

Все изображения принадлежат их соответствующим правообладателям, используются исключительно в информационных целях и не подразумевают наличие какого-либо аффилированного отношения между Selectel и правообладателями.
Когда дело доходит до инференса ML-моделей, на ум приходит стандартный вариант — задеплоить Helm chart с Triton в Kubernetes. А что если добавить магии, как в «Аватаре»?
Привет! Я — Антон, DevOps-инженер в команде Data/ML-продуктов Selectel. В статье я продолжу рассказывать о нашем новом продукте — Inference-платформе (для которой все еще доступен бесплатный двухнедельный тест). На этот раз рассмотрим пять новых фичей, которые и отличают ее от стандартного варианта. Вас ждет тест работающих моделей без даунтайма, генерация котят голосом и много другой магии.
Для наглядности я бы сравнил нашу платформу с аватаром Аангом — обладателем силы четырех стихий: огня, воды, земли, воздуха и духовной составляющей, мостом между нами и миром духов.

Пришло время рассмотреть каждый элемент нашей платформы подробнее!
Вода — Canary Deployment

Знакомьтесь, это Корра— маг школы воды. Она умеет управлять потоками жидкости для нанесения точечных ударов в битве и для лечения ран союзников. В нашей платформе мы так же умеем управлять потоком трафика, распределяя его между двумя версиями инференса с помощью Canary Deployment.
Чтобы понять, как трафик распределяется по инференсам, стоит обозначить все компоненты, которые участвуют в этом процессе, вплоть до конкретного пода. Рекомендую к ознакомлению отличную статью на Хабре о работе Istio.
В случае Inference-платформы мы решаем следующую задачу. Допустим, клиент хочет обновить ML-модель без даунтайма и протестировать ее новую версию на ограниченном трафике. Если по результатам теста все хорошо, трафик на обновленную модель можно направлять в полном объеме. Если нет, ее нужно доработать. Схематично это выглядит как на рисунке ниже.
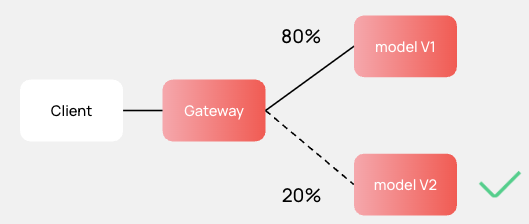
Мы можем направить на новую версию, скажем, 20% трафика. Если тест будет успешным, увеличим его до 100%. Это и есть Canary Deployment.
Для реализации стратегии нам понадобились следующие сущности.
- Istio Gateway — через шлюз проходит весь трафик. Это наш балансировщик нагрузки в Managed Kubernetes.
- Virtual Service — обеспечивает связность между Istio Gateway и Inference-платформой. Именно здесь указывается, в каком соотношении будет разделен трафик между моделями.
- Istio Injection — на каждый namespace, где находится инференс, необходимо установить лейбл istio-injection=enabled. Это нужно, чтобы envoy пробросился как side-контейнер.
- Jaeger — сервис сбора трейсов запросов. Далее мы будем его визуализировать, о чем я расскажу ниже.
Первое время мы долго не могли понять, как имплементировать поддержку Basic Auth в нашу платформу. Сначала даже оборачивали запросы через traefik, так как там был опыт внедрения авторизации. Но потом нашли issue на GitHub и смогли реализовать Basic Auth в Istio с помощью следующего манифеста Virtual Service:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: kafka-ui
namespace: kafka-dev
spec:
hosts:
- "kafka-ui-dev.example.com"
gateways:
- gateway-kafka-ui-dev
http:
- match:
- uri:
prefix: "/"
headers:
Authorization:
exact: "Basic YWRtaW46MTIzNDU2"
# YWRtaW46MTIzNDU2 - its base64 encode admin:123456
route:
- destination:
host: kafka-ui
port:
number: 80
timeout: 3s
- match:
- uri:
prefix: "/"
directResponse:
status: 401
headers:
response:
set:
Www-Authenticate: 'Basic realm="Authentication Required"'
Мы добились обновления моделей без даунтайма и протестировали их новые версии с помощью Canary Deployment. Пора переходить к реализации автоскейлинга.
Огонь — автоскейлинг

Это Зуко — мастер огненной магии. Он способен раздуть из искры огромное пламя, а потом погасить его при необходимости. Так и наша платформа умеет масштабироваться под входящей нагрузкой.
Чтобы наша инфраструктура автоматически масштабировалась при увеличении входящего трафика, нам необходимо его измерять. Для этого отлично подходит Prometheus-адаптер. Он позволяет конвертировать метрики Triton в Prometheus в кастомные метрики Kubernetes, по которым Horisontal Pod Autoscaler (HPA) будет производить масштабирование.
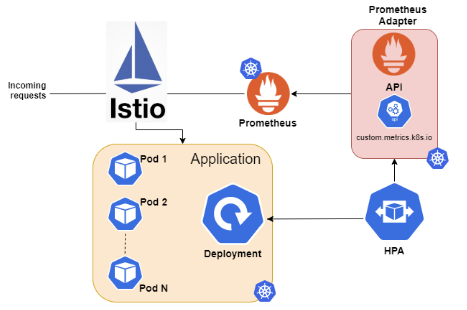
Как только появляется новая реплика, выполняется автоскейлинг.
- Новой реплике требуется GPU, при этом в кластере свободной видеокарты нет.
- Node-автоскейлер начинает создавать новую виртуальную машину, которая станет новой нодой Kubernetes.
- GPU-оператор готовит ноду для работы с видеокартой.
- Реплика аллоцируется и скачивает образ на ноду. Как только под поднимется, трафик начнет распределяться между репликами равномерно, а задержка в очереди снижается.
Узкие горлышки автоскейлинга
Про автоскейлинг в кластере с GPU я уже рассказывал в Академии Selectel. В этом же материале предлагаю пройтись по узким горлышкам этого процесса в нашей платформе.
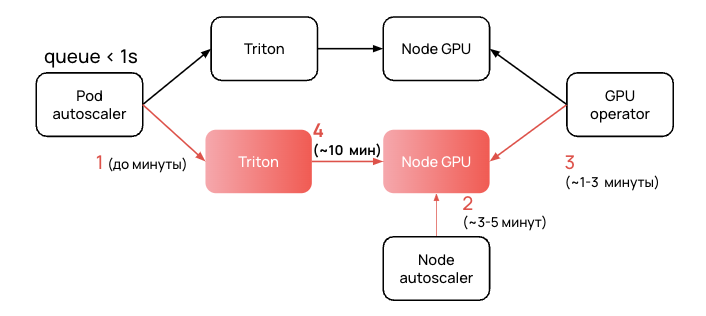
Опишем процесс распределения времени на все этапы автоскейлинга.
- HPA смотрит на выставленный таргет по метрике и создает дополнительную реплику, как только порог будет пройден. Это занимает до минуты, нас это устраивает.
- После появления реплики Triton ей требуется ресурс nvidia.com/gpu — свободная нода с видеокартой. Если в кластере такой ноды нет, начинается автоскейлинг в K8s. Для Managed Kubernetes мы сделали форк проекта с GitHub и добавили API для взаимодействия с нашим облаком. Автоскейлер поднимает ноду из образа, который по умолчанию указан в группе нод, и устанавливает необходимые сервисы для интеграции с Kubernetes. Время деплоя зависит от скорости поднятия новой виртуальной машины в облаке, поэтому здесь мы мало что можем ускорить.
- Следующим этапом необходимо подготовить ноду для работы с GPU. В нашем случае GPU-оператор устанавливает драйверы и тулкиты для работы с видеокартой. Процесс занимает до трех минут, так как мы используем precompiled-драйверы (как они ускоряют запуск, можно посмотреть еще в одной моей статье в Академии Selectel). Кстати, в качестве альтернативы можно использовать заранее подготовленные образы с драйвером для GPU. В Managed Kubernetes такая опция тоже есть.
- После установки сервисов GPU-оператора в кластере становится доступна нода с ресурсом nvidia.com/gpu. Это позволяет аллоцировать на нее реплику Triton. И это — самый долгий процесс, о котором стоит поговорить подробнее.
Ускоряем пулинг образа на ноду
Что нужно знать об аллоцировании образа на ноду с GPU?
- Образ содержит CUDA, PyTorch/TensorFlow, NVIDIA Triton Inference Server. В нашем случае все это весит примерно 20 ГБ.
- Вы можете заложить в образ веса модели. Если это LLM, речь может идти о десятках гигабайт.
Веса моделей можно вынести в отдельное кэширующее хранилище, например NFS или S3. В качестве NFS мы используем собственное файловое хранилище, которое подключается ко всем используемым репликам нашего инференса. Внутри уже лежат веса моделей, что экономит порядка трех-четырех минут (если, допустим, взять Falcon 7b). Кстати, в качестве альтернативы можно применять и S3. Об использовании объектного хранилища в качестве кэша можно прочитать эту статью, где для PVC S3 используется сервис geesefs.
Но мы все еще имеем большой образ, который достаточно долго скачивается. В этом случае мы посмотрели в сторону lazy-loading.
Согласно статье с сайта usenix, 76% времени старта контейнера уходит на загрузку пакетов, но при этом только 6,4% этих данных действительно требуется для начала выполнения полезной работы контейнером. Есть интересные варианты снепшоттеров, связанные с lazy-loading: eStargz, SOCI и Nydus. Правда, нам ни один из них не подошел, так как слои в Triton-контейнере достаточно большие. Хоть образ и стал пулиться за полторы минуты, инициализация модели все также занимала до семи минут.
Основная проблема больших образов — экстрактинг слоев, так как он выполняется последовательно в отличие от загрузки, которая происходит параллельно. Нам помог переход на формат сжатия образа ZSTD. Собираем образ через buildx с форматом сжатия zstd, и вуаля — он экстрактится в разы быстрее.
docker buildx build \ --file Dockerfile \ --output type=image,name=<image name>,oci-mediatypes=true,compression=zstd,compression-level=3,force-compression=true,push=true .В нашем случае получилось сократить время более чем в два раза: с шести до двух с половиной минут.
Если вам интересна тема ускорения пулинга образов, пишите в комментариях об этом. Я подумываю над статьей, в которой подробно раскрою работу каждого из снапшотеров и различных технологий ускорения пулинга.
Что делать, если нет богатого парка GPU
Теперь рассмотрим подробнее GPU-ресурсы, которые требуются для наших инференсов. По умолчанию ресурсы целочисленны и мапятся в соотношении один инференс – одна GPU.
А что делать, если GPU не так много, а систему с автоскейлингом построить хочется? В этом случае стоит присмотреться к технологиям шеринга GPU, таким как MIG, TimeSlicing и MPS. Я подробно про них писал в статье в Академии Selectel, где можно увидеть как реализовать автомасштабируемый инференс на партициях MIG. Почитать о сравнении этих технологий можно также в статье в Академии.
Также я измерил с помощью бенчмарков производительность частей MIG на A100 и нескольких других видеокартах. Стоимость брал в Selectel.
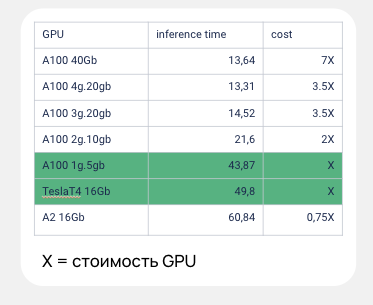
1/7 часть A100 схожа с картой Tesla T4 как по производительности, так и по стоимости. При этом тесты я проводил летом, сейчас A100 в Selectel можно арендовать со скидкой. Соответственно, 1/7 ее часть будет даже дешевле, чем Tesla T4!
Наконец, при автоскейлинге ресурсов важно понимать, где находятся узкие горлышки и как их преодолеть. Также стоит иметь в виду возможность автоскейлинга на одной видеокарте.
Земля — инференс-граф

Это Тоф — профессионал в магии земли и металла. Она умеет как разделять огромные каменные и земляные блоки на мелкие части, так и собирать их в одну огромную стену. А мы научились запускать несколько моделей на одной видеокарте в цепочке и разделять их на несколько видеокарт при необходимости.
Рассмотрим инференс-граф, решающий задачу транскрибации аудио и генерации изображения из полученного текста.
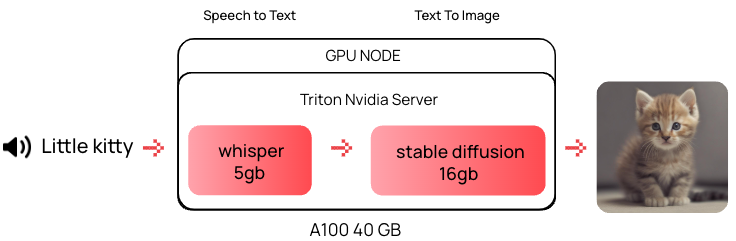
Допустим, у нас есть A100 на 40 ГБ. В нее могут поместиться две модели: Whisper для транскрибации аудио в текст и Stable Diffusion для генерации изображения. Задача — сформировать цепочку из этих моделей, чтобы ответ от Whisper автоматически попадал на Stable Diffusion.
С этой задачей отлично справится сам Triton, так как под капотом у него есть ансамбль моделей. Пройдя небольшой туториал от NVIDIA, не сложно разобраться как это работает, поэтому углубляться не будем.
Но что делать, если нет большой A100, но есть GPU поменьше, такие как Tesla T4? Можно использовать ноду с двумя и более GPU — там также справится ансамбль моделей. Но мы разберем кейс с мультинодальным инференс-графом, когда есть отдельные ноды с одной GPU.
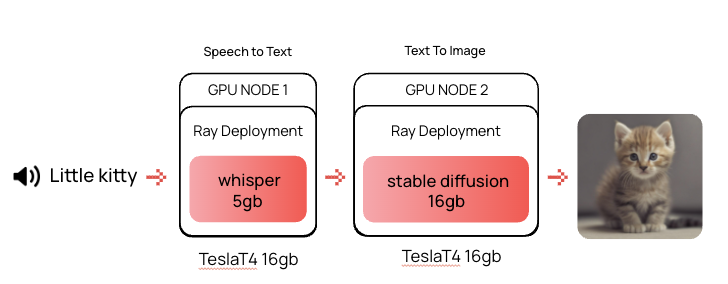
В этом случае ансамбль моделей не поможет, так как мы не можем запустить Triton в нескольких подах на разных нодах. Нужно связать несколько Triton в цепочку моделей. Ранее мы рассматривали Seldon для этого, но от него решили отказаться. В этот раз посмотрим на еще один инструмент — Ray Serve.
Он имеет поддержку инференс-графа, о чем рассказано в документации, а также нативную поддержку Triton SDK. Разобраться с последним помогут туториалы на GitHub. Посмотрим, что нам нужно для поддержки Ray.
Во-первых, установить зависимости в наш образ с Triton. Здесь все просто: берем базовый образ с Triton и устанавливаем туда зависимости. Для этого используем команду:
pip install ray[serve]Во-вторых, написать Python-скрипт запуска деплоя. Ray имеет свой SDK, поэтому для реализации графов придется писать Python-код. Выглядит он следующим образом:
@serve.deployment(ray_actor_options={"num_gpus": 1})
class TritonDeploymentDiffusion:
def __init__(self):
self._triton_server = tritonserver.Server(model_repository)
self._triton_server.start(wait_until_ready=True)
def generate(self, prompt: str):
response = ""
for response in self._stable_diffusion.infer(inputs={"prompt": [[prompt]]}):
generated_image = (
numpy.from_dlpack(response.outputs["generated_image"])
.squeeze()
.astype(numpy.uint8)
)
return generated_image
В декораторе мы обозначаем наш деплой и указываем количество ресурсов GPU. В init-методе инициализируем наш Triton server с указанием репозитория, где хранятся модели. Метод generate используем, чтобы описать сам процесс инференса. То же самое делаем для другой модели и формируем цепочку с помощью следующего примера (не путайте Ray Deployment и K8s Deployment — это разные сущности!):
@serve.deployment
@serve.ingress(app)
class Ingress:
def __init__(
self, whisper_responder: DeploymentHandle, diffusion_responder: DeploymentHandle
):
self.whisper_responder = whisper_responder
self.diffusion_responder = diffusion_responder
@app.post("/graph")
async def graph(self, file: UploadFile = File(...)):
prompt = await self.whisper_responder.detect.remote(file)
response = await self.diffusion_responder.generate.remote(prompt)
image_ = Image.fromarray(response)
image_.save("//6ef4e6a1-9d49-47ac-bfed-170f67a815cf.selcdn.net/workspace/generated_image.jpg")
return FileResponse("//6ef4e6a1-9d49-47ac-bfed-170f67a815cf.selcdn.net/workspace/generated_image.jpg")
Добавляем декоратор ingress, что означает точку входа в наш инференс-граф. В методе graph явно прописываем логику работы цепочки.
В целом, для простых графов можно оставить обычный деплой Triton server и написать свой собственный сервис по связыванию моделей в цепочку. Тот же метод graph, по сути, можно реализовать на FastAPI и выложить отдельным контейнером как точку входа. Ray стоит использовать при создании сложных графов.
Опишем составные части Ray для создания инференс-графа.
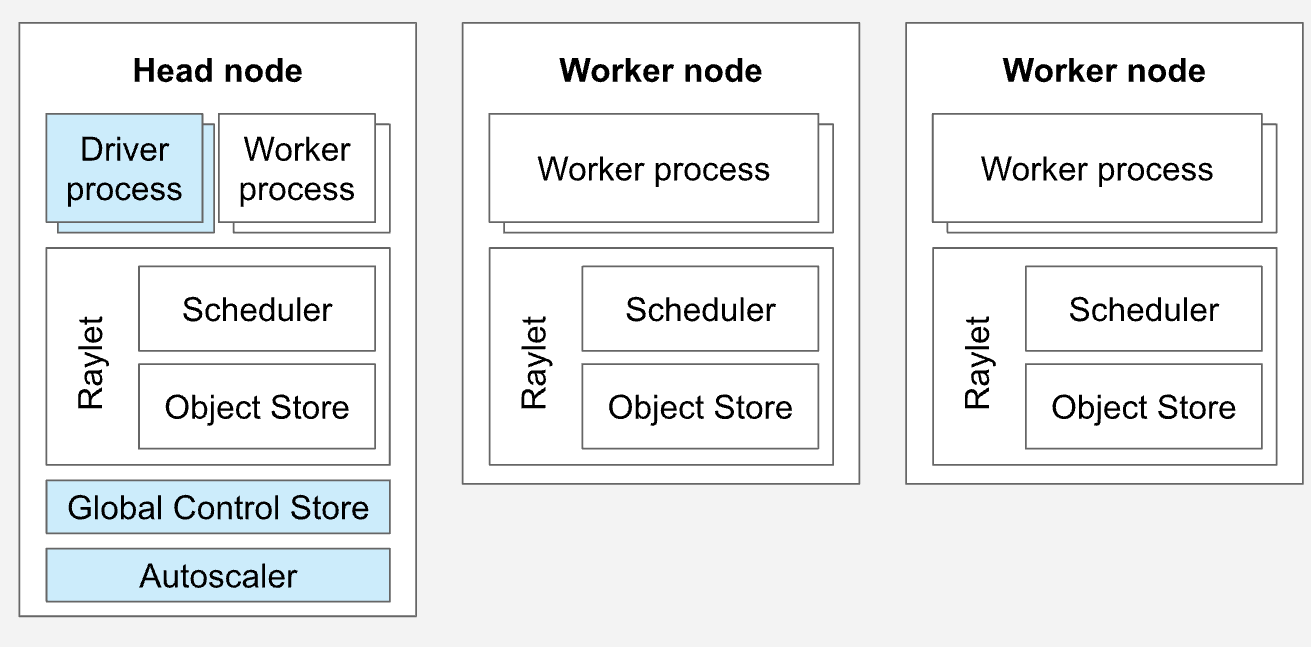
- Kuberay — это оператор K8s, который создает CRD Ray Cluster, RayService, ray-job.
- Ray Cluster — состоит из одной head-ноды и нескольких worker-нод. На последних запускается код, на head-ноде — сервисы управления и автоскейлинга. Ноды ray — это поды в K8s.
- RayService — RayService состоит из двух частей: Deployment Graph Ray Cluster и Ray Serve. RayService обеспечивает обновление RayCluster без простоя и высокую доступность. Это инференс + кластер Ray Serve.
При этом worker-ноды состоят из образов, в которых находится подготовленный нами Triton. Для каждой модели мы подготовили свой образ (репозитории на GitHub: Whisper и Stable Diffusion) и столкнулись со следующей проблемой. В Ray нельзя явно обозначить, какой deployment на какой worker аллоцируется. Соответственно, может произойти ситуация, когда deployment попадает не на свой worker, что приведет к ошибке.
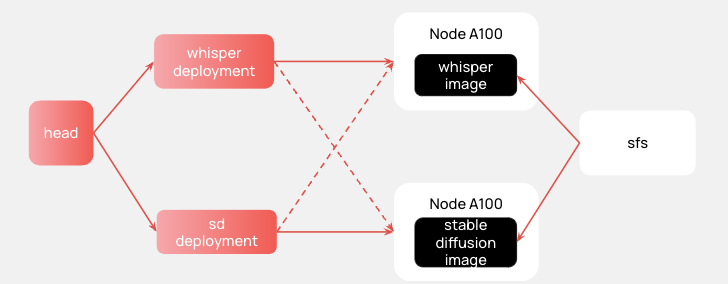
Выяснить, как явно указывать нужный worker, мы пока не смогли, поэтому оставляйте свои решения в комментариях! Мы поняли, что в нашем случае с помощью Ray можно создать мультинодальный инференс-граф. Но на данный момент такой способ является слишком трудозатратным для клиентов, так как требует погружения в продукт Ray. Сейчас мы ищем способы упрощения создания таких графов, но это уже отдельная история.
После внедрения всех необходимых фич платформы мы занялись оптимизацией инференса на наших GPU.
Воздух — оптимизация работы Triton

Это последний маг — аватар Аанг. Первая стихия, которой он научился эффективно управлять, — воздух. Подобно воздуху, который наполняет все помещение, в котором мы находимся, наши инференсы полностью заполняют видеокарту и утилизируют ее на 100%. В этом нам помогает встроенная оптимизация NVIDIA Triton Inference Server.
Рассмотрим батчинг запросов, который нативно поддерживает Triton. Динамический батчинг применительно к Triton Inference Server означает функциональность, позволяющую объединять один или несколько запросов на вывод в один пакет (который должен быть создан динамически). Это дает возможность максимизировать пропускную способность.
Также Triton Inference Server может запускать несколько экземпляров одной и той же модели, которые могут обрабатывать запросы параллельно. Кроме того, экземпляры можно запустить как на одном и том же, так и на разных устройствах GPU на одном узле в соответствии со спецификациями пользователя.
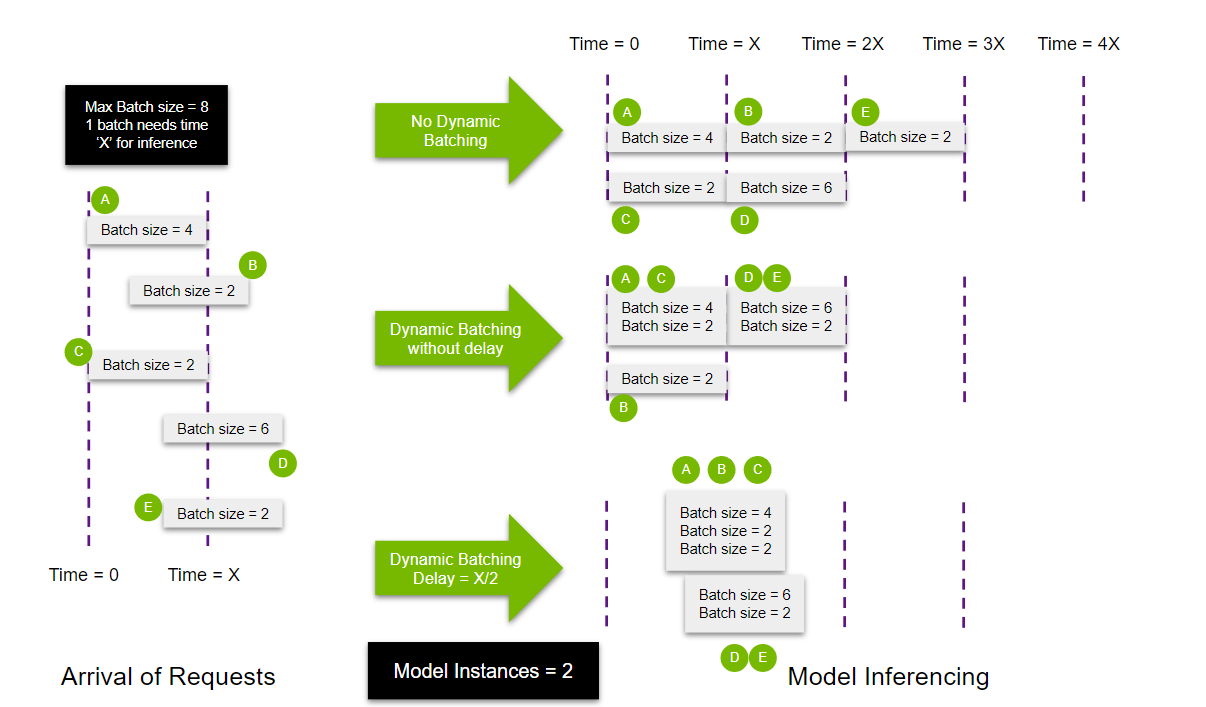
Подробно изучить пример использования батчинга и нескольких инстансов моделей можно в туториале на GitHub.
Запускать Triton можно как с батчингом, так и без. В первом случае запросы, которые поступают одновременно, Triton соберет в батч и обработает параллельно. Во втором — последовательно. Если запросы одновременно не приходят, можно поставить задержку. Тогда Triton будет их накапливать и затем обрабатывать параллельно.
Возникает вопрос: как подобрать конфигурацию Triton так, чтобы получить максимальную производительность? Для такой ситуация подойдет сервис от NVIDIA — Model Analyzer.
Это инструмент CLI, который поможет найти оптимальную конфигурацию на имеющемся оборудовании для одиночной, множественной, ансамблевой или BLS-модели, запущенной на Triton Inference Server. Сервис также генерирует отчеты, чтобы помочь лучше понять компромиссы различных конфигураций и их требования к вычислительным ресурсам и памяти. Он запускает несколько инференс-сервисов с Triton и подает нагрузку на них с помощью perf_client — утилиты для высоконагруженных тестов. Далее формирует отчет, в котором указана оптимальная конфигурация, где perf_client показал лучшую производительность.
Также Triton поддерживает множество различных форматов моделей, таких как TensorRT, TensorFlow, PyTorch, Python, ONNX Runtime и OpenVino. Конвертация в различные форматы моделей помогает ускорить наши инференсы. Например, переход из ONNX в TensorRT может дать прирост в несколько раз. Как это все работает, можно посмотреть в еще одном туториале на GitHub.
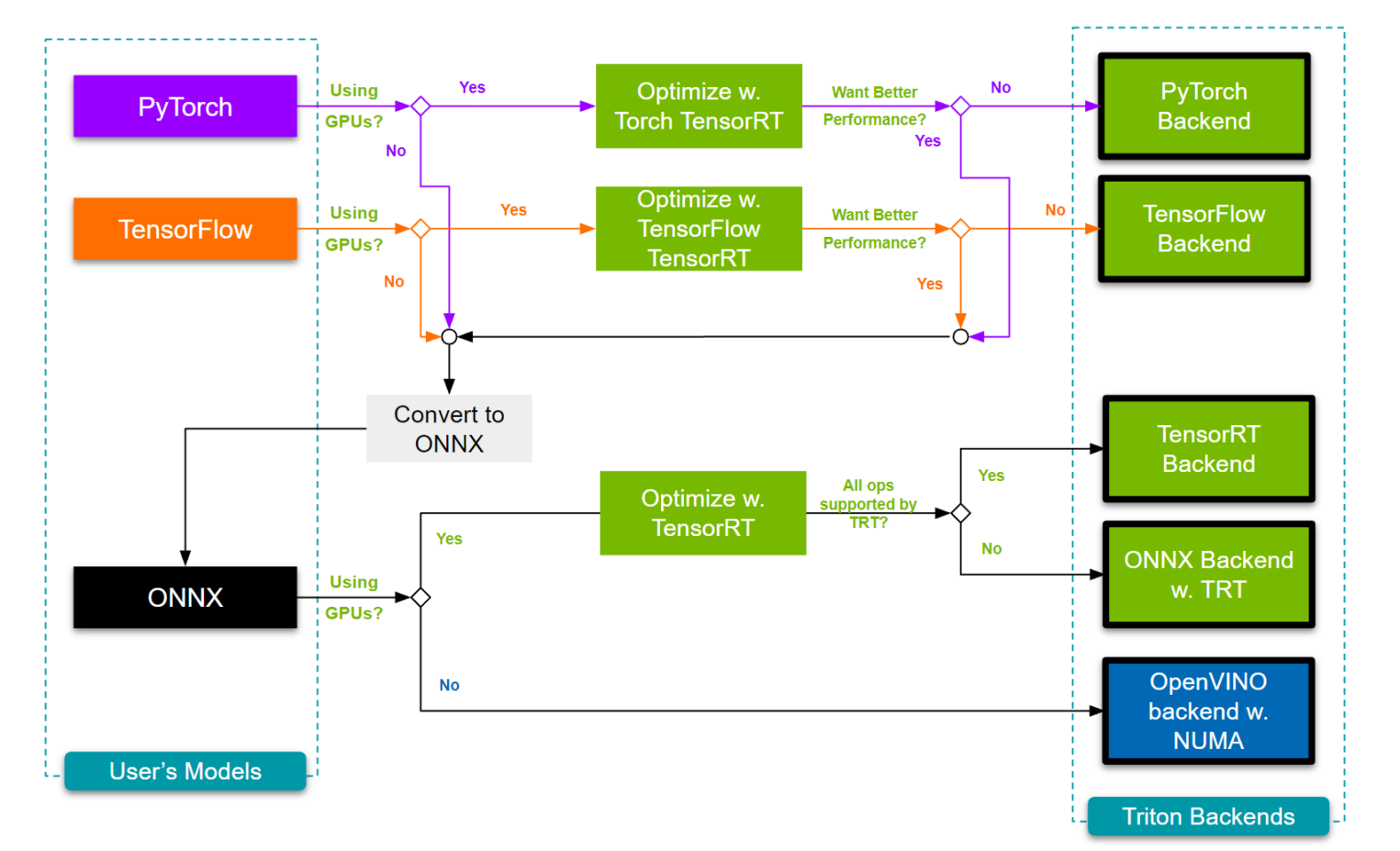
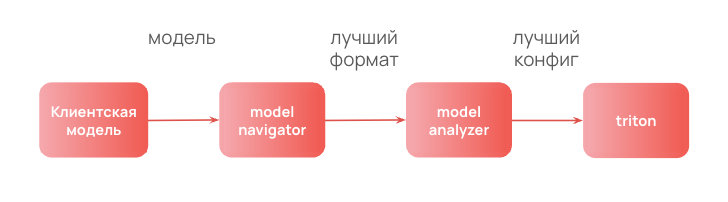
Также у Nvidia есть сервис, который помогает автоматически подобрать нужный формат моделей — Model Navigator. Конвертирует, если это возможно, модель в разные форматы и подбирает из них оптимальный по времени инференса тестового запроса.
Таким образом, можно разработать автоматический пайплайн нахождения наилучшей конфигурации и формата моделей для инференса.
Такие оптимизации экономят деньги. К нам приходил клиент с запросом на инфраструктуру для транскрибации миллиона минут голосовых записей в месяц с помощью Whisper. Его код показал 28 дней непрерывной работы на GTX 1080. Как оказалось, конвертация модели клиента в TensorRT и деплой в нашу платформу сокращают время на несколько дней. А если подобрать GPU помощнее, то прирост скорости будет трехкратным.

Пришло время перейти к последней фиче нашей платформы — UI, который мы сделали без разработчиков.
Дух — User Interface без разработчиков

Аватар является мостом между двумя мирами: миром людей и духов. Так как у нас не было фронтенд-разработчиков, мы обратились за помощью к духам Grafana!
Чтобы в Grafana строить дашборды, в Prometheus мы собираем следующие метрики:
- из экспортера Triton забираем метрики по времени выполнения запросов, задержкам в очереди, количеству выполненных запросов (за основу можно взять дашборд с GitHub);
- из Istio забираем метрики по входящему трафику (присмотритесь к этому дашборду от Istio);
- из экспортера DCGM собираем метрики с наших GPU по их утилизации и занимаемой памяти (на основе дашборда от NVIDIA мы сделали свой);
- из Kubernetes собираем дефолтные метрики насыщения наших подов;
- из Loki собираем логи с наших Triton.
Примеры интерфейсов, которые мы отдаем пользователю, приведены ниже:
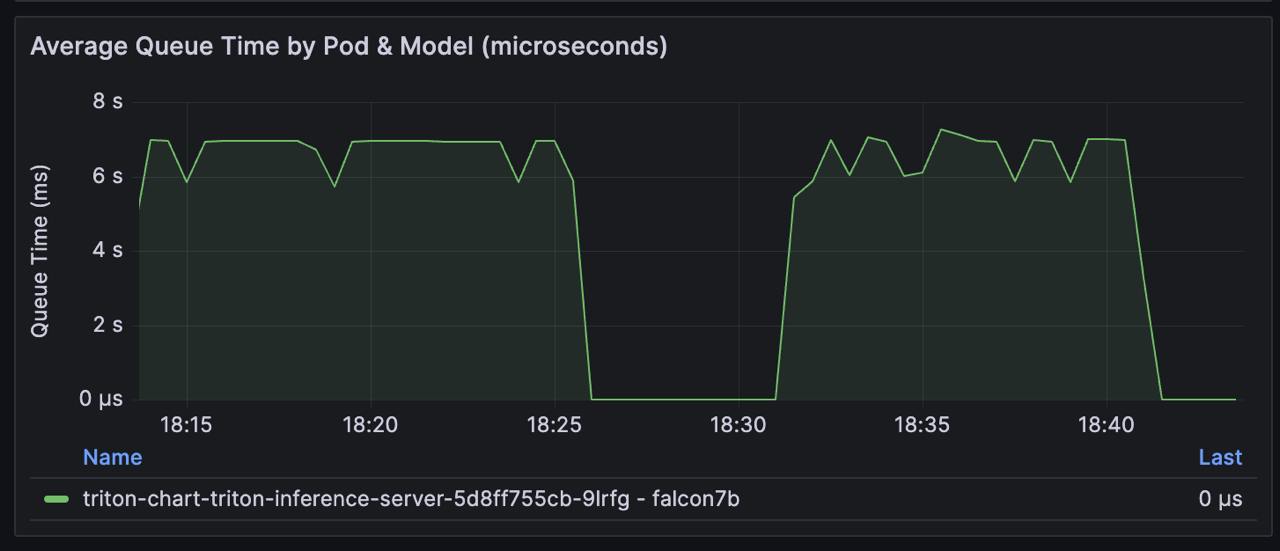
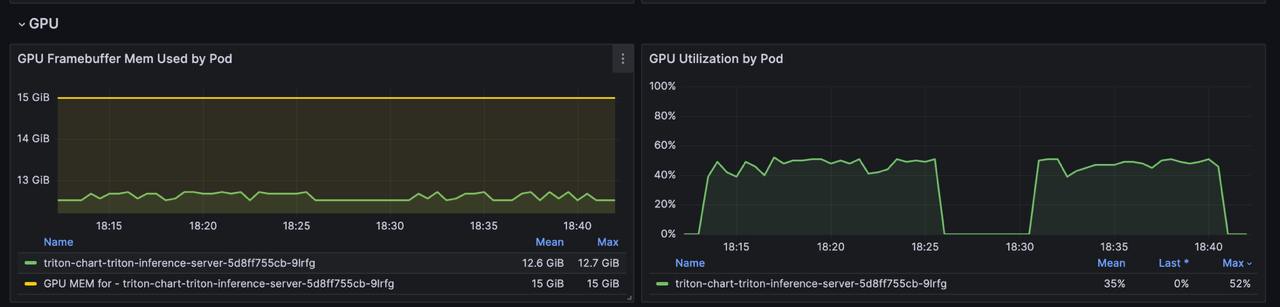
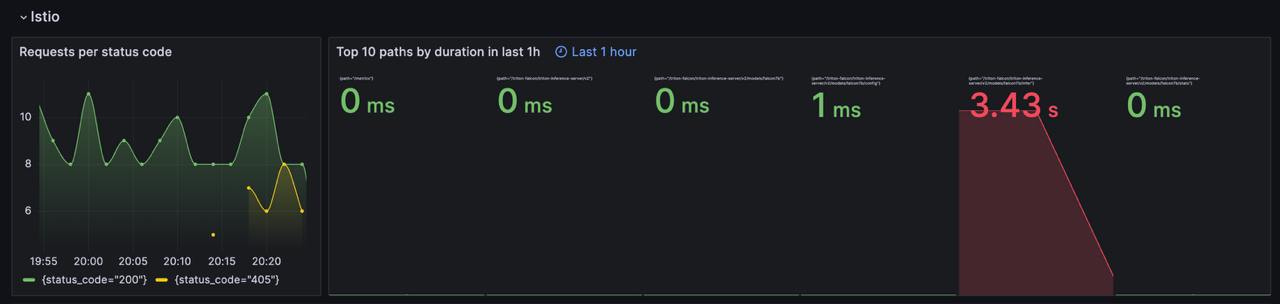
В платформу добавлен компонент Kiali, который позволяет визуализировать связи и статусы между Istio-компонентами, группируя их по общим меткам в режиме реального времени. Данный инструмент позволяет отображать различную полезную информацию, такую как RPS, traffic rate/distribution, логи, трейсы, метрики и многое другое. В целом Kiali помогает понять общую картину происходящего в Istio, видеть связи между компонентами и находить проблемные ресурсы. Например, с некорректной настройкой, потерянными лейблами или не прописанными версиями.
Помимо отслеживания трафика, в режиме анимации Kiali позволяет отследить ошибки в каждом из задеплоенных сервисов. Например, ниже мы наблюдаем Canary Deployment и распределение трафика.
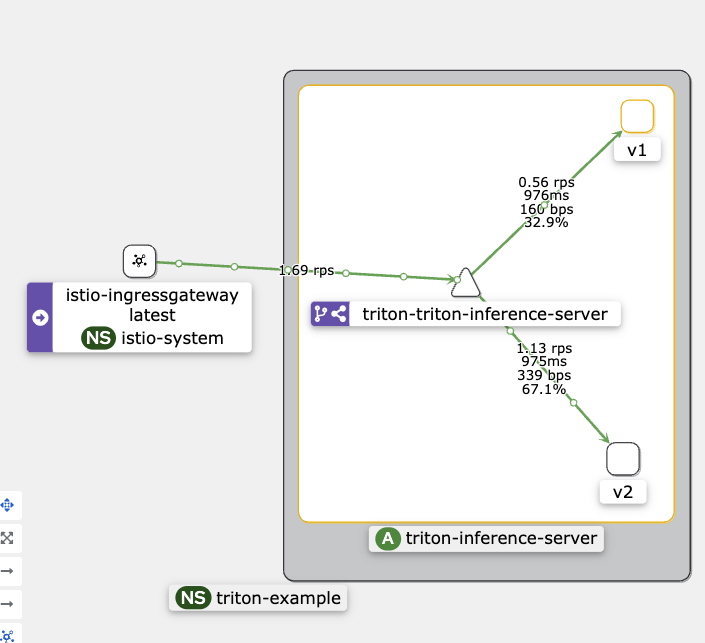
Также пользователь может из интерфейса Kiali изменить процентное соотношение трафика, о котором я писал в самом начале. Например, можно направить вплоть до 100% на одну из версий Triton.
Заключение
Рассмотрим основные моменты, с которыми мы столкнулись при разработки платформы.
- Деплой без даунтайма. Здесь нам помогли Istio и Canary Deployment. Не забываем Istio Injection в неймспейсах для проброса envoy в контейнер.
- Автоскейлинг ресурсов. Кэшируем веса модели в SFS или в S3. Используем снапшотеры для ускорения выгрузки образов и форматирования в zstd. Для разделение GPU используем MIG.
- Объединение моделей в цепочки. Ансамбль моделей нативно поддерживается Triton на одной ноде. Ray можно использовать для графа на нескольких нодах.
- Максимальная утилизация GPU . Model Analyzer — автоматически подбираем конфигурацию Triton. Model Navigator — автоматически подбираем формат модели.
- UI. Grafana для визуализации метрик Prometheus. Для визуализации трафика ставьте Jaeger + Kiali.
Напомню, что Inference-платформа Selectel сейчас находится на этапе бета-теста. Мы предлагаем испытать ее возможности бесплатно в течение двух недель. Переходите по ссылке и оставляйте заявку.





