Как мы проводили sentiment-анализ комментариев в блоге Selectel на Хабре
В материале рассказываем, как развернули платформу аналитики на инфраструктуре Selectel и с ее помощью оценили тональность тысяч комментариев в нашем блоге на Хабре.

Каждый месяц в блоге Selectel на Хабре появляется 35-40 материалов. Сбор статистики по ним мы давно автоматизировали, но до последнего времени не охватывали sentiment-анализ, то есть оценку тональности комментариев средствами машинного обучения. При этом у нас есть своя ML-платформа, серверное железо и опыт в развертывании IT-инфраструктуры. Естественно, возник вопрос: а что, если проанализировать эмоциональный окрас комментариев в блоге на Хабре с помощью LLM?
Выбираем большую языковую модель
Sentiment-анализ в нашем случае — задача мультиклассовой классификации. Отправляемся на Hugging Face в раздел Models (отсюда с помощью библиотеки Transformers позже будем вытаскивать веса модели). Во вкладке Tasks выбираем «Text Classification», во вкладке Languages — «Russian», а в поле для ввода имени LLM пишем Sentiment. В результате получаем список моделей, которые, судя по названию и описанию, были файнтюнены специально на предварительно размеченных датасетах под определение эмоционального окраса текста.
Здесь нужно сделать оговорку. Если в обучающей выборке модели объект (текст, комментарий и т. д.) отнесен сразу к нескольким тегам, речь будет идти о мультилейбле, а не о мультиклассе (positive, neutral, negative). Это может быть полезно, если нам нужна не просто оценка эмоционального окраса, а выделение комментариев, авторы которых, например, одновременно пытаются оскорблять и запугивать.
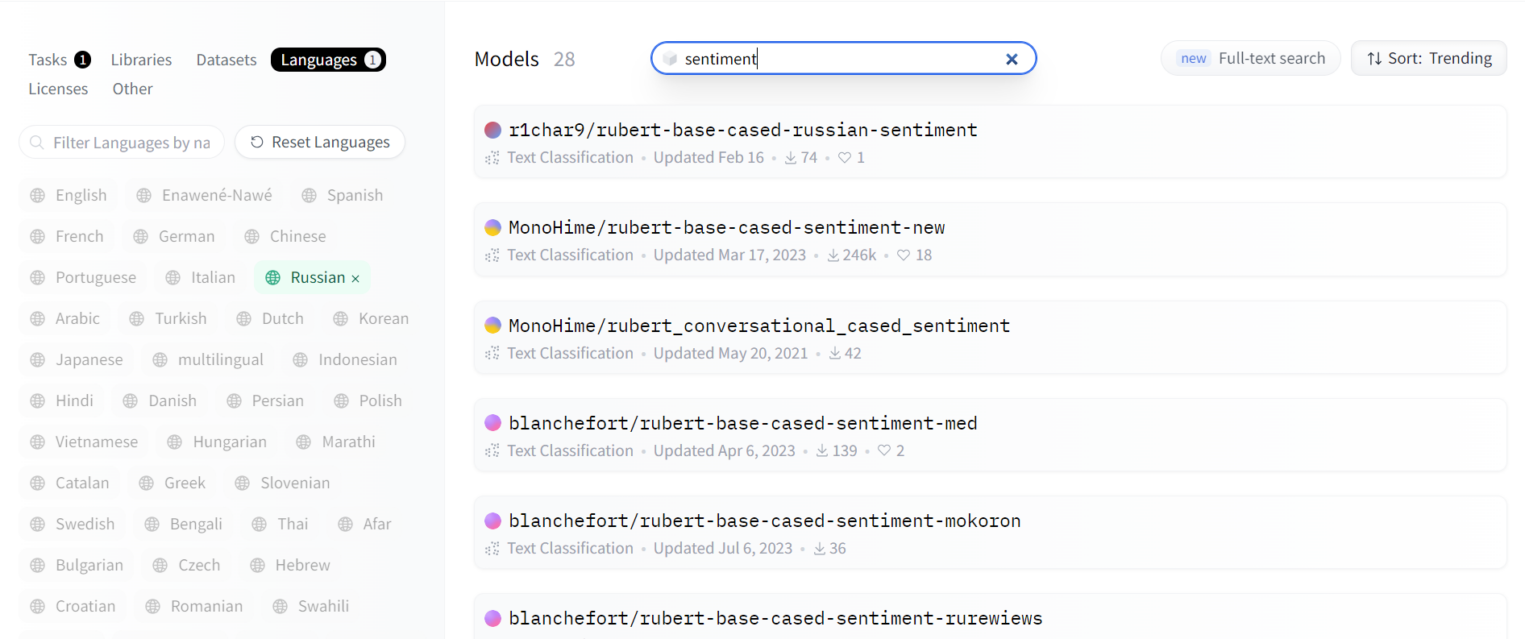
Большинство отсортированных LLM крутятся вокруг разных модификаций bert-моделей. Поверх строится пулинг-слой, а дальше это все сходится к нескольким классам. Мы протестировали разные модели и остановились на cointegrated/rubert-tiny-sentiment-balanced.
Вытаскиваем модель и токенайзер, кладем ее на CUDA Device и пишем небольшой кусочек кода. На самом деле мы берем готовый кусок кода из карточки модели и фиксим в нем одну строчку.
def get_sentiment_fixed(text, return_type='label'):
""" Calculate sentiment of a text. `return_type` can be 'label', 'score' or 'proba' """
with torch.no_grad():
inputs = tokenizer(text, return_tensors='pt', truncation=True, padding=True).to(model.device)
proba = torch.nn.functional.softmax(model(**inputs).logits, dim=1).cpu().numpy()[0]
if return_type == 'label':
return model.config.id2label[proba.argmax()]
elif return_type == 'score':
return proba.dot([-1, 0, 1])
elif return_type == 'all':
return {"label": model.config.id2label[proba.argmax()], "score": proba.dot([-1, 0, 1]), "proba": proba.tolist()}
return proba
Все, что в дальнейшем будет происходить с GPU, мы отслеживаем через nvitop. Почему nvitop, а не nvidia-smi? Можно, конечно, сделать watch -n 0.01 nvidia-smi, но нам милее, когда все раскрашено и само обновляется. Кроме того, nvitop удобно кастомизируется, а с помощью встроенной Python-библиотеки можно сделать свой дашборд через запросы в API.
Оцениваем пригодность модели
Сперва для примера возьмем выдуманный комментарий. Так мы поймем, как модель в принципе справляется со своей задачей. Фразу «Какая гадость эта ваша заливная рыба!» модель однозначно определяют как негативную. Уже неплохо.
text = 'Какая гадость эта ваша заливная рыба!'
# classify the text
print(get_sentiment(text, 'label')) # negative
# score the text on the scale from -1 (very negative) to +1 (very positive)
print(get_sentiment(text, 'score')) # -0.5894946306943893
# calculate probabilities of all labels
print(get_sentiment(text, 'proba')) # [0.7870447 0.4947824 0.19755007]
negative
-0.5894944816827774
[0.78704464 0.4947824 0.19755016]
{'label': 'negative', 'score': -0.5894944816827774, 'proba': [0.7870446443557739, 0.49478238821029663, 0.19755016267299652]}
Если мы заменим «гадость» на «радость», комментарий будет оценен как положительный.
text = 'Какая радость эта ваша заливная рыба!'
# classify the text
print(get_sentiment(text, 'label')) # positive
# score the text on the scale from -1 (very negative) to +1 (very positive)
print(get_sentiment(text, 'score')) # 0.8131021708250046
# calculate probabilities of all labels
print(get_sentiment(text, 'proba')) # [0.1313372, 0.2358502, 0.9444394]
positive
0.8131021708250046
[0.13133724 0.23585023 0.9444394 ]
{'label': 'positive', 'score': 0.8131021708250046, 'proba': [0.1313372403383255, 0.2358502298593521, 0.9444394111633301]}
Далеко не всегда и не во всем с такой моделью можно согласиться. Это видно даже по оценкам, которые она выдает. У нее есть ограничения и в наборе данных, на котором она училась, и в качестве разметки, и в специфике предметной области.
В идеальном мире ее придется файнтюнить из-за языковых особенностей конкретных пользователей, терминологии компании и так далее. На этом подробнее остановимся в конце статьи, когда будем смотреть, что в итоге выдала LLM.
Но мы пока возьмем эту модель в качестве базового решения и будем строить с ее помощью аналитику комментариев на Хабре. В конце концов, мы можем взять данные, подставить их в конкретную модель и получить оценку — то, что мы изначально хотели.
Автоматизируем сбор данных
Теперь начинаются «боль и страдания» — базовая автоматизация бесконечно большого количества вещей, которые мы точно не хотим делать руками. В нашем случае речь о парсинге данных. Раскладывать по ячейкам комментарии к каждой статье — это не совсем аналитическая задача.
Есть смысл разбить сбор данных на три последовательных этапа:
- начальный сбор данных,
- прогон комментариев через LLM и загрузку информации в отдельную базу данных,
- настройку пайплайна для новых статей/комментариев.
Разберем каждый этап по порядку.
Начальный сбор данных
Когда публикаций и комментариев немного, можно собрать все данные вручную. Но это точно не наш случай. Мы «считерим» и пройдемся по нашему блогу Selenium-ботом. Он соберет информацию о количестве страниц со статьями, ссылки на статьи и комментарии к ним.
Полный код бота можно посмотреть в репозитории. Если кратко, скрипт содержит Webdriver_manager (чтобы не приходилось вручную указывать версию браузера и его директорию), отвечает за нахождение количества страниц в блоге, их сбор и скролл секций с комментариями.
Этот скрипт — исключительно утилитарный инструмент, который создавался под конкретную задачу. Его можно сделать аккуратнее, но со своей задачей он справляется и в таком виде.
Прогон комментариев через LLM
Есть два пути. Выбор зависит от подхода к работе с базой данных.
- Вариант 1. Создать облачную базу данных, управляемую PostgreSQL, и прогнать комментарии через LLM в Data Science Virtual Machine. Этот вариант подходит, если у вас есть какие-то специфические требования к БД.
- Вариант 2. Запустить Data Analytics Virtual Machine. В образ вшитаPostgreSQL, поднятый как Docker-образ, в рамках Superset. Это вариант подойдет, если вы хотите быстро создать прототип и не тратить много времени на базу данных.
Мы пошли по второму пути, поэтому далее опишем именно его.
Настройка пайплайна для новых статей и комментариев
Этот шаг отчасти можно назвать опциональным. Он необходим, если в будущем вы планируете встраивать более качественные модели.
Итак, запускаем DAVM и переходим в Prefect Flow, который:
- идет в объектное хранилище Selectel и забирает новый файл с новыми статьями/комментариями,
- прогоняет комментарии через LLM,
- загружает результаты в базу данных.
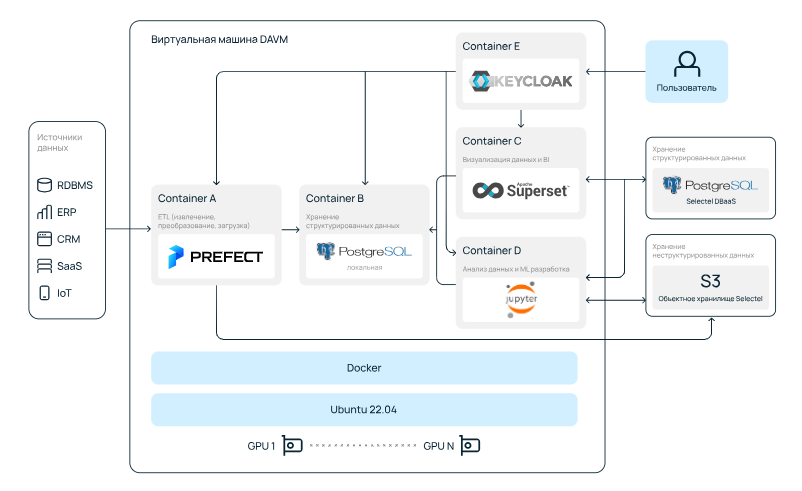
Что такое DAVM
DAVM, или Data Analytics Virtual Machine, — это не просто виртуалка с Ubuntu, драйверами и библиотеками. Это небольшая платформа аналитики данных. В ней собрано несколько инструментов:
- Jupyter Hub для одновременной работы нескольких пользователей,
- Keycloak для управления авторизацией,
- Prefect в качестве оркестратора,
- Superset для BI-аналитики,
- предустановленные библиотеки,
- туториалы и примеры, чтобы было проще разобраться с самой платформой.
Все, что есть в DAVM, можно настраивать и менять по своему усмотрению. А если вдруг что-то перестало работать, платформу можно пересоздать, особенно если все данные хранятся вне ее: например, в облачной базе данных или объектном хранилище.
Под капотом платформы — Ubuntu 22.04 и столько GPU, сколько вы захотите получить из доступных конфигураций. Внутри установлен Docker, в нем в контейнерах запущены все компоненты: Prefect, Superset, Keycloak, Jupyter Hub. Отдельно работает PostgreSQL, на который «нацелен» Superset. То есть можно загрузить данные из любого источника через Prefect в PostgreSQL, а потом вытащить их оттуда в Superset. В качестве надежного хранилища можно использовать не эту же виртуалку (хотя и так тоже можно), а S3 или облачные базы данных, в том числе с PostgreSQL.
Для изолированного запуска Jupyter Lab на одной виртуалке можно использовать технологию Multi Instance GPU (MIG). Она позволяет разделить видеокарту на несколько частей (партиций). В DAVM уже встроена команда для запуска нужного процесса на определенной партиции. Но эта команда сработает только в том случае, если GPU настроить соответствующим образом, то есть применить конфигурацию MIG.
Чтобы разобраться во всех тонкостях шеринга GPU, рекомендуем обратиться к статьям нашего DevOps-инженера Антона Алексеева: «Как разбить GPU на несколько частей и поделиться с коллегами», «Делим неделимое в Kubernetes: шеринг GPU с помощью MIG и TimeSlicing», «Как разделить видеокарту с помощью MIG, MPS и TimeSlicing».
Создаем и запускаем платформу аналитики
Чтобы приступить к работе, открываем панель управления Selectel, переходим в раздел Облачная платформа и создаем новый сервер. Здесь в качестве источника обязательно выбираем Data Analytics VM (Ubuntu 22.04 LTS 64-bit). Подбираем параметры видеокарты, добавляем белый IP и «подкидываем» SSH-ключ.
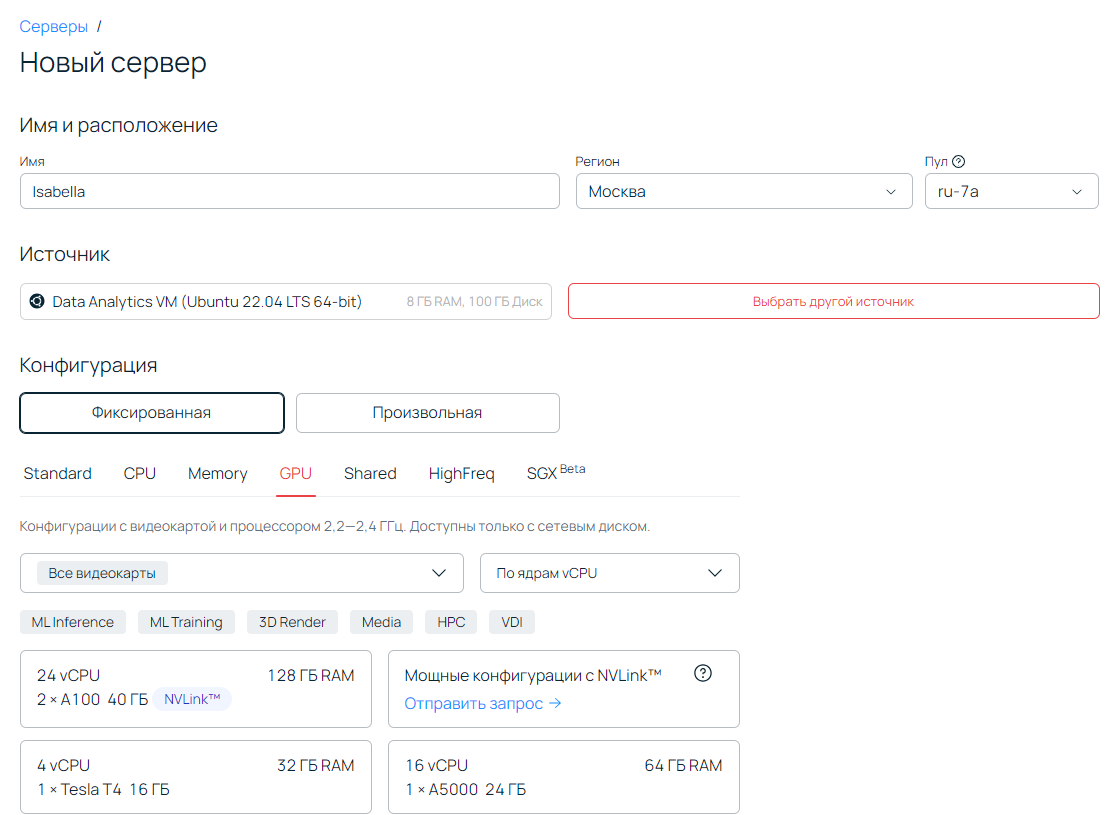
После этого запускаем саму виртуальную машину. Это не самый тривиальный шаг, поэтому в документации есть простая пошаговая инструкция по запуску DAVM.
После входа видим все наши приложения, ссылки на туториалы и ноутбуки. Кстати, вся базовая информация о DAVM, схема платформы, инструкции, руководства и описания доступны в Welcome notebook.

Keycloak позволяет создать несколько пользователей, каждый из которых будет работать в отдельном инстансе Jupyter Lab со своими файлами. Если добавить к этому MIG, они будут использовать еще и разные партиции GPU. Так можно исключить ситуации, когда пользователи каким-либо образом аффектят друг друга в рамках одной платформы.
При работе с DAVM нас будет интересовать в основном раздел Superset. На его главной странице находятся дашборды, чарты и прочее. Дашборды собираются из отдельных чартов, чарты опираются на датасеты, датасеты собираются в основном из SQL-запросов и подключений к базе данных. Именно здесь мы и запускаем обработку данных.
Сами данные заботливо собраны в файлы json с помощью все того же скрипта, с помощью которого можно собирать комментарии из блога на Хабре. Вручную просмотреть содержимое файлов json можно в разделе JupyterHub.

Вот еще один комментарий к той же статье, что на скриншоте выше:

Здесь же можно найти дополнительную информацию, например охват в хабах. Впрочем, разберем все на отдельном примере.
Формируем чарты и дашборды
Заходим в DAVM и переходим в JupyterHub. Здесь импортируем все пакеты, необходимые для работы, вытаскиваем список файлов json, загружаем нашу языковую модель на GPU и запускаем ее. LLM начинает классифицировать комментарии в блоге. Наблюдать за ее работой, как уже сказано выше, удобнее через nvitop.
Когда все комментарии размечены, формируются датасеты. После этого идем в PostgreSQL и запускаем скрипты, чтобы создать базу данных, таблицы со связями и так далее. Отчасти это тоже «путь мук и страданий», потому что здесь нет универсального решения на все случаи жизни в духе «запустил скрипт и все само сделалось».
В любом случае, инициация такого пайплайна вынуждает подготовить базу данных и продумать модель, чтобы и связи между таблицами были, и все атрибуты находились на своих местах. Можно сказать, что это итеративный процесс: начинаешь чуть ли не с плейн-таблицы, а потом потихонечку раскидываешь атрибуты, продумываешь связи, индексы и так далее.
Важный момент: в самом коде мы не держим никакие данные для доступов. Мы предварительно загрузили их Prefect, а теперь можем в коде на них ссылаться.
Следующий шаг — подключаемся к PostgreSQL, создаем базу данных и таблицы, а затем загружаем туда сформированные датасеты. После возвращаемся в Superset и формируем новый датасет на основе базы данных, схемы и таблиц, а затем создаем чарты.

Чарты будут собраны во вкладке Charts. Если мы откроем любой из них, то увидим, что у нас две таблицы формируют датасет. Визуализацию чарта можно выбрать из предложенных вариантов: графиков, диаграмм, таблиц и прочих вариантов.
Визуализация данных
Каждый чарт можно настроить так, чтобы он отображал нужные параметры. Например, показывал зависимость между оценкой комментария (оценкой его тональности языковой моделью) и его рейтингом. Дополнительно можно вывести названия комментируемых статей, ссылки на них, время появления комментариев, распределение по хабам и так далее. Вот наглядные примеры:
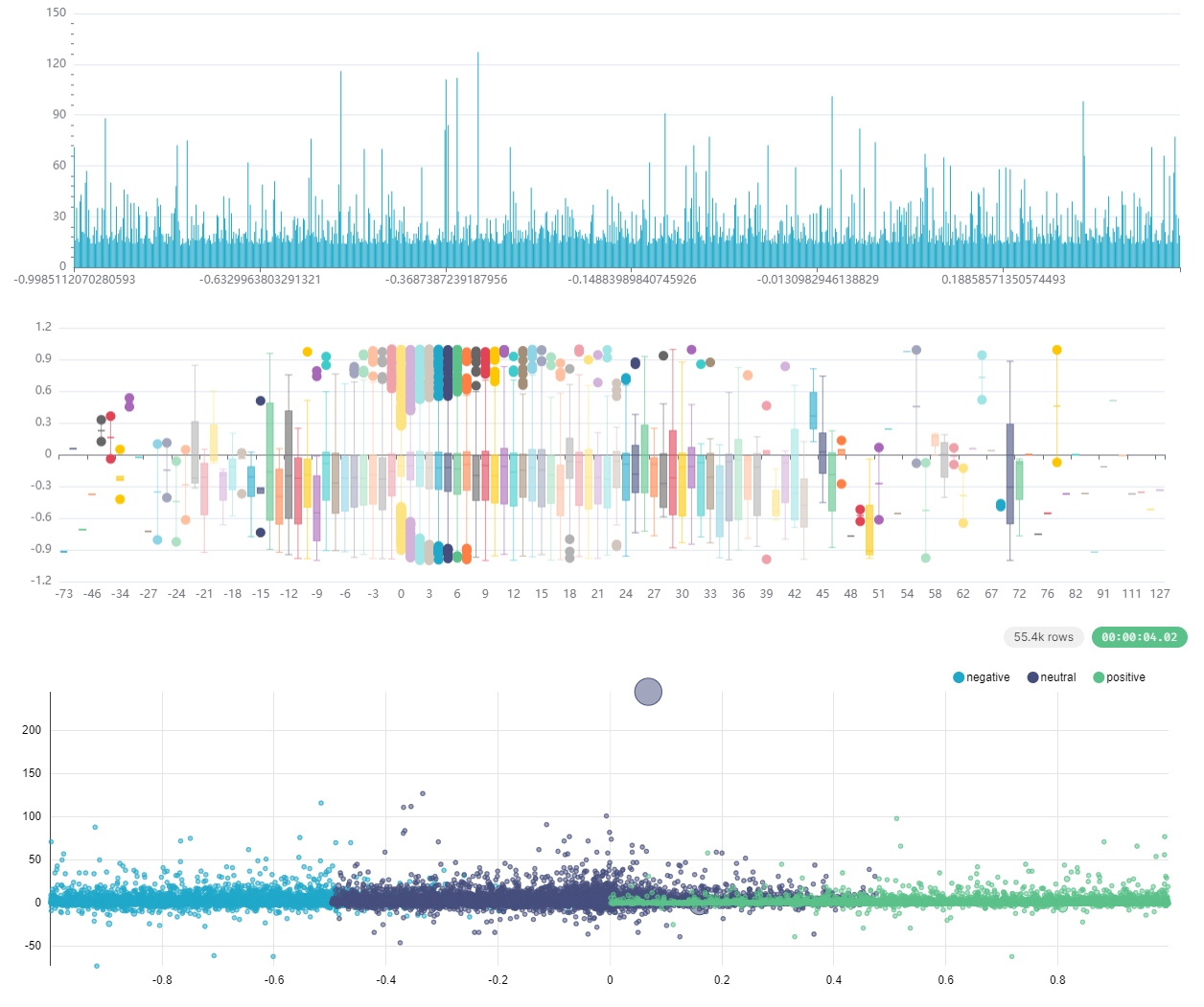
Удобство последнего чарта в том, что в нем соотносятся длина комментария, его тональность и рейтинг. Каждый пузырек здесь — отдельный комментарий.
- Положение пузырька на шкале Х показывает тональность комментария (чем левее, тем больше негатива; чем правее, тем, соответственно, больше позитива).
- Размер пузырька отражает длину комментария.
- Положение по оси Y отображает рейтинг комментария.
Здесь можно смело играться с разными параметрами в зависимости от того, какая аналитика нужна и как удобнее ее визуализировать. На этом шаге можно было бы и закончить: мы собрали аналитику, увидели тенденции в тональности, еще раз почитали комментарии, в которых нас хейтят и хвалят.
Однако по мере появления новых статей и комментариев дашборды нужно обновлять. Делать это вручную мы не хотим, поэтому переходим к следующему шагу.
Автоматизируем обновление данных
Мы не хотим каждый день ходить и руками складывать данные — метки и оценки комментариев — в наши файлы json. А именно эти данные попадают на S3-бакет, забираются оттуда и прокручиваются через LLM. Благодаря этому обновляются дашборды.
Чтобы автоматизировать процесс, пишем скрипт для Prefect, из секретов забираем данные для входа в S3 и в Kserve. Это замечательный инструмент, который позволяет за два-три часа превратить нашу модель в inference service. Можно и быстрее, но для этого придется реже пить чай и повторять операцию регулярно.
После запуска скрипта в разделе Prefect мы можем наблюдать, как стартовал новый флоуран, пошел в S3, забрал файлы json и начал их отрабатывать. На скриншоте ниже как раз комментарии пропускаются через inference service. На выходе мы имеем, соответственно, response.
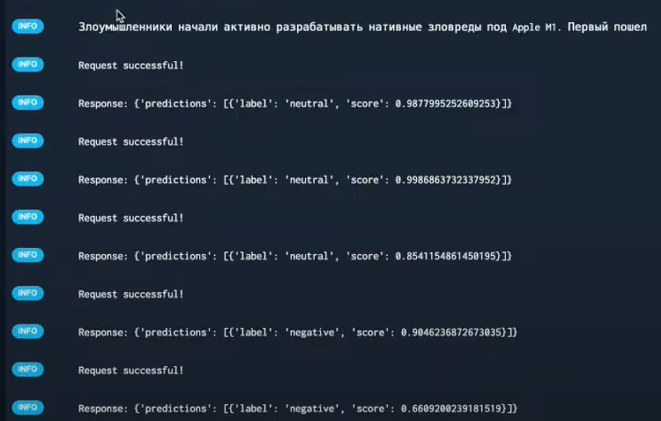
Когда все отработает, флоуран в Prefect будет помечен как completed. Можно задать логику, по которой новые файлы в объектного хранилища будут пропускаться через inference service. А если нагрузка на него вырастет, он просто масштабируется.
Немного об эндпоинте
Файлы json из S3 необходимо пропустить через эндпоинт Kserve. Он, в свою очередь, тоже забирается из секретов. Сам эндпоинт — это результат работы нескольких файлов.
Первый — скрипт на Python. Здесь используем библиотеку kserve и пишем кастомный inference service, в котором имплементируем методы load и predict. В load забираем команды, которые были в ноутбуках, а в predict вытаскиваем атрибут sequence, пропускаем через токенайзер и получаем из модели нужные данные. Дальше формируем из этого результаты и отдаем их.
import kserve
import torch
from transformers import AutoModeForSequenceClassification, AutoRikenizer
from kserve import ModelServer
import logging
class KServeBERTSentimentModel(kserve.Model):
def __init__(self, name: str):
super().__init__(name)
KSERVE_LOGGER_NAME = 'kserve'
self.logger = logging.get.Logger(KSERVE_LOGGER_NAME)
self.name = name
self.ready = False
def load(self):
# Biuld tokenizer and model
name = "cointegrated/rubert-tiny-sentiment-balanced"
self.tokenizer = AutoTokenizer.from_pretrained(name)
self.model = AutoModeForSequenceClassification.from_pretrained(name)
if torch.cuda.is_available():
self.model.cuda()
self.ready = True
def predict(self, request: Dict, headers: Dict) -> Dict:
sequence = request["sequence"]
self.logger.info(f"sequence:-- {sequence}")
input = self.tokenizer(sequence, return_tensors='pt', truncation=True, padding=True).to(self.model.device)
# run prediction
with torch.no_grad:
predictions = self.model(**inputs)[0]
scores = torch.nn.Softmax(dim=1)(predictions)
results = [{"label": self.model.config.id2label[item.argmax().item()], "score": item.max().item()} for item in scores]
self.logger.info(f"results:-- {results}")
# return dictionary, which will be json serializable
return {"predictions": results}
Второй — Docker-файл, в котором мы ставим все необходимые зависимости: kserve, torch и transformers. Запускаем скрипт и на этом весь наш Docker-файл заканчивается.
# Use the official lightweight Python image.
# https://hub.docker.com/_/python
FROM python:3.8-slim
ENV APP_HOME /app
WORKDIR $APP_HOME
#Install production dependencies.
COPY requiremetns.txt ./
RUN pip install --no-cache-dir -r ./requirements.txt
# Copy local code to container image
COPY Kserve_BERT_Sentiment_ModelServer.py ./
CMD ["python", "KServe_BERT_Sentiment_ModelServer.py"]
Последний файл можно посмотреть в UI Kserve в самой ML-платформе: Learning – Inference – Kserve. Во вкладке YAML описан inference service: указан Docker-образ, собранный из Docker-файла, имя kserve-контейнера и парочка вещей вроде bert-sentiment.
Во вкладке Logs можно посмотреть, как разворачивается inference service: как отрабатывает метод load, загружаются токенайзеры и веса модели, с какого момента LLM становится готовой для сервинга.
В этом же UI во вкладке Overview можно найти детали по эндпойнту, который нам необходимо использовать. Тут мы можем самостоятельно развернуть свой KServe (или KubeFlow) и работать с ним, но в нашем случае KServe уже разворачивается и настраивается в рамках нашей ML-платформы.
О чем пишут в комментариях
Разумеется, никто не ждал, что sentiment-анализ откроет нам что-то совершенно новое. В целом картина оказалась вполне предсказуемой: преобладают нейтральные комментарии, потом появляются негативные и позитивные.
Впрочем, с оценкой тональности стоит быть осторожным. Помните, что выбранная LLM не совершенна? В идеальном мире для ее файнтюнинга мы бы сформировали датасеты из комментариев на Хабре. Тогда итог анализа получился бы, вероятно, еще более качественным.
Но даже так интересно взглянуть на самые негативные и самые позитивные комментарии в блоге Selectel по мнению LLM. Максимальную оценку модель поставила комментарию к статье «Как сделать консистентный UX для 40+ продуктов. Уроки, которые я извлекла из перезапуска дизайн-системы». А вот и сам комментарий:

А вот подборка самого-самого негатива (вы же за этим статью открыли?):


Безусловно, в блоге можно найти и куда более негативные комментарии. Достаточно проверить чарты вручную или обучить LLM на более релевантном датасете. Впрочем, отыскать в числе «самых злых» комментариев (score — ниже -0,9) интересные экземпляры совсем не сложно:






