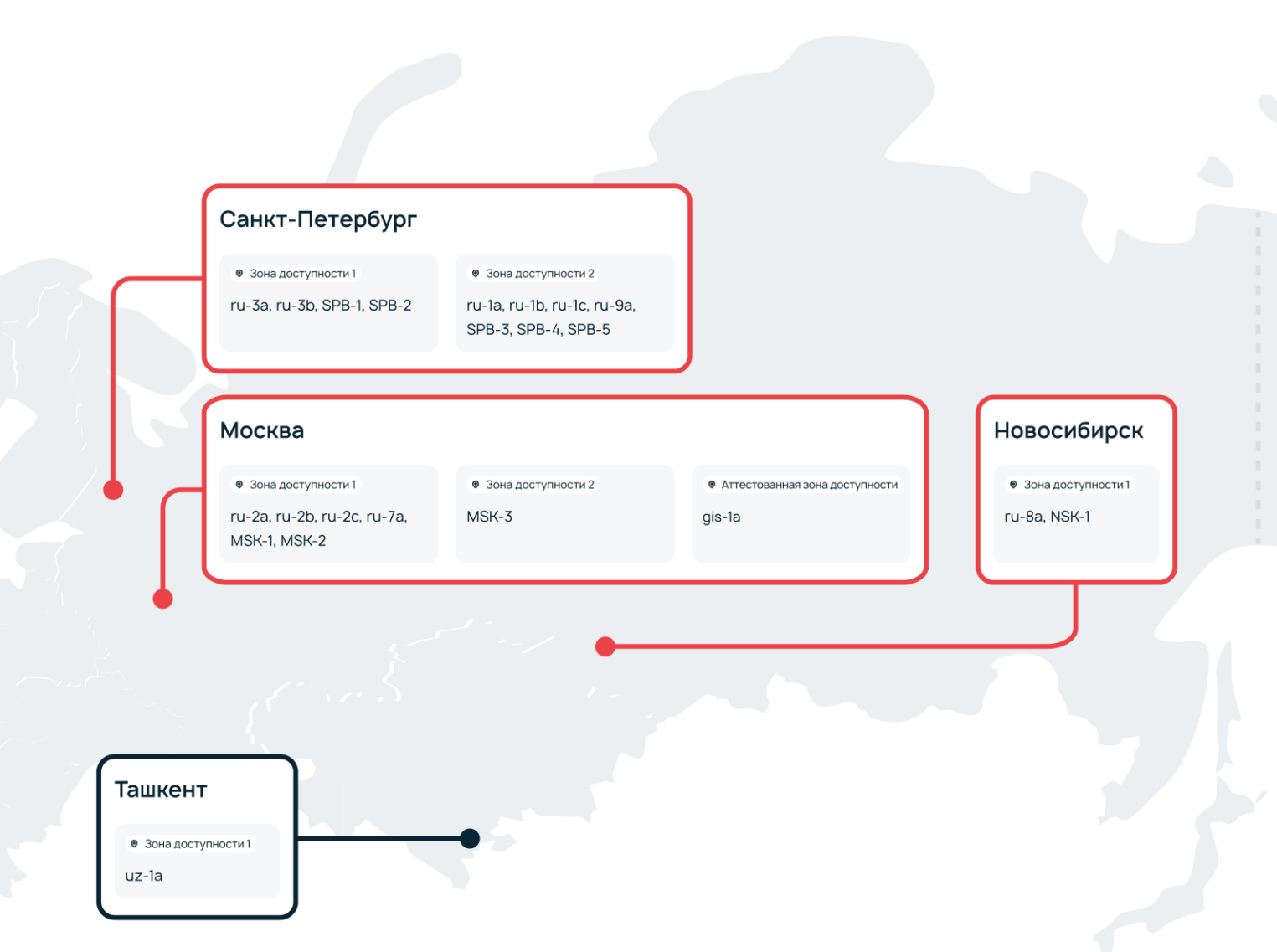
Что это дает? Рабочую модель отказоустойчивой инфраструктуры без издержек в виде возросшего латенси. Дата-центры в зоне доступности хорошо связаны между собой и находятся относительно близко друг к другу.
При этом разные зоны не имеют единой точки отказа. Если, конечно, весь регион вдруг не уничтожит упавший метеорит. В остальном распределение инфраструктуры по зонам доступности повысит уровень защиты данных, спасет от внеплановых отключений электроэнергии в районе дата-центра или пожаров в конкретном ДЦ.
Каким компаниям подойдет? Всем, кто хочет «застраховать» свой сервис от даунтаймов. Близость дата-центров в составе зон доступности обеспечивает быструю скорость передачи данных и не увеличивает задержки. Мы рекомендуем клиентам резервировать критические сервисы именно на этом уровне.
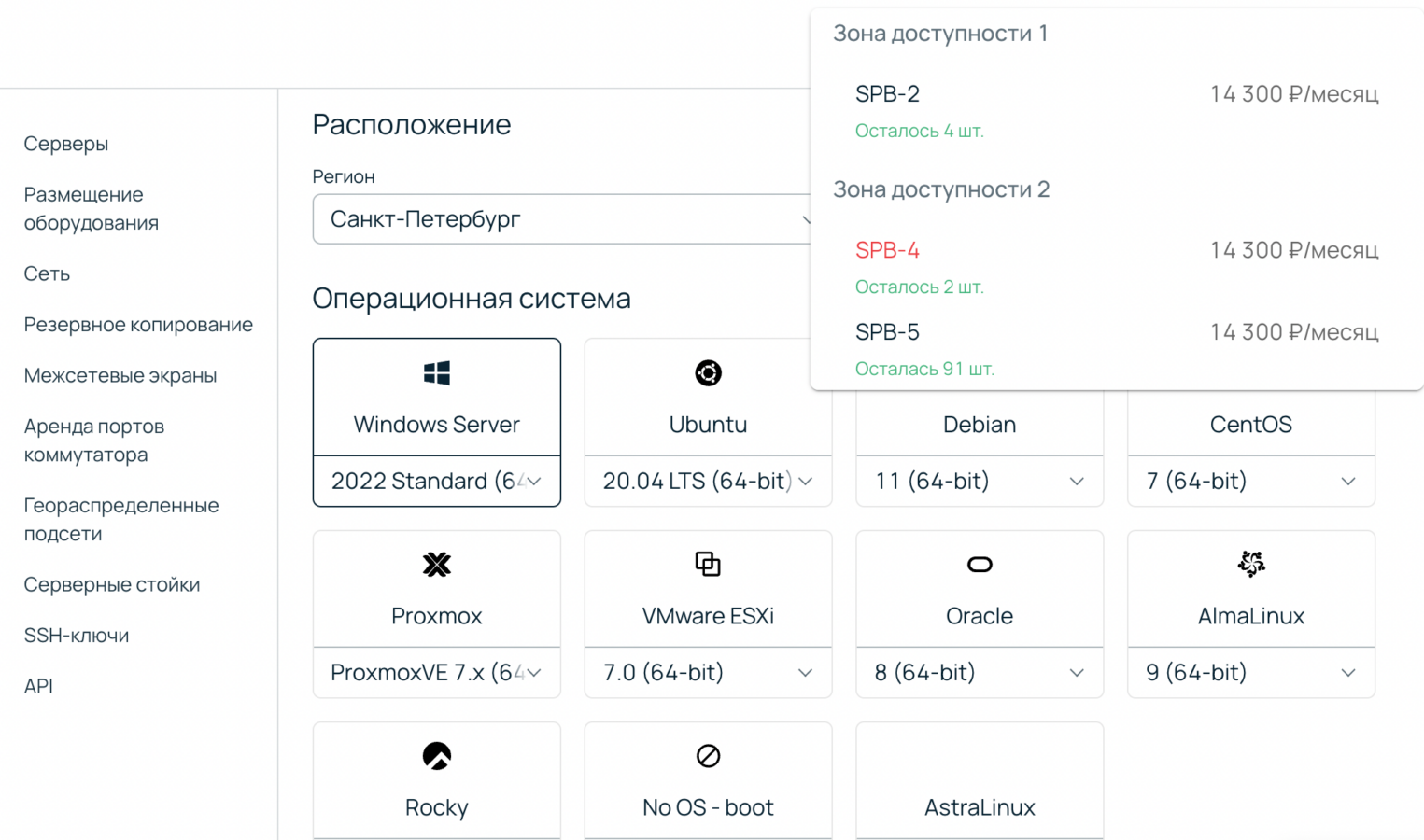
Нюанс: некоторые услуги Selectel доступны в ограниченном числе зон доступности Так, облачные серверы линейки HighFreq (на базе высокочастотных процессоров) можно арендовать лишь в зоне доступности 1, в Москве. Организовать полноценный дубль сервера в другой зоне не получится. Также ограничена в размещении услуга аттестованного ЦОД — по одной зоне доступности в Москве и Санкт-Петербурге.
С полной матрицей доступности услуг можно ознакомиться в базе знаний →
Уровень пула: гигиенический минимум
На этом уровне мы условно оперируем территорией одного дата-центра и его наполнением. Пул — это набор серверов, связанных между собой логически или технически. Пулом могут быть серверы одной линейки, одних характеристик или, например, машины, которые размещены на разных этажах дата-центра.
Так, разными пулами считаются второй и третий этажи ДЦ «Берзарина». С одной стороны, каждая серверная — отдельный дата-центр с не зависящими друг от друга коммуникациям. С другой — здание одно, а значит, точек отказа больше: если вследствие человеческой ошибки в нем произойдет пожар, последствия затронут оба пула. Точкой отказа может стать любой сбой, который повлияет на работу всего здания.
Что это дает? Размещение критических сервисов в разных пулах все еще лучший вариант, чем размещение инфраструктуры в одном регионе, одной зоне доступности и одном пуле. Распределение на уровне пулов предохраняет от таких проблем, как сбой сетевого оборудования или локальные сбои электропитания — отказ PDU.
Пул — довольно легко масштабируемая часть инфраструктуры в отличие от регионов и зон доступности. Так, новая зона доступности в Selectel появится, когда будет достроен ДЦ «Юрловский» в Москве, а новый регион — если компания, например, продолжит зарубежную экспансию. В пул же можно «оформить» новые стойки, добавленные в существующий дата-центр.
В Selectel их немало. При выборе пула можно отталкиваться от желаемого региона, услуги и вида сервера — выделенного или облачного. Сориентироваться поможет уже упомянутая матрица доступности.
Распределение в стойках и сервер-группы: отказоустойчивость на микроуровне и из «коробки»
Завершаем обзор возможностей самым маленьким элементом инфраструктурной «матрешки» — стойкой (для выделенных серверов) и хостом виртуализации (для облачных серверов). Рассмотрим их отдельно.
Распределение в стойке
Заказывая несколько выделенных серверов в одном пуле, клиент может не знать, как именно они будут расположены в машинном зале. Так, они могут попасть в одну стойку, подключенную к одному сетевому оборудованию. Значит, серверы будут находиться в одном домене отказа: случится сбой конкретной стойки по сети или откажет PDU — попадет обоим серверам.
В Selectel клиент выделенных серверов может посмотреть, как распределены машины по стойкам, и оценить, нужно ли менять расположение инфраструктуры. Как это сделать, читайте в базе знаний.
Что это дает? В идеале распределение по стойкам должно дополнять другой способ повышения отказоустойчивости (на уровне зоны доступности или пула). Но если другие концепции — не вариант, то распределение по стойкам предохранит критические сервисы от последствий плановых работ или мелких аварий.
Нюанс: На данный момент возможность доступна не всем клиентам. Если для вас фича недоступна, а задача обеспечения непрерывной работы актуальна, напишите в техподдержку. Мы предоставим вам необходимую информацию в ручном режиме и поможем найти оптимальное решение для повышения отказоустойчивости.
Сервер-группы в облаке
В случае облачной инфраструктуры повысить отказоустойчивость можно на уровне хоста виртуализации. Делается это за счет создания группы размещения. Группа создается для конкретного пула или группы пулов с общей частью в названии (ru-2а, ru-2b, ru-2c).
Что это дает? Быстро развертываемую отказоустойчивость на старте, в единой панели управления Selectel. Не нужно думать о выборе конкретного пула — все произойдет автоматически.
Нюанс: При создании группы можно выбрать политику, которая определит, как именно серверы будут располагаться на физическом оборудовании. Выбрав anti-affinity (размещение строго обязательно на разных хостах), есть риск, что подходящий хост не найдется. Тогда сервер не будет создан. Soft-anti-affinity (размещение желательно на разных хостах) подразумевает опцию, что в отсутствии выбора серверы развернутся на одном хосте виртуализации.
Выделим главное
Selectel предоставляет большое количество сценариев повышения отказоустойчивости. Мы призываем использовать хотя бы один-два из них. Тем более, это легко и быстро делается в панели управления.
Для более сложной гибридной инфраструктуры, подразумевающей связь разных сервисов (дедиков, облака, в том числе от VMware) в разных регионах и зонах доступности, есть сеть L3 VPN из «коробки». На данный момент она бесплатна для всех клиентов Selectel. Повысить отказоустойчивость можно также за счет универсального балансировщика нагрузки. Он по умолчанию зарезервирован в Москве и Санкт-Петербурге и хорошо справляется с балансировкой трафика между выделенными и облачными серверами.
Чтобы выбрать нужный уровень отказоустойчивости, задайте себе несколько вопросов:
- Что для вас важнее — географическое расположение, конкретная услуга или определенное «железо»?
- Какой латенси вы можете себе позволить?
- Насколько критично падение сервиса для бизнеса?
Ответы помогут сориентироваться в описанных возможностях. Если вы все еще затрудняетесь в выборе, сотрудники техподдержки помогут подобрать оптимальный сценарий повышения отказоустойчивости.




