Как спрогнозировать движение льда в Арктике с помощью ML
В статье посмотрим, как сделать свой первый ML-проект, используя только свертки CNN-моделей.

Привет! Меня зовут Андрей, я студент ИТМО. В вузе есть NSS-лаборатория, в которой создают AutoML-решения и моделируют природные процессы. Например, прогнозируют концентрацию и толщину льда в Арктике. Но выводы и результаты таких исследований могут жить не только в кровавом энтерпрайзе.
Зачем нейросети в Арктике
Итак, все началось с того, что среди математического многообразия исследований лаборатории есть вполне прикладная задача — моделирование распространения льда в Арктике. Ее решение может быть актуально для больших компаний, ведущих бизнес в этом регионе. Например, перевозчиков на Северном морском пути или нефтедобывающих предприятий. Им буквально жизненно необходимо знать, где, когда и какой толщины будет лед, а также куда и с какой скоростью он будет двигаться.
Существует много строгих аналитических методов подобного прогнозирования. Впрочем, их недостатки заключаются в неудобстве использования и масштабирования, а также в большой сложности вычислений. Здесь и вступает в игру машинное обучение.
Очевидно, концентрацию льда в арктических водах можно прогнозировать с помощью нейронных сетей. Сделаем модель, которая на вход будет принимать карты распространения льда, т. е. просто фотографии за некоторый период времени, а на выходе — выдавать карты его прогнозного распространения.
И в этот момент вся романтика Арктики заканчивается. Дальше мы будем говорить только о сверточных нейросетях и моделировании. Как я уже сказал, все, что будет описано ниже, можно использовать не только для прикладных бизнес-задач с миллиардными бюджетами. Это подойдет и для первого пет-проекта, чтобы поближе познакомиться с ML. Теоретически описанными методами можно попытаться предсказать видеоряд, ведь это тоже некоторая последовательность изображений во времени.
Решаемая задача — прогнозирование n-мерного временного ряда (в нашем случае изображения — это одноканальные тензоры). Для искушенных читателей приведу статьи сотрудников NSS-лаборатории, которые рассматривают применение сверточных нейросетей для предиктивной аналитики, немного их модернизируют и наглядно демонстрируют жизнеспособность такого подхода:
Чем хороши свертки
Чтобы спрогнозировать изменения изображений, можно использовать сверточные нейронные сети. Они легче рекуррентных аналогов, формально более подходящих для данных вида временной последовательности. К тому же, мы работаем с изображениями карт, которые удобно обрабатывать именно свертками. Наверняка кто-то сможет предложить альтернативы для более легкого инференса, улучшения и дополнения полученного решения. С удовольствием изучу все в комментариях.
Если вы еще не знакомы со сверточными нейронными сетями, на Хабре есть огромное количество гайдов по ним. Поскольку мы говорим о первых шагах в ML и реализации несложного пет-проекта, глубокое погружение в тему пока не потребуется.
Для понимания работы сверточных нейросетей представим изображение как матрицу, где каждый пиксель — отдельное число. Я хочу извлечь из нее полезные признаки, не забыв о вычислительных сложностях и уменьшив все изображение. Для этого мы проходимся некоторым ядром (другой матрицей) по нашей картинке. Мы поэлементно умножаем, а потом складываем все значения, получая на выходе меньшую по размерам матрицу.
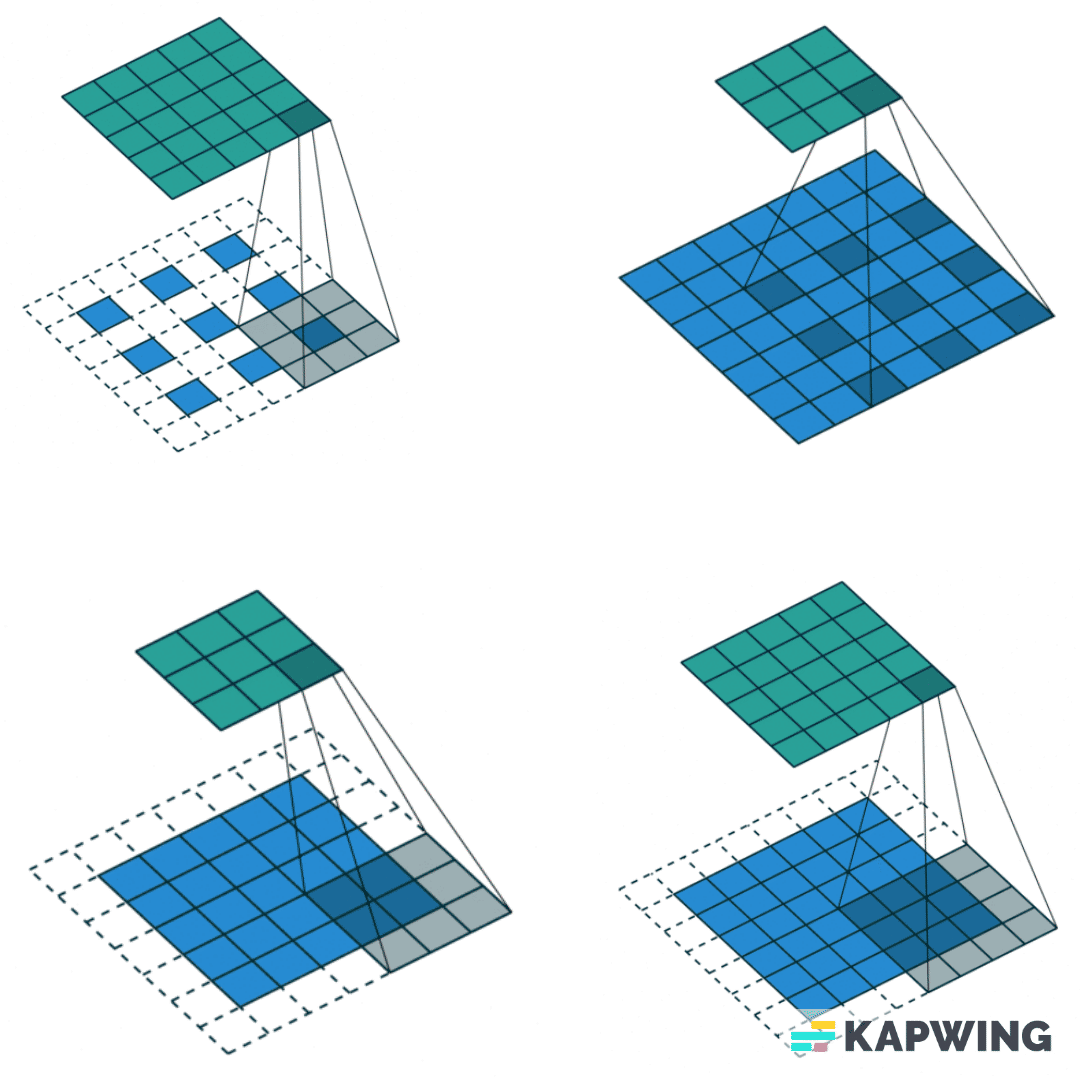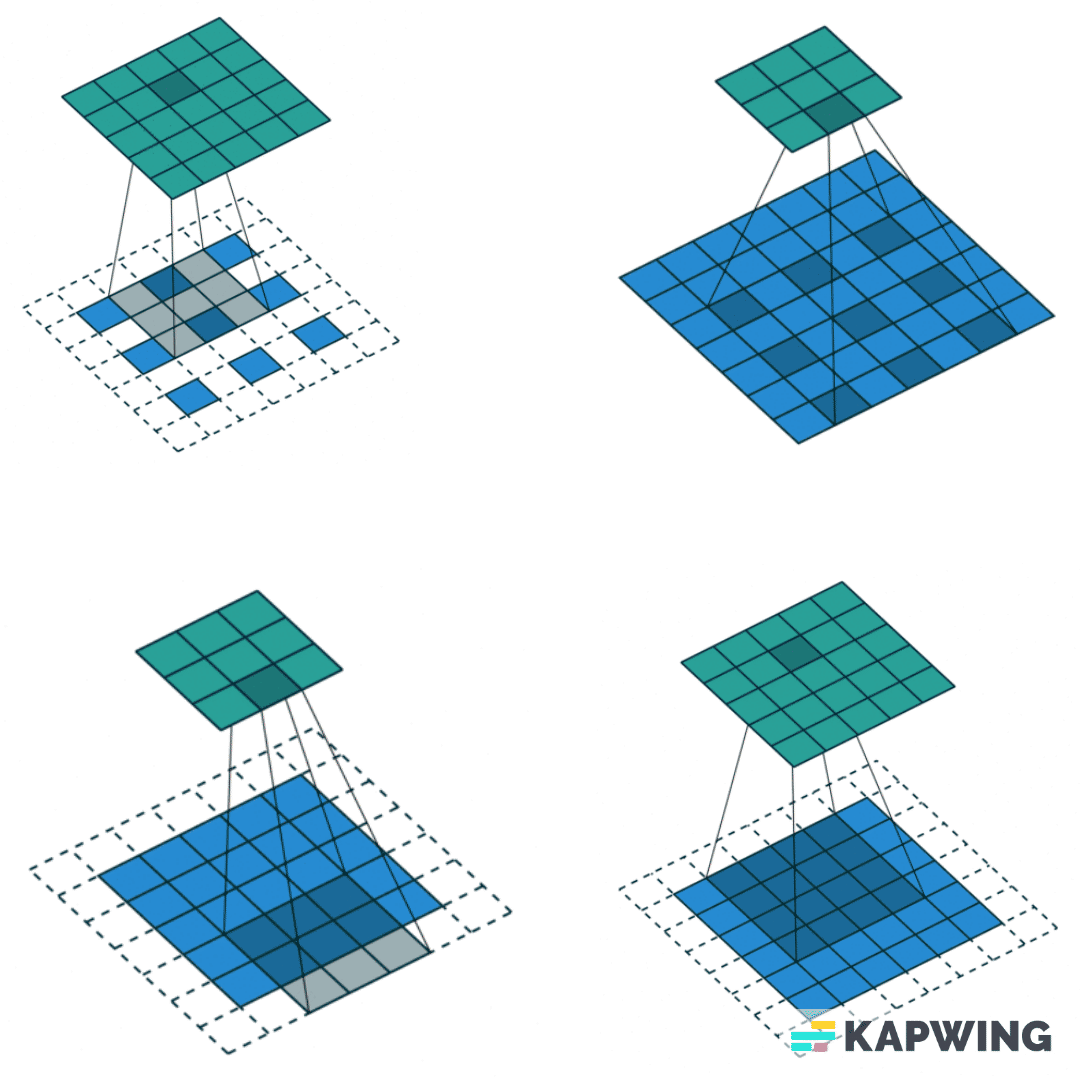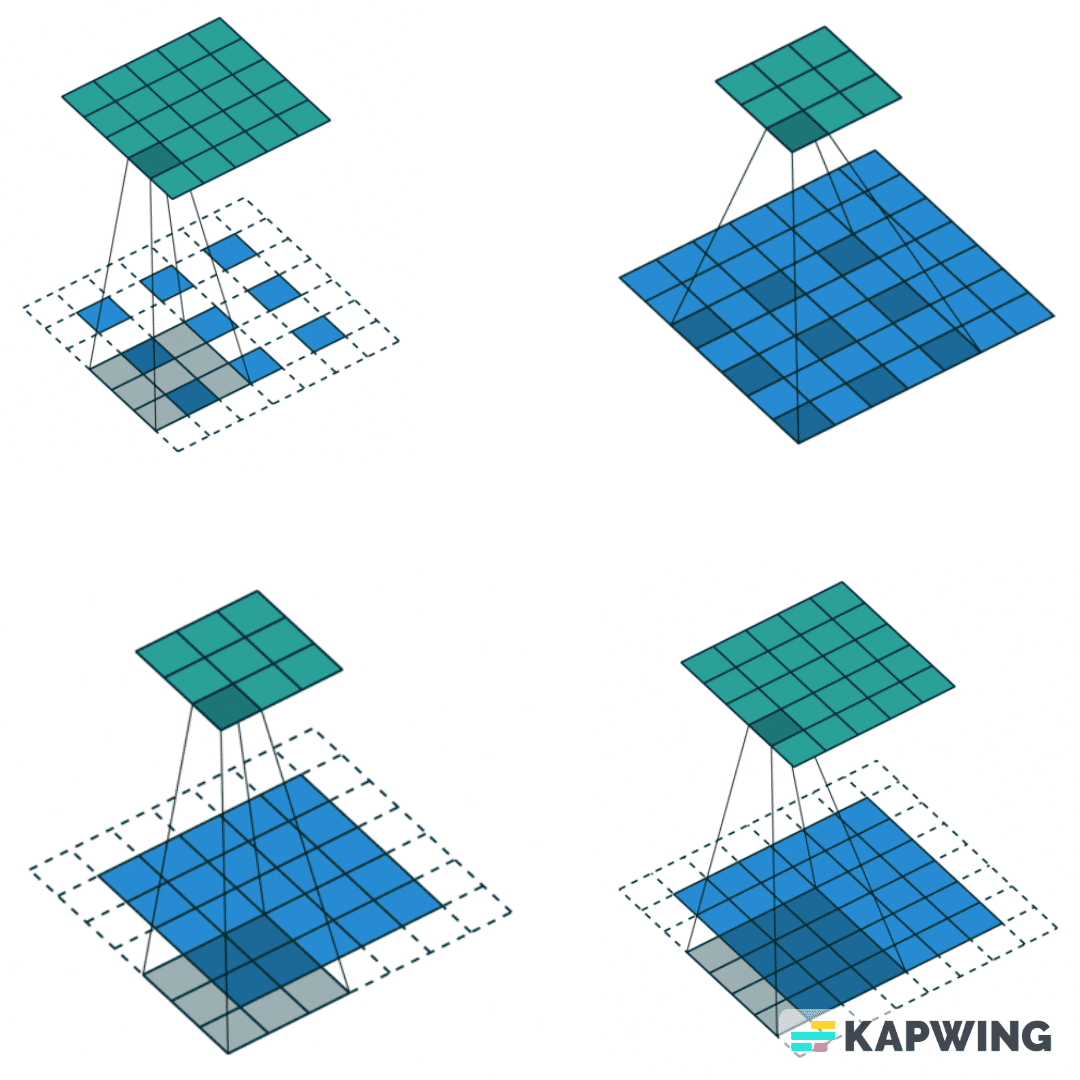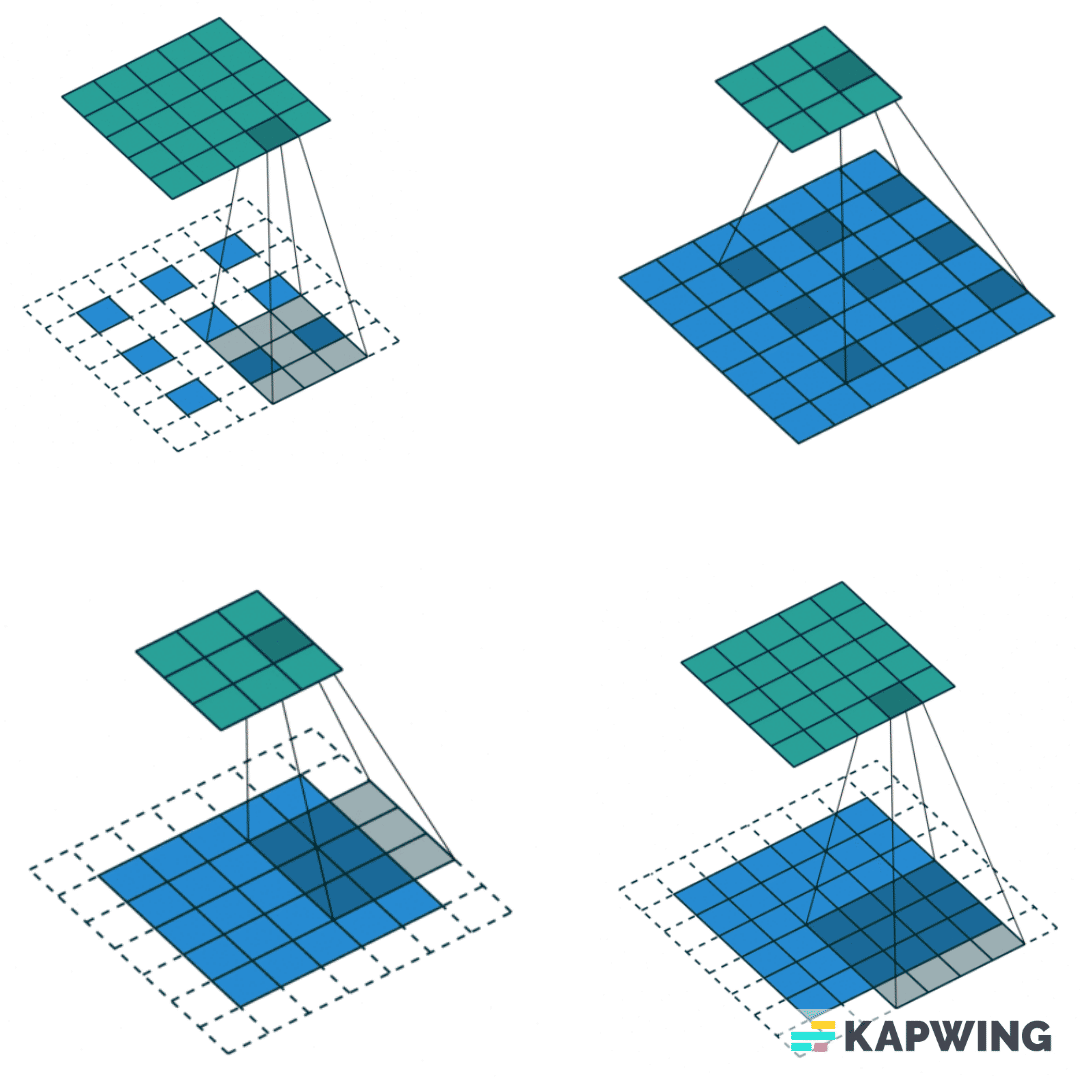
Найти оптимальный вид сверточной нейронной сети — значит понять, какое количество слоев нужно, какие параметры и настройки должны у них быть, какие функции активации использовать, какие дополнительные слои нормализации подставить и т. д. Для этого нужно перепробовать много вариантов, а это не совсем приятная история:
- каждый раз нужно переписывать и менять код модели, который выглядит очень шаблонно и пишется под копирку с помощью control+c и control+v;
- хочется гибко манипулировать настройкой всех параметров нашей модели;
- нужно контролировать модель на работоспособность, чтобы код не падал, входные изображения проходили через все слои и мы понимали, как уменьшается или увеличивается наш feature map (результат каждого сверточного слоя в виде новой матрицы или многомерного тензора).
Для решения этих проблем на основе кода из статей выше я и написал фреймворк TorchCNNBuilder. Он упрощает построение легких сверточных архитектур до пары строк кода.
Хорошие практики open-source проектов
Прежде чем браться за создание собственного инструмента, я решил проверить, не делал ли уже кто-то что-то подобное, причем в виде open source решения. Всегда есть вероятность, что необходимость в разработке своего проекта отсутствует.
Я нашел похожие инструменты: AutoPyTorch и AutoCNN. Оба в той или иной мере затрагивают нужную функциональность и преследуют две важных цели: упрощение подбора оптимальный архитектуры CNN и упрощение написания кода. Но эти решения давно потеряли поддержку и не обладают некоторой гибкостью функций, которые я бы хотел поэтапно добавлять или видоизменять в случае необходимости.
Следующий вопрос — в каком формате должен быть проект? На мой взгляд, наиболее удобный и простой в использовании вариант почти для любой среды разработки — открытый фреймворк. Его можно применять почти везде и он позволит создать действительно универсальный инструмент. Отмечу, что очень важно найти референсы хороших open source проектов, перенять полезные советы и подглядеть эффективные практики. Для ознакомления могу посоветовать большой репозиторий от NSS лаборатории и Open Source Meetup. Там можно найти мастер-классы, шаблоны типовых файлов, стайлгайды и т. д.
В общей структуре проекта я выделил под каждую ветку функциональности отдельный API, т. е. некоторый интерфейс и подмодуль. Получился подобный дизайн директорий:
torchcnnbuilder/
├── preprocess/
│ ├── __init__.py
│ └── time_series.py
├── __init__.py
├── builder.py
├── models.py
└── version.py
Здесь внутри файла builder.py будут храниться функции, отвечающие за класс «строитель». Он вызывает свои методы и строит сверточные последовательности модели или просто стакает друг за другом слои torch.
В директории preprocess хранятся вспомогательные функции. Они необходимы для первичной предобработки наших данных и их подготовки ко входу в модель. Вся апробация алгоритма происходит по факту на данных для временных рядов, потому и файл с функциями называется подобным образом.
В models.py лежат готовые шаблоны сверточных моделей, которые написаны с помощью автоматически строящихся последовательностей из Builder. Таким образом, получается следующая идея проекта:
- preprocess — предобработка данных,
- builder — последовательное построение сверточных слоев друг за другом,
- models — примеры моделей на базе кода из builder.
Все это будет основным API библиотеки torchcnnbuilder. Помимо этого есть корневая директория самого проекта (корень репозитория в GitHub). Туда я добавил документацию, лицензию, зависимости и файл установки для pip. Все это понадобится для общей настройки фреймворка. В моем случае значительная часть функций уже реализована, поскольку код взят из уже упомянутой статьи Forecasting of Sea Ice Concentration using CNN, PDE discovery and Bayesian Networks. Но даже так требуется серьезный рефакторинг. Разработка общего пайплайна и дизайна всей системы по факту уже является его первым этапом.
Зачем нужен рефакторинг, если код и так работает? Код для научной статьи и продакшен-решение — разные сущности, т. к. они преследуют разные идеи. Во втором случае меня интересует масштабируемость предложенных идей и практическая реализация решения в контексте нескольких сценариев использования. В идеале бы хотелось совместить лучшие практики из обеих областей: воспроизводимость, читабельность, масштабируемость, работоспособность, хорошую оптимизацию и т. д.
Следуя всем канонам удобных и приятно читаемых open source проектов, я выполнил три простых действия (помимо разработки и доработки ключевых функций):
- добавил комментарии и док-стринги,
- добавил типизацию с typing,
- учел нейминг переменных и pep8.
Для будущей публикации библиотеки советую пройтись по следующим ссылкам:
- Как загрузить свой модуль на PyPI — небольшая дока на GitHub,
- Как выложить свой модуль на PyPI — мини-туториал на Хабре.
Реализуйте этот или другой ML-проект на виртуальных серверах для машинного обучения и аналитики данных. Обучайте и тестируйте ваши модели с помощью предустановленных инструментов и фреймворков: PyTorch, TensorFlow, Keras, OpenCV, XGBoost, Jupyter Notebook. Для ускорения работы с нейросетями доступны семь моделей GPU: Tesla T4, А2, А30, А100, А2000, А5000, GTX 1080 — до восьми штук на одной виртуальной машине.
Разработка ключевых функций
Теперь пройдемся по каждому API в отдельности и посмотрим, что в итоге получилось с проектом и с какими трудностями я столкнулся в процессе реализации.
Предобработка
Итак, основной архитектурой выбрана сверточная нейронная сеть. Теперь нужно понять, в каком виде подавать в нее данные.
Я хочу предсказывать несколько карт будущего распространения льда, имея на входе некоторое количество предыдущих карт. Это означает, что X-часть выглядит как тензор из нескольких последовательных изображений (они одноканальные, просто матрицы), которые являются предысторией предсказания.
В подобной постановке модель можно обучать по-разному. Например, поделить весь датасет на «до» (X часть) и «после» (Y часть). Или двигаться некоторым окном, где по конкретному фиксированному числу X-сэмплов можно предсказывать фиксированное число Y-сэмплов. Иногда первый случай удобнее. А иногда хочется свести задачу к виду «по 30 предыдущим дням хочу предсказывать 10 следующих». Для обоих случаев реализованы функции single_output_tensor и multi_output_tensor.
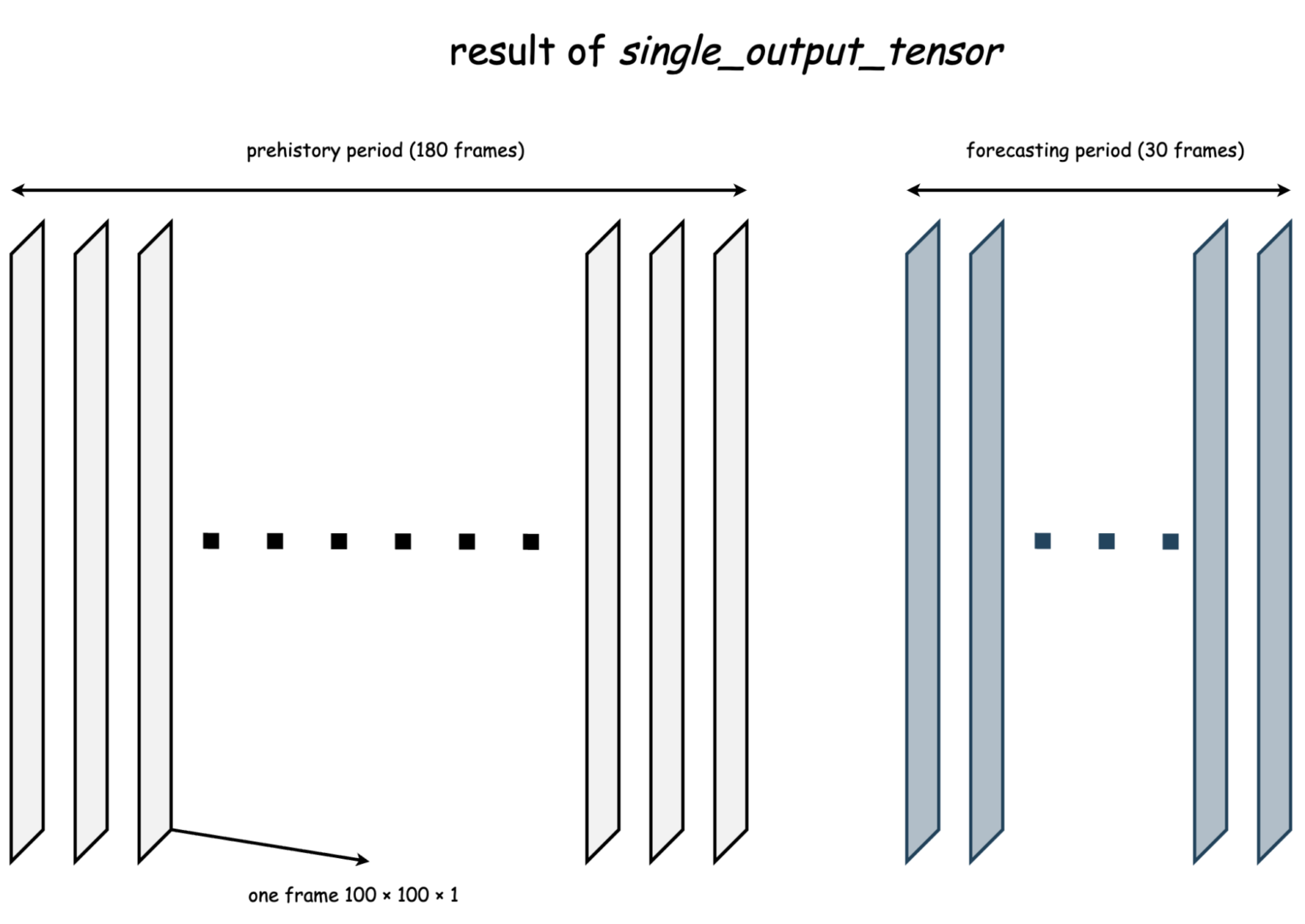
Кстати, один объект (one frame на картинке, в нашем случае — карта льда) гипотетически может иметь любую размерность и быть разным по своей природе: от n-мерного вектора до n-мерного тензора.
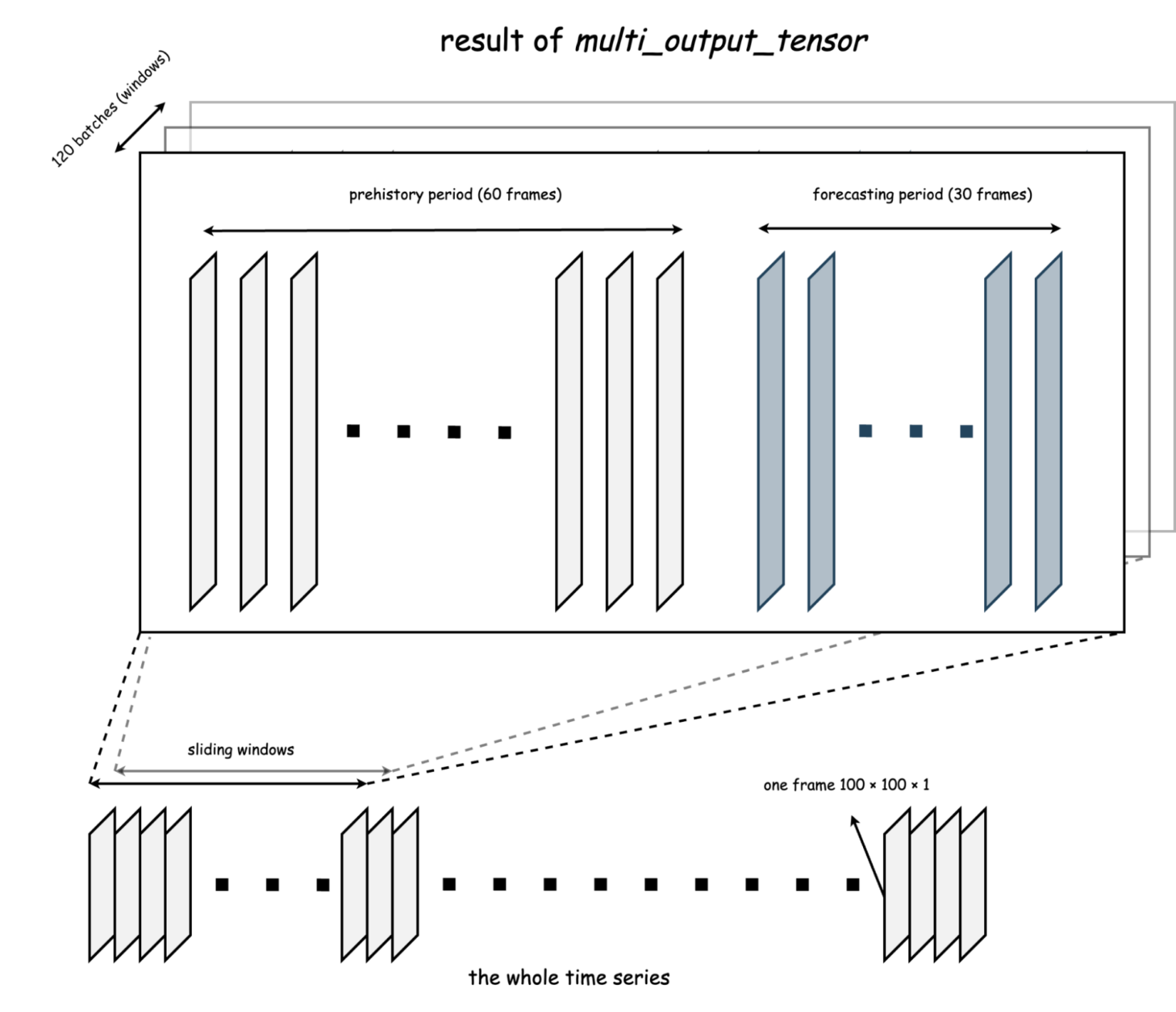
На самом деле, мы просто итерируемся в цикле по каждому тензору, агрегируя их в «группы». Закономерный вопрос — разве single_output_tensor не является частным случаем multi_output_tensor? Так и есть, но, признаюсь, я сделал две функции, т. к. в рамках одной попросту не смог удачно организовать и структурировать код, сохраняя дополнительные возможности:
- независимо бинаризовать X и Y части по заданному трешхолду (параметры x_binarize и threshold),
- добавлять другие временные ряды, которые либо стакаются к X и Y частям по новому измерению, либо конкатенируются к ним (зависит от выбора пользователя, параметры additional_x, additional_is_array, additional_is_stack).
Пример вызова функции со всеми параметрами выглядит следующим образом:
dataset = multi_output_tensor(data=noise_data,
additional_x=[noise_data.copy(), noise_data.copy(), noise_data.copy()],
additional_is_array=True,
forecast_len=30,
pre_history_len=60,
threshold=0.5,
x_binarize=True)
А таким кодом можно проверить, какие размерности внутри батчей мы получили:
for i, batch in enumerate(dataset):
print(f'batch number: {i}',
f'new stacked X shape: {batch[0].shape}\nY shape: {batch[1].shape}',
f'new stacked X max: {batch[0].max()} | min: {batch[0].min()}\nY max: {batch[1].max()} | min: {batch[1].min()}',
sep='\n',
end='\n\n')
if i == 1:
break
print(f'Dataset len (number of batches/X-windows): {len(dataset)}')
Вывод кода:
batch number: 0
new stacked X shape: torch.Size([60, 4, 100, 100])
Y shape: torch.Size([30, 100, 100])
new stacked X max: 1.0 | min: 0.0
Y max: 1.0 | min: 0.0
batch number: 1
new stacked X shape: torch.Size([60, 4, 100, 100])
Y shape: torch.Size([30, 100, 100])
new stacked X max: 1.0 | min: 0.0
Y max: 1.0 | min: 0.0
Dataset len (number of batches/X-windows): 120
Соответствующие примеры и подробную документацию с описанием всех параметров, классов и функций для preprocess можно найти в директории examples.
Сверточные последовательности
На этом этапе основная задача — сделать инструмент для автоматизации построения сверточных слоев. Чтобы валидировать, что происходит внутри сверточных последовательностей, было бы неплохо иметь четкое представление о размерах тензора после каждого слоя. В таком случае можно еще до forward-прогона через слой аналитически понимать, ляжет модель или нет, ведь у нас есть возможность просчитать все размерности в любой момент времени. Для всего этого достаточно реализовать подобные формулы из torch документации в виде соответствующих им функций.
На данный момент в PyTorch есть поддержка одномерных, двумерных и трехмерных сверточных и транспонированных (в некотором смысле «обратных») сверточных операций. По итогу получим шесть функций. Также отмечу, что каждое измерение (условно «высота», «ширина» и т. д.) считается аналогично. Это значит, можно сделать всего одну функцию для подсчета одного измерения, а далее использовать ее во всех остальных случаях n раз для n измерений. Дальнейшие формулы взяты из документации nn.Conv2d и nn.TransposeConv2d и учитывают сразу несколько параметров:
- kernel — размер ядра свертки,
- padding — дополнение результата каким-то значениями,
- stride — шаг свертки,
- dilation — какие по счету друг от друга берем значения тензора для свертки.
Формула подсчета output измерения после сверточной операции:
H_{out} = \lfloor \frac{H_{in} + 2 \times padding[0] - dilation[0] \times (kernel[0] - 1) + 1}{stride[0]} \rfloor + 1Формула подсчета output измерения после транспонированной сверточной операции:
H_{out} = (H_{in} - 1) \times stride[0] - 2 \times padding[0] + dilation[0] \times (kernel\_size[0] - 1) + output\_padding[0] + 1Теперь есть удобные функции, которыми можно подсчитать output измерения по любым заданным пользователем параметрам. Есть также параметр n_layers. Его можно использовать, чтобы понять, каким будет выход свертки после нескольких одинаковых идущих друг за другом слоев (внутри обычный цикл):
from torchcnnbuilder.builder import conv1d_out, conv2d_out, conv3d_out
# считаем выход для двумерной свертки
new_size = conv2d_out(input_size=(55, 40),
kernel_size=(4, 5),
padding=(1, 0),
dilation=(2, 2))
print(f'Tensor size after nn.Conv2d: {new_size}')
from torchcnnbuilder.builder import conv_transpose1d_out, conv_transpose2d_out, conv_transpose3d_out
# считаем выход для трехмерной транспонированной свертки
new_size = conv_transpose3d_out(input_size=(11, 11, 12),
kernel_size=3,
dilation=(2, 2, 1),
n_layers=3)
print(f'Tensor size after nn.ConvTranspose2d: {new_size}')
Выход скрипта:
Tensor size after nn.Conv2d: (51, 32)
Tensor size after nn.ConvTranspose2d: (23, 23, 24)
Сами сверточные последовательности построю в классе Builder. Инициализирую класс с input размерностями и с помощью его методов построю блок за блоком сверточные слои. Каждая сверточная последовательность — это nn.Sequential объект, который состоит из подблоков. Внутри блока выстраивается логика «слой свертки -> слой нормализации -> слой функции активации».
А зачем отдельно создавать блоки, которые все равно потом все находятся в одной большой последовательности? Дело в том, что в какой-то момент мне захотелось попробовать сделать слои из U-Net архитектуры, где есть несколько идущих подряд почти одинаковых сверток, которые на выходе не меняют изначальный размер тензора. К тому же такая гибкость позволяет потенциально отдельно настраивать каждый блок (хотя это пока в полной мере не реализовано в коде).
Признаюсь, подобная декомпозиция дизайна класса пришла в голову не сразу. Конечно, по-хорошему сначала нужно максимально подробно все спроектировать, а уже потом приступать к написанию кода. Я же часто учился на своих ошибках, понимая, что код получается монструозным и нечитабельным. Это главный сигнал плохого проектирования.
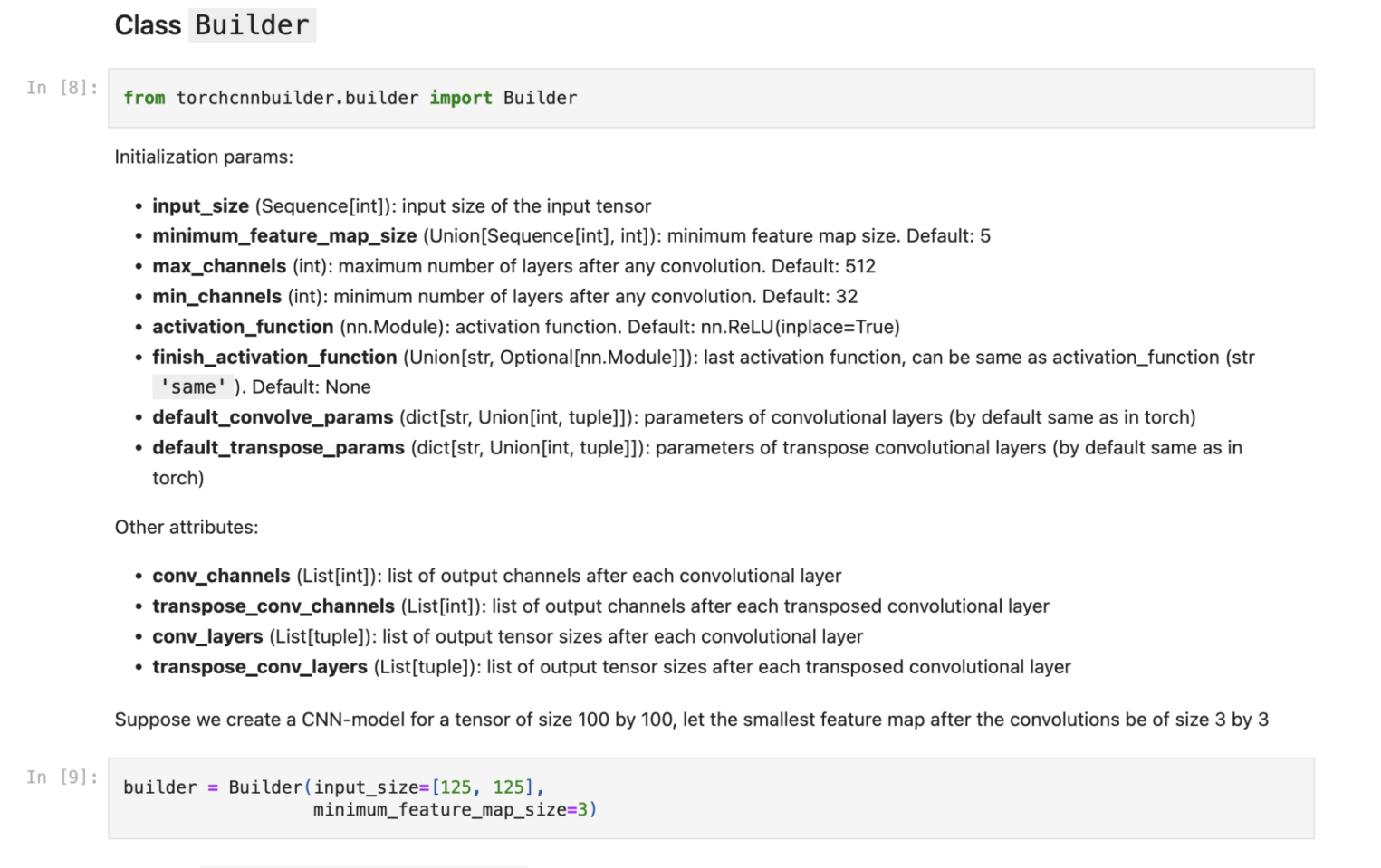
Реализация кода тоже достаточно простая. Итеративно добавляю сверточные блоки и каждый раз проверяю output размерность с помощью написанных выше формул. Если размерность становится меньше допустимого минимального значения (параметр minimum_feature_map_size), пробрасываю пользователю кастомную ошибку.
Параллельно проверяю допустимое количество каналов после каждого слоя. Обычно увеличение или уменьшение их числа происходит по экспоненте. Хотелось бы как-то ограничить диапазон изменения количества каналов. Для этого стоит добавить параметры max_channels и min_channels. Если они нарушаются, опять же выбрасываю кастомную ошибку.
Также я адаптировал и имплементировал другой метод расчета каналов, который рассчитывается пропорционально изменению размеров output тензора (его предложили коллеги постарше). В документации examples про это тоже можно почитать подробнее. На деле он просто дает последовательность, которая растет с гораздо меньшей скоростью:
From torchcnnbuilder.builder import Builder
builder = Builder(input_size=[125, 125],
minimum_feature_map_size=3)
# строим последовательность из двух слоев, где каждый слой = двум подблокам
builder.build_convolve_sequence(n_layers=2,
in_channels=3,
sub_blocks=2,
normalization='dropout')
На выходе из такого скрипта получаем:
Sequential(
(conv 1): Sequential(
(sub-block 1): Sequential(
(0): Conv2d(3, 34, kernel_size=(9, 9), stride=(1, 1), padding=(4, 4))
(1): ReLU(inplace=True)
)
(sub-block 2): Sequential(
(0): Conv2d(34, 34, kernel_size=(9, 9), stride=(1, 1), padding=(4, 4))
(1): ReLU(inplace=True)
)
)
(conv 2): Sequential(
(sub-block 1): Sequential(
(0): Conv2d(34, 65, kernel_size=(9, 9), stride=(1, 1), padding=(4, 4))
(1): ReLU(inplace=True)
)
(sub-block 2): Sequential(
(0): Conv2d(65, 65, kernel_size=(9, 9), stride=(1, 1), padding=(4, 4))
(1): ReLU(inplace=True)
)
)
)
Как видно, получился уже неплохой костяк сверточной сети. Если хочется более гибкий инструмент, блоки можно строить и по отдельности. В обоих случаях есть возможность указывать тип нормализации (пока это dropout и batchnorm) и его параметры, а также параметры самих сверток вместе со способом подсчета каналов:
# строим один сверточный блок
conv_layer = builder.build_convolve_block(in_channels=3,
out_channels=64,
params={'kernel_size': (7, 7), 'dilation': (3, 3)},
normalization='batchnorm',
eps=1e-7)
conv_layer
Результат:
Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(1, 1), dilation=(3, 3))
(1): BatchNorm2d(64, eps=1e-07, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
Отмечу, что размерность нормализации и сверточных операций автоматически подстраивается под размерность input тензора (dim может быть равно 1, 2 или 3). Зачастую в лаборатории мы пользуемся свертками на одну размерность меньше, чем наш input. Например, трехмерные RGB-изображения обрабатываем с помощью Conv2d, но формально можно это делать и с помощью Conv3d. Для таких случаев есть возможность регуляризации параметра conv_dim:
builder.build_convolve_block(in_channels=3,
out_channels=4,
normalization='dropout',
conv_dim=3)
Результат:
Sequential(
(0): Conv3d(3, 4, kernel_size=(3, 3, 3), stride=(1, 1, 1))
(1): Dropout3d(p=0.5, inplace=False)
(2): ReLU(inplace=True)
)
Весь инструмент адаптирован также для транспонированных сверточных операций, нужно просто добавить transpose перед словом convolve. Единственное отличие в том, что у транспонированного блока можно убрать функцию активации, т. к. предполагается, что эти слои могут находиться в финальной decoder части, где не всегда нужна активация.
На самом деле, транспонированные и обычные сверточные операции не полностью взаимно обратные. Это проявляется в изменении размеров output тензоров в зависимости от четности/нечетности параметров свертки. По этим причинам в конце транспонированной последовательности стоит nn.AdaptiveAvgPool2d, который сглаживает эту разницу в «один пиксель».
# меняем последнюю функцию активации
builder.finish_activation_function = 'same'
builder.build_transpose_convolve_sequence(n_layers=3,
in_channels=30,
out_channels=2,
normalization='batchnorm')
Результат:
Sequential(
(deconv 1): Sequential(
(0): ConvTranspose2d(30, 15, kernel_size=(3, 3), stride=(1, 1))
(1): BatchNorm2d(15, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(deconv 2): Sequential(
(0): ConvTranspose2d(15, 7, kernel_size=(3, 3), stride=(1, 1))
(1): BatchNorm2d(7, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(deconv 3): Sequential(
(0): ConvTranspose2d(7, 2, kernel_size=(3, 3), stride=(1, 1))
(1): BatchNorm2d(2, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(resize): AdaptiveAvgPool2d(output_size=(125, 125))
)
Шаблоны моделей
В последней части API models будут храниться шаблоны сверточных архитектур, которые сделаны с помощью автоматически собираемых последовательностей. Пока там только одна модель — Forecaster Model. Она состоит из сверток в encoder части и транспонированных сверток в decoder части. И именно ее и будем использовать для прогнозирования новых карт распространения льда.
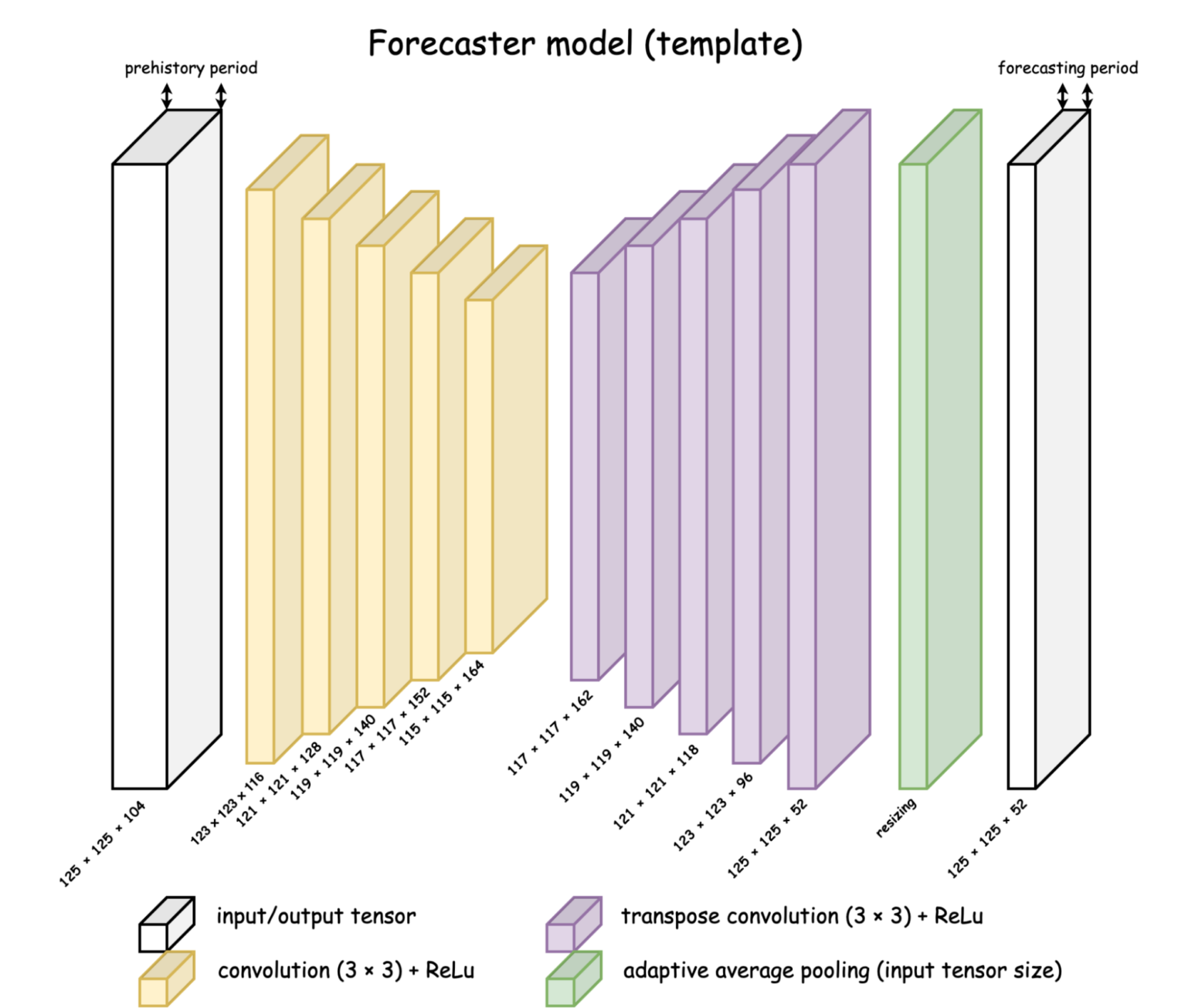
Основной код модели состоит из двух строк инициализаций сверточных последовательностей. Остальное является проверкой на дополнительные настраиваемые параметры (можно добавить нормализацию, менять активации и т. д.).
from typing import Union, Sequence, Optional
from torchcnnbuilder.builder import Builder
import torch.nn as nn
# ------------------------------------
# CNN Forecaster pattern class
# ------------------------------------
class ForecasterBase(nn.Module):
"""
The template class of the time series prediction CNN-architecture. The source of the original `article code
<https://github.com/ITMO-NSS-team/ice-concentration-prediction-paper?ysclid=lrhxbvsk8s328492826>`_.
Attributes:
convolve (nn.Sequential): convolutional sequence - encoder part
transpose (nn.Sequential): transpose convolutional sequence - decoder part
conv_channels (List[int]): list of output channels after each convolutional layer
transpose_conv_channels (List[int]): list of output channels after each transposed convolutional layer
conv_layers (List[tuple]): list of output tensor sizes after each convolutional layer
transpose_conv_layers (List[tuple]): list of output tensor sizes after each transposed convolutional layer
"""
def __init__(self,
input_size: Sequence[int],
n_layers: int,
in_channels: int,
out_channels: int,
n_transpose_layers: Optional[int] = None,
convolve_params: Optional[dict] = None,
transpose_convolve_params: Optional[dict] = None,
activation_function: nn.Module = nn.ReLU(inplace=True),
finish_activation_function: Union[str, Optional[nn.Module]] = None,
normalization: Optional[str] = None) -> None:
"""
The constructor for ForecasterBase
:param input_size: input size of the input tensor
:param n_layers: number of the convolution layers in the encoder part
:param in_channels: number of channels in the first input tensor (prehistory size)
:param out_channels: number of channels in the last output tensor (forecasting size)
:param n_transpose_layers: number of the transpose convolution layers in the encoder part. Default: None (same as n_layers)
:param convolve_params: parameters of convolutional layers (by default same as in torch). Default: None
:param transpose_convolve_params: parameters of transpose convolutional layers (by default same as in torch). Default: None
:param activation_function: activation function. Default: nn.ReLU(inplace=True)
:param finish_activation_function: last activation function, can be same as activation_function (str 'same'). Default: None
:param normalization: choice of normalization between str 'dropout' and 'batchnorm'. Default: None
"""
super(ForecasterBase, self).__init__()
builder = Builder(input_size=input_size,
activation_function=activation_function,
finish_activation_function=finish_activation_function)
if n_transpose_layers is None:
n_transpose_layers = n_layers
if convolve_params is None:
convolve_params = builder.default_convolve_params
if transpose_convolve_params is None:
transpose_convolve_params = builder.default_transpose_params
self.convolve = builder.build_convolve_sequence(n_layers=n_layers,
in_channels=in_channels,
params=convolve_params,
normalization=normalization,
ascending=True)
self.transpose = builder.build_transpose_convolve_sequence(n_layers=n_transpose_layers,
in_channels=builder.conv_channels[-1],
out_channels=out_channels,
params=transpose_convolve_params,
normalization=normalization,
ascending=True)
self.conv_channels = builder.conv_channels
self.transpose_conv_channels = builder.transpose_conv_channels
self.conv_layers = builder.conv_layers
self.transpose_conv_layers = builder.transpose_conv_layers
def forward(self, x):
"""
Forward pass of the model
:param x: tensor before forward pass
:return: tensor after forward pass
"""
x = self.convolve(x)
x = self.transpose(x)
return x
Класс Builder хранит в себе историю размерностей и каналов последней сверточной последовательности, что было достаточно легко реализовать за счет аналитических формул проверки (просто в каждой итерации делаем append результата в общий список). А это значит, каждая модель, реализованная через класс Builder, тоже хранит в себе подобную историю.
Тестирование
Я пока не писал автоматических тестов. Для проверки работоспособности кода использовал синтетические данные — видеоряд из движущегося по кругу квадратика. Это тоже последовательность изображений во времени. Значит, с помощью такой модели можно пробовать предсказывать наивные видеоряды.
from torchcnnbuilder.models import ForecasterBase
from torchcnnbuilder.preprocess.time_series import multi_output_tensor, single_output_tensor
import torch.nn as nn
# инициализируем модель
model = ForecasterBase(input_size=[65, 65],
in_channels=120,
out_channels=40,
n_layers=5,
normalization='batchnorm',
finish_activation_function=nn.ReLU(inplace=True))
# агрегируем данные
train_dataset = multi_output_tensor(data=train,
pre_history_len=120,
forecast_len=40)
test_dataset = single_output_tensor(data=test,
forecast_len=40)
Лучший результат я получил при другой конфигурации модели, нежели в примере выше. Пришлось отказаться от батчнормализации, поставить сигмоиду в качестве финальной функции активации и обучать вместе с кросс-энтропией. На деле я просто заставил модель запомнить видеоряд и идеально его воспроизводить с какого-то момента:
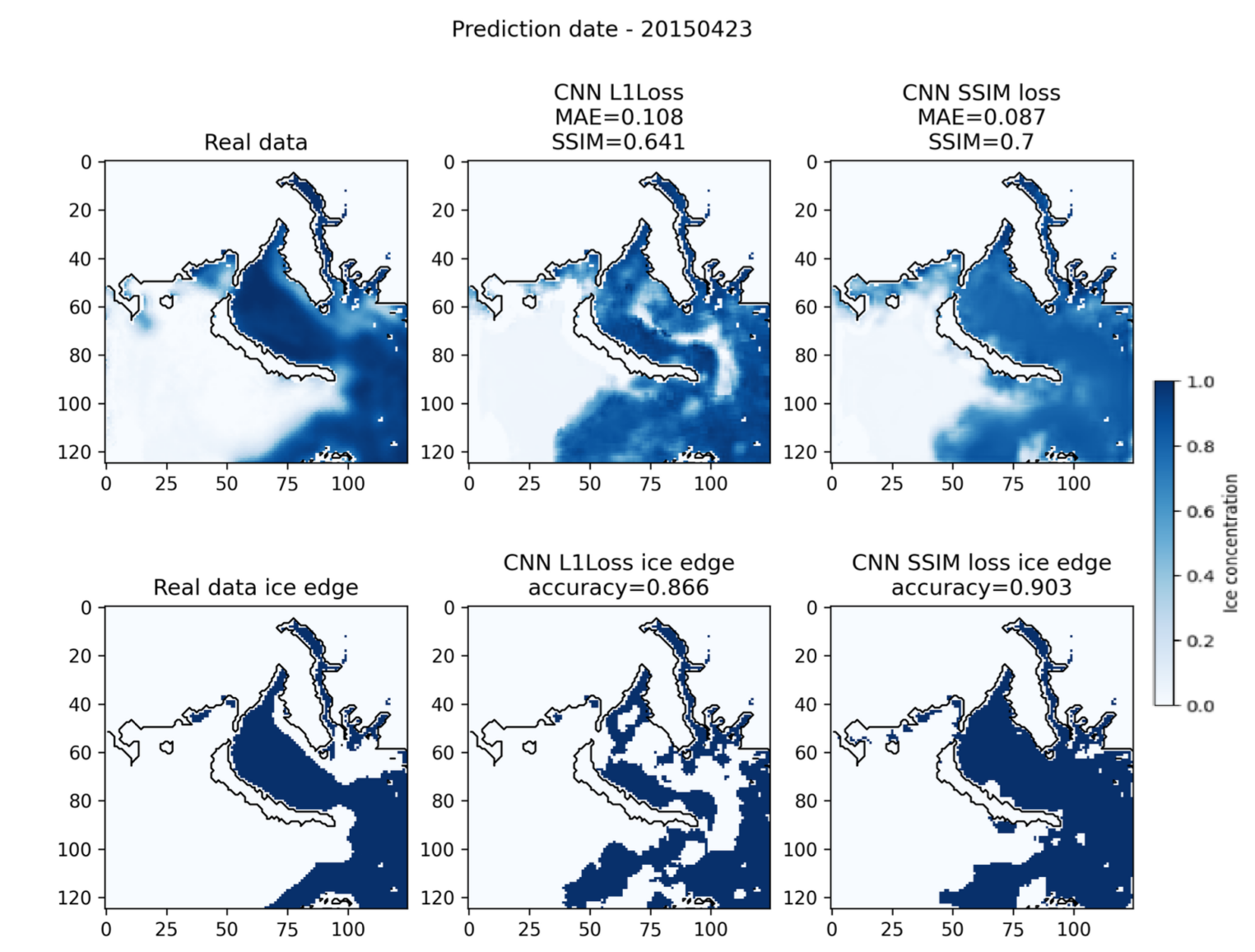
Для настоящих данных на арктических морях тоже было опробовано большое количество настроек модели (комбинации loss-ов, наличие или отсутствие нормализации, разные функции активации, количество слоев, размеры ядер сверток и т.д.). На момент выхода статьи Forecasting of Sea Ice Concentration using CNN, PDE discovery and Bayesian Networks одними из лучших вариантов были модели, обученные на L1 и SSIM лоссах. Но эксперименты с архитектурой и алгоритмом обучения до сих пор продолжаются.
Ниже представлено два ряда графиков из упомянутой статьи. Это карты распределения толщины льда в непрерывном диапазоне от 0 до 1 и карты кромки льда, полученные за счет бинаризации по заранее выбранному трешхолду. Результаты моделей сравнивались по двум критериям одновременно, т. к. важна не только толщина, но и граница распространения.
Итог
Полученное решение можно воспринимать как MVP более продвинутого исследовательского инструмента. Конечно, в планах есть его доработка, новый рефакторинг и расширение функций. В моем представлении разработка подобных пет-проектов хорошо укладывается в итеративный процесс, когда ты поэтапно улучшаешь свой продукт, не стремясь за лучшим качеством с первых строк.
Исследование возможностей сверточных сетей в задаче предсказания карт льда северных вод еще продолжается. Уже есть неплохие результаты в соотношении времени инференса, легковесности модели и точности прогнозирования.
Надеюсь, мой опыт решения очень маленькой, но вполне прикладной и конкретной задачи поможет найти вдохновение в поиске темы для своего первого ML-проекта.
Напоминаю, что весь код лежит на GitHub. Вероятно, в будущем этот фреймворк или его наработки станут фундаментом более узкоспециализированных, профессиональных и серьезных проектов. Пока же это, скорее, демонстрация потенциальных возможностей, агрегирование научных изысканий и пример первого пет-проекта в ML.





