Платформы обработки данных: какие бывают и всем ли нужны
Рассказываем, в какой момент бизнесу стоит организовать платформу для обработки данных и какие варианты есть в России.

Обрабатывают данные, то есть вытаскивают из них пользу, совершенно разнопрофильные компании. Даже сеть семейных парикмахерских на районе может вести отчеты в Excel, используя ее как CRM-систему. На основе данных вывели список клиентов, давно не приходивших на стрижку? Самое время кинуть им sms с «индивидуальной» скидкой.
В какой момент бизнесу стоит организовать целую платформу для обработки данных? Всегда ли обработка данных — это про big data? И какие варианты есть сейчас в России? Рассказываем в тексте.
От Excel до ML — уровни зрелости дата-аналитики
В начале текста мы упомянули семейную парикмахерскую. Хороший пример, чтобы продолжать рассказывать про то, что вообще происходит в мире аналитики данных. Для дальнейшего повествования пусть это будет сеть барбершопов «Бородатый сисадмин».
Ниже — график зрелости аналитических систем, основанный на классификации компании Gartner. На нем можно выделить четыре уровня. Далеко не каждая компания линейно проходит эволюцию от начала до конца. Есть те, что «с ноги» врываются на 3-4 уровни. Главное, чтобы были необходимые ресурсы — деньги и специалисты, а также соответствующие бизнес-задачи. А есть компании, которые за все время существования так и останутся на Excel-таблицах и простенькой BI-системе. Это тоже нормально.
Наш «Бородатый сисадмин» пройдет по каждому этапу, чтобы было проще понять разницу уровней зрелости.

Первый уровень: описательный
Первые три пункта объединим в один блок: сырые и очищенные данные, стандартные отчеты. Это самый низкий уровень работы с данными, который чаще всего производится в Google Таблицах или Excel.
Так, наш барбершоп начал собирать данные о клиентах, которые приходят на стрижку, и считать посещения. Администратор вбивает информацию вручную, некоторые данные стягиваются из формы регистрации на сайте. Менеджер может очистить данные от дублей, поправить ошибки, которые были совершены при регистрации, и даже структурировать данные по количеству и разнообразию оказанных услуг в месяц.
На основе этого можно делать обычные отчеты. Узнать, растет ли количество клиентов месяц к месяцу, что дало больше дохода за лето — стрижка бороды и волос.
Эти данные отвечают на вопрос: что случилось? На основе них можно формулировать гипотезы и принимать решения. В большинстве своем — в ручном режиме и за счет когнитивных усилий менеджера.
К этому же уровню относятся такие форматы аналитики, как Ad hoc reports и OLAP. Ad hoc reports — это отчеты, сделанные под конкретный бизнес-запрос. Чаще всего это что-то нестандартное, чего нет в обычной отчетности. Например, перед менеджером «Бородатого сисадмина» стоит задача узнать, сколько продаж случилось за три месяца для когорты лысых, но бородатых посетителей (с разбивкой по дням).
Второй уровень: диагностический
На этом уровне — так называемая аналитика самообслуживания (self-service BI). Она подразумевает, что выполнять запросы к нужным данным и генерировать обобщающие отчеты могут специалисты разных профилей, а не только аналитики данных. Такой подход также проявляется в использовании BI-cистем типа Power BI, Qlik или Tableau. При этом дашборды в них, как правило, настраивают специалисты по работе с данными.
Здесь данные отвечают на вопрос, почему это случилось? Они не просто описывают нынешнее состояние компании, но являются источником аналитических выводов. Например, выручка «Бородатого сисадмина» выросла в 2 раза в сравнении с предыдущим месяцем. Данные показывают, что случилось это из-за нескольких рекламных постов в Telegram об акции барбершопа.
На этом уровне компания может перейти от Excel-таблиц к Python-скриптам и SQL-запросам. Также здесь уже не обойтись без одного-двух дата-аналитиков в команде.
Зачем вообще переходить на более сложные инструменты?
Причины могут отличаться для каждой конкретной компании:
- Увеличился объем работы с данными. Компания стала не только подсчитывать прибыль и расходы за месяц, но и собирать данные по маркетинговым активностям, фиксировать отток клиентов и так далее. Плодить десятки новых Excel-таблиц становится нерационально — в них легко запутаться и сложно проводить корреляции между событиями.
- Появилась потребность в автоматизации. Сотрудники тратят много времени, чтобы собирать данные вручную. Это время они могут посвятить более полезной для роста бизнеса работе.
- Нужно повысить качество данных. Чем меньше автоматизации процессов, тем больше поле для человеческих ошибок. Какие-то данные могут перестать собирать или вносить с ошибками. Автоматизация и BI-системы помогут лучше «чистить» данные и находить новые направления для аналитики.
- Увеличилось число аналитиков. Например, компания стала развиваться в нескольких регионах. В каждом — свой аналитик, но сводить данные им нужно в одном месте. Для унификации инструментов и подходов можно использовать единую BI-систему и общее хранилище (или хотя бы базу данных).
Третий уровень: предикативный и предписательный
На этом уровне начинается работа с более сложными концептами. Речь о предсказательной и предписательной аналитике.
В первом случае данные отвечают на вопрос, что будет дальше. Например, можно спрогнозировать рост выручки или клиентской базы через полгода. Тут алгоритм анализа может лечь в основу ML-модели.
Предписательная аналитика строится на вопросе, что стоит оптимизировать. Данные показывают: чтобы показатели выручки барбершопа выросли на 60%, нужно увеличить бюджет на рекламное продвижение на 15%.
На этом этапе речь уже не о нескольких аналитиках, а о целой команде, которая может работать на несколько бизнес-направлений. Как правило, в этой точке у компаний появляется необходимость в платформах для обработки данных.
Четвертый уровень
«Вышка» — это автономные системы аналитики на основе искусственного интеллекта. Тут машина предлагает некоторое предположительно верное решение по результату анализа больших данных, а человек принимает финальное решение.
Подобные системы могут использовать банки. Например, это могут быть скоринговые системы для выдачи кредитов. А наш барбершоп может использовать Lead scoring — технологию оценки базы данных клиентов с точки зрения их готовности приобрести продукты компании.
Третий и четвертый уровни только для больших данных?
Короткий ответ — нет.
Объем данных не так важен, как задачи, которые стоят перед компанией
Конечно, чем больше данных, тем репрезентативнее результаты. Но оперировать доводами в духе «у меня база всего на миллион человек, вся эта платформенная обработка — не для меня» тоже неверно.
Данных может быть немного, но они могут быть очень разнообразными: записи бесед с клиентами, записи с камер наблюдения, пользовательские изображения и т.д. Все это нужно систематизировано хранить, чтобы успешно извлекать из них ценные для компании, применимые в бизнес-задачах знания.
Объем данных не так важен, как количество аналитики и аналитических команд
Если в компании несколько аналитических команд по разным бизнес-направлениям, это приводит к проблемам. Команды могут использовать один источник данных, но при этом разные инструменты аналитики, разные хранилища. Иногда они могут анализировать одно и то же или по-разному считать один и тот же показатель, что не очень рационально. Если добавить новую аналитическую команду, она рискует начать дублировать часть уже сделанной работы.
Разнородность аналитических пайплайнов также приводит к задержкам в выполнении требований бизнеса. Продакт-менеджер попросит починить дашборд с выручкой по продукту, а фикс получит только через 1,5 месяца.
Когда растут сложность аналитических задач и число аналитиков, компании задумываются о платформах обработки данных. Они дают общую базу, общепринятые договоренности: с помощью каких инструментов и как мы забираем данные из источников, куда их складываем, каким образом организуем хранилище.
Из чего состоят платформы обработки данных
В целом, дата-платформа — это набор интегрированных между собой инструментов, которые позволяют компаниям делать регулярную и воспроизводимую аналитику данных.
Набор инструментов может быть разнообразным, но вкладываются они примерно в один и тот же пайплайн работы с данными:
- Источники. Весь набор источников данных — от простых файлов и реляционных БД до SaaS-решений, собирающих какую-либо потенциально полезную для бизнеса информацию.
- Обработка и трансформация данных. Здесь в работу вступают ETL- или ELT-инструменты. Данные забираются из источника, подвергаются преобразованиям, если это необходимо, и направляются в хранилище. Здесь могут быть задействованы такие инструменты, как Apache Spark, Kafka, Airflow.
- Хранение данных в формате, подходящем для дальнейшей работы c ними. Самыми популярными тулзами для этого являются Greenplum, Clickhouse, Vertica, инструменты из экосистемы Hadoop.
- Непосредственно анализ данных — описательный и/или предсказательный. В качестве инструмента тут может использоваться SQL, Python или любые другие языки.
- Вывод/визуализация данных для конечных пользователей. Чаще всего какая-то принятая в компании BI-система (Power BI, Qlik, Tableau, Apache Superset или их аналоги).
Это грубое деление на этапы работы, которые охватывает платформа для обработки данных. Архитектура конкретного решения может быть более сложной. Один инструмент может охватывать несколько этапов работы, а какой-то определенный этап, например, хранение или трансформация данных, может быть более комплексным.
Как построить дата-платформу
Здесь вернемся к нашему «Бородатому сисадмину». Довольно сложно представить барбершоп, которому нужна платформа обработки данных, но мы уже слишком далеко зашли. Представим, что им управляет Федор Овчинников. Филиалы барбершопа открыты в 4 регионах страны и 22 городах. А еще он запустил онлайн-курсы по уходу за бородой в домашних условиях и всероссийскую платформу для барберов с системой личных кабинетов.
В общем, данных много, запросов для роста бизнеса тоже, аналитические команды не справляются. Какие есть варианты?
Создаем самостоятельно, с нуля
Самый трудно реализуемый вариант, но исключать его полностью нельзя. В таком случае компании нужно нанимать дорогостоящих на рынке специалистов — DevOps- или дата-инженеров. И надеяться, что они справятся без дата-архитектора (или нанять и его тоже).
Также нужно будет арендовать или закупать инфраструктуру под платформу. Понадобятся быстрые серверы и хорошие пропускные каналы. Если инфраструктура on-premises, серверы, естественно, нужно будет еще обслуживать (+ сменные инженеры в техническую команду для обслуживания 24/7).
Весь набор выбранного для платформы ПО нужно будет настроить и «подружить» между собой, чтобы обработка данных проходила максимально автономно и без сбоев. Отраслевого стандарта по факту нет, готовых инструкций очень мало.
В общем, проект масштабный — нужно вложить большие средства в то, что не будет приносить прибыли до и немного после окончания «стройки». А работа может растянуться в лучшем случае на несколько месяцев.
Нашему барбершопу не подходит. Нужных специалистов нет, IT-бренда, чтобы привлекать хороших специалистов, нет, а профит от анализа данных нужен как можно быстрее.
Нужно искать что-то более готовое. Какие есть варианты?
Идем к облачному провайдеру
У зарубежных компаний, которые нередко cloud native, есть один распространенный сценарий. Когда нужна платформа для обработки данных, они идут к одному из популярных иностранных облаков — например, AWS, Google Cloud, Azure — и там из отдельных «кубиков» собирают себе систему.
У них много продуктов, и там можно найти нужное «коробочное» решение для каждого из этапов пайплайна, который мы рассмотрели выше. «Кубики», впрочем, тоже нужно будет связать — с помощью собственных cloud-архитекторов или соответствующего managed-сервиса от провайдера.
Приобретаем готовую платформу
Еще один вариант — обратиться, например, к компании Cloudera, которая на данный момент является единственным адекватным поставщиком Hadoop. У них можно получить готовую, уже собранную платформу и даже техническое сопровождение. Но будет дорого. Ценник сможет принять только крепко стоящий на ногах энтерпрайз.
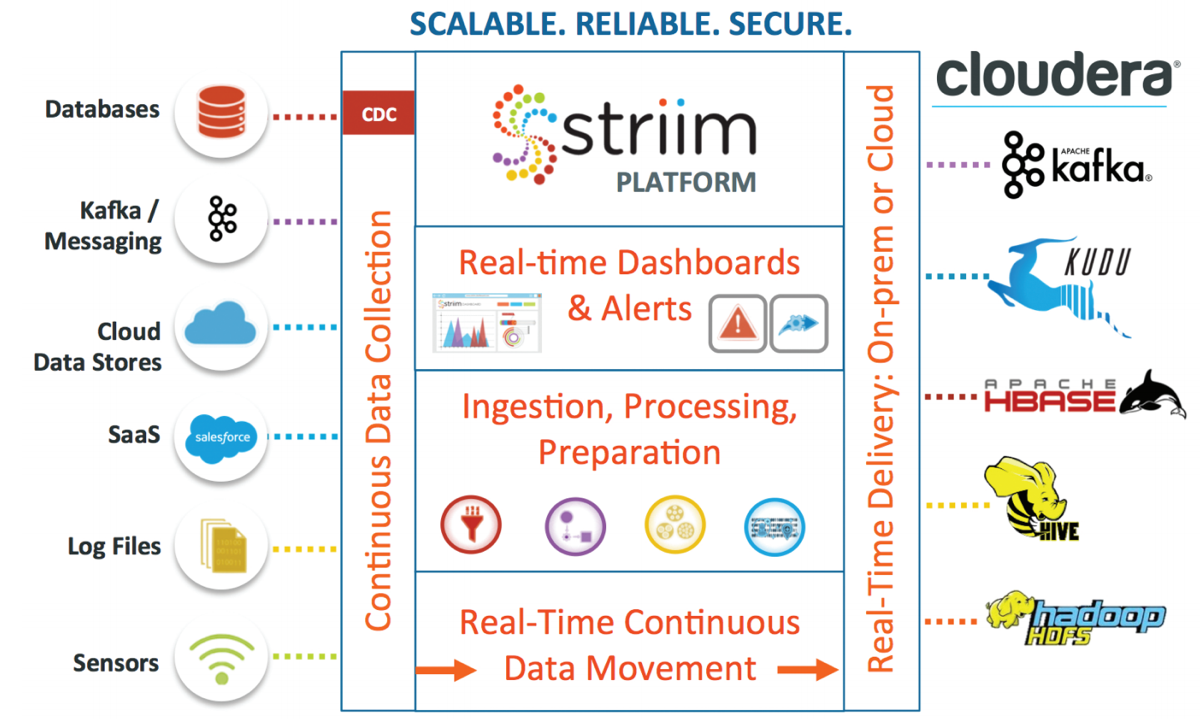
Где проблема? Владелец «Бородатого сисадмина» понимает, что оплата сервисов сейчас затруднена, платить нужно в долларах, а данные безопаснее хранить на территории России. Нужно рассматривать отечественные альтернативы.
Что в России?
В стране есть альтернативы обоим «западным» форматам: и набор необходимых PaaS-решений в облаке, не связанных между собой, и варианты, что ближе к «коробочным». В этом тексте не будет подробного обзора российских решений — этому стоит посвятить отдельный текст (кстати, напишите в комментариях, если вам будет интересно почитать такой обзор).
Здесь мы сосредоточимся на варианте, который обособлен от существующих решений и может быть полезен тем, кто ищет баланс между ценой и качеством.
Арендуем инфраструктуру с предустановленным ПО для обработки данных
Наша ситуация: у «Бородатого сисадмина» нет компетентных архитекторов и нескольких миллионов на интеграцию «коробочного» решения. Какие есть еще варианты?
У Selectel появилась платформа обработки данных — сервис, который снимает с бизнеса сразу две боли: необходимость связывать сервисы в одной инсталляции и заниматься вопросами безотказной работы инфраструктуры.
Работает как ателье. Клиент — это может быть CTO, DevOps, главный аналитик, дата-инженер — рассказывает о своих потребностях. Указывает «мерки»: сколько данных обрабатывается, какой вид обработки нужен — потоковая или пакетная (можно обе), что хочется получать на выходе.
Под требования подбирается инфраструктура — выделенные серверы на высокочастотных процессорах (до 3,6 ГГц) с большим объемом RAM и быстрыми дисками. На ней дата-инженеры из ITSumma поднимают все необходимое ПО под платформу обработки данных — настраивают сетевую связность и все необходимые каналы их взаимодействия.
Минимально достаточное число серверов — четыре машины. Это необходимо для обеспечения отказоустойчивости. Большинство из систем, устанавливаемых в платформу, — распределенные, нужно несколько мастер-нод, размещенных на разных «железных» хостах. Верхняя граница не устанавливается. Инфраструктура под платформу может масштабироваться горизонтально под запросы клиента.
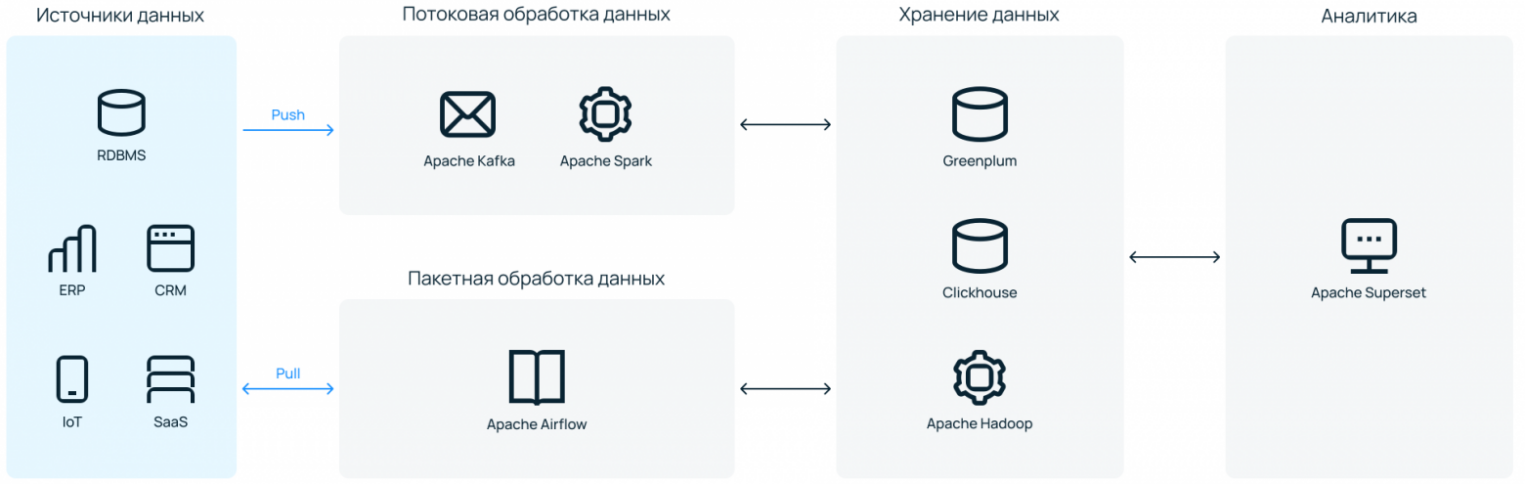
Выбранное ПО — инструменты, которые можно встретить в большинстве эволюционно зрелых дата-платформах. Это open source, поэтому можно не переживать из-за вендор-лока.
Другие особенности
Умеренная кастомизируемость. Клиент может подключать любой источник данных, который ему удобен. Также можно синхронизировать вывод данных в BI-систему клиента, если он, например, использует не Apache Superset. В остальном стек негибкий: поменять один инструмент на другой или добавить инструмент к существующему списку не получится. Можно удалить лишние элементы — например, Kafka и Spark, если компания не занимается потоковой обработкой данных. Это позволит снизить нагрузку на инфраструктуру и сэкономить место для хранения данных.
Контроль на каждом этапе. Клиент получает доступ ко всему: от физической инфраструктуры до интерфейсов каждого из входящего в нее инструмента. Всегда можно добавить новый источник данных или запланировать выполнение нового Python-скрипта в Airflow. Это можно сделать также через поддержку в ITSumma. Если компании это не надо, такой вариант тоже рабочий. И инфраструктура, и софт будут настроены для работы с данными без участия ее сотрудников.
Отдельный бонус — можно добавить к платформе сопровождение дата-инженеров ITSumma, исключив необходимость нанимать in-house специалистов. Все через панель управления Selectel.
Не обязательно быть клиентом. Чтобы построить платформу обработки данных в Selectel, не обязательно хостится на инфраструктуре компании. Сетевую связность можно настроить как on-prem-площадки. Единственное — при этом сценарии могут быть ожидаемые задержки при трансфере данных из источников. Для высоконагруженных систем и систем, чувствительных к latency, лучше перевезти обрабатываемые данные ближе к месту размещения платформы.
Стоимость платформы складывается из стоимости инфраструктуры и работы дата-инженеров ITSumma. Оплата помесячная. Время построения платформы зависит от сложности запроса конкретной компании. На выходе клиент получает отказоустойчивую, хорошо отлаженную систему для регулярной обработки данных.
Зачем компаниям платформы обработки данных
Мы уже много написали о структуре и вариантах реализации дата-платформ. Теперь коротко о том, почему компаниям может быть полезно использование платформ для обработки данных:
- На подготовленных качественных данных можно строить рекомендательные системы (актуально для e-commerce и ритейла). Именно они после заказа продуктов в сервисе доставки предлагают ваши любимые продукты со скидкой. Так компания повышает средний чек и занимается допродажей услуг.
- Компания получает общий инструментарий для всех аналитических команд в компании: ограничивает список используемых инструментов и экономит на найме новых специалистов.
- Платформы данных помогает поднять аналитику на новый уровень — от описательной к предсказательной — и получать более ценную для бизнеса информацию.
- В решениях с технической поддержкой можно перевести траты на работу дата-инженеров из ФОТ в OPEX.
- Готовые платформы снизят нагрузку на дата-инженеров и дата-сайентистов. Они не будут тратить время на настройку софта и его совместимости с инфраструктурой.
Платформы обработки данных — не мастхэв для каждой компании, но и не какой-то уникальный инструмент, который доступен только большим и очень большим компаниям. Это может быть решение и для среднего бизнеса, который хочет расти и видит этот рост именно в data-driven подходе.





