Как поднять платформу для анализа данных за вечер
Рассказываем, как подготовить облачное окружение и начать работу с Jupyter, Superset, PostgreSQL и другими инструментами.
Текущее состояние российского рынка аналитических и ML-решений сложно назвать стабильным. Какие-то инструменты более недоступны, а на их место регулярно приходят новые. Причем не только вендорские, но еще и open source, а также облачные сервисы.
Инструменты «из коробки» не всегда подходят для решения всех необходимых задач. Какие-то слишком сложны для базовой аналитики, другие стоят больших денег, третьи заточены под определенный тип данных или более узкие задачи.
Один из набирающих популярность вариантов — собрать собственное решение, можно сказать, небольшую платформу данных. Варианты могут быть разнообразные — от разработки софта до интеграции готовых open source-элементов. Касаться первого варианта сегодня бы не хотелось, а вот второй рассмотрим подробнее.
В статье рассказываем, как всего за час (или почти) подготовить облачное окружение, создать свою небольшую платформу для анализа данных и спарсить весь Hugging Face.
Набор джентельмена: инструменты для аналитики
Для начала давайте разберемся, какие инструменты нужны для базовых задач — простого исследования данных (EDA), построения наглядных визуализаций, регрессионного анализа, прогнозирования, классификации, кластеризации или обучения ML-моделей. Можно выделить следующий джентльменский набор:
- Jupyter, Zeppelin или DataSpell — среды разработки для DataScince- и ML-специалистов.
- Airflow, Prefect или Dagster — инструменты для построения пайплайнов обработки данных. Помогает регулярно запускать ETL-процессы и мониторить результаты их выполнения.
- Metabase, Power BI, Superset, Redash, Tableau или Qlik — компонент для визуализации данных и построения дашбордов.
- Базы данных PostgreSQL, Clickhouse или облачные DataWarehouse — неотъемлемая часть каждой платформы для анализа данных.
- Python и специализированные библиотеки — например, TensorFlow или PyTorch. Выбор зависит от вашей задачи.
И самое главное — вычислительные ресурсы, на базе которых можно развернуть все компоненты. Для создания полноценной платформы и организации совместной работы локальная машина не подойдет: часто задачи аналитика потребляют много ресурсов и времени. Особенно в случае, если нужно использовать мощности GPU. Поэтому для работы нашего проекта понадобится сервер — выделенный или облачный.
Выбор сервера
Выделенный сервер можно более гибко настроить, в том числе и на уровне железа. Ресурсы ни с кем делить не нужно — вычислительные мощности работают только на вас.
С другой стороны, если с выделенным сервером что-то случится, то восстановление всех компонентов может занять много времени. Облачные серверы же не привязаны к конкретному хосту и могут мигрировать, если тот выйдет из строя. Поэтому для небольших проектов это более предпочтительный вариант.
Однако нужно помнить, что для настройки всех компонентов понадобится навык работы с Docker или Linux, а также время, которое есть не всегда. Многие инструменты, упомянутые в начале статьи, — это решения с открытым исходным кодом, настройка которых может занять более одного вечера. Помимо этого, необходимо выбрать и правильно настроить веб-сервер (Nginx или Apache), на котором будут запущены нужные инструменты.
Чтобы сэкономить свое время и не разбираться с сотнями страниц документации, корректной настройкой Nginx и другими компонентами, можно арендовать DAVM (Data Analytics Virtual Machine) — виртуальный сервер с предустановленным набором инструментов для анализа данных и машинного обучения. Среди них — Jupyter Lab, Superset и Prefect.
DAVM быстро разворачивается и позволяет:
- строить процессы обработки данных (ETL/ELT) с помощью Prefect,
- разрабатывать ML-модели с помощью PyTorch, TensorFlow, Keras, XGBoost, OpenCV в интерактивной среде JupyterLab,
- визуализировать данные с помощью Apache Superset.
Все инструменты уже настроены и готовы к работе, поэтому экономить время удается на каждом этапе.
Парсинг и обработка данных
С набором инструментов определились, сервер выбрали. Осталось подготовить облачное окружение и написать «базовый шаблон» нашей платформы для анализа данных.
Подготавливаем облачное окружение
Запустить сервер DAVM можно всего за несколько шагов:
- Переходим в раздел Облачная платформа внутри панели управления.
- Выбираем пул ru-7a и создаем облачный сервер с дистрибутивом Ubuntu LTS Data Analytics 64-bit и нужной конфигурацией.
Подробная инструкция по созданию и запуску DAVM доступна в документации.
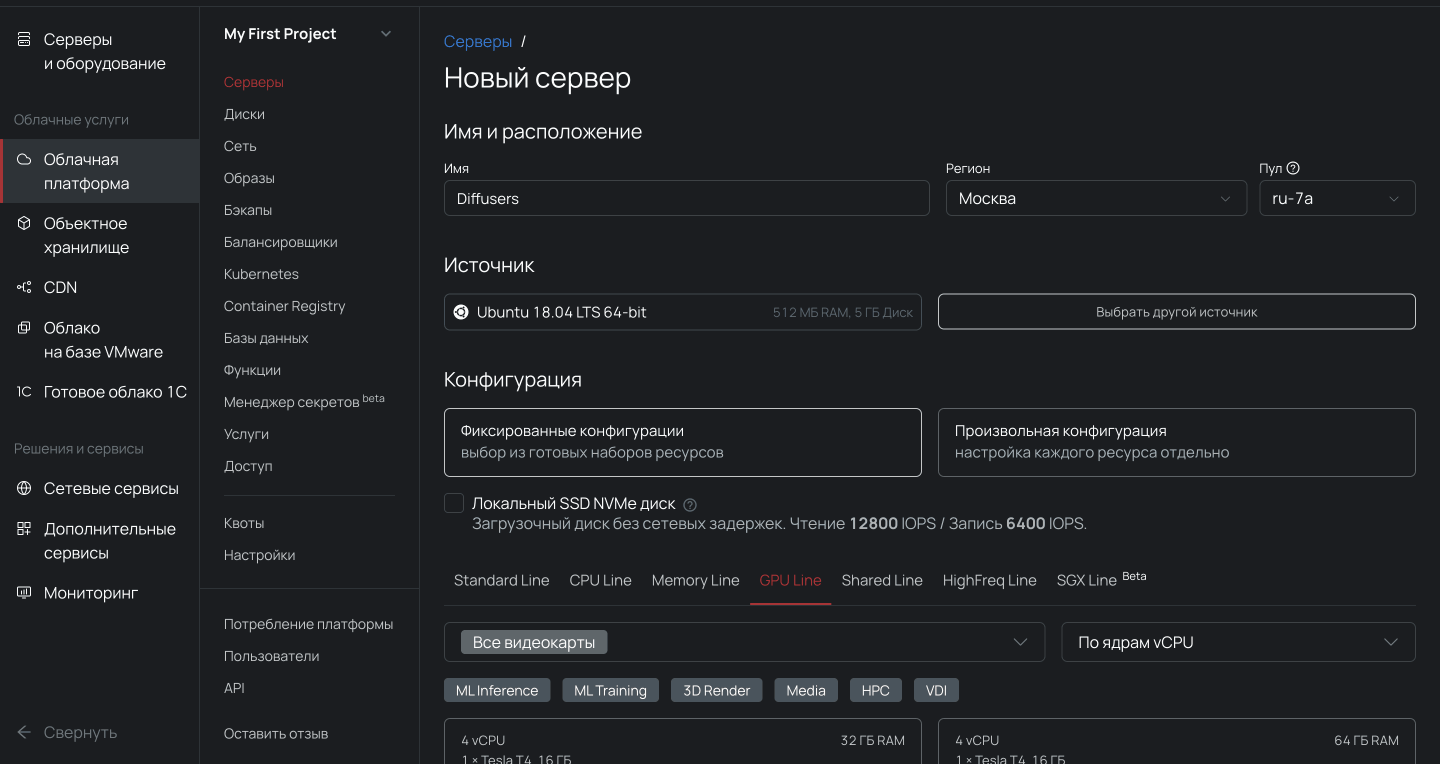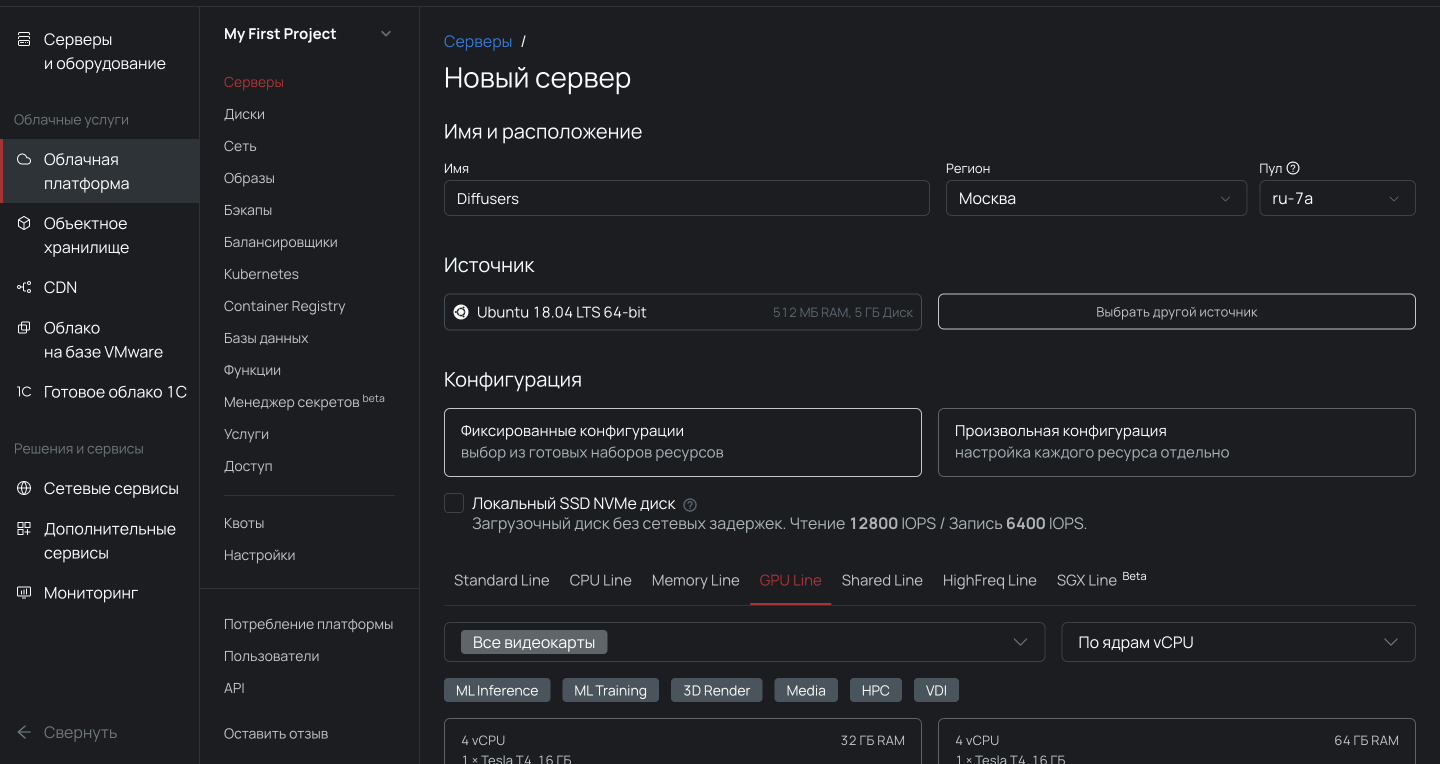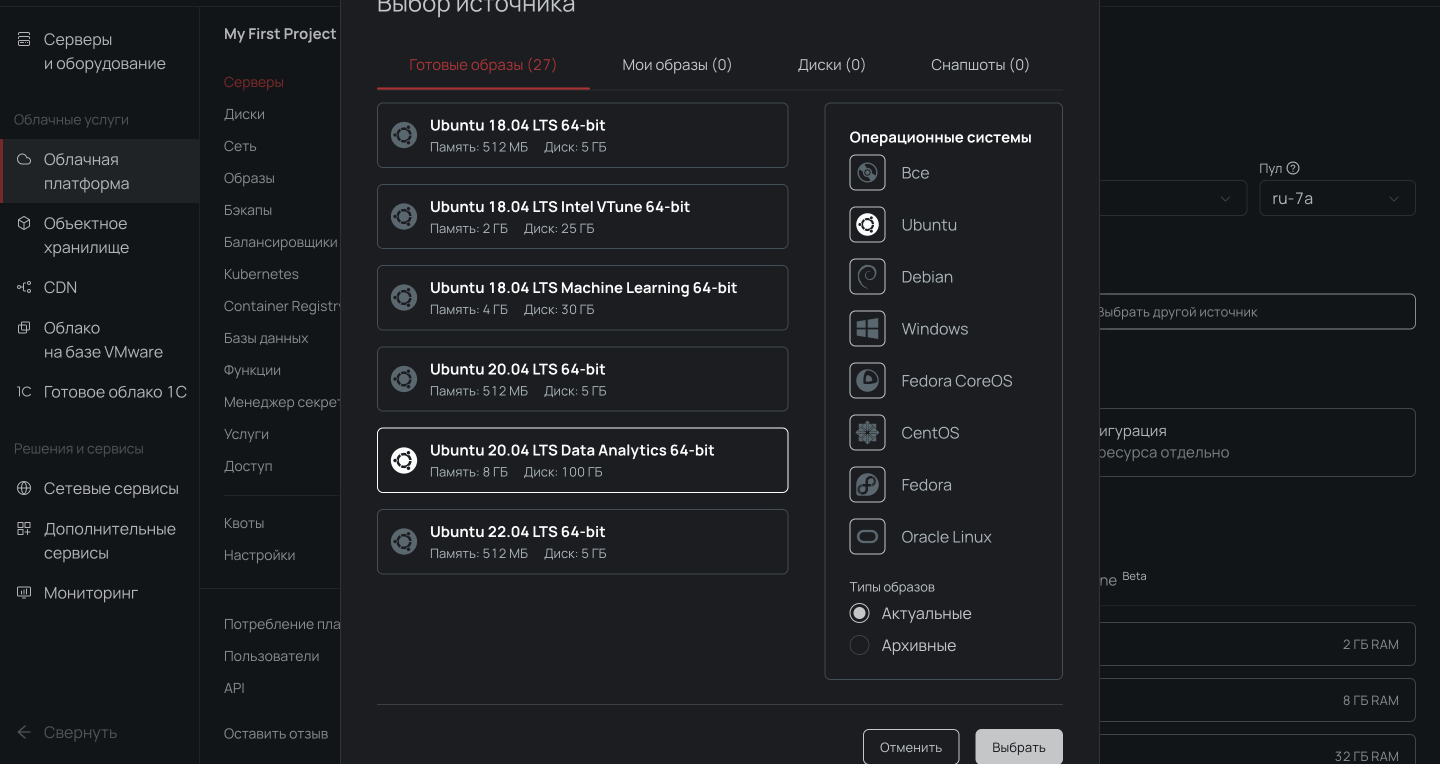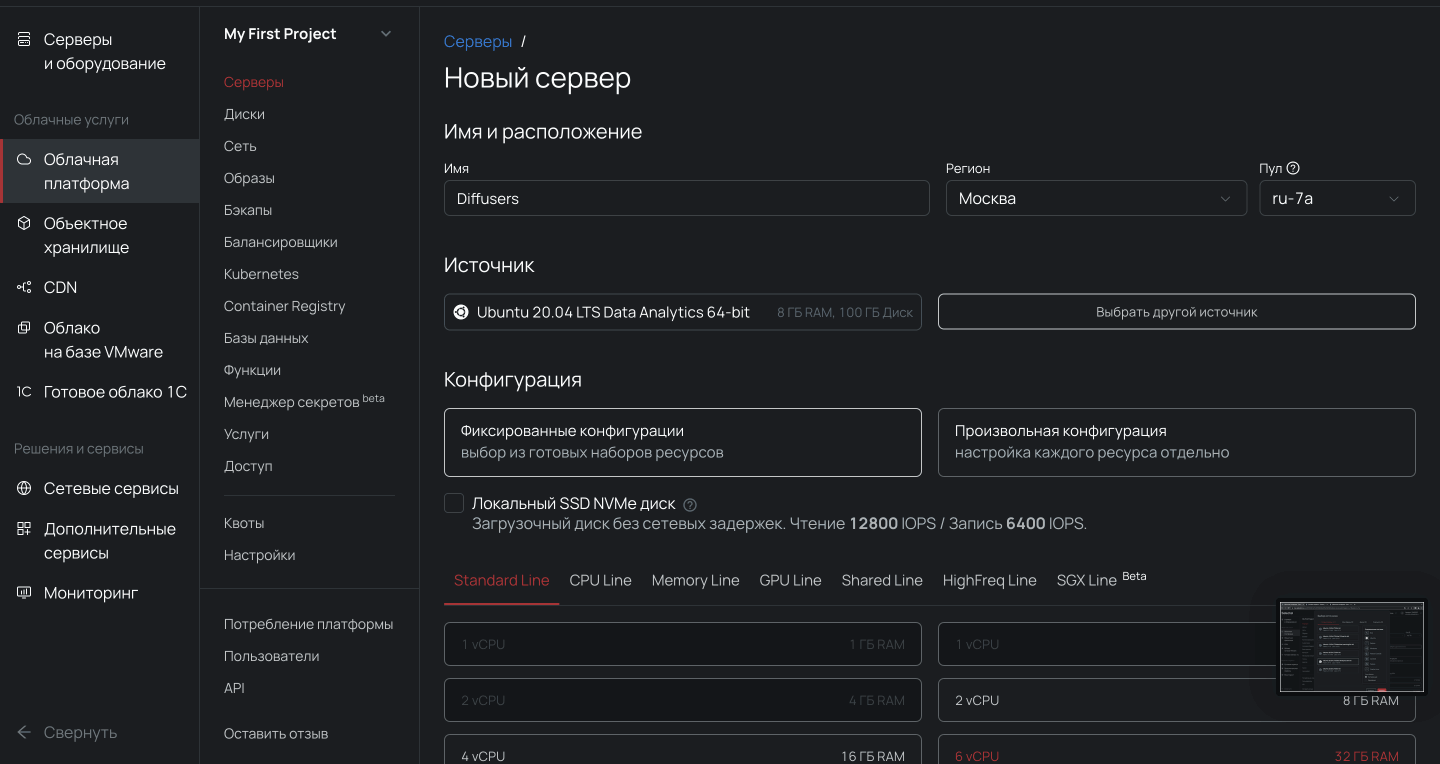
Важно, чтобы сервер был доступен из интернета, иначе с компьютера не подключиться. Для этого во время настройки конфигураций выберите новый публичный IP-адрес.
Подключаемся к DAVM
Нужно дать системе пару минут на подгрузку всех Docker-образов. Потом нужно подключиться к серверу по SSH — тогда он покажет данные для авторизации в окружении DAVM.
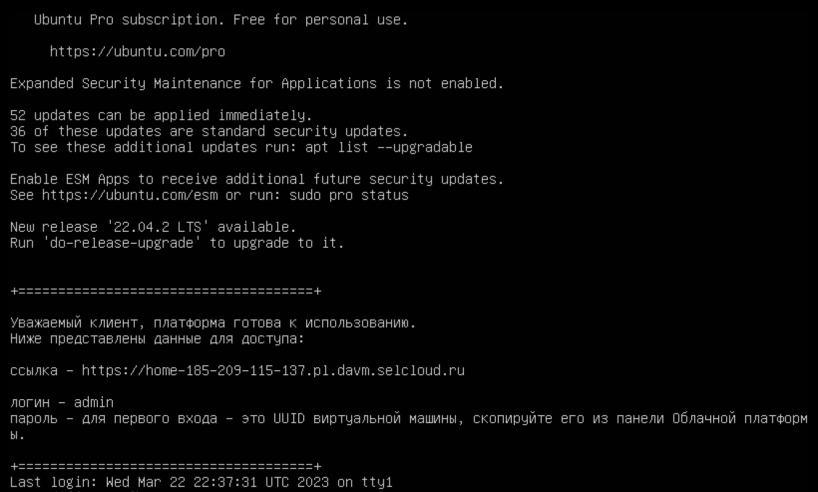
Теперь, если перейти по ссылке из сообщения и авторизоваться в DAVM, можно запустить JupyterLab, Keycloak, Prefect или Superset.
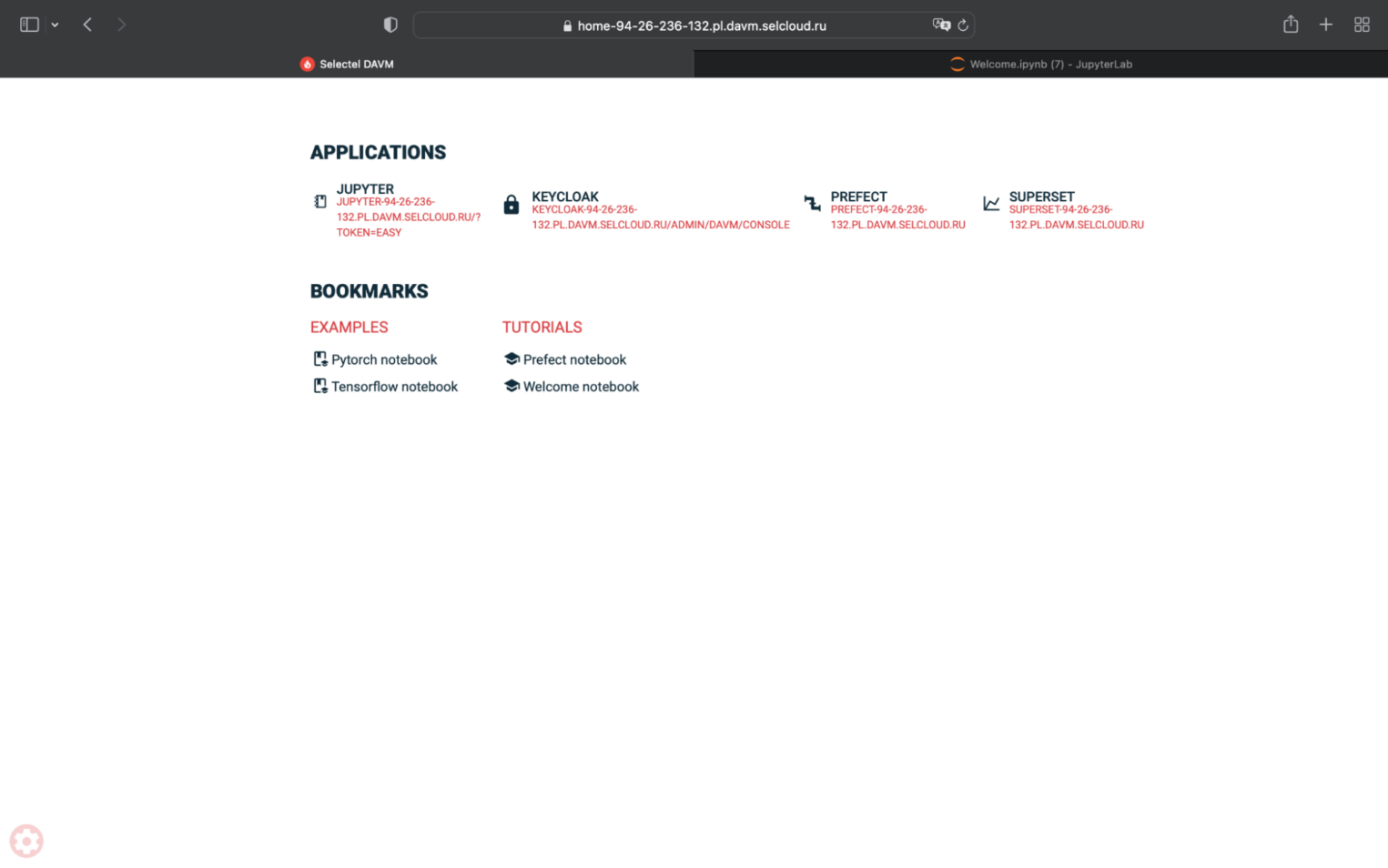
В DAVM можно создавать пользователей, управлять ими и авторизацией во внутренних приложениях с помощью Keycloak. Обратите внимание, что после первичной смены стандартного пароля на собственный, его удаленный сброс силами технической поддержки невозможен.
Парсим данные с Hugging Face
Для примера напишем простой парсер библиотеки Hugging Face. А после — загрузим полученную информацию в базу данных и построим дашборд для визуализации.
Получение данных
Для парсинга данных будем использовать стандартный API Hugging Face. Для этого устанавливаем через pip и импортируем необходимые библиотеки в программу:
import pandas as pd
import matplotlib.pyplot as plt
from datetime import datetime
from sqlalchemy import create_engine
import json
from huggingface_hub import HfApi
from huggingface_hub import ModelSearchArguments, DatasetSearchArguments
Далее необходимо инициализировать API Hugging Face и спарсить датасеты, модели и метрики:
# инициализируем API, парсим модели и датасеты
# получите токен по ссылке: https://huggingface.co/settings/token
api = HfApi(token="ваш токен")
hugging_face_models = list(iter(api.list_models()))
hugging_face_datasets = list(iter(api.list_datasets()))
# выводим количество моделей и датасетов
print(len(hugging_face_models))
print(len(hugging_face_datasets))
# загружаем поля (свойства и атрибуты) моделей и датасетов
for i in range(len(hugging_face_models)):
hugging_face_models[i] = hugging_face_models[i].__dict__
for i in range(len(hugging_face_datasets)):
hugging_face_datasets[i] = hugging_face_datasets[i].__dict__
# переводим данные объектов в json
hugging_face_models_json = json.dumps(hugging_face_models)
hugging_face_datasets_json = json.dumps(hugging_face_datasets)
Обработка результата
Теперь то, ради чего мы и парсим Hugging Face. Данные из этой библиотеки можно использовать для сравнения моделей и поиска лучших. А также, например, для поиска датасетов под свои задачи:
# настраиваем отображение датафреймов
pd.options.display.max_rows = 200
pd.options.display.max_colwidth = None
n = 20
# читаем json-структуру с моделями
models_slice_df = pd.read_json(hugging_face_models_json)
# сортируем значения по лайкам и скачиваниям
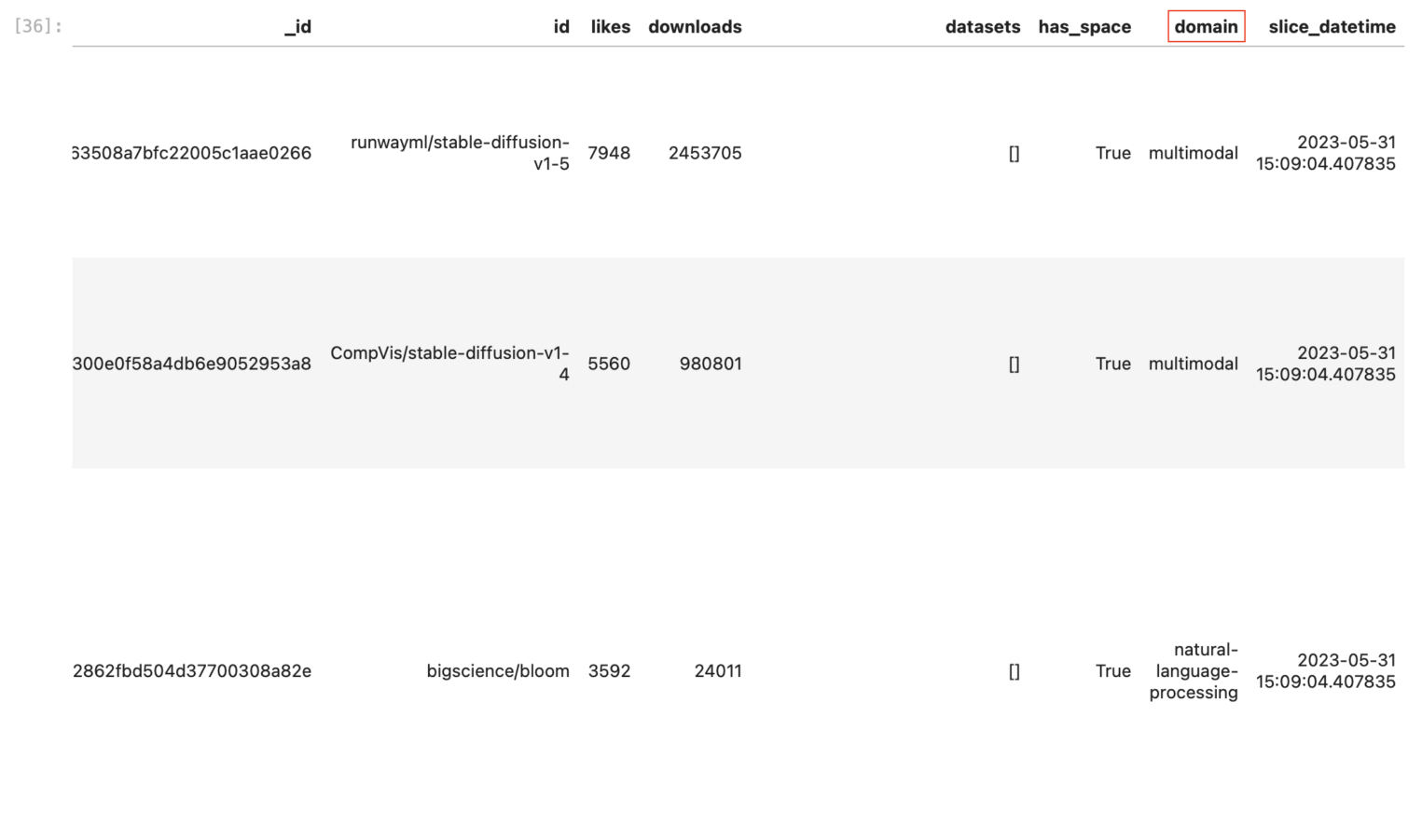
models_slice_df.sort_values(["likes", "downloads"], ascending=False).head(n)
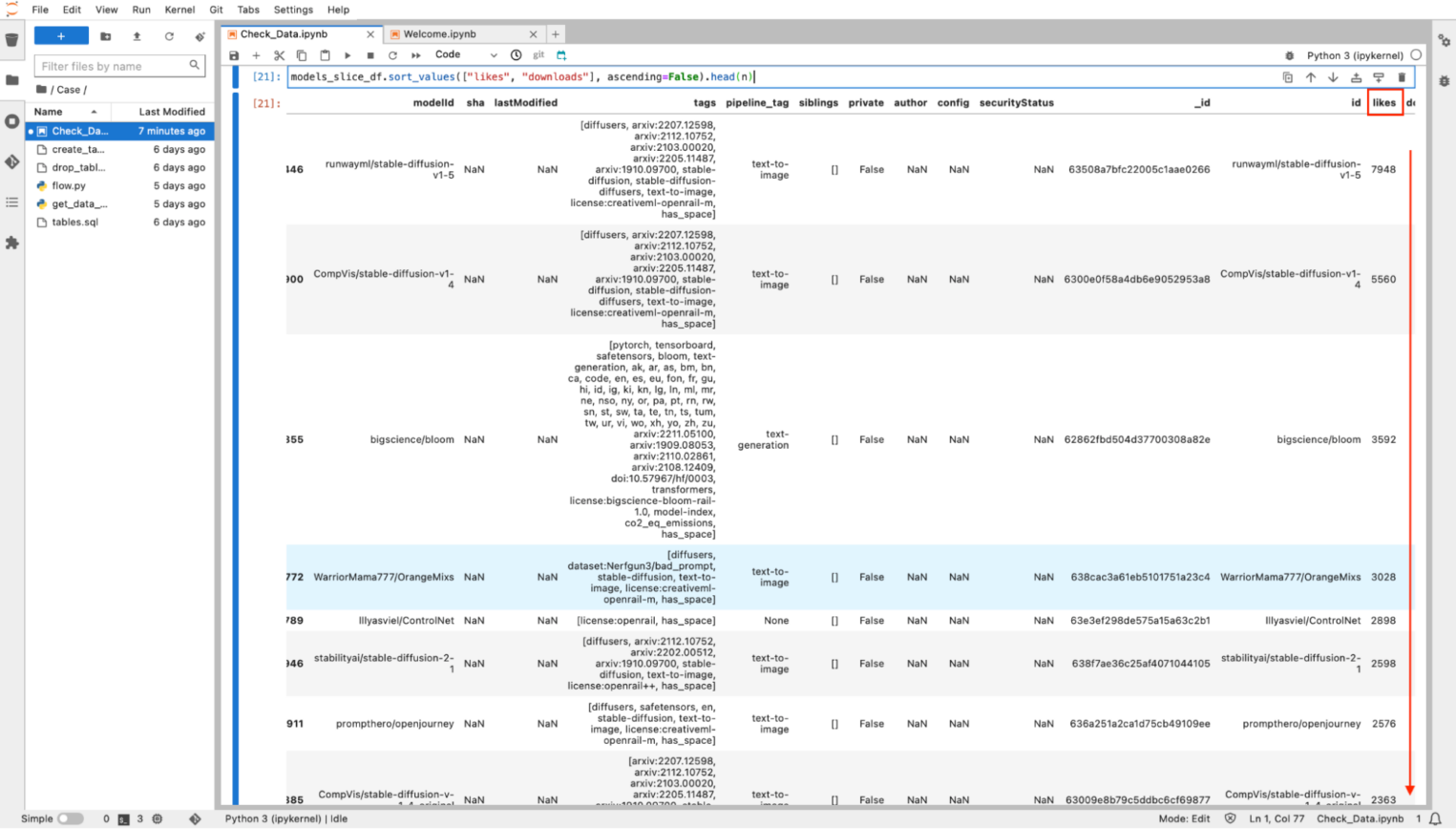
Готово — в нотбуке появился отсортированный список моделей Hugging Face. То же самое можно провернуть с датасетами и другими спаршенными данными. Также для моделей можно назначить «домены», которые помогут при анализе данных.
task2domain = {
"text-classification": "natural-language-processing",
"reinforcement-learning": "reinforcement-learning",
"text2text-generation": "natural-language-processing",
"text-to-image": "multimodal",
...
"depth-estimation": "computer-vision",
"document-question-answering": "multimodal",
"text-to-video": "multimodal",
"visual-question-answering": "multimodal",
"voice-activity-detection": "audio",
"robotics": "robotics",
"other": "unknown-domain",
"graph-ml": "graph",
"time-series-forecasting": "time-series"
}
models_slice_df["domain"] = models_slice_df.pipeline_tag.apply(lambda tag: task2domain.get(tag, "unknown-domain"))
models_slice_df["slice_datetime"] = datetime.now()
models_slice_df.sort_values(["likes", "downloads"], ascending=False).head(n)
Код шаблона для работы с датасетами и моделями Hugging Face доступен в нашем репозитории на GitHub. Делайте форк и предлагайте свои улучшения!
При желании можно автоматизировать процесс парсинга данных и регулярно обновлять датасет, написав один небольшой flow в Prefect. Для простоты, мы опустим подобные детали, но вы можете посмотреть реализацию в нашем репозитории.
Подключение базы данных
Супер — мы получили и даже обработали какие-то данные. В контексте нашей задачи — датафреймы моделей и датасетов. Осталось только загрузить их в облачную базу данных, чтобы не парсить каждый раз через API — этот процесс довольно длительный.
Создаем кластер PostgreSQL
В качестве основной базы данных будем использовать PostgreSQL. Причин ее популярности, кроме открытого исходного кода, много. Например, PostgreSQL умеет работать с составными запросами, большими нагрузками и критическими данными, которые записываются на диск. Это особенно важно для хранения датасетов, которые могут содержать десятки параметров и сотни записей.
Создать кластер PostgreSQL можно в несколько кликов:
1. Переходим в раздел Облачная платформа → Базы данных в панели управления.
2. Выбираем пул и нажимаем Создать кластер. Рекомендуем выбрать пул в Санкт-Петербурге — в нем же находится сервер DAVM. Близость обеспечит высокую скорость передачи данных.
3. Настраиваем кластер. При желании можно увеличить или уменьшить количество реплик.
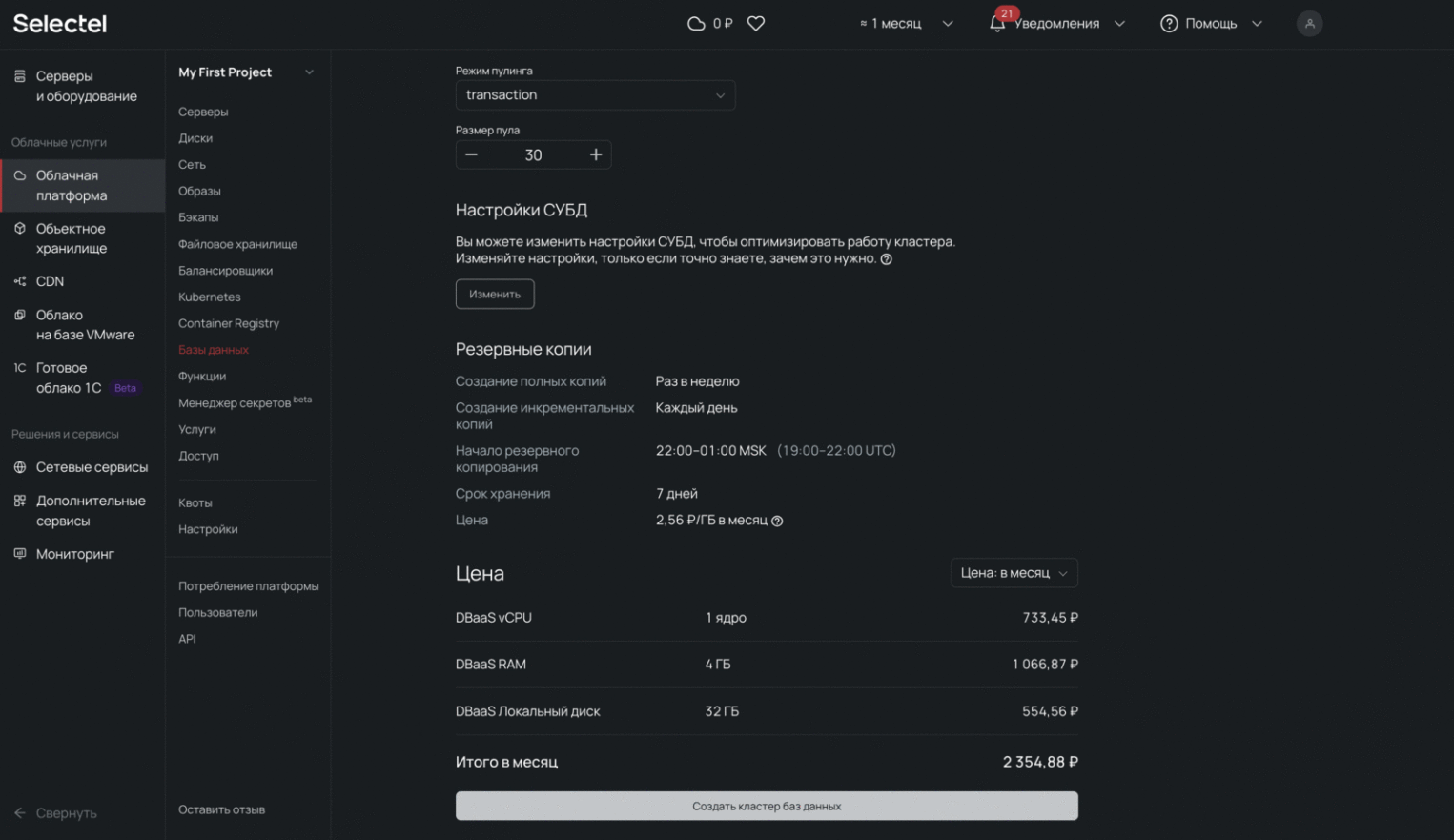
4. Кликните по кластеру, создайте нового пользователя и саму базу данных. Сохраните пароль — его нельзя будет посмотреть в панели управления.
Настраиваем подключение
В разделе Подключение можно скопировать код для соединения с базой данных через интернет. Если вы хотите настроить соединение в рамках приватной сети, читайте документацию.
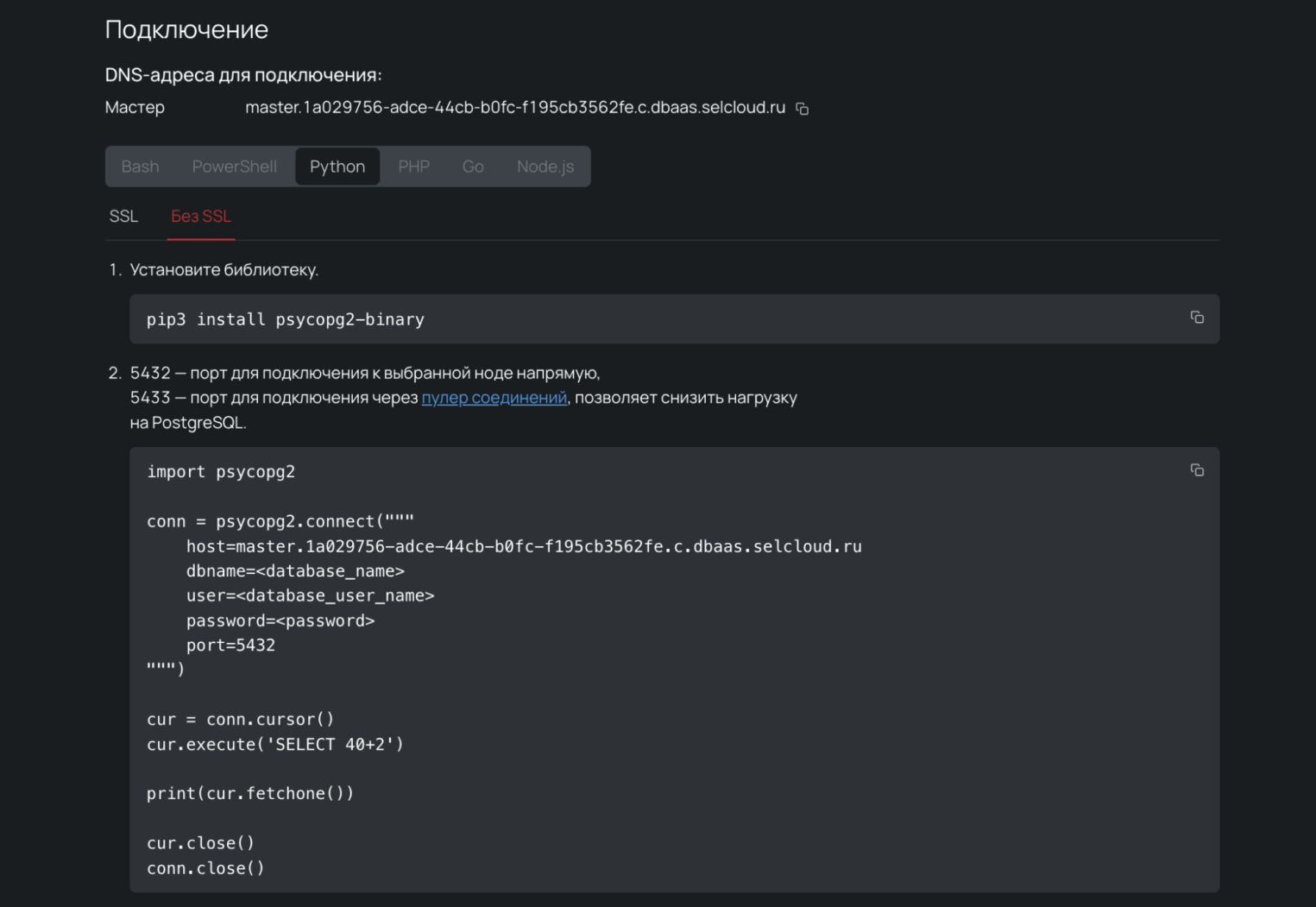
Выходим из панели управления и возвращаемся в DAVM, чтобы подключиться к PostgreSQL. В DAVM уже установлена библиотека для работы с ней — psycopg. Поэтому открываем JupyterLab и просто делаем Ctrl+C:
import psycopg2
con = psycopg2.connect(
host="master.1a029756-adce-44cb-b0fc-f195cb3562fe.c.dbaas.selcloud.ru",
dbname=<database_name>,
user=<database_user_name>,
password=<database_password>,
port=5432
)
cur = con.cursor()
cur.execute('SELECT 40+2')
print(cur.fetchone())
cur.close()
con.close()
Давайте подставим значения параметров подключения из панели управления. Но чтобы не светить чувствительными данными прямо в коде, будем загружать их из Prefect Secrets.
1. Переходим в терминал JupyterLab и добавляем новые секреты:
nano /home/davm/.prefect/config.toml
[context.secrets]
DB_HOST = "master.1a029756-adce-44cb-b0fc-f195cb3562fe.c.dbaas.selcloud.ru"
DB_NAME = "davm_db"
DB_USER = "davm_db_user"
DB_PASSWORD = "c8BVYD2oj6n2"
2. Импортируем секреты в программу и добавляем в качестве значений параметров:
from prefect.client import Secret
import psycopg2
...
con = psycopg2.connect(
host=Secret("DB_HOST").get(),
dbname=Secret("DB_NAME").get(),
user=Secret("DB_USER").get(),
password=Secret("DB_PASSWORD").get(),
port=5432
)
cur = conn.cursor()
cur.execute('SELECT 40+2')
print(cur.fetchone())
cur.close()
con.close()
Готово — подключение настроено, можно создать таблицу и загрузить в нее датафреймы.
Загружаем датафреймы
Чтобы наша платформа загружала в облачную базу данных информацию по моделькам и датасетам с Hugging Face, будь то датасеты или модели, нужно описать создание соответствующих таблиц:
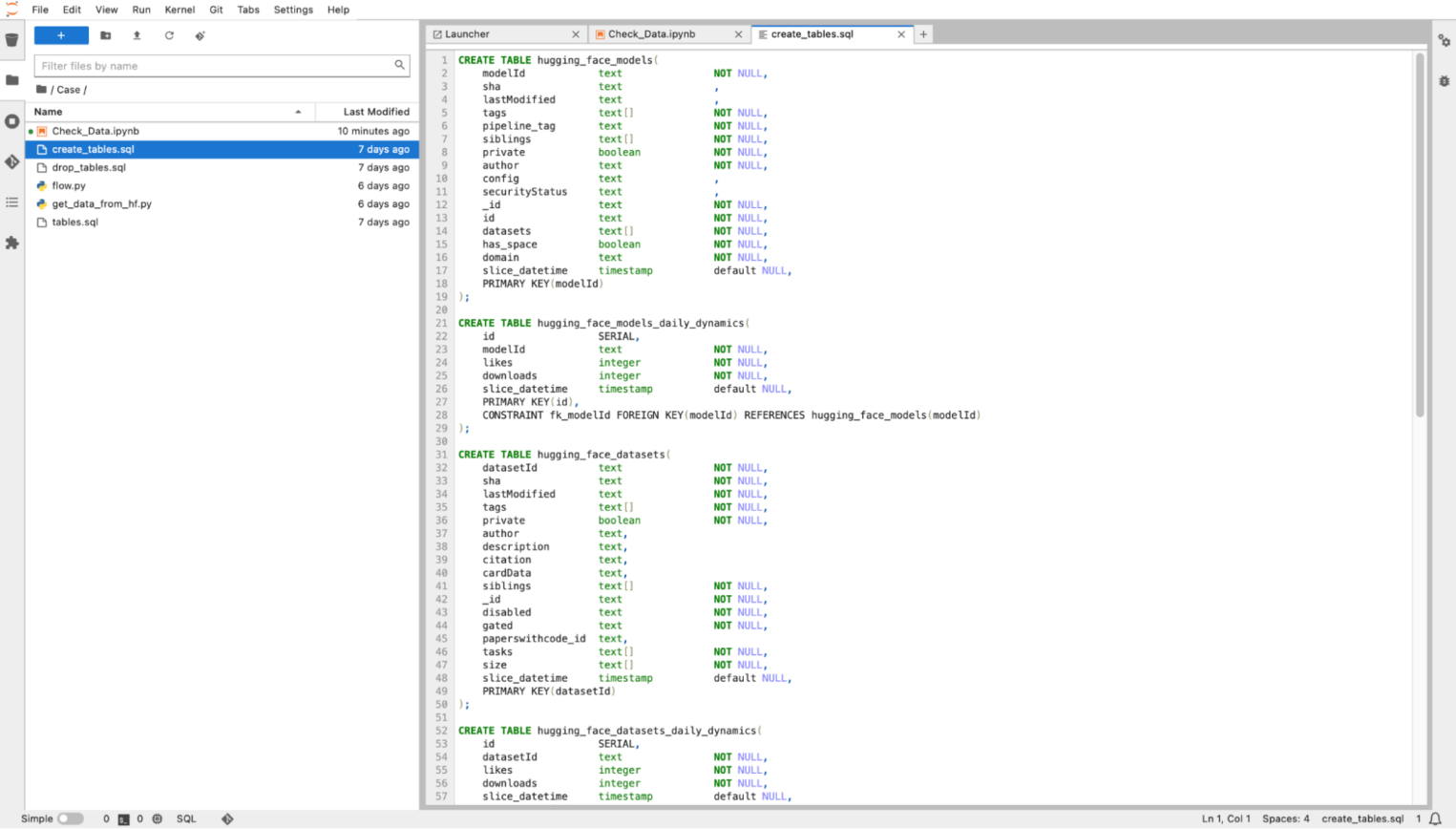
После необходимо добавить код для запуска crete_tables.sql:
from prefect.client import Secret
import psycopg2
from psycopg2.extensions import ISOLATION_LEVEL_AUTOCOMMIT
...
con = psycopg2.connect(
host=Secret("DB_HOST").get(),
dbname=Secret("DB_NAME").get(),
user=Secret("DB_USER").get(),
password=Secret("DB_PASSWORD").get(),
port=5432
)
con.set_isolation_level(ISOLATION_LEVEL_AUTOCOMMIT)
cur = conn.cursor()
# последовательно создаем таблицы,
# описанные в транзакции create_tables.sql
with open("create_tables.sql", "r") as file:
cursor.execute(file.read())
Дело осталось за малым — нужно загрузить сами датафреймы. Это можно сделать через sqlalchemy:
from sqlalchemy import create_engine
…
engine = create_engine('postgresql://{}:{}@{}:5432/{}'.format(db_user, db_password, db_host, db_name))
models_df = pd.read_sql('hugging_face_models', engine)
models_df.head()
datasets_df = pd.read_sql('hugging_face_datasets', engine)
datasets_df.head()
# подготовка масок для загрузки данных в таблицы
models_mask = [col for col in models_df.columns if col not in ["likes", "downloads"]]
datasets_mask = [col for col in datasets_df.columns if col not in ["likes", "downloads"]]
if len(models_slice_df[~models_slice_df.modelid.isin(models_df.modelid)]) > 0:
models_slice_df[~models_slice_df.modelid.isin(models_df.modelid)][models_mask].to_sql('hugging_face_models', engine, if_exists='append', index=False)
if len(datasets_slice_df[~datasets_slice_df.datasetid.isin(datasets_df.datasetid)]) > 0:
datasets_slice_df[~datasets_slice_df.datasetid.isin(datasets_df.datasetid)][datasets_mask].to_sql('hugging_face_datasets', engine, if_exists='append', index=False)
# для таблиц daily_dynamics используем другие маски.
# daily_dynamic нужны, чтобы мониторить ТОП датасетов и моделей
models_mask = ["modelid", "likes", "downloads", "slice_datetime"]
datasets_mask = ["datasetid", "likes", "downloads", "slice_datetime"]
models_slice_df[models_mask].to_sql('hugging_face_models_daily_dynamics', engine, if_exists='append', index=False)
datasets_slice_df[datasets_mask].to_sql('hugging_face_datasets_daily_dynamics', engine, if_exists='append', index=False)
Готово — данные загружены. В таблицах hugging_face_models и hugging_face_datasets загружены сами модели и датасеты, а в hugging_face_models_daily_dynamics и hugging_face_datasets_daily_dynamics — их показатели популярности на Hugging Face.
Визуализация данных
Все данные собраны, датафреймы загружены в удобном формате. Теперь данные нужно визуализировать — например, через Superset, который по умолчанию установлен в DAVM.
Знакомство с Superset
Для начала запускаем Superset и в разделе Settings → Database Connectionsподключаемся к нашей облачной базе данных:
В меню Datasets необходимо добавить датафреймы, которые хотите проанализировать:
После загрузки датафреймов можно построить графики. Какие именно — решать вам. В рамках примера сгенерируем столбцовую диаграмму (bar chart), чтобы посмотреть, какие типы моделей встречаются на Hugging Face чаще всего. Для этого нужно перейти в раздел Charts, выбрать соответствующий тип графика, в качестве Chart Source указать hugging_face_models и настроить параметры отображения:
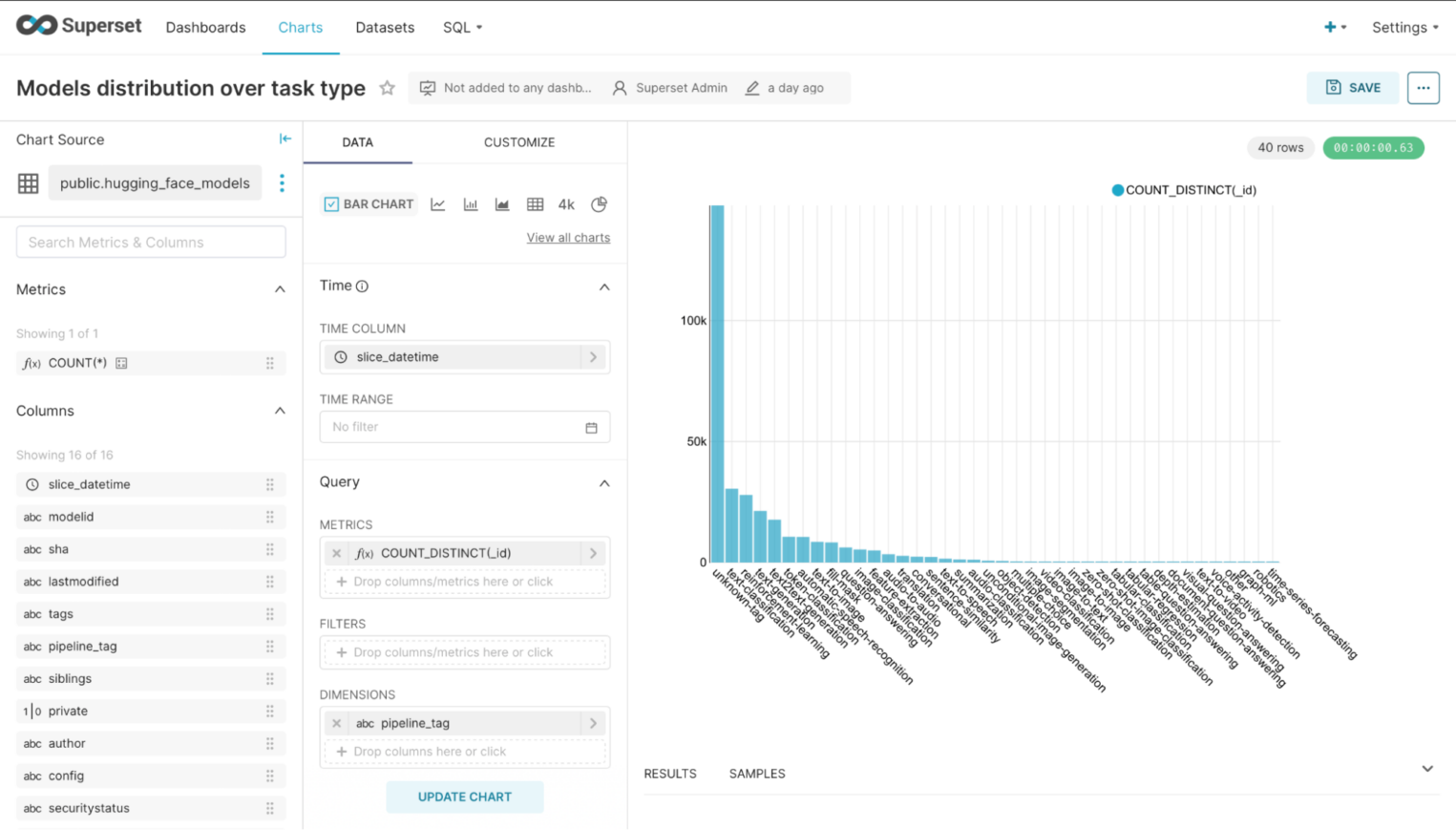
Как мы видим, большинство моделей помечены авторами, как other (unknown-domain). Почему так — открытый вопрос. Но стало понятно, что не все, например, модели текстовой классификации можно найти по тегу natural-language-processing.
Настройка источников данных
Можно пойти дальше и построить столбцовую диаграмму, которая покажет, какой тип модели самый популярный. Но для этого нужно объединить два датафрейма — hugging_face_models и hugging_face_models_daily_dynamics. Из первого мы получим типы моделей, а из второго — количество лайков и скачиваний.
Объединить датафреймы можно с помощью специального SQL-запроса в разделе SQL → SQL Lab:
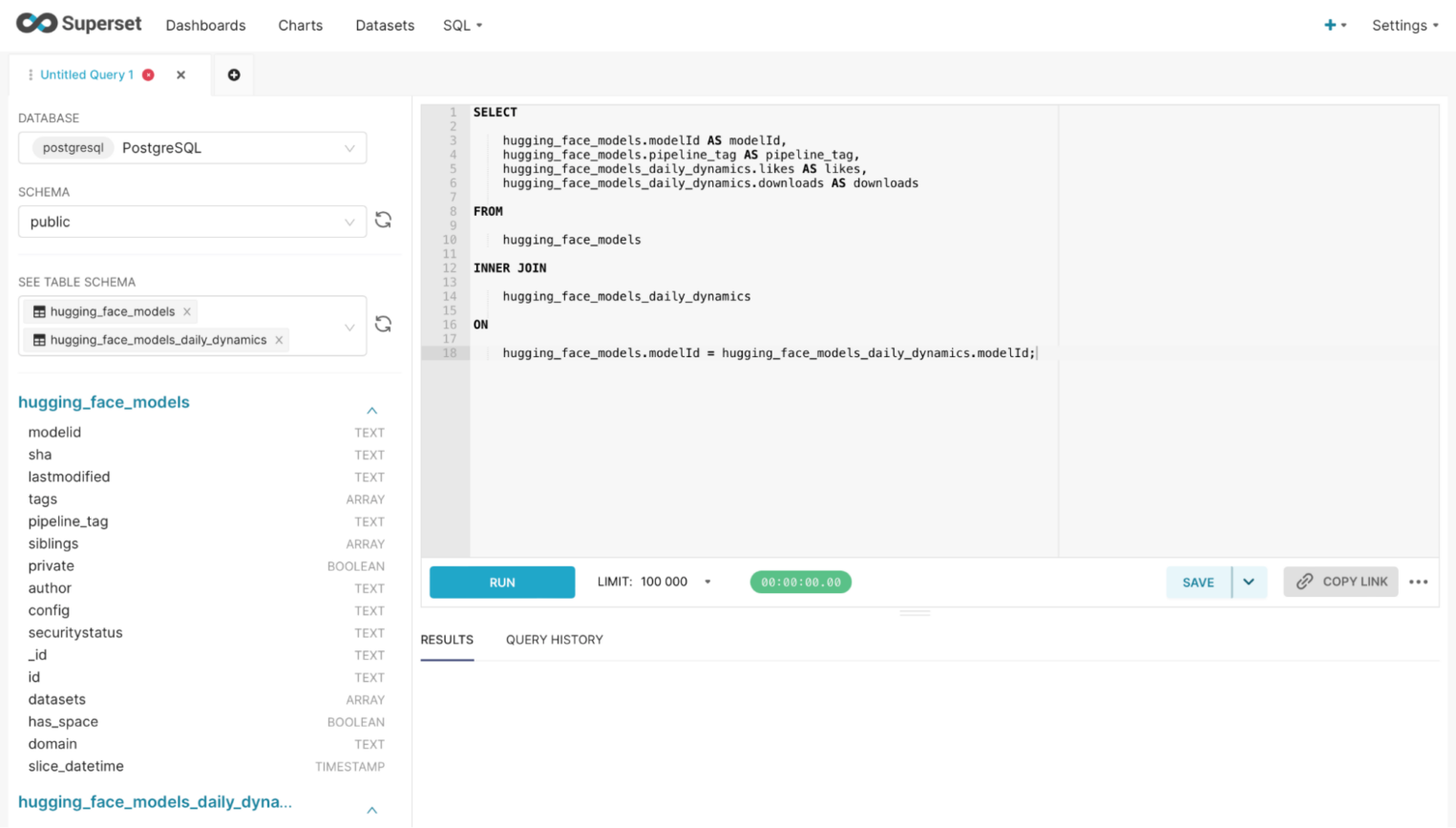
У нас получилась новая таблица — источник данных с полями modelid, likes, downloads и pipeline_tag. Аналогичным образом можно перейти в раздел Charts и создать гистограмму с рейтингом популярности моделей:
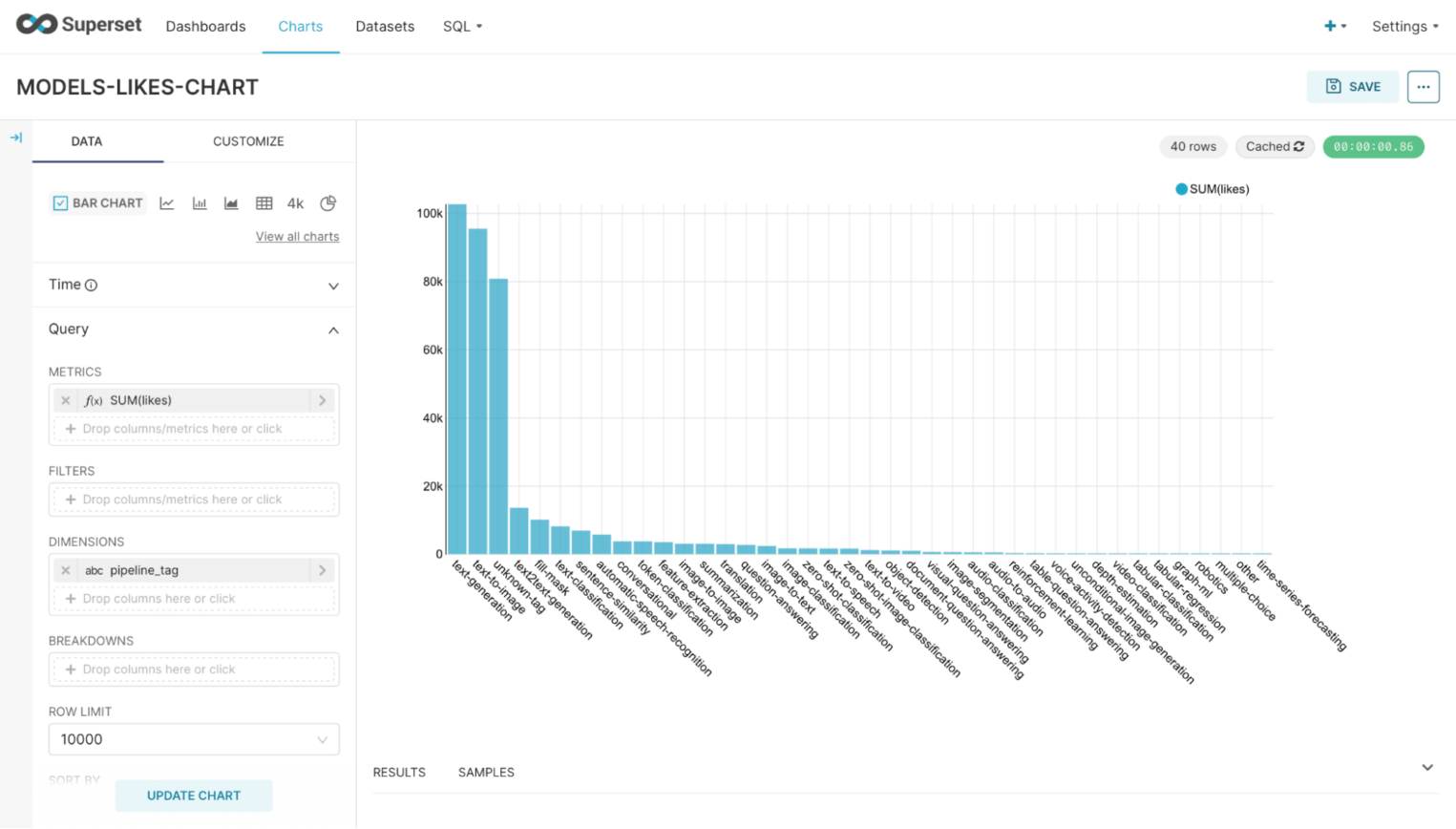
Готово — диаграмма построена, первое место занимают модели текстовой генерации.
Заключение
Весь процесс от аренды DAVM до парсинга данных и их визуализации занял около часа — с учетом того, что код был подготовлен заранее. Ничего настраивать на стороне виртуальной машины не пришлось.
Подключайтесь к нашему репозиторию на GitHub, делайте форк и используйте его в качестве референса, если хотите разобрать кейс из статьи подробнее. До связи!





