Как развернуть приложение в кластере Managed Kubernetes на выделенном сервере
Изучаем на практических примерах, как работать с группами нод на выделенных серверах, как создавать кластер, как его настраивать и как публиковать приложения.
Всем привет! С вами на связи Евгений Листраткин, ведущий инженер команды администрирования клиентских сервисов. Мы предоставляем услуги DevOps as a Service как в дата-центрах Selectel, так и на любых других площадках.
Под задачи клиентов держим значительную часть сервисов в Kubernetes-кластерах, используя managed‑решения нашей компании. При этом не участвуем в разработке и технической поддержке самого продукта, а выступаем исключительно в роли его пользователей — как внутренних, так и внешних.
Сегодня расскажу и на практических примерах покажу, как работать с группами нод на выделенных серверах. Создание кластера, его настройка, публикация приложений — все занимает не больше часа.
Микроэкономика и тенденции
В современном мире IT контейнерные приложения стали де‑факто стандартом, а их оркестрация все чаще переходит под управление Kubernetes. Любая подобная система требует точной настройки базовых компонентов и круглосуточной поддержки — только так можно гарантировать стабильность и доступность развернутых приложений.
Однако в последние годы ситуация на кадровом IT-рынке заметно усложнилась. Поток соискателей вырос, компании внедряют жесткие фильтры отсева, а кандидаты пытаются их обойти. Из‑за обилия недостоверных резюме и описаний позиций поиск по‑настоящему квалифицированных специалистов занимает гораздо больше времени.
Добавим к этому урезанные бюджеты и растущий акцент на FinOps-практики. В результате получаем серьезно возросшую нагрузку на действующих инженеров: им приходится поддерживать новые приложения и сервисы, решать сетевые проблемы и брать на себя задачи с незакрытых должностей.
Когда растут обязанности инженеров, а закрытие вакансий буксует, логичным шагом становится переход на managed-продукты. Да, это не «серебряная пуля» от всех фундаментальных проблем, но облегчить жизнь такие решения точно способны.
По данным исследования State of DevOps 2025, доля managed-решений за прошлый год немного снизилась, хотя общее использование Kubernetes продолжает расти. Самостоятельная поддержка кластеров — управление master-нодами, настройка сетевой связности и интеграция с облачными сервисами — все еще сохраняет внушительную долю в общем объеме инсталляций.
Зачастую выбор в пользу self-hosted продиктован ограничениями облачных платформ. Инженерам может не хватать гибкости в управлении системными компонентами, нужного уровня изоляции инфраструктуры, производительности или экономической выгоды.
Частый пример таких барьеров — сложности с выделенными серверами. У одних провайдеров их просто нет, у других worker-ноды в managed-кластерах можно развернуть только на виртуальных машинах.
Все это вынуждало инженеров расчехлять инструменты самостоятельной настройки вроде Kubespray, а в самых требовательных проектах — собирать платформу с полного нуля. Мы в Selectel решили устранить эти препятствия — теперь кластеры могут включать группы нод на выделенных серверах, а их развертывание занимает не больше 60 минут. Можно снова отложить Kubespray подальше и избавить себя от лишней головной боли с контролем master-нод.
Преимущества
Чем же так выгодно использование выделенных серверов в кластерах?
Главное преимущество — полноценная зарезервированная мощность. Все вычислительные ресурсы полностью изолированы от соседей. Ну и куда же без FinOps — выделенный сервер обходится дешевле, чем облачные конфигурации аналогичного объема.
Как и облачные ресурсы, инсталляции на выделенных серверах имеют свои особенности. Из главного: пока не поддерживается автомасштабирование, а также популярная опция подключения сетевых дисков.
С подробным описанием Managed Kubernetes можно ознакомиться на странице продукта, а со всеми техническими особенностями сервиса — в документации.
Следить за доступными ресурсами кластера тоже пока приходится самостоятельно, а масштабировать вычислительные мощности — вручную. Для этого нужно увеличивать количество машин в существующей группе или добавлять новые нод-группы с доступными конфигурациями выделенных серверов.
Про расширение дискового пространства, а также о том, как в таких условиях работать с дисковой подсистемой и использовать persistent volumes в приложениях, поговорим на конкретных примерах ниже.
Создание кластера
Развертывание приложений на выделенных серверах логично начать с создания самого кластера. Как упоминалось ранее, управление master-нодами берет на себя облачный провайдер. Единственное отличие от классической инфраструктуры на виртуальных машинах кроется на этапе настройки нод-групп.
Как создать кластер Managed Kubernetes на выделенном сервере подробно описано в нашей документации.
Откроем раздел Managed Kubernetes и создадим новый кластер.
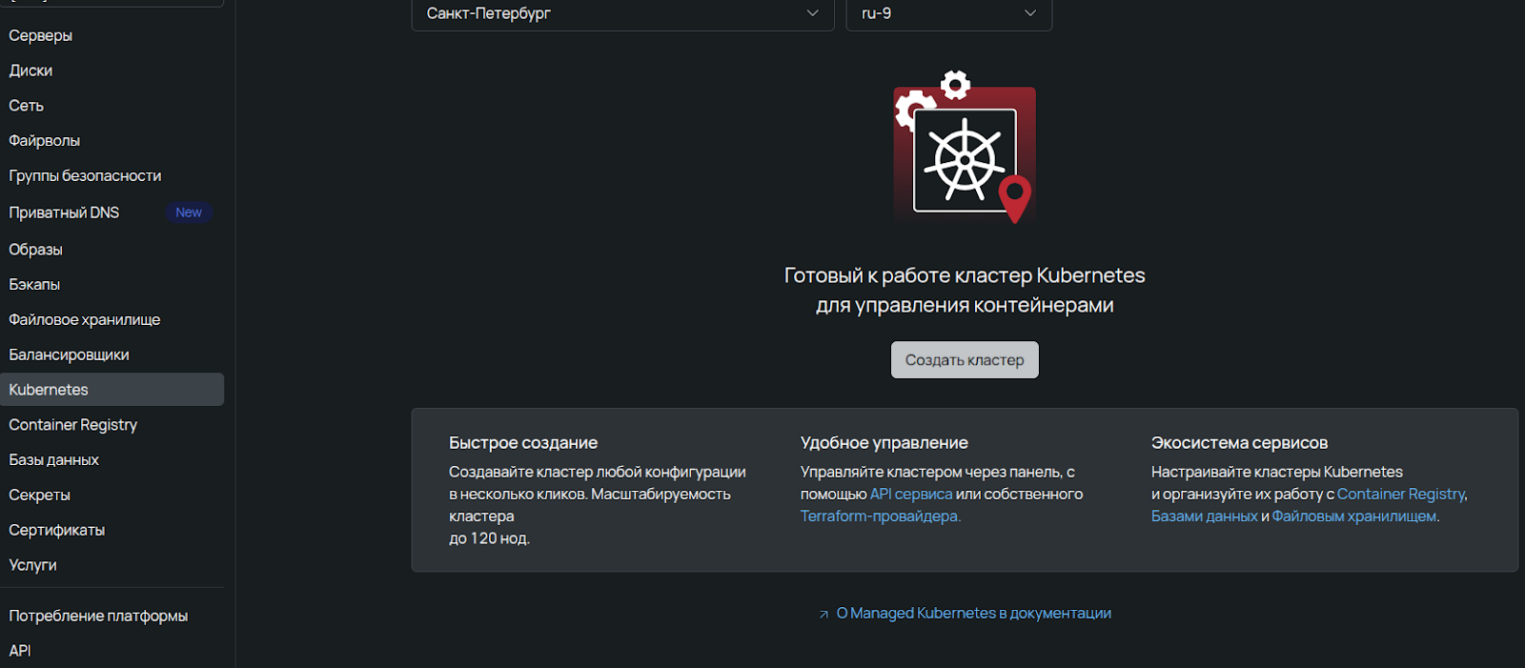
На этапе создания master-нод нужно выбрать фундаментальные параметры, которые в дальнейшем нельзя изменить без полного пересоздания кластера.
Регион — нод-группы будут развернуты в выбранной локации при условии, что имеются свободные ресурсы.
CNI (Container Network Interface) — по умолчанию применяется Calico, но также доступен Cilium.
Тип кластера — отказоустойчивый вариант резервирует master-ноды в трех экземплярах в разных пулах. Это значит, что control plane выйдет из строя только при одновременном отказе их всех. Базовый тип разворачивается без резервирования и больше подвержен рискам недоступности, но отлично подходит для тестовых и dev-сред.
Тип API (публичный или приватный) — при выборе приватного варианта внешний доступ к API закрыт, в таком случае для управления кластером придется самостоятельно настраивать jump host и прокидывать туннель.
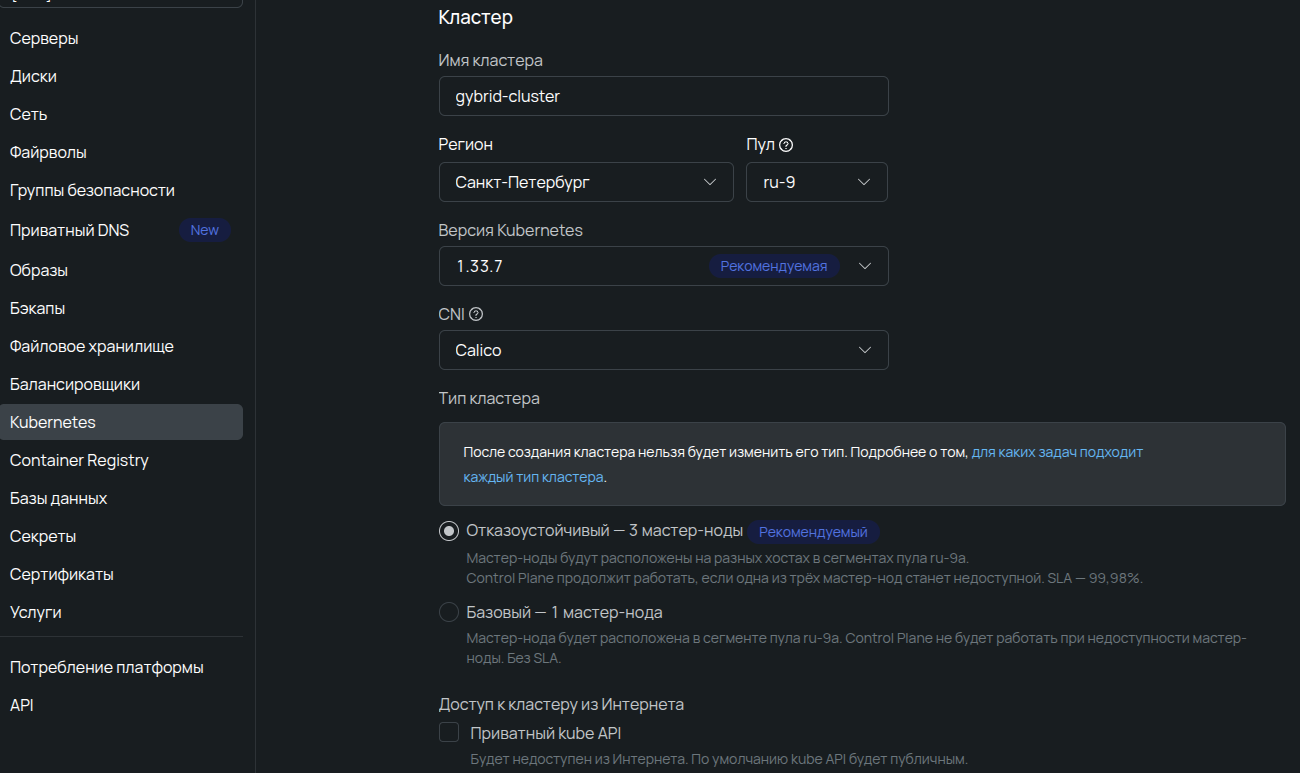
С master-нодами разобрались, переходим к worker-узлам. На этом этапе появляется возможность вместо облачных выбрать выделенные серверы — их доступные настройки и рассмотрим.
Пул — распределение вычислительных мощностей по разным пулам повышает отказоустойчивость приложений. Для этого достаточно создать несколько нод-групп в разных зонах. Подробнее — в нашей документации.
Конфигурация ноды — набор ресурсов для каждого worker-узла. Здесь есть специфичный для выделенных серверов параметр — тарифный план, который определяет, в том числе, и минимальный срок аренды.
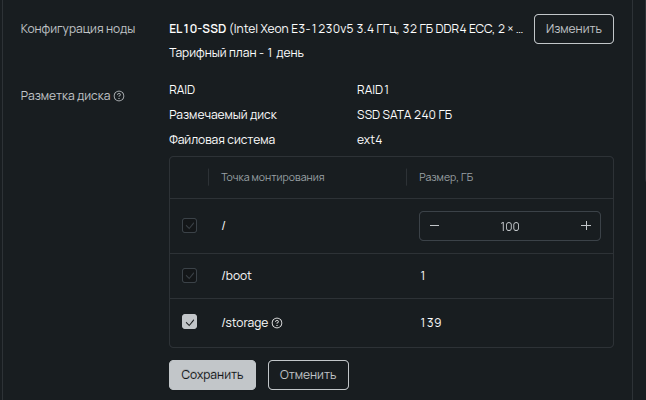
Также доступна настройка разметки диска. Помимо штатных корневого и загрузочного разделов, можно выделить /storage для локальных persistent volumes. Такой раздел хорошо подходит для постоянных данных в подах, но важно помнить, что они не мигрируют между серверами. Если не планируется запускать сервисы, жестко привязанные к конкретной ноде, то логичнее отдать все пространство под корневой раздел и эфемерные хранилища, которые им пользуются.
Количество нод — задать значение больше, чем есть машин нужной конфигурации в наличии, не получится — доступный лимит отображается еще на этапе выбора. После создания кластера группу можно масштабировать, если останутся свободные серверы, или добавить новые нод-группы с другими аппаратными конфигурациями.
Метки и тейнты — базовый инструмент Kubernetes для распределения приложений по узлам.
В документации K8s есть подробные статьи с объяснением концепции и примерами:
CIDR подсетей — настройка внутренней адресации кластера и связности с глобальным роутером. При выборе кастомных сетей стоит свериться с документацией по допустимым диапазонам (см. п. 8).
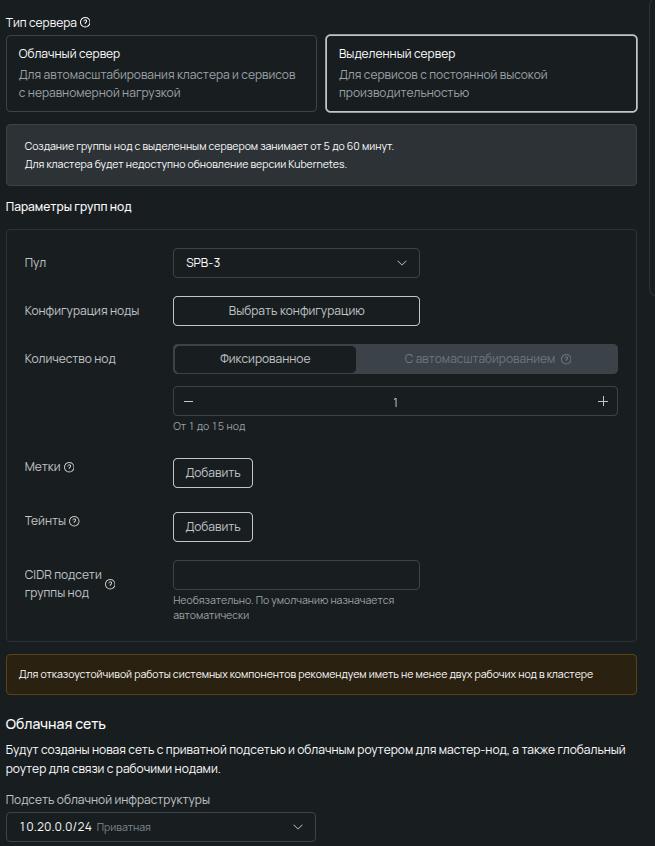
После того как все требуемые параметры выбраны, переходим к настройке автоматизации, а затем — к условиям тарификации и подтверждению стоимости. Наливаем кофе и ждем. В течение 5−60 минут статусы кластера и нод-группы должны смениться на ACTIVE.
Для сторонников подхода IaC (Infrastructure as Code) предусмотрено развертывание через Terraform. Правда, пока функциональность ограничена созданием master-нод — собрать нод‑группу на базе выделенных серверов таким способом еще не получится.
О том, как описать создание кластера кодом, можно почитать в нашей документации.
Мне пришлось срочно допивать кофе уже через 17 минут. Пришло оповещение, что обе машины на связи и нод-группа готова. Возвращаемся в панель управления на вкладку Настройки и забираем kubeconfig для подключения. Поскольку API был выбран публичным, можно обойтись без лишних телодвижений и сразу приступить к делу — достаточно передать полученный конфиг в любимый GUI-клиент или положить в рабочий каталог kubectl.
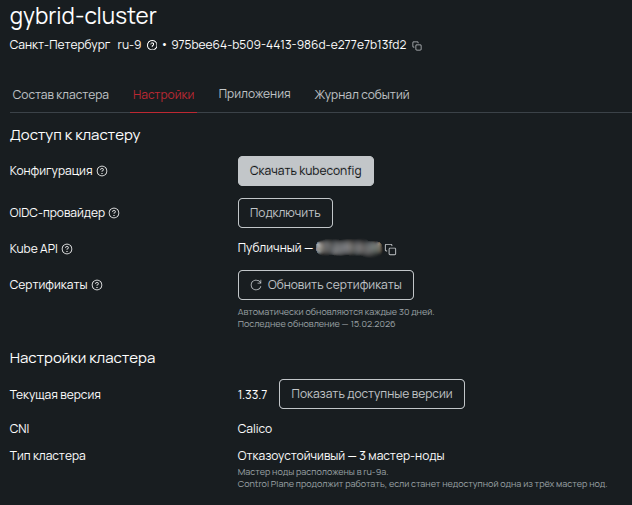
Полученный kubeconfig окажется временным. В целях безопасности сертификаты автоматически обновятся через несколько недель, после чего файл придется скачать заново.
Для работы с одиночным кластером правильнее применять ролевую модель (RBAC) на базе сервисных аккаунтов. Если же инсталляций несколько, лучше организовать единую точку входа через OIDC-провайдера — например, Keycloak.
В сети есть множество подробных инструкций о том, как подружить Keycloak с Kubernetes буквально за пару минут. Не обязательно все делать самостоятельно — можно воспользоваться облачным сервером с уже преднастроенным образом.
Настройка кластера
Оказавшись внутри кластера, перейдем к установке системных компонентов, без которых полноценная работа сервисов просто невозможна. Начнем с главного — Ingress-контроллера, который станет ядром балансировки внешнего трафика.
Самый простой путь его развернуть — открыть вкладку Приложения в панели управления и выбрать нужный инструмент в локальном маркетплейсе. Приверженцы классического подхода могут установить его через традиционный Helm-чарт.
Пошаговая установка Ingress Controller на примере Helm-чарта — в нашей документации.
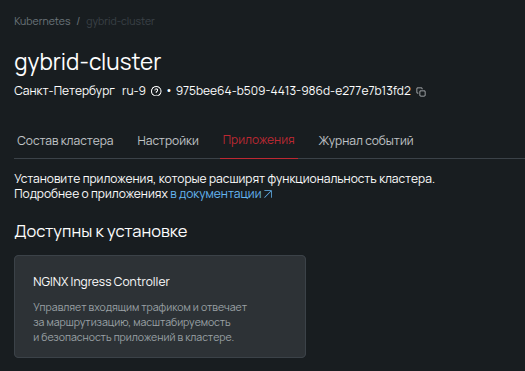
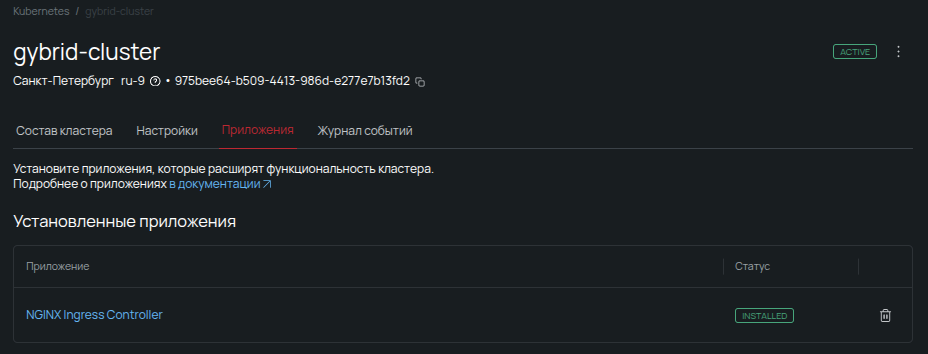
Через некоторое время приложение успешно установится. По умолчанию будет создан IngressClass с именем nginx, который пригодится при дальнейшей настройке.
Фактически этот класс работает как целеуказатель на конкретный Ingress-контроллер. Он совершенно необходим, если таких контроллеров в кластере несколько — например, когда нужно отделить внутренний или служебный трафик от основного.
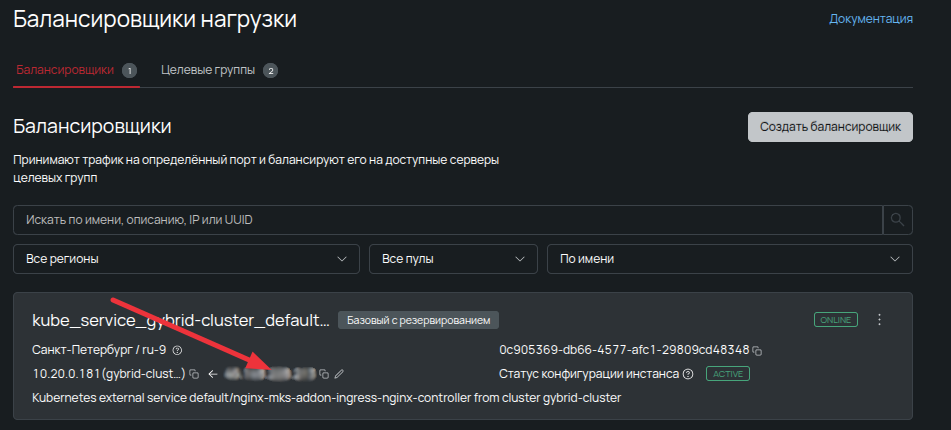
Тем временем в сервисе балансировщиков появился новый объект, привязанный к кластеру и его контроллеру. Выделенный публичный IP‑адрес станет внешней точкой входа для приложений — именно его предстоит прописать в A‑записях DNS.
Перед развертыванием приложения нужно выбрать доменное имя и подготовить сертификат. Если тестовая или рабочая зона уже существует, достаточно добавить A‑запись, указывающую на настроенный ранее балансировщик. Если домена нет, его можно зарегистрировать тут же в панели Selectel.
Как только все готово, самое время позаботиться об HTTPS-сертификатах. Стандартом для управления ими в Kubernetes уже давно стал cert-manager. Установим этот прекрасный контроллер в кластер.
Далее исходим из того, что kubectl уже настроен, а конфигурационный файл успешно импортирован.
Все описанные операции можно выполнить и через графические интерфейсы (GUI). Однако поскольку логика работы сильно отличается от утилиты к утилите, примеры для конкретных визуальных клиентов здесь не приводятся — при необходимости разбираться с ними предстоит самостоятельно.
helm repo add jetstack https://charts.jetstack.io
helm repo update
helm install cert-manager jetstack/cert-manager \
--namespace cert-manager \
--create-namespace \
--set crds.enabled=true
Убедимся, что в кластере появились поды контроллера — именно они будут отвечать за выпуск сертификатов:
kubectl get pods --namespace cert-manager

Чтобы автоматизировать получение сертификатов через HTTP challenge, добавим объект ClusterIssuer. Логика этой проверки проста: сертификат выдается на конкретный домен, чья DNS-запись должна указывать на источник запроса.
Созданный ClusterIssuer сможет обслуживать всю инфраструктуру. Главное — не забыть прописать в его настройках корректный IngressClass, который был задан при развертывании Ingress-контроллера:
apiVersion: cert-manager.io/v1
kind: ClusterIssuer
metadata:
name: le-prod # Имя issuer, на который нужно ссылаться при выпуске сертификатов
spec:
acme:
server: https://acme-v02.api.letsencrypt.org/directory
email: my-wonderful-email@example.com # Почта администратора для уведомлений от центра сертификации
privateKeySecretRef:
name: le-prod-key
solvers:
- http01:
ingress:
# Класс созданного контроллера
class: nginx
С этого момента cert-manager берет под контроль все объекты типа Certificate и автоматически обновляет их незадолго до истечения срока действия. Это особенно актуально на фоне инициативы по сокращению времени жизни сертификатов Let’s Encrypt как минимум вдвое.
При работе с этим механизмом есть один важный нюанс. Во многих статьях в интернете следующим шагом предлагают вручную создать ресурс Certificate, а затем сослаться на сгенерированный секрет в Ingress-правиле для терминации трафика.
Если этот манифест не зашит в Helm-чарт приложения, при удалении сервиса про него часто забывают. В итоге «осиротевшие» ресурсы продолжают «висеть» в кластере и безуспешно пытаются обновиться — что, конечно, обречено на провал, если A-запись домена уже удалена или изменена.
Более надежный и корректный подход — запрашивать выпуск прямо через аннотации в том Ingress-манифесте, для которого и нужен HTTPS.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ...
namespace: ...
annotations:
cert-manager.io/cluster-issuer: le-prod
...
spec:
...
При таком подходе жизненный цикл TLS-секрета полностью берет на себя cert-manager. Появилось Ingress-правило с аннотацией — сертификат автоматически выпущен, удален ресурс — исчез и связанный с ним секрет.

Более сложные сценарии, требующие wildcard-сертификатов, можно реализовать с помощью объектов Issuer на основе DNS-записей. Пример настройки такого механизма для доменов Selectel есть в нашем репозитории на GitHub.
Приложения в кластере
Теперь можно переходить к публикации приложений в кластере. Их логика и манифесты будут намеренно несложными, поскольку сейчас важнее разобрать особенности деплоя по сравнению с облачными инсталляциями.
Начнем с самого простого случая — stateless-сервиса, которому не нужно хранить состояние и данные в своем окружении. Для работы понадобятся три манифеста:
- Deployment — описание самого приложения и его среды;
- Service — сетевая абстракция над группой объектов;
- Ingress — сущность, маршрутизирующая внешний трафик к сервисам внутри кластера.
Не будем мудрствовать и представим, что гипотетический многомиллиардный проект состоит из одного пода с Nginx — без дополнительных конфигов, учета best practices, строгой изоляции и прочих доработок для prod-окружений.
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: default
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx
namespace: default
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
type: ClusterIP
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: nginx
namespace: default
annotations:
cert-manager.io/cluster-issuer: le-prod # Аннотация для автоматического выпуска сертификата через cert-manager
spec:
ingressClassName: nginx # Целеуказатель на созданный ранее Ingress-контроллер
tls:
- hosts:
- my.wonderful.ru
secretName: tls-my-wonderful-ru
rules:
- host: my.wonderful.ru
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: nginx
port:
number: 80
Применим подготовленные манифесты к кластеру. Способ деплоя может быть любым: команда kubectl apply, интерфейс K8s IDE или готовый тестовый конвейер поставки. После этого проверим результат.

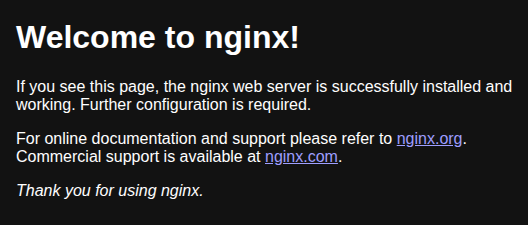
Все отлично — с базовыми задачами кластер на выделенных серверах справляется без проблем.
Теперь немного усложним сценарий. Допустим, сервису потребовалось место для постоянных данных — например, многомиллиардный проект через простую конфигурацию Nginx и отдельный location с методом PUT складывает файлы прямо «себе под ноги» для дальнейшей обработки.
Такие ресурсы выделяются с помощью объектов PersistentVolume (PV) и настроенных StorageClass. Еще на этапе развертывания кластера пространство на сервере было размечено под локальный класс хранения —по умолчанию он называется local-storage. Однако важно помнить про его главную особенность: диск жестко привязан к конкретному железу. Если под переедет на другую ноду, доступ к накопленным файлам будет потерян.

В облачных кластерах эта проблема решается через StorageClass на основе сетевых дисков, но для выделенных серверов такая опция пока недоступна. Это не приговор — отличной, а местами и более выигрышной альтернативой станут диски на базе файлового хранилища.
Как и у сетевых дисков, здесь есть разные типы накопителей со своими лимитами и скоростью доступа. Однако у файлового хранилища есть важное преимущество — поддержка режима ReadWriteMany (RWX). Это значит, что один и тот же том можно примонтировать к нескольким подам одновременно.
Кроме того, при миграции подов между нодами нет задержек, поскольку этот режим не требует атомарного переподключения (reattach) сетевого диска.
Для сравнения: у зарубежных провайдеров подобный режим для PV доступен либо с огромным минимальным объемом (от 1 ТБ против 50 ГБ в Selectel), либо через FUSE-тома поверх S3. В последнем случае активная работа с файлами серьезно ударит по бюджету, так как биллинг учитывает каждое обращение к объектному хранилищу.
Для начала создадим файловое хранилище. Ради простоты и удобства разместим его в том же регионе и пуле, где находится кластер, и привяжем к его подсети — так сможем обойтись без дополнительной работы с маршрутами в подсетях.
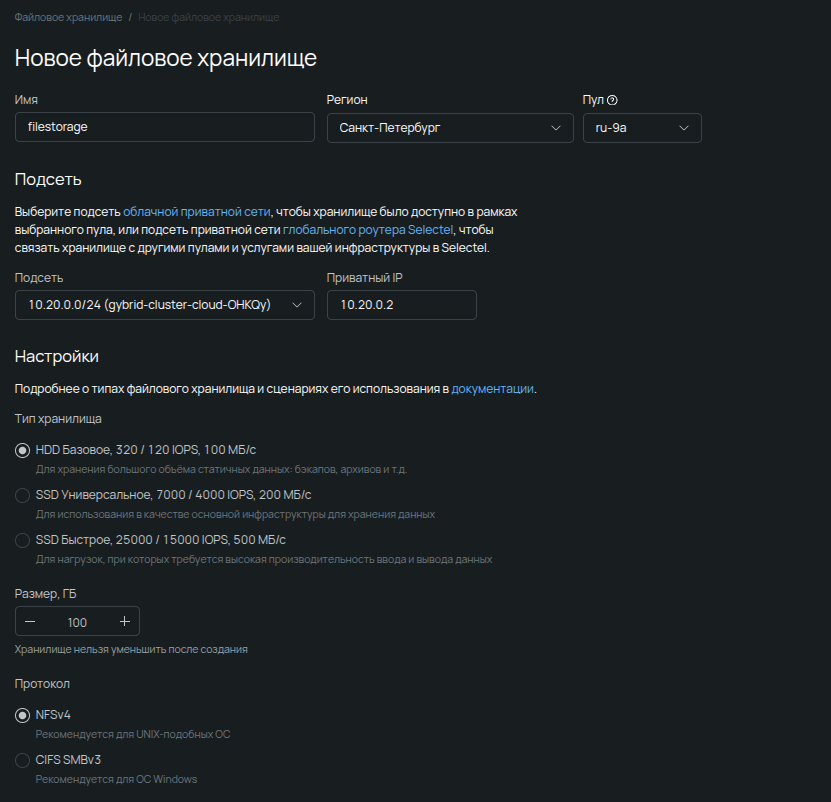
Файловое хранилище также можно полностью развернуть через Terraform. Как это сделать — в нашей документации.
Дождемся, пока оно будет готово, и скопируем нужные параметры из информационного блока.
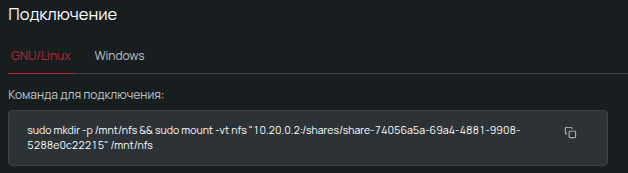
В нашем случае для подключения понадобятся два параметра: IP-адрес хранилища и путь к выделенному каталогу:
10.20.0.2:/shares/share-74056a5a-69a4-4881-9908-5288e0c22215Подготовим кластер к работе с новым хранилищем: добавим CSI-контроллер для NFS. Разберем, почему для выделения вольюмов выбран именно он.
Главная причина — встроенная логика изоляции данных. Под каждый PVC в файловом хранилище автоматически создается отдельный каталог, который и становится точкой монтирования для пода.
Благодаря этому данные разных PVC надежно изолированы друг от друга — такого результата не всегда удается добиться стандартными контроллерами.
helm repo add nfs-subdir-external-provisioner https://kubernetes-sigs.github.io/nfs-subdir-external-provisioner
helm repo update
helm install nfs-subdir-external-provisioner nfs-subdir-external-provisioner/nfs-subdir-external-provisioner --namespace kube-system \
--set nfs.server=10.20.0.2 \
--set nfs.path=/shares/share-74056a5a-69a4-4881-9908-5288e0c22215 \
--set storageClass.pathPattern='${.PVC.namespace}/${.PVC.name}'
# nfs.server — IP-адрес файлового хранилища;
# nfs.path — его корневой каталог;
# storageClass.pathPattern — шаблон для создания подкаталогов.
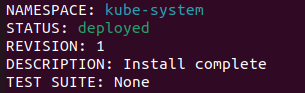
Helm рапортует об успешной установке. Заодно в кластере появился StorageClass с именем nfs-client — именно он будет автоматически выделять вольюмы по каждому запросу согласно заданным правилам.
Запросим выделение вольюма с помощью манифеста PersistentVolumeClaim (PVC). Пусть вся магия его создания останется на плечах контроллера и нового StorageClass.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc
namespace: default
spec:
storageClassName: nfs-client # Имя созданного StorageClass
accessModes:
- ReadWriteMany # Режим доступа, позволяющий монтировать вольюм к нескольким подам
resources:
requests:
storage: 1Gi
Убедимся, что PVC успешно создан.
kubectl get pvc
kubectl get pv


Теперь можно обновить манифест Deployment, подключив к приложению созданный вольюм.
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: default
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
volumes: # Определение подключаемого вольюма
- name: upload
persistentVolumeClaim:
claimName: pvc # Имя созданного PVC
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: upload
mountPath: /usr/share/nginx/html/upload # Путь для постоянного хранения файлов в контейнере
Убедимся, что вольюм успешно подключен к поду, а сам деплоймент работает без ошибок:
kubectl describe deployment nginx
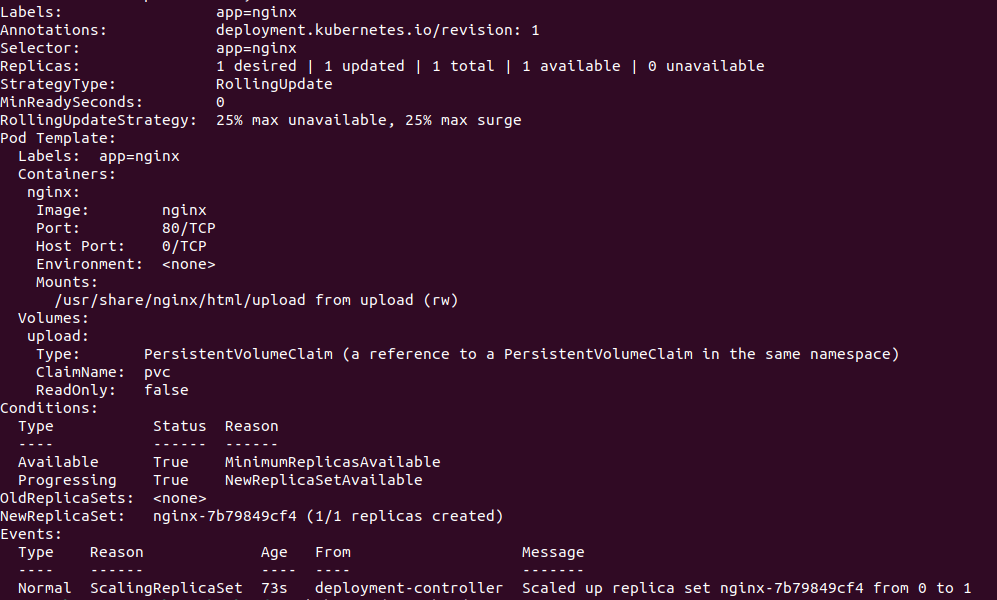
Теперь воспользуемся преимуществами режима ReadWriteMany и увеличим количество реплик сервиса — например, до трех.
---
...
spec:
replicas: 3
...
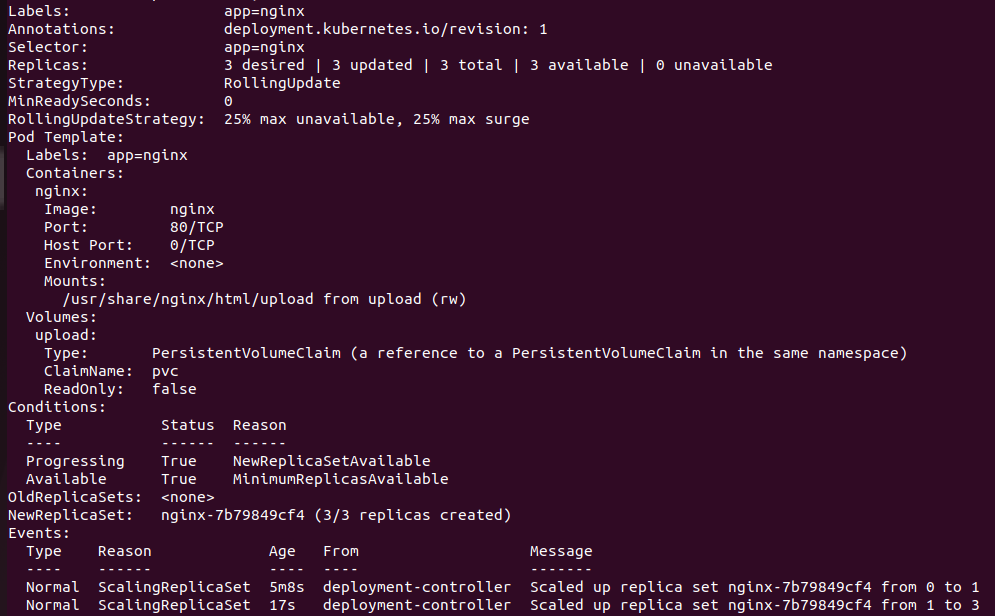
Все прошло, как задумывалось. Теперь в кластере запущено три экземпляра сервиса. У каждого из них к пути /usr/share/nginx/html/upload примонтирован один и тот же PV — данные сохранятся при перезагрузке подов и будут доступны всем репликам приложения одновременно.
Заключение
Как видим, развертывание Kubernetes-кластеров на выделенных серверах не является чем‑то сложным или своеобразным. Передача управления мастер-нодами облачному провайдеру снимает головную боль инженеров, связанную с администрированием Control Plane и высвобождает время для более важных задач.
Более того, провайдер предлагает готовые сервисы, расширяющие функциональность кластера и закрывающие специфические потребности инфраструктуры. Мы в Selectel продолжает развивать свои продукты, чтобы сохранить ставшие всем привычными возможности облачных инсталляций.
Коллеги из команды Managed Kubernetes поделились планами: в ближайшем будущем для кластеров на выделенных серверах появится поддержка сетевых дисков, а также полноценный процесс обновления минорных версий Kubernetes.