
Если регулярно читать статьи на тему MLOps, начинает формироваться определенное восприятие контекста. Так, авторы текстов в основном пишут про работу с тремя типами артефактов:
- данные,
- модель,
- код.
В целом, этого достаточно, чтобы объяснить суть MLOps. ML-команда должна создать кодовую базу, за счет которой будет реализован автоматизированный и повторяемый процесс:
- обучения на качественных датасетах новых версий ML-моделей,
- доставки обновленных версий моделей в конечные клиентские сервисы для обработки входящих запросов.
Теперь детализируем эти аспекты.
Данные
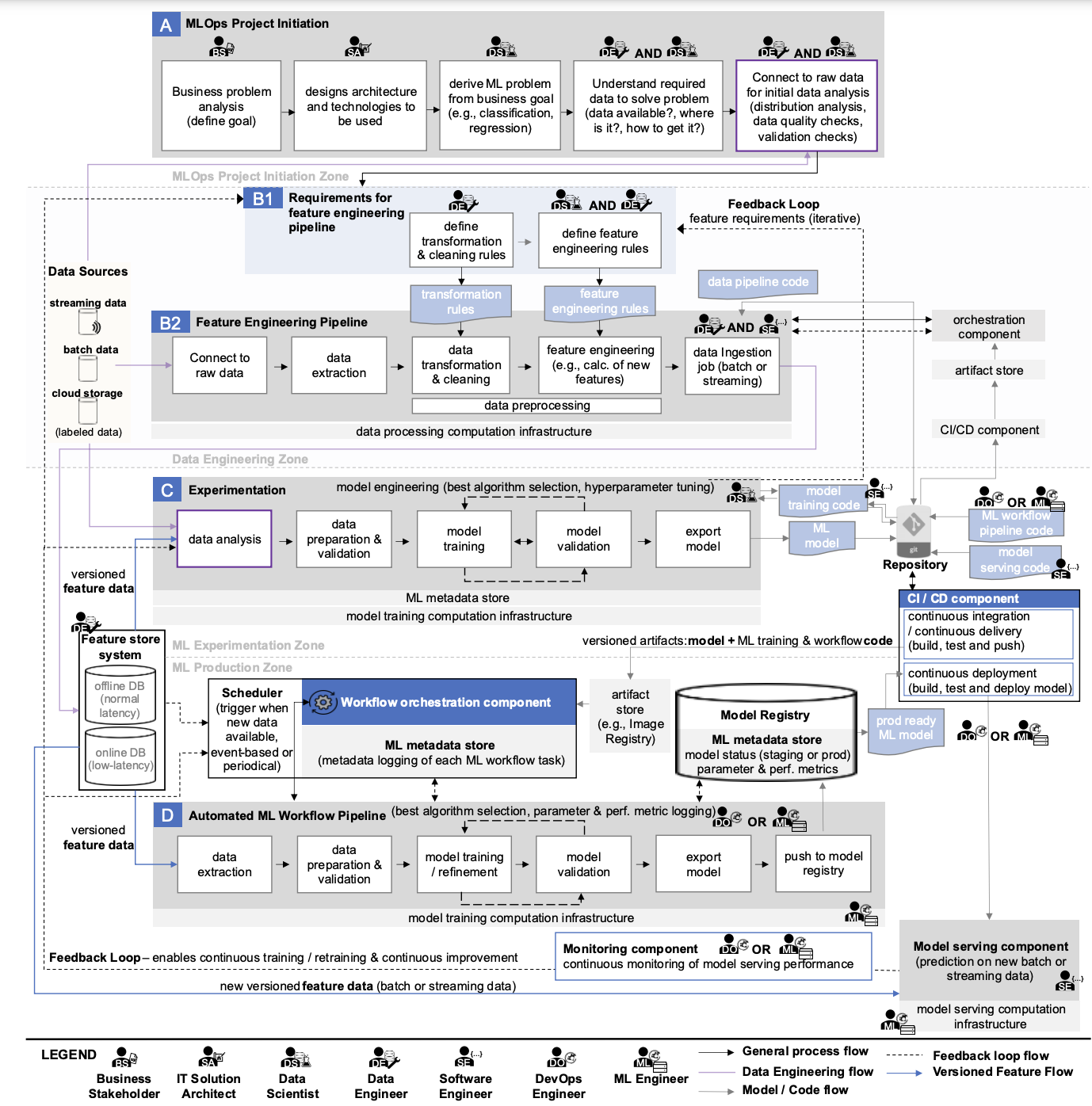
Если внимательно посмотреть на схему, которую мы подробно рассматривали в предыдущем тексте, то можно найти следующие «источники данных»:
- Streaming data,
- Batch data,
- Cloud data,
- Labeled data,
- Feature online DB,
- Feature offline DB.
Весьма спорно называть этот список источниками, но концептуальная задумка, кажется, ясна. Есть данные, которые хранятся в большом количестве систем и по-разному обрабатываются. Все они могут потребоваться для ML-модели.
Что делать, чтобы нужные данные попадали в ML-систему:
- использовать инструменты и процессы, которые позволят забирать данные из источников, формировать из них датасеты, расширять их новыми фичами, которые затем сохраняются в соответствующих базах для общего использования.
- внедрить инструменты мониторинга и контроля, потому что качество данных может меняться.
- добавить каталог, который упростит поиск по данным, если их стало много.
В итоге у компании может появиться полноценная Data Platform с ETL/ELT, шинами данных, объектными хранилищами и прочими Greenplum.
Ключевой аспект использования данных в рамках MLOps: автоматизация подготовки качественных датасетов для обучения ML-моделей.
Модель
Теперь поищем на схеме артефакты, имеющие отношение к ML моделям:
- ML model,
- Prod ready ML model,
- Model Registry,
- ML Metadata Store,
- Model Serving Component,
- Model Monitoring Component.
По аналогии с данными нужны инструменты, которые будут помогать:
- искать лучшие параметры ML-моделей за счет проведения множества экспериментов,
- сохранять лучшие модели и достаточное количество информации о них в специальные реестр (чтобы в дальнейшем можно было воспроизвести результат экспериментов),
- организовывать доставку лучших моделей в конечные клиентские сервисы,
- осуществлять мониторинг качества их работы, чтобы при необходимости автоматически запускать обучение новых моделей.
Ключевой аспект работы с моделями в рамках MLOps: автоматизация процесса переобучения моделей для достижения лучших качественных метрик их работы с клиентскими запросами.
Код
С кодом проще всего: он как раз автоматизирует процессы работы с данными и моделями.
На нашей схеме можно найти упоминание:
- data transformation rules,
- feature engineering rules,
- data pipeline code,
- model training code,
- ML workflow code,
- model serving code.
Можно только добавить infrastructure as a code (IaaC), с помощью которого поднимается вся необходимая инфраструктура.
Следует отметить, что иногда бывает дополнительный код для оркестрации, особенно если в команде используется несколько оркестраторов. Например, Airflow, который запускает DAG в Dagster.
Инфраструктура для MLOps
На схеме мы видим несколько типов используемой вычислительной инфраструктуры:
- data processing computational infrastructure,
- model training computational infrastructure,
- model serving computational infrastructure.
Причем последнее используется как для проведения экспериментов, так и для переобучения моделей в рамках автоматизированных пайплайнов. Такой подход возможен, если утилизация вычислительной инфраструктуры имеет запас для одновременного выполнения этих процессов.
На первых этапах все задачи можно решать в рамках одной инфраструктуры, но в дальнейшем потребность в новых мощностях будет расти. В частности, из-за специфических требований к конфигурациям вычислительных ресурсов:
- для обучения и переобучения моделей не обязательно использовать самые производительные GPU Tesla A100, можно выбрать вариант попроще — Tesla A30, также можно выбрать карты из линейки RTX A-Series (A2000, A4000, A5000).
- для Serving у Nvidia есть GPU Tesla A2, которая подойдет, если ваша модель и порция данных для обработки не превышают размер ее видеопамяти; если превысят, выбирайте из GPU в первом пункте;
- для обработки данных может вообще не понадобится видеокарта, так как этот процесс может быть построен на CPU; здесь, впрочем, выбор еще сложнее — можно рассмотреть AMD Epyc, Intel Xeon Gold или современные десктопные процессоры.
Сложности добавляет повсеместное распространение Kubernetes как инфраструктурной платформы для ML-систем. Все вычислительные ресурсы нужно уметь использовать в k8s.
Получается, большая схема про MLOps — лишь верхний уровень абстракции, с которым приходится иметь дело.
Reasonable и Medium Scale MLOps
После рассмотрения настолько обширной схемы и озвученных артефактов пропадает желание что-то подобное строить в собственной компании. Нужно выбрать и внедрить множество инструментов, подготовить необходимую для них инфраструктуру, научить команду со всем этим работать, а еще и поддерживать все вышеперечисленное.
В этом деле главное — начать. Не стоит внедрять сразу все компоненты MLOps, если в них нет бизнес-потребности. Руководствуясь моделями зрелости, можно создать базу, вокруг которой в дальнейшем будет развиваться ML-платформа.
Вполне вероятно, что для достижений бизнес-целей многие компоненты никогда и не понадобятся. Эта мысль уже активно продвигается в различных статьях про reasonable и medium scale MLOps.
Разница между MLOps и ModelOps
В завершение упомянем и ModelOps. Это он часть MLOps или это MLOps часть ModelOps? Вот статья, которая отлично отвечает на этот вопрос. Вообще The MLOps Blog от neptune.ai стоит регулярно читать — иногда там публикуют неплохие статьи.
В следующем тексте мы рассмотрим MLOps как информационную систему.




