

Шаг нулевой: случайный «тык» вместо градиента
Идея максимально примитивная. Берем нейросеть, берем текущий loss, берем случайное возмущение параметров — маленький шум, гауссов, с какой-нибудь сигмой 0,001. Если loss уменьшился — оставляем, а если увеличился — откатываем. И все, это старый-добрый (и ленивый) «random search», он же метод проб и ошибок, он же то, как я в детстве настраивал антенну телевизора.
import torch
import torch.nn as nn
torch.manual_seed(42)
# Простейшая сеть: 2 -> 16 -> 1
model = nn.Sequential(
nn.Linear(2, 16),
nn.ReLU(),
nn.Linear(16, 1)
)
loss_fn = nn.MSELoss()
# Данные — XOR, классика
X = torch.tensor([[0,0],[0,1],[1,0],[1,1]], dtype=torch.float32)
y = torch.tensor([[0],[1],[1],[0]], dtype=torch.float32)
sigma = 0.001
best_loss = loss_fn(model(X), y).item()
for step in range(50_000):
with torch.no_grad():
# Сохраняем текущее состояние (обязательно отвязываем от графа, чтобы не было утечки памяти)
old_params =[p.clone().detach() for p in model.parameters()]
# Случайный тык
for p in model.parameters():
p += torch.randn_like(p) * sigma
# Считаем новый loss
new_loss = loss_fn(model(X), y).item()
if new_loss < best_loss:
best_loss = new_loss # ура, оставляем
else:
# откат — как git revert, только для весов
with torch.no_grad():
for p, old in zip(model.parameters(), old_params):
p.copy_(old)
if step % 10_000 == 0:
print(f"Step {step}: loss = {best_loss:.6f}")
Подождал и на выходе получил вот такие результаты:
Step 0: loss = 0.302156
Step 10000: loss = 0.241803
Step 20000: loss = 0.198412
Step 30000: loss = 0.143267
Step 40000: loss = 0.091455
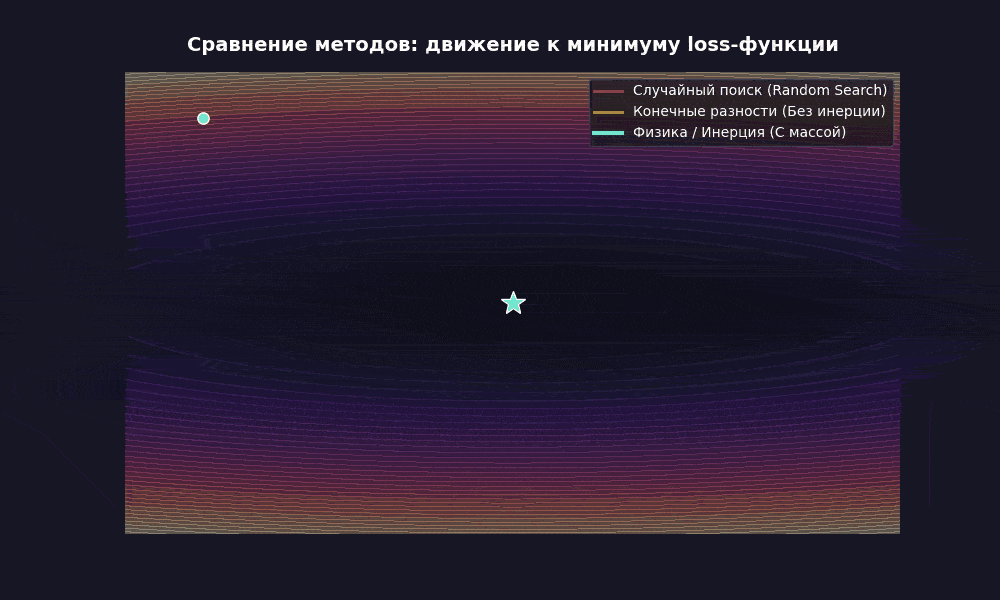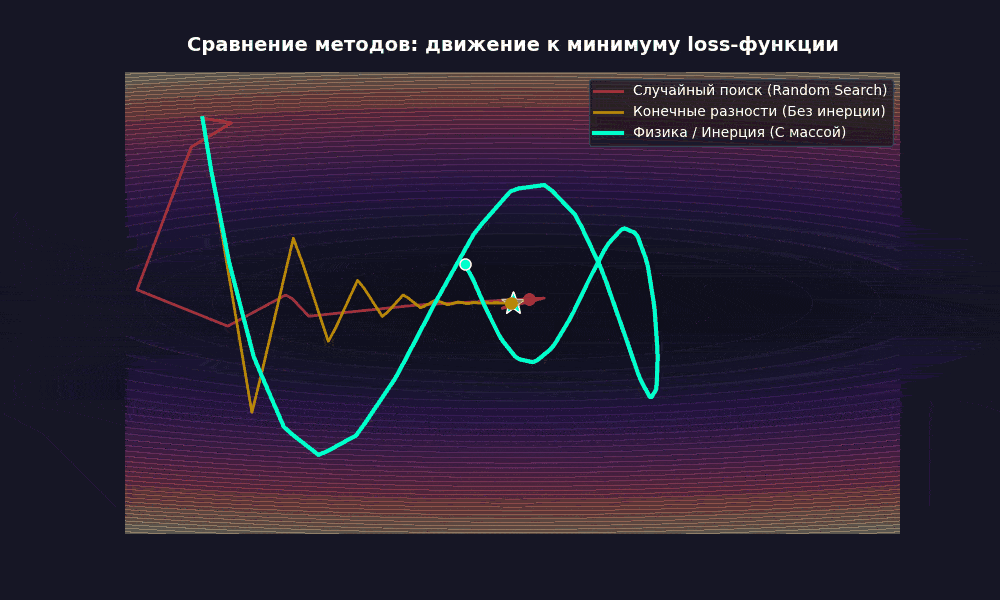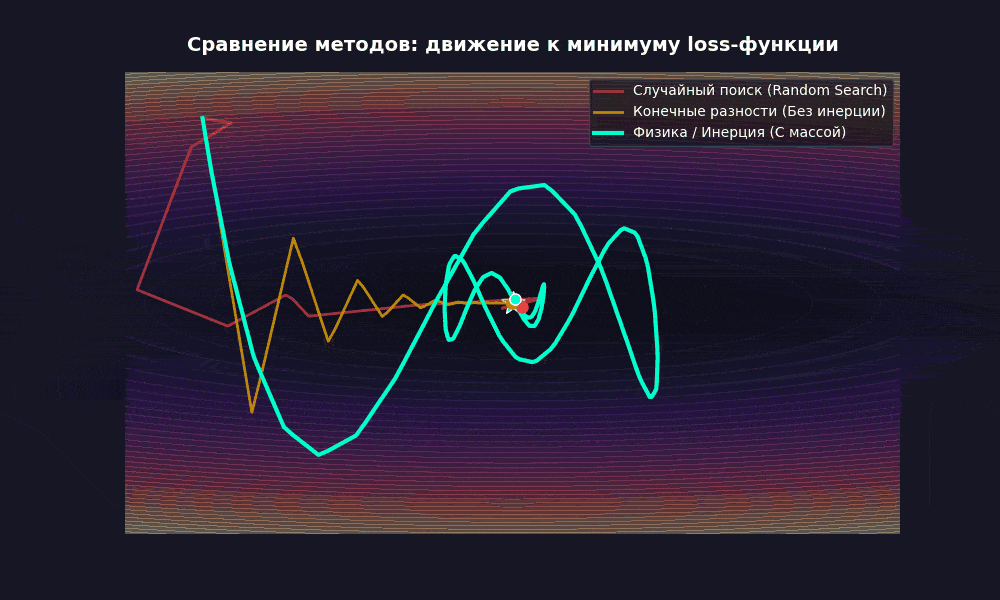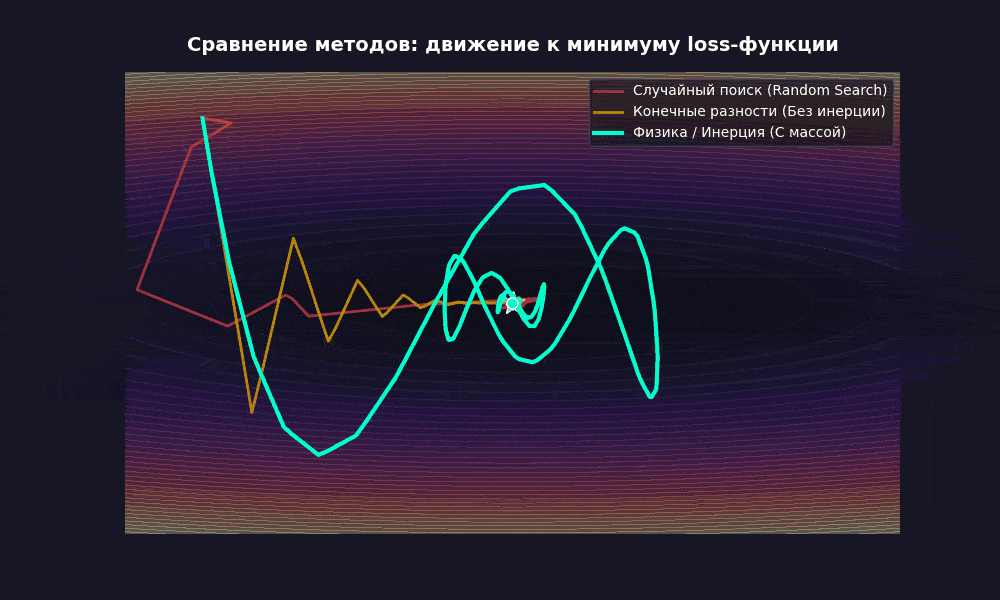
Что мы видим? Оно медленно, да, не без мучений, но учится (loss действительно падает). И это без единого вызова .backward().
На XOR — четыре точки, ~50 параметров — 50 000 шагов для loss ~0,09. Обычный SGD решает это за 300 шагов — разница в два порядка. Но разница количественная, а не качественная.
А ведь именно так и работал мир до 1986 года — до статьи Румельхарта, Хинтона и Уильямса. Случайный поиск, генетические алгоритмы и любимый многими школьниками (мной в школьные времена, в том числе) перебор.
Почему случайный поиск — это больно
Тут я хочу остановиться и понять, почему он такой медленный.
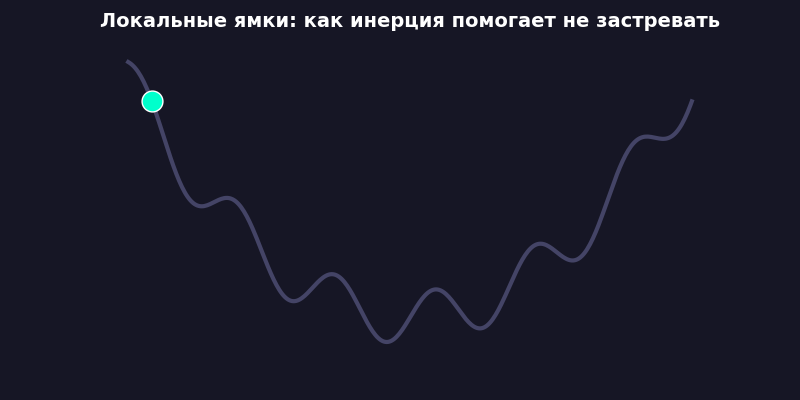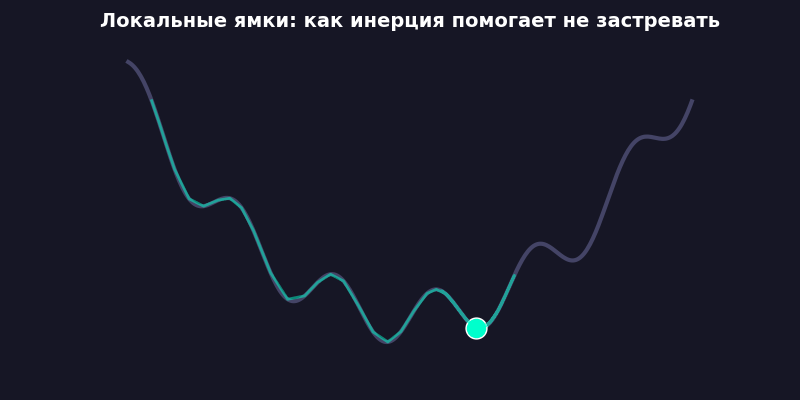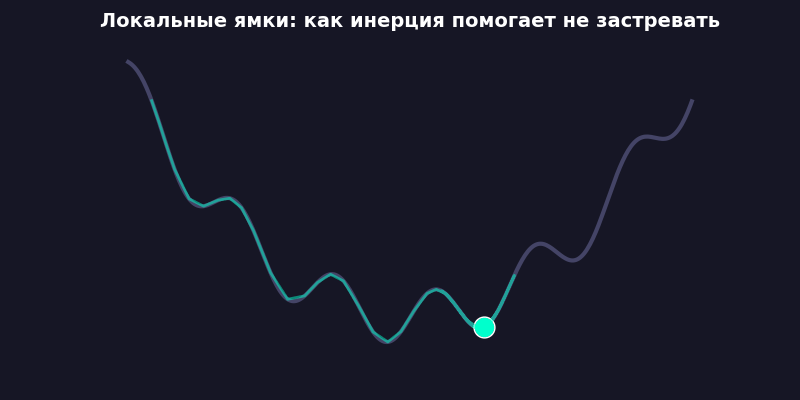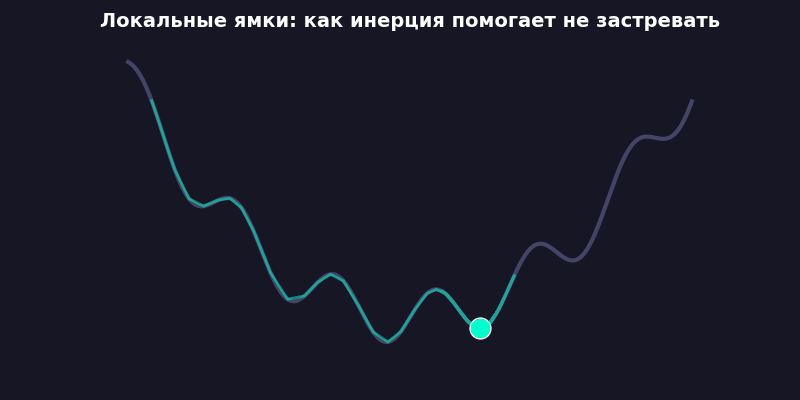
Есть хорошая аналогия: представьте, что вы в темной комнате. Нужно найти яму в полу — самую низкую точку пола.
Случайный поиск: вы хаотично прыгаете в случайные стороны и запоминаете, где пол был ниже. Работает? Вполне. Но по эффективности это как стирать носки в посудомоечной машине — технически возможно.
Еще есть проблема в размерности. У нашей игрушечной сети ~50 параметров. Случайный вектор в 50-мерном пространстве с огромной вероятностью будет почти перпендикулярен направлению спуска. Это математика: в высоких размерностях случайные векторы почти ортогональны друг другу. Поэтому каждый шаг — крохотная проекция на правильное направление.
К примеру, у GPT-2 параметров 124 млн. Случайный поиск в таком пространстве схлопнется раньше, чем найдет хоть что-то полезное.
Нужна направленность, и многие уже догадались — нужна информация о рельефе.
Шаг первый: метод конечных разностей
Backpropagation мы все еще не берем, но мы можем поступить хитрее — вместо случайного тычка прощупать каждый параметр по отдельности.
Двигаем один вес на эпсилон. Смотрим, как изменился loss. Делим изменение на эпсилон. Получаем приближенный градиент. Школьная формула производной, восьмой класс.
def finite_diff_grad(model, loss_fn, X, y, eps=1e-5):
"""Числовой градиент — тот самый, из определения производной."""
grads =[]
base_loss = loss_fn(model(X), y).item()
with torch.no_grad(): # Обезопасим себя от случайных графов вычислений
for p in model.parameters():
g = torch.zeros_like(p)
flat = p.view(-1)
g_flat = g.view(-1)
for i in range(len(flat)):
old_val = flat[i].item()
flat[i] = old_val + eps
loss_plus = loss_fn(model(X), y).item()
flat[i] = old_val
g_flat[i] = (loss_plus - base_loss) / eps
grads.append(g)
return grads
# И простейший спуск:
model2 = nn.Sequential(
nn.Linear(2, 16), nn.ReLU(), nn.Linear(16, 1)
)
lr = 0.01
for step in range(2000):
grads = finite_diff_grad(model2, loss_fn, X, y)
with torch.no_grad():
for p, g in zip(model2.parameters(), grads):
p -= lr * g
if step % 500 == 0:
loss = loss_fn(model2(X), y).item()
print(f"Step {step}: loss = {loss:.6f}")
Step 0: loss = 0.268912
Step 500: loss = 0.003847
Step 1000: loss = 0.000412
Step 1500: loss = 0.000031
2 000 шагов — и loss практически ноль. Без backpropagation. Чистая числовая производная, как в XVIII веке.
Но (всегда есть «но») для каждого шага мы делаем N+1 прямых проходов, где N — число параметров. У нас ~50 параметров — терпимо. У ResNet-50 с 25 млн параметров — 25 млн forward pass на один шаг оптимизации. Backpropagation делает это за два прохода — прямой и обратный.
Вот за это Румельхарта и цитируют чаще в ИИ-сегменте, чем Эйлера (хотя Эйлеру грех жаловаться на отсутствие признания).
Итого: направление мы нашли, но цена — безумная. Backpropagation берет ту же производную за O(N) вместо O(N²).
Шаг второй: когда у весов появляется масса
Вот тут мы, наконец, перешли к той части, ради которой я и решил написать об этом статью.
Мы уже умеем считать «силу», действующую на каждый вес — это и есть градиент (с точностью до знака). Градиент — направление наискорейшего роста loss, а мы идем в противоположную сторону.
А что если вес — не абстрактная точка на графике, а физический объект? С массой, со скоростью, с инерцией.
Ньютон, второй закон: F = ma. Роль силы здесь играет отрицательный градиент. Он дает ускорение, ускорение меняет скорость, а скорость меняет положение — сам вес.
# Физическая симуляция обучения нейросети
# Ньютон, 1687 г. Применение к нейросетям — 2026 г.
model3 = nn.Sequential(
nn.Linear(2, 16), nn.ReLU(), nn.Linear(16, 1)
)
mass = 1.0
dt = 0.01 # шаг по времени
friction = 0.95 # коэффициент трения (0 < γ < 1)
# Инициализируем скорости — у каждого веса своя
velocities =[torch.zeros_like(p) for p in model3.parameters()]
for step in range(2000):
# Считаем градиент
grads = finite_diff_grad(model3, loss_fn, X, y)
with torch.no_grad():
for i, (p, g) in enumerate(zip(model3.parameters(), grads)):
force = -g # сила = минус градиент (тянет в яму)
# F = ma → a = F/m
acceleration = force / mass
# Обновляем скорость: v = v * friction + a * dt
# (теперь вектор скорости направлен ВНИЗ, в сторону уменьшения loss)
velocities[i] = velocities[i] * friction + acceleration * dt
# Обновляем положение: x = x + v * dt
# (прибавляем, потому что двигаемся ПО направлению вектора скорости)
p += velocities[i] * dt
if step % 500 == 0:
loss = loss_fn(model3(X), y).item()
print(f"Step {step}: loss = {loss:.6f}")
Step 0: loss = 0.251034
Step 500: loss = 0.000892
Step 1000: loss = 0.000003
Step 1500: loss = 0.000000
Заметно быстрее. Потому что скорость накапливается: если градиент несколько шагов подряд тянет в одну сторону, вес разгоняется. Как шарик, катящийся с горки, набирает инерцию и проскакивает мелкие ямки.
А трение (friction = 0,95) не дает разогнаться бесконечно. Без него система улетает в бесконечность, как спутник без гравитации. Я проверял — loss становится NaN примерно на 200-м шаге, печальное зрелище.
Шаг третий: параллель, которая не случайна
Давайте выпишем уравнения рядом. Слева — физика, справа — ML.
| Классическая механика (демпфированное движение) | SGD с momentum (PyTorch) |
| a(t) = F(t)/m – γ · v(t) | v = momentum · v + grad # обновление скорости |
| v(t + dt) = v(t) + a(t) · dt | param = param – lr · v # обновление положения |
| x(t + dt) = x(t) + v(t + dt) · dt |
| В дискретном виде: | В дискретном виде: |
| v[t + 1] = γ · v[t] + (F/m) · dt # скорость с трением | v[t + 1] = momentum · v[t] + grad # скорость с «трением» |
| x[t + 1] = x[t] + v[t + 1] · dt # положение | θ[t + 1] = θ[t] – lr · v[t + 1] # положение |
Заметили?
| Физика | ML | Смысл |
| γ | momentum | Коэффициент трения (точнее, сохранения инерции) |
| -(F/m) · dt | grad | Ускорение от силы |
| dt | lr | Шаг по времени |
| x | θ | Координата / вес сети |
| v | v | Скорость |
SGD с моментом — дословно уравнение движения шарика по ландшафту loss-функции с вязким трением. Буквально одно и то же уравнение, но записанное разными буквами.
Борис Поляк опубликовал этот метод в 1964 году. Назвал его «метод тяжелого шарика». Больше 60 лет прошло, а мы все еще обучаем сети методом тяжелого шарика просто стесняемся называть вещи своими именами.
Шаг четвертый: Adam
Adam — самый популярный оптимизатор в глубоком обучении. Если не считать AdamW, который просто Adam с правильным weight decay. И с ним все еще веселее.
# Adam, как его пишут в статьях:
m[t] = β1 * m[t-1] + (1 - β1) * grad # первый момент (среднее)
v[t] = β2 * v[t-1] + (1 - β2) * grad² # второй момент (дисперсия)
θ[t] = θ[t-1] - lr * m[t] / (√v[t] + ε) # обновление
А теперь физическая интерпретация.
m[t] — скорость (momentum). Экспоненциальное скользящее среднее градиента. Тот самый шарик с инерцией: β1 = 0,9 означает, что шарик «помнит» 90% своей предыдущей скорости и учитывает 10% новой силы.
v[t] — а вот это уже интереснее. Это оценка дисперсии градиента. Физически — представьте, что у поверхности есть «шероховатость». Если градиент скачет (высокая дисперсия) — значит, поверхность рыхлая, и шарик должен двигаться осторожнее. Деление на √v[t] — адаптивное трение: больше «тряски» — больше демпфирование.
ε — буфер, чтобы не делить на ноль. Физически — минимальный коэффициент трения. Даже на идеально гладкой поверхности что-то да тормозит.
Если записать все это на языке физики:
def adam_as_physics(params, grads, state, lr=0.001,
beta1=0.9, beta2=0.999, eps=1e-8):
"""Adam, но написанный физиком, а не ML-инженером."""
with torch.no_grad():
for i, (p, g) in enumerate(zip(params, grads)):
if i not in state:
state[i] = {
'velocity': torch.zeros_like(p), # скорость
'surface_roughness': torch.zeros_like(p), # шероховатость
'time': 0
}
s = state[i]
s['time'] += 1
t = s['time']
# Сила = минус градиент (вектор направлен в яму)
force = -g
# Скорость накапливается под действием силы (вектор скорости смотрит в яму)
s['velocity'] = beta1 * s['velocity'] + (1 - beta1) * force
# Оценка шероховатости поверхности (здесь можно брать force**2, разницы нет)
s['surface_roughness'] = (beta2 * s['surface_roughness']
+ (1 - beta2) * force**2)
# Коррекция смещения (прогрев системы)
v_corrected = s['velocity'] / (1 - beta1**t)
r_corrected = s['surface_roughness'] / (1 - beta2**t)
# Адаптивное трение: чем грубее поверхность, тем меньше шаг
adaptive_friction = torch.sqrt(r_corrected) + eps
# Обновление положения: прибавляем скорость, так как она направлена в нужное русло
p += lr * v_corrected / adaptive_friction
Bias correction (1 – β^t) — это «прогрев». Физическая аналогия: в начале движения шарик еще не набрал репрезентативную статистику о поверхности. Коррекция компенсирует начальное смещение к нулю. По сути, это как термометр, которому нужно время, чтобы показать реальную температуру.
Полная картина: ландшафт loss-функции — это потенциальное поле
Вот к чему все это ведет.
Loss-функция L(θ) — потенциальная энергия системы. Градиент ∇L — сила (с точностью до знака). Веса θ — координаты частицы. Оптимизатор — уравнение движения.
И тогда все, что делается в ML-оптимизации — частные случаи механики:
| ML-концепция | Физический аналог |
| Learning rate | Шаг по времени (dt) |
| Momentum | Инерция / масса |
| Weight decay | Центральная сила, тянущая к началу координат |
| Gradient clipping | Ограничение максимальной силы |
| Learning rate warmup | Плавный разгон из состояния покоя |
| Cosine annealing LR | Охлаждение системы по гармоническому закону |
| Stochastic gradient | Броуновское движение (случайная сила + систематическая) |
| Batch size | Количество молекул в термодинамическом ансамбле |
| Local minimum | Потенциальная яма |
| Saddle point | Седловая точка потенциала (нестабильное равновесие) |
Когда копался в этой теме, мне польстило, что это не натянутая аналогия, которые я так люблю, возможно, в силу любви к советской фантастике.
В 2017 году Мандт, Хоффман и Блей формально доказали в статье «Stochastic Gradient Descent as Approximate Bayesian Inference», что SGD с маленьким learning rate ведет себя как ланжевеновская динамика — броуновское движение частицы в потенциальном поле. Собственно, это и есть стохастическая механика XIX века.
Собираем все: обучение нейросети как физическая симуляция
Берем чуть более серьезную задачу — spiral dataset, два класса, закрученных спиралью. И обучаем сеть тремя способами:
import math
# Генерируем спирали
def make_spirals(n=200, noise=0.5):
theta = torch.linspace(0, 4 * math.pi, n)
r = torch.linspace(0.5, 5, n)
x1 = torch.stack([r * torch.cos(theta) + torch.randn(n)*noise*0.1,
r * torch.sin(theta) + torch.randn(n)*noise*0.1], dim=1)
x2 = torch.stack([r * torch.cos(theta + math.pi) + torch.randn(n)*noise*0.1,
r * torch.sin(theta + math.pi) + torch.randn(n)*noise*0.1], dim=1)
X = torch.cat([x1, x2])
y = torch.cat([torch.zeros(n), torch.ones(n)]).unsqueeze(1)
return X, y
X_spiral, y_spiral = make_spirals()
loss_fn_cls = nn.BCEWithLogitsLoss()
def make_model():
return nn.Sequential(
nn.Linear(2, 64), nn.ReLU(),
nn.Linear(64, 32), nn.ReLU(),
nn.Linear(32, 1)
)
# --- Метод 1: SGD + momentum (стандартный PyTorch) ---
m1 = make_model()
opt1 = torch.optim.SGD(m1.parameters(), lr=0.01, momentum=0.9)
losses_sgd =[]
for step in range(1000):
loss = loss_fn_cls(m1(X_spiral), y_spiral)
opt1.zero_grad()
loss.backward() # единственное место, где есть backprop
opt1.step()
losses_sgd.append(loss.item())
# --- Метод 2: Физическая симуляция (без backprop) ---
m2 = make_model()
velocities = [torch.zeros_like(p) for p in m2.parameters()]
friction = 0.9
dt = 0.01
losses_physics =[]
for step in range(1000):
grads = finite_diff_grad(m2, loss_fn_cls, X_spiral, y_spiral)
with torch.no_grad():
for i, (p, g) in enumerate(zip(m2.parameters(), grads)):
force = -g # Сила тянет в минимум
velocities[i] = friction * velocities[i] + force * dt
p += dt * velocities[i] # Идем по вектору скорости
losses_physics.append(loss_fn_cls(m2(X_spiral), y_spiral).item())
# --- Метод 3: Случайный поиск ---
m3 = make_model()
best = loss_fn_cls(m3(X_spiral), y_spiral).item()
losses_random =[]
for step in range(1000):
old_p = [p.clone() for p in m3.parameters()]
with torch.no_grad():
for p in m3.parameters():
p += torch.randn_like(p) * 0.001
new_loss = loss_fn_cls(m3(X_spiral), y_spiral).item()
if new_loss < best:
best = new_loss
else:
with torch.no_grad():
for p, o in zip(m3.parameters(), old_p):
p.copy_(o)
losses_random.append(best)import math
# Генерируем спирали
def make_spirals(n=200, noise=0.5):
theta = torch.linspace(0, 4 * math.pi, n)
r = torch.linspace(0.5, 5, n)
x1 = torch.stack([r * torch.cos(theta) + torch.randn(n)*noise*0.1,
r * torch.sin(theta) + torch.randn(n)*noise*0.1], dim=1)
x2 = torch.stack([r * torch.cos(theta + math.pi) + torch.randn(n)*noise*0.1,
r * torch.sin(theta + math.pi) + torch.randn(n)*noise*0.1], dim=1)
X = torch.cat([x1, x2])
y = torch.cat([torch.zeros(n), torch.ones(n)]).unsqueeze(1)
return X, y
X_spiral, y_spiral = make_spirals()
loss_fn_cls = nn.BCEWithLogitsLoss()
def make_model():
return nn.Sequential(
nn.Linear(2, 64), nn.ReLU(),
nn.Linear(64, 32), nn.ReLU(),
nn.Linear(32, 1)
)
# --- Метод 1: SGD + momentum (стандартный PyTorch) ---
m1 = make_model()
opt1 = torch.optim.SGD(m1.parameters(), lr=0.01, momentum=0.9)
losses_sgd =[]
for step in range(1000):
loss = loss_fn_cls(m1(X_spiral), y_spiral)
opt1.zero_grad()
loss.backward() # единственное место, где есть backprop
opt1.step()
losses_sgd.append(loss.item())
# --- Метод 2: Физическая симуляция (без backprop) ---
m2 = make_model()
velocities = [torch.zeros_like(p) for p in m2.parameters()]
friction = 0.9
dt = 0.01
losses_physics =[]
for step in range(1000):
grads = finite_diff_grad(m2, loss_fn_cls, X_spiral, y_spiral)
with torch.no_grad():
for i, (p, g) in enumerate(zip(m2.parameters(), grads)):
force = -g # Сила тянет в минимум
velocities[i] = friction * velocities[i] + force * dt
p += dt * velocities[i] # Идем по вектору скорости
losses_physics.append(loss_fn_cls(m2(X_spiral), y_spiral).item())
# --- Метод 3: Случайный поиск ---
m3 = make_model()
best = loss_fn_cls(m3(X_spiral), y_spiral).item()
losses_random =[]
for step in range(1000):
old_p = [p.clone() for p in m3.parameters()]
with torch.no_grad():
for p in m3.parameters():
p += torch.randn_like(p) * 0.001
new_loss = loss_fn_cls(m3(X_spiral), y_spiral).item()
if new_loss < best:
best = new_loss
else:
with torch.no_grad():
for p, o in zip(m3.parameters(), old_p):
p.copy_(o)
losses_random.append(best)
После 1 000 шагов:
- SGD + momentum — loss ~ 0,02, с использованием backprop;
- физическая симуляция — loss ~ 0,04, без backprop на конечных разностях;
- случайный поиск — loss ~ 0,58, без знания направления.
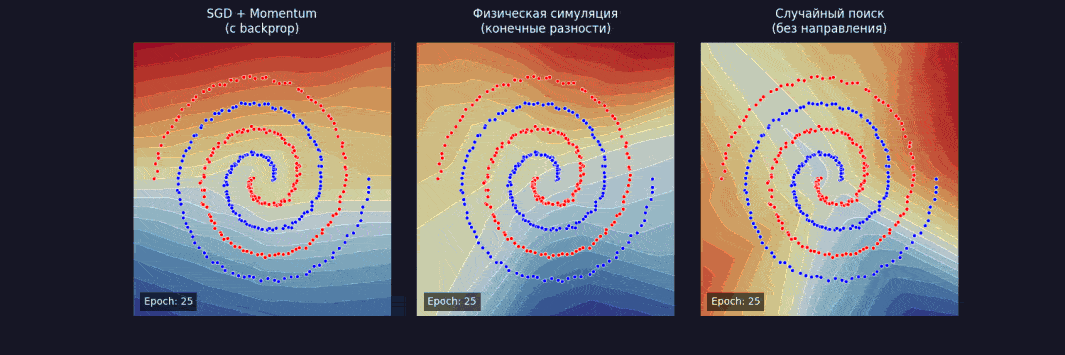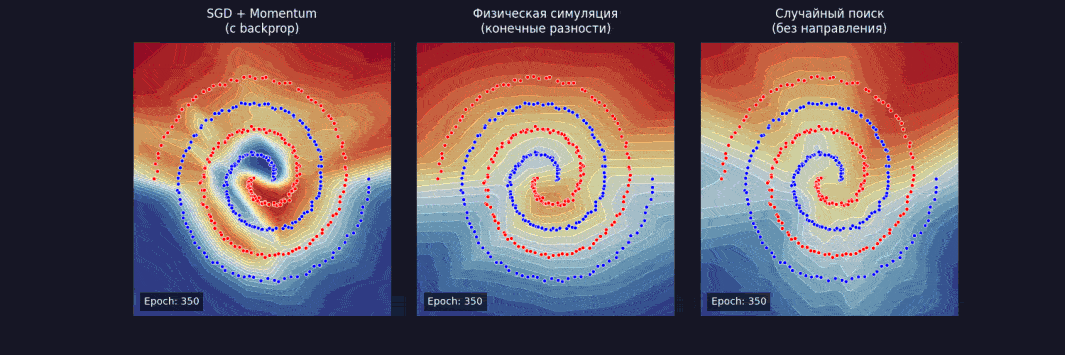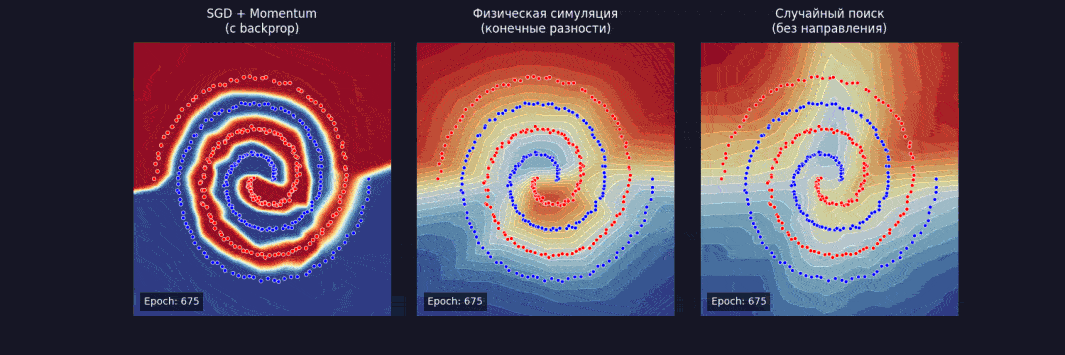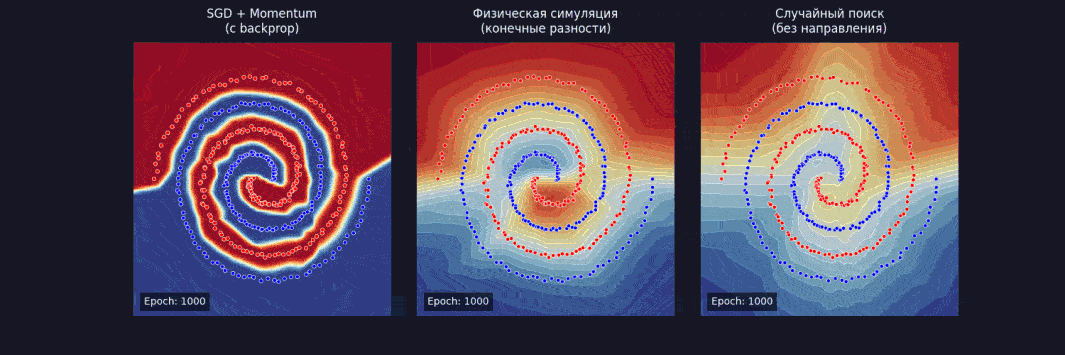
Физика работает. Медленнее, чем backpropagation, потому что конечные разности — дорого, но неплохо по качеству. А случайный поиск застрял — слишком много параметров, слишком мало информации о рельефе.
Зачем все это знать
Ну серьезно, зачем?
Я же не предлагаю выбросить backpropagation. Это было бы как предлагать отказаться от колеса, потому что «ноги — тоже вариант». Backprop работает, но понимание физической природы оптимизации дает кое-что ценное.
Первое, интуицию для гиперпараметров. Learning rate — это шаг по времени, а не рандомное число:
- слишком большой — система нестабильна (шарик улетает с горки);
- слишком маленький — шарик застревает в первой попавшейся ямке;
- Momentum 0,9 — шарик «помнит» 90% своей скорости.
Поменяйте на 0,99 и он станет тяжелее, будет дольше разгоняться и дольше тормозить. Это уже не подбор чисел наугад, а физическая интуиция, хотя, не вдаваясь в детали, это тоже кажется своего рода угадыванием.
Второе — понимание расписаний learning rate. Cosine annealing здесь работает как медленное охлаждение, Warmup — как плавный разгон, а Warm restarts — это способ встряхнуть систему, чтобы вылезти из локального минимума (аналог в физике — метод имитации отжига).
Третье, объяснение, почему большие батчи хуже обобщают. Маленький батч создает сильный стохастический шум. Это как броуновское движение: случайные толчки помогают шарику перепрыгнуть через невысокие барьеры и найти широкий минимум (который обычно лучше обобщает). Большой батч — это детерминированная сила, шарик катится в ближайшую яму и сидит там.
Вместо итогов
Я потратил пару выходных на то, чтобы обучить нейросеть методами Ньютона и Эйлера. Не самый продуктивный уикэнд, скажу честно. Зато теперь, когда я пишу optimizer = Adam(lr=3e-4), я вижу знакомое уравнение движения шарика по холмистому ландшафту.
lr=3e-4 — шаг по времени. betas=(0.9, 0.999) — инерция и адаптивное трение. weight_decay=0.01 — пружина, не дающая шарику уехать слишком далеко от центра.
Физика XVII–XVIII веков, замаскированная под API XXI века.





