

Меня зовут Витя, я проектирую интерфейсы в Selectel. Недавно мы запустили новую функциональность — выделенные ядра для облачных серверов. Чтобы понять, как спроектировать интерфейс управления новой фичей, я решил погрузиться в матчасть: от работы планировщика Linux до архитектуры NUMA-нод.
В тексте разберем, чем физические ядра отличаются от vCPU, как Hyper-Threading влияет на производительность и почему «шумные соседи» — измеряемая потеря денег.
Основные понятия
Представим: нам нужно запустить приложение на облачном сервере. Например, вы решили развернуть базу данных под высокий трафик или запустить микросервис для обработки видео. В зависимости от особенностей приложения и нагрузки подбирается нужная конфигурация: количество ядер, оперативной памяти, объем диска для хранения данных. Вот тут мы и встречаемся с понятием vCPU.
vCPU (Virtual Central Processing Unit) — виртуальное ядро процессора, выделяемое гипервизором. Оно представляет собой долю вычислительной мощности физического ядра (Core) или один поток в физическом процессоре (CPU), обеспечивая работу операционной системы.
Как физический процессор превращается в vCPU
В основе сервера лежит CPU — физический чип, который вставляется в разъем на материнской плате. В современных серверах таких процессоров обычно два, и каждый из них внутри нарезан на независимые ядра.
Если у процессора два ядра, он может выполнять две инструкции параллельно, если четыре — четыре и так далее. Это и есть настоящая многоядерная система (Multi-Core), где задачи не мешают друг другу физически.
Но на уровне операционной системы все выглядит чуть сложнее из-за технологий вроде Hyper-threading (или SMT). Она позволяет одному физическому ядру обрабатывать сразу два потока команд. Для ОС (например, Linux) это выглядит не как два полноценных ядра, а скорее как два «входа» в один конвейер.
Такие логические ядра, которые делят между собой ресурсы одного физического, называются сиблингами (siblings). Они вместе используют общие блоки процессора и, что важнее всего, общие кэши L1 и L2.
В обычном облаке ваш vCPU — это как раз один такой поток-сиблинг. Когда мы говорим о выделенных ядрах, мы просто забираем физическое ядро целиком, не деля его ресурсы и кэши с «соседями».
Типичный сервер (хост) — это многопроцессорная многоядерная система. В ней два и более процессорных сокета, каждый из которых, например, по 24 ядра с поддержкой гиперпоточности.

Операционная система в такой системе увидит 96 vCPU (2 сокета × 24 ядра × 2 гиперпотока), если включена опция гиперпоточности (HT или SMT). Если ее выключить — будет 48 vCPU. Соответственно, гипервизору доступно 96 vCPU, которые можно распределить между виртуальными серверами на данном хосте. Гиперпоточностью можно управлять, включая или отключая ее на ядре.
Управление процессами в гипервизоре
В гипервизоре есть планировщик, который управляет процессами, выполняемыми vCPU.
Предположим, у нас есть рассмотренная система с двумя процессорами (CPU), и на ней выполняется несколько типичных процессов: работа оболочки, несколько ресурсоемких рабочих задач с интенсивными вычислениями.
При использовании обычного алгоритма планирования любой из этих процессов может быть размещен на любом из доступных процессоров. По мере завершения работы или перепланирования задач эти процессы могут перемещаться с одного процессора на другой так, как сочтет нужным планировщик.
Звучит прекрасно — всеми процессами занимается планировщик, но давайте представим, что задач с интенсивными вычислениями становится больше. Если позволить планировщику размещать их на любых доступных CPU, это может привести к полной загрузке системы. Технически, она может работать «в полку» и без перепланировки, но основная проблема здесь именно в росте latency и jitter производительности из-за постоянных переездов процессов между ядрами.

В сценариях, когда необходима гарантированная производительность, можно выделить определенные vCPU под задачи, чтобы в дальнейшем планировщик не менял их.

Офис как аналогия процессору
Описанные проблемы со снижением продуктивности при выполнении сложных задач можно представить в виде аналогии из реальной жизни. Если поискать преимущества выделенных ядер, то, скорее всего, вы встретите упоминание, что они решают проблему «шумных соседей» (это когда вы развернули ВМ в публичном облаке и делите с кем-то еще физическое железо; этот кто-то может создавать такие нагрузки, что будет в моменте влиять на производительность вашего сервера).
Мне же кажется, что более подходящей будет аналогия не с общежитием, а с офисом или коворкингом. Работа планировщика в обычном режиме похожа на опенспейс, где за сотрудником не закреплено фиксированное место.
В таком сценарии, если офис полупустой, планировщик рассадит сотрудников оптимальным образом и всем будет комфортно работать. Но каково работать в полностью заполненном опенспейсе? Гарантии комфорта обеспечить уже будет сложно.
А если выделить каждому сотруднику кабинет? В таком случае можно гарантировать комфортные условия и, в идеальном случае, отличную производительность каждого.
Помимо комфорта сотрудник получает еще и конфиденциальность, ведь он физически изолирован от других. Того же самого эффекта мы достигаем, выделяя ядра под определенные процессы: получаем гарантию производительности и изоляции.
Основные сценарии использования выделенных ядер
Учитывая проведенное тестирование и факт защиты инфраструктуры от известных уязвимостей на аппаратном уровне, можно сказать, выделенные ядра — это основа для продакшен-окружений, где важна стабильная и гарантированная производительность.
Это могут быть высоконагруженные и критичные к производительности системы, где требуется предсказуемая и стабильная работа vCPU без влияния других облачных серверов.
Мы рекомендуем переходить на выделенные ядра в следующих сценариях:
- Высоконагруженные базы данных (PostgreSQL, MySQL, ClickHouse). Когда сосед по хосту активно использует ресурсы общего кэша, время выполнения SQL-запросов растет. Выделенные ядра исключают конкуренцию за L1/L2 кэши.
- Ресурсоемкая аналитика и ML-модели. Задачи, которые нагружают vCPU на 100% в течение долгого времени. Здесь важна стабильная тактовая частота и отсутствие переключений контекста планировщиком.
- Сборка проектов (CI/CD). Выделенные ядра гарантируют, что время билда будет одинаковым вне зависимости от общей нагрузки на физическую ноду.
- Игровые серверы и приложения реального времени. В системах, чувствительных к задержкам (latency), даже микро-лаги при перемещении процесса между ядрами вызывают джиттер.
- API с жестким SLA. Если сервис должен отвечать за фиксированное время, нельзя делить ресурсы физического ядра с чужими процессами.
- Мониторинг и логирование. Обеспечение стабильной обработки потока событий при высокой частоте запросов.
Юридические лица и ИП, которые еще не пользовались услугами Selectel, могут получить грант до 30 000 бонусов на тестирование нашего облака. Подробности на сайте.
Настройка выделенных ядер
Воспользоваться выделенными ядрами можно при создании нового сервера. Для этого:
Заходим в панель управления Selectel → Продукты → Облачные серверы.

В разделе серверов кликаем на Создать сервер.

На странице создания сервера выберите локацию: ru-3b, ru-7a или ru-7b. Актуальную информацию о доступности по локациям можно узнать в документации.

Прокрутите страницу вниз до выбора конфигурации. В линейке Standard кликните на блок с описанием конфигурации. Далее откроется меню, которое позволит управлять настройкой выделенных ядер. Оставьте галочку отмеченной и Создайте сервер.

Доступность выделенных ядер в облачной платформе
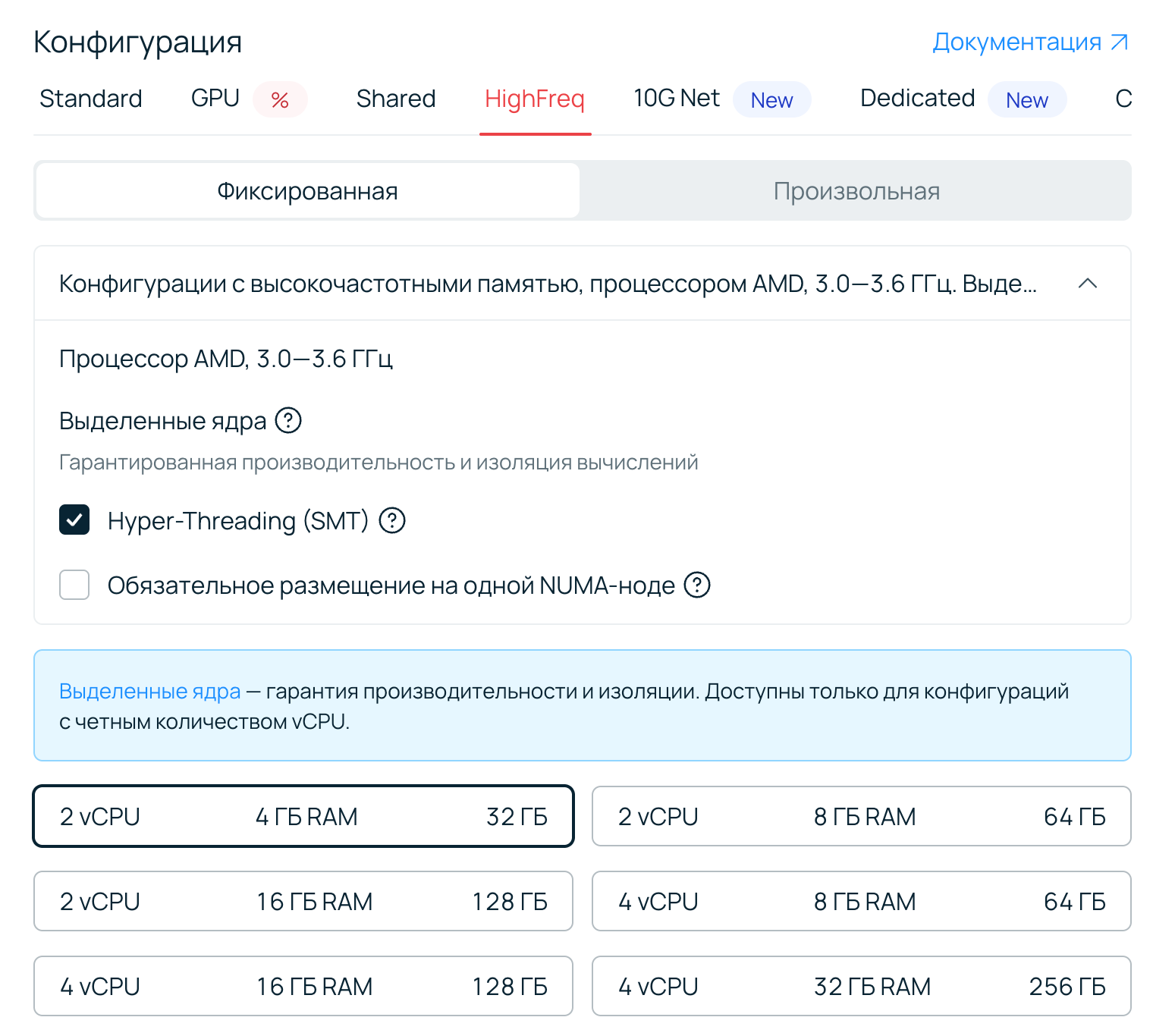
Выделенные ядра мы внедряем поэтапно. На текущий момент они доступны в нескольких регионах. Настроить их можно в линейках Standard и HighFreq. В зависимости от выбранного флейвора выделенные ядра могут быть включены по умолчанию.
В процессе конфигурации сервера из линейки Standard их можно выбрать опционально — так вы сможете самостоятельно протестировать, какой сетап будет производительнее для вашего софта.
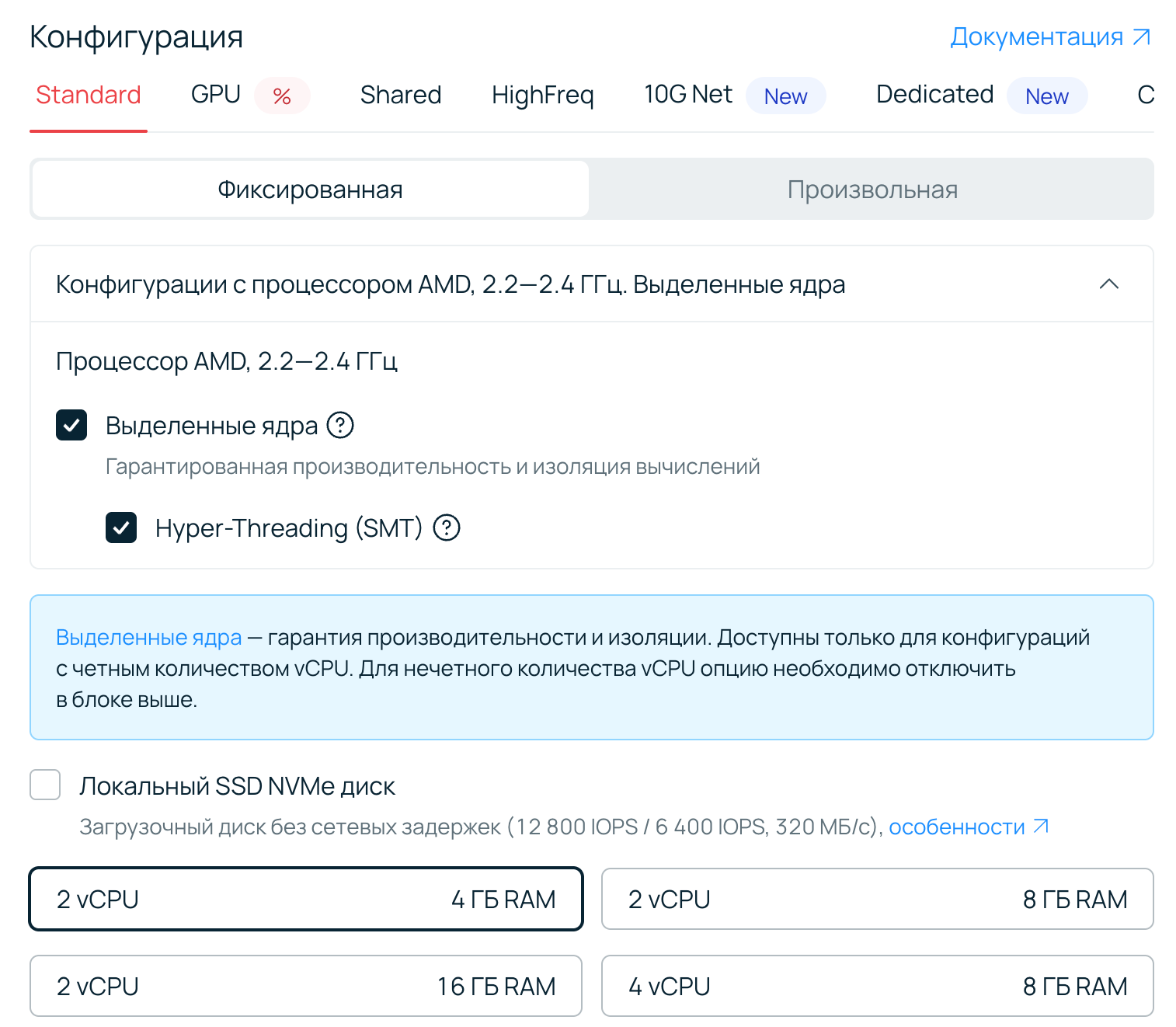
На выделенных или обычных ядрах можно работать в разных режимах: с включенной опцией гиперпоточности (Hyper-Threading (SMT)) или без нее.
Для конфигураций линейки HighFreq на высокочастотных процессорах выделенные ядра включены по умолчанию, и отключить их нельзя. Эта линейка ориентирована на базы данных, игровые серверы и другие задачи, требующие максимальной скорости отклика, поэтому здесь производительность гарантирована изначально.
Также доступна опция обязательного размещения на одной NUMA-ноде.
NUMA (Non-Uniform Memory Access) — это архитектура многопроцессорных систем, где система делится на ноды (блоки). NUMA-нода — это архитектурные блоки в многопроцессорных системах, где узел (node) включает один процессор и локальную оперативную память, доступ к которой у процессора внутри ноды быстрый и с низкой задержкой.
При размещении ресурсов на одной NUMA-ноде, облачный сервер работает только внутри ноды — использует ядра процессора и локальную память, которые привязаны к ноде. Это исключает задержки при обращении к «чужой» памяти через шину между процессорами.
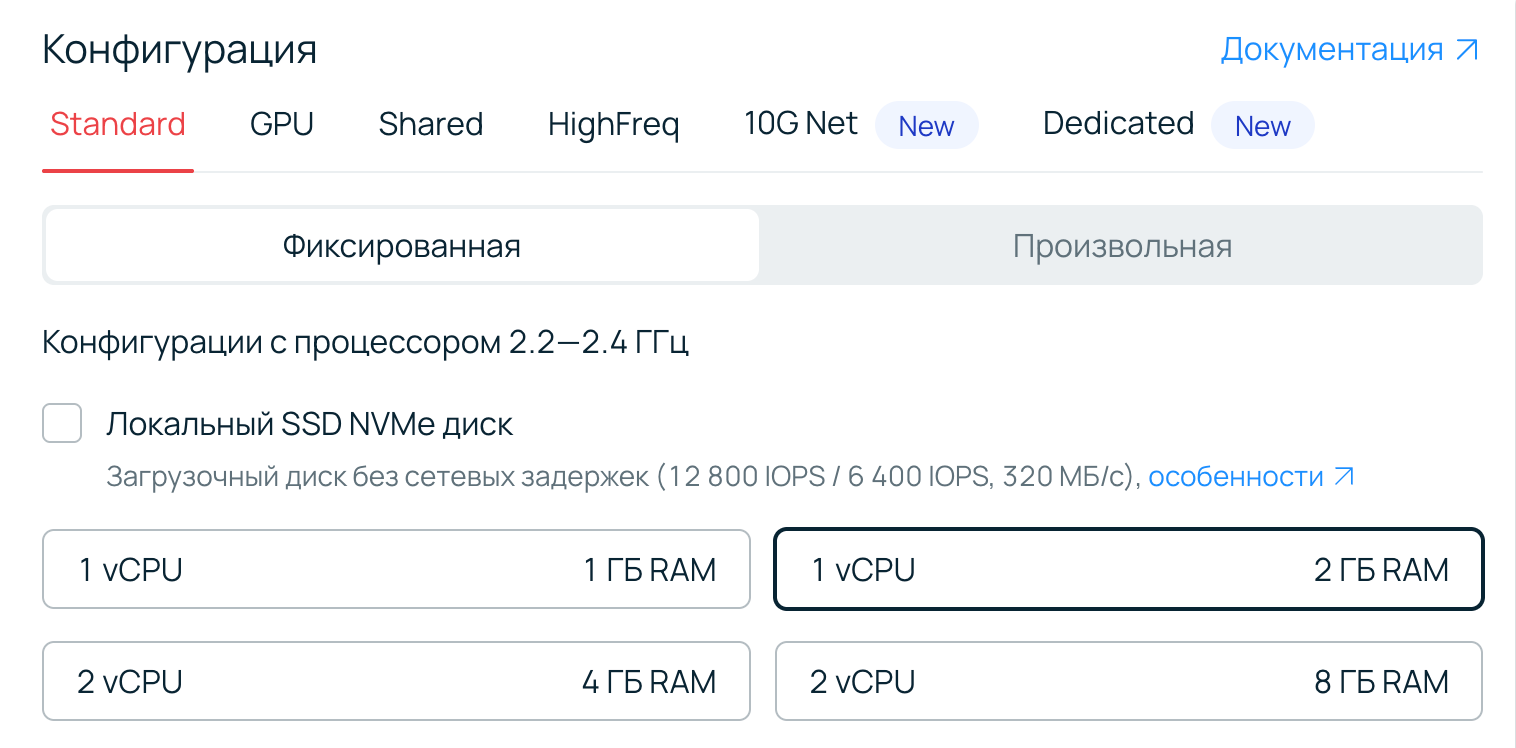
Если в регионе пока еще нет возможности использования выделенных ядер, то в интерфейсе вместо раскрывающегося блока будет отображаться описание конфигурации.
Тестирование
Предложение выделенных ядер клиентам уже встречается у глобальных провайдеров инфраструктуры. Перед реализацией такой же функциональности мы провели серию тестов, чтобы убедиться, что наши пользователи получат топовое решение, которое подойдет самым требовательным клиентам под самые сложные вычислительные задачи.
Чтобы описать весь процесс тестирования производительности в разных режимах — при обычной работе планировщика, на выделенных ядрах, а также в комбинациях с включенной или выключенной гиперпоточностью — потребуется отдельная статья. Поэтому здесь я перейду сразу к выводам.
Планировщик эффективно управляет процессами и распределяет их на свободные ядра, пока хост заполнен виртуальными машинами на половину или меньше. В таком случае производительность vCPU выше, так как планировщик оставляет соседние ядра свободными. Когда хост начинает заполняться больше, чем на половину, то процессы начинают выполняться и на соседних ядрах, из-за чего производительность падает.
Тесты на выделенных ядрах показали, что производительность всегда находится на одном уровне и не зависит от заполненности хоста. Учитывая, что для эффективной работы провайдеры стремятся заполнить хосты полностью, выделенные ядра действительно являются гарантированным решением для клиентов и обеспечивают одинаковый уровень производительности.
Также провели тестирование на производительность на RealTime-задачах обеих политик vCPU.
Для этого мы выбрали четыре инструмента:
- sysbench;
- Geekbench6;
- pgbench;
- redis-benchmark.
Sysbench
Выделенные ядра показывают постоянный результат в то время, как обычная политика имеет отклонения. Из-за подобных отклонений снижается общая производительность, в отличии от производительности выделенных ядер.

Geekbench6
Аналогичные результаты показало тестирование в GeekBench. Отклонение здесь меньше, но результат в итоге тот же — выделенные ядра дают прогнозируемую постоянную производительность.

Pgbench
Похожую картину показали результаты в Pgbench. Видно, что при высокой загрузке у обычных ядер возрастает Latency значительно выше, чем у выделенных, где этот эффект лишь немного заметен.

Latency — чем меньше, тем лучше.
Redis
- HD — высокая плотность I/O и CPU нагрузки на гипервизоре;
- LD — низкая плотность I/O и CPU нагрузки на гипервизоре.

Latency — чем меньше, тем лучше.
Отклонение от среднего в случае:
- с обычными ядрами — 43%;
- с выделенными ядрами — 12%.
RPS — при высоких нагрузках на гипервизоре мы достигли снижения производительности Redis в среднем на 36% из-за миграции памяти и vCPU.
На выделенных ядрах получали один и тот же RPS вне зависимости от нагрузки на гипервизоре.
Заключение
Добавление функциональности в виде выделенных ядер в облачной платформе Selectel дает то, чего часто не хватает в виртуальной среде: гарантированную производительность и защиту от уязвимостей на аппаратном уровне. При этом у вас остается гибкость облака — можно собрать именно тот конфиг, который нужен под конкретную задачу, не переплачивая лишнее.




