Подойдет ли PostgreSQL вообще всем проектам или нужны альтернативы
В статье рассматриваем популярные базы данных, их особенности и возможности использования в реальных условиях.

В интернете только и разговоров, что про PostgreSQL и MySQL, но выбор СУБД много шире. В этом материале мы рассмотрим несколько популярных баз данных, разберемся с их спецификацией и сценариями использования, чтобы выйти за рамки привычных решений.
«Базы данных — это просто», говорили они
Кажется, чтобы развернуть любую базу данных, достаточно пяти секунд. Устанавливаем Docker, пишем команду:
docker run postgres
Готово, вы великолепны! На самом деле, вокруг этой задачи у любого администратора еще много работы. Сначала нужно было подобрать железо, которое будет подходить СУБД. Настроить операционную систему и регулярные обновления. Организовать мониторинг и график бэкапов. Отладить репликацию и собрать кластер. Чтобы сэкономить время, бизнес чаще выбирает готовые решения от провайдеров, которые уже прошли эти квесты с каждым продуктом.
На выбор СУБД под проект влияют два основных фактора:
- Команда обладает опытом в работе с конкретным решением и не видит смысла вступать в неизведанные воды.
- Если это не первая БД в проекте, то новую выбирают с учетом развернутой инфраструктуры. В первую очередь учитываются настройки операционных систем и оборудования, с которого получают/отдают данные. Учитывают особенности сбора аналитики и особенностей других БД. Кроме этого, нужно учитывать, как выделяются ресурсы и как контролируется их расход.
Рассмотрим несколько популярных СУБД, которые работают самостоятельно или могут быть классными напарниками, чтобы вместе реализовать более сложные и быстрые решения.
Особенности PostgreSQL
База данных относится к типу объектно-реляционных и часто используется как основная в проектах самых разных масштабов. Коротко работу с данными можно описать так: данные записываются в таблицы, индексируются для быстрого поиска и обрастают сложными зависимостями. Индексы помогают разметить данные в логике оглавления книги, чтобы не тратить время на полный просмотр базы данных. Зависимости нужны для реализации гибкой системы триггеров записи и чтения данных. Например, сотрудник банка с их помощью может выгрузить информацию по всем клиентам ипотекой, оформленной в понедельник.
Причин популярности PostgreSQL, кроме открытого исходного кода, много, но выделим две основные. Впрочем, это диалектический вопрос.
Надежность и репликация
PostgreSQL умеет работать с составными запросами, большими нагрузками и критическими данными, которые записываются на диск. Чтобы не потерять данные из-за сбоя сервера, запись сначала происходит в журнал транзакций (WAL). В аварийном случае из него можно будет восстановиться. WAL также участвует в обоих типах потоковой репликации:
- Асинхронная репликация. PostgreSQL сначала применит изменения на master-ноде, а потом отправит записи из WAL на реплики. Преимущество такого способа — быстрое подтверждение транзакции, поскольку не нужно ждать, пока все реплики применят изменения.
- Синхронная репликация. Изменения сначала записываются в WAL хотя бы одной реплики и только после этого фиксируются на основном сервере. Преимущество — более надежный способ, при котором сложнее потерять данные.
В панели управления Selectel можно добавить до шести реплик. Есть также схемы реализации репликации, которые позволяют снизить нагрузку на мастер и организовать чтение со slave-нод.
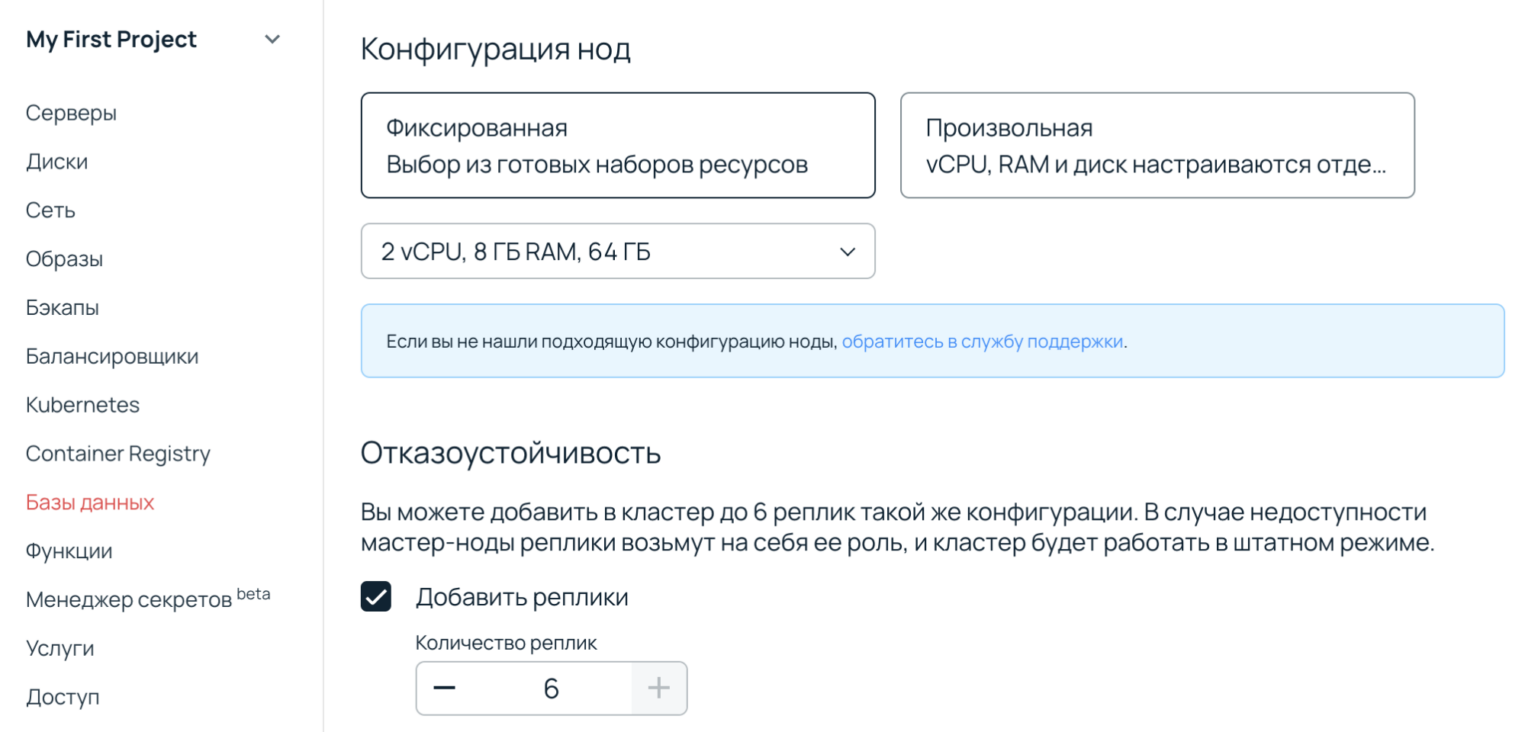
Еще есть логическая репликация. Этот вид оперирует записями в таблицах PostgreSQL. Этим она отличается от потоковой репликации, которая оперирует физическим уровнем данных: битами, байтами и адресами блоков на диске. Один сервер публикует изменения, другой подписывается на них. Подписываться на изменения можно выборочно. Например, на основном сервере 50 таблиц: 25 могут копироваться на одну реплику, а 25 — на другую.
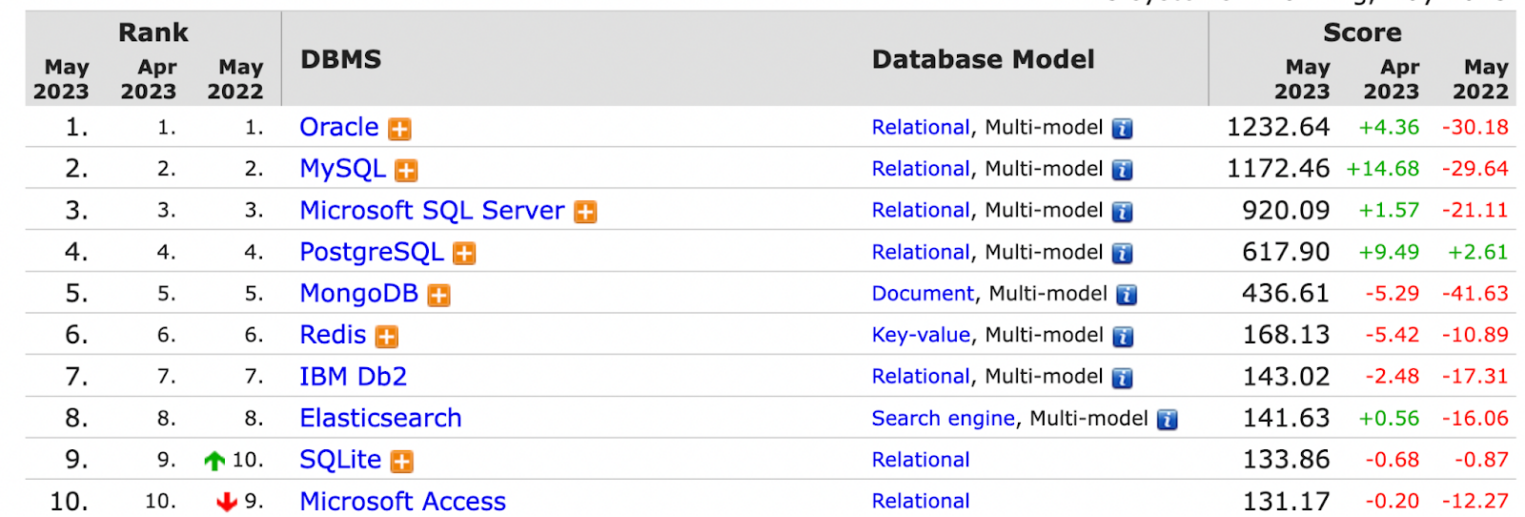
По последним данным, СУБД занимает четвертое место в мире по популярности:
Универсальность: модули и расширения
Решение подходит для работы в любой операционной системе: Linux, macOS, Windows. Большинство фреймворков (Ruby on Rails, Yii, Symfony, Django) поддерживают использование PostgreSQL в разработке.
За счет модулей и плагинов PostgreSQL адаптируется под самые разные задачи. Например, модуль pgcrypto предоставляет криптографические функции, а hstore — тип данных для хранения пар key-value, чтобы получить квази-Redis или MongoDB.
С помощью расширений PostgreSQL можно интегрировать в системы, которые ранее не понимали команды СУБД или работали медленно и некорректно. Так появились масштабные расширения для 1С, GIS и IoT. О нескольких таких решениях мы поговорим ниже, они заслуживают особого внимания.
При работе с PostgreSQL можно создавать пользовательские типы данных. Они нужны, чтобы упростить работу с базой или установить ограничения. Например, есть устройство, которое показывает только целые числа от 1 до 5. Данные с устройства необходимо писать в базу. Можно создать пользовательский тип данных, который состоит только из чисел 1, 2, 3, 4, 5. Тогда ввод других значений будет ошибкой, а значит, не нарушит данные.
Звучит как магия, но PostgreSQL может работать даже с NoSQL и JSON и слабоструктурированными данными. Еще с 2012 года для этих целей есть тип данных JSON, который хранит в себе только корректный JSON. Перед преобразованием в этот тип происходит проверка на валидность, и любые ошибки будут заметны:
--ERROR: invalid input syntax for type json
Поддержка SQL-стандартов позволяет обеспечить максимальную совместимость с другими СУБД и переносить код между разными базами данных. PostgreSQL похож на молоток – при должном умении все вокруг становится гвоздями, поэтому другие инструменты кажутся не такими нужными. Тем не менее у БД есть ряд «классических» сценариев, в которых решение раскрывается в полную силу.
Для чего используют PostgreSQL в реальных условиях
- Обработка и хранение больших объемов данных. Популярная задача для PostgreSQL – интеграция в архитектуру мультиязычных сайтов с большим количеством магазинов в разных странах. БД позволяет быстро синхронизировать информацию о товарах на точках и складах, чтобы держать актуальные списки товаров.
- Защищенные транзакции. PostgreSQL предлагает многоуровневую систему безопасности, включая поддержку шифрования данных, контроль доступа и аудит операций. PostgreSQL также обеспечивает защиту от SQL-инъекций, блокирует доступ к системным таблицам и функциям и предоставляет другие инструменты для обеспечения безопасности данных. PostgreSQL поддерживает требования ACID, поэтому активно используется в финансовой и банковской средах.
- Аналитика данных. Возможности СУБД используются для анализа больших объемов данных и генерации отчетов. Например, можно использовать OLAP-кубы для построения сводных таблиц. Это помогает использовать СУБД в задачах, связанных с обучением ML-моделей и machine learning.
Резюме
Русскоязычное комьюнити PostgreSQL одно из самых больших в мире. Точных причин этому, пожалуй, не найти, но СУБД любят использовать в проектах из-за большого потенциала кастомизации и надежной работы с большими нагрузками.
Особенности PostgreSQL 1С
Исторически сложилось, что код платформы 1С написан в основном для работы с Microsoft SQL Server и Oracle. Ванильный PostgreSQL даже не понимал часть команд. Например, оператор равенства в нем реализован так, что результатом сравнения двух NULL оказывается NULL. На СУБД Microsoft SQL оператор равенства ведет себя по-другому и возвращает TRUE, когда оба его операнда равны NULL.
Во многом это связано с особенностями архитектуры 1С: огромное количество таблиц в одной базе, множество баз на одном сервере, 99% запросов работают с использованием временных таблиц. Для PostgreSQL работа в таком «хаосе» оказалась непривычной, а коммерческое использование просто невозможным. Например, MS SQL мог подготовить зарплатный отчет по 10 000 человек за пару минут, а PostgreSQL занимался бы этой задачей несколько часов. Но, как мы уже говорили, СУБД умеет адаптироваться к среде за счет настроек и модулей. Поскольку PostgreSQL — это open source-проект, сообщество постоянно вносит вклад в развитие расширения для 1С.
Код 1С при использовании PostgreSQL 1С
Важный вопрос при интеграции новой БД: насколько придется переписывать код 1С, чтобы перейти на PostgreSQL 1С? На самом деле, работы не так много, но это критичная задача для обеспечения быстродействия инфраструктуры. Выделим пару основных рекомендаций:
- Если в запросе используется соединение с виртуальной таблицей СрезПоследних() и запрос работает медленно, то нужно вынести обращение к виртуальной таблице в отдельный запрос с сохранением результатов во временной таблице.
- Не рекомендуется использовать ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ. В результате такого соединения получается одна таблица, содержащая все выбранные колонки. Обычно число строк равняется сумме совпадающих по ключам строк и всех несовпадающие.
Как видно, особых доработок для перехода на PostgreSQL не требуется. 99% инсталляций 1С проходят процедуру перехода без каких-либо изменений кода 1С. В основном проблему вызывают настройки операционной системы и виртуализация.
Влияние виртуализации
Компаниям нужна возможность быстрого масштабирования ресурсов, которую обеспечивает облачный подход, поэтому отказаться от использования виртуализации для СУБД практически невозможно. Для работы PostgreSQL в виртуальных средах нужно обратить внимание на рекомендации вендора по поводу настроек гостевой системы для оптимальной работы дисковой подсистемы:
- Ключевое правило размещения виртуальных машин без потери производительности — суммарное число ядер, ГГц, объема RAM и IOPS всех виртуальных машин не может превышать параметров хоста, на котором они расположены.
- Нужно в обязательном порядке резервировать 100% ресурсов для виртуальной машины с СУБД и не использовать динамическое распределение ресурсов.
Резюме
Исследование настроек операционных систем и доработки PostgreSQL 1С помогли решению стать полноценной альтернативой MS SQL. Таким образом архитекторы получили возможность интегрировать привычное решение, а также пользоваться преимуществами экосистемы PostgreSQL.
Далее можно посмотреть отчет о производительности СУБД для конкретной конфигурации продукта.
Производительность в тестах: 1C:ERP 2.4.8 (150 пользователей, 500 ГБ):
| Операция | Время выполнения на обычном PostgreSQL 1С | Время выполнения на настроенном PostgreSQL 1С |
| Открытие формы списка «Заказы клиентов/поставщикам» | 5 сек | 0,7 сек |
| Открытие документа «Заказ клиента/поставщику» | 8-10 сек | 1,3 сек |
| Проведение документа «Заказ клиента/поставщику» | 5 сек | 2 сек |
| Проведение «Реализация товаров и услуг» | 12 сек | 3 сек |
| Проведение «Поступление товаров и услуг» | 5 сек | 1,5 сек |
| Формирование этапа производства | 8 мин | 1,5 мин |
| Формирование отчета оборотно сальдовая ведомость по всем счетам за год | 15 сек | 2 сек |
| Формирование модели бюджета на год | 3 часа 15 мин | 1 час 45 мин |
| Ведомость по товарам на складах | 10 сек | 2 сек |
| Открытие документа «Начисление зарплаты и взносов (500 сотрудников)» | 30 сек | 2,5 сек |
| Проведение документа «Начисление зарплаты и взносов (500 сотрудников)» | 2 часа | 10 мин |
Как видно из тестов, PostgreSQL вполне готов брать на себя реальные задачи и предоставлять комфортное время на запись и чтение данных.
Особенности MySQL c синхронной и полусинхронной репликацией
MySQL принадлежит Oracle и является одним из самых популярных решений в области БД, хотя по количеству форков тот же PostgreSQL его опережает. Для некоммерческого использования MySQL распространяется бесплатно. На базах данных MySQL работают такие масштабные проекты, как Github, Wikipedia, Google, Booking.com, Yelp. Поэтому разговоры о том, что MySQL устарел — точка зрения евангелистов других СУБД.
Решение относится к типу реляционных, то есть связанные данные хранятся в таблицах, как и в PostgreSQL. Система автоматически подбирает наиболее подходящий результат под запрос оператора, исходя из имеющихся данных. Каждая таблица содержит набор столбцов:
- table_name — имя таблицы,
- column_name — имя столбца,
- column_type — тип данных столбца.
Команда создания таблицы обязательно должна содержать все вышеупомянутое. Для каждого столбца таблицы определяется тип данных. Неправильное использование типов данных увеличивает объем занимаемой памяти и время выполнения запросов к таблице. Чаще ошибки такого плана заметны в больших проектах, когда количество строк исчисляется десятками тысяч.
MySQL умеет хранить данные как key-value и позволяет работать с разными типами данных. В их числе:
- числовые,
- символьные,
- текстовые и бинарные,
- дата и время,
- JSON,
- составные типы.
Поле JSON лучше для хранения JSON, чем поле text, потому что:
- Предоставляет автоматическую валидацию документа. То есть если мы попытаемся туда записать что-то невалидное, выпадет ошибка.
- JSON хранится в бинарном формате, что позволяет переходить от одного документа JSON к другому (skip).
Любые тезисы о том, какая СУБД работает быстрее и надежнее, — спекуляция. В каждом сравнении нужно смотреть схему инфраструктуры, синтаксис запросов, настройки и конфигурацию. Без этих данных какой-либо объективный ответ дать нельзя.
Как устроена репликация в MySQL
Репликация в MySQL состоит из трех основных шагов:
- Master-сервер записывает изменения данных (события) в двоичный журнал (binary log).
- Slave копирует изменения двоичного журнала в свой, который называется журналом ретрансляции (relay log).
- Slave воспроизводит изменения из журнала ретрансляции, применяя их к своим данным.
Существует два принципиально разных подхода к репликации: покомандная и построчная. В первом случае в журнал мастера протоколируются запросы изменения данных (INSERT, UPDATE, DELETE), а slave в точности воспроизводит команды у себя. При построчной же репликации в журнале окажутся непосредственно изменения строк в таблицах, и эти же фактические изменения применятся затем на слейве.
В MySQL поддерживаются оба способа репликации, а дефолтный изменялся в зависимости от версии. В современных версиях, например MySQL 8, по умолчанию используется построчная репликация.
Второй принцип разделения подходов к репликации — количество master-серверов. Наличие одного master-сервера подразумевает, что только он принимает изменения данных и является образцом, с которого далее распространяются изменения на прочие slave. Так, например, можно давать удаленным клиентам одинаково быструю возможность вносить изменения в базу.
В Selectel до 2022 года из семейства MySQL существовал только один вариант — MySQL sync с синхронной репликацией данных. Клиентам, которые хотели использовать этот вариант облачных баз данных, приходилось мириться с некоторыми ограничениями. Сейчас можно использовать оба варианта.
Отличия синхронной и полусинхронной репликации MySQL:
| MySQL sync (синхронная репликация) | MySQL semi-sync (полусинхронная репликация) | |
| Кластеризация и отказоустойчивость | Можно создать инстанс только из мастера или отказоустойчивый кластер с мастером и двумя синхронными репликами | Можно создать инстанс только из мастера или отказоустойчивый кластер с мастером, одной или двумя репликами |
| Ограничения работы БД в режиме кластера | Для отказоустойчивых кластеров с репликами накладываются ограничения | Нет ограничений |
| Подключение к кластеру | Подключение к кластеру происходит через ProxySQL, используется порт 6033 | Подключение напрямую к кластеру, используется порт 3306 |
Сферы использования и преимущества MySQL
Самая подходящая для MySQL сфера применения — это интернет-ресурсы и веб-приложения. В плане работы с большими нагрузками единого мнения, что выбрать — MySQL или PostgreSQL — пожалуй, нет, но среди преимуществ решения часто выделяют следующие моменты:
- Высокая скорость работы. Если ориентироваться на open source- инструменты тестирования, например Sysbench, то с определенными настройками СУБД показывает такую производительность.
- Надежная и простая система безопасности. MySQL использует безопасность, основанную на Access Control Lists для всех соединений, запросов и других операций, которые пользователи могут попытаться выполнить.
- Поддержка нескольких типов таблиц. Например, MyISAM, InnoDB.
- Корректная работа с нагрузками. MySQL используют как надежное и масштабируемое хранилище для OLTP нагрузок (с key-value как частный случай).
- Практичность и гибкость системы. Многолетний опыт использования и большое комьюнити позволяют находить ответы на самые нестандартные вопросы.
- Большой набор инструментов. Разные типы таблиц, индексы, транзакции, хранимые процедуры.
- Поддержка графических интерфейсов. WorkBench, SequelPro, DBVisualizer и Navicat DB.
Все функции проверки и восстановления базы данных MySQL сосредоточены в функциональности утилиты mysqlcheck. Это позволяет быстро и безопасно осуществлять проверку базы данных MySQL-сервера.
Резюме
MySQL — почти универсальное решение для E-commerce благодаря работе СУБД с транзакациями и быстрой скорости обработки запросов. MySQL — такой же стандарт индустрии, как MS SQL или PostgreSQL.
Особенности Redis
Redis — это система управления базами данных в виде структур. Redis хранит данные по принципу key-value и относится к типу in-memory решений.
С одной стороны, можно говорить, что Redis стал популярным, поскольку работает в 16-20 раз быстрее, чем PostgreSQL или MySQL. С другой стороны, Redis никогда не используется в качестве единственной базы данных в проекте, но, если вы знаете такие случаи, — опишите их в комментариях.
СУБД хранит все кэшируемые данные в доступной оперативной памяти. Это позволяет не ходить каждый раз в основную БД и оптимизирует нагрузку на нее. Стоит заметить, что в топ-10 самых популярных решений Redis — единственный представитель нереляционных СУБД.
Одна из самых популярных задач для Redis — построение очередей сообщений. Это механизм передачи данных между приложениями или компонентами, который обеспечивает асинхронную обработку и оптимизирует нагрузку на систему.
Для построения очередей сообщений СУБД использует структуру данных List. Она позволяет добавлять элементы в конец списка и получать элементы из начала списка, что делает ее идеальной для построения очередей. Для работы с очередями сообщений в Redis используются команды LPUSH, RPUSH, LPOP и RPOP. Команды LPUSH и RPUSH добавляют элементы в начало и конец списка соответственно, а команды LPOP и RPOP удаляют первый и последний элементы списка.
Redis также поддерживает блокирующие операции BLPOP и BRPOP, которые позволяют ожидать появления новых элементов в списке и автоматически извлекать их из списка при появлении.
Redis поддерживает все самые распространенные языки программирования: Python, Golang, семейство C, Java, Ruby, Perl, PHP и JavaScript. О том, как работает кэширование в Redis, можно подробнее прочитать здесь.
Как используют Redis
- Хранение сессий пользователей. К примеру, части HTML-кода страниц, товары в корзине интернет-магазинов или маршруты в навигаторах.
- Хранение временных данных. Это могут быть лайки под постами, заполненные формы, таблицы.
- Брокер сообщений. СУБД преобразует сообщения по одному протоколу от источника в сообщение протокола приемника и выступает между ними посредником для маршрутизации и и вызова веб-сервисов при необходимости.
- Хранение пользовательских данных. Например, для аналитики и других случаев, когда важна скорость и отсутствие задержек передачи.
- Машинное обучение. Скоростное хранилище, которое использует система для информации, позволяет обрабатывать большие объемы данных, автоматизировать процессы и быстро проводить эксперименты.
Преимущества решения
- Асинхронная репликация. Это значит, что, если вы скопируйте информацию на несколько связанных серверов, это позволит распределить запросы между ними и увеличит скорость чтения.
- Масштабируемость. В Redis есть возможность настроить кластерную архитектуру, выбрать размер кластера или нарастить его. Таким образом ваши проекты будут работать быстро и надежно.
- Гибкость. В отличие от обычных хранилищ в Redis можно работать с неструктурированными данными – они хранятся по типам: строки, списки, потоки и другие. Также вы можете добавить дополнительные типы данных.
О том, как Redis использует туристический сервис QVEDO, можно почитать в нашем кейсе.
Резюме
Свое место в топ-10 Redis заслужил не только собственными показателями и функциональностью, но и возможностью к легкой интеграции с другими системами. Возможности Redis максимально раскрываются в работе в паре с PostgreSQL или MySQL, при решении задачи с построением очередей или кэшированием данных.
Особенности TimecaleDB
TimescaleDB — это расширение PostgreSQL для работы с временными рядами (time series). Временные ряды можно хранить в PostgreSQL и без дополнительных настроек, но TimescaleDB обеспечивает большую производительность на том же железе для такого типа задач. Чаще всего временные ряды используют для сбора данных с каких-либо устройств и построения дальнейших прогнозов на основе этой информации. СУБД унаследовала отказоустойчивость, набор инструментов и всю экосистему PostgreSQL, например, поддержку собственных типов данных.
Многие инженеры начинают использовать PostgreSQL для хранения данных временных рядов из-за его надежности и простоты использования, но при сильном росте объемов данных переходят на какую-либо систему NoSQL. Некоторые полностью отказываются от PostgreSQL для работы с временными рядами.
TimescaleDB поддерживает масштабирование таблиц до миллиардов строк, сохраняя при этом высокую и постоянную скорость вставки данных (INSERT). СУБД позволяет хранить реляционные метаданные и временные ряды в одной базе данных, выполнять запросы с использованием оптимизированного для временных рядов SQL и продолжать использовать любимые инструменты и дополнения.
СУБД используют трейдинговые платформы, чтобы отображать котировки валют. Решение применяется в телеметрии транспортных маршрутов. Статистика обращения к серверу или нагрузки на CPU — все это time series-данные. Инструментов для такой работы много. Например, InfluxDB или ClickHouse, но даже у популярных решений для хранения временных рядов есть особенности.
Проблема time series-хранилищ в том, что они низкоуровневые. То есть подходят для time series-данных и точка. Но их интеграция в IT-инфраструктуру — отдельный трудоемкий процесс, который можно упростить, используя TimescaleDB.
Временные ряды имеют свои особенности:
- Время фиксации. Любая time series-запись имеет поле с меткой времени, куда фиксируется значение.
- Повсеместный append-only режим. Новые данные не заменяют старые. Удаляются только устаревшие данные.
- Записи не рассматриваются отдельно друг от друга. Данные используются только в совокупности по временным окнам или периодам.
Когда стоит использовать TimescaleDB
TimescaleDB может быть альтернативой, например, для InfluxDB в небольших проектов. Решение хорошо справляется с небольшим фиксированным набором тегов.
- Работа с БД плотно связана со вставкой данных (обычно это происходит при работе с десятком миллионов строк, в зависимости от выделенной памяти).
- Когда удаление данных становится проблемой.
- Запросы основаны на времени и включают в себя более одного поиска key-value.
- Когда не хватает возможностей SQL для анализа временных рядов. Нужна временная привязка, запись двух дат для одного объекта (темпоральная и дата регистрации события).
TimescaleDB vs PostgreSQL
По сравнению с ванильным PostgreSQL TimescaleDB демонстрирует:
- Ускорение вставок. Например, ванильному PostgreSQL потребуется почти 40 часов для вставки миллиарда рядов данных, а TimescaleDB справится с объемом примерно за 3 часа.
- Оптимизация запросов. Специализированная система улучшения запросов (до 14 000 параметров), которая позволяет ускорить работу с зависимостями.
- Быстрое очищение. 2000-кратное ускорение удаления данных для реализации гибкой политики хранения информации.
- Новая функциональность. Манипуляции с временными рядами в SQL еще проще для чтения с IoT.
Резюме
Несмотря на то, что спецификация TimescaleDB более узкая, решение постепенно набирает видимость за счет более простой и дешевой интеграции в проекты, если команда уже знакома с PostgreSQL и использует ее как реляционную СУБД.
Заключение
Кажется, что многие СУБД сегодня пришли к схожей функциональности и выбор под проект происходит скорее по законам легаси: работаем с тем, что уже есть. Тем не менее решения типа Redis и TimescaleDB имеют более узкую специализацию и могут точечно закрывать задачи бизнеса. Например, могут более эффективно работать с временными рядами и кэшем, чтобы пользователям не приходилось каждый раз обращаться к БД. Как правило, они не используются как единственная СУБД в проекте, но вместе с MySQL или PostgreSQL показывают отличный результат и расширяют возможности сервисов.





