

Итак, ваш проект вырос и вам потребовалась новая функциональность, будь то рекомендательный движок, база знаний или автоматизированная первая линия техподдержки. Для всего этого можно использовать векторный и/или семантический поиск, а также интегрировать в проект LLM. Поздравляю — теперь вам нужно еще и хранить embedding-векторы, а также искать по ним ближайшие объекты. Решений два: внешняя векторная БД или интеграция всего этого богатства в существующий стек. Второй путь проще на старте, немного быстрее и обычно дешевле — разумеется, если вы уже используете PostgreSQL.
Если вы это читаете, то, скорее всего, уже используете PostgreSQL. Возможно, вы не хотите сразу разворачивать отдельную инфраструктуру под векторный поиск, планируете попробовать работу с embedding’ами от OpenAI, Cohere, HuggingFace и других моделей, планируете строить или уже строите RAG-системы, рекомендательные движки, семантический поиск или базу знаний в MVP-формате.
Зачем вообще нужен векторный поиск
Когда вы работаете с embedding’ами от LLM, вы неизбежно сталкиваетесь со следующей задачей. Приходит запрос клиента и нужно быстро находить похожие объекты по вектору.
Вот типовые примеры таких задач.
- Семантический поиск. В отличие от классического поиска по ключевым словам, семантический поиск позволяет находить документы по смыслу. Например, если пользователь ищет, как сделать бэкап БД, система найдет статьи, в которых не обязательно есть эти слова, но описаны релевантные процессы.
- RAG-пайплайны (Retrieval-Augmented Generation). Эта архитектура объединяет LLM и внешнюю базу знаний. Когда пользователь задает вопрос, система сначала находит релевантные документы по векторной близости, а затем передает их LLM для генерации ответа. Так работают продвинутые чат-боты, корпоративные ассистенты и интерфейсы к документации.
- Рекомендательные системы. Вместо жестких правил («похожие жанры», «покупали вместе») можно анализировать embedding-профили ваших пользователей и объектов. А после рекомендовать песни, статьи, фильмы, товары, даже если они текстово совершенно разные, однако имеют схожую векторную репрезентацию.
- Классификаторы. В embedding-пространстве можно обучать модели, которые определяют категорию, тональность или тематику документа. Один из подходов задать центроиды для каждого класса (например, «позитив», «негатив», «нейтрально»), а затем относить новый документ к ближайшему по векторному расстоянию. Также применяются k-NN-модели, которые ищут несколько ближайших примеров с известной меткой и определяют класс по большинству. Например, можно классифицировать отзывы пользователей по тону, статьи по теме, а письма по отделу, которому они адресованы.
Индустрия предлагает широкий спектр специализированных инфраструктурных решений для таких задач: Faiss, Milvus, Pinecone, Qdrant, Weaviate, Vespa. Но так как я люблю PostgreSQL, то не могу не рассказать о возможной альтернативе на ее базе. Это дает возможность пощупать новое без зоопарка технологий и разрозненных API — прямо в PostgreSQL.
Что такое pgvector
Итак, pgvector — это расширение к PostgreSQL, которое добавляет тип данных vector и операторы поиска по расстоянию. Поддерживаются три основные метрики сравнения векторов.
- L2 (евклидово расстояние). Классическое расстояние между двумя точками в многомерном пространстве. Хорошо работает, если векторы не нормализованы и распределение значений относительно равномерное.
- Cosine similarity (косинусное сходство). В отличие от предыдущей метрики измеряет не абсолютное расстояние, а угол между двумя векторами. Подходит для текстовых embedding’ов, где важна направленность, а не масштаб. Требует нормализации векторов (единичная длина).
- Inner product (внутреннее произведение). Скалярное произведение двух векторов. Может использоваться как прокси для оценки «сходства» при обучении моделей и в задачах ранжирования.
Выбор метрики влияет на операторный класс индекса и характер сортировки поблизости. Важно понимать, какая из них подходит под вашу задачу. Например, cosine similarity чаще используется в задачах семантического поиска, а inner product может быть полезен в рекомендательных системах.
Развернем pgvector в облачной базе данных
В облачном PostgreSQL от Selectel pgvector можно установить в пару кликов через панель управления. С полным списком поддерживаемых расширений можно ознакомиться в документации.
1. Разверните кластер в панели управления. Как это сделать, подробно описано в документации.
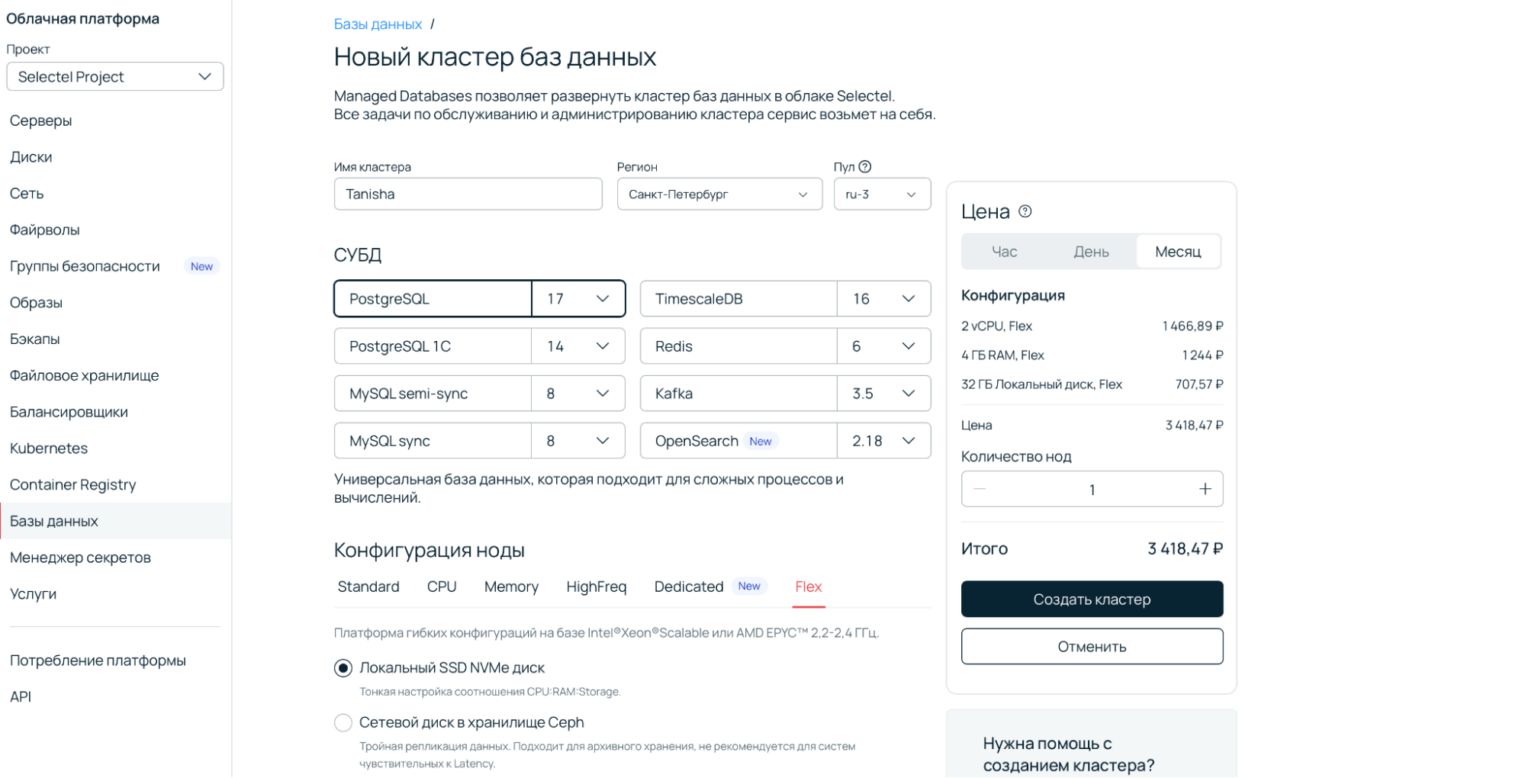
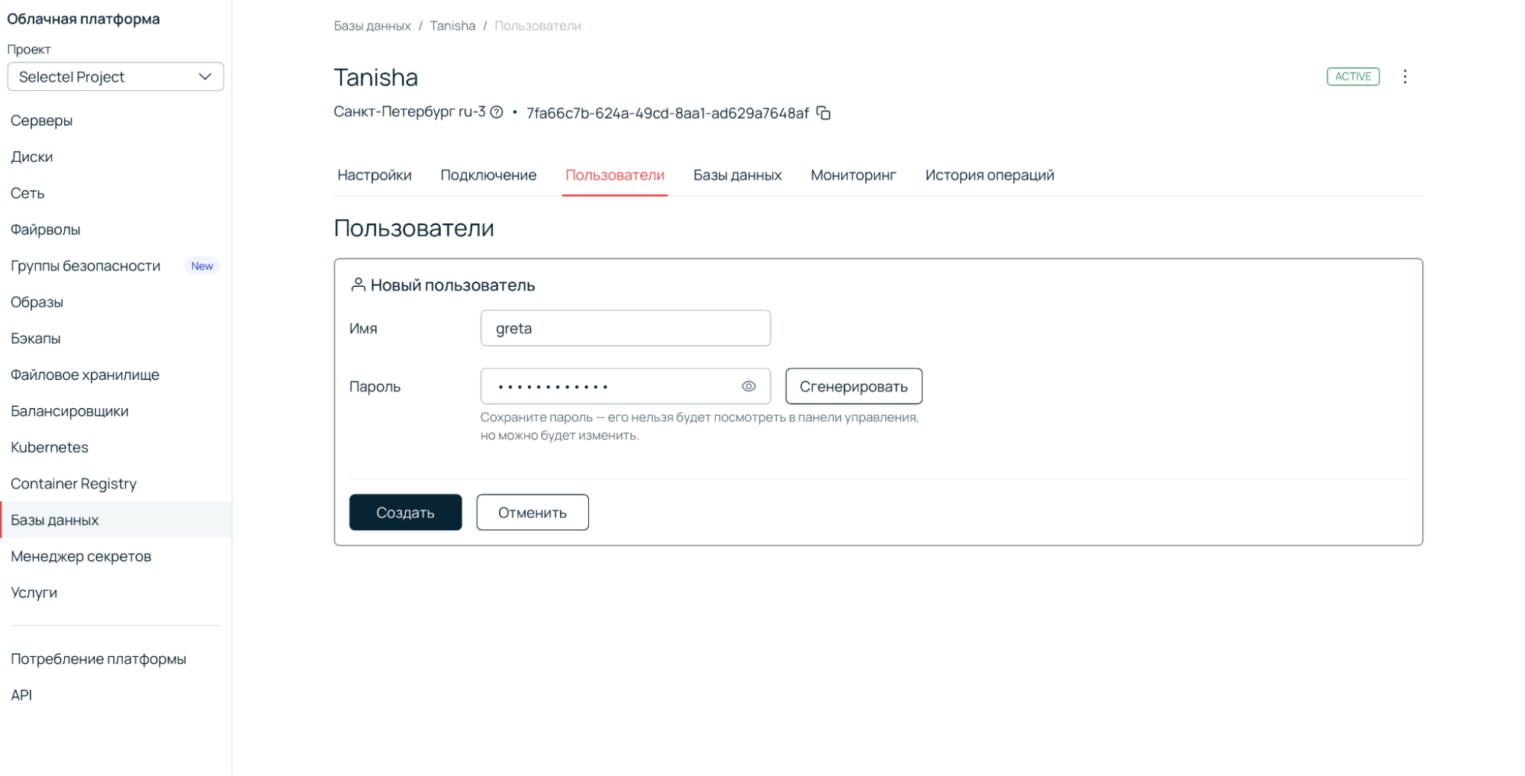
2. Создайте пользователя.
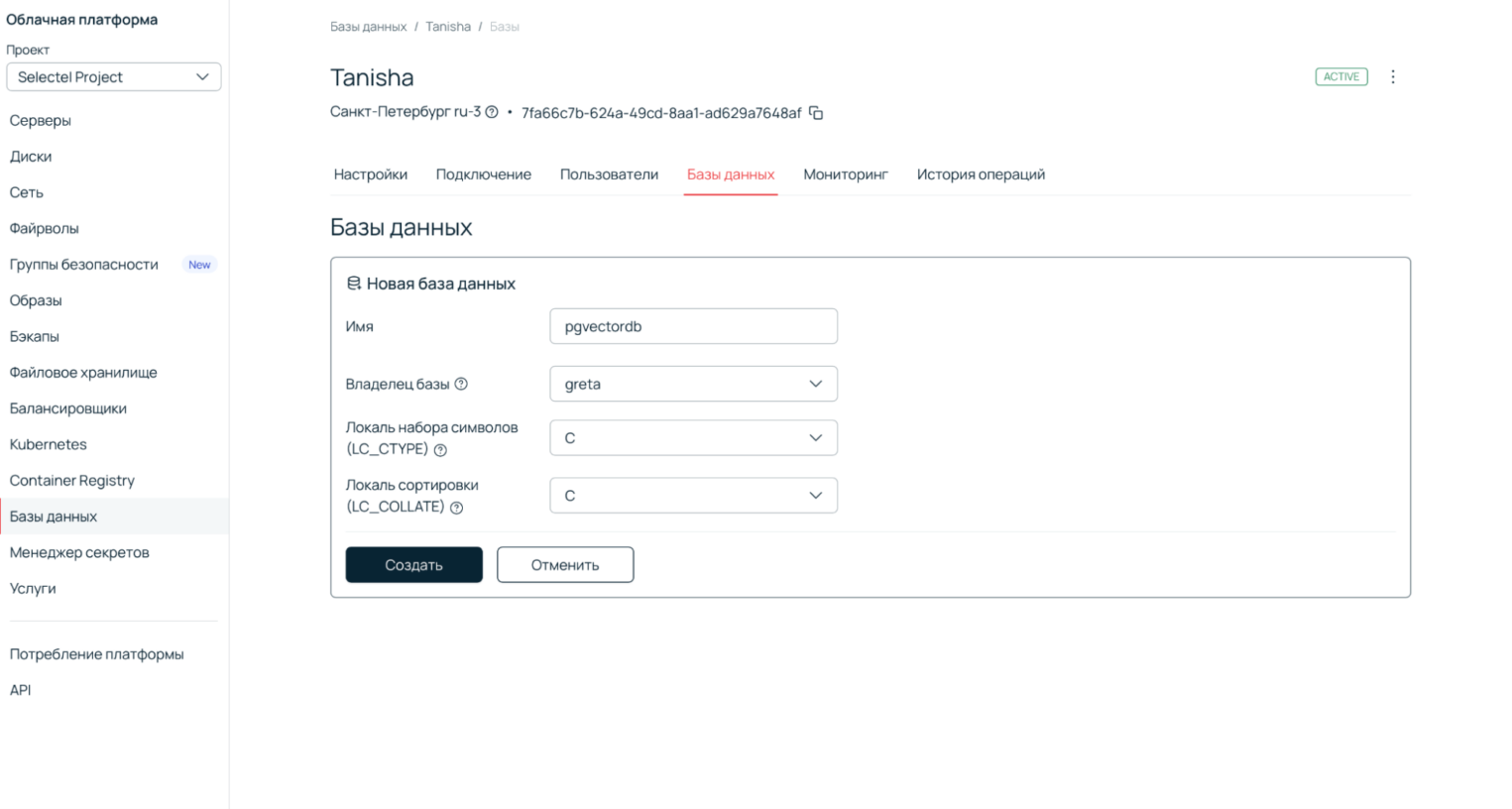
3. Создайте базу данных.
4. Добавьте расширение vector.
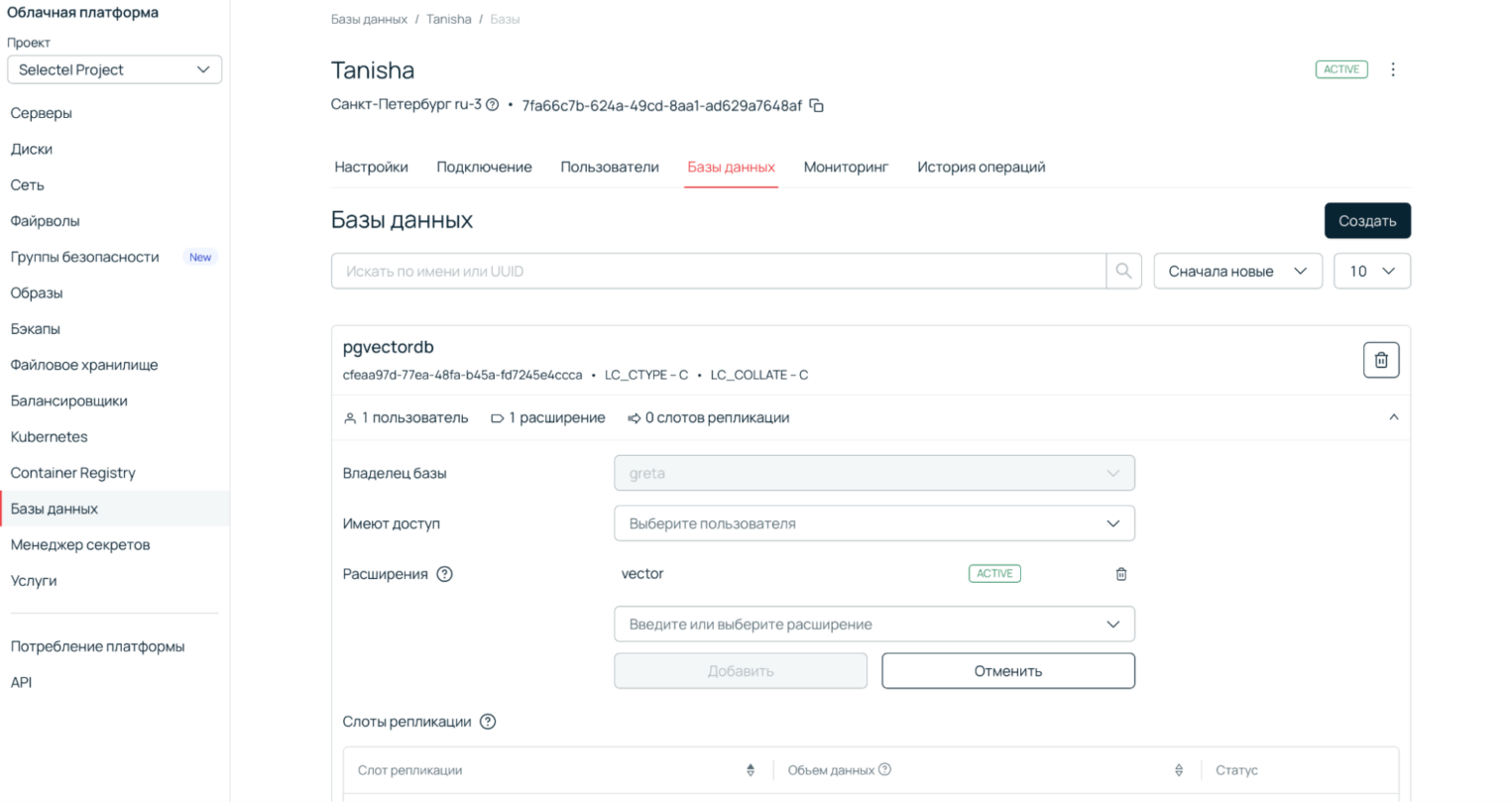
5. Подключитесь и используйте готовую облачную базу данных.
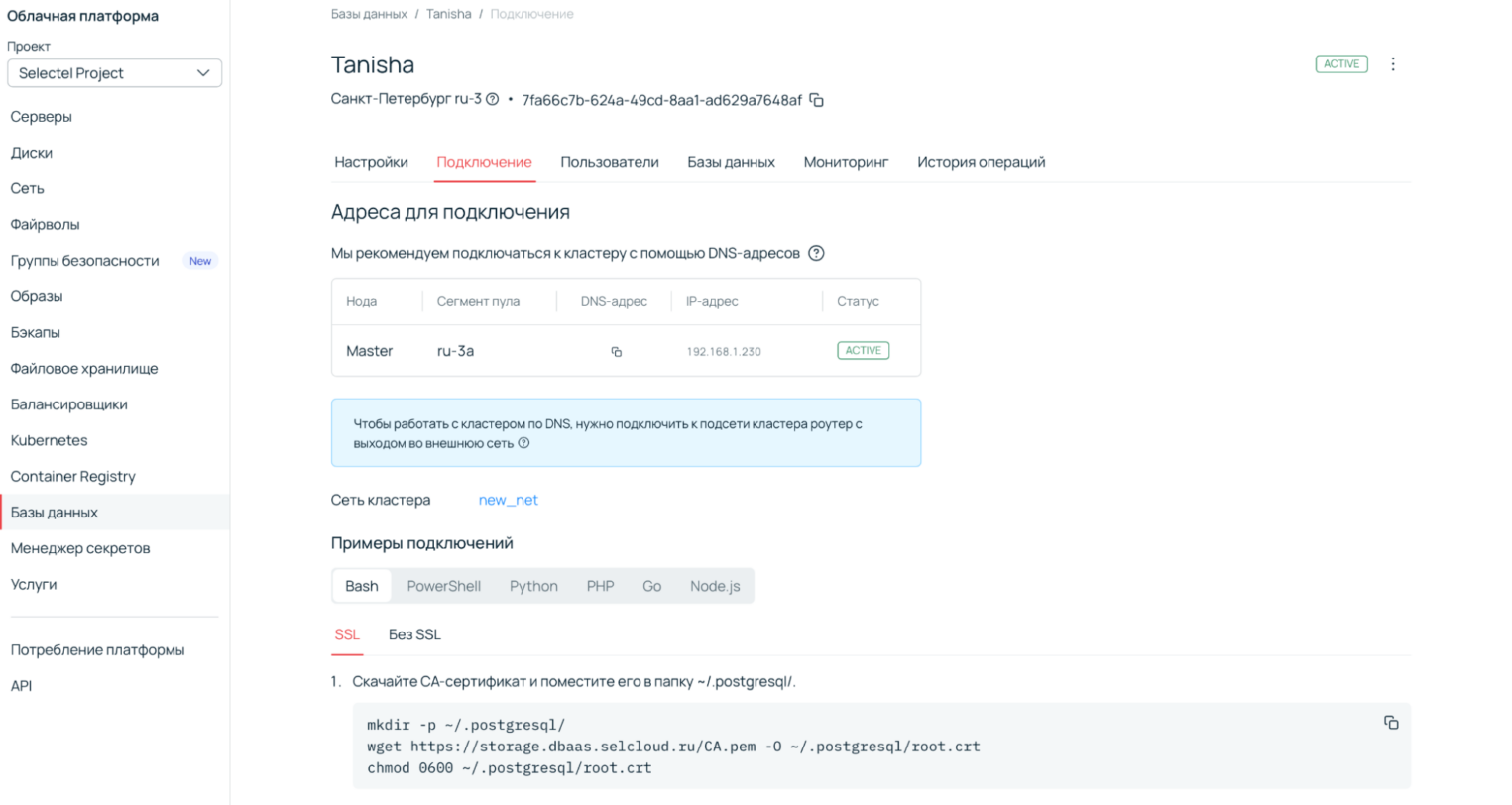
Рассмотрим расширение детальнее
Когда вы передаете текст в модель вроде text-embedding-3-small от OpenAI, она возвращает вектор с размерностью 1 536. Где каждый из 1 536 элементов — это числовое представление одного аспекта смысла или структуры текста. Такие векторы называются embedding’ами:
[0.134, -0.823, 0.521, …, 0.004]
В pgvector это отражается в типе данных — embedding VECTOR(1536). И тогда PostgreSQL будет следить, чтобы каждый вектор точно содержал эти 1 536 значений. Для упрощения повествования дальше будем использовать только три значения.
Допустим, мы получаем на наш запрос именно такой вектор от модели OpenAI. Для хранения создаем таблицу с типом VECTOR:
CREATE TABLE items (
id SERIAL PRIMARY KEY,
title TEXT,
embedding VECTOR(1536)
);
Добавим данные для нескольких embedding-векторов разных объектов:
INSERT INTO items (title, embedding) VALUES
('PostgreSQL embeddings', '[0.10, -0.80, 0.45]'),
('Neural image processing', '[0.42, 0.18, -0.35]'),
('Sound pattern matching', '[-0.20, 0.70, 0.60]'),
('Document clustering', '[0.09, -0.79, 0.48]');
Теперь сравним их попарно и отсортируем по расстоянию:
SELECT
a.title AS title_a,
b.title AS title_b,
a.embedding <-> b.embedding AS distance
FROM items a
JOIN items b ON a.id < b.id
ORDER BY distance;
Здесь оператор <-> вычисляет расстояние между двумя векторами.
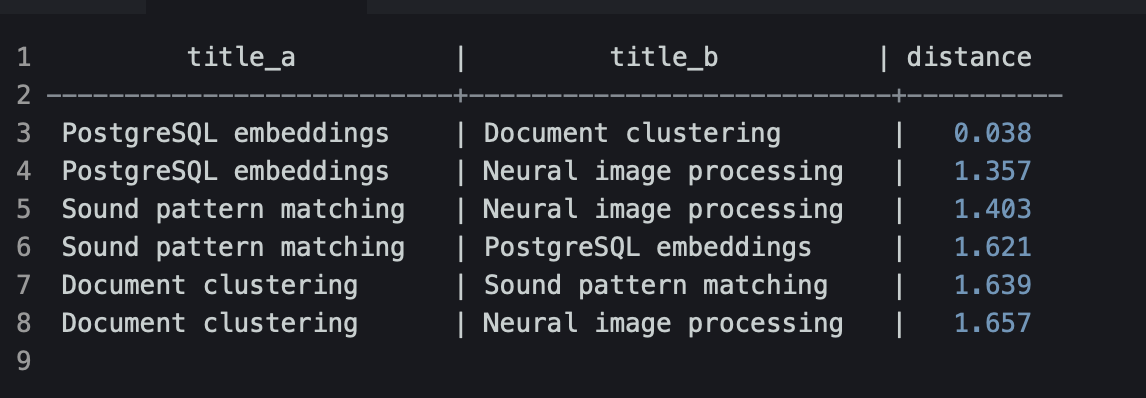
Из вывода видно, что:
- «PostgreSQL embeddings» ближе всего к «Document clustering» — у них почти одинаковые векторы;
- «Sound pattern matching» и «Neural image processing» — ближе друг к другу, чем к текстовым статьям.
Таким образом, мы можем оценивать степень семантической близости любых объектов, представленных векторами. Какая именно метрика используется, зависит от операторного класса, заданного при создании индекса.
Как я уже говорил, в pgvector доступны три варианта. Рассмотрим каждый из них подробнее.
Евклидово расстояние: vector_l2_ops
Стандартная метрика, измеряющая «прямое» расстояние между точками в пространстве. Хорошо подходит, если векторы не нормализованы.
CREATE INDEX ON items USING ivfflat (embedding vector_l2_ops);
SELECT id, embedding, embedding <-> '[0.1, -0.8, 0.5]' AS distance
FROM items
ORDER BY embedding <-> '[0.1, -0.8, 0.5]'
LIMIT 3;
Разберем подробнее, что тут происходит.
- Создаем индекс. Тип индекса — ivfflat: это приближенный метод поиска ближайших соседей (Approximate Nearest Neighbor), реализующий IVF (inverted file index).
- Указываем, что используется операторный класс vector_l2_ops — это значит, что сравнение векторов будет происходить по евклидову расстоянию (L2-норма). Индекс ускоряет поиск ближайших векторов по расстоянию.
- Выбираем id, сам вектор embedding и вычисляем расстояние между этим вектором и заданным вектором-запросом ‘[0.1, -0.8, 0.5]’.
- Оператор <-> — это универсальный оператор «расстояния» в pgvector. В зависимости от выбранного индексного операторного класса (vector_l2_ops), он означает евклидово расстояние.
- Сортируем по возрастанию расстояния и выводим три самых похожих вектора. Т. е. в первую очередь возвращаются векторы, находящиеся ближе всего к заданному.
Вывод может быть каким то таким:
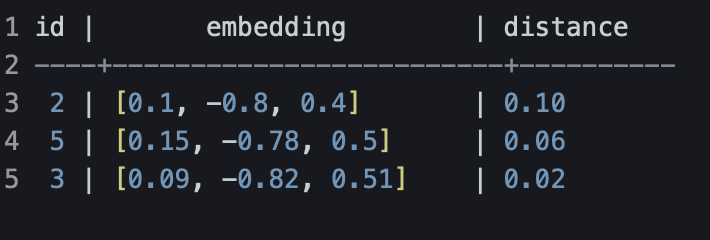
Здесь distance — это скалярное значение, показывающее, насколько далеко embedding из таблицы находится от заданного нами вектора [0.1, -0.8, 0.5] в евклидовом пространстве. Чем меньше значение, тем ближе векторы.
Косинусная мера: vector_cosine_ops
Этот операторный класс измеряет угол между векторами. Тут получается, что важно не расстояние, а направление. Подходит для embedding’ов текста, но требует нормализации векторов (длина = 1).
CREATE INDEX ON items USING ivfflat (embedding vector_cosine_ops);
-- Все векторы должны быть нормализованы заранее
SELECT id, embedding, embedding <-> '[0.1, -0.8, 0.5]' AS similarity
FROM items
ORDER BY embedding <-> '[0.1, -0.8, 0.5]'
LIMIT 3;
Разберем подробнее работу этого запроса.
- Создаем индекс для ускорения поиска по embedding-вектору в колонке embedding.
- Операторный класс vector_cosine_ops — это способ измерения косинусного расстояния, которое показывает угол между векторами.
- Сравниваем каждый вектор из таблицы items с вектором-запросом [0.1, -0.8, 0.5].
- Оператор <-> вызывает расчет расстояния согласно выбранной метрике.
- Псевдоним AS similarity помогает нам отобразить значение косинусной «дистанции» между векторами.
- Сортируем строки от наименьшего косинусного расстояния к наибольшему. Выводим три наиболее похожие.
Результат может быть каким то таким:
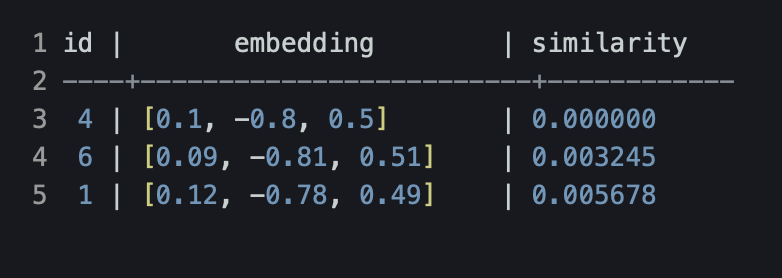
Первая строка показывает точное совпадение, поэтому расстояние = 0. Остальные с минимальными отличиями, но направление у них довольно близкое к запросу.
Чтобы лучше понимать, что значит «близкое», разберем рассчет расстояния в этой метрике. Оно измеряется как косинус угла между векторами и показывает, насколько их направления совпадают:
- cos 0° (одинаковое направление) = 1,
- cos 90° (ортогональные, несвязанные вектора) = 0,
- cos 180° (противоположные направления) = -1.
При этом значение, которое возвращает оператор <-> с vector_cosine_ops, не является напрямую косинусом угла между векторами, а вычисляется как 1 – cos (угла между векторами).
Таким образом, максимальное отличие по косинусной метрике — это расстояние, равное 2. Оно достигается у векторов с противоположным направлением и является крайним случаем — антисмыслом, с противоположной запросу семантикой.
Скалярное произведение: vector_ip_ops
Скалярное произведение измеряет степень сонаправленности векторов. Такой тип оператора подходит в задачах рекомендаций, где важна схожесть предпочтений. Чем больше значение, тем выше степень совпадения интересов.
CREATE INDEX ON items USING ivfflat (embedding vector_ip_ops);
SELECT id, embedding, embedding <-> '[0.1, -0.8, 0.5]' AS inner_product
FROM items
ORDER BY embedding <-> '[0.1, -0.8, 0.5]'
LIMIT 3;
Уже по сложившейся традиции рассмотрим подробнее, что происходит в этом запросе.
- Снова создаем индекс по колонке embedding с использованием метода ivfflat и операторного класса vector_ip_ops, определяющего метрику сравнения (в данном случае это скалярное произведение).
- Извлекаем id и сам вектор embedding, вычисляем расстояние между ним и входным вектором [0.1, -0.8, 0.5].
- Результаты сортируются по мере убывания схожести, возвращаются только три наиболее похожих по направлению вектора.
Пример вывода:
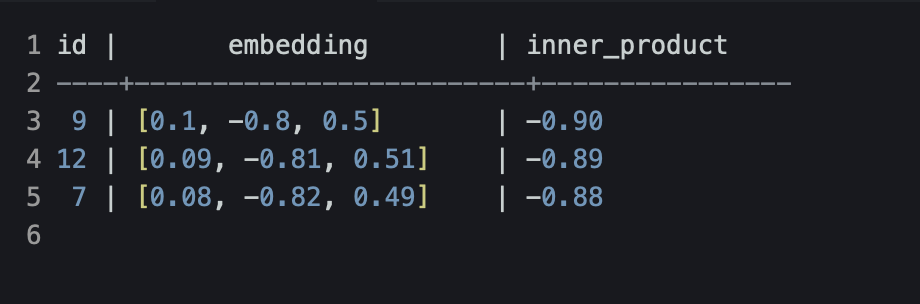
Это может быть полезно, например, для рекомендательных систем. Если embedding пользователя и товара «смотрят» в одну сторону, то, возможно, этот товар релевантен интересам пользователя.
Чтобы избежать полного перебора, мы выше использовали индексы. После загрузки данных не забываем обновить статистику:
ANALYZE items;
Теперь можно делать запросы быстрее.
Что под капотом
Векторы хранятся как массивы float4 и сравниваются через SIMD-инструкции. Индексы реализованы аналогично IVF в Faiss. На данный момент в pgvector нет поддержек:
- HNSW (более точная и быстрая структура),
- Multi-vector запросов (например, объединение нескольких embedding’ов),
- хранения версий или тегов.
ivfflat — это Approximate Nearest Neighbor (ANN). Он не гарантирует, что ближайший найденный объект действительно окажется ближайшим по метрике. Это компромисс между скоростью и точностью.
Кроме того, есть еще пара подводных камней, которые стоит учитывать при работе с этим инструментом.
- Вывод команд недетерминирован — два запуска могут дать разные результаты.
- Индекс поддерживает только одну метрику.
- Нельзя обновить вектор в индексе — допустимы только удаление и повторная вставка.
Это может повлиять на статистику и эффективность планировщика запросов PostgreSQL. Когда вы обновляете вектор, удаляя старую строку и вставляя новую, это оставляет в таблице «мертвые» строки. PostgreSQL не удаляет их сразу — они остаются до тех пор, пока не сработает autovacuum или не выполнится вакуум инженером в ручную.
Если таких операций становится много, таблица раздуется, производительность упадет, а планировщик будет выбирать неэффективные планы из-за устаревшей статистики. Особенно это критично для больших таблиц с индексами и при профиле нагрузки, который подразумевает постоянное обновление большого количества данных. Подробнее об этом механизме я рассказывал в прошлой статье.
Вывод
pgvector — простой способ добавить векторный поиск туда, где уже есть PostgreSQL, и понять необходимость новой функциональности в вашем проекте. Он не заменит более серьезные инструменты и, скорее всего, не справится с enterprise-нагрузкой при работе с миллиардами объектов, но идеально подойдет для:
- MVP или стартапов,
- простых интеграций,
- нетребовательных внутренних AI-систем,
- pet-проектов.
Напоследок поделюсь интересным сравнением различных инструментов хранения векторных данных. Надеюсь, оно поможет вам правильно выбрать наиболее подходящий для вас.
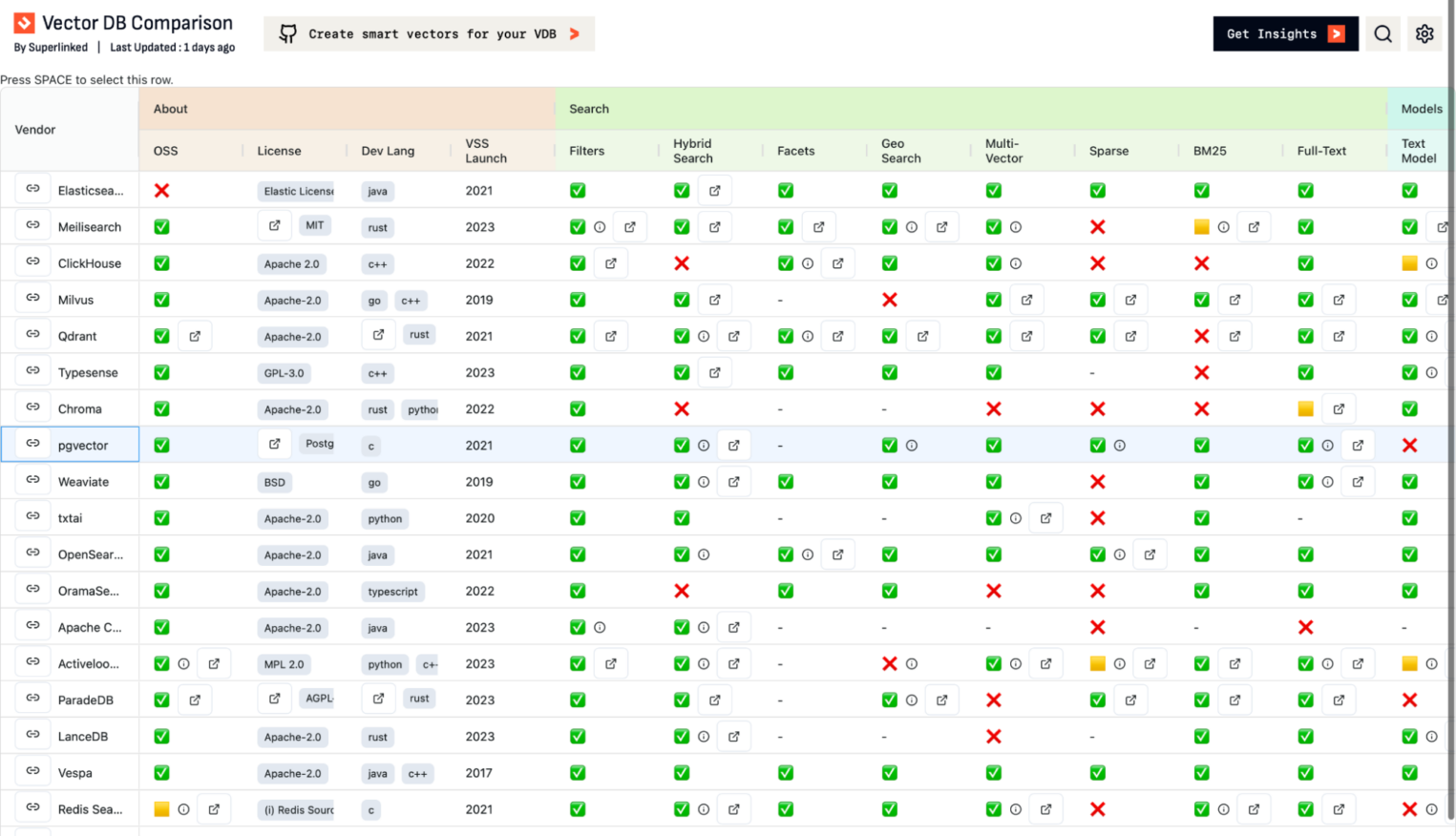
А мы недавно выпустили ультимативный по производительности сервис — первый в России DBaaS на выделенных серверах. Подробнее об этой услуге я уже рассказывал в одной из предыдущих статей.
В обозримом будущем я продолжу эту тему и расскажу о других полезных расширениях для PostgreSQL.




