Каким должен быть Feature Store, чтобы оптимизировать работу с ML-моделями
В статье рассказываем о том, что нужно бизнесу от Feature Store сегодня, и разбираем архитектуру open source-платформы Feast.
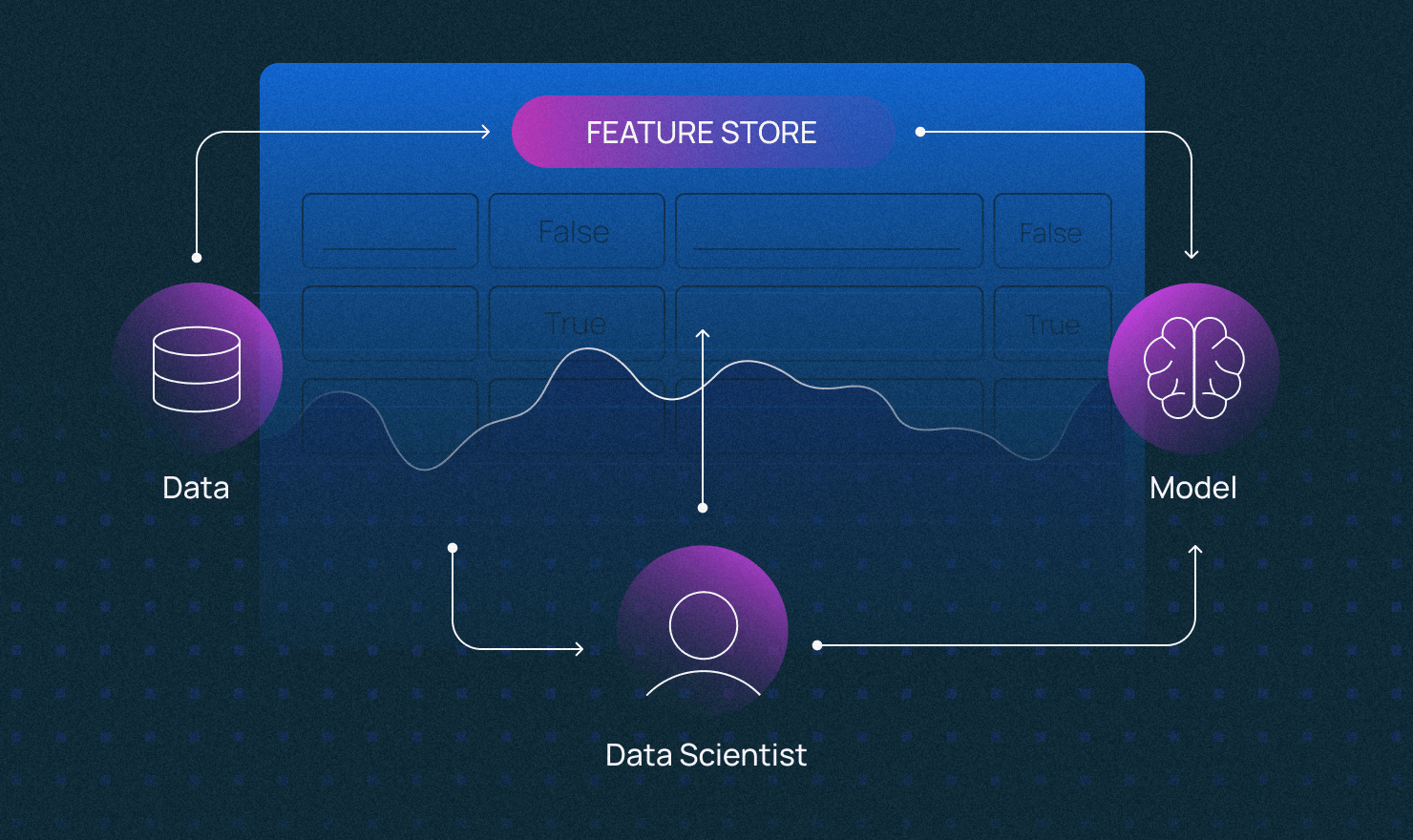
В работе с данными для обучения нейросетей много рутины: под каждую ML-модель нужно создать датасет, потом «вычеркнуть» лишние признаки (фичи) и протестировать точность предсказаний. Иногда при изменении датасета нужно собирать данные по новой. Это неудобно, если нужно переиспользовать уже собранные фичи для обучения новых моделей. Чтобы оптимизировать работу с данными, ML-инженеры объединили разные практики и сформировали парадигму Feature Store.
По мотивам выступления Артёма Глазкова (@Allront), ведущего эксперта MLOps в Polymatica, рассказываем о том, что нужно бизнесу от Feature Store сегодня, и разбираем архитектуру «эталонного» решения.
Если вам интересна тема статьи, присоединяйтесь к нашему сообществу «MLечный путь» в Telegram. Там мы вместе обсуждаем проблемы и лучшие практики организации production ML-сервисов, а также делимся собственным опытом. А еще там раз в неделю выходят дайджесты по DataOps и MLOps.
Задачи Feature Store

Feature Store — это «магазин» фичей, интерфейс между данными и моделями ML. Но технология вовсе не революционная. Она объединяет давно сложившиеся практики по управлению данными. В частности, каталогизацию фичей для обучения и продакшена ML. Просто раньше их применяли в работе с офлайн-данными (батчами), а сейчас «перебрались» в онлайн.
По сути, технология абстрагирует работу с данными от разработки ML-моделей, делает процессы независимыми друг от друга. Подробней о том, что такое Feature Store в принципе, можно узнать тут.
Вот несколько случаев, когда Feature Store может выручить.
- Нужно переобучить нейросеть на новом наборе параметров.
- Нужно перенести датасет из одной модели в другую с учетом ее особенностей параметризации.
Кому может понадобиться?
Feature Store нужен не всем. В первую очередь технология полезна компаниям, которые много работают с ML-сервисами. Рассмотрим пару примеров.
Онлайн-банк
Классический случай: онлайн-банк выдает займы клиентам. Последних можно описать большим количеством внутренних и внешних данных — они подаются на входы моделей в виде фичей. По усредненному результату система определяет, можно ли заключить с клиентом договор.
С помощью Feature Store банк организовал централизованную работу с фичами, которые одинаково хорошо работают в моделях, собранных разными департаментами.
Студия ML-сервисов
Случился «бум!» — всем вдруг понадобилось машинное обучение. Tesla тестирует новые машины с компьютерным зрением, а очередной банк создал голосового помощника «Олежа». И все обращаются к студии ML.
Компании нужно ускорить time-to-market сервисов, чтобы быстрее сдавать заказы. Для этого разработчики студии интегрировали Feature Store. Теперь они способны централизованно проводить эксперименты с разными параметрами моделей и оперативно выпускать сервисы в продакшен.
Но Feature Store не всегда был таким «эффективным».
История развития
Задачи о подготовке данных появились давно. Однако термин Feature Store ввели лишь в 2017 году. Тогда в компании Uber начали развивать сервисы обработки данных и в рамках ML-платформы Michelangelo ввели «новую» технологию.

В 2018-2019 был важный «поинт» — появление первых open source-платформ — Hopsworks и Feast. И уже в 2020-2021 годах компании начали запускать альтернативные платформы, а стартапы — внедрять Feature Store в свои проекты.
Рынок Feature Store-платформ сегодня
На рынке есть около 20 решений, которые можно использовать в своих ML-системах.
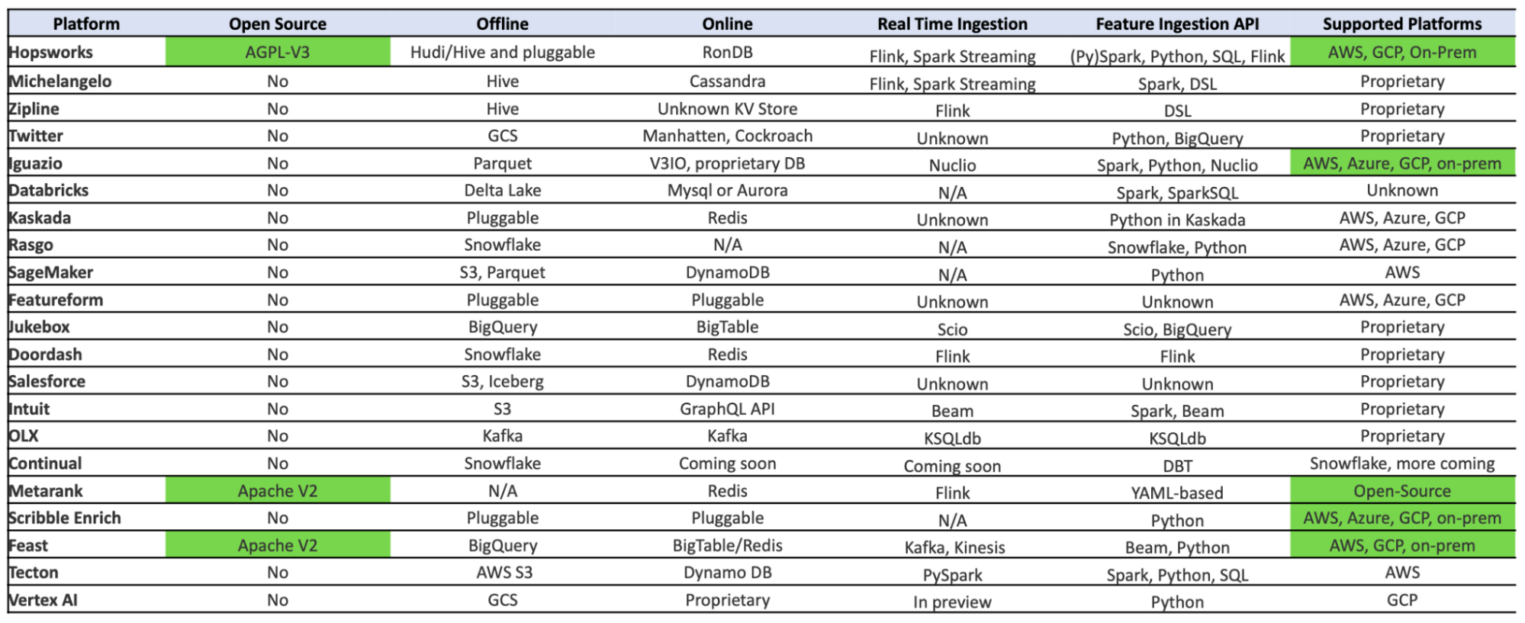
Большинство Feature Store-платформ проприетарны, open source-решений мало. Это нужно учитывать, например, при проектировании собственной ML-платформы.
Также смотрите, чтобы выбранное решение соответствовало вашим требованиям. Иногда вендоры называют свой продукт Feature Store, а внутри платформы реализуют только базовый функционал. Так каким запросам должен отвечать современный Feature Store?
Что нужно ML-инженерам от Feature Store?
На рынке нет «серебряной пули» — существующие платформы можно оценить только через потребности ML-команд и компаний. Вот распределение по частоте запросов бизнеса к функциональным возможностям Feature Store:

Рассмотрим самые частые требования, отраженные в первой и четвертой группах:
- Версионирование фичей — наблюдение за версиями и логикой расчета фичей на исторической прямой. Если нужно ввести новую переменную, можно посмотреть, как она влияет на точность фичей. И «зашить» ее в логику расчетов таким образом, чтобы качество модели не пострадало.
- Офлайн-расчеты — возможность расчета витрины в офлайн-режиме. Можно организовать на базе простого хранилища данных (DWH). Здесь нет rocket science.
- Поддержка on-premise — реализация всего пайплайна внутри собственной IT-инфраструктуры. Особенно важно для тех, кто не доверяет публичным облакам свои фичи и «секретные статистики». Актуально для научных, банковских и других организаций.
- Наличие Linage — наличие взаимосвязей между моделями и данными. Во время работы с большим количеством экспериментов важно, чтобы в любой момент была доступна информация о том, в каких моделях используются фичи.
- Работа с моделями в потоковом режиме — возможность использовать Feature Store в онлайн- и офлайн-режимах одновременно. Например, в онлайн-режиме запускать модели с данными для продакшена, а в офлайн — для обучения.
Все остальное — менее частые запросы. Среди них простые — управление и разграничение прав доступа и GUI — и более сложные:
- Расчеты внутри источников данных — возможность «опустить код к данным» и делать ресурсоемкие расчеты внутри источника данных.
- Управление ресурсами — функция резервирования памяти и мощности процессора под N расчетов, например, внутри источников данных.
- Процессы согласования — то, что редко встречается в платформах «из коробки». Полезно для компаний, в которых есть несколько отделов, — например, риск-менеджеры, маркетологи и антифроды — которые используют ML-модели. С помощью процессов согласования DS-специалист может «запросить» разрешение на изменение логики расчёта фичей и предупредить коллег, чтобы не «сломать» модели.
Не обязательно, чтобы выбранная Feature Store-платформа отвечала всем запросам. Но при выборе платформы можно ориентироваться на «эталон». Рассмотрим пример хорошего открытого решения.
Feast: «эталон» open source-Feature Store
Feast — наиболее популярный открытый Feature Store. На него можно ориентироваться при выборе платформы.
В рамках реализации платформы есть пять функциональных блоков — Registry, Transform, Storage, Serving и Operational Monitoring. Рассмотрим их по отдельности.
Registry
Это «каталог фичей» — основной компонент Feast. Некий центральный интерфейс для каталогизации и классификации фичей. Помогает расставить все «по полочкам» — сформировать структуру репозитория признаков.
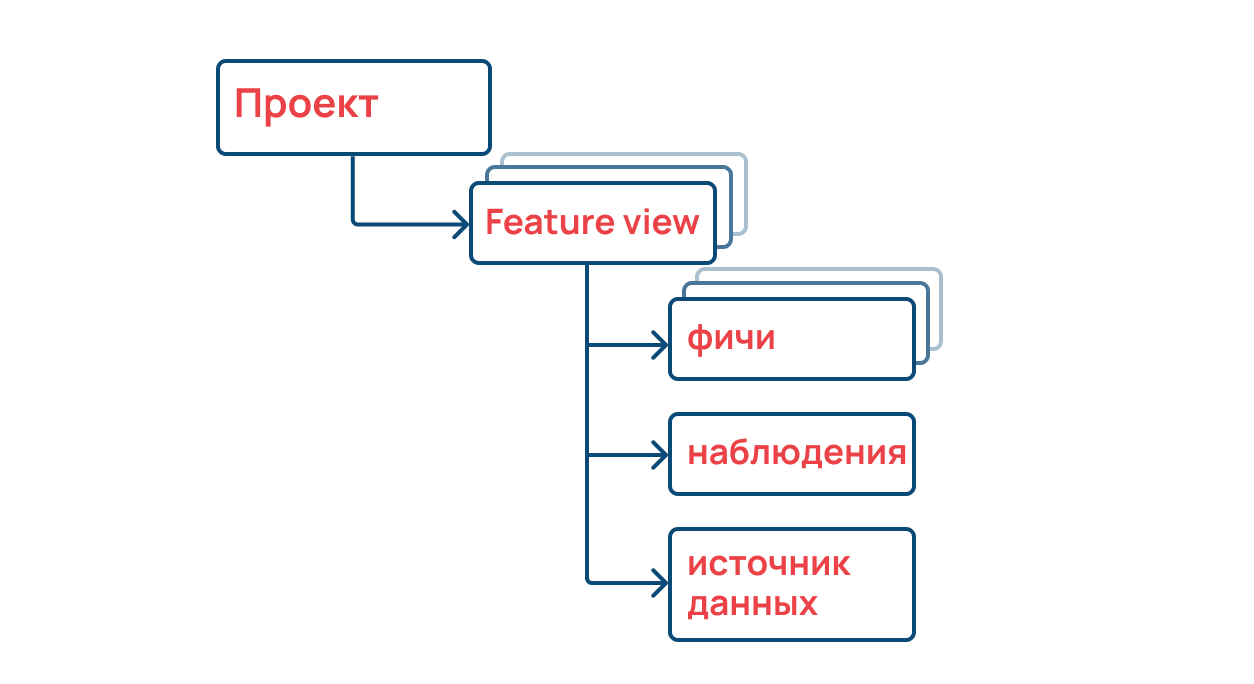
В представлении этой структуры хранятся фичи по такому сценарию:
Есть проект, который решает определенную бизнес-задачу. Feature view описывает набор наблюдений (Entity). На этом уровне можно понять, из какого источника брать фичи, и получить их.
Transform
Компонент для преобразования фичей под определенные модели.

Вот основные типы преобразований:
- Преобразования на пакетных данных — когда на основании таблиц из базы данных нужно сделать определенные расчеты, чтобы подать фичи на вход модели.
- Потоковые преобразования — расчеты данных, которые поступают в режиме реального времени, и подготовка их для работы модели. Актуально для сервисов в продакшене — например, для онлайн-сервисов по покупке авиабилетов.
- Преобразование по запросу — работает только на этапе применения модели. Они нужны для определения оптимальных путей обработки входящих запросов. Актуально для тех, кто хочет «скармливать» данные и критерии без помощи экспертов, — например, менеджерам.
Storage
После описания и получения фичей в Registry нужно их «материализовать» — представить в виде конкретных таблиц и векторов, а после — загрузить в хранилище фичей Storage.
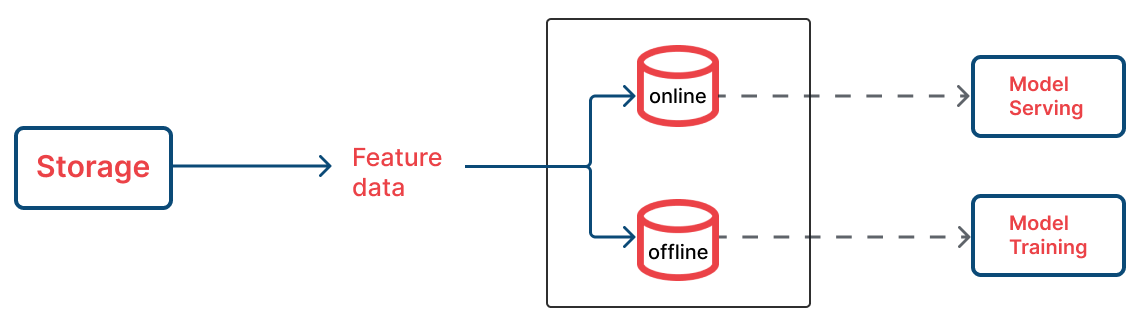
Feast позволяет загружать фичи в офлайн- и онлайн-хранилища. Первое подходит для хранения kv-store (оперативных данных), а последнее — для data lake (данных для обучения).
Serving
Позволяет пользователю получить доступ к фичам, которые размещены в Storage.

Serving реализован в простом Python SDK. То есть пользователь может прямо из Jupyter Notebook сделать запрос к Feast и описать, по каким переменным нужно построить модель данных. Платформа вернет результат в формате Pandas-dataframe.
Как компоненты работают в связке
Рассмотрим пример работы Feature Store.
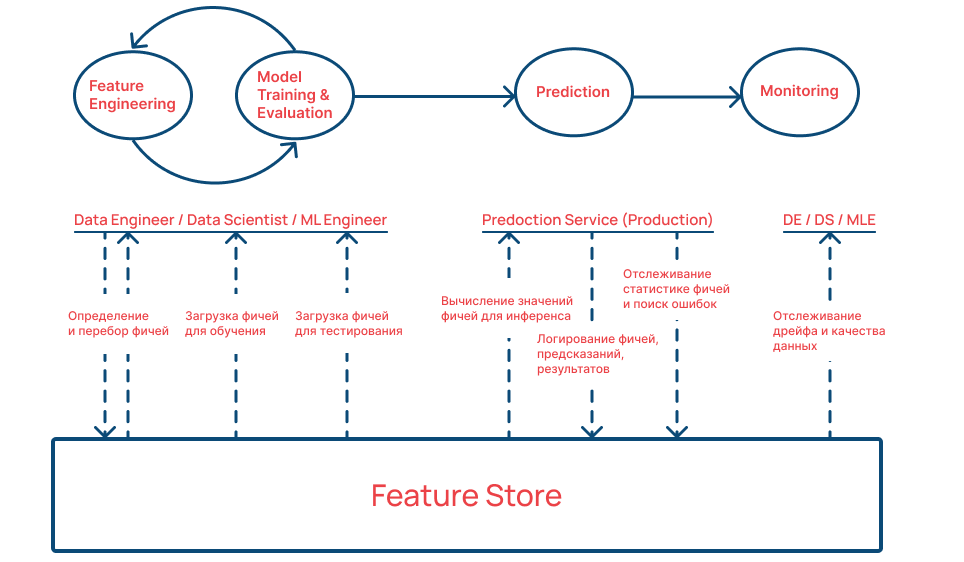
Чтобы платформа заработала, нужно описать схему расчета фичей — за это отвечает Registry. На основании этой схемы загружаются фичи для обучения и Feature Store наполняется материальными данными. Далее признаки можно использовать для построения моделей. А после проверки корректности расчета — выпустить Feature Store в продакшен.
На этапе инференса платформа может рассчитывать фичи — для этого Feature Store запускает логирование вектора данных на вход моделей. В режиме реального времени можно отслеживать качество сборки фичей, прогнозы моделей и в дальнейшем дрейф данных. Это полезно, когда нужно, например, беспрерывно прогнозировать продажи в собственном интернет-магазине.




