Qwen в облаке: поднимаем OpenAI-совместимый API через vLLM
Разберем, как за несколько шагов развернуть модель Qwen на GPU-сервере и поднять OpenAI-совместимый API через vLLM для интеграции в свои проекты.
Большие языковые модели все чаще используют как сервис инференса: к ним обращаются по HTTP-API из внутренних инструментов и приложений так же, как к базам данных или поисковым движкам.
В бизнес-практике это дает быстрые прикладные сценарии:
- помощник для поддержки и operations — суммаризация обращений, черновики ответов, классификация;
- ассистент для инженерных команд —объяснение кода, генерация шаблонов, работа с регламентами и runbooks;
- внутренний помощник по знаниям — корпоративная документация.
Чтобы перейти от идеи к прототипу, нужен воспроизводимый стенд: доступный по HTTP, с понятным способом подключения клиентов и быстрыми проверками работоспособности. А модель должна быть поднята как сервис.
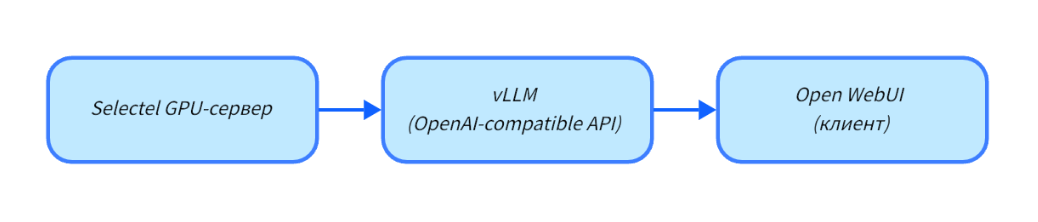
Развернем Qwen из Hugging Face на GPU-сервере Selectel, запустим ее через vLLM в режиме OpenAI-совместимого API, а затем подключим Open WebUI для первичной проверки ответов и поведения модели на типовых запросах.
Это станет базой для более сложных систем. Построение полноценного RAG (индексация, эмбеддинги, ретривер, пайплайн обновления) — следующий этап и тема для отдельной статьи. В рамках текущей статьи мы подготовим только основу для него — стабильный эндпоинт инференса, который вы получите по итогам этой инструкции.
Qwen: подбор и описание модели
В этой инструкции используем Qwen3-30B-Instruct из Hugging Face.
Для стенда инференса Instruct-модификация практичнее базовой: она предназначена для диалоговых и ассистентских сценариев, сразу ориентирована на режим «вопрос–ответ», лучше управляется через системные инструкции и предсказуемее ведет себя в типовых интеграциях.
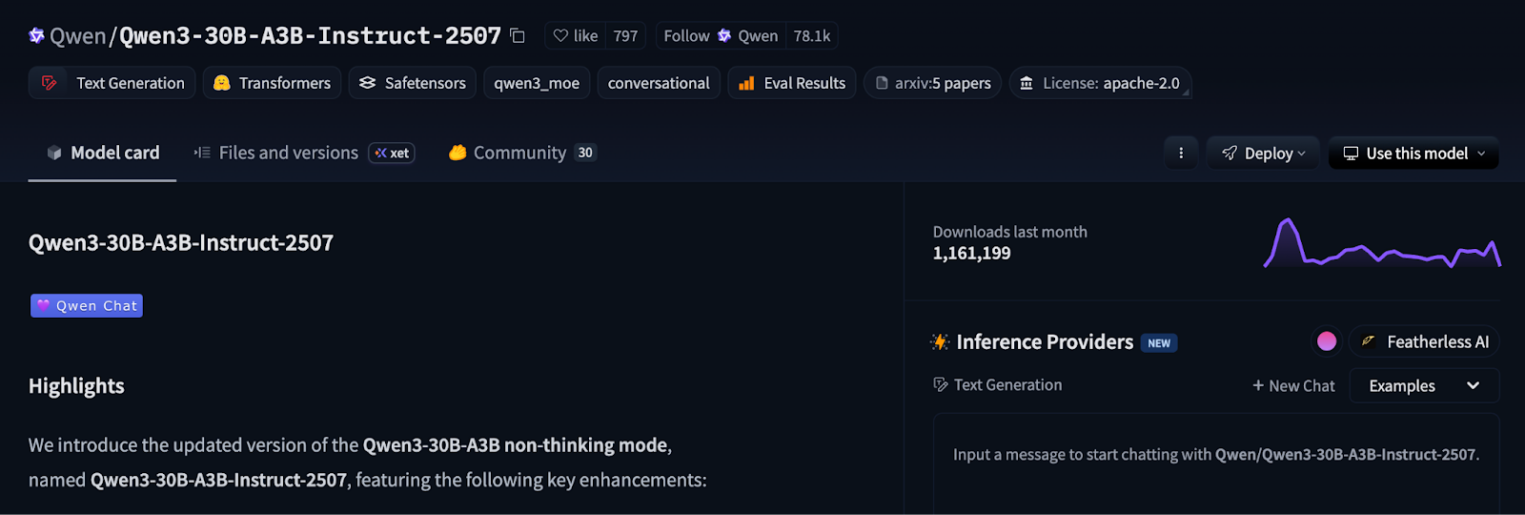
Hugging Face используется как источник весов и конфигурации: vLLM загружает модель по model id и сохраняет артефакты в кэш на диске сервера. При повторных запусках загрузка не выполняется заново, если кэш сохранен.
Перед развертыванием достаточно сверить в карточке модели:
- точный model id — именно он будет использован при запуске vLLM;
- длину контекста — от нее зависят профиль тестов и рост потребления VRAM при увеличении входа/истории;
- условия доступа и лицензию — если требуется принять условия или использовать токен для скачивания, это лучше сделать заранее.
Выбор сервера
Для развертывания крупной LLM в облаке ключевое — правильно выбрать конфигурацию и сразу продумать контур доступа. Эти параметры определяют сколько времени займет первый старт и насколько повторяемыми будут итерации теста.
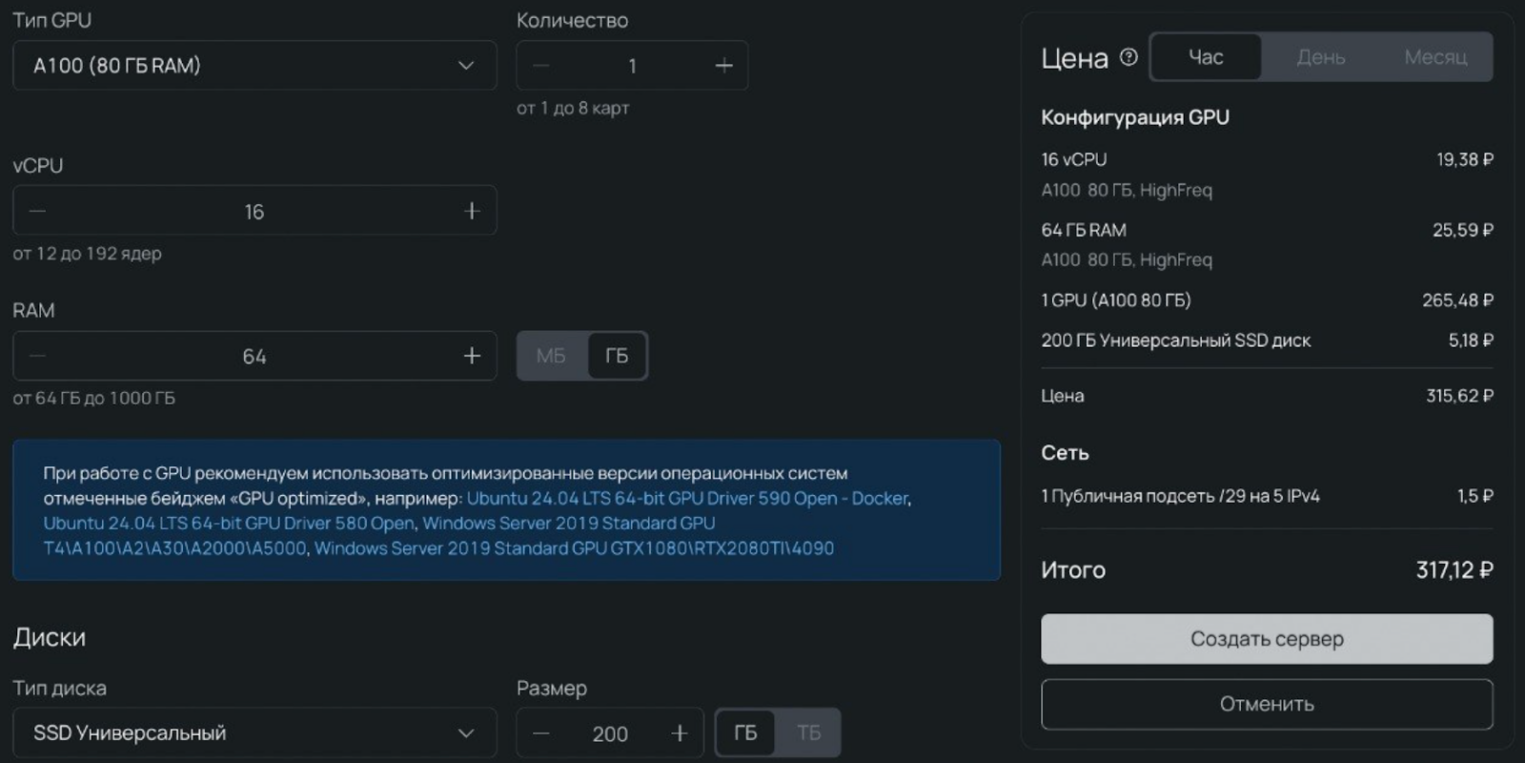
Для запуска локального Qwen воспользуемся облачной платформой Selectel. Для этого переходим в панель управления, в верхней части экрана видим слово Продукты и нажимаем на него. Далее переходим в Облачные серверы, выбираем пул, например Москва и нажимаем Создать сервер.
Даем имя проекту и выбираем образ, например: Ubuntu 24.04 LTS.
GPU и VRAM
При инференсе видеопамять расходуется на:
- веса модели;
- KV-кэш, который растет с длиной контекста и числом параллельных запросов.
Поэтому оценка памяти должна учитывать запас по VRAM под контекст и параллельность. Во вкладке Конфигурация переходим в раздел GPU и выбираем видеокарту.
Для текста нам будет достаточно одной A100 80GB — это базовая конфигурация для Qwen3-30B, которая снижает риск упереться в память на этапе первичного запуска.
Диск и кэш модели
Первый запуск включает скачивание весов с Hugging Face и запись в кэш. Если кэш хранится на маленьком системном разделе или диска недостаточно, возникают повторные загрузки и увеличивается время холодного старта и работы GPU.
На практике лучше сразу выделить каталог на диске (например, /data/models) под кэш Hugging Face и артефакты запуска. И запастись местом, чтобы модель не упиралась в диск в момент скачивания.
Доступ к стенду: API и UI
На этапе теста есть два рабочих подхода:
- открыть порты наружу (быстрее для демо), но ограничить доступ по IP/ACL и включить токен на API;
- использовать SSH-туннель (без публикации портов наружу), что обычно безопаснее для инженерного теста.
В этой инструкции используем второй вариант — SSH-туннель. Он безопаснее по умолчанию, потому что сервисы vLLM и Open WebUI остаются доступными только через SSH-подключение, а не через публичные порты. Кроме того не требуется настраивать правила доступа к портам API/UI на периметре для внешнего интернета.
Важно понимать, что SSH-туннель не заменяет аутентификацию. Мы в любом случае включим токен на API, но сам туннель снизит площадь атаки сервиса на уровне сети.
Установка и запуск модели по шагам
Переходим к основной части — развертыванию и запуску Qwen. В этом разделе мы поднимем модель как сервис инференса, настроим кэш Hugging Face на диске и проверим, что эндпоинт работает: GPU доступен, модель загрузилась, API отвечает и защищен токеном.
1. Подключение к серверу и базовые проверки
Подключаемся к серверу по SSH. В macOS и Linux это делается через стандартный терминал, в Windows через PowerShell или командную строку:
ssh <user>@<server_ip>
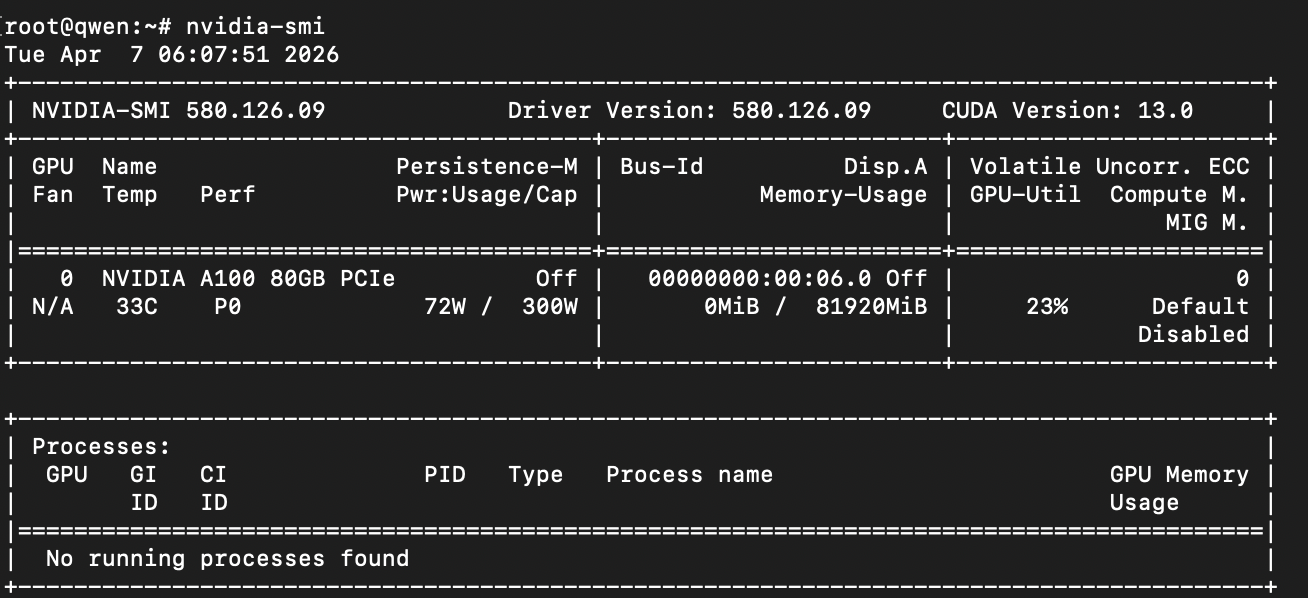
Проверяем GPU:
nvidia-smi
А затем и свободное место на диске:
df -h
2. Настройка кэша Hugging Face на диске
Создаем каталог под кэш и фиксируем переменные окружения. Это важно: при
корректном кэшировании повторные запуски не начинают загрузку модели заново.
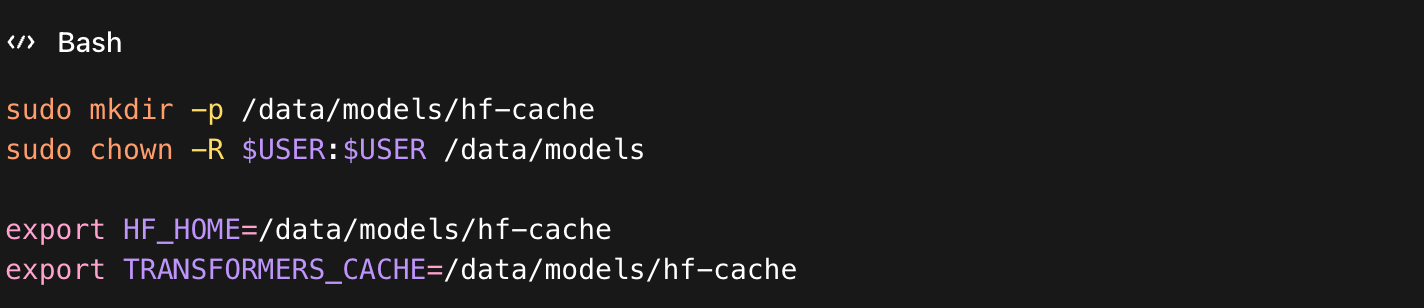
Нюанс: если не задать HF_HOME/TRANSFORMERS_CACHE, кэш уйдет в домашний каталог пользователя. На облачных инстансах он часто размещен на небольшом системном диске, места на котором для весов Qwen точно не хватит.
3. Python-окружение и установка vLLM
Ставим Python и создаем изолированное окружение (venv) — это упрощает воспроизводимость и дальнейший перевод запуска в сервис.
sudo apt update
sudo apt install -y python3 python3-venv python3-pip build-essential python3-dev
python3 -m venv ~/venvs/vllm
source ~/venvs/vllm/bin/activate
pip install -U pip
Устанавливаем библиотеку vLLM:
pip install vllm
Проверить корректность установки можно командой:
python -c "import vllm; print(vllm.__version__)"
4. Запуск Qwen через vLLM
Фиксируем идентификатор модели и токен доступа. MODEL_ID должен совпадать с model id на Hugging Face.
export MODEL_ID="Qwen/Qwen3-30B-A3B-Instruct-2507"
export VLLM_API_KEY="PASTE_YOUR_TOKEN_HERE"
Токен лучше предварительно прописать в переменную на сервере — так с ним удобнее работать и он не «засветится» в истории команд.
printf "%s" "$VLLM_API_KEY" > ~/.vllm_api_key && chmod 600 ~/.vllm_api_key
Запускаем сервер vLLM. Ограничим длину контекста, чтобы KV-кэш точно поместился в доступную VRAM:
vllm serve "$MODEL_ID" \
--host 0.0.0.0 \
--port 8081 \
--dtype auto \
--api-key "$VLLM_API_KEY" \
--max-model-len 16384
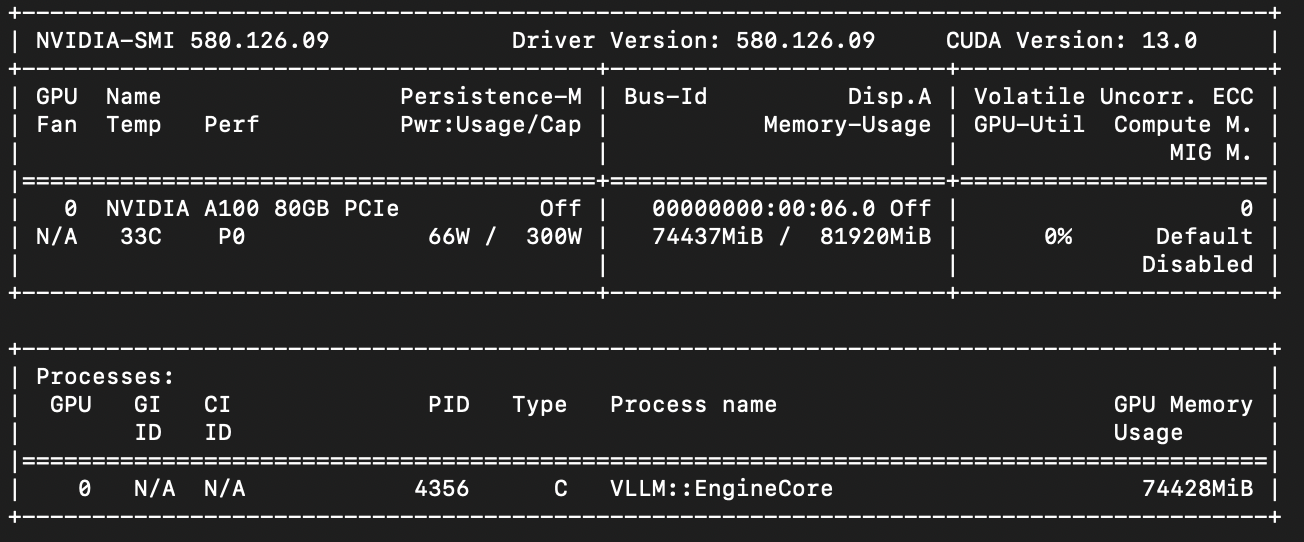
Что наблюдаем при первом запуске:
- первый старт займет время, из-за скачивания весов и прогрева;
- в nvidia-smi появится процесс vLLM и потребление VRAM;
- в логах будет видно, что сервер поднялся и слушает порт.
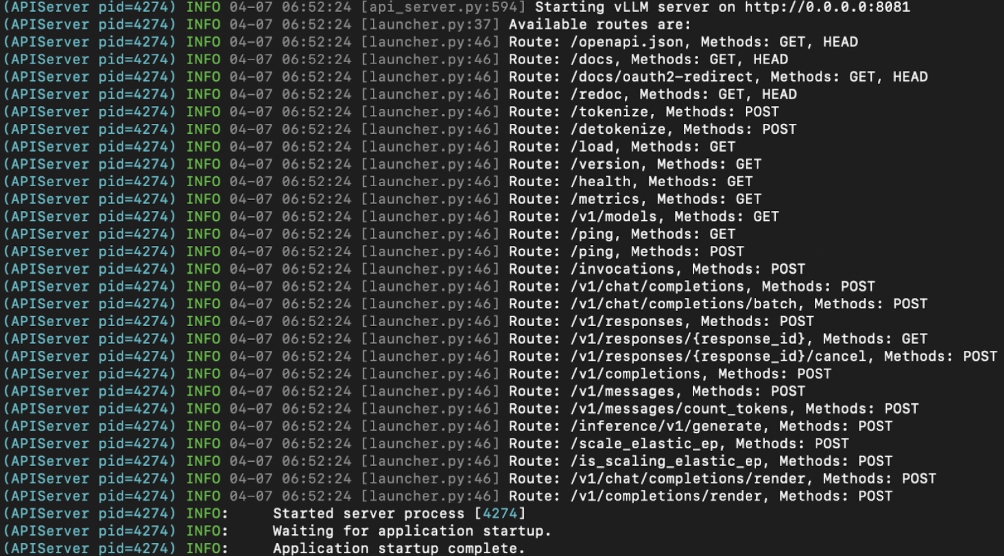
5. Проверка эндпоинта и генерации (локально на сервере)
Для текстов откройте вторую SSH-сессию или второе окно терминала. В новой сессии заново экспортируйте VLLM_API_KEY, если вы не прописывали его или в файле/~/.bashrc. При этом в первой сессии процесс vllm serve должен продолжать работать.
Проверяем, что эндпоинт доступен и авторизация включена:
curl -s http://localhost:8081/v1/models \
-H "Authorization: Bearer ${VLLM_API_KEY}" | head
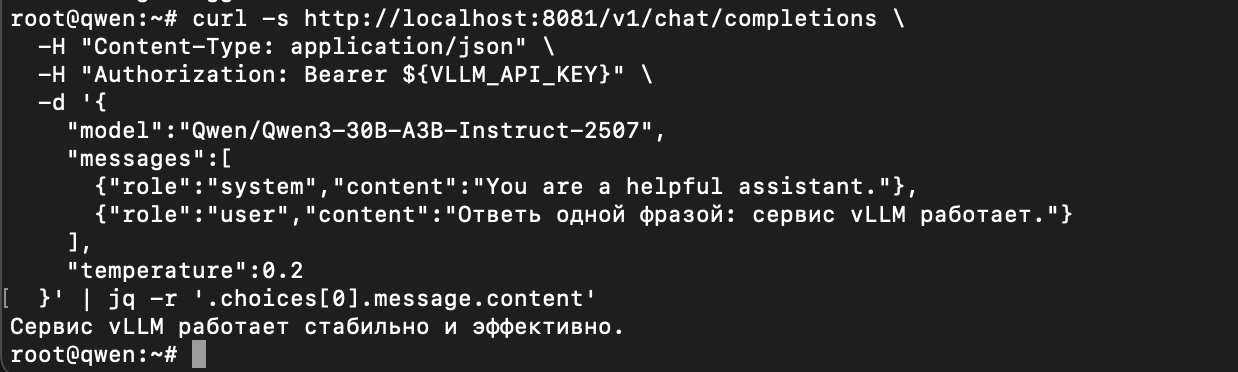
Проверяем генерацию ответа:
curl -s http://localhost:8081/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${VLLM_API_KEY}" \
-d '{
"model":"Qwen/Qwen3-30B-A3B-Instruct-2507",
"messages":[
{"role":"system","content":"You are a helpful assistant."},
{"role":"user","content":"Ответь одной фразой: сервис vLLM работает"}
],
"temperature":0.2
}' | head -c 1200
Критерий успешного запуска:
- эндпоинт /v1/models отвечает и возвращает список моделей;
- эндпоинт /v1/chat/completions отдает осмысленный ответ;
- в логах vLLM в первом терминале видно обработку запроса.
6. SSH-туннель для доступа с macOS (API и UI)
Так как мы не открывали порты сервера наружу, для доступа к модели с локальной машины используем SSH. В терминале выполните команду:
ssh -L 8081:localhost:8081 -L 3000:localhost:3000 <user>@<server_ip>
После этого API будет доступен локально http://localhost:8081/v1.
Если вы планируете запускать Open WebUI в Docker-контейнере на том же сервере, учитывайте специфику изоляции. Внутри контейнера localhost указывает на сам контейнер, а не на хост. Чтобы Open WebUI увидел API vLLM, в качестве адреса эндпоинта нужно указывать IP-адрес интерфейса docker0 (обычно 172.17.0.1) или использовать флаг –network=host.
7. Контроль состояния и логи
На этом этапе у вас есть рабочий бэкенд. Перед тем как подключать UI, стоит приучить себя проверять два инструмента мониторинга:
- nvidia-smi: помогает следить за утилизацией VRAM. Если вы решите увеличить длину контекста через –max-model-len, именно здесь вы увидите, сколько памяти осталось под задачи генерации.
- Логи контейнера/процесса: vLLM подробно пишет о входящих запросах и состоянии KV-кэша. Это основной источник информации, если API начинает отвечать с задержкой.
Если эндпоинт стабильно отдает JSON в ответ на curl — база готова. Переходим к визуализации.
Open WebUI для теста
После того как vLLM эндпоинт поднят и отвечает, удобно перейти от проверки через curl к интерактивному тесту.
Open WebUI дает минимальный интерфейс для работы с моделью: можно быстро прогонять промты, сравнивать ответы и фиксировать наблюдения без написания клиентского кода.
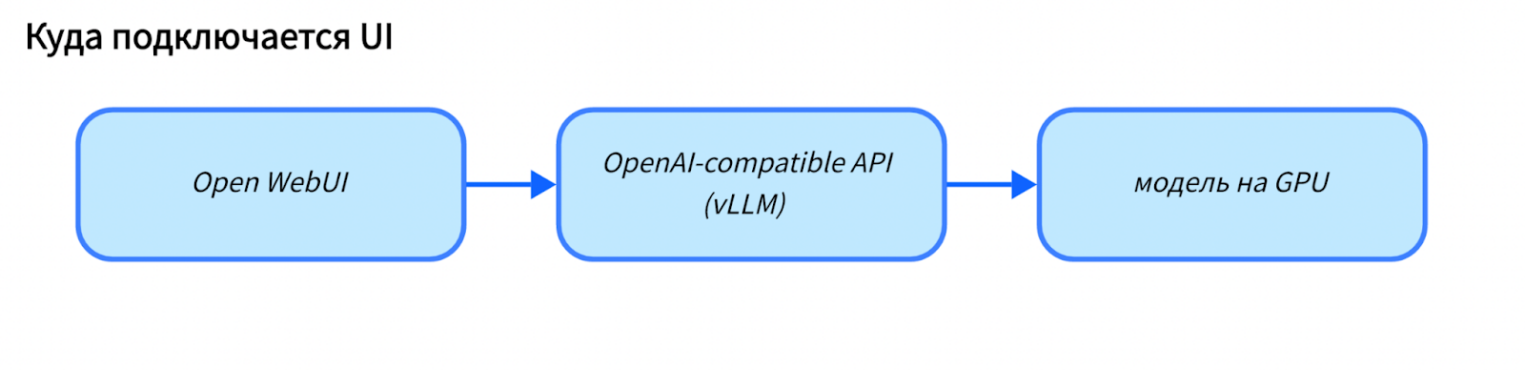
На сервере устанавливаем Docker и добавляем текущего пользователя в группу, чтобы управлять контейнерами без sudo:
sudo apt update
sudo apt install -y docker.io
sudo systemctl enable --now docker
sudo usermod -aG docker $USER
newgrp docker
docker version

Теперь запускаем контейнер Open WebUI. Чтобы интерфейс «увидел» наш эндпоинт vLLM, нужно передать адрес API и токен через переменные окружения.
docker pull ghcr.io/open-webui/open-webui:main
docker run -d \
--name open-webui \
-p 3000:8080 \
-v open-webui:/app/backend/data \
--restart unless-stopped \
ghcr.io/open-webui/open-webui:main
Проверяем, что контейнер работает:
docker ps

Создаем защищенный туннель. Если туннель для API уже поднят, добавляем проброс порта WebUI:
ssh -L 8081:localhost:8081 -L 3000:localhost:3000 <user>@<server_ip>
После этого WebUI будет доступен локально по адресу http://localhost:3000.
Настройка подключения в Open WebUI
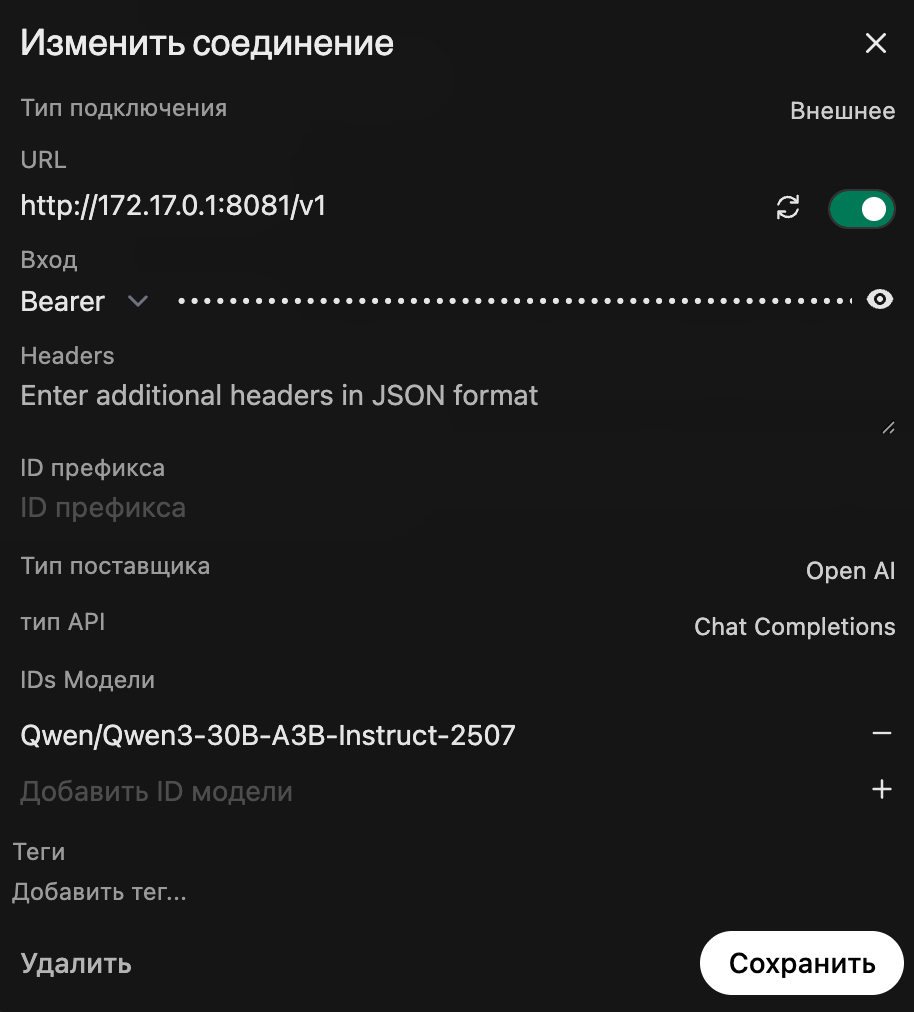
В интерфейсе Open WebUI перейдите в настройки и добавьте подключение к OpenAI-совместимому эндпоинту.
Поскольку WebUI запущен в контейнере, он должен обращаться к серверу через IP-адрес сетевого моста.
Далее вводим команду для получения IP хоста для Docker-контейнеров (docker0):
ip -4 addr show docker0 | grep -oP '(?<=inet\s)\d+(\.\d+){3}'
Используйте полученные данные для настройки в веб-интерфейсе:
- Base URL — http://<docker0_ip>:8081/v1(где <docker0_ip> — адрес, полученный командой выше- обычно 172.17.0.1);
- API Key — тот же токен, который задан при запуске vLLM (VLLM_API_KEY).
После подключения модель уже работает.
Дальше можно настраивать системный промт и работать с моделью.
В рамках тестового контура мы минимизируем сетевую экспозицию: не публикуем порты API и UI наружу, работаем с ними только через SSH-туннель. Дополнительно включаем токен на vLLM эндпоинт, чтобы доступ к API оставался контролируемым даже внутри туннеля.
Расширение и эксплуатация
После тестового запуска стоит привести стенд к виду «продакшен-контура»: чтобы сервис переживал перезапуски, был наблюдаемым и не выставлял API/UI наружу без контроля.
Запускать vllm serve вручную в SSH-сессии неудобно. Для стабильной работы стоит перенести запуск в systemd или контейнер с restart policy. Это обеспечивает автозапуск после перезагрузки и автоматический перезапуск при падении.
Для защиты контура достаточно держаться трех правил:
- сетевой периметр — API доступен только из доверенной сети (VPC/VPN) или через периметр (proxy/gateway). Прямые порты vLLM и WebUI в интернет не публикуются;
- аутентификация — токен на API остается обязательным, ключи хранятся вне репозитория и подлежат ротации;
- лимиты — на входе появляются rate limiting/таймауты и ограничения на размер запроса, чтобы защититься от ошибок клиентов и неконтролируемой нагрузки.Когда стенд превращается в сервис, обычно первыми параметрами которые «упираются», становяться объем VRAM и:латентность на p95/p99.
Дальше масштабирование идет двумя путями:
- вертикально — больше ресурсов на одном инстансе;
- горизонтально — несколько инстансов и балансировка.
Следующим логичным шагом будет собрать поверх эндпоинта прикладной сценарий: например, RAG/поиск по документации. Это отдельная тема, но базовый элемент уже готов: стабильный эндпоинт инференса с контролируемым доступом и повторяемым запуском.
Итог
Мы собрали стек, который позволяет перевести задачи инференса на свои мощности, сохранив привычный интерфейс OpenAI API. Главная фишка vLLM здесь в том, что он превращает «голую» модель в управляемый сервис: с предсказуемым потреблением
VRAM и готовой очередью запросов.
Это хороший фундамент для разработки. На такой базе можно собирать RAG-системы или внутренних ассистентов, не переживая за приватность данных и не завися от лимитов или доступности внешних провайдеров.