

Каждый день регистрируются сотни тысяч новых доменов, поэтому найти среди оставшихся что-то короткое, понятное и незанятое становится сложнее. Хороший домен — это узнаваемость и доверие пользователя.
Идея автоматизации
Будем честны: подбор домена — это тупая механическая работа. Придумали название, открыли регистратор, вбили желаемое в поиск — «Занято».
Сначала пытаешься играть с буквами, потом добавляешь дефисы, в итоге психуешь и лезешь в другие зоны, но это не всегда актуально.
В какой-то момент мне стало банально лень. Но вместо того, чтобы смириться, я решил потратить вечер-два и собрать костыль, который будет страдать за меня. Идея простая: заставить LLM-агента генерировать названия и сразу проверять их доступность по API, чтобы на выходе получать только свободные и адекватные варианты.
Хорошее доменное имя: существует или нет
Кризис доменных имен
Пространство доменных имен не резиновое — особенно в популярных зонах, таких как: .com, .ru, .io и .org. По данным статьи DomainIncite, только в зоне .com зарегистрировано более 160 млн доменов.
Короткие, осмысленные, легко запоминающиеся имена разобраны уже давно — часть из них перепродается на вторичном рынке за десятки тысяч долларов. Новым проектам приходится либо идти на компромисс, либо проявлять изобретательность.
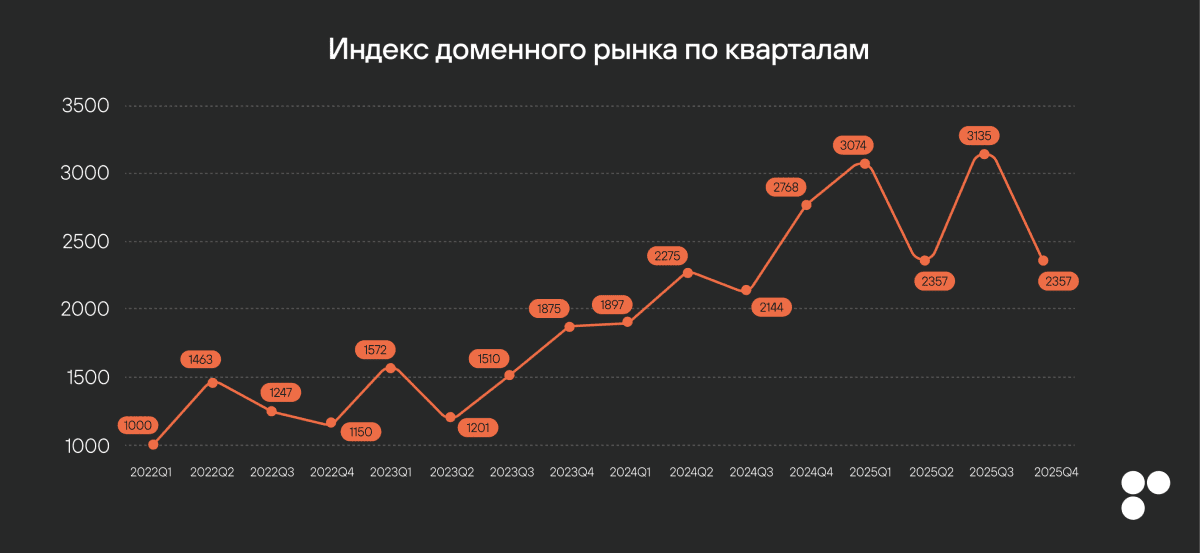
Обычно в таких случаях инженеры идут по пути наименьшего сопротивления: просто добавляют цифры или лишние буквы. Получается, вместо flowers.ru, что-то вроде flowers11.ru или flowerrs.ru. Это не только выглядит дешево, но и несет риски для безопасности: пользователи могут ошибиться в написании и попасть на фишинговый сайт.
Фишинговые домены и домены-зеркала
Фишинговые домены плодят сущности вроде sberbank-online.ru или pay-pal-service.com. И именно тут появляются мошенники, используя тайпосквоттинг — регистрацию имен, которые визуально почти не отличимы от оригинала: go0gle.com (через ноль) или paypa1.com.
Реальный кейс: минус $500 000 за одну букву. Летом 2025 года блокчейн-разработчик из России лишился криптоактивов на полмиллиона долларов из-за одной опечатки. Он скачал расширение для подсветки синтаксиса Solidity из маркетплейса Open VSX. Плагин выглядел легитимным, имел тысячи загрузок и хорошие отзывы.
Подвох был в имени автора: злоумышленники использовали ник juanbIanco — с заглавной латинской I вместо строчной l. Разработчик, как и алгоритмы ранжирования, не заметил подмены. В итоге расширение подтянуло бэкдор, который выгреб приватные ключи из системы.
Если даже опытный инженер попадается на замену одной буквы в знакомом имени, то обычный пользователь и подавно не отличит ваш «официальный» my-service-24.io от мошеннического my-servlce-24.io.
Домены-зеркала — это еще одна проблема. Популярные бренды и сервисы часто вынуждены создавать копии своих сайтов после блокировок, используя созвучные адреса (например, добавляя приставки mirror, online или порядковые номера), или через другие зоны.
Проблема в том, что пользователь привыкает: «Ага, основной сайт не открывается, значит, надо искать что-то похожее в поиске». Оба явления процветают именно потому, что в «нормальных» зонах места почти не осталось — злоумышленники занимают соседние ниши.
Масштабы могут быть и более катастрофическими. В 2024 году перед Олимпиадой в Париже, киберпреступники развернули сеть из 700+ доменов типа paris2024-tickets.com. Сайты были отрисованы один в один с официальными, а из-за ажиотажа люди массово вводили данные карт. В итоге 180 000 пострадавших, 15 млн евро ущерба и гигантский слив персональных данных.
Домен — это не просто эстетика
Хороший домен работает как первое рукопожатие с пользователем. Он должен легко произноситься вслух, без ошибок набираться с клавиатуры и мгновенно ассоциироваться с тематикой сайта. Домен вида xn--e1afmapc.xn--p1ai или my-super-cool-startup-2024.net создает лишнюю нагрузку и подрывает доверие еще до того, как пользователь увидел сам сайт. Но это вы и сами знаете.
Автоматизация подбора доменного имени
LLM хорошо справляется с задачами, где нужно генерировать много вариантов по заданным критериям — короткое, тематическое, без цифр, в определенной зоне. Если сразу после генерации автоматически проверять каждый вариант через WHOIS, получается замкнутый конвейер: на выходе мы получаем разные домены и видим, какие из них заняты, а какие свободны. Никакой ручной работы.
Обзор проекта в общих чертах
Проект состоит из двух последовательных этапов.
Первый — обращение к LLM-агенту с описанием проекта и требованиями к домену (длина, ключевые слова, зоны). В итоге получаем список потенциальных названий.
Второй — автоматический фильтр. Скрипт прогоняет каждый вариант через WHOIS-запрос: занят или свободен. В конце на руках остается готовый список: мы видим и сами идеи, и информацию о том, какие из них свободны для регистрации. Весь ручной перебор в интерфейсе регистратора исключается.
Детали реализации
Стек и структура проекта
Проект написан на Python. Для обращения к LLM-агенту используется OpenAI-совместимый API-ключ. WHOIS-запросы реализованы через библиотеку python-whois. Структура сама по себе компакта: модуль генерации через агента, модуль проверки занятости адреса, точка входа с конфигурацией через .env и простой web-интерфейс.
Как компоненты работают вместе
Генерация и проверка соединены в линейный конвейер: сначала агент создает список из возможных адресов, потом каждый домен проходит WHOIS-проверку на занятость. Результат — отфильтрованный список доменов, который выводится на веб-странице. Весь процесс от запуска до результата занимает порядка 10–30 секунд в зависимости от количества кандидатов и скорости WHOIS-серверов.
Процесс создания проекта
Первым делом мы получаем API-ключ на сайте openrouter.ai для того, чтобы можно было обращаться с запросом к LLM-агенту. Далее выносим его в env-файл, после чего беремся за создание самого проекта:
MODELS = [
"qwen/qwen3-next-80b-a3b-instruct:free",
"arcee-ai/trinity-large-preview:free",
"openai/gpt-oss-120b:free",
]
Для отказоустойчивости, возьмем небольшой список из бесплатных моделей в случае, если одна из них отвалится:
def generate_domains(user_prompt: str, tlds: list, count: int) -> list:
if not OPENROUTER_API_KEY:
raise Exception("OPENROUTER_API_KEY не задан. Проверьте файл .env")
headers = {
"Authorization": f"Bearer {OPENROUTER_API_KEY}",
"Content-Type": "application/json",
}
tlds_str = ", ".join(tlds) if tlds else ".com, .net, .org"
prompt_text = (
f"Based on the following description, generate exactly {count} creative and relevant domain name suggestions.\n\n"
"Description: " + user_prompt + "\n\n"
"Rules:\n"
f"- Use ONLY these TLDs (domain zones): {tlds_str}\n"
"- Each domain should be concise (2-20 characters before the TLD)\n"
"- Make them memorable and brandable\n"
"- No spaces or special characters except hyphens\n"
"- Distribute suggestions across the provided TLDs\n"
"- Return ONLY a JSON array of domain names, nothing else\n"
'- Example format: ["example.com", "mystore.net", "coolbrand.io"]\n\n'
f"Generate exactly {count} domain suggestions as a JSON array."
)
last_error = None
for model in MODELS:
try:
payload = {
"model": model,
"messages": [{"role": "user", "content": prompt_text}],
"max_tokens": 1024,
}
body = json.dumps(payload, ensure_ascii=False).encode("utf-8")
response = requests.post(OPENROUTER_URL, headers=headers, data=body, timeout=60)
response.raise_for_status()
data = response.json()
response_text = data["choices"][0]["message"]["content"].strip()
json_match = re.search(r'\[.*?\]', response_text, re.DOTALL)
if json_match:
domains = json.loads(json_match.group())
if domains:
print(f"Used model: {model}")
return domains[:count]
except Exception as e:
print(f"Model {model} failed: {e}")
last_error = e
continue
raise Exception(f"Все модели недоступны. Последняя ошибка: {last_error}")
Зададим структурированный промт и передадим в него описание проекта пользователя, список доменных зон и желаемое количество вариантов. Спарсим ответ модели, и извлечем JSON-массив из полученного текста
def check_domain_availability(domain: str) -> dict:
try:
w = whois.whois(domain)
if w.domain_name or w.registrar or w.creation_date:
return {"domain": domain, "available": False, "status": "taken"}
else:
return {"domain": domain, "available": True, "status": "available"}
except SystemExit:
return {"domain": domain, "available": None, "status": "unknown"}
except Exception as e:
error_str = str(e).lower()
if any(x in error_str for x in ["no match", "not found", "no entries", "no data"]):
return {"domain": domain, "available": True, "status": "available"}
return {"domain": domain, "available": None, "status": "unknown"}
Выполняем WHOIS-запросы и анализируем результат по названию, регистратору или дате создания. Если хотя бы один из них присутствует — домен занят.
def check_domains_parallel(domains: list) -> list:
results = [None] * len(domains)
with ThreadPoolExecutor(max_workers=10) as executor:
futures = {
executor.submit(check_domain_availability, domain): i
for i, domain in enumerate(domains)
}
for future in as_completed(futures):
i = futures[future]
results[i] = future.result()
return results
Проверять все результаты по очереди было бы очень долго, поэтому мы создаем пул из десяти потоков для параллельной проверки, благодаря чему проект работает шустрее.
@app.route('/generate', methods=['POST'])
def generate():
data = request.get_json(force=True)
prompt = data.get('prompt', '').strip()
tlds = data.get('tlds', ['.com', '.net', '.org', '.io', '.store', '.shop'])
count = int(data.get('count', 10))
count = max(1, min(20, count))
if not tlds:
tlds = ['.com', '.net', '.org']
if not prompt:
return jsonify({"error": "Пожалуйста, введите описание"}), 400
try:
domains = generate_domains(prompt, tlds, count)
if not domains:
return jsonify({"error": "Не удалось сгенерировать доменные имена"}), 500
results = check_domains_parallel(domains)
return jsonify({"domains": results})
except Exception as e:
return jsonify({"error": f"Ошибка: {str(e)}"}), 500
if __name__ == '__main__':
app.run(debug=True, port=5000)
Здесь мы проводим валидацию входных значений: число выводимых результатов, какие доменные зоны будут выводиться и описание запроса.
После того, как проект был готов, я провел пару тестов на работоспособность на своей системе, поправил некоторые нюансы. После финальных правок необходимо было развернуть проект на своем сервере, чтобы доступ к сервису был в любой момент времени.
Выгрузил данные на сервер, установил необходимые зависимости, создал и запустил systemd-сервис, открыл порт на файрволе. И теперь проект функционировал и был доступен в любой момент при необходимости.
Как работает проект
При переходе на страницу проекта мы попадаем на пользовательский интерфейс. Он выполнен максимально просто.
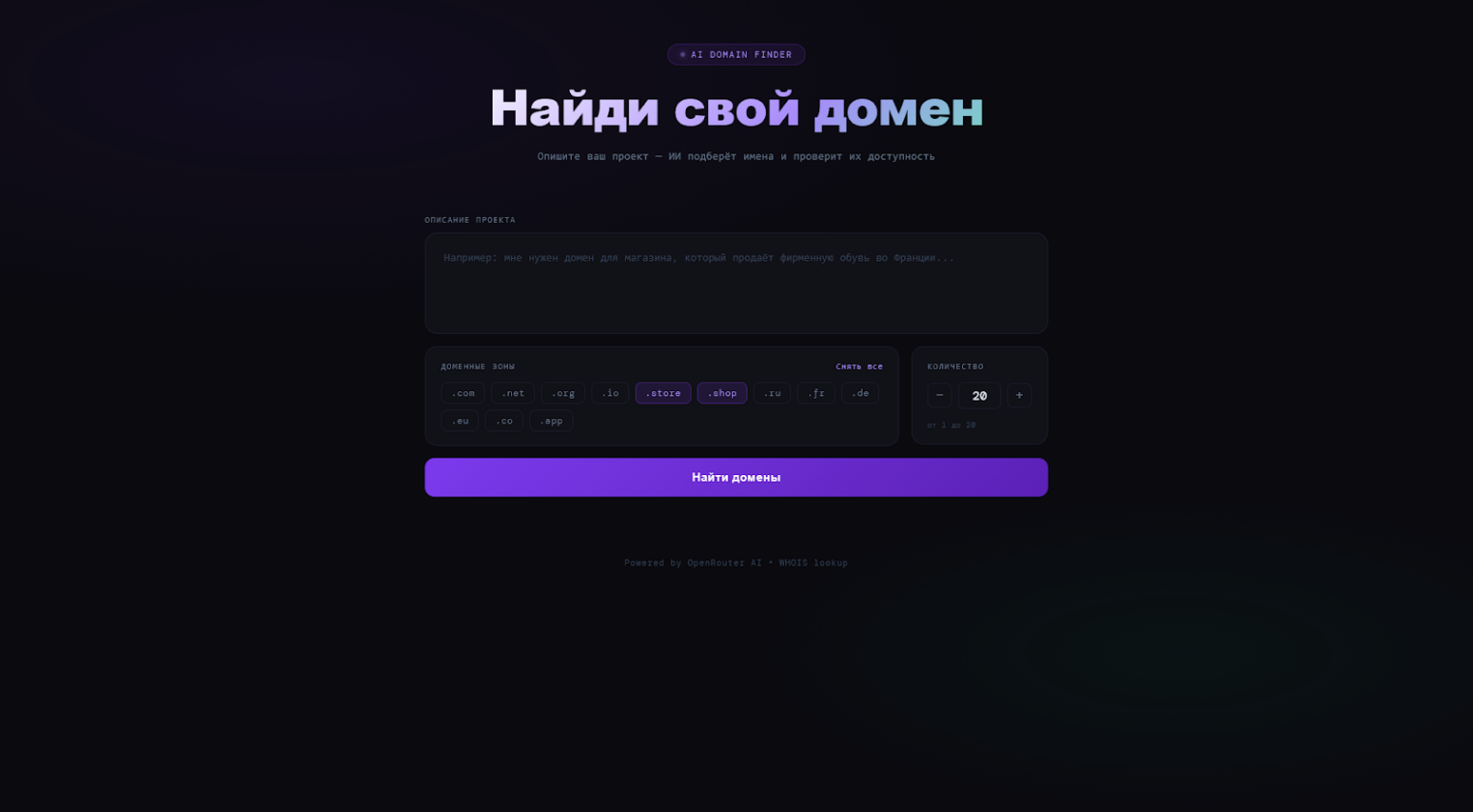
На странице есть поле для описания проекта, блок с чекбоксами для выбора предпочтительных доменных зон (например, .io, .tech, .ru), поле-счетчик, в котором указывается количество выходных результатов, и кнопка для запуска поиска.

Задаем входные значения и нажимаем кнопку Найти домены.
После этого запускается процесс генерации вариантов через LLM, проверка доступности и парсинг ответов WHOIS.

В конце мы получаем результат в виде списка из возможных вариантов, которые уже проверены на занятость и отмечены либо «Свободен», либо «Занят».
Входные данные: что передаем агенту
На вход агент принимает текстовое описание проекта или продукта, желаемые доменные зоны и их количество. Чем точнее описание, тем релевантнее результат: «сервис для автоматизации бухгалтерии малого бизнеса» даст значительно лучшие варианты, чем просто «финтех». Иначе получим стандартный набор с корнем pay или coin.
Проверка занятости через WHOIS
Когда модель генерирует пачку названий, скрипт проверяет их через WHOIS-запросы пулом по 10 потоков одновременно.
Логика простая:
- если в ответе есть запись о регистраторе или дата истечения — домен занят;
- если WHOIS вернул пустой ответ или статус AVAILABLE / NOT FOUND — домен свободен, можно брать.
В итоге вся рутина с копипастом в поиск регистратора исчезает: ты сразу видишь только то, что реально можно купить.
А теперь к примерам
Вот пара примеров того, что предлагает нам агент, и насколько это органично смотрится:
Тест 1:
Для первого теста я задал следующие параметры: описание — «Бизнес-коучинг в Москве», зоны — .com, .net, .org, .ru, а желаемое количество вариантов — 15.
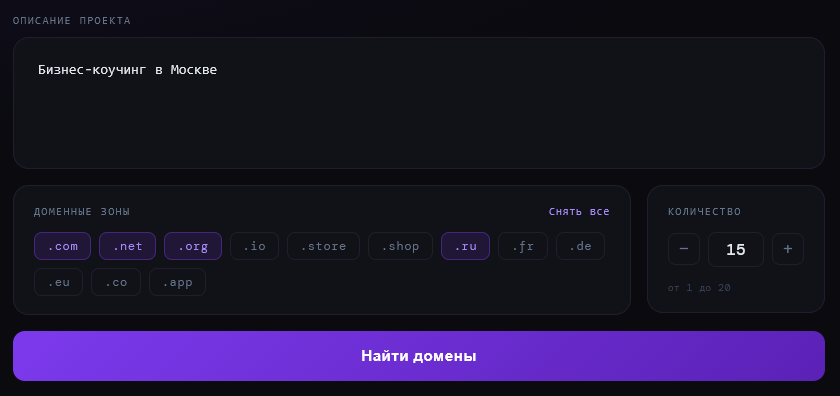
Результат:
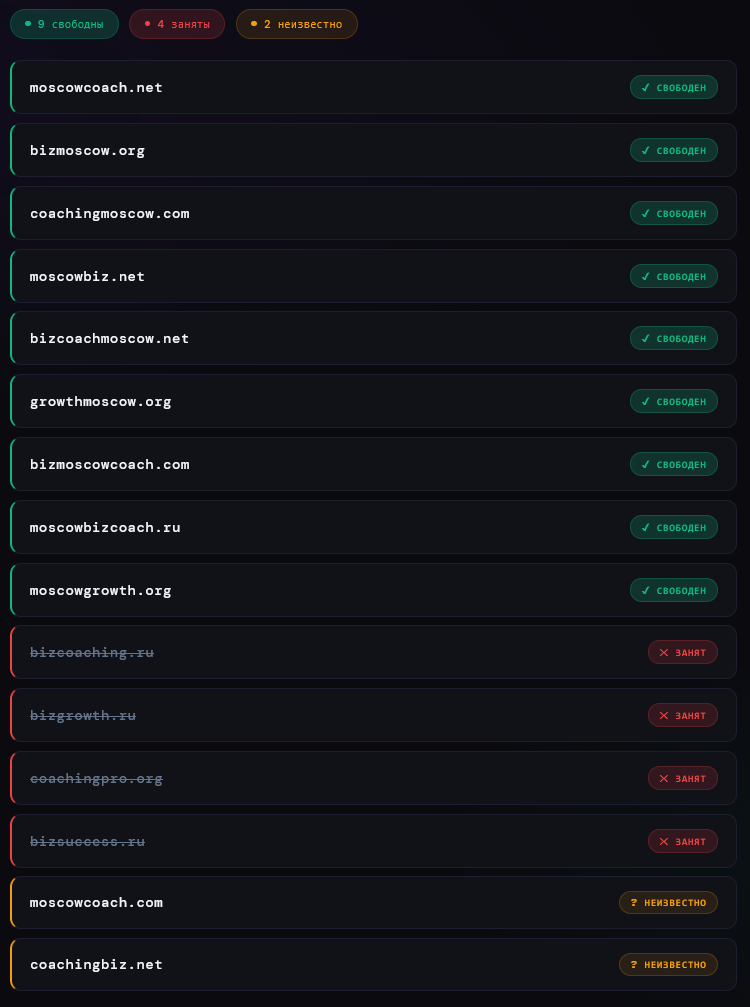
Есть свободный и лаконичный вариант — bizmoscow.org.
Тест 2:
Во втором случае я решил проверить более узкую нишу — «Магазин кофейной продукции в Саратове». В качестве целевых зон выбрал .store, .shop и .ru, ограничив выдачу 10 вариантами.
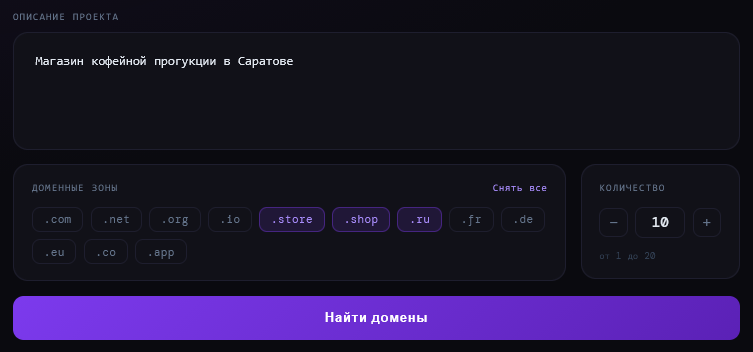
Результат:
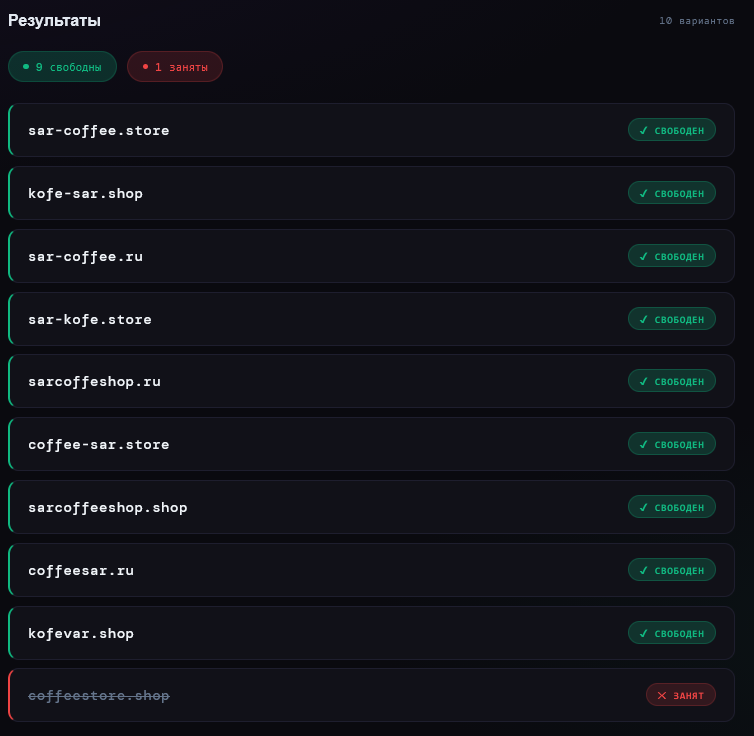
Тут тоже есть несколько хороших вариантов.
Заключение
В конечном итоге проект получился небольшим и узконаправленным, но со своей задачей справляется. LLM-агент хорошо подходит для генерации определенного количества вариантов, которые потом уже можно модернизировать и изменять по своему усмотрению или оставить как есть, а WHOIS-запросы закрывают вопрос доступности. Как пет-проект — это интересный опыт. Инструмент вполне неплох для конкретных задач, но явно требует определенных доработок и добавления более тонких настроек.
Полный код проекта можно посмотреть в моем профиле на GitHub.





