

Когда речь заходит о выборе инфраструктуры, возникает классический вопрос: использовать готовый сервис в облаке или собрать свой на выделенных серверах. На первый взгляд, все просто: облако — это про скорость и удобство, а выделенные серверы — про мощность и производительность. Но все не так просто.
Облако — это не монолит, а набор кубиков (сервисов), из которых можно собирать решения под любые задачи — в том числе под очень требовательные к производительности. А что если объединить вариативность облака и производительность выделенного сервера? Готовы? Давайте соберем это облачное «LEGO» вместе!
Облако — это LEGO для взрослых
Наши клиенты в облаке обычно решают две базовые задачи: хранение данных и вычисления. Давайте упрощенно посмотрим, сколькими способами можно хранить данные в Selectel. На выбор у нас имеется:
- семь типов виртуальных машин: Standard, CPU, Memory Line, GPU, Shared, HighFreq, SGX;
- четыре типа дисков: локальный SSD NVMe, сетевой HDD базовый, сетевой SSD универсальный, сетевой SSD быстрый;
- три типа файловых хранилищ: базовое, универсальное, быстрое;
- четыре типа объектного хранилища: S3, OpenStack Swift, стандартное, холодное;
- три типа СХД: шаренный LUN, выделенное аппаратное устройство, ленточная СХД;
- семь типов готовых облачных СУБД;
- выделенные серверы (можно же хранить данные просто на сервере).
Итого: 29 способов хранить данные.
Теперь рассмотрим варианты реализации вычислений:
- снова те же семь типов виртуальных машин,
- два типа кластеров Kubernetes: обычный и отказоустойчивый,
- четыре типа воркер-нод в каждом кластере Kubernetes,
- снова выделенные серверы.
И вот у нас 16 способов организовать вычисления на сервере.
Оценим, сколько есть способов решить какую-нибудь тривиальную задачу. Скажем, нам нужно развернуть простой сайт, используя один способ хранения и один способ вычисления в облаке. Посчитаем количество сочетаний «кубиков». Кажется, пока все просто:
29 х 16 = 464 сочетания.
При этом мы всегда можем пойти по скользкой дорожке — отказаться от набора элементов и реализовать все на одном «кубике». Например, использовать только одну виртуальную машину для всего или реализовать статический сайт вообще без вычислений, используя только функциональность объектного S3-хранилища.
Это расширяет наш набор до 481 сочетания. Только задумайтесь 481 способ решения тривиальной задачи в духе «сделайте мне простой сайт».
Рассмотрим что-нибудь посложнее — распилим монолит. Допустим, мы хотим из огромного старого сервиса сделать что-то красивое и современное, состоящее из пяти микросервисов. Выбираем пять независимых способов хранения и пять способов вычислений. В этот раз не будем считать за сочетания возможность объединить compute и storage. Предположим, в нашем ТЗ явно прописано, что они должны быть разнесены.
Возьмем базовую формулу комбинаторики, чтобы оценить, сколькими способами можно выбрать пять вариантов из 29 с условием, что они могут повторяться (мы же можем для всех пяти микросервисов использовать один и тот же тип СУБД):
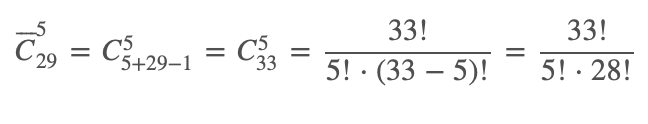
Мы получаем 237 336 способов хранения информации.
Оценим, сколько есть способов выбрать пять «кубиков», отвечающих за вычисления:
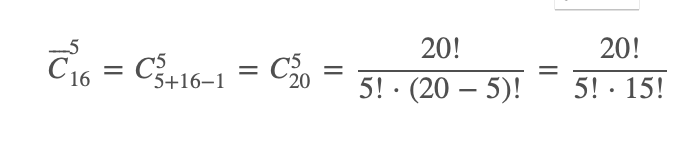
Получается, у нас есть 15 504 способа выбрать пять вариантов из 16 с условием, что они могут повторяться.
Неплохо. Это означает, что есть больше 3,6 млрд вариантов решения нашей тривиальной задачи в облаке.
237 336 х 15 504 = 3 683 831 424 способа сложить «кубики».
Стоит учесть, что представленная мною оценка осознанно упрощена и исключает некоторые базовые элементы инфраструктуры: регионы, пулы, автономные сегменты облака, варианты реализации сетевой связанности, балансировщики, глобальные и облачные роутеры, CDN, DNS, кэш, очереди и шины данных, мониторинг, логирование, резервное копирование и другие сервисы Selectel. Добавим их и получим уже десятки миллиардов сочетаний. Каждый раз, когда я осознаю эту вариативность облака, я в первую очередь вспоминаю конструктор LEGO.
И при всем этом на самом деле у нас всего два принципиальных подхода к инфраструктуре:
- использовать готовые сервисы в облаке;
- собирать и настраивать все самостоятельно на выделенном сервере.
Давайте пройдемся по их плюсам и минусам, а затем перейдем к объединению двух подходов в одно решение — облачной базе данных на выделенном сервере.
Готовые базы данных в облаке
Облачный сервис — это набор готовых решений от провайдера, где все уже установлено и настроено для клиента. Буквально бери и пользуйся. В качестве примера рассмотрим интерфейс заказа облачной базы данных (DBaaS):
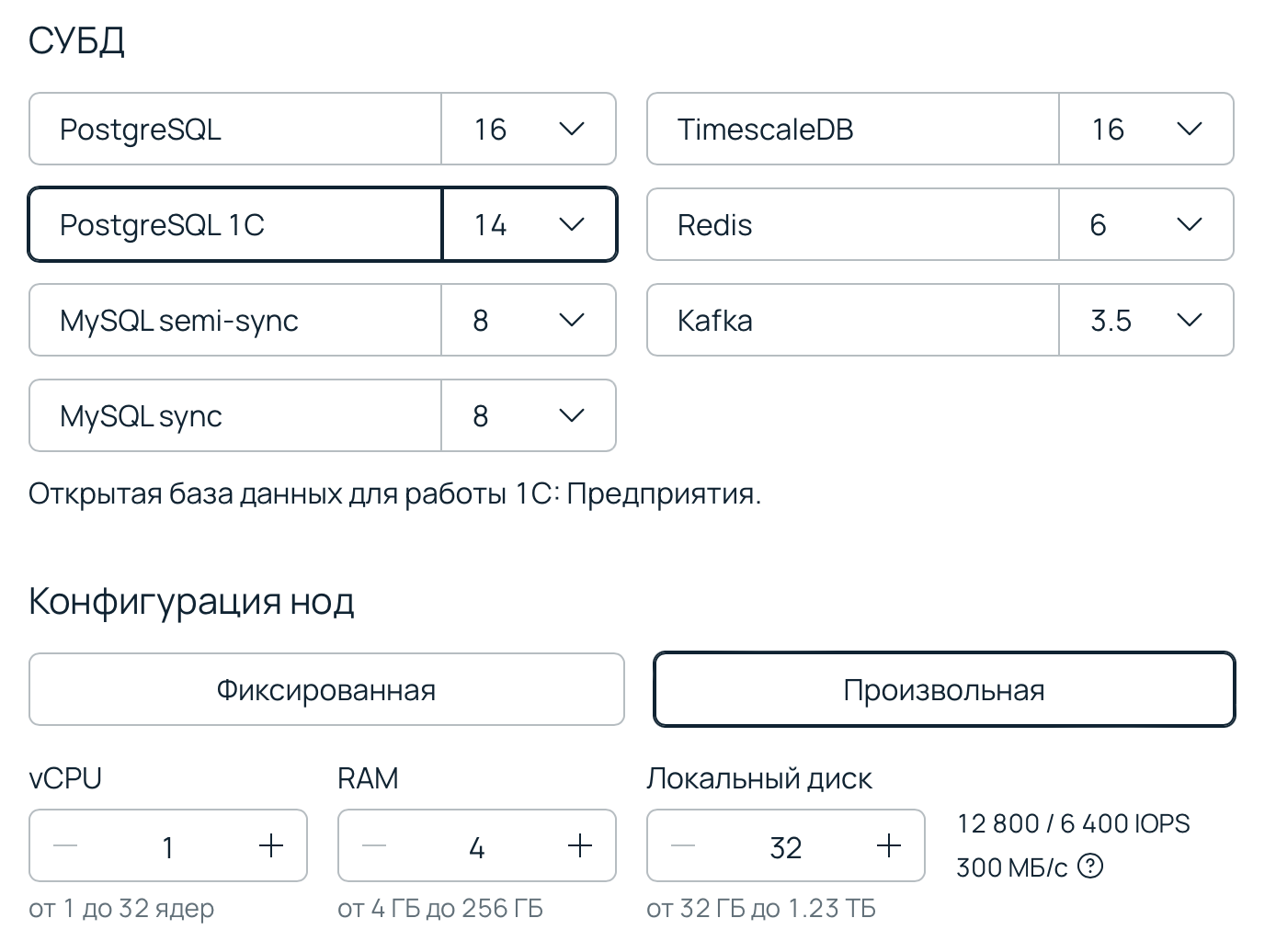
Сервис подразумевает небольшое количество настроек: пользователю нужно подобрать только версию СУБД, количество ядер, объем RAM и диска. Все уже готово к использованию и быстро развернется после пары кликов в интерфейсе.
Плюсы:
- простота и скорость запуска,
- легкость масштабирования,
- простое обслуживание,
- логическая изоляция инфраструктуры,
- оплата только за фактически потребленные ресурсы по модели pay-as-you-go.
Как следствие, клиент получает хороший time-to-market и минимальные расходы на старте.
Минусы:
- нет физической изоляции — одна база данных делит физический хост (а значит, дисковую подсистему, шину, канал и прочее) с другими виртуальными машинами;
- нет возможности кастомизации аппаратной платформы — инфраструктура хостов в облаках гомогенна, так проще обеспечивать абстракцию виртуальных машин от аппаратной составляющей.
Следовательно, клиенту сложнее получить выдающуюся производительность. Даже если вы знаете, что под ваш профиль нагрузки лучше подходит какое-то конкретное оборудование или его настройка, сервис уже собран. Одновременно с вами его используют десятки тысяч других клиентов. Вы можете только взять и использовать его «как есть».
Выделенные серверы
В целом, здесь все наоборот. Полная гибкость и свобода, собрать можно что угодно, но смысл в этом есть только при условии, что вы справитесь с управлением инфраструктурой.
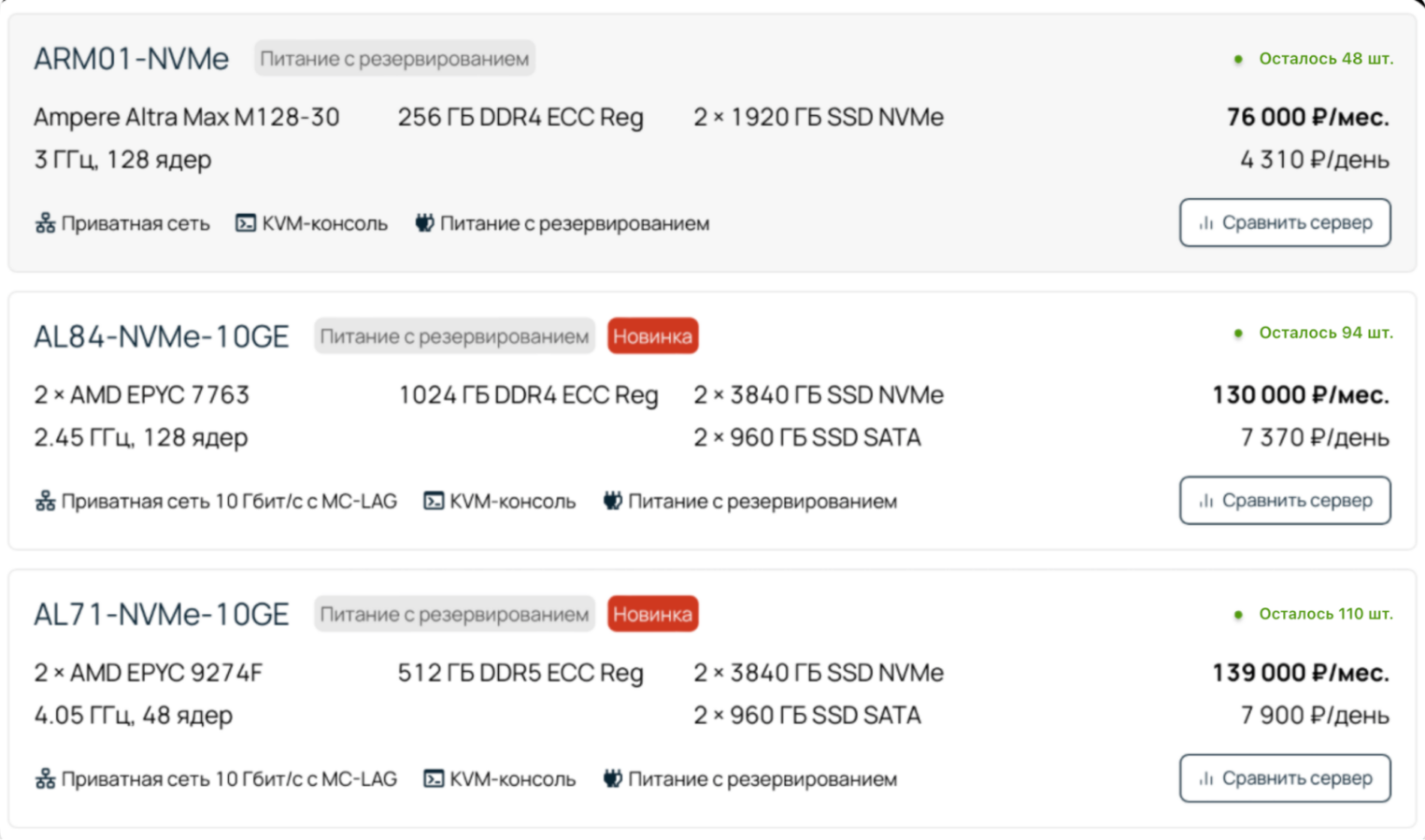
Все начинается с выбора сервера. Можно взять что-то из того, что есть в наличии, или собрать кастомную конфигурацию. Провайдер предоставит вам предустановленную операционную систему, если она нужна, и доступ к BMC по IPMI. Дальше к работе приступят ваши специалисты: развернут виртуализацию и нужные сервисы хранения, вычисления, мониторинга и резервного копирования.
Плюсы:
- кастомизация аппаратной платформы под конкретную задачу,
- изоляция на физическом уровне (а это, в том числе, плюс для ИБ),
Как следствие, есть возможность получить более высокую производительность.
Минусы:
- вашим специалистам предстоит больше работы — зона ответственности провайдера в такой услуге заканчивается обеспечением питания, охлаждения и охраны вашего сервера;
- минимальный шаг масштабирования — один сервер;
- для эксплуатации нужна сравнительно большая экспертиза и компетенции;
- вы оплачиваете все арендованные ресурсы даже если часть из них простаивает.
В результате time-to-market в таком варианте, как правило, ниже, а расходы и трудозатраты на старте — выше.
Так что же выбрать? Вот тут-то и начинается самое интересное. Мы решили проверить, что получится, если взять облачную услугу и запустить ее на выделенном сервере. Начали с DBaaS и Managed Kubernetes. О Kubernetes расскажут мои коллеги в другой раз, а дальше я сосредоточусь на облачных базах данных.
DBaaS на выделенном сервере
Как выглядит схема классической облачной базы данных как услуги:
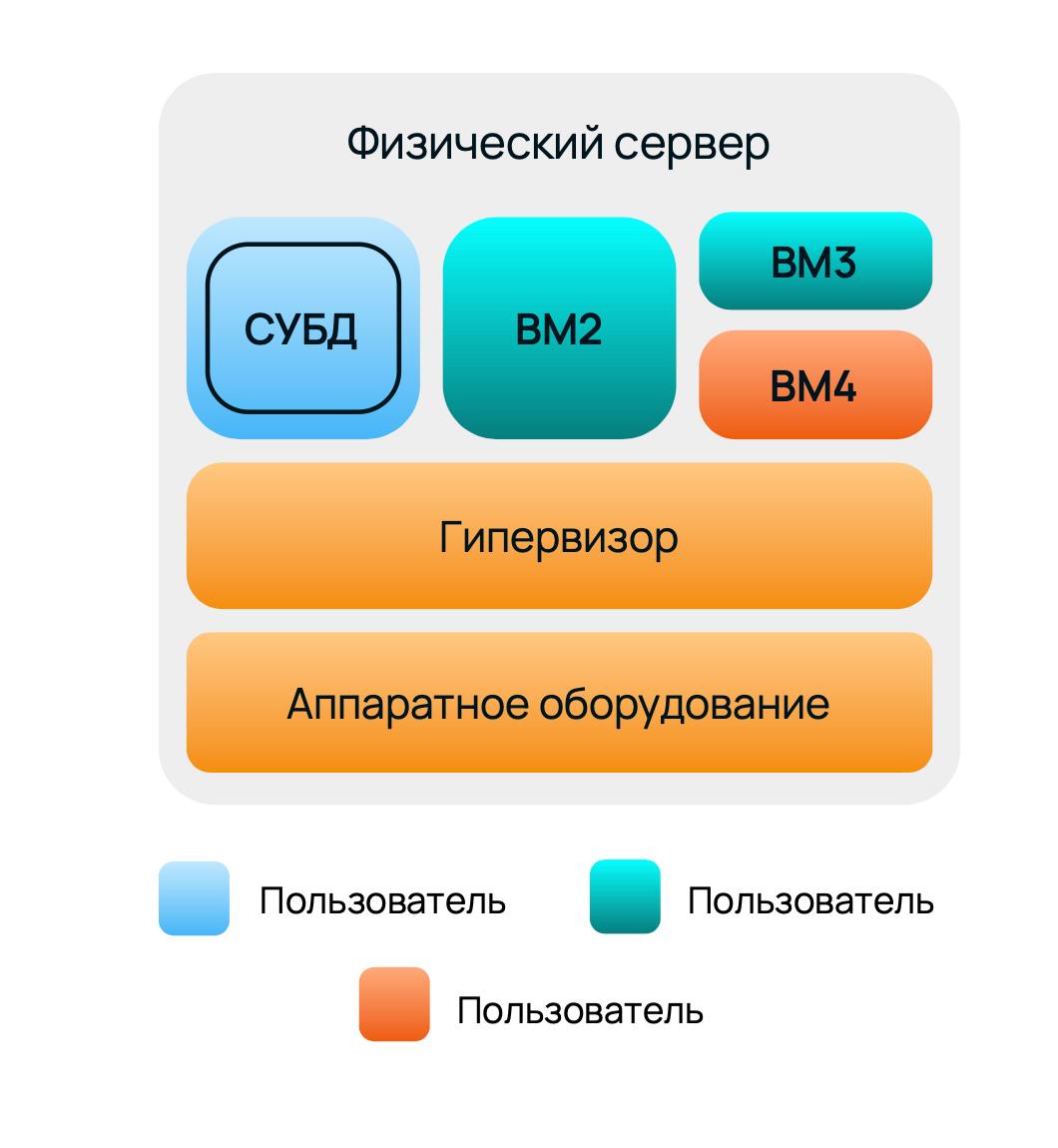
DBaaS работает поверх облака. В инфраструктуре есть стандартный хост гомогенной конфигурации, стандартная виртуальная машина, общая на хост дисковая подсистема, сетевые интерфейсы и канал.
В реальности один сервер обслуживает десятки, а то и сотни виртуальных машин. Профиль нагрузки на каждую непредсказуем. На схеме выше одна из ВМ может оказаться СУБД, а все остальные — чем угодно. Они могут появляться, исчезать, масштабироваться и т. д. Подобрать оборудование, идеально настроить ОС, BIOS, гипервизор невозможно. В итоге СУБД вынужденно подстраивается под все облако.
Чтобы решить описанные проблемы, мы пришли к конфигурации DBaaS на выделенном сервере, заточенном под конкретную задачу — обеспечить высокую производительность базы данных.
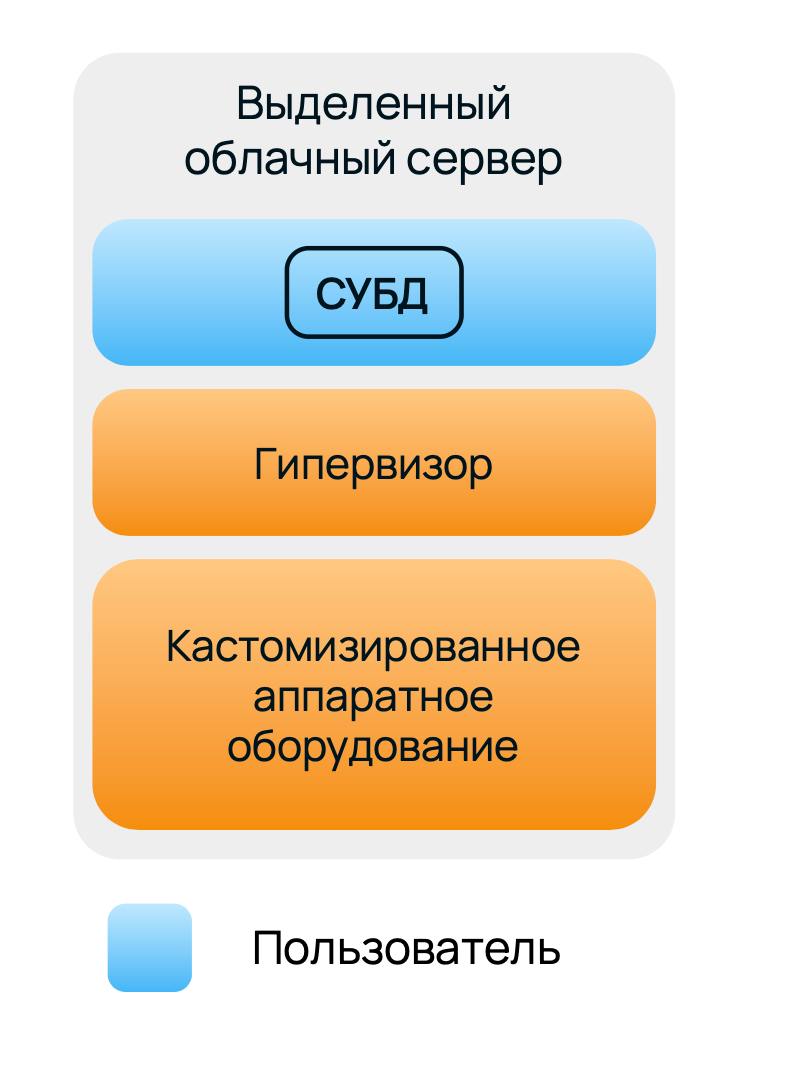
Здесь мы всегда имеем одну виртуальную машину размером почти с весь выделенный сервер. По сути, весь хост — одна нода кластера СУБД, в которой можно настроить и гипервизор, и ОС, и BIOS. На уровне железа можно подобрать комплектующие, которые наиболее оптимальны для той или иной СУБД. И больше нет конкуренции за общие компоненты системы вроде пропускной способности сети или производительности дисковой подсистемы хоста.

Другими словами, все уровни инфраструктуры от сокетов процессора и планок RAM до кастомных настроек в KVM служат одной цели — повышению производительности СУБД. Эффективно ли это? В тестах мы получили показатели производительности почти в 10 раз превосходящие стандартный подход DBaaS по таким параметрам, как TPS, IOPS, bandwidth.
В интерфейсе все просто — здесь все тот же конструктор, но вместо выбора конфигурации виртуальной машины можно подобрать выделенный сервер.
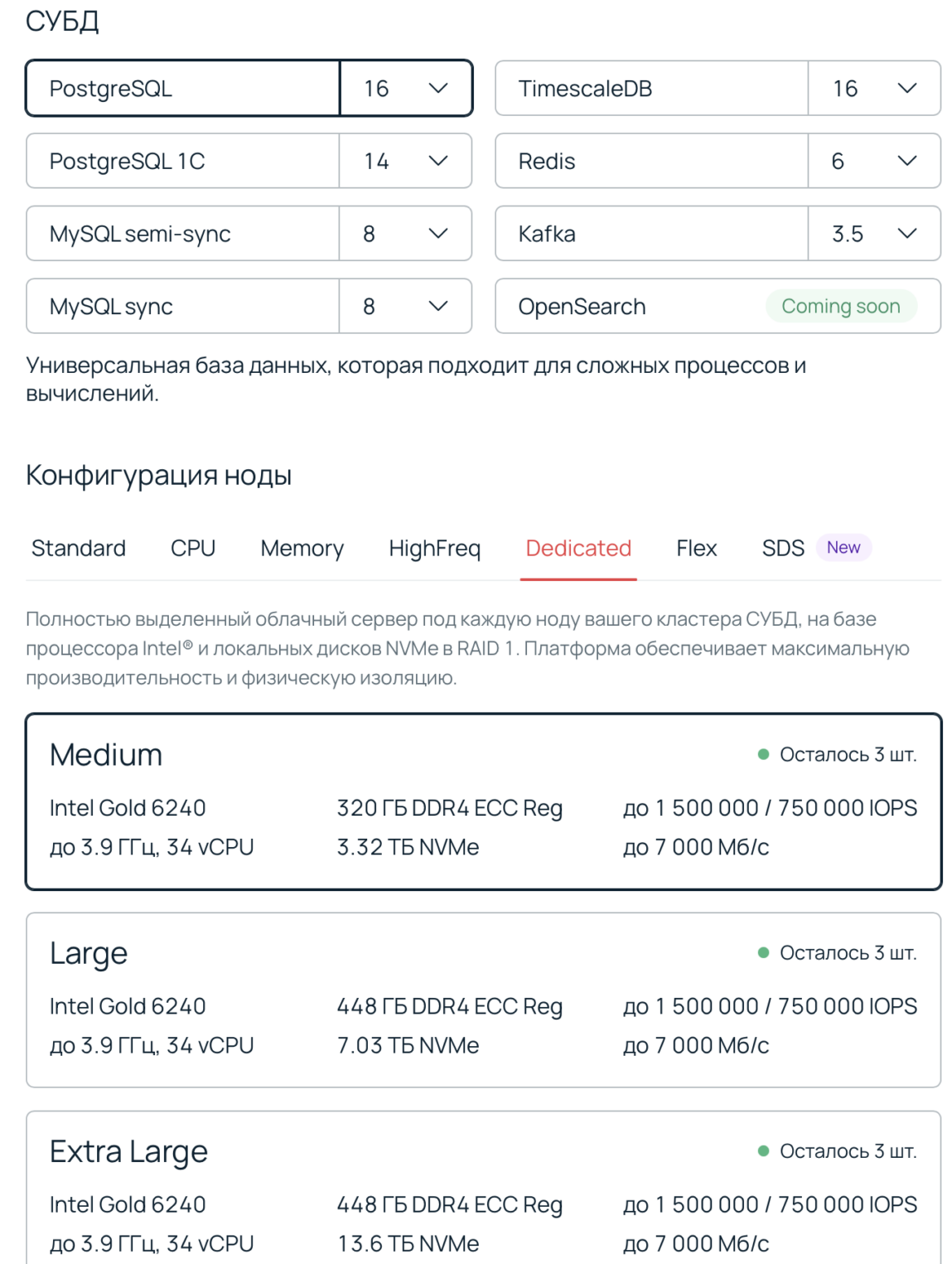
Приятный бонус к производительности: новая услуга получилась на 40% дешевле, чем классический вариант в облаке. Снизить цену получилось за счет предсказуемости. Клиент арендует сразу весь сервер, который точно будет использоваться для запуска СУБД, поведение и масштабирование которой заранее известно.





