Как переехать на Kubeflow в качестве ML-платформы?
В статье рассказываем о том, как перейти на Kubeflow в качестве ML-платформы. По мотивам доклада компании Mediascope.
В этом материале мы поделимся докладом Сергея Савватеева о переходе сервиса Mediascope на Kubeflow, который он подготовил к ML MeetUp.
Поговорим о роли команды в компании, как был устроен процесс разработки до перехода на Kubeflow. Разберем подробно сам переход, какие архитектурные решения принимались. С какими сложностями столкнулись и какие наметили шаги.
Если вам интересна тема статьи, присоединяйтесь к нашему сообществу «MLечный путь» в Telegram. Там мы вместе обсуждаем проблемы и лучшие практики организации production ML-сервисов, а также делимся собственным опытом. А еще там раз в неделю выходят дайджесты по DataOps и MLOps.
О компании
Mediascope занимается измерением аудитории различных медиа, мониторингом рекламы и исследованиями потребительских предпочтений, то есть опросами.
Что такое измерение аудитории? Например, это нужно для мобильных приложений или для сайтов, сколько человек ими пользуется, как эти люди распределяются по полу, по возрасту, по географической принадлежности, по доходу, семейному положению и так далее.
Исторически компания выросла из измерения аудитории TV. На текущий момент рейтинги Mediascope являются валютой рынка, по которой определяется стоимость рекламы. Затем измерения распространились на другие медиа. Сейчас самым динамично развивающимися каналами являются интернет и мобайл. Мы получаем данные от устройств наших панелистов, от интернет-счетчиков, от внешних компаний-партнеров и многих других источников. Все это многообразие потоков данных обрабатывается нашей big data платформой на основе Hadoop, в которой есть разные слои хранения данных.
Данные поступают из источников в разных форматах и как есть попадают во входной слой. Затем они обогащаются внутренними справочниками и раскладываются в корпоративную модель данных.
На ее основе уже строятся общие или специальные витрины данных. Далее происходит поставка данных клиентам в виде API, дашбордов или готовых датасетов. Конвейеры производства данных оркестрируются с помощью Airflow. Иногда на разных этапах возникает необходимость каких-то вероятностных методов обогащения или фильтрации данных, или, например, интеграции различных источников данных на основе статистических моделей. Именно в этих точках вызываются наши сервисы.
Специфика задач и немного рекурсии
Основа измерений компании — это панели. Панель — это случайная выборка из генеральной совокупности. Что такое генеральная совокупность? Например, для мобильной панели — это множество жителей России от 12 лет и старше, которые пользуются мобильным интернетом. Для того, чтобы панель хорошо репрезентировала генеральную совокупность, каждому панелисту назначается вес. Вес — это то, сколько людей в генеральной совокупности он собой репрезентирует.
В генеральной совокупности нам для различных социально-демографических переменных известно распределение количества людей по их значениям. Например, мы знаем долю людей с высшим образованием или, если это касается пола/возраста, то мы знаем долю в генеральной совокупности женщин от 25 до 34 лет. Эти доли являются целями для процедуры взвешивания.
Процедура взвешивания расставляет веса таким образом, что они сходятся на все цели по всем значениям всех социально-демографических переменных, которые в этой процедуре участвуют. Процедура проводится один раз в сутки. Во многом из-за этого большое количество процессов обработки данных происходит за последние сутки, то есть это такая batch-обработка.
Важно, что после того, как данные поставлены клиентам, они не должны изменяться. ML-модели должны быть так устроены, что если их запустят ровно на тех же данных, то они должны воспроизводить тот же результат на выходе.
Как был устроен ML-сервис
Для каждого сервиса использовался свой git-репозиторий. Там был Dockerfile с необходимыми библиотеками и тегированные версии образов. Также был скрипт, который по соглашениям внутри команды назывался runner.py. Он отвечал за всю логику работы сервиса от начала до конца: за обработку входного задания, подгрузку данных, обучение или подтягивание готовой модели, за сохранение результатов и отправку метрик качества.
Для этого пришлось «изобрести велосипед». Речь идет про обертку, которая позволяет асинхронно запускать расчеты по REST API. Airflow отправляет POST-запрос с JSON-заданием на обработку, получает в ответ id запуска и по нему может отслеживать статус выполнения задачи.
Все это происходит в docker-контейнере. Метрики качества моделей попадают на дашборды с настроенными порогами. Если метрики выходят за границу допустимых порогов, происходит оповещение. Команда эксплуатации следит за работоспособностью конвейеров данных и может по этим дашбордам отслеживать качество производимых данных.
Есть еще внутренние дашборды на Kibana, они побогаче. Помимо графиков, отображается информация про каждый запуск сервиса: когда стартовал, когда завершил работу, с каким статусом, какая версия кода крутится на проде и пр. Логи из Elasticsearch также подтягиваются на эти дашборды.
Хочется также отметить возможность разработки в удаленных контейнерах Visual Studio Code. Контейнер поднимается в удаленной среде на сервере в условиях, максимально приближенных к проду. Так мы можем быстрее релизить наработки на прод без каких-либо изменений. Роль Visual Studio Code в том, что он делает удаленную разработку максимально эффективной.
Если разработка ведется на основе тестов, то как только появляется функция теста, с префиксом test_, Visual Studio Code ее обнаруживает и прямо над ней появляются кнопки отладки или запуска, что достаточно удобно. Как дополнительная и очень полезная опция: можно взять json-задание для сервиса с production. Затем подгрузить его и по шагам отлаживаться и разбираться, что произошло, если возникла проблема или просто хочется посмотреть, что происходило внутри сервиса.
Как устроен процесс релиза
Data scientist или ML-инженер ведет разработку в удаленном контейнере, коммитит свои изменения в GitLab. Мы используем GitLab CI. Когда он ставит тег на версию, запускается пайплайн CI, собирается образ и прогоняются тесты. В случае успешного прохождения пайплайна, появляется кнопка «Deploy to prod». По этой кнопке контейнер со свежим образом, соответствующим новому тегу, запускается в Kubernetes. У сервиса есть фиксированный адрес, который знает Airflow, и туда он отправляет задания для запуска расчетов.
Промежуточный итог
Первый момент. Сервис представляет собой монолит, в котором внутри может быть свой пайплайн из десятка шагов, несколько ML-моделей, с отсутствием observability. Снаружи это похоже на черный ящик: если ML-сервис упал, то только его разработчик может разобраться в причинах.
Сервер, который отвечает на запросы, также запускает и расчеты. Все это происходит в одном контейнере. То есть нарушается идеология «один контейнер — один процесс». Если процесс с логикой был завершен OOM-killer’ом, то очень сложно отловить такую проблему снаружи.
Второй момент. Чтобы не нарушить работу больших конвейеров Airflow, релизы нужно было проводить строго в определенное время. Так происходило потому, что за фиксированным URL сервиса всегда стоит какая-то одна конкретная версия кода, соответствующая тегу образа. Это немного затрудняло процесс релиза новых версий в прод.
Переход на Kubeflow
На этот момент Kubernetes в компании уже был развернут. Оставалось найти подходящее решение. Тогда в поле зрения попал Kubeflow.
Kubeflow инструмент не новый, про него достаточно сказано, поэтому я остановлюсь на двух моментах, которые имеют отношение непосредственно к нам.
Во-первых, это удобная среда для проведения экспериментов. Можно открыть соответствующую вкладку в UI, выбрать параметры: сколько CPU, сколько памяти, какой volume к нему примонтировать, какие дополнительные параметры указать. После этого нажать кнопку и запустится персональный jupyter-ноутбук дата-саентиста с ограничением по ресурсам.
У нас в компании есть RnD-команда, которая разрабатывает методологию решения задач интеграции различных панелей, и они предпочитают работать в R. Они, например, могут использовать ноутбуки с RStudio. Из коробки там также есть VSCode Online и возможность запуска каких-то кастомных образов. Это удобно, потому что так к jupyter-ноутбуку и VSCode Online можно добавить какие-то свои внутренние библиотеки. Просто указываем адрес образа в Artifactory, и ноутбук запускается сразу с нужными библиотеками.
Во-вторых, Kubeflow — это движок для запуска ML-пайплайнов, UI для управления ими и отслеживания статусов эксперимента. Каждый шаг пайплайна — отдельный под. Они независимы и никак не связаны друг с другом, только передают друг другу данные. Выходы одних шагов подаются на вход других.
Kubernetes развернут поверх облака, поэтому есть возможность легко масштабировать ресурсы. При необходимости можно подключать GPU к подам, если нужно что-то запустить на GPU.
Как это все это устроено архитектурно
Есть dev-среда, в который развернут Kubeflow для экспериментов. Здесь также, как и раньше, используется GitLab CI, но есть разница. Помимо образов в Artifactory улетают еще и сами пайплайны. Дальше в production-среде эти пайплайны попадают в Argo, и Airflow запускает Argo-workflow. Получается, что одновременно могут работать несколько версий, то есть в Argo находятся несколько версий пайплайна.
Как изменился процесс релиза
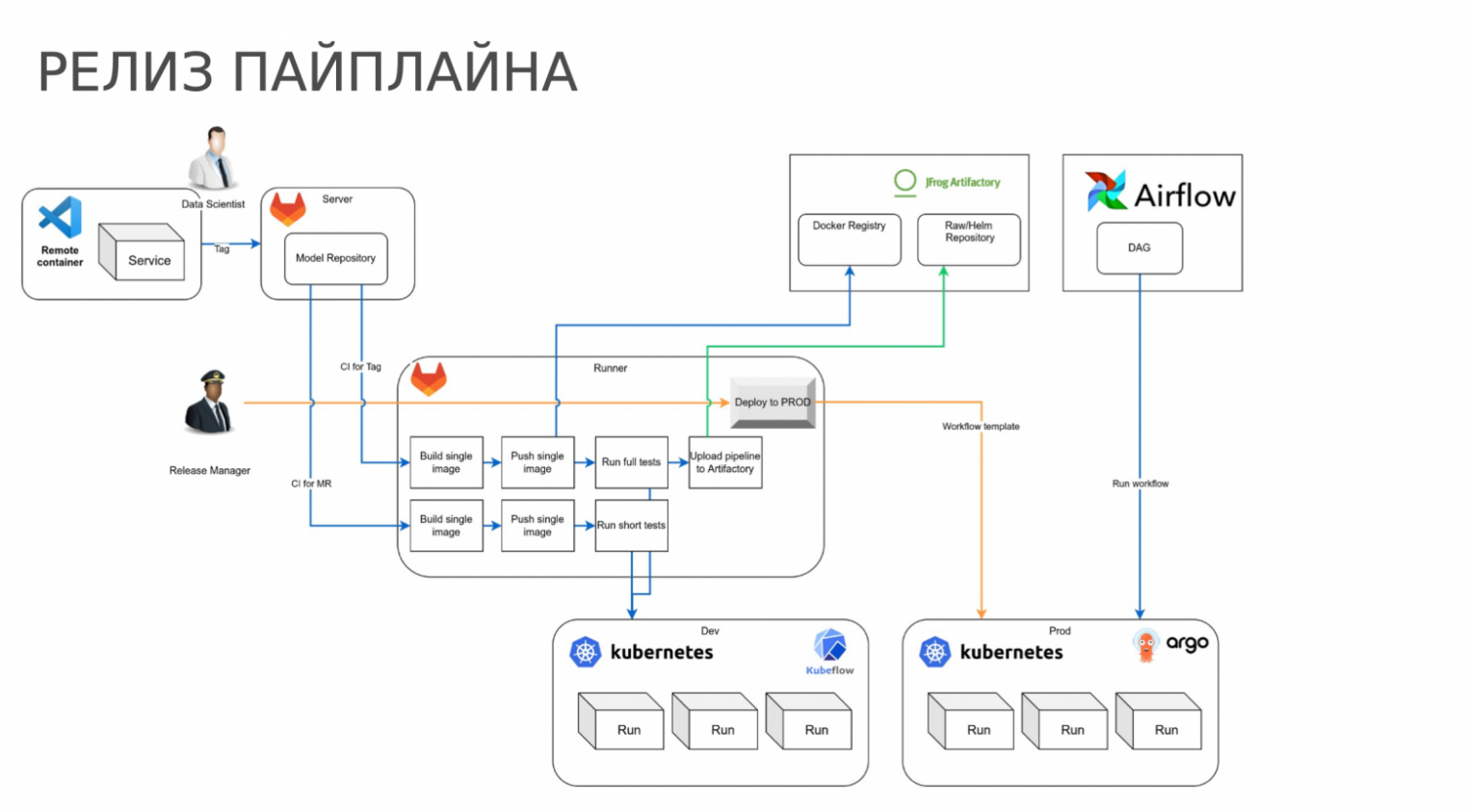
Сначала появилась вторая ветка CI для merge-requests. Когда создается merge request в master-ветку, то прогоняются короткие тесты, чтобы убедиться, что мы ничего не сломали. Если проставить тег, то происходит прогон полных тестов, весь пайплайн тестируется целиком. В случае успеха пайплайн в виде yaml-файла улетает в Artifactory. Также используется кнопка «Deploy to prod», но теперь при нажатии она скачивает соответствующий yaml-пайплайн из Artifactory и отправляет его в production Argo.
Airflow дальше может запускать версию, для которой состоялся релиз.
Преимущество такого подхода
Раньше ML-инженер отвечал за ручной релиз. То есть в релизное окно, чаще всего вечером, появлялась новая версия сервиса, и в целях проверки воспроизводимости больших конвейеров запускались тесты на них. Если что-то пошло не так, то ML-инженер должен был нажать на кнопку Deploy to prod предыдущей версии и таким образом все откатить.
Сейчас в Argo одновременно находятся несколько версий пайплайнов. Если что-то идет не по плану, есть возможность самостоятельного переключения на предыдущую версию со стороны эксплуатации без привлечения ML-инженеров.
Как устроены пайплайны
Получается, пайплайн — это последовательность логических шагов. В Kubeflow шаги создаются из компонентов.
Есть два способа создания компонентов:
- Создание прямо из python-функции, при этом она заворачивается в компонент Kubeflow.
- Создание из yaml-спецификации — вариант, который мы рассмотрим далее.
Как это было устроено? Был питоновский скрипт с командным интерфейсом, для которого вручную создавался yaml-файл. В нем указывался образ, какой модуль вызвать и какие входные и выходные параметры передать модулю. В Kubeflow параметры типизированы и типы InputPath и OutputPath имеют специальное значение.
Если мы указываем тип параметра OutputPath, то Kubeflow сам берет артефакт по указанному пути и сохраняет его в S3. Когда артефакт нужен другому шагу (указывается в качестве InputPath), он автоматически подгружает его из S3 и монтирует в под по определенному пути. Далее эти пути передаются как аргументы на вход скрипта, и скрипт может загрузить данные. То есть в этом случае обмен данными между шагами Kubeflow берет на себя.
Таким образом, все компоненты создавались из yaml-файлов. Далее из них как можно быстрее собирался работающий пайплайн с простой baseline-моделью внутри, чтобы там считались метрики. После этого уже усложняли модель и растили метрики. Пожалуй, сейчас это стандартный подход для всех.
Как выглядит теперь фрагмент реального пайплайна?
Сначала из yaml-файлов загружаются компоненты. Далее компоненты вызываются, на вход им передаются аргументы, и они превращаются уже в шаги. На вход шагам могут передаваться выходы других шагов.
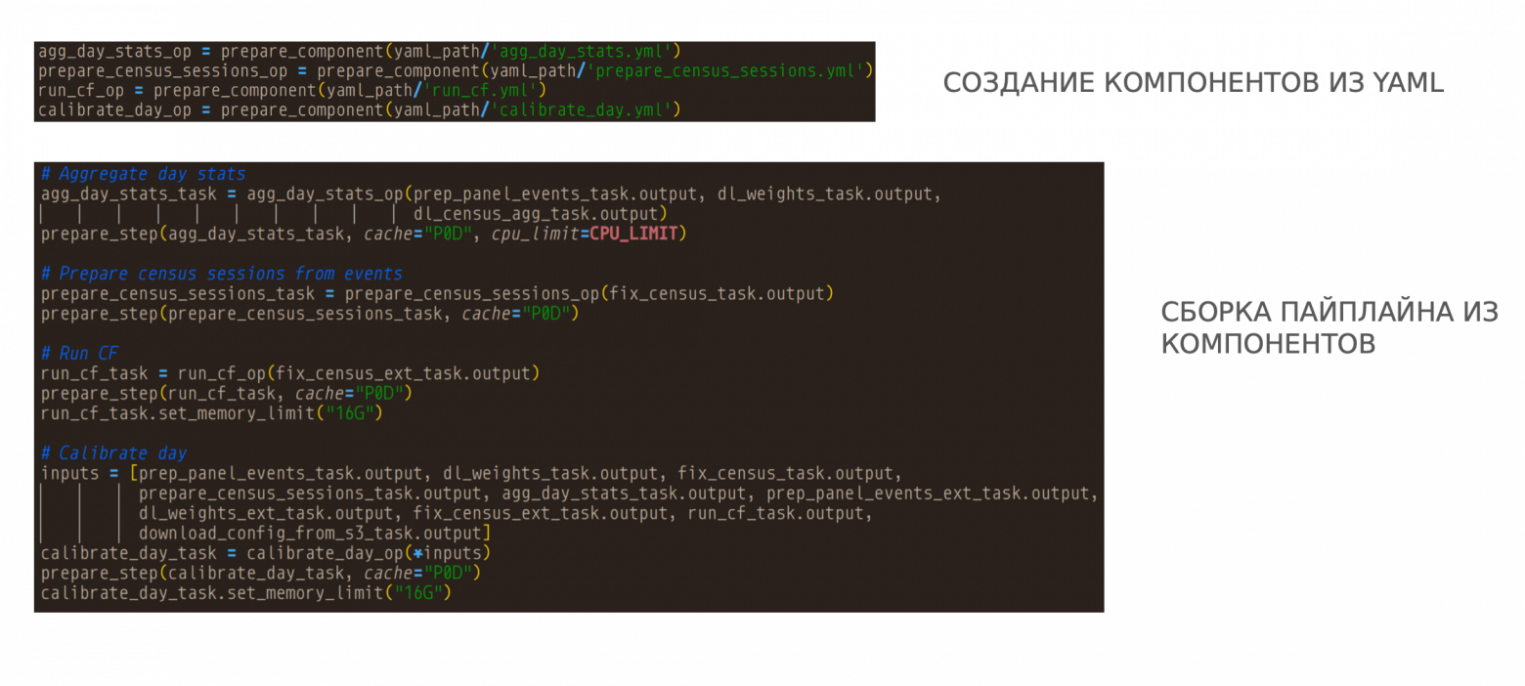
На основе этих зависимостей Kubeflow неявно понимает, как связать эти шаги в DAG. Если мы хотим поменять последовательность шагов, мы можем явно это указать. Для этого у шага есть атрибут .after.
Некоторым шагам может понадобиться сходить в HDFS за данными, для этого им нужно примонтировать соответствующие секреты. Или, например, может понадобиться указать режим кэширования или выставить лимиты по CPU и по памяти. Когда это делается прямо в коде пайплайна, он получается громоздким — создали шаг, а далее указываем множество модификаций, большая часть из которых достаточно типовые.
Что дало такое разделение, когда у нас шаги пайплайна в отдельных модулях?
Во-первых, так получается более правильный ход с точки зрения архитектуры. Каждый шаг реализует какую-то свою логическую задачу. В результате получается, что и сам пайплайн выглядит более наглядно. Если новый человек видит пайплайн, он сразу понимает, что там происходит, потому что логически все шаги отделены, и видно, как они выстроены.
Во-вторых, так можно параллелить разработку. Можно давать нескольким дата-саентистам в разработку разные параллельные компоненты. Также благодаря этому удобно покрывать компонент тестами и отлаживать компоненты по отдельности.
Первые впечатления от работы с Kubeflow
Самый первый вопрос — это как к вычислениям подтянуть данные? Самый простой способ — примонтировать туда persistent volume. Это по сути получается единая обменная папка для всех шагов. С точки зрения скорости работы, решение на первый взгляд выглядит как оптимальное. Как только шаг поднимается в виде пода, к нему сразу примонтированы данные для вычислений, и начинается работа.
При этом на практике наблюдались разные side-эффекты. Например, если CPU-шаги используют persistent volume, то они работают параллельно. Если для тех же шагов запросить использование GPU, то они работают строго последовательно, ждут друг друга, и параллельная обработка фактически не функционирует.
Также шаги, которые используют persistent volume, могут по неизвестной причине очень долго инициализироваться.
Это все, безусловно, можно решать на уровне инфраструктуры, но главный минус в том, что логика обработки получается опять непрозрачная. Почему так?
Есть большой пайплайн, в котором определенные шаги пишут данные в том, какие-то — читают из него. Нет ясности, что нужно для работы конкретным шагам.
Из минусов перехода
- После перехода на Kubeflow порог вхождения нового DS в проект не стал ниже.
- Между шагами постоянно происходит выгрузка данных на S3 и загрузка обратно. Казалось, это должно увеличивать время работы, но поскольку компоненты достаточно крупные, то этого overhead практически не заметно.
- Иногда нужно подключиться к поду для отладки, чтобы понять, что происходит внутри. Возможность такая есть, но пользоваться этим не очень удобно.
Как дорабатывали решение
Поработав с этим, у коллег появились идеи, как решить часть проблем. Конечно же, появился свой велосипед — обертка над Kubeflow. Что получилось в результате — при разработке и отладке пайплайна он выглядит как обычный скрипт на питоне.
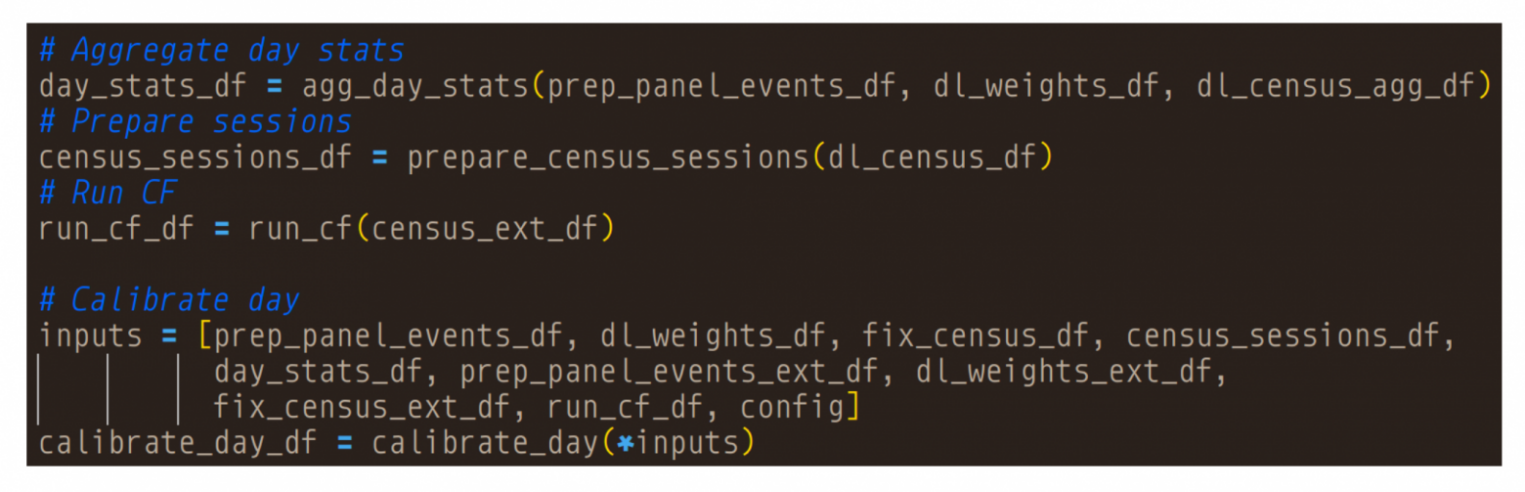
Как видно на иллюстрации, есть функции, которые принимают на вход pandas DataFrame и возвращают DataFrame. Все также есть возможность работать с Visual Studio Code в удаленном контейнере и отлаживать код локально.
В зависимости от настроек среды пайплайн может запускаться локально (в удаленном контейнере) или компилироваться в пайплайн Kubeflow, и это абсолютно прозрачно для пользователей.
За счет чего это достигается? Большая часть логики по монтированию секретов, настройке кэширования и т.д. была перенесена в специальный декоратор kubeflow_step. За счет аннотаций входов и выходов, при локальном запуске автоматически определяется — как сохранять результаты работы и как загружать входные аргументы в оперативную память. Для этого в нашей библиотеке kfrun появились свои кастомные типы. Это могут быть не только pandas DataFrame, а обученные модели, словари и другие объекты.
Если режим работы — компиляция в Kubeflow-пайплайн, то функция шага не запускается, а компилируется в yaml. Если раньше yaml составлялся вручную, то сейчас он создается автоматически.
Во-первых, это избавляет от лишней ручной работы. Во-вторых, при ручном создании yaml возникали ошибки, которые трудно обнаружить, а здесь все происходит автоматом по заданной спецификации функции.
Кейс на каждый день
Недавно возникла задача объединения нескольких источников данных. Нужно было объединить просмотр телевизора в TV-панели с просмотром того же телеэфира, но в интернете, когда смотрят телевизор с мобильных или десктопных устройств. Панели имеют некоторое пересечение, но все-таки разные. Если бы это была одна панель, никаких проблем бы не было. Мы просто сложили бы веса всех уникальных панелистов и получили бы оценку охвата аудитории. Но здесь получается сложный пайплайн и несколько точек, где можно выбрать различные опции. Например, как отбирать активных? У нас есть TV-панель и нужно выбрать определенное количество активных панелистов, которым мы перенесем эту активность, потому что активны не все каждый день, а лишь небольшой процент. Здесь своя опция для модели.
Как переносить активность? Нужно не просто перенести, а сохраняя исходное распределение социально-демографических переменных. Тут есть свои опции, как переносить. И это не разовая операция, а конвейер, который работает день за днем. И здесь нужно учитывать историю предыдущих переносов, чтобы наши данные оставались консистентными на длительном периоде.
Сначала мы собрали пайплайн с baseline-моделью в каждой точке, а затем над задачей в параллель работало четыре дата-саентиста. Каждый из них в своей точке улучшал модель, глядя на финальные метрики. Каждому удалось улучшить — кому-то больше, кому-то меньше, но когда мы все эти улучшения собрали в итоговом пайплайне, то получили дополнительный прирост метрик.
Получился достаточно обширный пайплайн, который работает около получаса. Стоит отметить, что Kubeflow не подводит в этом месте и позволяет запускать сложные пайплайны без проблем.
Какими будут следующие шаги
Новая обертка существенно упростила разработку, но нам все еще есть куда развиваться.
- Сами авторы Kubeflow продвигают концепцию reusable components, чтобы компоненты были переиспользованы в разных пайплайнах. Пока эта концепция у нас широкого распространения не получила.
- Если мы хотим оптимизировать потребление ресурсов в облаке, то нам надо ставить лимиты для шагов по процессу и/или по памяти. Сейчас это происходит так, что все шаги по умолчанию занимают минимум ресурсов. Каким-то отдельным шагам, которые делают сложные вычисления, мы вручную наращиваем лимиты. Это не очень удобно делать руками, поэтому хотелось бы наладить процесс автоматизации.
- Мы хотим продолжать работать над тем, чтобы это был максимально удобный инструмент для разработки ML-пайплайнов.




