

Привет, я Оля Ходаковская — ведущий продуктовый дизайнер облака Selectel. Я отвечаю за проектирование и развитие облачных продуктов: сетей, файрволов, балансировщиков, глобального роутера и логов — и лидирую такие UX-инициативы, как модель UX-зрелости и UX-бенчмаркинг.
В дизайн-процессе Selectel был формально описан этап измерения успешности дизайна, однако никто не знал, как именно ее измерять. В этой статье я расскажу, как мы решили эту задачу с помощью UX-бенчмаркинга. Будет много примеров и внутренней кухни!
Точка отсчета
Первой мыслью было смотреть на продуктовые метрики — количество платящих клиентов, количество денег, которые они приносят и так далее. Однако продуктовые метрики не позволяли прицельно оценить успешность дизайна панели управления по следующим причинам.
- На продуктовые метрики влияет множество факторов, особенно когда речь идет о B2B с заметным участием команды продаж. Показатели будут меняться, если мы привлекли большого клиента, выиграли тендер, повысили цены, провели успешную маркетинговую кампанию или, наоборот, привели не тех лидов — и все это не зависит от дизайна.
- Некоторые наши продукты бесплатны, поэтому невозможно напрямую оценить успешность фичей или сценариев в деньгах.
- Речь идет о дизайне панели управления, но она является не единственным интерфейсом управления инфраструктурой. Многие наши клиенты исповедуют подход Infrastructure-as-Code (IaC) и управляют инфраструктурой через API или Terraform.
Мы регулярно анализируем продуктовые метрики, однако кроме них была нужна простая и близкая дизайнерам UX-метрика, на которую мы могли бы непосредственно влиять.
Уверена, вы слышали о трех ключевых метриках юзабилити: результативности (Effectiveness), эффективности (Efficiency) и удовлетворенности (Satisfaction). Эффективность или Time On Task (время, за которое пользователь выполнил задачу) мы сознательно решили не отслеживать. Дело в том, что в технически сложном продукте она вступает в конфликт с реализацией новых фичей, которые нередко привлекают новых клиентов, но увеличивают время конфигурации. Хотя не исключено, что мы пока не нашли правильный подход к этой метрике.
Удовлетворенность — субъективную оценку процесса выполнения задачи пользователями — мы тоже отслеживаем, но в основном на уровне всей компании. На уровне отдельных продуктов — скорее эпизодически, когда нужно собрать дополнительный фидбек. Так что в качестве простой и близкой дизайнерам метрики для регулярного анализа мы выбрали результативность.
Как измерять результативность
Результативность — это то, насколько успешно пользователи справляются с той или иной задачей. По-другому метрику можно назвать Task Success Rate, Task Completion Rate или UX Conversion.
Task Success Rate рассчитывается по очень простой формуле: делим количество пользователей, успешно справившихся с задачей, на количество всех, кто начал выполнение задачи. Например, 10 000 пользователей начали создавать сервер — и 4 500 из них его создали. Получаем значение Task Success Rate = 4 500 / 10 000 = 45%. Изи.
Дальше начинаются сложности. Что считать задачей? Где ее начало и конец? Как собрать данные? С какой регулярностью? Как улучшать метрику? На все эти вопросы мы нашли ответы в рамках процесса, который назвали UX-бенчмаркингом.
Что такое UX-бенчмаркинг
UX-бенчмаркинг — это тип сравнительного количественного UX-исследования. Сравнение может происходить несколькими способами.
- Во времени. Например, значение метрики в первом квартале против значения метрики во втором.
- Между схожими продуктами. Например, Task Success Rate выделенных серверов против Task Success Rate облачных серверов.
- Между конкурентами. Например, результативность нашей формы заказа облачных серверов против результативности формы заказа облачных серверов нашего конкурента. Отмечу, что это сложное и дорогое исследование.
При этом UX-бенчмаркинг может быть:
- регулярным — раз в квартал, полугодие или год (в зависимости от частоты изменений интерфейса и влияния сезонных факторов);
- окказиональным — например, до редизайна и после редизайна.
Мы сравниваем значение Task Success Rate во времени.
В чем отличие от A/B-тестирования
Может показаться, что альтернатива UX-бенчмаркингу — это A/B-тестирование. И тот, и другой являются методами сравнительного количественного исследования, но есть нюанс. В UX-бенчмаркинге мы сравниваем одно и то же в разные периоды времени (например, конверсию формы заказа балансировщика в первом и во втором квартале), а в A/B-тестировании — разное в один и тот же период времени (например, разные варианты формы заказа сервера).
В некоторых компаниях все изменения катятся в прод через A/B. Однако в сложном B2B-продукте вроде нашего во многих сценариях не набирается статистическая значимость. В связи с этим на первый план для нас выходит качественная подготовительная работа: продуктовые и пользовательские исследования, ревью решений, юзабилити-тестирования, альфа- и бета-тестирования. Повышается важность пост-релизной работы: сбора фидбека и анализа метрик, в том числе нашей UX-метрики.
Как часто проводить бенчмаркинг
Мы анализируем данные по Task Success Rate поквартально: смотрим на изменения в сравнении с предыдущим кварталом (QoQ) и в сравнении с тем же кварталом прошлого года (YoY). Более частое измерение не учитывало бы сезонные колебания.
Однако даже от квартала к кварталу у многих фичей метрика стабильна (не считая нормальных флуктуаций ±3%): у нас длинные циклы разработки, поэтому изменения происходят нечасто, а небольшие перемены в интерфейсе, во всяком случае по отдельности, не оказывают заметного влияния на метрику. Нужно запастись терпением. На длинной дистанции регулярных наблюдений мы замечаем тренды.
Например, видим как метрика одного из продуктов, находившаяся в коридоре 45–50%, устойчиво, на протяжении нескольких кварталов не выходит из коридора 40–45%, либо эпизодически опускается ниже 40%. Это сигнал того, что клиенты стали хуже справляться с задачей, и совокупность изменений в интерфейсе за последние кварталы могла повлиять на деградацию метрики.
Что считать задачей при измерении метрики
На такой вопрос не будет единого ответа: это задача, а это — нет. Скорее, можно говорить о разных уровнях задач.
Есть микрозадачи на уровне отдельных фичей: создать порт, изменить шлюз подсети, добавить сервер в балансировщик. Обычно это очень простые формы из пары полей. Можно представить ключевые сценарии на уровне компании: клиент зарегистрировался → заполнил профиль → пополнил баланс → оплатил сервер. В то же время некая макрозадача всегда ведет к тому, что клиенту вообще-то нужно заработать деньги: у него свой бизнес, свои клиенты, ему важно, чтобы все работало стабильно и решались задачи его бизнеса.
Все эти задачи важны в разных контекстах: хотим сделать более удобной настройку сетевой связности — смотрим на сценарии в рамках управления сетями, хотим удерживать клиентов — работаем над задачами надежности сервисов.
В процессе UX-бенчмаркинга мы не смотрим на микроконверсии, потому что обычно у них очень высокие показатели из-за простоты самих микрозадач. Верхнюю границу мы проводим там, где заканчиваются наши возможности отследить действия пользователя. Если после успешного создания сервера клиенту понадобится продолжить настройку приложения на своей стороне, мы не сможем это отследить. Значит, наша воронка заканчивается на успешном заказе сервера.
При этом, поскольку UX-бенчмаркинг — это сравнение не только во времени, но и между продуктами, то уровни задач должны совпадать. Мы понимаем, что в таком сравнении есть определенная условность: некорректно в лоб сравнивать конверсию в заказ основного платного продукта (например, облачного сервера) и конверсию в заказ вспомогательного бесплатного продукта (например, облачного файрвола). Тем не менее, UX-бенчмаркинг позволяет увидеть срез информации о том, как пользователи работают с разными задачами в панели управления, и задаться вопросом, почему у одной задачи Task Success Rate из квартала в квартал составляет 40%, а у другой — 10%.
Обычно задачи состоят из 2–5 шагов. Примеры задач:
- заказ облачного сервера: открыть форму заказа облачного сервера → успешно создать облачный сервер;
- создание группы пользователей: открыть форму группы → успешно создать группу → добавить хотя бы одного пользователя → добавить хотя бы одну IAM-роль (два последних шага могут быть выполнены в любом порядке);
- создать балансировщик нагрузки: открыть форму балансировщика → перейти на второй шаг → перейти на третий шаг → успешно создать балансировщик.
Как собирать данные
Для измерения Task Success Rate нужен инструмент, собирающий события по определенным триггерам в панели управления. Мы начинали с Amplitude, но переехали на self-hosted PostHog.
Все события проектируются UX-дизайнерами, имеют единообразный нейминг, описываются в Confluence по единому шаблону, добавляются в код панели фронтендерами и тестируются QA перед релизом. Когда пользователи триггерят события (например, кликают на кнопку), они отправляются в API PostHog. Мы видим их в панели PostHog, после чего собираем графики и дашборды для анализа этих данных.
Единообразный нейминг нужен для удобной работы с событиями: по имени ивента любому дизайнеру, аналитику, продакт-менеджеру должно быть понятно, что происходит. У нас они имеют «четырехчастную структуру».
- Источник события: panel_, site_, backend_.
- Продуктовое направление: cloud_, dedicated_, billing_.
- Продукт или фича: compute_, networks_, logging_.
- Объект и действие с ним: server-create-start, server-create-finish, target-group-server-add, firewall-port-assign
Таким образом, для Task Success Rate создания облачного файрвола мы построим воронку по событиям:
panel_cloud_networks_firewall-create-finish / panel_cloud_networks_firewall-create-start
Для корректности сравнительного анализа всех воронок (график типа funnel) выставляются единые настройки.
- Настройка 1. Фильтрация внутренних и тестовых пользователей — чтобы сотрудники компании не аффектили пользовательские данные.
- Настройка 2. Агрегация по уникальным пользователям. Пользователь, успешно прошедший воронку более одного раза за период, будет посчитан только один раз, поскольку уже понятно, что он справился с задачей,
- Настройка 3. Окно конверсии составляет 14 дней. Если пользователь в течение 14 дней десять раз открыл форму заказа сервера и один раз его заказал, конверсия будет 100%, а не 10%. Это особенно важно для сложных услуг, где человеку нужно подумать, согласовать что-то с коллегами, принять решение. Если он не выполнил задачу сразу, то дело не в ней (возможно). Плюс это снижает влияние ситуаций, когда пользователь отвлекся, ушел на обед и закрыл форму, а потом открыл снова.
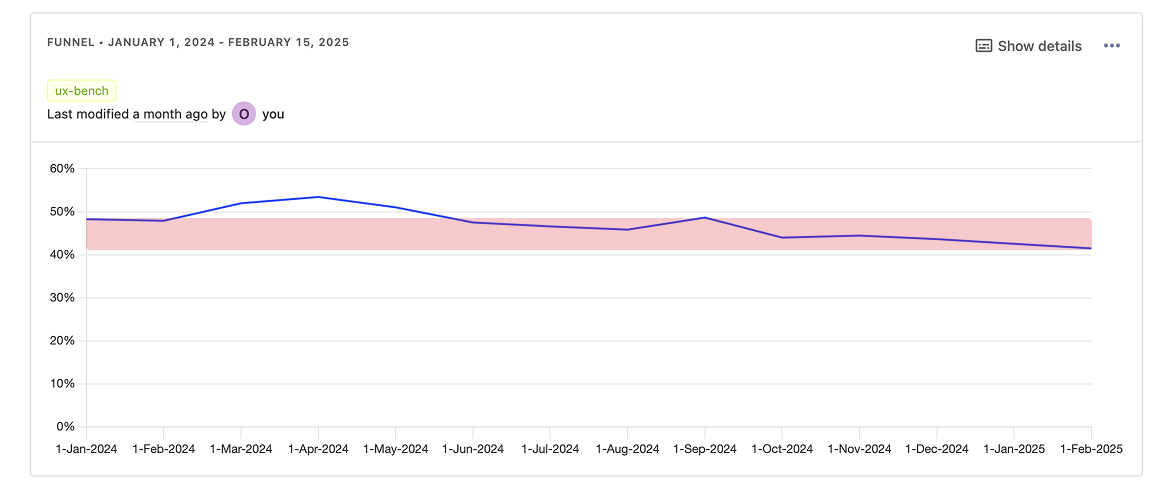
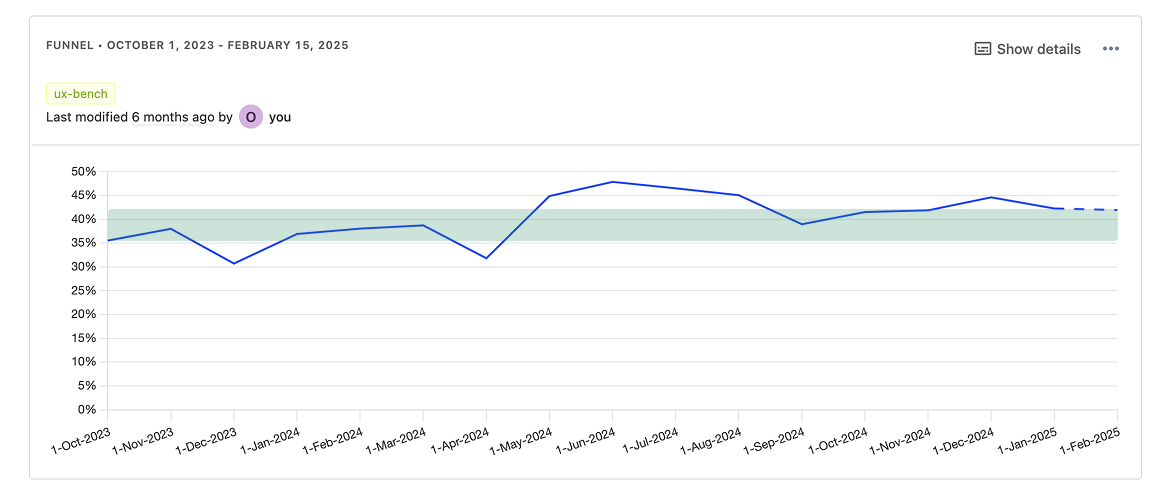
Как оценивать успешность метрики
Важным понятием в UX-бенчмаркинге является baseline, или базовый уровень. С этим показателем мы сравниваем значение Task Success Rate, чтобы оценить успешность выполнения задачи пользователем, понять, высокая она или низкая, снижается или растет.
Базовым уровнем может быть:
- первый замер, с которым мы сравниваем последующие;
- уже известное значение метрики у аналогичных продуктов;
- целевое ожидаемое значение метрики, которое мы выбираем для себя в качестве Objective Key Result (OKR) и которого хотим достичь после релиза нового дизайна или редизайна.
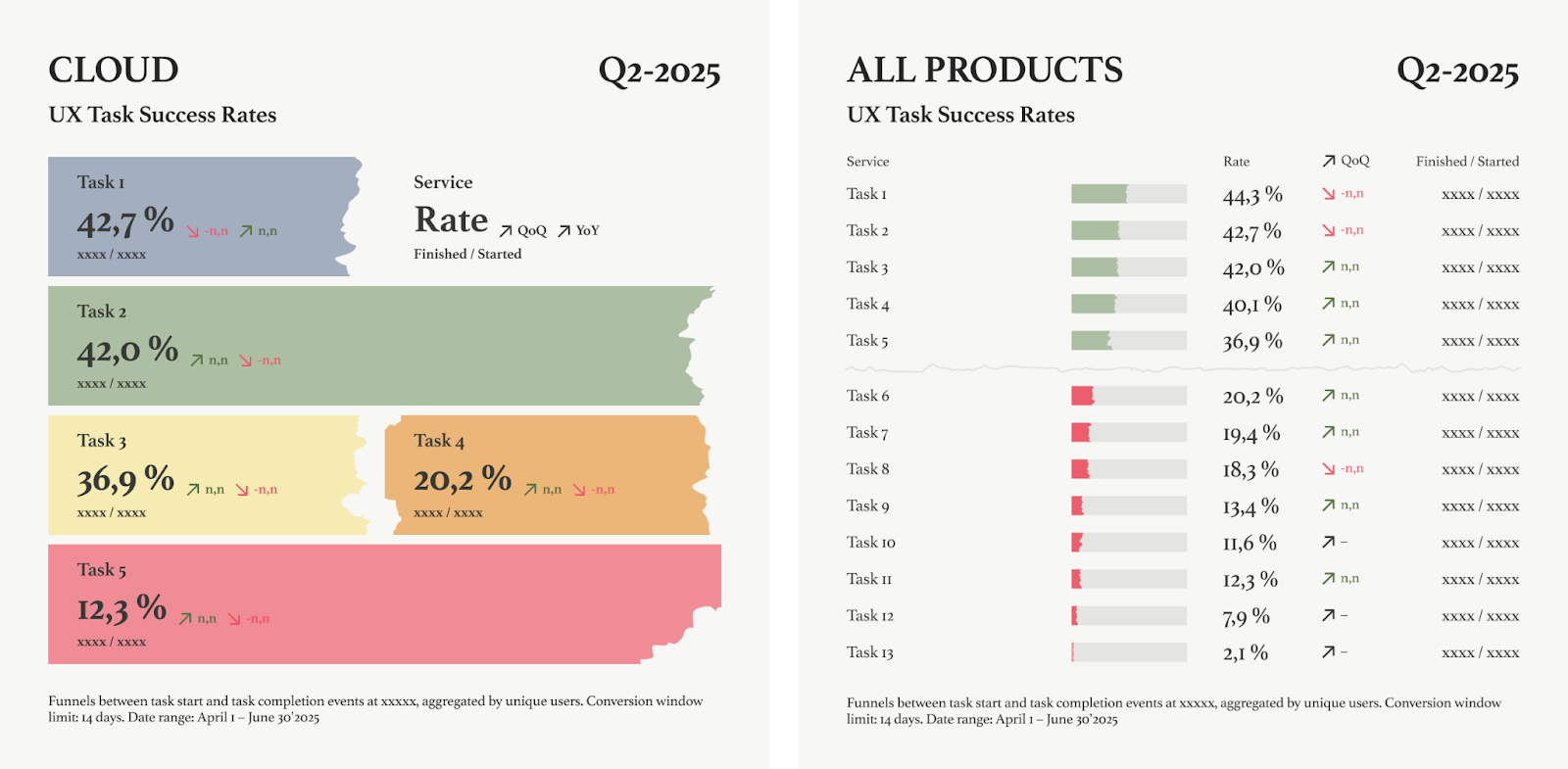
Изначально в нашем бенче было лишь несколько облачных сервисов: серверы, планы бэкапов, файрволы, балансировщики и файловые хранилища. Затем инициатива вышла за пределы облака, и другие команды тоже начали наблюдать за Task Success Rate своих продуктов в панели. Cейчас в бенче 13 сценариев, за которыми мы следим от двух кварталов до четырех лет.
На протяжении этого времени мы эмпирически вывели несколько базовых уровней Task Success Rate. Первый из них составлял 33% — мы использовали его на старте работы с бенчмаркингом. Тогда мы вывели его как среднее значение между Task Success Rate первых облачных сценариев. В тот момент как раз готовился к релизу облачный файрвол, и именно это значение мы выбрали в качестве OKR для него.
В итоге файрвол вышел в продакшен с Task Success Rate около 35% — и через год постепенно достиг стабильного уровня в 43%. В совокупности с хорошими продуктовыми метриками и фидбеком пользователей это позволило высоко оценить успешность дизайна интерфейса этого сервиса. Аналогичным образом Task Success Rate плана бэкапов составил 36% и оказался выше базового уровня. В соответствии с этим можно сделать вывод, что пользователи хорошо справляются с настройкой плана бэкапов.
В то же время UX-конверсия формы заказа балансировщиков находилась на уровне всего 8% — сильно ниже базового уровня. Да, это платный сервис, и да, он значительно сложнее. Возможно, его конверсия никогда не будет такой же, как у простого файрвола. Однако очень низкое значение Task Success Rate стало важным сигналом того, что мы плохо решали задачу пользователей. Низкое значение метрики оказалось одним из аргументов для проведения исследования, последующих доработок сервиса на бэкенде и полного редизайна в панели по его итогам.
Сейчас в бенче 13 сценариев. Они четко разделились на две группы: хай-перформеры с Task Success Rate 35–45% и лоу-перформеры со значением метрики ниже 20%.
Текущие базовые уровни в связи с этим таковы:
- 48% — для ключевых сервисов, за которыми приходят клиенты;
- 33% — для базовых вспомогательных сервисов;
- 20% — для сложных сервисов и сервисов, которые нужны только определенным сегментам клиентов.
Возвращаясь к простым микросценариям вроде создания сети или заказа публичного IP-адреса, которые мы не отслеживаем в рамках UX-бенчмаркинга: для них обычное значение Task Success Rate составляет около 60%. Если бы мы включили их в общий бенч со сложными сценариями, то проиграли бы в его информативности.
Оптимизация метрики
Само измерение метрики — это лишь половина дела, констатация состояния as is. За получением метрики следует ее улучшение.
В примере с балансировщиком UX-бенчмаркинг помог нам выявить проблему и стал драйвером изменений. Мы провели большое продуктовое исследование: проанализировали данные по текущему использованию балансировщиков, провели интервью с пользователями и экспертами, изучили обращения в поддержку по балансировщику, исследовали конкурентов, выявили пул изменений, которые по нашей гипотезе должны улучшить конверсию, оценили стоимость доработок и приоритизировали их. Все по классике.
Мы реализовали часть ключевых изменений из нашей гипотезы (добавили L7-балансировку, поддержали LE-сертификаты и их автообновление, повысили прозрачность статусов), сделали редизайн, провели закрытое альфа-тестирование, исправили баги, выкатились в прод в бете, наблюдали и через три месяца вышли из беты.
Сейчас, через полгода после редизайна и через два года после начала исследования, мы видим первые результаты: х2 по клиентам, которые ежемесячно заказывают балансировщик через панель, и устойчивые +5 пунктов Task Success Rate (8% → 13%). При этом еще не все изменения из изначальной продуктовой гипотезы реализованы (не хватает логов и мониторинга), а мы по-прежнему ниже базового уровня 20%.
Что тут является фактором печали для продуктового дизайнера, так это невероятно долгие итерации. За два года мы не прошли даже одну итерацию по сервису балансировщика: у команды есть на в работе и другие сервисы, ресурс ограничен, а разработка дорогая. А что если мы не докрутили гипотезу или ошиблись? Надо очень много лет работать в компании, чтобы увидеть реальные результаты работы и пройти больше одной итерации изменений.
Однако печаль компенсируется большим набором сервисов. Пока нет ресурсов или не в приоритете развитие одного сервиса, идет развитие другого или создание нового — и везде UX-бенчмаркинг позволяет оценить успешность решения в панели.
Дополнительные метрики в бенчмаркинге
В рамках бенчмаркинга можно замерять и иные метрики, например удовлетворенность. На уровне компании такой бенч проводится раз в полгода с помощью регулярного опроса.
По отдельным задачам мы не включаем удовлетворенность в бенчмаркинг, потому что делаем такой замер лишь эпизодически, чтобы собрать больше фидбека по новому или проблемному сценарию. Для этого мы используем контекстные опросы, всплывающие в панели по триггеру (например, через 20 секунд после успешного заказа облачного файрвола).
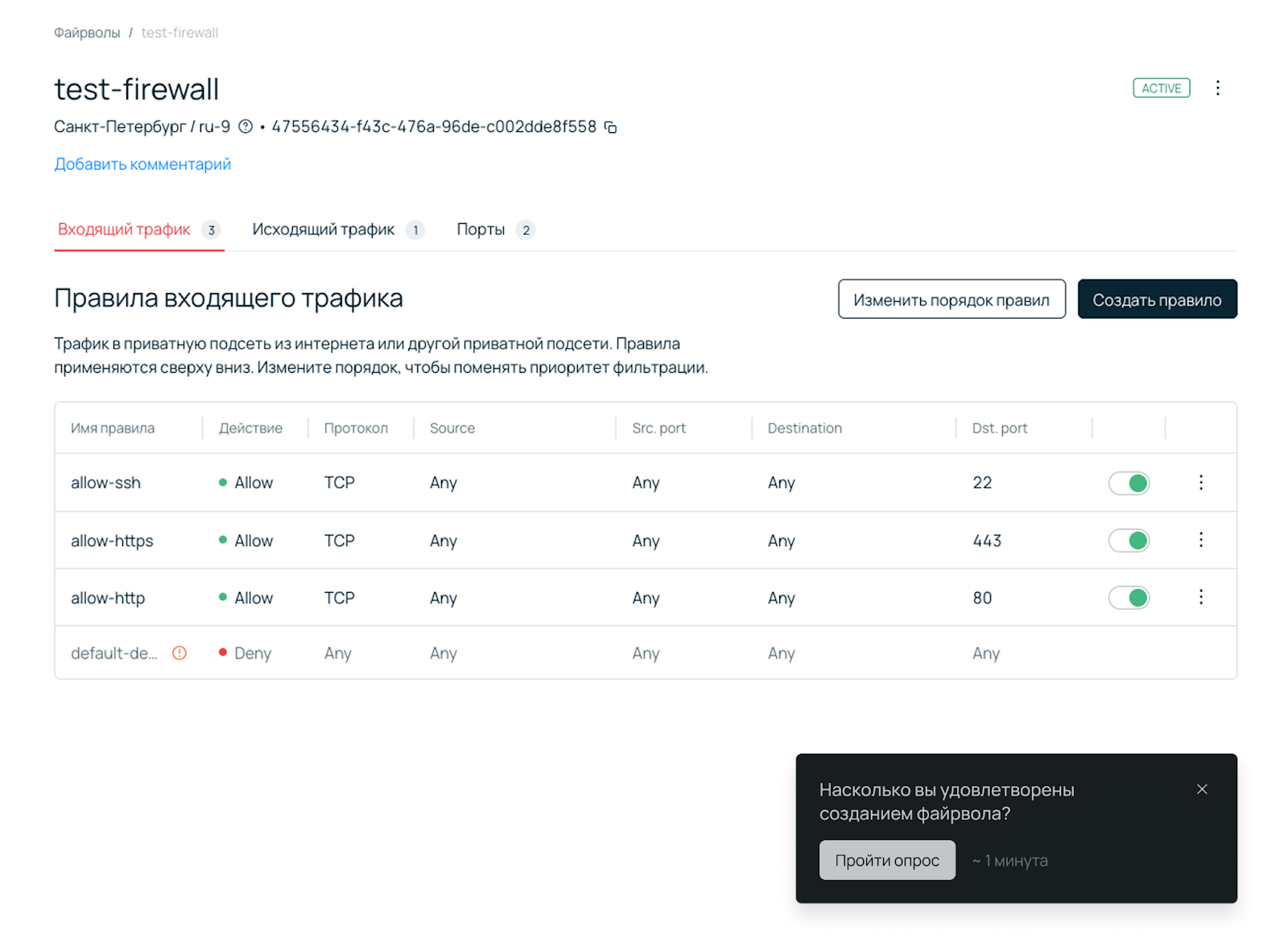
Мы используем метрику Customer Satisfaction Score (CSAT), которая предполагает один основной вопрос («Насколько вы удовлетворены созданием облачного файрвола?»), оценку от 1 до 5 и дополнительный открытый вопрос («Расскажите, почему вы поставили такую оценку»), если оценка 3 и ниже.
CSAT рассчитывается как отношение количества пользователей, поставивших оценку 4 и 5, к общему количеству проголосовавших пользователей. Например, если проголосовало 1 000 пользователей, 870 из них поставили оценку 4 или 5, значит CSAT = 870 / 1000 = 87%.
При этом в панели есть строгое ограничение по опросам, чтобы не было негативного эффекта от всплывающих окон. Один пользователь может видеть опросы не чаще одного раза в квартал.
Мы запускали контекстные опросы по сценариям создания облачного сервера, файрвола и балансировщика. К примеру, по файрволу CSAT был очень высоким (на уровне 92%), что коррелировало и с его хорошим результатом по Task Success Rate, а по серверам — около 83%. Однако самый ценный фидбек был от клиентов, поставивших 3 и ниже, когда они объясняли низкую оценку. Это позволило запланировать немало улучшений.
Презентация и рефлексия: как использовать результаты бенчмаркинга
Нередко я наблюдаю, как роль UX-дизайнера сводится к внесению изменений в UI по заданию от менеджера продукта или разработчиков. К сожалению, немало дизайнеров поддерживают это положение и говорят: «То, как фича устроена под капотом, — не моя ответственность, это ответственность разработчика» или «Метрики — не моя ответственность, это ответственность менеджера продукта».
UX-бенчмаркинг — одна из возможностей взять на себя больше ответственности за то, что делаешь. Не просто сделать и сказать «получилось классно, поверьте на слово», а в численном выражении показать, классно или нет. Да, далеко не весь UX можно измерить. Нередко мы только опосредованно можем что-то понять из продуктовых метрик и опросов удовлетворенности. Однако быть классным всегда лучше, чем казаться.
В связи с этим немаловажной частью процесса UX-бенчмаркинга становится регулярная рефлексия и презентация результатов, причем не только позитивных, но и негативных. Обнаружение проблемы — первый шаг к ее исправлению.
Что мы делаем, чтобы UX-бенчмаркинг был важным и заметным процессом?
- Ежеквартальная встреча проектировщиков продуктового направления для обсуждения результатов очередного бенча и шагов по оптимизации метрики.
- Ежеквартальная публикация итогов бенча в тематическом корпоративном канале: визуализации результатов и описание того, какие изменения мы видим, что хорошо, что плохо, и какие действия в связи с этим мы предпринимаем.
- Промо процесса среди UX-дизайнеров и включение новых сценариев в общий бенч.
- Повышение awareness среди стейкхолдеров (тимлиды, менеджеры, CTO, CPO). Ссылаемся на метрику в обсуждениях и демо, показываем скрины из PostHog, используем в качестве аргумента при приоритизации и планировании и даже включаем в персональные и командные OKR.
В качестве итога отмечу, что UX-бенчмаркинг позволяет объективно оценивать успешность дизайна или редизайна продукта, выявлять задачи, с которыми пользователи плохо справляются, инициировать исследование проблемы, улучшение проблемных воронок. А еще — реально, не на словах, улучшать продукты.
Кроме того, UX-бенчмаркинг повышает видимость и роль UX/продуктового дизайнера в команде, продукте и компании в целом. Дизайнер влияет на роадмап команды и становится агентом, драйвером изменений в продукте.





