

Последние годы развитие LLM шло по пути экстенсивного масштабирования: считалось, что чем больше весов и данных, тем умнее модель. В индустрии даже сложилась жесткая классификация по количеству параметров: 7B, 8B, 32B. Она же создает иллюзию, что модели одной весовой категории обладают сопоставимыми аналитическими, генеративными и логическими характеристиками, что в корне противоречит современным эмпирическим наблюдениям.
Но действительно ли «вес» модели все еще определяет ее качество в 2026 году? Или компактная архитектура способна конкурировать с гигантами, требующими H100 и сотни гигабайт VRAM?
Имеет ли размер значение
На практике выбирать модель только по количеству параметров для продакшена — ошибка. Этот подход игнорирует эволюцию методов обучения, архитектурную оптимизацию и тонкую настройку — файн-тюнинг. Ярким примером, опровергающим прямую корреляцию между параметрическим объемом и интеллектом, является большая разница в производительности моделей с сопоставимым числом весов.
Устаревшие архитектуры размером 7B демонстрируют весьма посредственные результаты в задачах, требующих математического рассуждения или алгоритмического мышления. В то же время современные модели аналогичного или даже меньшего размера превосходят их в два, а иногда и в три раза. Например, базовая архитектура Phi-3-mini, обладает всего 3,8 млрд параметров, а демонстрирует производительность, сопоставимую с моделями уровня Mixtral 8x7B (чья общая емкость превышает 46 млрд параметров). Тот же Phi-3-mini уже превосходит модель Llama-2 13B в ряде тестов. Развитие этой линейки в виде Phi-4-Reasoning доказывает, что целенаправленная тренировка на логических цепочках может дать малым моделям преимущество перед гигантами.
Судить о модели по потреблению видеопамяти тоже неверно. Модели с одинаковым весом могут вести себя по-разному в зависимости от топологии своей сети: плотные (dense) трансформеры загружают GPU иначе, чем разреженные архитектуры с экспертами (MoE). А вот на скорость инференса и стоимость работы с длинным контекстом напрямую влияют механизмы внимания — Grouped-Query Attention (GQA) или Sliding Window Attention (SWA).

В текущем цикле развития LLM размер модели перестал быть главным показателем качества. Парадигма «равных весов» больше не работает, поэтому при выборе решения для продакшена нужно смотреть глубже — на архитектурные особенности и реальную производительность в конкретных задачах. Дальше разберем современные архитектуры, которые сейчас наиболее эффективны для деплоя.
Анализ целевых моделей
Для этого теста я отобрал модели, которые сейчас висят в топах бенчмарков. Искал разные подходы к обучению: было интересно, как разработчики сжимают большие сетки и затачивают их под логику и код. Плюс добавил сюда свежие релизы за 2025–2026 годы.
Выбирал только малый и средний класс — от 1,5B до 32B параметров. Огромные модели брать не стал, так как эти «малыши» проще в запуске. Их можно крутить локально или на дешевой виртуалке, а качество при этом не страдает.
Семейство Qwen3
Модели от Alibaba Cloud развивают классическую dense-архитектуру. В третьем поколении разработчики заметно прокачали агентские навыки и работу с кодом. Между поколениями Qwen2.5 и Qwen3 случился сильный скачок в плане агентских возможностей и написания кода.
Если прошлый Qwen2.5-7B вывозил математику за счет экспертных модулей, то новые Qwen3.6-Plus и линейка Coder берут задачи посерьезнее. Например, они могут кодить фронтенд или разбираться в структуре огромных чужих репозиториев.
Отдельно можно отметить Coder на 30B параметров. Это узкоспециализированный тяжелый софт для инженеров.
Phi-4-Reasoning (Microsoft)
В свое время Phi-3-mini показала, как за счет чистых синтетических данных сетка на 3,8 миллиарда параметров может соревноваться с GPT-3.5. Новая Phi-4-Reasoning-Plus бьет в другую точку — разработчики выкрутили на максимум аналитику.
Модель выбила 79% в бенчмарке Arena-Hard. Для ее скромных размеров это серьезно. Весь упор тут сделан на длинные цепочки рассуждений. Кому интересны технические детали обучения и архитектуры — Microsoft выложили все подробности в Phi-4-reasoning Technical Report.
Mistral-Small-24B-Instruct-2501
Французская лаборатория Mistral AI закрепила за собой репутацию создателя наиболее эффективных моделей среднего размера. Mistral Small 24B —
эта версия вышла в начале 2025 года. На обычном железе вроде Apple M3 с 36 ГБ оперативки она выдает около 18 токенов в секунду — скорость высокая. При этом по качеству ответов модель не уступает тяжелым и неповоротливым сеткам прошлого поколения.

DeepSeek-R1-Distill-Qwen-1,5B
Эта модель представляет собой, пожалуй, наиболее радикальный отход от традиционного масштабирования. Лаборатория DeepSeek, известная своей MoE-архитектурой DeepSeek-V2-Lite, применила методы дистилляции рассуждений, определение которых будет чуть ниже.
Здесь разработчики взяли логические цепочки от огромной модели R1 и сжали их в малый объем — на 1,5 млрд параметров. В итоге появилась микромодель, способная к глубокому саморефлексивному мышлению. Старые базовые сетки на 7B параметров так делать не умели близко.

GPT-OSS-20B
Open-source аналог закрытых моделей класса GPT. При своих 20 млрд параметров она сохраняет баланс: у нее широкая эрудиция и полный контроль над весами.
На тестах скорости модель выдает до 313 токенов в секунду. Задержка до первого ответа (Time to First Token) составляет всего 0,65 секунды.В бенчмарке Humanity’s Last Exam модель набрала 11%. Кажется, что мало. Но на деле средний результат по рынку на апрель 2026 года находится в районе 10,7%, а абсолютный топ среди тяжеловесов пока дошел только до 44,7%.
На странице Humanity’s Last Exam Benchmark Leaderboard | Artificial Analysis можно посмотреть актуальный LeaderBoard по данному бенчмарку.

Серия IBM Granite 4.0 H
Корпоративная модель от IBM для задач, где нельзя ошибаться. В агрегированных тестах Granite 4.0 H Micro доходит до 97,9%.
Главная фишка — предсказуемость. Модель строго держит схемы генерации и почти не галлюцинирует, когда нужно просто вытащить данные из документов. На дашборде это хорошо видно. Все это важно для финансового и медицинского секторов.
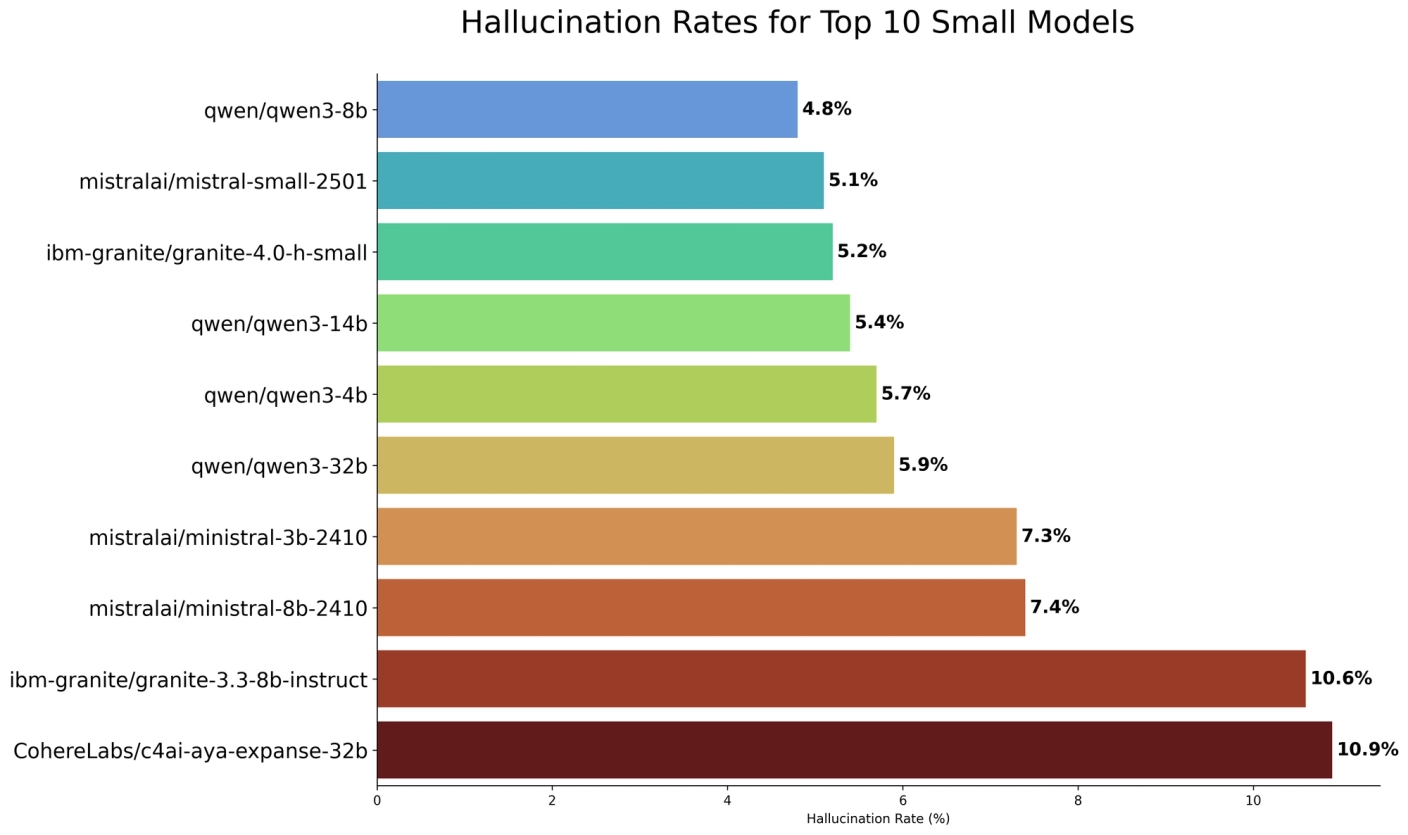
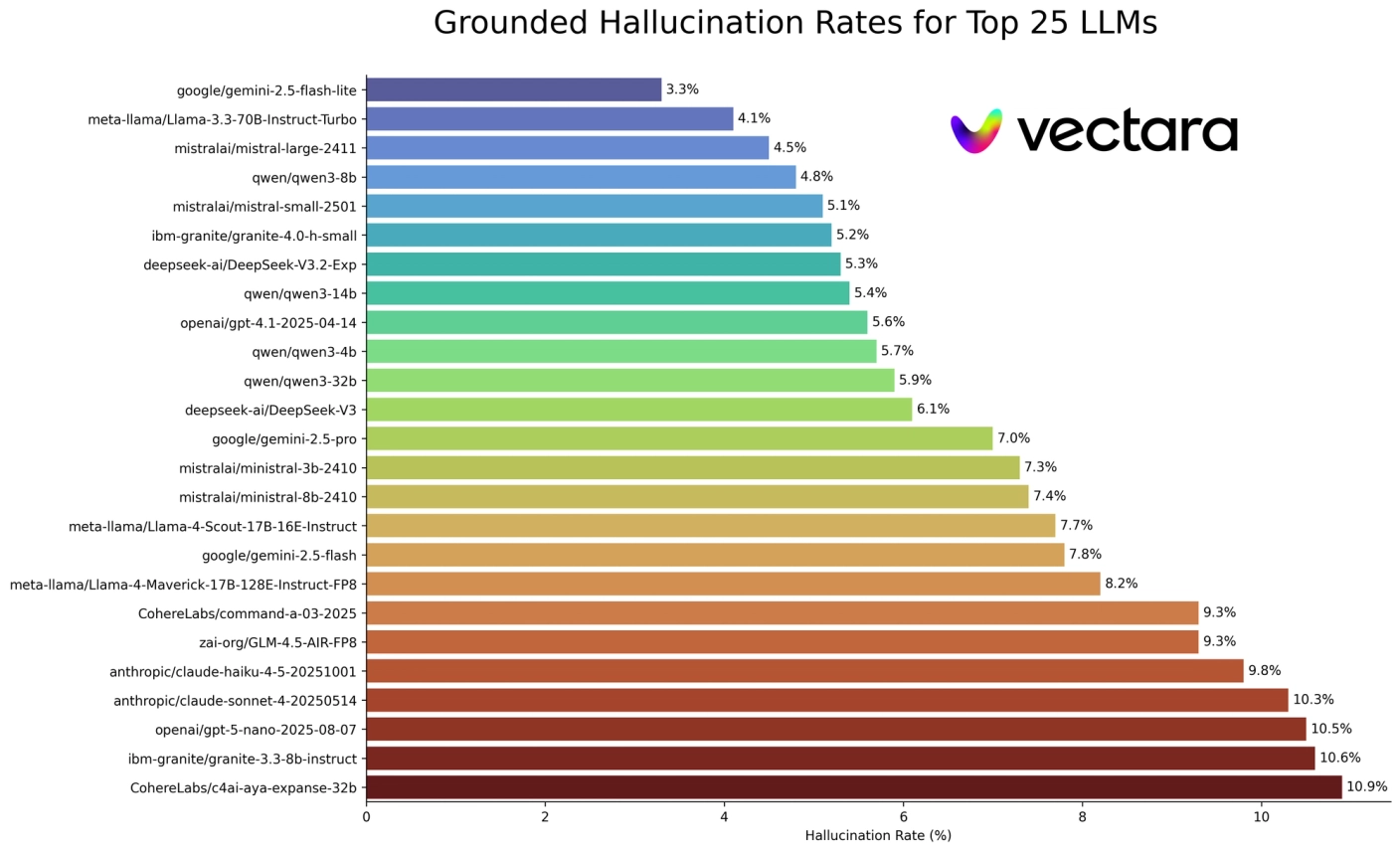
Таблицы с показателями галлюцинаций у 25 лучших моделей и 10 маленьких.
Тема большая. Если нужны основы — как и почему нейросети врут, — это отлично расписали в статье Jesus Vicente Roig и команда Kamiwaza AI.
Что на самом деле формирует интеллект модели
Разница в работе моделей одного размера — не случайность. Это результат того, как их проектировали и учили. Давайте посмотрим, что определяет качество генерации.
Архитектурные инновации
Базовая архитектура трансформера, предложенная в 2017 году, претерпела изменения. Современные модификации направлены на устранение узких мест: квадратичной вычислительной сложности механизма внимания O(n^2) и высоких требований к пропускной способности памяти.
Плотные сети против Mixture-of-Experts
В классических плотных сетях типа Llama-3-8B или Qwen2.5-7B для предсказания каждого следующего токена задействована вся матрица весов. Модель на восемь миллиардов параметров делает все восемь миллиардов математических операций ради одного шага генерации.
Архитектура Mixture-of-Experts (MoE) работает иначе. Она использует маршрутизатор.
Суть MoE — деление параметров на блоки, то есть на «экспертов». Из общих 15,7 млрд параметров DeepSeek-V2-Lite во время инференса активируется лишь 2,4 млрд параметров на токен. Роутер анализирует контекст токена и направляет его только тем экспертам, которые специализируются на данном типе данных: например, на синтаксисе Python или правилах пунктуации.
Так сеть вмещает больше знаний, но не тормозит и не требует суперкомпьютера для запуска. Объем вычислений падает.
В итоге MoE обходятся дешевле на больших объемах текста. Инференс DeepSeek-V2-Lite-Chat (16B) стоит около $0,14 за миллион токенов, по сравнению с $0,25 для плотной Mistral 7B Instruct.
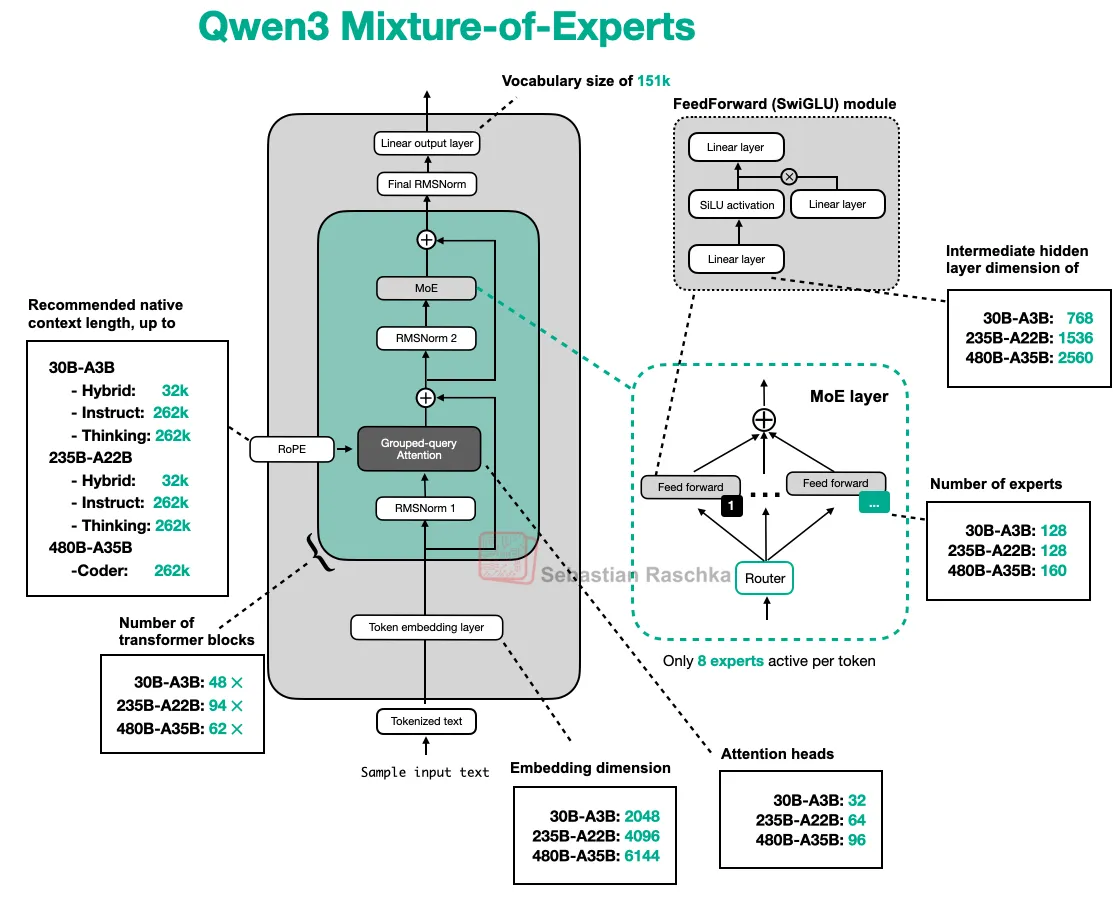
Оптимизация механизма внимания
На задержки и скорость генерации сильно влияет то, как устроен блок внимания. Раньше использовали Multi-Head Attention (MHA). Этот механизм заставлял хранить в памяти огромные тензоры KV-кэша, из-за чего на длинных текстах видеопамять улетала моментально.
Сейчас разработчики перешли на более экономичные схемы:
- Grouped-Query Attention (GQA): используется в Llama-3, Mistral и Qwen. GQA объединяет головы запросов в группы и привязывает их к одной голове ключей и значений. KV-кэш сжимается, а точность почти не падает;
- Sliding Window Attention (SWA): Такое решение внедрили в Mistral 7B. В обычном глобальном внимании токен перебирает вообще всю прошлую историю текста. SWA смотрит только назад на фиксированное окошко. Вычислений становится меньше, и модель обрабатывает длинные последовательности с минимальными затратами ресурсов;
- Multi-head Latent Attention (MLA): уникальная разработка DeepSeek, которая сжимает KV-кэш в латентное пространство с низкой размерностью и обеспечивает беспрецедентную скорость генерации при контекстах до 128 000 токенов.
Длина контекста и позиционное кодирование
Длина контекста сейчас решает все. Ранние модели вроде Mistral-7B оперировали окном в 4 000 – 8 000 токенов. Для бизнеса этого мало: туда целые книги, базы кода или логи аудита. Современные модели, типа Qwen2.5-7B, Llama-3.1-8B или Qwen3.6-Plus обрабатывают от 128 000 до 1 млн токенов.
Контекст расширяют с помощью специальных хитростей вроде позиционного кодирования RoPE (Rotary Position Embedding) с динамическим масштабированием частоты.
От этих механизмов напрямую зависит тест «Иголка в стогу сена» (Needle in the Haystack) — то, насколько хорошо нейронка помнит мелкий факт из середины огромного текста на 128k токенов. Две одинаковые по размеру модели с разным позиционным кодированием будут искать данные с кардинально разной точностью.
Морфология и качество обучающих данных: эпистемология искусственного интеллекта
Эпистемология — раздел философии, изучающий природу, структуру, источники и границы знания. Она исследует, что мы знаем, как мы это узнаем, а также условия достоверности, истинности и обоснованности наших убеждений. Эпистемология отвечает на вопрос, почему полученное знание является объективным.
Если архитектура определяет пропускную способность, то данные детерминируют само видение картины мира нейронной сети.
Синтетические данные и фильтрация
Подход Microsoft к серии Phi доказал: если хорошо почистить данные и добавить правильные комбинации с синтетическими текстами, то это может компенсировать маленький размер модели.
Ту же Phi-3-mini обучили на 3,3 триллиона токенов. Причем датасет собирали так, чтобы натаскать нейронку на логику, а не заставить ее просто зубрить факты. Из обучения сознательно вырезали всякий инфомусор вроде новостных сводок или результатов локальных футбольных матчей. Оставили только то, что помогает усваивать абстрактные логические паттерны.
Следующий шаг — Phi-4-Reasoning. Ее целиком обучили на синтетических датасетах со сложными цепочками рассуждений и математическими доказательствами. Результат — лидерство в профильных бенчмарках при скромных размерах.
Код и мультиязычность как драйверы интеллекта
Если встроить в процесс предобучения тонны математики и кода, у модели в целом прокачивается интеллект.
Когда разработчики перенесли наработки из чисто математической Qwen2-Math в базовую Qwen2.5-7B, показатели сразу подскочили. Балл на сложном олимпиадном тесте MATH у нее взлетел с 52,9 до 75,5.
Умение кодить напрямую связано со строгим структурным мышлением. Выпуск линейки Qwen3 Coder это только подтверждает: когда модель глубоко понимает синтаксис программирования, она и обычные логические задачи решает гораздо лучше.
То же самое с языками. Многоязычные датасеты учат модель не просто переводить слова, а понимать культурный контекст. Например, та же Qwen2.5-7B поддерживает больше 29 языков и работает стабильно. Старые или плохо настроенные сетки на этом часто сыплются: их спрашиваешь на русском или корейском, а они в ответ зачем-то пишут на английском.
Пост-тренировка и парадигмы выравнивания
Сырая базовая модель умеет только угадывать следующее слово. Как ассистент она бесполезна. Нормальный интерфейс, стиль общения и понятную структуру ответов нейронка получает только на этапе постобучения.
SFT, RLHF и DPO
Supervised Fine-Tuning (SFT) закладывает базовый формат диалога («вопрос-ответ»). Но настоящее качество ответов дают другие методы: обучение с подкреплением на основе отзывов людей (RLHF) и прямая оптимизация предпочтений (DPO).
Взять ту же Phi-3-mini-4k-instruct. Она прошла жесткое постобучение через SFT и DPO, чтобы четко выполнять команды и не нарушать правила безопасности. На этом же этапе выравнивания модели учатся нормально выдавать структурированные данные. Например, Qwen2.5-7B-Instruct после такого улучшения стала понимать JSON-схемы в разы лучше прошлых версий.
При этом настройки функции вознаграждения в RLHF могут увести модель либо в творческую многословность, либо в сухие факты. На выходе две одинаковые по архитектуре сетки могут работать как абсолютно разные инструменты.
Дистилляция рассуждений
Важнейшим прорывом конца 2025–2026 годов — внедрение дистилляции цепей рассуждений (Chain-of-Thought). Модель DeepSeek-R1-Distill-Qwen-1.5B является продуктом этой методологии.
Суть метода в том, что огромная модель-учитель (вроде базовой R1 на 685B параметров) решает тысячи сложных задач и расписывает каждый свой шаг. Затем микромодель c 1,5B параметров обучается не просто на финальных ответах, а на всем пути размышлений учителя.
Это позволяет компактным моделям воспроизводить аналитическую глубину, характерную для ИИ уровня 100B+, преодолевая ограничения своего скромного размера.
Практическое сравнение моделей
Для объективного сравнения производительности необходимо деконструировать результаты стандартизированных бенчмарков, оценивающих логику, математику, программирование, а также критические для бизнеса параметры — скорость и стоимость инференса.
Когнитивные способности: от конкретных фактов к абстракции
Традиционный тест Massive Multitask Language Understanding (MMLU) исторически служил базовым критерием оценки знаний в различных областях. Однако для выявления способности к истинному рассуждению современные аналитики ориентируются на GSM8K и MATH. Соответственно — на математику начальной школы, требующую надежных многошаговых вычислений, и на олимпиадные математические задачи, требующие высокого уровня абстракции, символьного манипулирования и длинных логических цепочек.
В нижеприведенной таблице синтезированы данные тестирования моделей из нашего FMC-пула и их прямых оппонентов:
| Модель | Параметры | MMLU | GSM8K | MATH | HumanEval (Code) | Примечание |
| Qwen2.5-7B-Instruct | 7B | 75,4 | 91,6 | 75,5 | 84,8 | Интеграция экспертных сетей (math/code) |
| Qwen3-Coder-30B-Instruct | 30B | ~82,0+ | >93,0 | >80,0 | >90,0 | Лидер среди открытых code-моделей |
| Phi-4-Reasoning-Plus | ~14B | 51,38* | 72,39* | 51,62* | 52,48* | Лидер Arena-Hard (79%) * |
| Mistral-Small-24B (2501) | 24B | ~81,3 | >85,0 | ~44-50 | ~76,0 | Оценка Wolfram: 98,3% (агрегат) |
| DeepSeek-V2-Lite-Chat | 15.7B (2.4B) | 55,7 | 72,0 | 27,9 | 57,3 | MoE-оптимизация |
| DeepSeek-R1-Distill-Qwen | 1.5B | ~65,0 | >80,0 | >45,0 | ~55,0 | Феноменальная логика для микро-моделей |
| Llama-3.1-8B-Instruct | 8B | 67,9 | 84,4 | 51,9 | 72,6 | Индустриальный baseline |
| Mistral-7B-v0.3 | 7,3B | ~63,4 | 46,4 | 24,0 | 32,3 | Устаревающая плотная архитектура |
| GPT-OSS-20B | 20B | – | – | – | – | Победитель Humanity’s Last Exam (11%) |
| Granite 4.0 H Micro | <4B | – | – | – | – | Оценка Wolfram: 97,9% |
Данные агрегированы на основе официальных технических отчетов и данных независимых лабораторий. Символ «*» отмечает значения для Phi-4-mini, так как детальные метрики полной версии могут варьироваться. Метрики подвержены дисперсии в зависимости от методов квантования и промтинга.
Анализ данных категорически опровергает гипотезу прямой зависимости интеллекта от весов. Qwen2.5-7B-Instruct, обладая всего 7 млрд параметров, демонстрирует феноменальный результат — 75,5 на бенчмарке MATH, что в 2,5 раза превосходит результат сопоставимой по размеру Llama-3-8B-Instruct 30,0 и более чем втрое превышает результаты базовой Mistral 7B 24.0. Этот гигантский скачок обусловлен не банальным увеличением количества вычислительных узлов, а глубокой интеграцией специализированных данных (из Qwen2-math) и агрессивным обучением на абстрактных математических паттернах.
Бенчмарк MATH выступает в роли фильтра, где модели, которые показывают высокие результаты на GSM8K за счет простого запоминания типовых школьных задач, полностью проваливаются на MATH, так как последняя требует способности к обобщению и выводу.
Отдельного упоминания заслуживает Phi-4-Reasoning. Несмотря на скромные показатели в базовых тестах на эрудицию (MMLU), эта модель демонстрирует потрясающую адаптивность в реальных, неструктурированных диалогах, выиграв престижный Arena-Hard с результатом 79%. Это свидетельствует о том, что синтетическое выравнивание и упор на Chain-of-Thought делают модель гораздо более полезной в реальных условиях, чем можно предсказать по сухим академическим метрикам.
В то же время в сверхкомпактной DeepSeek-R1-Distill-Qwen-1.5B дистилляция мыслительного процесса позволяет этой 1.5B модели решать математические задачи лучше, чем это делали флагманы размером 13-34B всего год назад.
Программирование: от автодополнения к агентным системам
Способность к генерации синтаксически корректного, безопасного и алгоритмически верного кода традиционно измеряется бенчмарками HumanEval и MBPP.
В классе малых моделей лидерство вновь принадлежит архитектурам от Alibaba: Qwen2.5-7B-Instruct достигает 84,8 баллов на HumanEval, оставляя позади Llama-3.1-8B (72,6) и DeepSeek-V2-Lite-Chat (57,3). Однако истинным прорывом является Qwen3-Coder-30B.
Эта модель переходит от помощника в автодополнении по типу copilot к парадигме агентного ИИ. Способность воспринимать миллионные контексты, анализировать скриншоты интерфейсов и автономно компилировать, тестировать и исправлять целые репозитории делает Qwen3-Coder уникальным инженерным инструментом, превосходящим многие модели на 70B+ параметров.
IBM Granite 4.0 H (Micro/Tiny), напротив, фокусируются на узкоспециализированных корпоративных задачах. Их сила не в творческом программировании, а в феноменальной предсказуемости при парсинге логов, генерации SQL-запросов и работе со строго типизированными данными. Высокий уровень соблюдения схем, например, JSON делает Granite одним из лучших в энтерпрайз-пайплайнах.
Динамика инференса: TTFT и квантование
Интеграция LLM в реальные производственные системы жестко лимитируется пропускной способностью (TPS — Tokens Per Second), задержкой до первого токена (TTFT — Time to First Token) и стоимостью хостинга.
Анализ скорости инференса (медианные показатели)
GPT-OSS-20B. Ультра-быстрая генерация — 250 токенов в секунду при TTFT 0,65 с.

Mistral-Small-24B-Instruct-2501. Превосходный баланс — на ноутбуке уровня Apple M3 (36GB RAM) модель выдает 18 TPS, что достаточно для комфортного чтения человеком в реальном времени, при этом обеспечивая логику уровня 70B.

Qwen3-8B. В локальных тестах обеспечивает стабильные 48 TPS. На серверных видеокартах около 65 TPS.

Особое влияние на баланс скорости и качества оказывает квантование — процесс сжатия весов модели из высокоточных форматов (FP16/BF16) в 8-битные или 4-битные целочисленные форматы (GGUF q8_0, q4_K_M). Квантование позволяет загрузить модель Mistral Small 24B в 16-24 ГБ видеопамяти, что недостижимо при полной точности. Однако этот процесс не проходит бесследно.
Эксперименты показывают, что квантование до четырех бит существенно деградирует математические способности модели. Например, на бенчмарке GSM8K модель может терять до 10-15% точности, при этом в некоторых реализациях процессорных вычислений время инференса может даже парадоксальным образом возрастать из-за накладных расходов на деквантование матриц. Деградация от квантования затрагивает сложные цепи рассуждений (бенчмарк MATH) гораздо сильнее, чем задачи извлечения фактов или суммаризации.
В облачной экономике архитектура MoE демонстрирует безоговорочное превосходство. DeepSeek-V2-Lite активирует лишь малую часть своей сети, что позволяет API-провайдерам снижать цены: $0,14 за миллион входных токенов против $0,25 для сопоставимой Mistral 7B. На масштабах корпоративного процессинга — например, при анализе 200 000 текстовых документов в месяц — выбор более дешевой и быстрой архитектуры может сократить издержки на 60-70% без потери качества бизнес-логики.
Дивергенция поведения: почему равные веса рождают разные сущности
Основываясь на проведенном анализе, можно выделить четыре ключевые причины, по которым модели с одинаковыми весами демонстрируют принципиально разное поведение.
Формирование уникальных способностей
В зависимости от распределения обучающей выборки, модель формирует свой уникальный профиль навыков. Модель может быть гениальной в одном домене и беспомощной в другом.
Так, Llama-3.1-8B отвечает правильно на 77,1% вопросов здравого смысла (CommonsenseQA), но выдает лишь 17,9% точных совпадений на тесте эрудиции NQ-Open. Это доказывает: параметрический объем не является мерой общего интеллекта.
Память против дедукции
Компактные модели (Phi-4, DeepSeek-R1-Distill) не обладают достаточным количеством синапсов, чтобы запомнить всю энциклопедию мировых знаний. Их обучение намеренно смещено в сторону развития дедуктивных и индуктивных механизмов. Они не знают факты, но они умеют их выводить на основе предоставленного в промте контекста. Плотные модели (Llama-3), напротив, сохраняют больший объем сырых знаний.
Степень и вектор выравнивания
Методология RLHF радикально меняет стиль взаимодействия. Mistral оптимизируется на максимальную лаконичность и минимальный TTFT, что делает ее идеальной для систем реального времени и голосовых ботов. Qwen3, наоборот, выровнена на тщательное, многословное планирование и генерацию строгих JSON-схем, что делает ее предпочтительной для серверной автоматизации.
Сегрегация знаний в MoE
В плотных архитектурах знания «размазаны» по всей сети, что часто приводит к катастрофическому забыванию при тонкой настройке. В сетях MoE знания инкапсулированы в конкретных экспертах. Это позволяет MoE-моделям лучше справляться с кросс-доменными задачами — например, одновременным переводом с французского и написанием SQL-кода, так как активируются разные, не конфликтующие подсети.
Практический гайд по выбору модели под задачу
Деконструкция мифа о параметрах требует от системных архитекторов и AI-инженеров перехода от количественного выбора (поиск модели с максимальным числом B, влезающей в сервер) к качественно-функциональному проектированию. Определение оптимальной модели должно опираться исключительно на специфику производственной задачи, доступный аппаратный бюджет и требования к задержкам.
Автономные агенты, сложное программирование и системная инженерия
В домене генерации кода и автономного планирования лидером является семейство Qwen3 (в частности, Qwen3-Coder-30B). Глубокое понимание синтаксиса, способность анализировать визуальные макеты интерфейсов и контекст до 1 млн токенов делают ее лучшим выбором для создания AI-разработчиков и сложных RAG-систем.
Глубокая логика и математический анализ при ограниченных ресурсах
Если задача требует сложного пошагового рассуждения, но бюджет на GPU жестко ограничен, идеальными кандидатами становятся DeepSeek-R1-Distill-Qwen-1.5B и Phi-4-Reasoning. Методы дистилляции и синтетического обучения наделили эти микро-модели способностью к абстрактному мышлению, недоступному классическим 7B/13B сетям. Эти модели идеально подходят для разбора сложных юридических или финансовых контрактов, если предварительно снабдить их необходимыми фактами через RAG.
Универсальный локальный ассистент и замена 70B моделей
Для персонального использования на рабочих станциях разработчиков (MacBook M3/M4, RTX 4090) или в малых корпоративных серверах оптимальной точкой (sweet spot) выступает Mistral-Small-24B-Instruct-2501. Обладая интеллектом, близким к флагманским 70B моделям, она работает в несколько раз быстрее и потребляет значительно меньше памяти при квантовании, обеспечивая точные и сбалансированные ответы для ежедневных задач.
Корпоративная интеграция и извлечение структурированных данных
В строгих enterprise-средах по типу банкинга и медицины, где галлюцинации недопустимы, а выходные данные должны строго соответствовать JSON-схемам для интеграции в классические API, хорошо проявляют себя модели Granite 4.0 H (Micro/Small). Их архитектура оптимизирована для предсказуемости и высокой скорости парсинга, что отражается в их выдающихся показателях агрегированных корпоративных бенчмарков.
Открытые экосистемы и крупномасштабные пайплайны.
Для исследовательских задач или создания собственных файн-тюнинг моделей с полным контролем над весами отлично подходит GPT-OSS-20B. Благодаря высокой скорости инференса и выдающимся результатам в сверхсложных тестах она является мощным универсальным инструментом.
Высокоскоростная потоковая обработка
Для голосовых агентов, где задержка TTFT свыше 500 миллисекунд разрушает пользовательский опыт, плотные модели малого размера Mistral 7B v0.3 или Llama-3.1-8B или сверхбыстрые MoE DeepSeek-V2-Lite остаются вне конкуренции. Они обеспечивают моментальный отклик и низкую стоимость эксплуатации на масштабе миллионов запросов.
Заключительные мысли
Эпоха, когда мы судили о силе модели только по количеству нулей в параметрах подошла к концу. Современные архитектуры и новые подходы к обучению меняют подход к AI-инжинирингу.
Во-первых, фраза «одинаковые веса – одинаковые возможности» больше не работает. Интеллектуальный потенциал модели больше не может быть сведен к простому подсчету параметров. Модель с 1,5–3,8 млрд параметров (DeepSeek-R1-Distill, Phi-4), обученная с применением дистилляции логики и синтетических данных, способна превосходить базовые архитектуры размером в 13–34 млрд параметров в задачах рассуждения и вывода. Параметр «B» утратил свою предсказательную силу как изолированная метрика.
Во-вторых, качество данных важнее размера сети. Успех Qwen3-Coder и Phi-4-Reasoning доказывает: если выкинуть из обучения «информационный мусор» и новости десятилетней давности, заменив их на цепочки сложных рассуждений, модель поумнеет быстрее, чем если просто добавить ей новых слоев
В-третьих, архитектурная сегрегация MoE и алгоритмическая оптимизация внимания MLA, GQA отвязали качество от цены. Благодаря архитектурам вроде DeepSeek, которые активируют лишь малую часть своих весов для ответа, мы получили «умные» модели-полиглоты, которые стоят в разы дешевле в эксплуатации. Это делает внедрение ИИ в бизнес по-настоящему выгодным.
Наконец, универсальной «лучшей» нейросети не существует. Сегодня инженеру нужно выбирать не самую большую модель, а самую подходящую под задачу. Нужен агент-программист? Берите Qwen3. Нужен баланс и скорость локально? Ваш выбор — Mistral-Small-24B. Требуется глубокая логика? Подойдет дистиллированная DeepSeek-R1. А для строгой работы с данными в энтерпрайзе лучше всего покажет себя Granite.
Понимание способностей каждой отдельной архитектуры — ключ к эффективному внедрению ИИ в 2026 году.




