

Современные S3-хранилища давно перестали быть «черным ящиком»: от их архитектуры напрямую зависят отказоустойчивость, производительность и экономика сервисов, которые на них опираются. Но за внешне простым API скрывается интересная, сложная, промышленная система — от железа в стойках до многослойного распределенного приложения.
Меня зовут Александр Гришин, я руковожу направлением хранения и обработки данных в Selectel. Отвечаю за развитие облачных баз данных, S3-хранилища, аппаратных СХД и сервисов для построения DLH.
Материал будет полезен CTO, CIO и архитекторам, которые выбирают или проектируют собственное S3-совместимое хранилище. Или инженерам которые хотят просто лучше понимать, что же происходит у нашего сервиса под капотом.
Погнали!
Зачем вообще объектное хранилище
Данные хранят все: микросервисы и монолиты, стартапы и крупный энтерпрайз, разработчики и инженеры. Для решения этой задачи индустрия предлагает множество инструментов:
- блочные устройства — СХД по iSCSI или Fibre Channel,
- файловые хранилища с POSIX-семантикой,
- объектные хранилища,
- базы данных,
- ленточные библиотеки и другие решения.
При этом данных становится все больше. Согласно публичным аналитическим отчетам, их объем данных растет на 20-30% год к году, и основную часть этого роста в последнее время обеспечивают неструктурированные данные в объектных хранилищах. Только объектные хранилища способны легко и просто масштабироваться до колоссальных объемов — миллиарды объектов, сотни и тысячи петабайт, сотен тысяч RPS.
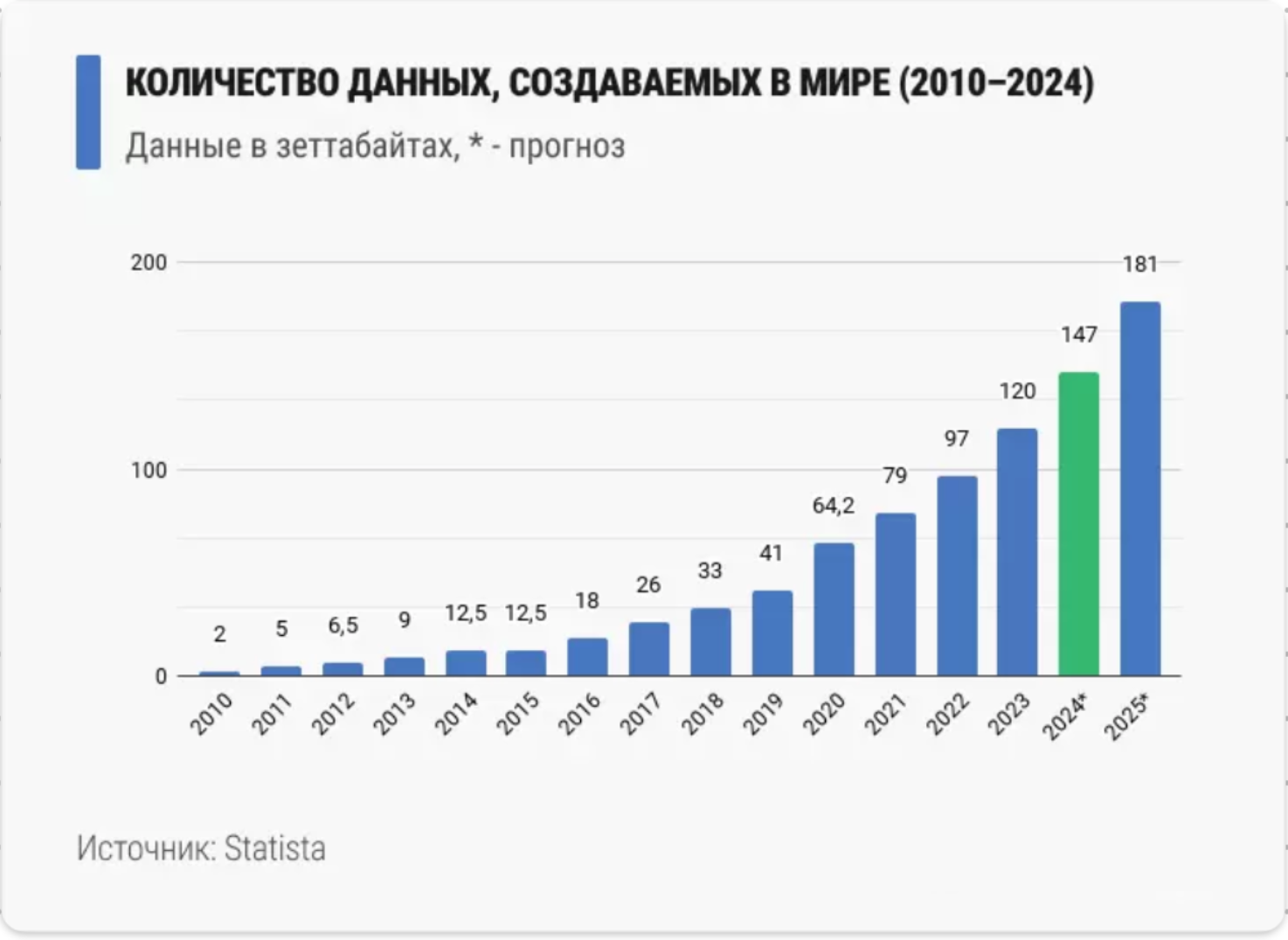
Как следствие консолидации расходов на огромных масштабах, рыночная стоимость хранения в S3 сейчас составляет 1−2 ₽ за ГБ/мес. Для сравнения: размещение данных на виртуальных машинах, например для СУБД, обойдется уже в 15−30 ₽ за ГБ/мес на аппаратных СХД в районе 6-12 ₽ за ГБ/мес.
Разумеется, компании быстро оценили преимущества Shared Storage и начали двигать индустрию в эту сторону. Netflix, AWS, Google — вот далеко не полный список ведущих контрибьюторов OpenSource‑проектов, обеспечивающих технологический переход от shared-nothing к shared-storage архитектуре.
Подробнее об этом тренде можно почитать в моей статье «Нобелевская премия по экономике 2025: почему это важно для рынка IT».
Разбираем термин по словам
Мы в Selectel не случайно используем термин «объектное облачное S3‑хранилище»: каждое слово в этом названии несет конкретный технический смысл.
Объектное
«Объектное» — это способ работы с данными. В отличие от блочных устройств, здесь нет побайтовой адресации и концепции offset. Если сравнивать с файловыми хранилищами, то нет файловой системы, привычной иерархии папок и поддержки POSIX-операций. Есть только объекты и доступ к ним по ключу.
То есть операции изменения не существует. Допускается только полное удаление и перезапись объекта целиком, даже если во всем гигабайтном объекте поменялись всего два байта. Это свойство позволяет масштабироваться до пределов, недоступных классическим файловым хранилищам.
Мой коллега подробно разобрал этот тип хранения в статье «Как работают объектные хранилища: объясняем на практике и собственных шишках».

Облачное
«Облачное» — значит доступное из любой точки мира через обычный интернет. Не нужно монтировать диск, настраивать специальный протокол или выделенную сеть. Если у вас есть интернет, то и доступ к хранилищу тоже есть.
Да, подключиться к хранилищу можно и через приватную сеть, без доступа в интернет. Однако это нетипичный способ использования S3, и о нем я подробнее расскажу ниже.
S3
Возможно, вы удивитесь, но S3 — термин не про само хранение. Он описывает интерфейс доступа к данным: протокол с методами GET, PUT, DELETE, HEAD и LIST. Его разработала компания Amazon примерно в 2006−2007 году, и с тех пор он стал общемировым стандартом.
Главная ценность S3 — унификация. Любой код, написанный для работы с Amazon S3, будет взаимодействовать с хранилищем Selectel и любым другим S3‑совместимым провайдером не требуя доработки. Благодаря такой унификации экосистема инструментов, которые поддерживают протокол S3, столь огромна: от rclone и aws-cli до Apache Spark, Trino, ClickHouse и почти любого современного аналитического движка.
Как мы строим S3‑хранилище
Требования
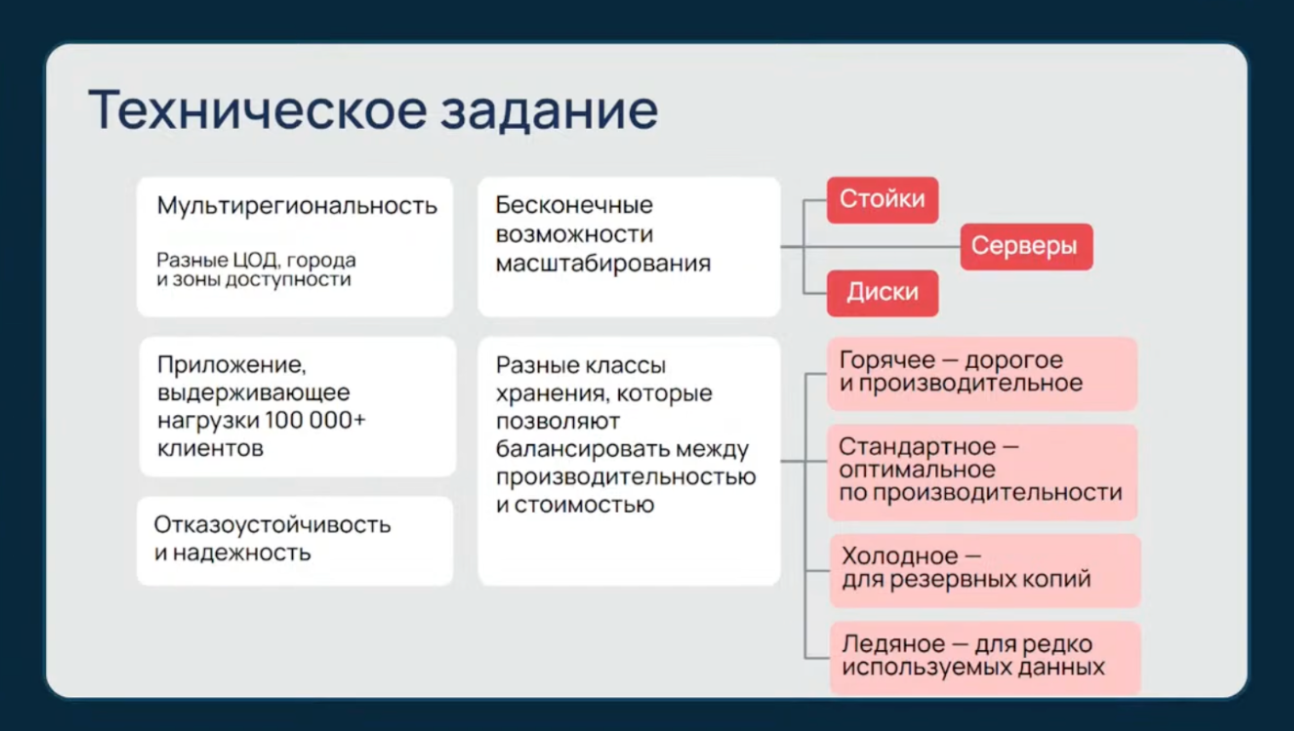
Прежде чем строить, надо определить желаемый результат. Обычно для промышленного S3-хранилища индустрия ожидает:
- мультирегиональность — минимум три независимые площадки (меньше трех — это уже не хранилище, а погребок);
- масштабируемость — практически бесконечная емкость без ограничений;
- готовность к высоким нагрузкам — способность одновременно обслуживать от тысяч до миллионов клиентов;
- отказоустойчивость — все возможные домены отказа должны быть отработаны;
- разные классы хранения — от «горячего» до «ледяного» для оптимального баланса между производительностью и стоимостью.
Теперь посмотрим, как это реализовано у нас.
Регионы, зоны доступности, ЦОДы
Инфраструктура Selectel размещается в трех регионах: Санкт-Петербург, Москва и Новосибирск. Физически это шесть собственных и нескольких партнерских дата-центров, которые образуют шесть автономных зон доступности (AZ).
Перед выбором места для размещения данных рекомендуется внимательно изучить документацию.
В зависимости от региона и пула могут отличаться:
- тип исполнения — Multi-AZ (надежнее) или Single-AZ (быстрее);
- классы хранения — не во всех локациях представлен полный набор;
- уровни соответствия — согласно требованиям регламентирующих организаций.
Разберем на примерах. Пул «ru‑1» в регионе «Санкт-Петербург» размещается в группе ЦОД «Дубровка», объединяющей три отдельные площадки. Каждая из них оснащена автономными системами жизнеобеспечения:
- электропитание — включая аккумуляторы и резервные дизель-генераторные установки;
- сетевое оборудование — в том числе, оптико‑волоконные линии связи с резервированием данных;
- системы охлаждения и пожаротушения.
Существенно, что они не разнесены друг от друга географически, а находятся в непосредственной близости — так минимизируется задержка сигнала. Согласно нашей спецификации, «ru-1» — это Single-AZ инсталляция S3 в одной зоне доступности.

В Москве несколько пулов «ru-7», «gis-1» (группа ЦОД Берзарина) также имеют Single-AZ тип исполнения так как находятся в пределах одной зоны доступности. При этом «gis-1» — это специальный изолированный пул для государственных информационных систем, соответствующий требованиям 21‑го и 17‑го приказов ФСТЭК.
Также в столице представлен S3 в Multi-AZ типе исполнения — новый пул «ru-6». Он «из коробки» распределен между тремя зонами доступности и отрабатывает домен отказа AZ.
Три независимые зоны доступности расположены в Москве. Расстояние между образующими их дата-центрами составляет 10−15 км.
Мы строим услугу так, чтобы выход из строя одного ЦОД целиком оставался незаметным для клиентов на уровне S3. Да, иногда приходится сознательно добавлять избыточность. Мы храним самое ценное — данные, — и такой подход полностью оправдан.

Что внутри стойки
Типовая стартовая инсталляция нашего хранилища — это шесть стоек: три под Control Plane и три под Data Plane. Масштабируемся мы постоечно. Каждая стойка функционирует независимо и оснащена собственным сетевым и электрооборудованием, а внутри дата-центра они размещаются в разных автономных сегментах. Выход из строя определенного количества стоек никак не влияет на наших клиентов.
В одной стойке находится примерно 12 серверов. В среднем для поддержания работы облачного хранилища в одном регионе задействовано около 120 стоек и более 1 000 серверов.
Точные характеристики платформ мы не раскрываем. Однако типичный узел хранения — это определенное количество ядер CPU (чаще всего Intel Gold 6336Y, но сейчас мы активно тестируем платформы на AMD), достаточный объем оперативной памяти, четыре NVMe-накопителя под систему и метаданные, а также 60 дисков непосредственно под сами данные. Мы любим железо и отлично в нем разбираемся, поэтому уверены в оптимальности конфигураций, подобранных для нашего S3.
Чуть подробнее о концептуальных проблемах при подборе железа для хранения данных я рассказывал в статье «Memory wall: что это и почему важно для индустрии хранения данных».

Сейчас мы используем более 100 000 дисков одновременно в сочетании HDD и NVMe-накопителей — они отличаются по производительности, объему, назначению и, главное, по себестоимости хранения каждого байта.
Про классы хранения
Данные в нашей системе размещаются в Ceph — распределенной системе хранения на базе обычных серверов.
Подробно останавливаться на ней не буду, лучше сошлюсь на отличную статью коллеги «Ceph: разбираем базовые операции в кластере на примере интеграции с Hashicorp Nomad». Если объяснять совсем просто: технологию можно сравнить с RAID-массивом, только распределенным по сети. Мы работаем с Ceph с 2015 года и являемся контрибьюторами проекта.
Здесь важно упомянуть ключевой для этой статьи параметр — CRUSH Rules, политику защиты данных. Существует несколько ее видов, каждый из которых имеет свои плюсы и минусы. Разберем основные.
Репликация (×2, х3, и тд)
Такой вариант чем‑то похож на распределенный по сети RAID 1. Мы используем репликацию х3: исходный объект разбивается на чанки, и каждый из них дублируется трижды. Полученные копии распределяются по разным дискам, серверам и стойкам.
Плюсы: алгоритм предельно простой, легкая процедура восстановления, высокая производительность на запись, предсказуемое поведение.
Минусы: оборудования нужно втрое больше.

Erasure Coding
Простая аналогия — распределенный по сети RAID 6. Объект разбивается на рабочие фрагменты, к которым добавляются контрольные. Этого достаточно, чтобы с помощью математических алгоритмов восстановить исходные данные, даже если часть оригинальных блоков окажется недоступна. Все полученные элементы распределяются по разным стойкам. EC, как и репликация, имеет разные конфигурации: 4+2, 8+2 и так далее.
Плюсы: оборудования нужно меньше, что особенно заметно на больших объемах данных.
Минусы: существенно усложняется эксплуатация.

Вывод: комбинируя тип накопителя (HDD или SSD NVMe), политику защиты данных, мы формируем необходимое количество классов хранения. Именно так появляются «горячее», «стандартное», «холодное» и «ледяное» хранилища. Для каждого из них подбираются оптимальные диски и настройки, чтобы сбалансировать производительность и стоимость.
Важная деталь: в нашей инфраструктуре работает далеко не один кластер Ceph. Под каждый класс выделяется отдельная инсталляция, причем даже в рамках одной категории их может быть несколько. Это позволяет при необходимости полностью исключать конкретный сегмент из процессов записи для технического обслуживания, перенаправляя новые данные на соседние. Кроме того, мы можем мигрировать информацию между кластерами для аппаратного апгрейда — абсолютно незаметно для пользователей, без даунтаймов.
Программная архитектура: layered design
Большинство компонентов системы мы разработали самостоятельно. В основном пишем на Go, но для нескольких чувствительных к производительности микросервисов выбрали Rust и C++.
В основе нашей архитектуры лежит подход Layered Design. Сложная система разбивается на независимые уровни, каждый из которых отвечает за свою часть логики и взаимодействует с соседними через API. При этом под каждый такой слой и отдельный компонент выделяется собственное оборудование.

Уровень 1 — Data Layer (фундамент)
Это основа всей системы. Она включает два компонента.
1. Ceph — о нем мы уже говорили выше: этот слой отвечает за физическое размещение данных на серверных дисках.
2. Object Storage Service (OSS) — отвечает за метаданные: содержит информацию о клиентах, проектах, бакетах и объектах. OSS обрабатывает операции создания и удаления, а также обеспечивает согласованность действий между уровнями S3 и Ceph.
В качестве базы данных для этого сервиса мы используем шардированные кластеры PostgreSQL c роутером запросов на базе pg_fdw. Наше решение позволяет масштабировать клиентскую нагрузку в разных бакетах, префиксах, папках на разное железо. Благодаря чему мы можем добиваться сотен тысяч RPS на уровне S3. К слову, если в комментариях будет интерес, в будущем мы подробнее расскажем об этом ноу-хау.
Data Layer отвечает за масштабируемость и отказоустойчивость всей платформы. Сейчас мы обслуживаем сотни петабайт клиентских данных в публичном хранилище и, учитывая текущие темпы роста, скоро перешагнем рубеж в тысячу.
На этом же уровне реализована мультитенантность: мы распределяем нагрузку от различных проектов, бакетов и даже их внутренних префиксов по независимым физическим устройствам. Это позволяет успешно «расшивать» узкие места серверных платформ и их комплектующих.
Уровень 2 — API Layer
S3 API — это наша собственная реализация одноименного протокола. Она обеспечивает совместимость с тем самым прикладным кодом, который уже работает с любым S3-совместимым хранилищем в мире.
На этом уровне мы отказались от решений open source, поэтому полностью контролируем развитие компонента. Это позволяет нам гарантировать главную ценность продукта — надежный интерфейс доступа к данным.
О наших разработках в этом направлении мы регулярно рассказываем в блоге. Сегодня хочу подсветить два обновления, подробно разобранных моим коллегой:
Selectel Storage API — это наш собственный интерфейс рядом с S3-протоколом. Он реализует дополнительную бизнес-логику, не нарушая спецификацию Amazon: работу с клиентскими доменами, поддержку SSL-сертификатов, мониторинг, настройку политик доступа и интеграцию с панелью управления.
Важный нюанс: стандарт S3 нельзя изменить — он глобально унифицирован. Однако специфическую функциональность — работу с логами, мониторинг, кастомные домены — нужно было где-то реализовать, не нарушая обратную совместимость. Для этого и существует SS API.
Важное ноу-хау нашей реализации S3-хранилища — это мультирегиональность (не путать с характеристикой Multi-AZ). Она дает возможность создавать бакеты и хранить данные в разных регионах в соответствии со спецификацией Amazon S3.
Таким образом, мы поддерживаем глобальный S3-эндпоинт (s3.storage.selcloud.ru) для работы, а также набор региональных S3-эндпоинтов для прямого обращения к конкретным сегментам:
- s3.ru-1.storage.selcloud.ru — для Single-AZ пула «ru‑1» в Дубровке (Ленинградская область),
- s3.ru-3.storage.selcloud.ru — для Single-AZ пула «ru‑3» в Санкт-Петербурге,
- s3.ru-7.storage.selcloud.ru — для Single-AZ пула «ru‑7» в Москве,
- s3.gis-1.storage.selcloud.ru — для Single-AZ пула «gis‑1» в Москве (аттестован согласно 17‑му приказу ФСТЭК),
- s3.ru-6.storage.selcloud.ru — для Multi-AZ пула «ru‑6» в Москве.
Мы предоставляем пользователям важную возможность — управлять размещением своих данных. Это необходимо, когда вычисления происходят в конкретном пуле или ЦОДе и расстояние становится существенным. Другой популярный сценарий — настройка disaster recovery между разными площадками или городами.

Уровень 3 — Proxy Layer
Это точка входа для всех клиентских запросов, состоит из двух компонентов.
Public Proxy — отдельный слой физических серверов. Он принимает весь публичный трафик, балансирует нагрузку, кэширует данные, защищает от DoS-атак и обеспечивает сетевую связность.
Private Proxy — выполняет те же функции, но работает изолированно для конкретного клиента. Применяется в случаях, когда заказчик не хочет передавать трафик через публичный интернет. Этот прокси обрабатывает запросы только из приватных пользовательских сетей и подключается через Direct Connect или глобальный роутер Selectel.
Именно наличие Private Proxy позволяет нам создавать выделенные хранилища для крупных клиентов, организуя прямой оптический канал непосредственно до их инфраструктуры.

Такие хранилища, хотя физически и располагаются в нашем ЦОД, технически являются частью инфраструктуры заказчика: под них отводятся выделенные стойки, серверы и сетевое оборудование.
Подобная инсталляция S3 полностью изолирована от любой другой инфраструктуры, и использует прямой канал связи до дата-центра клиента. Такая архитектура позволяет соблюдать строгие внутренние регламенты организаций (вплоть до ГОСТ 57580 и др) и безопасно размещать чувствительные данные на базе нашего S3.
Два реальных кейса: горячее и холодное хранилище
Архитектуру лучше всего рассматривать на живых примерах. Приведу два совершенно разных кейса, в рамках которых мы развернули приватные хранилища под задачи конкретных заказчиков.
Кейс 1: видеохостинг и холодное хранилище на 120 ПБ
Задача: организовать хранение огромных объемов видеоконтента максимально экономично.
Первичное ТЗ от заказчика:
- регион — Москва;
- объем: на старте — 40 ПБ, планируемый рост до 120 ПБ в течение первого года;
- производительность — до 40 000 RPS, пропускная способность — до 100 Гбит/с;
- архитектура — Multi-AZ (три автономные зоны доступности);
- бизнес-требования — минимальная стоимость хранения гигабайта, приоритет надежности над производительностью.
Архитектурное решение: большой объем данных при невысокой нагрузке на диски — это идеальный сценарий для использования HDD в связке с алгоритмом Erasure Coding. Соотношение стоимости и емкости в таком варианте оптимально. Под проект была развернута выделенная инсталляция: отдельные стойки, серверное и сетевое оборудование предназначены исключительно для этого заказчика.

Результат:
- нагрузка — стабильно держится на уровне ~60 Гбит/с, в пиках достигает 70 Гбит/с. Следовательно, у системы остается хороший запас по производительности.
- масштабирование — объем клиентских данных вырос с 8 до 26 ПБ всего за полтора месяца. Если разделить этот прирост на время, получатся те самые стабильные 70 Гбит/с.
- срок реализации проекта — два месяца.
Кейс 2: Data Lakehouse и горячее хранилище на 1 ПБ
Задача: построить корпоративное озеро данных на базе Redash, Trino, Iceberg, Airflow и Spark.
Первичное ТЗ от заказчика:
- регион — Москва;
- объем — до 1 ПБ, рост в ближайшее время не предполагается;
- архитектура — Single-AZ (однозональная инсталляция);
- производительность — на старте до 200 000 RPS и пропускная способность до 200 Гбит/с, с возможностью дальнейшего кратного масштабирования;
- бизнес-требования — максимальная производительность без ограничений по бюджету; бизнес-процессы, базирующиеся на дата-платформе, должны работать без задержек.
Архитектурное решение: для столь небольшого объема данных при довольно высокой нагрузке мы решили использовать NVMe-накопители, а в качестве алгоритма защиты данных — трехкратную репликацию (RFx3). Тесты профиля нагрузки заказчика показали, что Erasure Coding в данном случае не подходит. Причина — более медленные операции записи и чтения файлов Parquet с метаданными Iceberg при таком паттерне запросов.
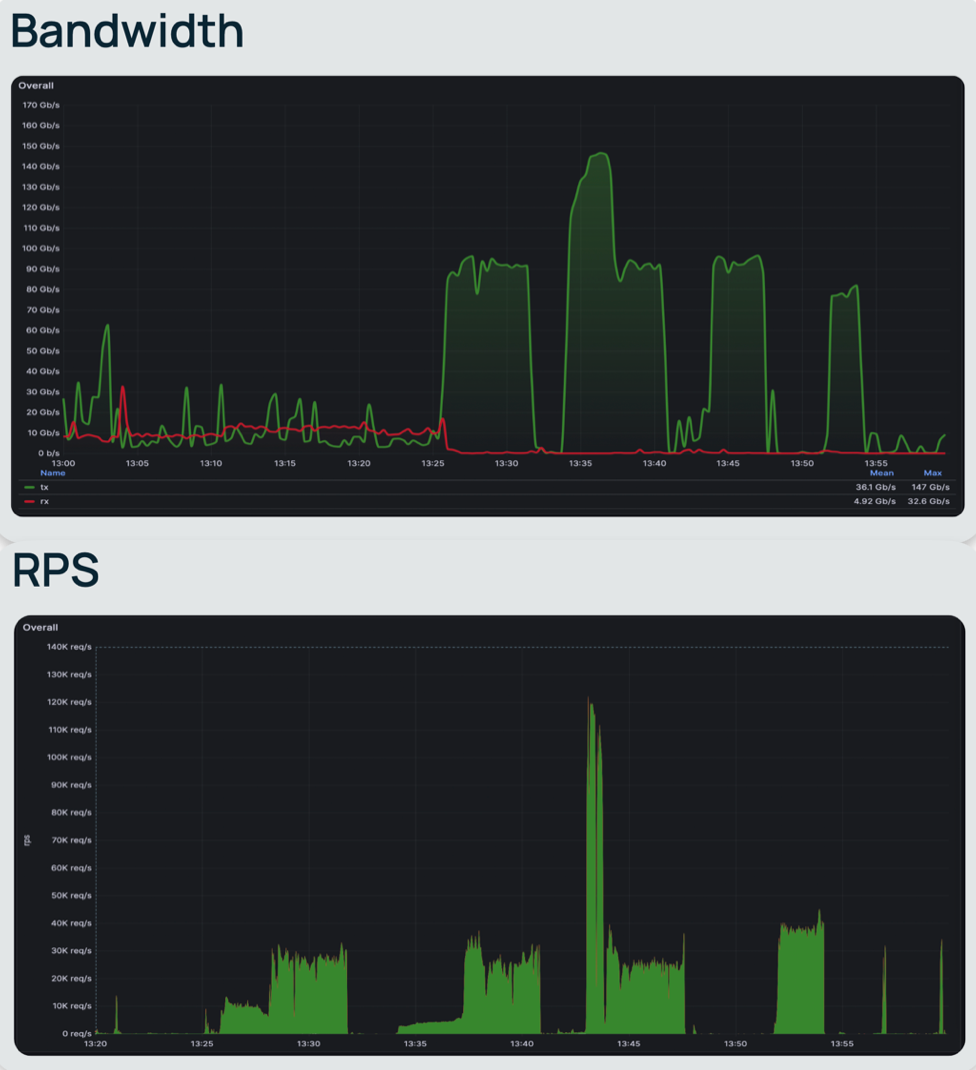
Пики до 150 Гбит/с на графике — это моменты, когда движок Trino массово вычитывает файлы Parquet. Именно поэтому для этого проекта мы выбрали NVMe-накопители.
Результаты в продакшене:
- нагрузка — интервальная (считаем, что движок Trino именно так и работает — пачками), в пиках достигает 150 Гбит/с и 120 000 RPS;
- масштабирование — развернуто Single-AZ хранилище с возможностью дальнейшего увеличения производительности до 200 000 RPS, 200 Гбит/с и выше;
- срок реализации проекта — 1,5 месяца.
Что еще важно знать
Роль S3 в ML
Объектное хранилище в машинном обучении — стандартная практика. Объектное хранилище в ML-стеке закрывает сразу несколько ролей.
- Хранение сырых данных для обучения — таких как, документы, видео, логи и любая другая неструктурированная информация. Их нужно где‑то разместить до тренировки модели, и S3 с этим отлично справляется.
- Размещение векторных данных и эмбеддингов для RAG-систем. Большие массивы векторов при хорошем соотношении стоимости и объема — это именно S3.
- Сохранение промежуточных артефактов — чекпоинтов, снапшотов, частичных результатов обучения.
- Инференс в продакшне — сами веса моделей, словари, конфигурации размещаются в S3 и загружается при старте сервиса.
- Доставка сгенерированного контента до пользователя — S3 отлично подходит не только для хранения, но и для раздачи результатов работы LLM, таких как текстовые документы, PDF, графики, презентации и тому подобное.
Для заказчиков, работающих с Big Data, AI/ML и GPU-нагрузками, важно, чтобы данные были не только надежно сохранены, но и располагались максимально близко к вычислительным ресурсам. Именно поэтому в нашей инфраструктуре S3 и вычислительные сервисы — Managed Kubernetes, DAVM, GPU-серверы — разворачиваются в одних и тех же регионах. Кстати, исходящий трафик из S3-хранилища к другим сервисам внутри Selectel совершенно бесплатен.
Мультирегиональность и георезервирование
Резервирование в пределах одного региона — это несколько ЦОД внутри одной группы. Эта задача уже решена на уровне нашей инфраструктуры. Например, пул «ru‑1» охватывает три независимых дата-центра «Дубровка» — выход из строя любого из них останется незаметным для пользователей S3. Пул ru-6 — это три независимых московских дата-центра в исполнении Multi-AZ, разнесенных на 10–15 км друг от друга.
Если рассматривать географически распределенное резервирование как удаленные друг от друга регионы, например Москва и Санкт-Петербург, то тут организация асинхронной репликации данных между регионами ложится на плечи заказчика. Но сделать это несложно: любой S3-совместимый инструмент — будь то rclone, AWS CLI или аналоги — позволяет настроить асинхронную синхронизацию парой команд в CLI. Достаточно просто создать бакеты в нужных регионах.
Выделенное S3-хранилище: когда публичного облака недостаточно
Публичное облако — это правильный старт для большинства задач. Однако есть сценарии, где нужен другой подход. Причины чаще всего следующие:
- строгие требования к безопасности и изоляции данных — например, в финансовом секторе, медицине или государственных структурах;
- очень большие объемы данных, когда собственная инсталляция экономически выгоднее;
- нестандартные требования к производительности, классам хранения или топологии сети.
В таких случаях кластер развертывается в наших дата-центрах и обслуживает исключительно данные одного клиента. При необходимости можно объединить выделенное S3‑хранилище с внешним ЦОД или другими сервисами через Direct Connect или L3 VPN.
Если ваша задача выглядит похожей — приходите, проработаем архитектуру под ваш профиль нагрузки.
Измеряете ли вы производительность в IOPS?
Нет, и это правильно. IOPS — метрика для дисковой подсистемы, а производительность S3-хранилища корректнее измерять в RPS (запросах в секунду) и пропускной способности (Гбит/с). Нагрузку можно масштабировать на любое количество дисков и серверов, поэтому IOPS конкретного диска — не та цифра, на которую стоит ориентироваться при выборе хранилища.
Насколько Ceph надежен?
Проблемы с Ceph, о которых говорят в сообществе, обычно связаны с неправильной эксплуатацией. Причины могут быть самые разные:
- была неверно выбрана политика защиты данных,
- сэкономили на железе,
- несвоевременно реагировали на алерты,
- провели неудачный апгрейд самого Ceph.
Мы используем только стабильные версии и обновляем ПО согласно нашей стратегии апгрейдов. Такая политика гарантирует достаточную испытанность версии сообществом — а это не меньше, чем полгода..
Кстати, наши инженеры — контрибьюторы проекта Ceph. Мы тоже участвуем в его развитии.
SLA
SLA на доступность — 99,95%. SLA на возмещение — 100%. Согласно нашему пользовательскому соглашению мы возмещаем ущерб при недоступности данных по любой причине. Мы считаем что RTО у нас максимально близко к нулю — ведь наша архитектура специально проектируется так, чтобы выход из строя любого элемента был незаметен для клиента.
Как устроена оплата?
Четыре составляющих, по потреблению:
- хранение (₽/ГБ·месяц),
- исходящий трафик за пределы инфраструктуры Selectel,
- GET-запросы (чтение),
- PUT-запросы (запись).
Входящий трафик — бесплатно. Трафик между сервисами внутри Selectel — бесплатно.
Рассказывать о нашем S3‑хранилище можно очень долго — архитектура живет и развивается уже больше 12 лет. Лучший способ понять ее — протестировать ее на практике. Для тех, кто еще не пользовался нашим сервисом, действует тестовый период — 30 дней бесплатного хранения без ограничений по объему.




