Как подключиться к S3-хранилищу из DAVM
В инструкции расскажем о ключевых особенностях S3 и платформе для анализа данных и машинного обучения. Пошагово разберем, как подключиться к S3 в Jupyter Notebook с помощью библиотеки boto3.
Data Analytics Virtual Machine (DAVM) — виртуальный сервер с образом ОС и набором инструментов для анализа данных и машинного обучения. Вы можете кастомизировать DAVM под свои задачи и быстро пересоздать платформу, если что-то пошло не так. Для второго сценария особенно будет удобно хранить данные вне виртуального сервера. В этом случае подойдет хранилище S3 (объектное хранилище).
Особенности S3
Сегодня объектное хранилище — это один из наиболее популярных сервисов облачного хранения данных. Технология позволяет работать с большим количеством информации любого типа и быстро масштабироваться. В числе ее преимуществ — автоматическое резервное копирование и возможность добавления метаданных к файлам.
С помощью метаданных можно удобно сортировать объекты по типу, дате создания и т. д. Находить и управлять объектами можно с помощью уникальных URL. Алгоритмы доступа здесь довольно простые. Даже если данных в объектном хранилище будет очень много, доступ к отдельным объектам вы получите также быстро. При этом в S3 можно хранить петабайты данных.
Хотя технология набирает популярность среди компаний и пользователей, есть нюансы. Для работы с хранилищем нужно специализированное программное обеспечение с правильной конфигурацией, а скорость доступа довольно ограничена в сравнении с другими типами хранилищ.
Следует исходить из задач, которые вы планируете решить с помощью сервиса. Так, к примеру, объектное хранилище не подходит для размещения базы данных. Среди распространенных сценариев использования S3 — хранение личной информации, бэкапирование, Big Data.
Вкратце о DAVM
Как упоминалось, DAVM — это платформа аналитики данных и машинного обучения. Образ разворачивается за несколько минут из панели управления. В нем используется Ubuntu 22.04, любое необходимое количество GPU, а также предустановлен готовый набор инструментов.
- JupyterLab — среда разработки для работы с Jupyter Notebooks, данными и кодом.
- Prefect — ПО для управления задачами по сбору, мониторингу и обработке данных.
- Apache Superset — веб-приложение для визуализации и исследования данных, создания дашбордов и отчетов.
- PostgreSQL — реляционная СУБД для хранения данных.
Различные библиотеки для машинного обучения. Например, TensorFlow и PyTorch. Кастомизировать все компоненты платформы можно в зависимости от задач.
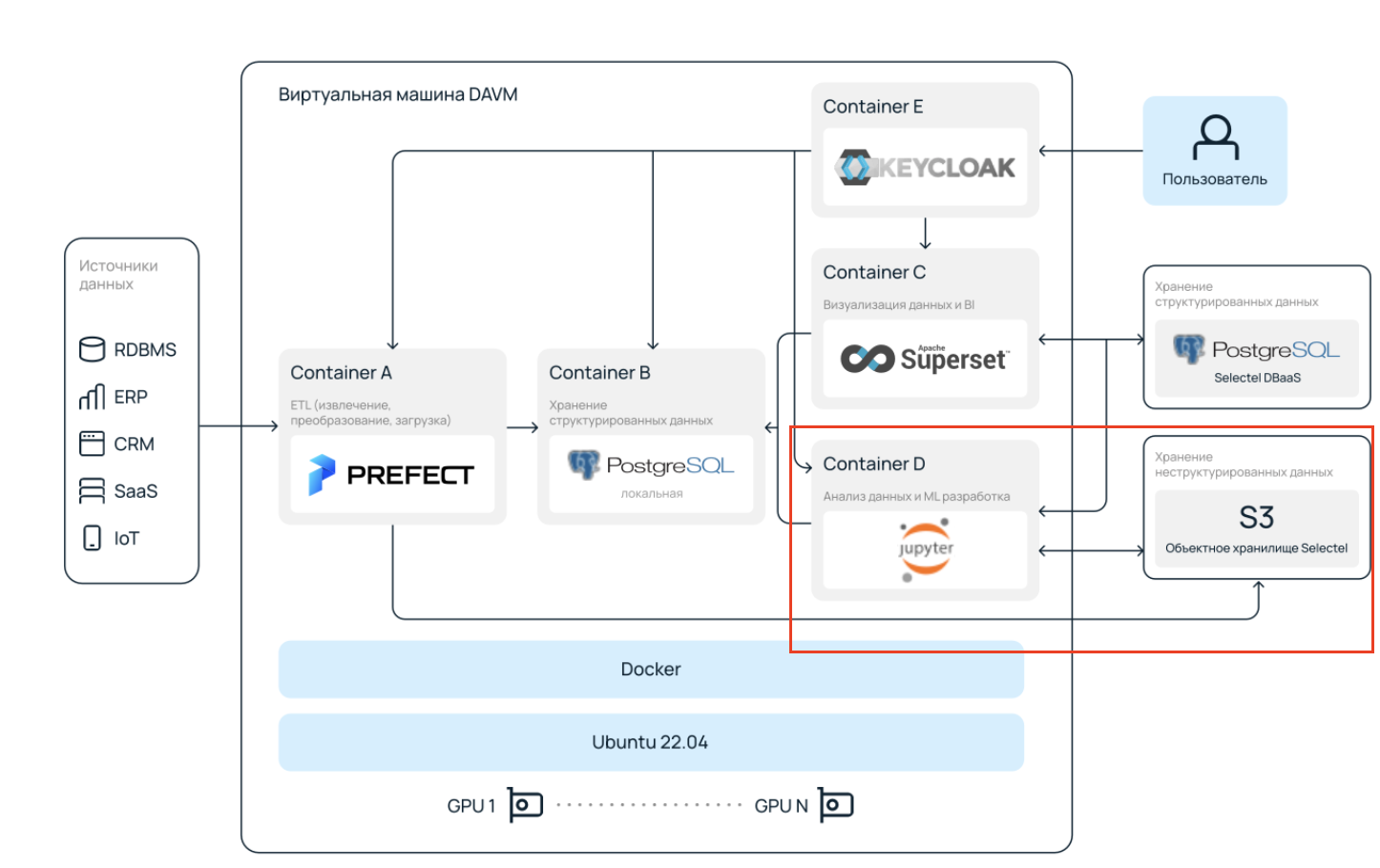
Внутри установлен Docker, где в контейнерах запущены Prefect, Superset, Keycloak и Jupyter Hub. Стоит отметить «отдельно стоящий» PostgreSQL, в связке с которым запущен Superset. Данные можно загрузить через Prefect в PostgreSQL, а затем переместить их в Superset.
Хранение можно организовать в рамках DAVM. Однако в таком случае есть риск потерять информацию в результате сбоя или пересоздания платформы. Лучше использовать S3 или облачные базы данных, к примеру, с PostgreSQL. Так будет возможность создать платформу заново, если что-то пойдет не так. Хранение данных станет более безопасным.
Полный список предустановленных библиотек и фреймворков, их версии и другие технические подробности о DAVM — в документации.
Создаем DAVM
За основу возьмем конфигурацию с видеокартой Tesla T4.
1. Переходим в раздел Облачная платформа внутри панели управления.
2. Выбираем пул ru-7a или ru-9a, создаем облачный сервер с дистрибутивом Ubuntu 22.04 LTS Machine Learning 64-bit и подходящей конфигурацией. Используем виртуальную машину с видеокартой NVIDIA Tesla® T4 16 ГБ.
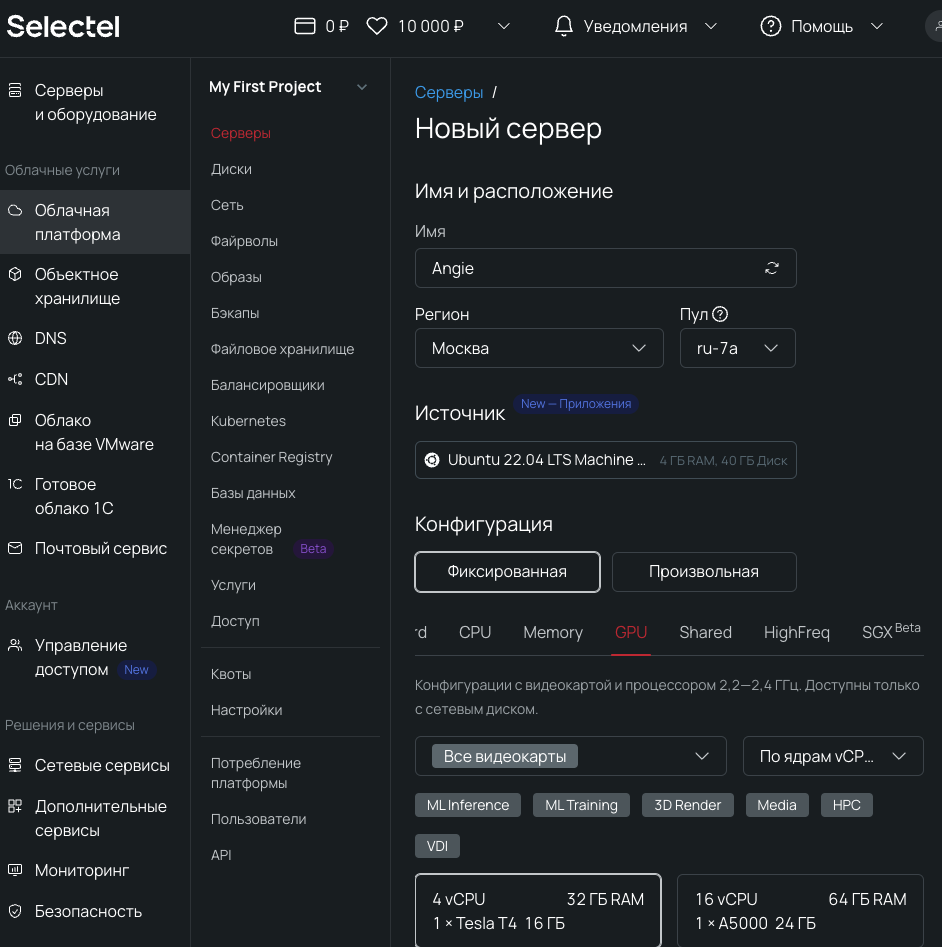
3. Важно, чтобы сервер был доступен «из интернета», иначе подключиться с компьютера будет нельзя. Для этого выбираем новый публичный IP-адрес.
4. Нажимаем Создать. Система загрузится в пределах пары минут. Чтобы настроить окружение, подключимся к серверу по SSH — тогда он покажет данные для авторизации в окружении DAVM. Команду для подключения можно найти во вкладке Конфигурация.
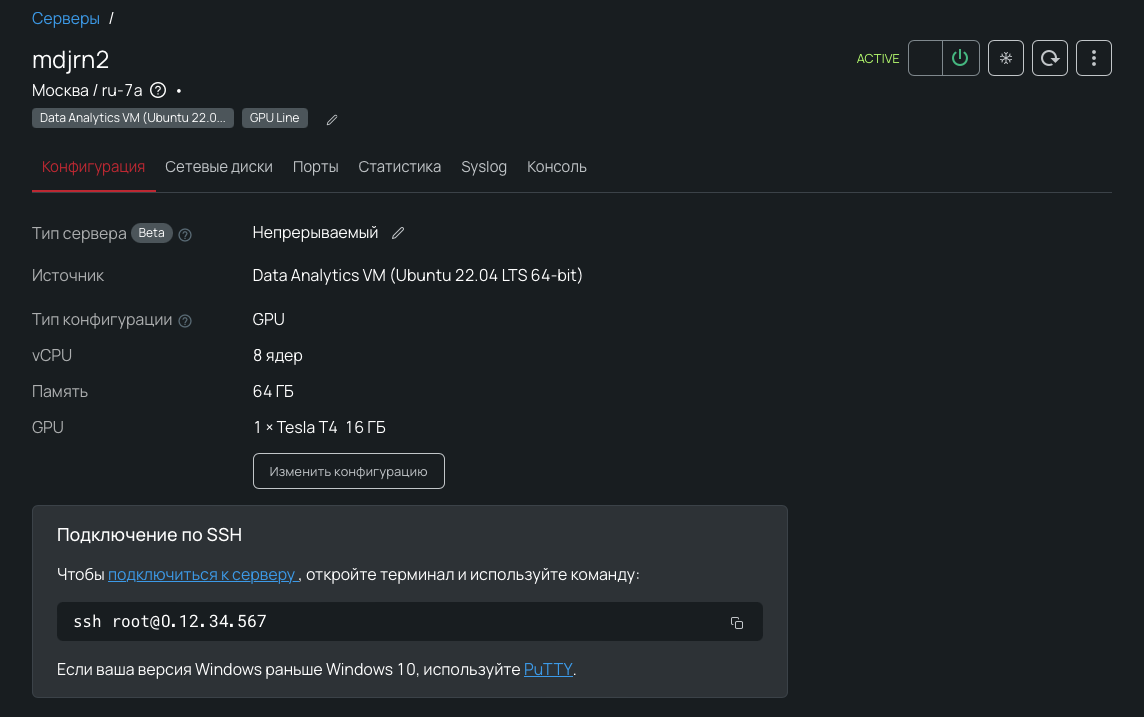
5. Берем в терминале ссылку для подключения, логин и информацию о пароле для первого входа.
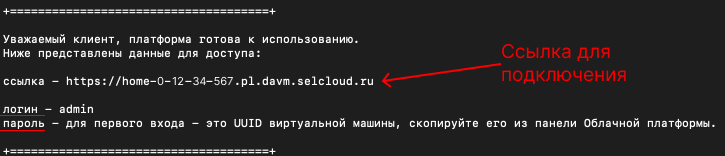
6. Переходим по ссылке и авторизуемся в DAVM. Теперь можно запустить Jupyter Lab, Keycloak, Prefect или Superset из браузера. В рамках статьи будем использовать только Jupyter Lab.

Настраиваем S3
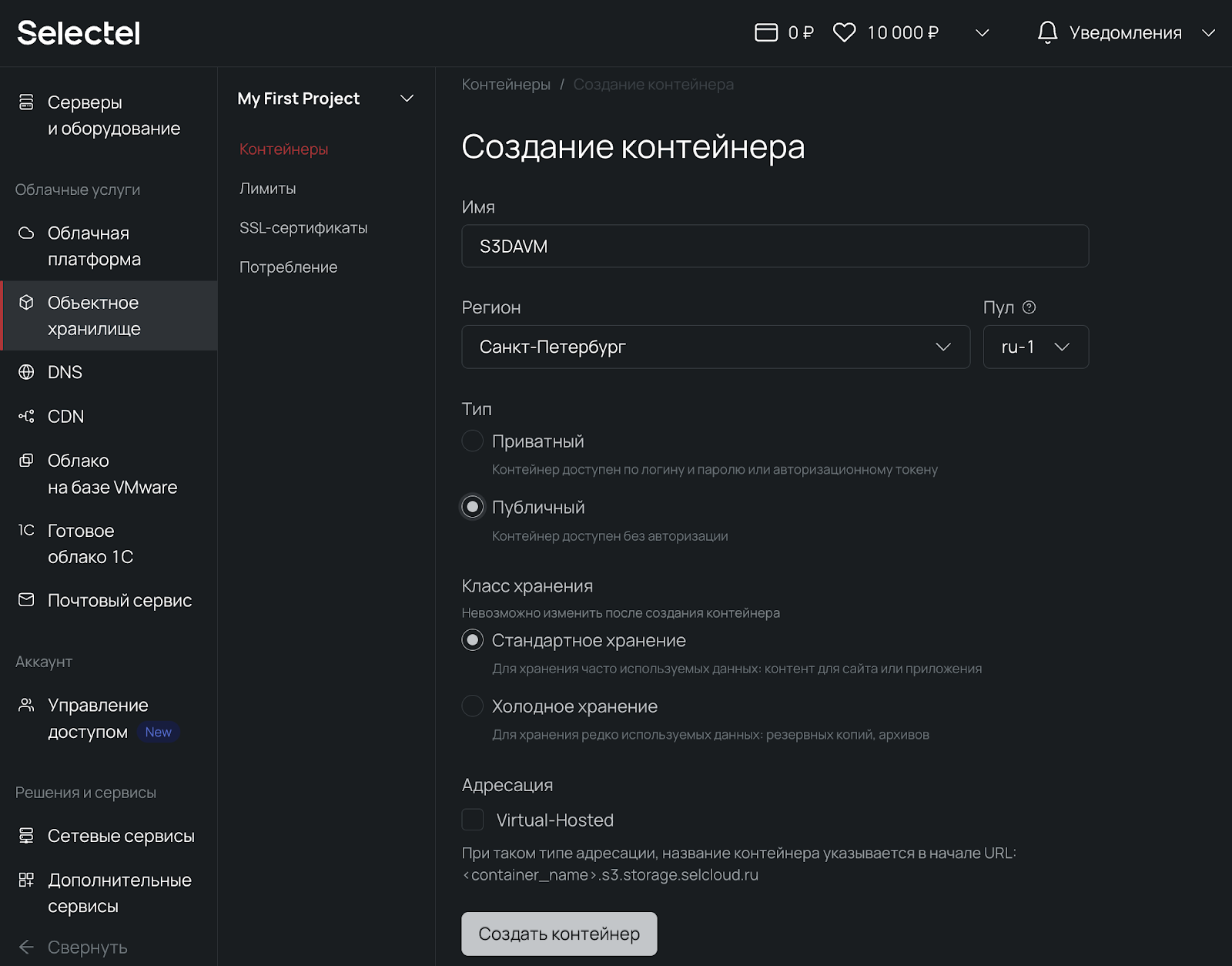
1. В панели управления переходим в Объектное хранилище → Создать контейнер.
2. Выбираем Регион — Санкт-Петербург и Пул — ru-1.
3. Тип — публичный. Такой контейнер доступен без авторизации. Если нужно ограничить прямой доступ до файлов — подойдет приватный. Класс — стандартное хранение. Оптимальный выбор для работы с часто используемыми данными. Холодное хранение применяется для бэкапов, архивов и прочих важных данных с редким обращением. 4. Выключаем адресацию. Нажимаем Создать контейнер.
Создаем сервисного пользователя
Чтобы взаимодействовать с S3 по API, следует создать сервисного пользователя.
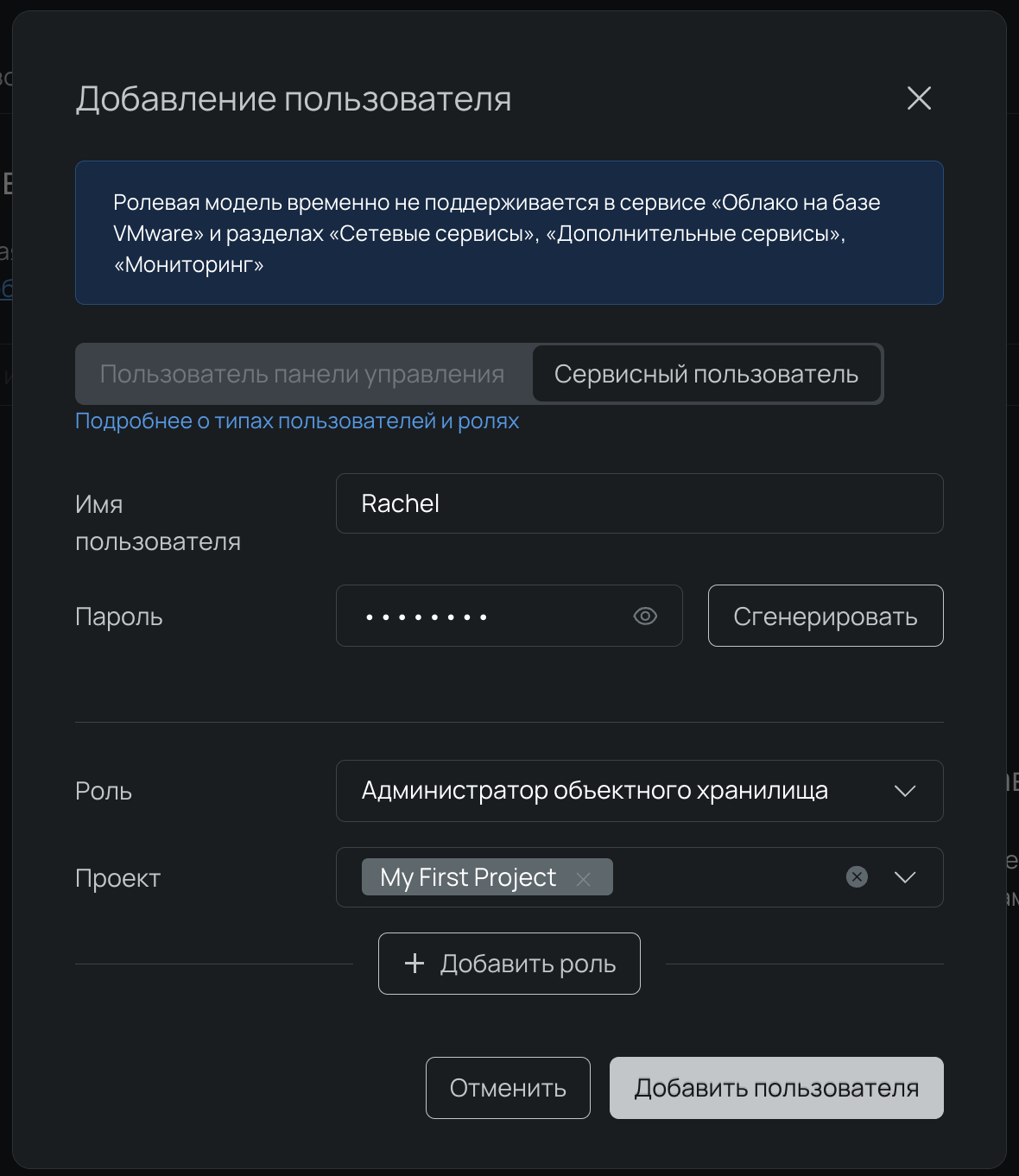
1. Переходим во вкладку Управление доступом → Сервисные пользователи.
2. Нажимаем Добавить пользователя. Имя пользователя можем оставить по умолчанию, а пароль сгенерировать.
3. В поле Роль выбираем Администратор объектного хранилища.
4. После выбора нужного проекта нажимаем Добавить пользователя.
Получаем ключи
На один проект можно выпустить несколько ключей. Однако на каждый новый нужно создавать отдельный ключ.
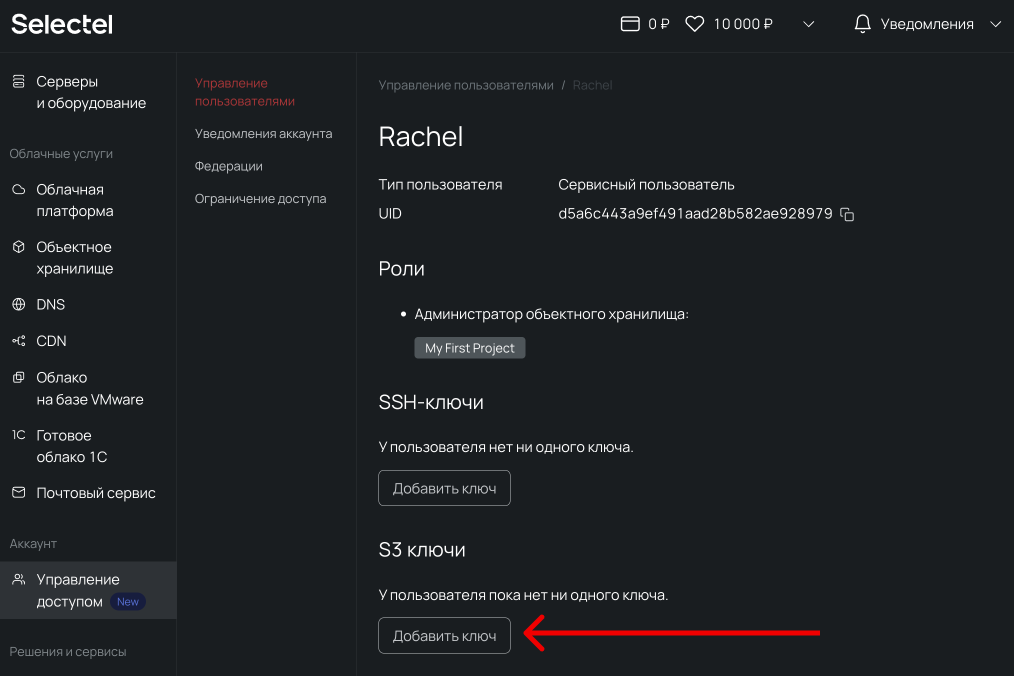
1. Во вкладке Управление пользователями переходим к созданному пользователю.
2. В поле S3 ключи нажимаем Добавить ключ.
3. В окне Добавление S3 ключа выбираем наш проект, имя можно оставить по умолчанию. Нажимаем Сгенерировать.
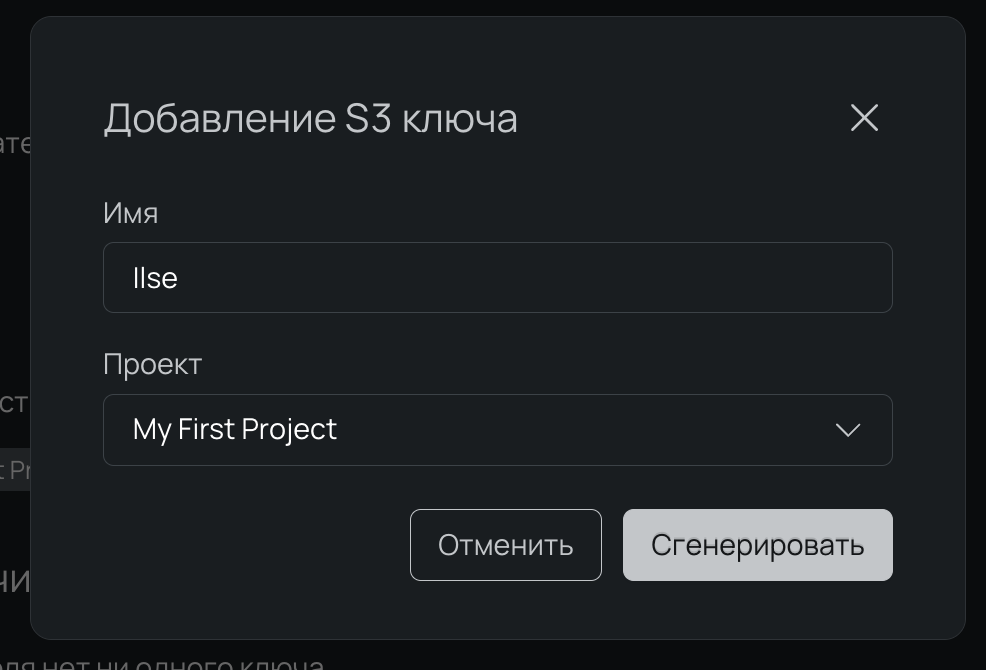
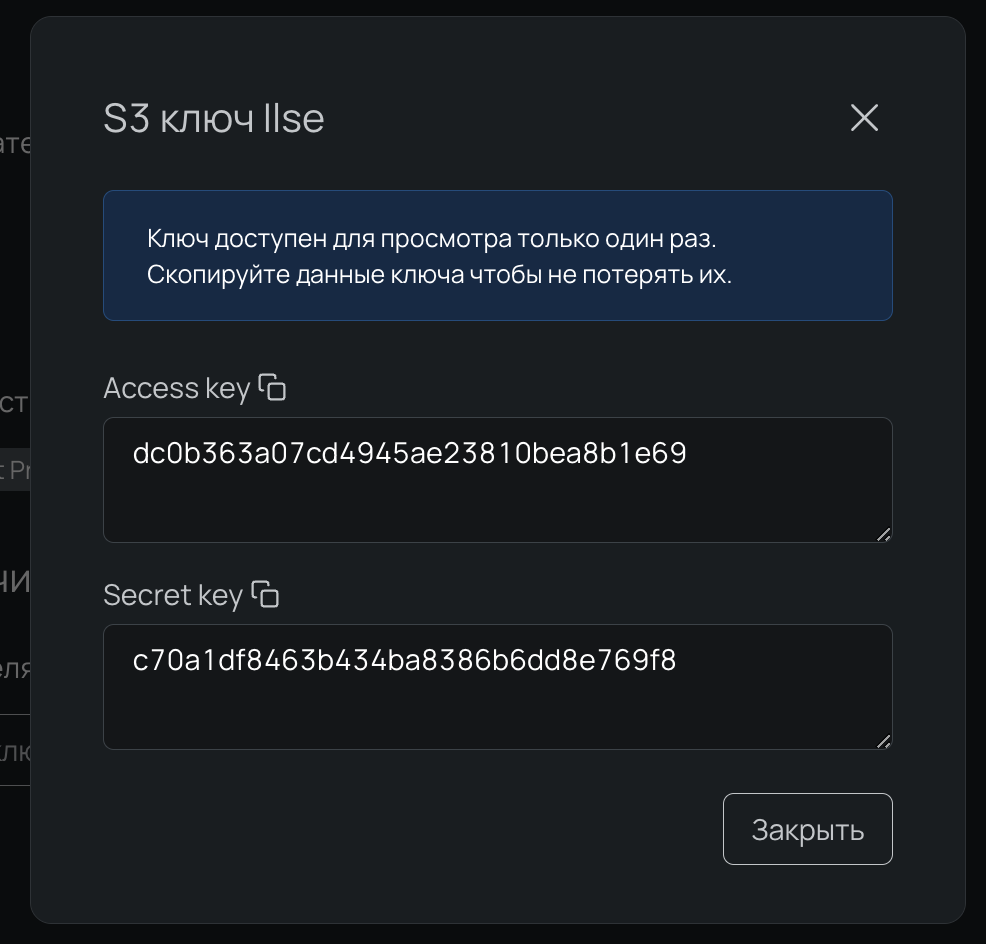
Видим, что сгенерировано два значения: Access key — идентификатор ключа, и Secret key — секретный ключ. Копируем и сохраняем ключ — после закрытия окна его нельзя будет просмотреть.
Теперь, когда мы создали и настроили S3 и DAVM, можно перейти к практике и организовать подключение между ними.
DAVM на практике
Для теста платформы возьмем готовый notebook-шаблон для работы с библиотекой Diffusers. Подробнее о применении мы уже рассказали в обзоре. Разворачиваем нейросеть для генерации изображений. Процесс занимает не более десяти минут, так как в DAVM уже установлены и настроены драйверы и необходимое ПО.
По умолчанию инференс модели запускаем на ядрах GPU. На мощностях CPU скорость генерации изображений займет значительно больше времени. Для удобства «общения» с нейросетью создали Telegram-бота. Пользователь может отправить запрос и быстро получить сгенерированное изображение. Саму модель можно настраивать через Jupiter Lab.
Подключаемся к S3
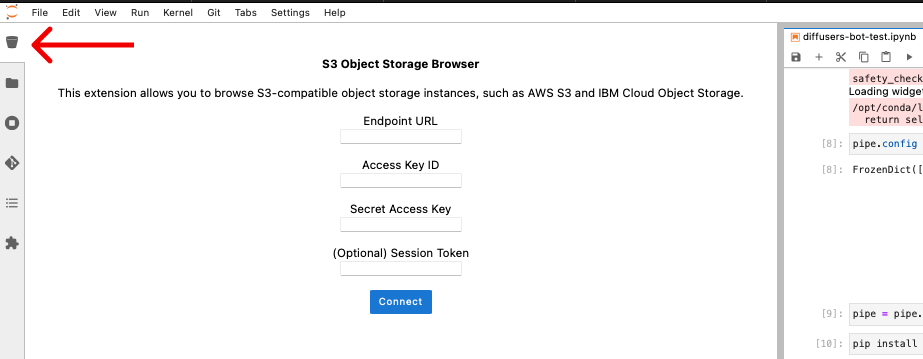
С помощью коннектора
Для подключения к объектному хранилищу можно использовать коннектор S3 в DAVM. В поле Access Key ID вводим идентификатор ключа, а в Secret Access Key — секретный ключ. В поле Endpoint URL вводим ссылку — https://s3.storage.selcloud.ru. Нажимаем Connect. Готово — вы храните данные вне виртуальной машины, в отдельном и масштабируемом хранилище.
Однако способ может быть недостаточно гибким для некоторых задач. Допустим, вы хотите настроить подключение к S3 в проекте. Так вы сможете добавлять метаданные к файлам, прописывать сценарии чтения и записи и кастомизировать их под свои цели.
Еще один из многочисленных инструментов для работы S3 — утилита s3fs. Она позволяет использовать объектное хранилище как файловую систему на операционных системах Linux. Подробнее — в инструкции.
С помощью Jupyter Notebook
Рассмотрим подключение к S3-бакету в Jupyter Notebook. Бакет — это сущность для хранения объектов в S3. Как и ранее, переходим в браузере по ссылке (<IP-виртуальной-машины>.pl.davm.selcloud.ru). Выбираем нужную иконку.
1. Импортируем комплект средств разработки (SDK) boto3, предназначенный для работы с AWS. Подробнее о библиотеке и ее использовании вы можете узнать в документации.
import boto3
Создаем сессию boto3 с указанием URL сервиса S3 для Selectel — https://s3.storage.selcloud.ru. ‘your_access_key_id’ и ‘your_secret_access_key’ — это наши учетные данные доступа к Selectel S3, их мы получили ранее.
session = boto3.session.Session()
s3 = session.client(
service_name='s3',
endpoint_url='https://s3.ru-1.storage.selcloud.ru',
aws_access_key_id='your_access_key_id',
aws_secret_access_key='your_secret_access_key'
)
Пример чтения файла из бакета:
bucket_name = 'your_bucket_name'
response = s3.list_objects_v2(Bucket=bucket_name)
for obj in response['Contents']:
key = obj['Key']
obj = s3.get_object(Bucket=bucket_name, Key=key)
body = obj['Body'].read()
print(f'Key: {key}, Body: {body}')
Соответственно, ‘your_bucket_name’ — имя нашего S3-бакета в Selectel.
Пример записи файла в бакет (метод upload_file):
user_image_path = f"./images/{user_id}.png"
if os.path.exists(user_image_path):
os.remove(user_image_path)
try:
image.save(user_image_path)
s3.upload_file(user_image_path, ‘your_bucket_name’, ‘your_file_name’, ExtraArgs={'Metadata':{'UserPrompt': user_prompt}})
return user_image_path
Здесь мы можем настроить запись метаданных (ExtraArgs). В случае с нейросетью-ботом будет удобно хранить пользовательские запросы. Вывести метаданные в консоли можно следующим способом:
metadata = s3.head_object(Bucket='your_bucket_name', Key=’your_file_name’)
print(metadata)

В каждом файле хранится запрос, на который было сгенерировано изображение. Сценариев применения метаданных множество. В случае с генерацией изображений это полезно для проведения тестов. Мы отслеживанием наименее удачные или спорные иллюстрации и запросы на них. Благодаря этому можно исключать подозрительные генерации на уровне модели и улучшать ее работу.
Заключение
S3 — удобный и функциональный инструмент для облачного хранения данных. Он предлагает высокую надежность, масштабируемость и гибкость, а также идеально подходит для хранения больших объемов данных.
Однако объектное хранилище — это не универсальное решение для любых целей. Так, к примеру, оно не подходит для размещения баз данных. Прежде чем выбрать S3 для своего проекта, необходимо тщательно оценить его возможности и ограничения. Для более детального изучения возможностей S3 рекомендуем ознакомиться с нашим обзором и документацией по работе с S3-хранилищем Selectel.