Что такое MLOps? Теоретический аспект
Подробно разбираем концепцию MLOps через самую полную, на наш взгляд, схему.
В этом материале мы подробно разбираем концепцию MLOps и «жизненный цикл» работ с ML-моделями через самую полную, на наш взгляд, схему.
Что такое MLOps?
Этот вопрос давно занимает умы многих команд разработки ML-систем. Под такой системой в этой статье мы будем понимать информационную систему, один или несколько компонентов которой содержат в себе обученную модель, выполняющую какую-то часть общей бизнес-логики.
Эту часть бизнес-логики, как и любые другие компоненты системы, необходимо обновлять, чтобы соответствовать меняющимся ожиданиям бизнеса и клиентов. В этом обновлении, причем регулярном, и заключается MLOps.
Определение и его пояснение
Единого и согласованного определения MLOps пока не существует. Многие авторы пытались его дать, но одновременно понятное и системное определение найти очень сложно.
Есть одно, которое можно таким считать. Чтобы не исказить смысл, приводим его на языке оригинала.
MLOps is an engineering discipline that aims to unify ML systems development(dev) and ML systems deployment(ops) to standardize and streamline the continuous delivery of high-performing models in production.
Выделим ключевые части определения MLOps:
- инженерная дисциплина,
- направлена на унификацию процессов разработки и развертывания ML-систем,
- для стандартизации и оптимизации непрерывной поставки новых версий,
- высокопроизводительные модели.
Получается, что MLOps — это своего рода DevOps для ML-моделей.
История появления MLOps
Легко поверить, что подобная инженерная дисциплина зародилась в недрах большой IT-компании. Так что можно довериться версии, что MLOps как осмысленный подход зародился в Google, где Д. Скалли (D. Sculley) пытался спасти свои нервы и время от рутинных задач вокруг вывода моделей машинного обучения в прод. Теперь Скалли широко известен как «The Godfather of MLOps» — одноименный подкаст легко найти в интернете.
Д. Скалли начал рассматривать работу с моделями с точки зрения технического долга команды. Да, можно быстро выпускать новые версии моделей, но стоимость поддержки получившейся системы будет сильно сказываться на бюджете компании.
Результатом его работы стала статья «Hidden Technical Debt in Machine Learning Systems», которая вышла в 2015 году на конференции NeurIPS. Именно дату публикации этой статьи можно считать точкой отсчета существования MLOps.
Уровни зрелости MLOps: самые известные модели
Как и у большинства IT-процессов, в системе MLOps есть уровни зрелости. Они помогают компаниям понять, на каком этапе развития они находятся сейчас и, что изменить в ML-подходах, чтобы перейти на следующий уровень (если есть такая цель). Также использование общепринятых методик определения зрелости позволяет определить свое место среди конкурентов.
Модель GigaOm
Одна из самых подробно описанных и во многом понятных моделей — от аналитической фирмы GigaOm. Из всех моделей она больше всего приближена к Capability Maturity Model Integration (CMMI). Это набор методологий совершенствования процессов в организациях, который также состоит из пяти уровней — от 0 до 4.
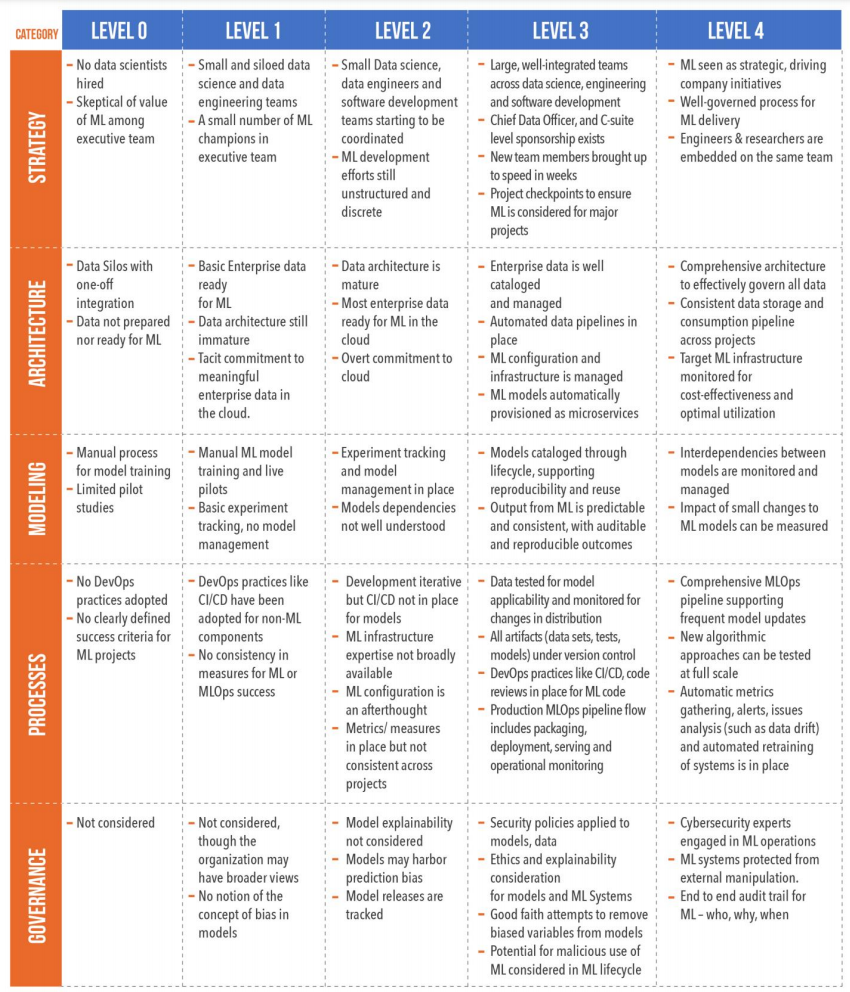
В модели от GigaOm каждый уровень зрелости расписывается через пять категорий: стратегия, архитектура, моделирование, процессы и управление.
Руководствуясь этой моделью на ранних этапах разработки и внедрения ML-системы, можно заранее обдумать важные аспекты и уменьшить шансы на неудачу. Фактически переход с одного уровня зрелости на более высокий ставит перед командой новые задачи, о существовании которых она раньше могла и не подозревать.
Модель Google
В Google также есть своя модель уровней зрелости MLOps. Она появилась одной из первых, лаконична и состоит из трех уровней:
- level 0: Manual process,
- level 1: ML pipeline automation,
- level 2: CI/CD pipeline automation
Сложно отделаться от мысли, что эта модель напоминает инструкцию по рисованию совы. Сначала делайте все руками, потом соберите ML-пайплайн, а потом доавтоматизируйте MLOps. При этом она действительно хорошо описана.
Модель Azure
На сегодняшний день многие крупные компании, использующие ML, составили собственные модели зрелости. Не осталась в стороне и Azure, которая использует схожий подход выделения уровней. Их, впрочем, больше, чем у Google:
- level 0: No MLOps,
- level 1: DevOps but no MLOps,
- level 2: Automated Training,
- level 3: Automated Model Deployment.
- level 4: Full MLOps Automated Operations.
Все выделенные модели сходятся примерно в одном: на нулевом уровне у них — отсутствие каких бы то ни было ML-практик, а на последнем — автоматизация MLOps-операций. В центре всегда что-то свое, что так или иначе связано с постепенной автоматизацией операций машинного обучения. У Azure это автоматизация процесса обучения, а потом и деплоя моделей.
Концептуальная схема MLOps с перечислением всех операций машинного обучения
Как описать все процессы, связанные с понятием MLOps? Удивительно, но трем немцам — авторам статьи «Machine Learning Operations (MLOps):Overview, Definition, and Architecture» — удалось даже заключить их в одну схему. Они провели настоящее исследование и описали концепцию MLOps очень подробно.
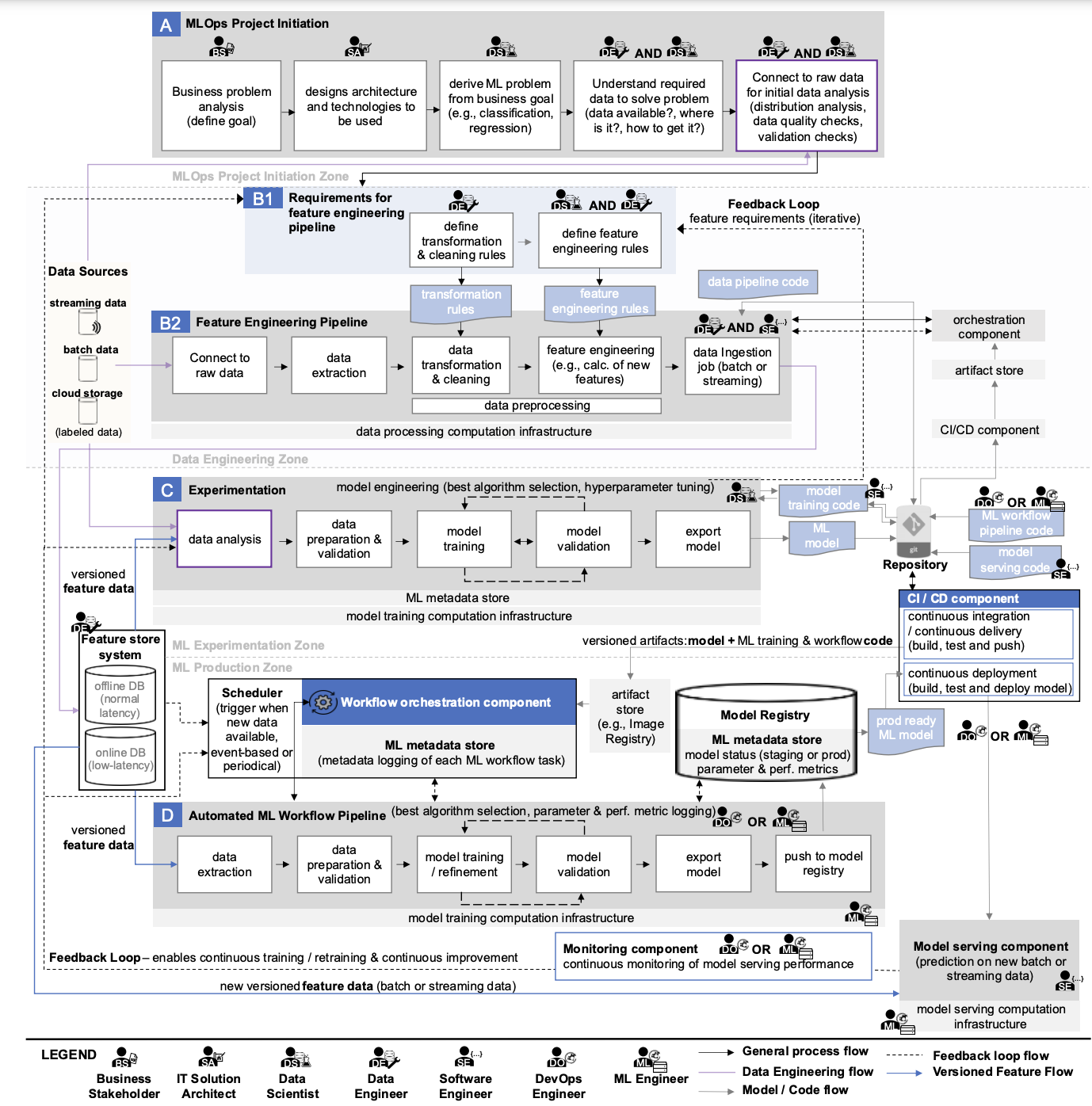
При первом знакомстве она может пугать — на ней много элементов, взаимодействующих друг с другом. При этом на ней можно найти многие характеристики упомянутых уровней зрелости. Как минимум автоматизированные пайплайны, CI/CD, Monitoring, Model Registry, Workflow Orchestration и Serving Component.
Теперь попробуем разобрать по кусочкам эту схему и рассказать о каждом более подробно.
Основные процессы MLOps
Главными частями схемы являются горизонтальные блоки, внутри которых описаны процедурные аспекты MLOps (им присвоены буквы А, B, С, D). Каждый из них предназначен для решения конкретных задач в рамках обеспечения бесперебойной работы ML-сервисов компании. Для простоты понимания схемы лучше начать не по порядку.
Experimentation, или процесс проведения экспериментов
Если в компании есть ML-сервисы, то есть и сотрудники, работающие в Jupyter. Во многих компаниях именно в этом инструменте сосредоточены все процессы по ML-разработке. Отсюда начинается большинство задач, для решения которых необходимо внедрять MLOps-практики.
Пример. В компании А появилась потребность в автоматизации части какого-то процесса при помощи машинного обучения (допустим, соответствующий отдел и специалисты есть). Маловероятно, что способ решения поставленной задачи известен заранее. Следовательно, исполнителям нужно изучить постановку задачи и провести тестирование возможных способов ее реализации.
Для этого ML-инженер/ML-разработчик пишет код различных реализаций задачи и оценивает полученные результаты по целевым метрикам. Все это практически всегда делается в Jupyter Lab. В таком виде необходимо очень много важной информации фиксировать вручную, а потом еще и сравнивать реализации между собой.
Подобная деятельность называется экспериментированием. Ее смысл состоит в получении работающей ML-модели, которую в дальнейшем можно использовать для решения соответствующих задач.
Представленный на схеме блок С описывает процесс проведения ML-экспериментов.
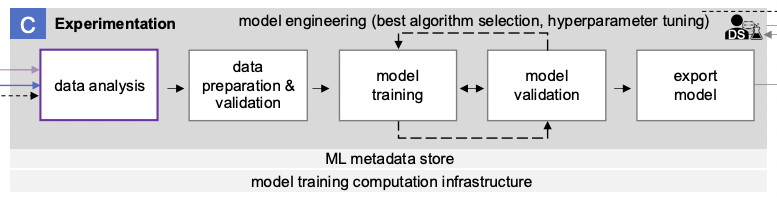
В его состав входят следующие этапы:
- data analysis,
- data preparation and validation,
- model training,
- model validation,
- model export.
Анализ данных, имеющихся в рамках задачи
Многие решения в рамках ML-разработки принимаются исходя из анализа имеющихся в компании данных (не обязательно big data). Не получится обучить модель с целевыми метриками качества на данных низкого качества или данных, которых нет.
Поэтому важно разобраться, какие данные нам достались и что с ними можно делать. Для этого, например, можно:
— провести ADHoc-исследование с помощью Jupyter или Superset
— стандартный EDA (Exploratory Data Analysis).
Лучшее понимание данных можно получить только в купе с семантическим и структурным анализом.
Не всегда, впрочем, подготовка данных находится в зоне влияния команды проекта — в таком случае дополнительные сложности обеспечены. Иногда на этом этапе становится понятно, что развивать проект дальше не имеет смысла, так как данные не пригодны для работы.
Формирование качественного датасета
Когда появилась уверенность в имеющихся данных, необходимо продумать правила их предобработки. Даже если есть большой набор подходящих данных, нет гарантии, что в нем нет пропусков, искаженных значений и т.д. Здесь в пору упомянуть термин «качество входных данных» и известную фразу «Garbage in — garbage out».
Какая бы хорошая модель не использовалась, на данных низкого качества даже она будет давать низкие результаты. На практике много ресурсов проекта уходит именно на формирование качественного набора данных — датасета.
Обучение и валидация ML-модели
После предыдущего этапа имеет смысл принимать в расчет метрики обучаемой модели при проведении экспериментов. В рамках рассматриваемого блока эксперимент заключается в связке обучения и валидации ML-модели.
Фактически эксперимент заключается в классической схеме обучения желаемой версии модели с выбранным набором гиперпараметров на подготовленном датасете. Для этого сам датасет делится на обучающую, тестовую и валидационную выборки:
— на первых двух подбирается оптимальный набор гиперпараметров,
— не третьей проводится финальная проверка и получается подтверждение, что модель, обученная на выбранном наборе гиперпараметров, адекватно себя ведет на неизвестных данных, которые не участвовали в процессе подбора гиперпараметров и обучения. Чуть подробнее об этом можно почитать в этой статье.
Сохранение кода и гиперпараметров в репозитории
Если метрики обучения модели признаны хорошими, то код модели и подобранные параметры сохраняются в корпоративном репозитории.
Ключевая цель процесса экспериментирования — model engineering, что подразумевает выбор наилучшего алгоритма реализации задачи (best algorithm selection) и подбор наилучших гиперпараметров модели (hyperparameter tuning).
Сложность проведения экспериментов — в том, что разработчику необходимо проверить огромное количество комбинаций параметров работы ML-модели. И это мы не говорим про различные варианты используемого математического аппарата.
В общем, это непросто. И что делать, если в рамках перебора комбинаций параметров модели не удалось добиться желаемых метрик?
Feature engineering, или разработка фичей
Если желаемых метрик работы ML-модели достичь не удалось, можно попробовать расширить признаковое описание объектов датасета новыми признаками (фичами). За счет них контекст для модели расширится, а значит, могут улучшиться искомые метрики.
В качестве новых фичей могут выступать:
- для табличных данных: произвольные преобразования уже существующих признаков объектов — например, X^2, SQRT(X), Log(x), X1*X2 и др.,
- исходя из предметной области: индекс массы тела, количество просроченных платежей по кредиту за год, оценка фильма на Кинопоиск и др.
Страждущие могут изучить хорошую книгу на тему работы с признаками.
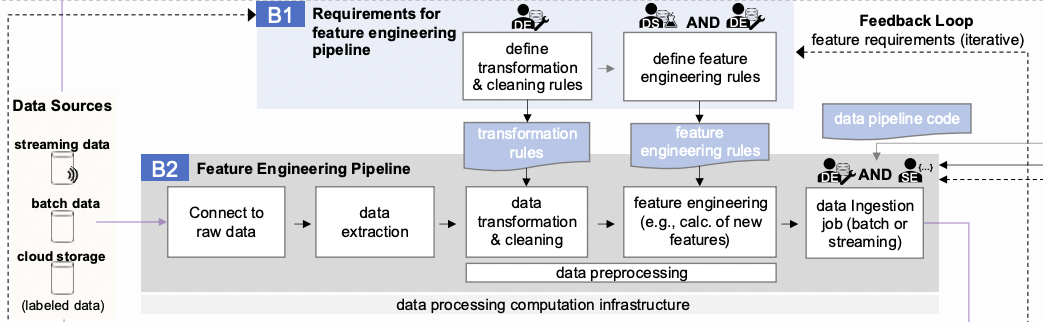
Посмотрим на часть схемы, которая относится к Feature engineering.
Блок B1 направлен на формирование набора требований к преобразованию имеющихся исходных данных и получение из них фичей. Причем расчет самих фичей происходит из этих самых предобработанных и очищенных данных по тем «формулам», которые ввел ML-разработчик.
Важно сказать, что процесс работы с признаками итеративный. Применяя один набор признаков, в голову может прийти новая идея, которая реализуется в другом наборе признаков, и так до бесконечности. Это явно показано на схеме в виде цикла обратной связи Feedback Loop.
Непосредственно процесс добавления новых фичей в данные описывается блоком B2 и включает в себя:
- connect to raw data.
- data extraction,
- data transformation and cleaning,
- feature engineering,
- data ingestion.
Подключение к источникам данных и их извлечение — технические операции, которые могут доставить достаточно сложностей. Для простоты объяснения будем считать, что есть несколько источников, к которым у команды есть доступ, и инструменты выгрузки данных из этих источников (хотя бы Python-скрипты).
Очистка и преобразование данных. Этот этап практически полностью перекликается с аналогичным шагом в блоке проведения экспериментов (С) — data preparation. По сути, уже на этапе первых экспериментов появляется понимание, какие данные и в каком формате нужны для обучения ML-моделей. Остается только правильно генерировать и проверять новые фичи, но сам процесс подготовки данных для этого хочется максимально автоматизировать.
Вычисление новых фичей. Как было замечено выше, эти действия могут состоять в простом преобразовании нескольких элементов кортежа данных. Другой вариант — запуск отдельного большого pipeline обработки для добавления одной фичи в тот же кортеж. В любом случае, есть набор действий, которые последовательно выполняются.
Добавление результата. Итог выполнения предыдущих действий добавляется к датасету. Чаще всего фичи добавляются в датасет порциями (batch), чтобы уменьшить нагрузку на базы. Но иногда необходимо делать это на лету (streaming), чтобы ускорить выполнение бизнес-задач.
Полученные фичи важно использовать максимально эффективно: сохранять и переиспользовать в задачах других ML-разработчиков компании. Для этого в схеме есть Feature store. По-хорошему, он должен быть доступен внутри компании, отдельно администрироваться и версионировать все попадающие в него фичи. В самом Feature store есть две части: online (для streaming-сценариев) и offline (для batch-сценариев).
Немногие захотят каждый раз проделывать это все руками, тем более все действия выглядят достаточно легко автоматизируемыми.
Automated Machine Learning Workflow
В начале статьи мы указали, что под ML-системой в данной статье мы подразумеваем информационную систему, один или несколько компонентов которой содержат в себе обученную модель, выполняющую какую-то часть общей бизнес-логики. Чем лучше полученная в результате разработки ML-модель, тем больше эффект от ее работы. Обученная модель обрабатывает входящий поток запросов и предоставляет в ответ какие-то предсказания, автоматизируя этим какую-то часть процесса анализа или принятия решений.
Процесс использования модели для генерации предсказаний называется inference, а процесс обучения модели — training. Наглядное пояснение разницы между ними можно позаимствовать у Gartner — здесь потренируемся на кошках.
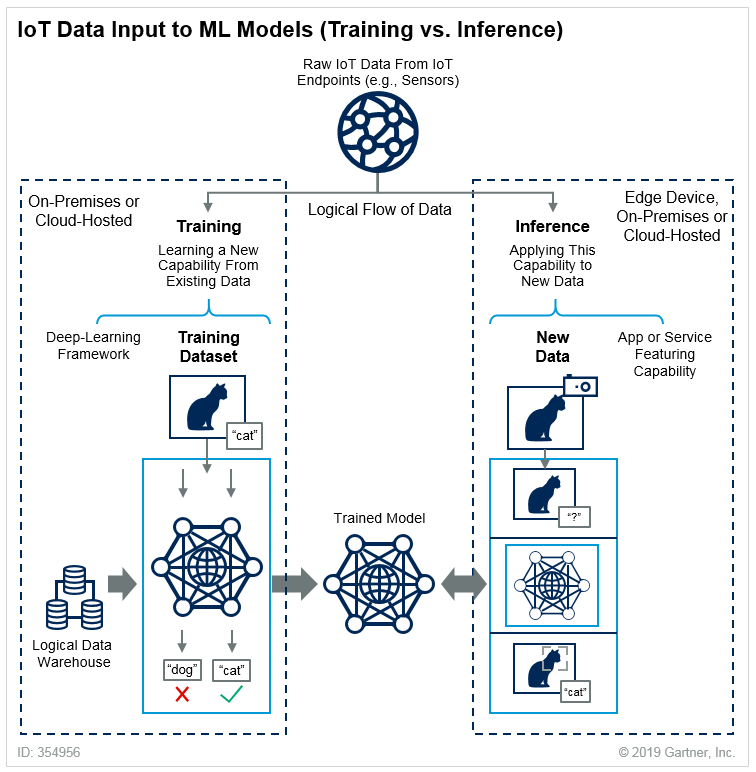
Для эффективной работы production ML-системы важно следить за inference-метриками модели. Как только они начинают проседать, модель нужно либо дообучить, либо заменить новой. Чаще всего это происходит из-за изменения входных данных (data drift). Например, есть бизнес-задача, в которой модель умеет распознавать хлеб на фотографиях, а ей на вход подается такое. Песики в примере — для баланса:

Модель в первоначальном датасете ничего не знала про корги, поэтому предсказывает некорректно. Значит, нужно изменить датасет и провести новые эксперименты. При этом новая модель должна оказаться в production как можно скорее. Пользователям никто не запрещает загружать изображения корги, а результат они будут получать ошибочный.
К слову, это не самый выдуманный сценарий. Есть реальная отсылка в кинематографе:

Теперь к более реальным примерам: рассмотрим рекомендательную систему маркетплейса.
Основываясь на истории покупок пользователя, покупок пользователей, схожих с целевым, и другим параметрам, модель или ансамбль моделей генерируют блок с рекомендациями. В нем — товары, выручка от покупки которых регулярно считается и отслеживается.
Что-то происходит и потребности покупателей меняются. Следовательно, рекомендации для них перестают быть актуальными и спрос на рекомендуемые товары падает. Все это приводит к снижению выручки.
Дальше — крики менеджеров и требования восстановить все к завтрашнему дню, которые ни к чему не приводят. Почему? Недостаточно данных о новых предпочтениях покупателей, поэтому даже новую модель не сделаешь. Можно, конечно, взять какой-нибудь базовый алгоритм генерации рекомендации (item based collaborative filtering) и добавить в production. Так рекомендации будут хоть как-то работать, но это лишь временный «костыль».
Получается, в идеале процесс должен быть выстроен так, чтобы без указки менеджеров, на основании метрик, запускался процесс переобучения или экспериментирования с разными моделями. А лучшая в итоге замещала текущую в production. На схеме это Automated ML Workflow Pipeline (блок D), который запускается по триггерам в каком-либо инструменте оркестрации.
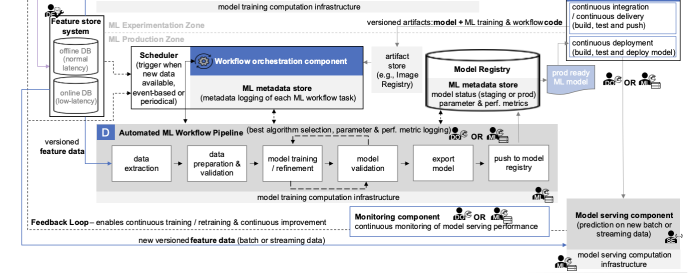
Это, пожалуй, самый нагруженный участок схемы. В работе блока D участвуют сразу несколько ключевых сторонних компонентов:
- Workflow orchestrator component, отвечающий за запуск пайплайна по заданному расписанию или событию,
- Feature Store, из которого берутся данные по необходимым для модели фичам,
- Model Registry и ML metadata store, куда помещаются модели и их метрики, полученные по завершении работы запущенного пайплайна.
Структура самого блока, по сути, совмещает в себе этапы блоков экспериментирования (C) и разработки фичей (B2). Неудивительно, учитывая что именно эти процессы нужно автоматизировать. Основные отличия в двух последних этапах:
- export model,
- push to model registry.
Остальные этапы идентичны описанным выше.
Отдельно отметим служебные артефакты, которые требуются оркестратору для запуска пайплайнов переобучения моделей. Фактически это код, который хранится в репозитории и запускается на выбранных серверах. Он версионируется и модернизируется по всем правилам разработки программного обеспечения. Именно этот код является реализацией пайплайна переобучения моделей и от его корректности зависит результат.
Чаще всего, в рамках кода запускаются различные ML-инструменты, внутри которых происходит выполнение этапов пайплайна, например:
- оркестратор Airflow запускает код выполнения этапов пайплайна,
- Feast по команде выгружает данные о имеющихся в датасете фичах,
- дальше ClearML формирует новый датасет и запускает эксперимент с необходимым набором параметров работы модели, которую он забирает из собственного репозитория,
- после завершения эксперимента ClearML сохраняет модель и метрики ее работы в репозиторий.
Тут стоит отметить, что автоматизировать эксперименты в общем случае невозможно. Можно, конечно, добавить в процесс концепцию AutoML, но на сегодняшний день нет признанного решения, которое можно было бы использовать с одинаковыми результатами для любой тематики эксперимента.
В общем случае AutoML работает так:
- Каким-то образом формирует набор из множества комбинаций параметров работы модели.
- Запускает эксперимент для каждой получившейся комбинации.
- Фиксирует метрики для каждого эксперимента, на основании которых выбирается лучшая модель.
По сути, AutoML проделывает все те манипуляции, которые проделывал бы условный Junior/Middle Data Scientist в кругу более-менее стандартных задач.
С автоматизацией немного разобрались. Далее необходимо организовать доставку новой версии модели в production.
Serving и мониторинг моделей машинного обучения
От ML-модели в проде требуется генерация предсказаний. Но сама ML-модель представляет собой файл, который так просто генерировать их не заставить. В интернете часто можно найти такое решение: команда берет FastAPI и пишет на Python обвязку вокруг модели, чтобы «можно было за предиктами ходить».
Если добавить деталей, то с момента получения файла с ML-моделью есть несколько вариантов развития событий. Команда может пойти:
- написать весь код для поднятия RESTfull-сервиса,
- реализовать всю обвязку вокруг него,
- собрать все это в Docker-образ,
- где-то потом из этого образа поднять контейнер,
- как-то его смасштабировать,
- организовать сбор метрик,
- настроить алертинг,
- настроить правила, по которым будут выкатываться новые версии модели,
- много еще чего.
Делать так для всех моделей, еще и поддерживая в дальнейшем всю кодовую базу, — задача трудоемкая. Чтобы ее облегчить, появились специальные serving-инструменты, которые ввели в обиход три новых сущности:
- Inference Instance/Service,
- Inference Server,
- Serving Engine.
Inference Instance, или Inference Service, представляет собой конкретную ML-модель, подготовленную для получения запросов и генерации ответных предсказаний. Фактически такая сущность может представлять собой под в кластере Kubernetes, в котором есть контейнер с необходимой ML-моделью и технической оснасткой для ее работы.
Inference Server является создателем Inference Instances/Services. Существует множество реализаций Inference Server. Каждая может работать с определенными ML-фреймворками, преобразуя обученные в них модели в готовые — для обработки входных запросов и генерации предсказаний.
Serving Engine выполняет главные управленческие функции. От него зависит, какой Inference Server будет задействован, сколько копий полученного Inference Instance нужно запустить и каким образом выполнять их масштабирование.
В рамках рассматриваемой схемы такой детализации компонентов model serving нет, но обозначены схожие аспекты:
- компонент CI/CD, который занимается развертыванием готовых для работы в проде моделей (можно считать его одной из версий Serving Engine),
- Model Serving, который в рамках доступной ему инфраструктуры организует схему генерации предсказаний для ML-моделей, причем и для потокового, и для пакетного сценариев (можно считать его одной из версий Inference Server).
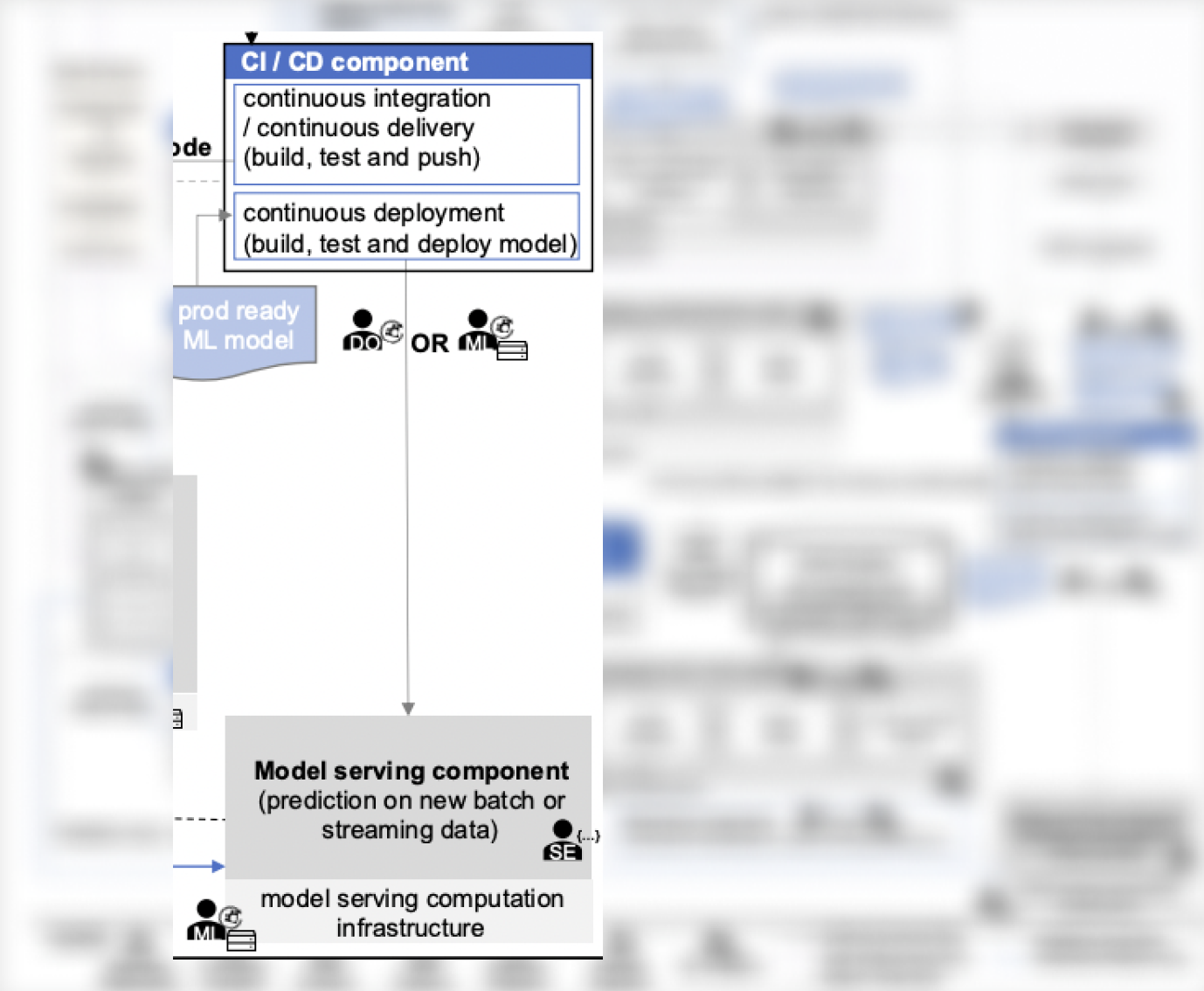
В качестве примера законченного стека для Serving можно ссылаться на стек от Seldon:
- Seldon Core является Serving Engine,
- Seldon ML Server является Inference Server, который подготавливает доступ к модели по REST или gRPC,
- Seldon MLServer Custom Runtime является Inference Instance — примером оболочки для любой ML-модели, экземпляр которой необходимо запустить для генерации предсказаний.
Существует даже стандартизированный протокол для реализации Serving, поддержка которого де-факто является обязательной во всех подобных инструментах. Он называется V2 Inference Protocol и разработан несколькими крупными игроками рынка — KServe, Seldon, Nvidia Triton.
Serving vs Deploy
В различных источниках можно встретить упоминание инструментов для «Serving and Deploy» как единого целого. Однако важно понимать разницу в назначении обоих. Это дискуссионный вопрос, но в этой статье будет так:
- Serving — про создание API модели и возможность получить от нее предсказания, то есть в итоге — получение единичного инстанса сервиса с моделью внутри.
- Deploy — распространение инстанса сервиса в нужном количестве для обработки входящих запросов (можно представлять replica set в деплойменте Kubernetes).
Существует множество стратегий, по которым можно осуществлять Deploy моделей, но это уже не ML-специфика. Платная версия Seldon, к слову, несколько из стратегий поддерживает, так что можно просто выбрать этот стек и наслаждаться тем, как все само собой работает.
Не стоит забывать, что метрики работы моделей должны отслеживаться, иначе не получится вовремя решать возникающие проблемы. Как именно отслеживать метрики — большой вопрос. Компания Arize AI на этом построила целый бизнес, но и Grafana с VictoriaMetrics никто не отменял.
Project initiation, или инициализация проекта
Учитывая все написанное выше, получается, что ML-команда:
- формирует датасеты,
- проводит на них эксперименты над ML-моделями,
- разрабатывает новые фичи для расширения датасетов и улучшения качества работы моделей,
- сохраняет лучшие модели в Model Registry для дальнейшего переиспользования,
- настраивает процессы Serving и Deploy моделей,
- настраивает мониторинг моделей в production и автоматический процесс дообучения текущей или создания новых моделей.
Выглядит очень дорого и не всегда оправданно. Поэтому на схеме существует отдельный блок MLOps Project Initiation (A), отвечающий за рациональное целеполагание.
В нем пять этапов:
- business problem analysis,
- designs architecture and technologies to be used,
- define ML problem from business goal,
- understand required data to solve problem,
- connect to raw data for initial data analysis.
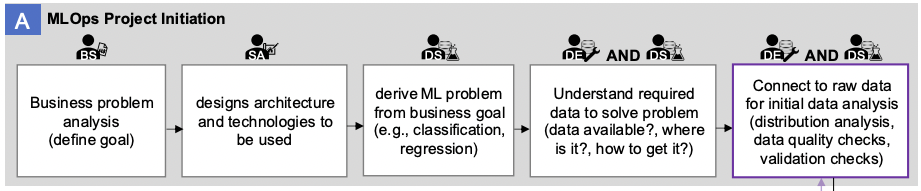
Ход мыслей тут можно продемонстрировать на примере рассуждений IT-директора в компании. К нему приходит вдохновленный менеджер проекта и просит новую инсталляцию платформы для построения ML-системы. Если оба действуют в интересах компании, от IT-директора последуют уточняющие вопросы:
- Какую проблему бизнеса вы собираетесь решать в рамках новой ML-системы?
- Почему вы решили, что эту проблему нужно решать новой ML-системой? Может, проще и дешевле изменить процессы или нанять больше людей в техническую поддержку?
- Где можно посмотреть сравнительный анализ компонентов ML-системы, на основании которого вы выбрали текущий набор?
- Как выбранная архитектура ML-системы поможет в решении проблемы бизнеса?
- А вы уверены, что в ML есть необходимый математический аппарат, чтобы решить обозначенную проблему? Какова постановка задачи для решения?
- Вы знаете, где будете брать данные для обучения моделей? А знаете, какие данные вам нужны для обучения моделей?
- Вы уже изучили имеющиеся данные? Качество данных достаточное для решения поставленной модели?
IT-директор валит, как препод в универе, зато сохранит деньги компании. Если ответить на все вопросы удалось, значит, необходимость в ML-системе реально есть.
Следующий вопрос: нужно ли делать в ней MLOps?
Зависит от задачи. Если нужно найти однократное решение, например, PoC (Proof of concept), то MLOps не нужен. Если важно обрабатывалось большое количество входящих запросов, то MLOps нужен. По сути, подход аналогичен оптимизации любого корпоративного процесса.
Чтобы обосновать необходимость MLOps перед руководством, нужно подготовить ответы на вопросы:
- что станет лучше,
- сколько денег сэкономим,
- нужно ли расширять штат,
- что нужно купить,
- где взять экспертизу.
А дальше снова сдавать экзамен IT-директору.
На этом сложности не закончатся, ведь команду тоже нужно убеждать в необходимости изменения процессов работы и стека технологий. Иногда это сложнее, чем выпросить бюджет у руководства.
Чтобы убедить команду, стоит подготовить ответы на вопросы:
- почему работать как раньше больше нельзя,
- какова цель изменений,
- какой будет стек технологий,
- чему и у кого учиться,
- как компания будет помогать в осуществлении изменений,
- за какой срок необходимо произвести изменения ML-подхода,
- что будет с теми, кто не успеет.
Заключение
Кажется, здесь мы закончили с подробным изучением схемы MLOps. Однако это только теоретические аспекты. Практическая реализация всегда выявляет дополнительные детали, которые могут изменить очень многое. Часть проблем с реализацией решит готовая MLOps-платформа — преднастроенная инфраструктура для обучения и развертывания ML-моделей.




