

Когда вы в последний раз очищали БД от старых записей? А ведь раздувание таблиц и индексов в PostgreSQL из-за неактуальных данных — один из часто недооцениваемых источников «тихих» деградаций. Запросы потихоньку становятся медленнее, бэкапы — тяжелее, а место на диске расходуется неэффективно. В итоге любое лишнее уведомление от алерта или доля секунды задержки могут обернуться сбоем системы.
На связи Александр Гришин. Я руковожу развитием облачных баз данных и S3-хранилища в Selectel. В этой статье предлагаю разобраться с одной из тех проблем, которые редко попадают в мониторинг, но легко становятся причиной инцидентов в проде. Материал будет полезен инженерам, поддерживающим PostgreSQL в продакшене, разработчикам облачных приложений и SaaS-сервисов и просто любопытным, кто стремится лучше понять, что происходит под капотом PostgreSQL в разных ситуациях. Погнали!
Откуда берется bloat
Bloat (раздувание) — это состояние, когда таблица или индекс занимает на диске значительно больше места, чем реально нужно. Причиной может быть механизм MVCC (многоверсионность), используемый PostgreSQL для обеспечения согласованности транзакций и параллелизма. Вот как это работает.
При выполнении запросов UPDATE или DELETE, старые версии строк помечаются «мертвыми», но физически остаются в файле на диске:
- UPDATE — на диске остается старая строка и появляется новая;
- DELETE — на диске остается старая строка, помеченная как dead.
Получается, что чем чаще меняются данные, тем больше пустого места образуется внутри страниц таблицы и индексов. Таблица раздувается, файл на диске растет, падает cache hit ratio, растут I/O, а планировщик отрабатывает менее оптимально. Подробнее эту проблему я уже разбирал в статье об оптимизации PostgreSQL. И как обещал, раскрываю тему дальше — посмотрим, как можно с этим бороться.
Для начала предлагаю вам посмотреть на физический размер вашей таблицы. Например, вот таким образом:
-- Размер таблицы на диске (в байтах)
SELECT pg_relation_size('your_table');
-- В человекочитаемом формате
SELECT pg_size_pretty(pg_relation_size('your_table'));
Что дает стандартный VACUUM
VACUUM — это команда в PostgreSQL, которая используется для очистки базы данных от «мертвых» (неактуальных) строк и освобождения занимаемого ими места. VACUUM очищает их, чтобы вернуть пространство обратно системе и предотвратить раздувание таблиц. А еще обновляет статистику, важную для EXPLAIN — встроенного оптимизатора запросов.
Есть несколько видов команды.
- VACUUM — просто помечает устаревшие строки как доступные для повторного использования (как reusable). Не уменьшает физический размер файлов таблицы.
- VACUUM FULL — выполняет более глубокую очистку, уплотняет таблицу и возвращает свободное место обратно операционной системе, уменьшая физический размер файла. Этот процесс требует блокировки таблицы, поэтому выполняется дольше и блокирует другие операции.
- AUTOVACUUM — автоматический процесс в PostgreSQL, который запускается в фоне и периодически выполняет VACUUM для поддержания здоровья базы.
VACUUM FULL решает проблему полностью, но эксклюзивно блокирует таблицу. Для продакшн‑нагрузки это почти всегда неприемлемо.
Пример
Допустим, есть таблица на 1 ГБ и вы удаляете 70% строк. Рассмотрим, как это работает.
- Выполняем VACUUM. Таблица все еще весит 1 ГБ на уровне файловой системы в ОС, но ~700 МБ может быть повторно использовано PostgreSQL.
- После VACUUM FULL таблица сжимается, допустим, до 300 МБ, т. к. PostgreSQL копирует только живые строки в новый файл, а затем подменяет им старый, освобождая место на уровне ОС.
Простая команда:
VACUUM;
- Очищает все таблицы в текущей базе от «мертвых» строк.
- Не блокирует операции SELECT, INSERT, UPDATE, DELETE.
- Не уменьшает физический размер файлов (файлы таблиц остаются того же размера).
- Освобождает место для повторного использования при вставках.
Можно запустить VACUUM для конкретной таблицы:
VACUUM public.orders;
- Очищает только таблицу orders в схеме public.
Добавим обновление статистики для планировщика запросов:
VACUUM ANALYZE public.orders;
- Одновременно очищает таблицу и собирает статистику (анализирует распределение данных).
- Статистика используется планировщиком запросов для оптимизации выполнения запросов.
Полностью перепишим таблицу в новый файл:
VACUUM FULL products;
- Делает полную очистку таблицы products и сжимает ее, уменьшая размер на диске.
- Физически перемещает строки и освобождает место, возвращая его операционной системе.
- Требует эксклюзивной блокировки таблицы — другие операции с таблицей будут ждать завершения.
- Используется, если таблица сильно раздулась (например, после массового удаления).
Дополнительно для лучшего понимания механики работы можно использовать параметр VERBOSE. Он выводит подробную информацию о процессе вакуума.
VACUUM VERBOSE public.orders;
Пример вывода:

Простая аналогия
Эта механика станет понятнее, если представить таблицу в PostgreSQL как обычный рабочий блокнот.
- Файл таблицы на уровне ОС — это бумажный блокнот.
- Каждая строка — это строка в блокноте.
- Когда мы удаляем строку (через DELETE), PostgreSQL просто зачеркивает ее, но не вырывает лист.
- VACUUM смотрит на зачеркнутые строки и помечает их как «теперь доступные». В будущем PostgreSQL сможет снова записать туда что-то.
- Но блокнот сам по себе не становится тоньше — его физический объем не изменился.
Теперь рассмотрим механику работы VACUUM FULL в этой аналогии.
- Таблица — это все тот же блокнот, в котором мы постоянно что-то записываем, зачеркиваем и исправляем.
- Со временем в блокноте становится много зачеркнутых строк, и он выглядит захламленном.
- PostgreSQL мог бы продолжать писать между зачеркнутыми строками (что и делает обычный VACUUM), но кажется, что место используется неэффективно.
- Мы можем взять новый чистый блокнот.
- Переписать в него только актуальные, нужные строки.
- После этого заменить старый захламленный блокнот на новый.
- На все время работы мы блокируем старый блокнот для новых изменений.
Как работает pg_repack
pg_repack — это расширение для PostgreSQL, которое удаляет мертвые строки, оставшиеся после DELETE и UPDATE. Это позволяет дефрагментировать и компактно переписать таблицу или индекс без блокировки таблицы, в отличие от VACUUM FULL.
- Создает временную «чистую» таблицу‑копию и индексы.
- Копирует в нее все актуальные данные.
- Следит за всеми изменениями в оригинальной таблице (использует триггеры и лог WAL).
- Догоняет изменения, произошедшие в исходной таблице.
- Переключает имена таблиц за доли секунды.
- Удаляет старый bloat‑файл.
Блокировка все еще нужна, но только на пятом шаге и длится миллисекунды.
Сравнение
| Механизм | Освобождает место | Уменьшает размер файла | Требует блокировку |
| VACUUM | Да | Нет | Нет |
| VACUUM FULL | Да | Да | Да |
| pg_repack | Да | Да | Только на финальной фазе переключения таблиц |
Аналогия для pg_repack
Продолжим представлять таблицу PostgreSQL как рабочий блокнот, в котором мы много пишем, зачеркиваем, иногда полностью переписываем всю информацию в новый.
- Мы понимаем, что блокнот раздулся от зачеркнутых строк, и его пора менять.
- Раньше мы останавливали все, чтобы сесть и вручную перенести актуальные данные в новый блокнот (VACUUM FULL). Но сегодня нам нельзя прерывать работу — кто-то все еще читает и пишет в наш блокнот!
- Тогда мы заводим новый блокнот рядом и говорим pg_repack: «Садись рядом со мной и переписывай актуальные данные в чистовую копию. Но учти, я буду продолжать работать со старым блокнотом, а тебе нужно следить за изменениями, которые я буду вносить, и тоже добавлять и удалять их в этом новом блокноте. Когда догонишь меня, мы переключим нагрузку на новый блокнот».
pg_repack начинает:
- копировать живые строки из старого блокнота в новый;
- следить за всеми новыми записями;
- параллельно добавлять их в новый блокнот тоже;
- когда все готово, быстро меняет местами старый и новый блокнот с минимальной блокировкой (обычно несколько сотен миллисекунд).
pg_repack в DBaaS Selectel
В сервисе баз данных Selectel расширение ставится кликом в панели, после чего функции pg_repack становятся доступны из PostgreSQL. С полным списком поддерживаемых расширений можно ознакомиться в документации.
1. Разверните кластер в панели управления.
2. Создайте пользователя.
3. Создайте базу данных.
4. Добавьте расширение
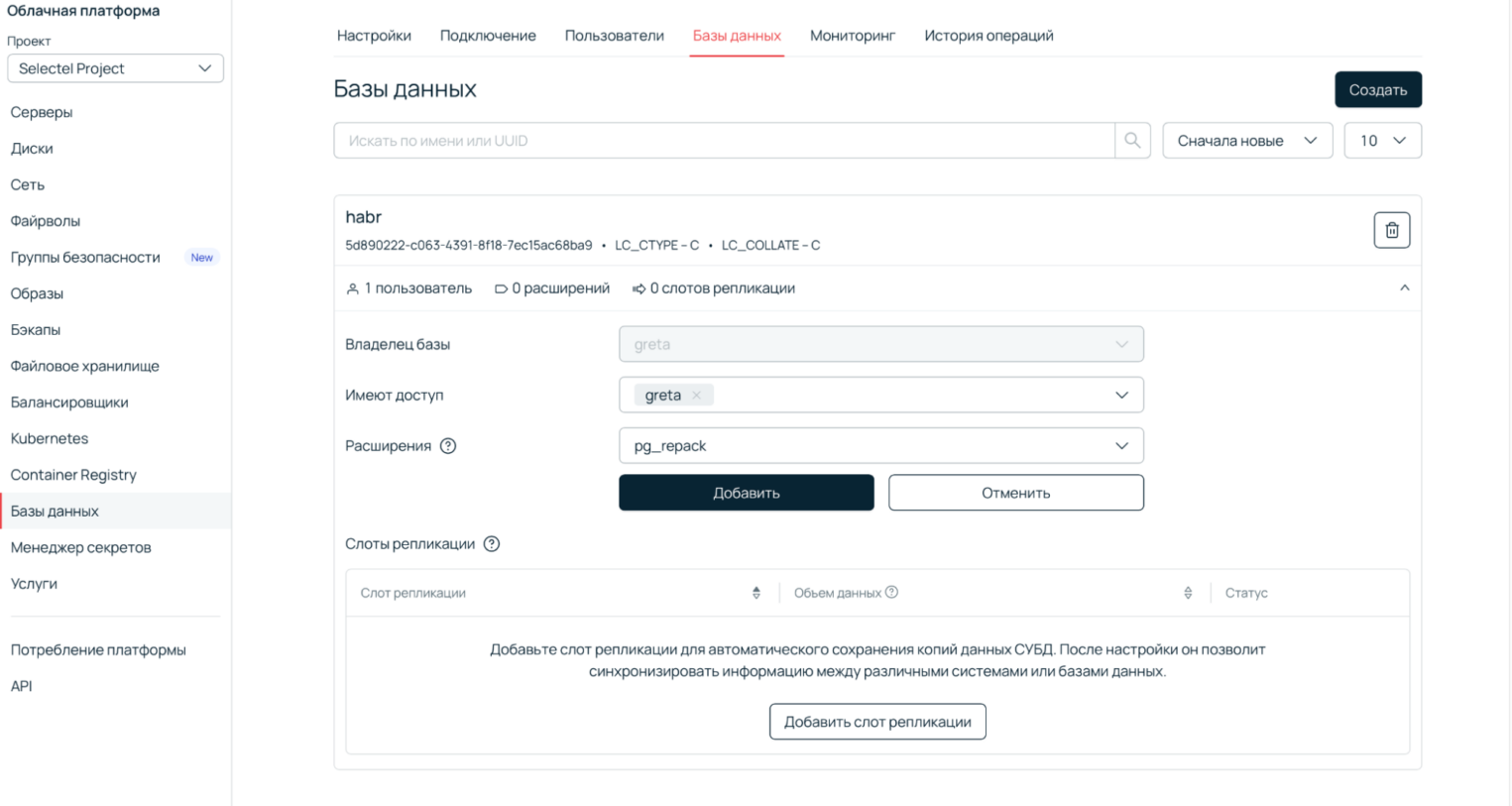
5. Подключитесь и используйте готовую облачную базу данных.
Рассмотрим расширение детальнее
Шаг 1. Подготовим тестовую таблицу и искусственно раздуем ее:
-- Создаем таблицу с 1 млн строк, каждая с payload ~100 байт
CREATE TABLE bloated AS
SELECT id, repeat('x', 100) AS payload
FROM generate_series(1, 1000000) AS id;
Для этого обновим 50% строк, чтобы создать «мертвые» версии старых данных:
UPDATE bloated
SET payload = repeat('y', 100)
WHERE id % 2 = 0;
Шаг 2. Измерим размер до репака:
SELECT pg_size_pretty(pg_total_relation_size('bloated')) AS size_before;
-- Результат: ~200 MB
Шаг 3. В управляемой базе данных Selectel DBaaS его нужно запускать с клиентской машины, подключаясь по внешнему адресу:
pg_repack -k -h <host> -p 6432 \
-U <user> \
-d <database>;
После запуска утилита автоматически создаёт копию таблицы, переносит данные без «мусора» и атомарно подменяет оригинальную таблицу. DML-операции при этом ставятся на короткую паузу в конце процесса (на этапе переключения).
Шаг 4. Проверим размер после:
SELECT pg_size_pretty(pg_total_relation_size('bloated')) AS size_after;
-- Новый результат: ~110 MB
Сравнение
| Метод | Размер «до» | Размер «после» | Время выполнения | Доступ к таблице |
| VACUUM | 200 MB | 200 MB | 3 s | доступна |
| VACUUM FULL | 200 MB | 100 MB | 15 s | заблокирована |
| pg_repack | 200 MB | 100 MB* | 8 s | доступна (pause ≤ 200 мс) |
*Почему размер новой таблицы в результате работы pg_repack может быть больше? Дело в том, что во время работы pg_repack в оригинальную таблицу могли приходить новые транзакции (INSERT/UPDATE/DELETE), и они тоже переносятся в новую таблицу.
Ограничения и грабли
Каждый новый инструмент имеет свои особенности и ограничения, которые полезно принимать во внимание:
- Учитывая описанную выше механику работы, нужен запас диска, примерно равный или больший, чем репакуемая таблица.
- Таблица должна иметь первичный ключ или уникальный индекс для корректной идентификации строк.
- Может дать сильная I/O‑нагрузка: лучше запускать вне пикового окна. И обязательно использовать быстрые диски. Подробнее уже рассказывал в статье о том, что нужно PostgreSQL.
- Работает на версиях PostgreSQL после 9.1.
- Для крупных таблиц (сотни гигабайт и выше) репак займет часы — стоит учитывать это при планировании и запускать его в вечернее или ночное окно.
Магии не бывает. Фактически утилита просто переписывает данные из одной таблицы в другую. Это, с одной стороны, позволяет вам обслуживать систему без даунтайма. А с другой, займет больше ресурсов.
Стоит иметь в виду, что интенсивная нагрузка на изменения оригинальной таблицы во время репака сведет на нет всю пользу от данной процедуры. Поэтому в некоторых случаях вам все равно не обойтись без VACUUM FULL. Всегда держите в плане эксплуатации регламентированные окна для обслуживания вашей системы.
Итоги
- Bloat в PostgreSQL — это не баг, а фича. Побочный эффект MVCC: старые версии строк не удаляются сразу, а копятся в таблице.
- VACUUM размечает старые строки как переиспользуемые, но не освобождает физически место на диске.
- VACUUM FULL удаляет bloat, но блокирует таблицу на все время операции.
- pg_repack убирает bloat почти без простоя и может подойти для обслуживания при невысокой нагрузке на СУБД.
- Автоматизация возможна: SQL-скрипт с repack.repack_table() можно запускать из внешнего планировщика по расписанию.
Если вы замечаете, что запросы стали выполняться медленнее, а размер базы данных растет быстрее, чем ожидалось, pg_repack может дать быстрый и безопасный прирост производительности, особенно в среде с высокими SLA и ограниченным доступом к серверу.
Попробуйте использовать pg_repack в составе облачного PostgreSQL от Selectel — установка в один клик, запуск прямо из SQL и никакой возни с настройкой расширений на сервере.
А еще мы в Selectel недавно выпустили ультимативный по производительности сервис — первый в России DBaaS на выделенных серверах. Подробнее об этой услуге я уже рассказывал в другой статье.
В обозримом будущем я продолжу эту тему и расскажу о других полезных расширениях для PostgreSQL.





