Настройка бэкапов в S3 через Microsoft SQL Server без скриптов и стороннего ПО
В этой инструкции разберемся, как создать и настроить контейнер в панели управления, а также как настроить сохранение в него резервных копий через Microsoft SQL Server.
Меня зовут Даниил, я дежурный системный инженер в Selectel. Но так было не всегда. Несколько лет назад я работал системным администратором в маленькой компании. И в какой-то момент мы решили внедрять 1С. А так как все вокруг у нас было на Windows, выбор пал на Microsoft SQL Server. Связка казалась самой очевидной и простой. В то время опыта у меня было маловато, многого я не знал, но прекрасно понимал, что резервное копирование — наше все. Так я без должного опыта занялся настройкой бэкапирования через MS SQL. Путь оказался не самым простым, поэтому я решил поделиться с новичками набитыми шишками и полученным опытом.
Как у меня не сложилось с FTP/SFTP
Начать я решил со знакомого FTP/SFTP. В ходе экспериментов с ним выяснил несколько неприятных моментов. Это устаревший протокол, который в принципе не предназначен для передачи больших файлов. К тому же, в случае обрыва он не восстанавливает передачу файлов автоматически. Мало того, что сам способ не очень удобен, так еще и работало все крайне нестабильно. В итоге решил отказаться от FTP/SFTP и разобраться, что ж за протокол такой S3.
Начал знакомиться с объектным хранилищем. В лабораторных экспериментах все работало максимально стабильно. Не устраивала меня только необходимость использовать сторонний софт, который никак не сообщал о своих проблемах. Из-за этого мы получали две точки отказа, что никого не устраивало. Но теперь все хотя бы стабильно работало и появилось логирование — уже прогресс.
Читая документацию Microsoft SQL Server, обнаружил, что он умеет делать резервные копии на S3. Начал разбираться — и да, действительно, начиная с версии 16.0 он умеет напрямую загружать копии в хранилище.
Настройка объектного хранилища и выдача прав
Создание и настройка контейнера
Если вы умеете создавать и настраивать объектное хранилище, то здесь я вряд ли расскажу вам что-то новое. Эта информация, скорее, для новичков. Таких, каким был я несколько лет назад.
1. Переходим в панель управления и выбираем нужный нам проект (или создаем новый). Идем в раздел Объектное хранилище и нажимаем кнопку Создать контейнер.
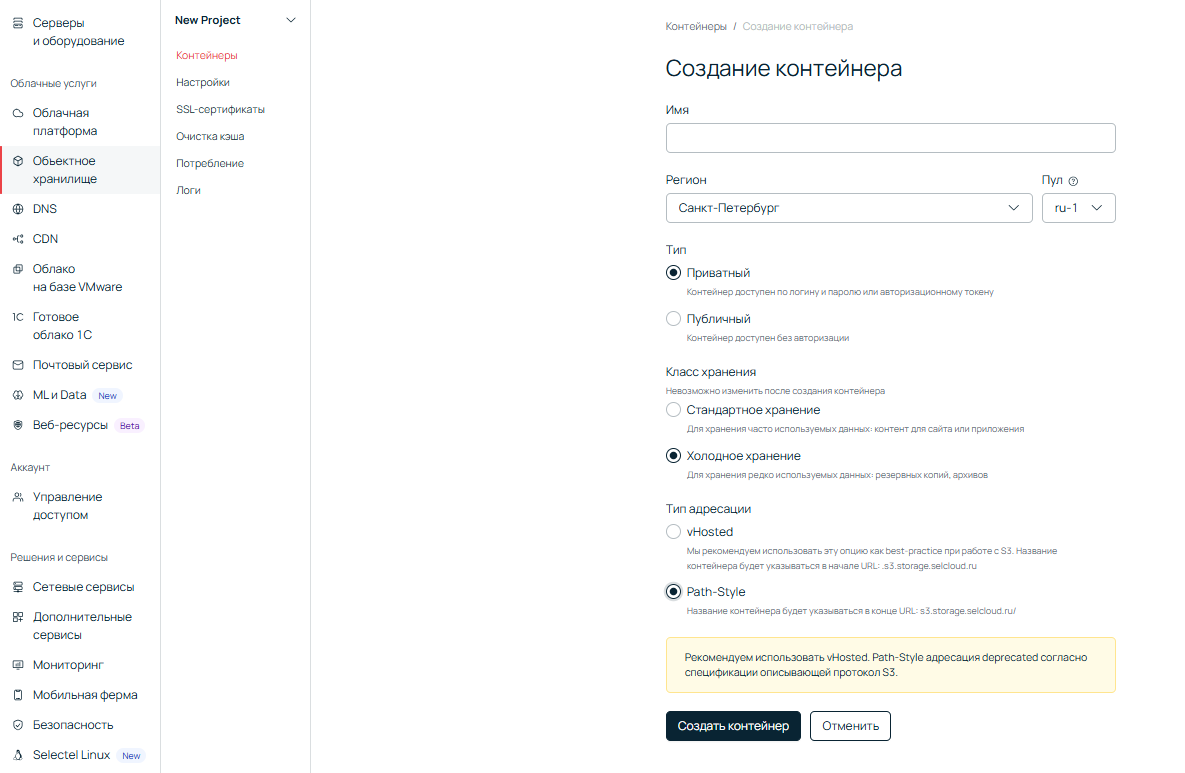
Для нужд резервного копирования оптимальным вариантом будет приватный бакет с холодным хранением. Бакет со стандартным хранением больше подойдет для сайта — к примеру, чтобы не хранить фото на сервере сайта, можно использовать ссылку на бакет. А там и до CDN недалеко.
2. Теперь осталось выбрать адресацию. Есть два ее вида:
- v-Hosted — имеет вид <backup.domain.ru> и в документации S3 описывается как рекомендуемая,
- Path-style — имеет вид <domain.ru/backup>, описывается как нерекомендуемая.
Поскольку в проекте нет домена, можно использовать второй вариант.
3. После создания контейнера кликаем по его названию и переходим внутрь.
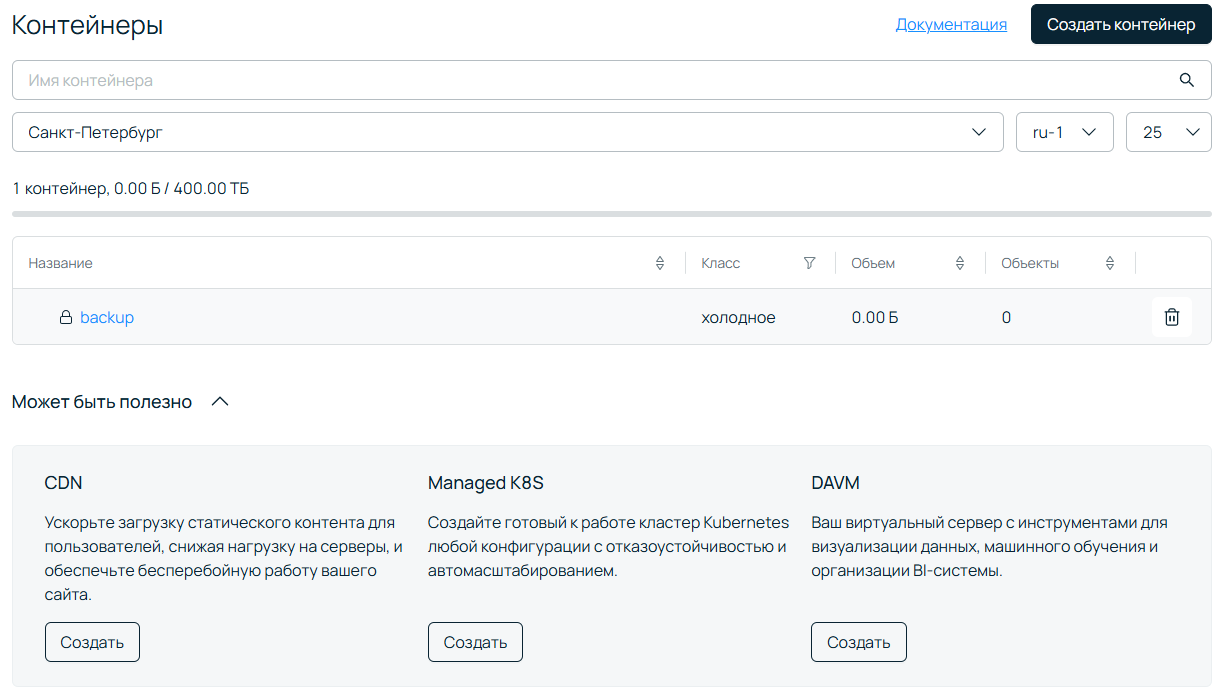
Нас может заинтересовать вкладка Конфигурация. Здесь можно прописать ограничения на бакет по количеству и суммарному объему файлов. Здесь же в разделе Время хранения мы можем указать, как долго будут храниться файлы после их загрузки. По истечении этого времени они будут удалены. Вот уже и авторотация копий готова.
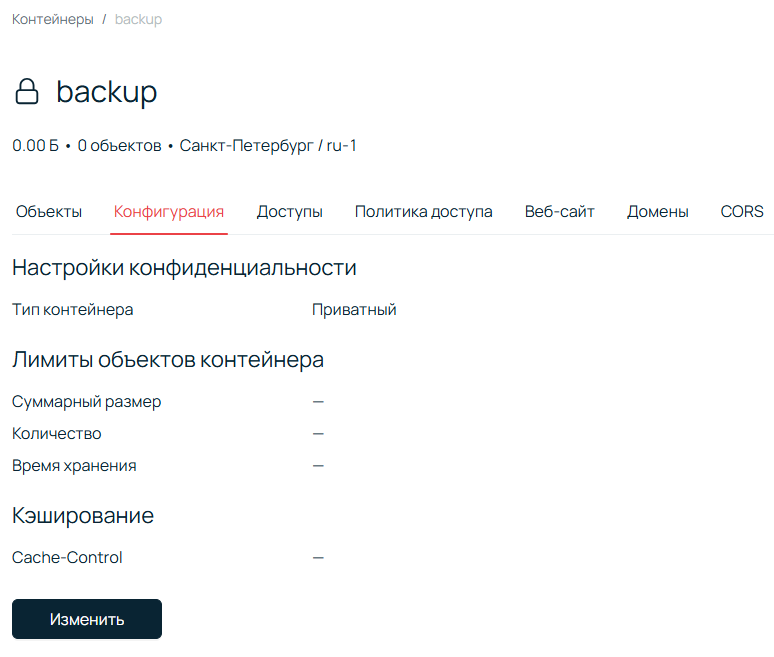
Настройка доступов
Следующая вкладка — Доступы. Здесь добавляем и настраиваем права на контейнер. Можно нажать на ссылку Сервисные пользователи, как на скриншоте ниже, а можно в левом боковом меню перейти в раздел Управление доступом. Тут уж как удобнее.
Если пользователей еще нет, вы увидите вот такую страницу:
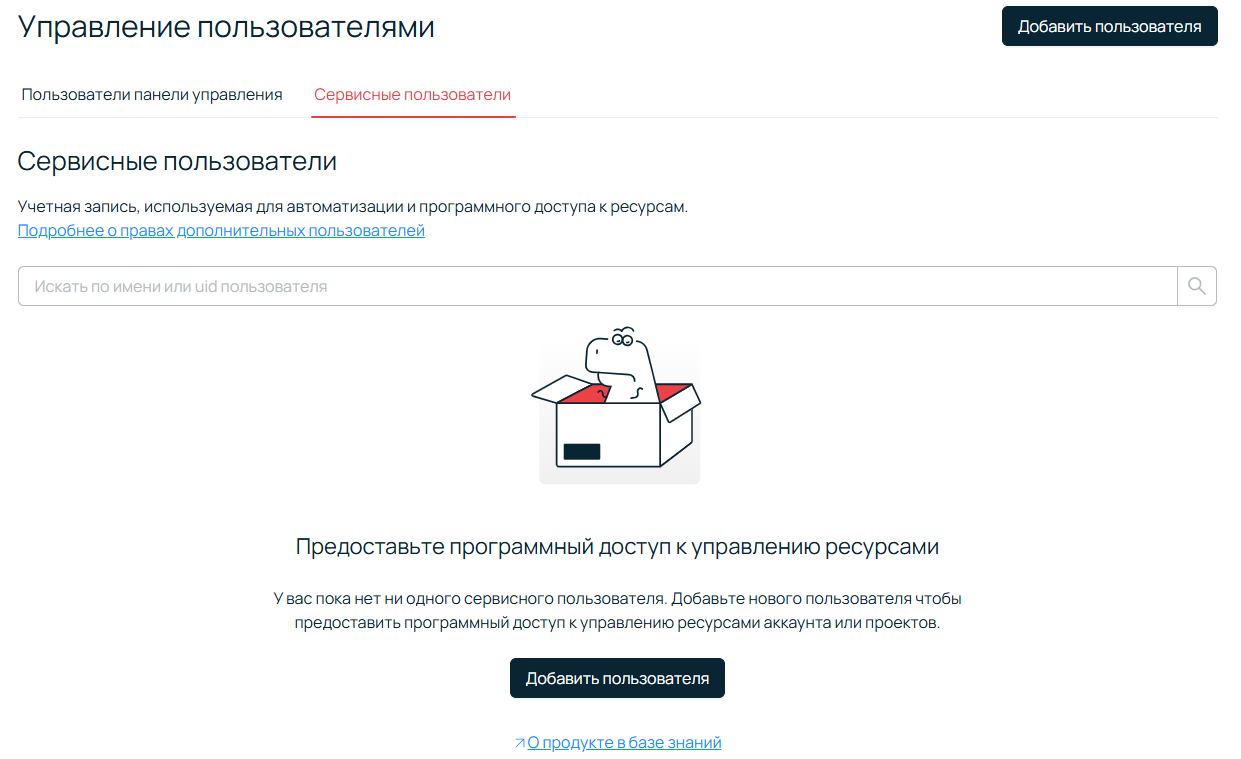
Добавление сервисного пользователя
Нажимайте Добавить пользователя → Сервисный пользователь. Так называется учетная запись без доступа в панель управления, но с доступом к API и другим инструментам. В нашем случае аккаунт нужен только для взаимодействия с файлами внутри бакета, поэтому прав пользователя достаточно. Выберите имя, придумайте пароль (или сгенерируйте его по кнопке), укажите из списка роль Пользователь объектного хранилища, выберите проект и нажмите Добавить пользователя.
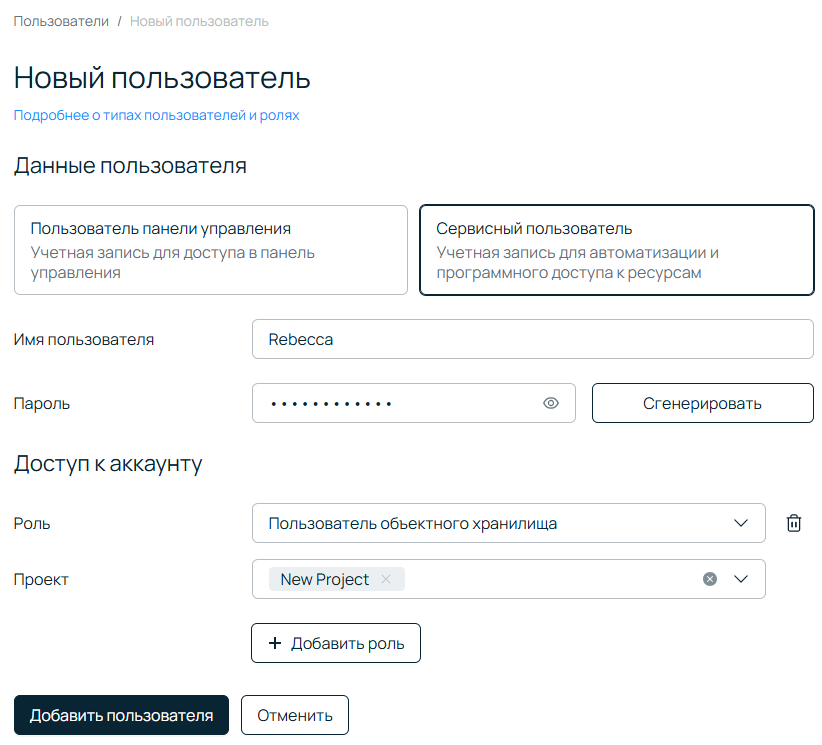
Если все сделано правильно, вы увидите вот такую страницу:
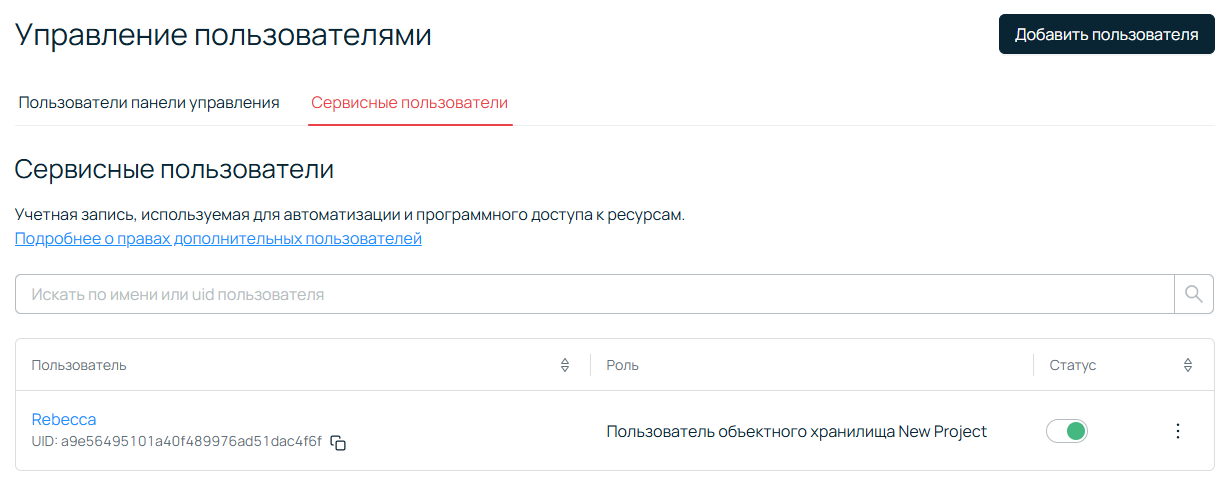
Кликайте по имени пользователя, переходите на вкладку Доступ, нажимайте Добавить ключ напротив надписи S3 ключи, а затем — кнопку Сгенерировать.
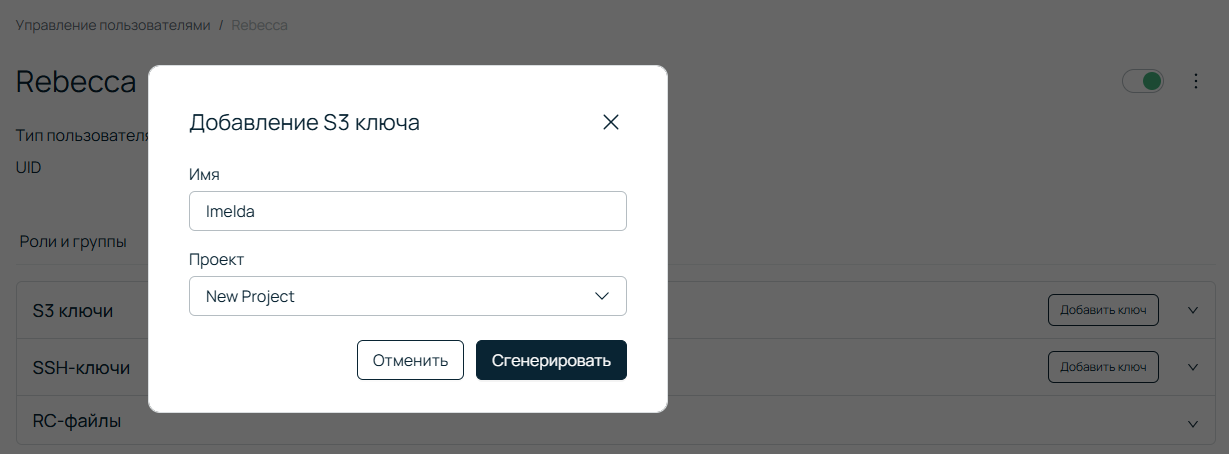
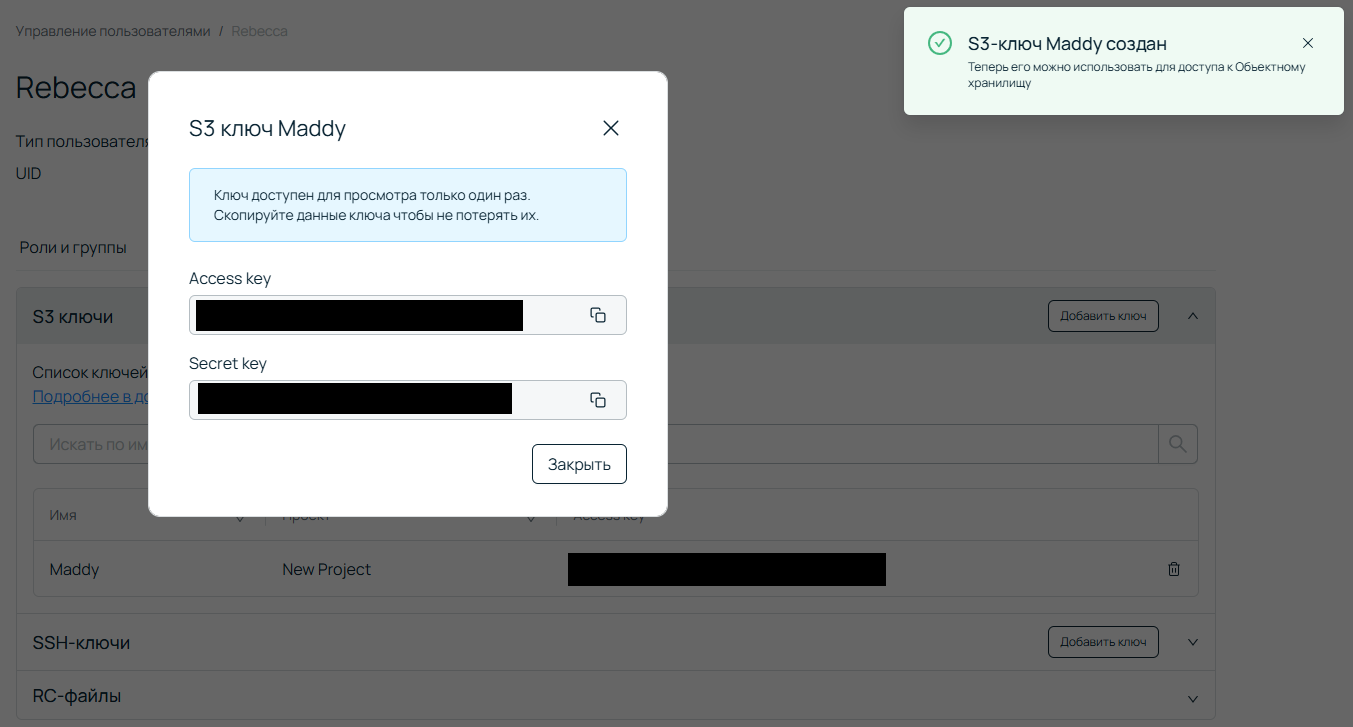
S3 ключ будет использоваться для подключения к бакету. У одного пользователя может быть несколько ключей, но все разграничение прав происходит именно по пользователю. То есть если один пользователь будет иметь несколько ключей, то доступы к бакетам у всех них будут едины. Рекомендую использовать один сервер, один бакет, один ключ. Во всяком случае, для резервных копий.
И вот мы получаем Access key и Secret key. Предупреждение о том, что ключ доступен для просмотра один раз, появляется не для красоты. Отнеситесь к этому ответственно, если не хотите потом заниматься настройкой доступов заново. Хост для подключения в моем случае — s3.ru-1.storage.selcloud.ru.
Настройка политик доступа
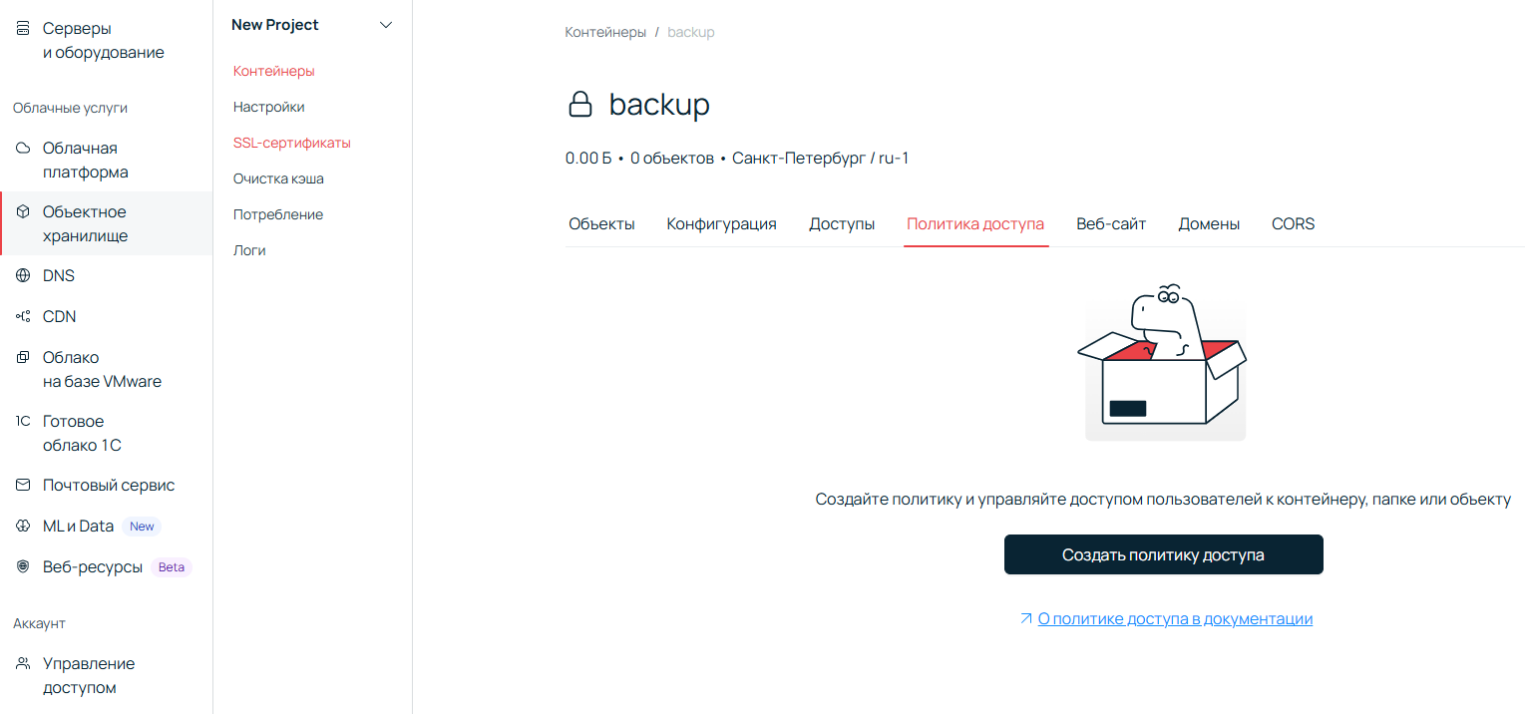
Следующий шаг — настройка доступа к бакету. Возвращаемся в раздел Объектное хранилище, выбираем наш контейнер, идем на вкладку Политика доступа и нажимаем Создать политику доступа.
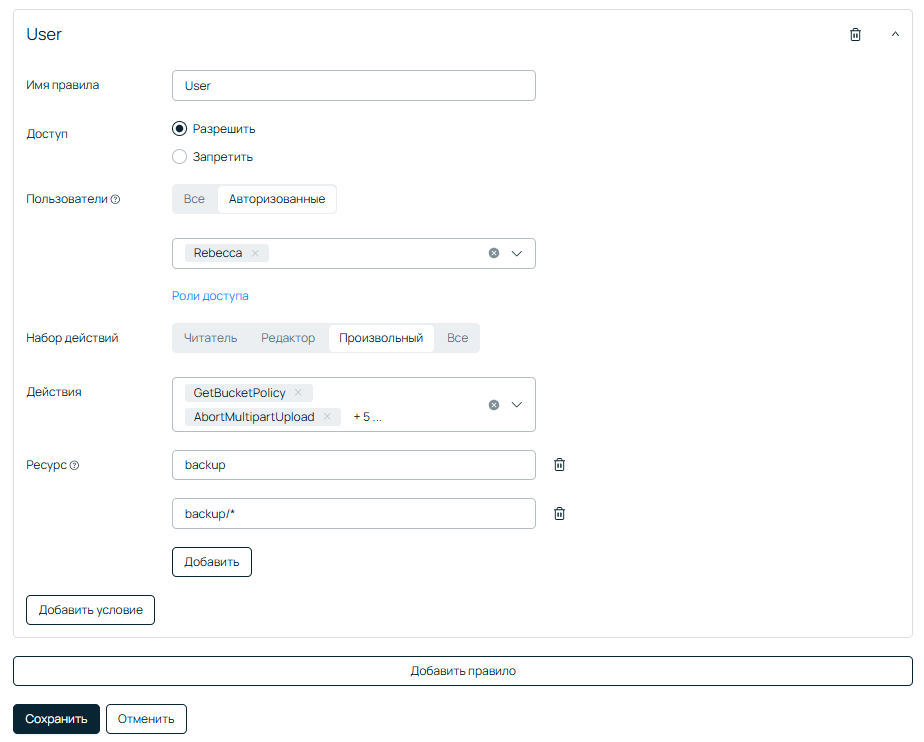
Первоначально необходимо добавить права администратору аккаунта, выбрав в пользователе название физического или юридического лица — собственника аккаунта. Без этого пункта доступа через веб интерфейс у администратора не будет, хоть и будет возможность прописать права себе. То есть сначала выбираем в разделе Пользователи себя и назначаем максимальные права.
Затем нажимаем Добавить правило, выбираем сервисного пользователя — и вот его уже в правах стоит несколько ограничить. Если этого не сделать, под данным пользователем можно будет редактировать настройки бакета. В нашем случае это категорически не рекомендуется, поэтому советую настроить минимально необходимые права для загрузки: GetBucketPolicy, AbortMultipartUpload, GetObject, PutObject, ListBucket, ListBucketMultipartUploads, ListMultipartUploadParts.
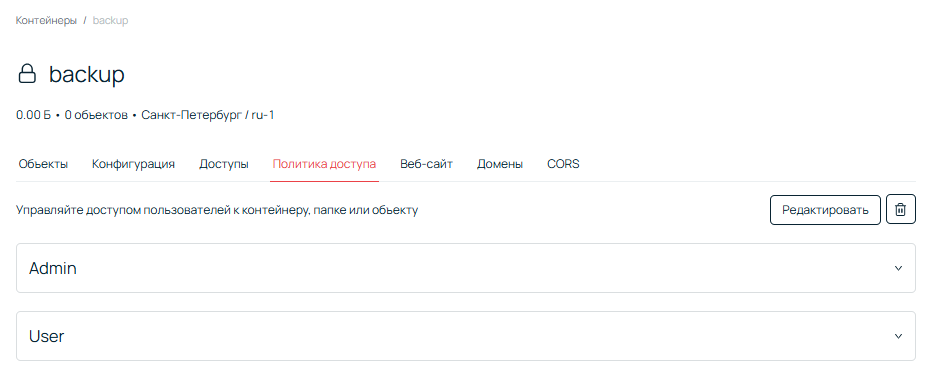
Когда права администратора и сервисного пользователя настроены, нажмите Сохранить. В итоге вкладка Политика доступа должна иметь вот такой вид:
Настройка Microsoft SQL Server
Что ж, с созданием бакета и настройкой прав разобрались. Теперь можно приступать к настройке СУБД. Делать это будем через запрос в консоль.
CREATE CREDENTIAL [s3://<endpoint>:<port>/<bucket>]
WITH
IDENTITY = 'S3 Access Key',
SECRET = '<AccessKeyID>:<SecretKeyID>';
Строка [s3://<endpoint>:<port>/<bucket>] используется для указания ссылки к бакету. В качестве endpoint используется домен без указания порта, поскольку он стандартный.
Строка IDENTITY указывает, что учетная запись используется для подключения к объектному хранилищу, поэтому ее важно оставить неизменной.
В строке SECRET используем данные, полученные на этапе добавления S3 ключа. У меня получилась такая команда:
use master;
CREATE CREDENTIAL [s3://s3.ru-1.storage.selcloud.ru/backup]
WITH
IDENTITY = 'S3 Access Key',
SECRET = '**************:****************'; #здесь укажите данные S3 ключа (количество звездочек не соответствует количеству символов в ключах)
В случае ошибок можно всегда удалить командой:
DROP CREDENTIAL [s3://s3.ru-1.storage.selcloud.ru/backup];
Есть разные способы настройки задач, но в нашем случае рассмотрим планы обслуживания как самые простые и наглядные. Для начала убеждаемся, что SQL Server Agent запущен.
Если вдруг он остановлен, достаточно будет нажать ПКМ → Start. Затем переходим в Management → Maintenance Plans и создаем новый.
Один план обслуживания может содержать множество «подпланов». Они могут пригодиться, например, для разных баз данных. Настоятельно советую использовать один план для нескольких баз данных, если у них одинаковый флоу копирования.
И вот мы создали пустой план обслуживания, внутри которого сразу создается подплан, в котором мы и будем работать. Поскольку инструмент позволяет визуально создавать схему, необходимо открыть визуальные элементы в разделе Toolbox в верхнем левом углу.
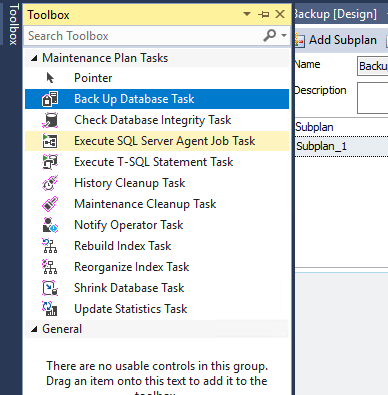
Теперь перетаскиваем необходимые нам действия в поле плана. Действия соединяем линией для обозначения порядка запуска задач.
Сразу рекомендую добавить проверку целостности базы данных и удаление старых копий. Одна задача может выполнять только одно действие, поэтому я добавил сначала создание копии на локальный диск, а после уже создание новой копии в S3. Да, это именно создание новой копии и сразу загрузка ее в S3, а не загрузка уже существующей копии.
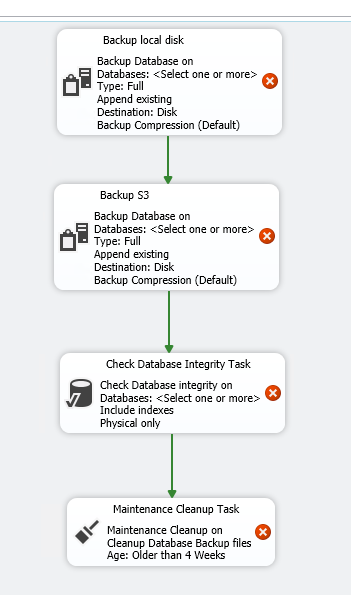
Настройка задачи в плане обслуживания
Сначала настроим создание копий на локальный диск. Для этого идем в раздел General → Databases и выбираем базы, которые будем копировать. Тип копии при этом полный, копирование осуществляется на диск.
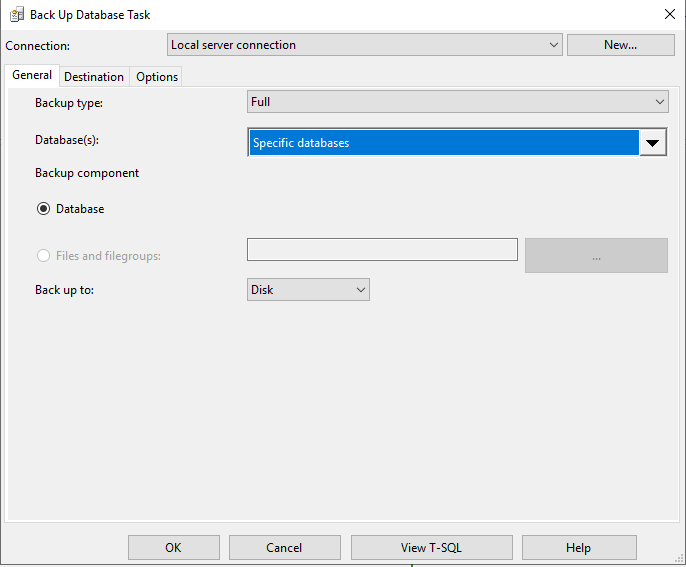
В разделе Destination нужно выбрать Create a backup file for every database и указать папку, в которую будут загружаться копии. Дополнительно можно выбрать создание вложенной папки для каждой базы, что я и рекомендую делать по умолчанию.
Настоятельно не советую использовать системный диск C:\ для хранения резервных копий. Это необходимо делать на отдельном диске с настроенными правами доступа. В данном случае диск C:\ я использую только для демонстрации.
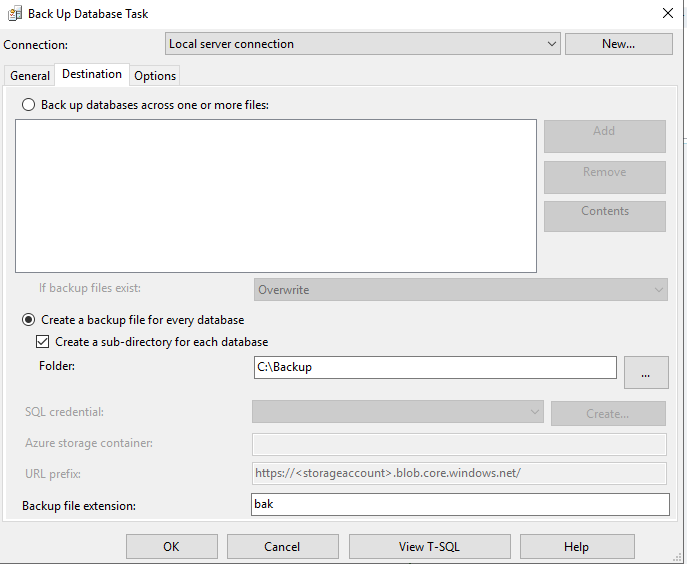
В разделе Options можно выбрать опции резервного копирования. Например, проверку контрольной суммы и целостности копии. При этом я дополнительно выбрал принудительно использование сжатой копии, поскольку это тестовый сервер с настройками по умолчанию.
Загрузка копии на S3
Открываем следующую по очереди задачу и на вкладке General в строке Back up to выбираем, что копирование будет не на диск, а на URL.
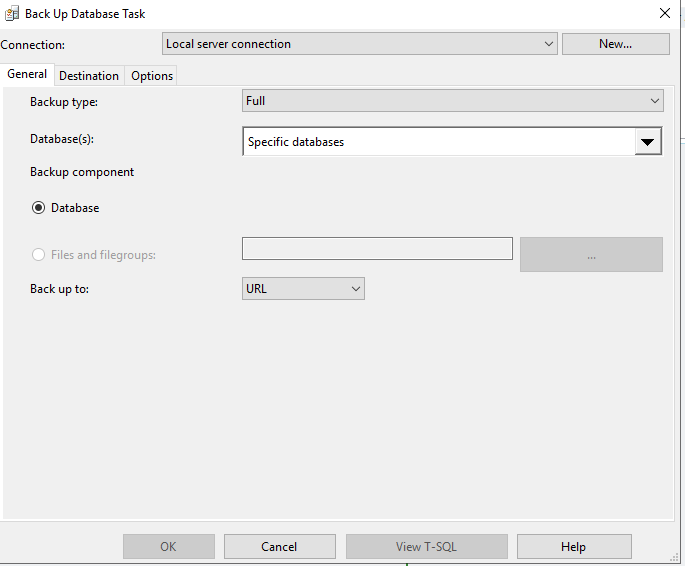
Теперь начинается интересное. В разделе Destination у нас появилась возможность выбора SQL credential. Выбираем созданный нами, он будет иметь вид s3://s3.ru-1.storage.selcloud.ru.
В разделе Azure storage container ничего не трогаем. Убедитесь, что поле URL prefix имеет вид s3://s3.ru-1.storage.selcloud.ru/backup. Здесь s3:// говорит о необходимости загрузки на в объектное хранилище, s3.ru-1.storage.selcloud.ru — ссылка на сервер, а все остальное (в нашем случае /backup) — путь к контейнеру.
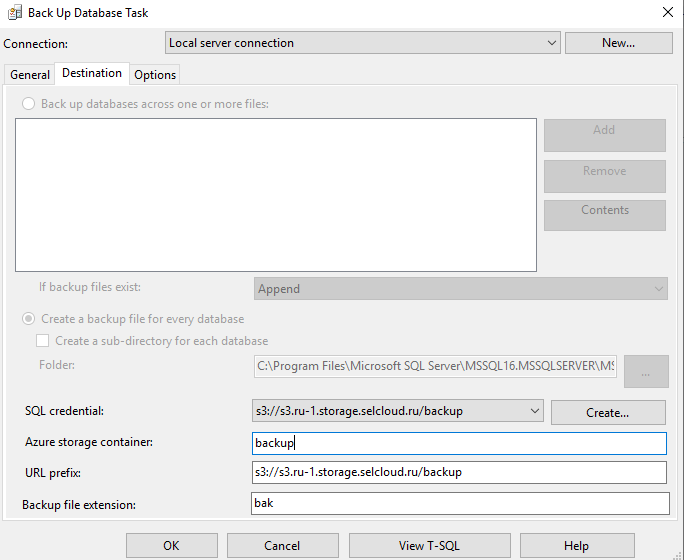
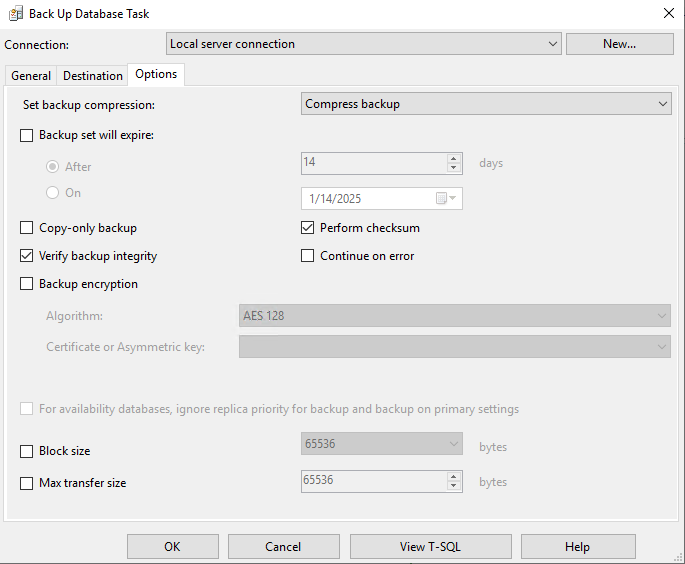
На вкладке Options у меня все по умолчанию: использовано принудительное сжатие, проверка контрольной суммы и целостности копии.
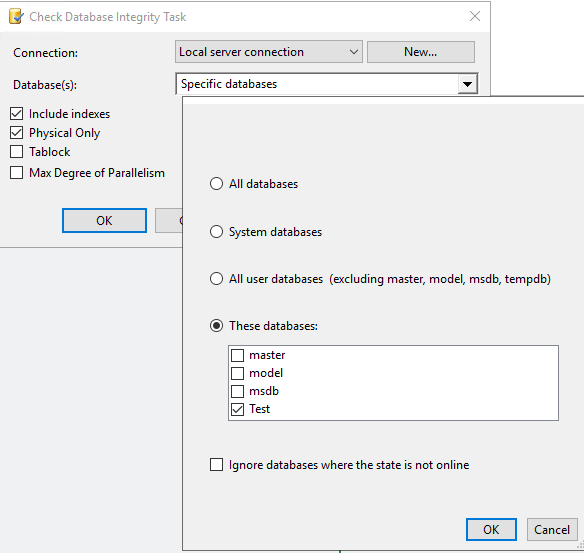
В задаче по проверке целостности базы базы необходимо только выбрать нашу БД (на скриншоте выбрана база Test). Остальное все можно оставить по умолчанию.
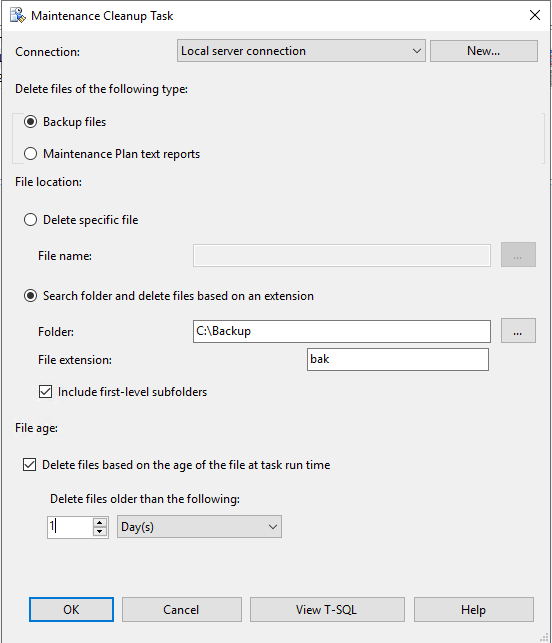
Очистка устаревших копий
Выбираем папку, не забывая, что на первом этапе мы использовали папку Backup. Автоматически создается папка с названием базы. В ней и будут расположены копии. Если план один и все базы будут копироваться по одному расписанию, можно указать общую папку и поставить галочку Include first-level subfolders. В таком случае SQL-агент будет удалять файлы и во вложенных папках от указанной вами директории.
Теперь указываем срок хранения. Для примера выбираем один день. Обратите внимание, что расширение файла нужно указывать без точки, иначе работать не будет.
Настройка расписания
Теперь выбираем наш подплан и пункт расписания, по которому он будет выполняться. Для каждого из подпланов нужно настраивать свое расписание.
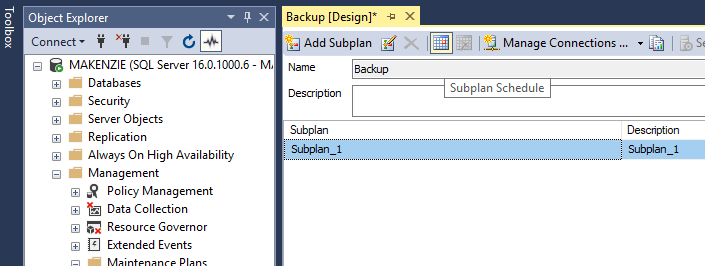
Поскольку много бэкапов не бывает, а база небольшая, указываю в расписании запуск каждый день в четыре часа утра.
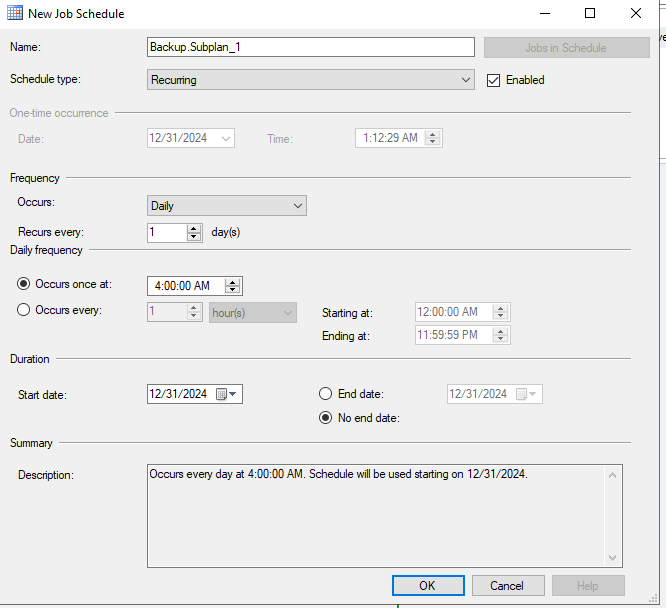
Теперь закрываем план и сохраняем. В разделе SQL Server Agent → Jobs появилась новая задача. А в Management → Maintenance Plans — новый план. Один подплан — это одна задача в агенте.
Проверка
Для проверки можно запустить напрямую задачу агента, а можно и весь план обслуживания, поскольку у нас подплан один. Если бы их было несколько, запустились бы все задачи одновременно.
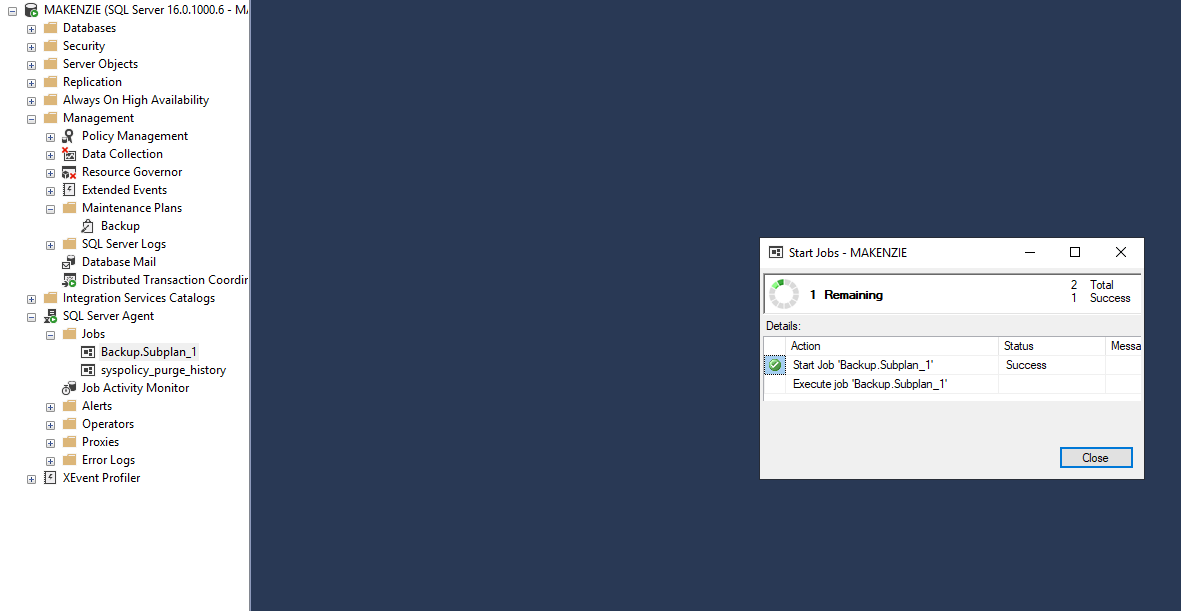
Если все было сделано правильно, задача завершится успешно. Проверить бакет можно через личный кабинет.
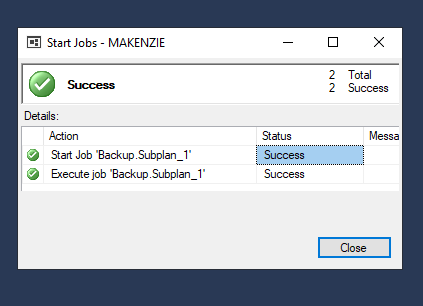
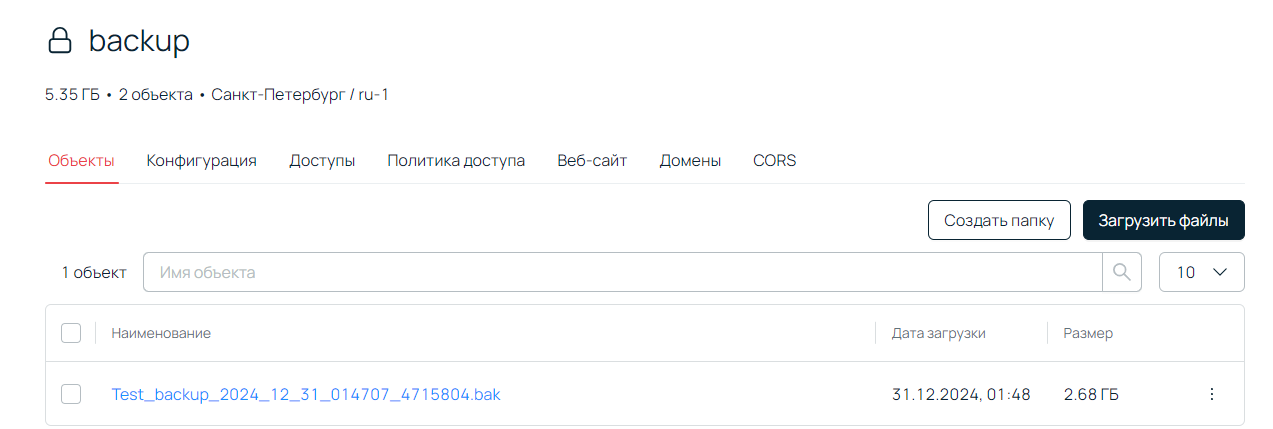
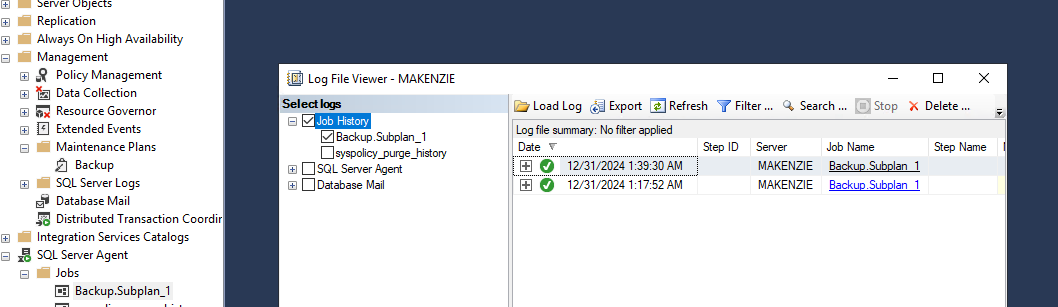
Если вдруг возникнут ошибки, можно посмотреть логи. Для этого нужно выбрать задачу в SQL server agent.
Восстановление из S3
Чтобы настроить восстановление резервной копии, необходимо указать прямую ссылку на файл, с которого оно будет выполняться. Все бы ничего, но названия генерируются автоматически по дате и времени создания бэкапа. При этом никакой возможности обзора хранящихся копий нет. Это не совсем удобно, поскольку приходится искать имя конкретной копии.
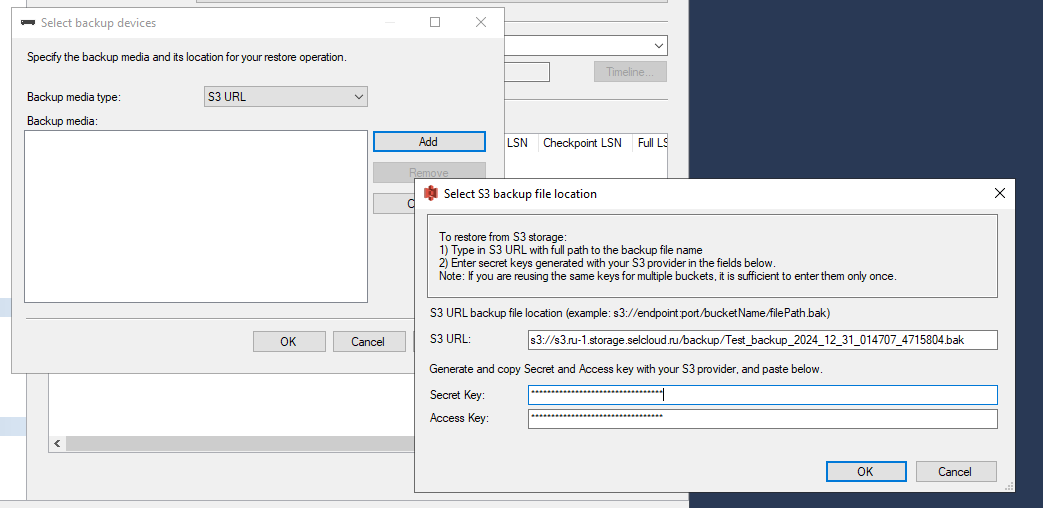
Само же восстановление происходит стандартно: выбираем базу, которую будем восстанавливать, и устройство, куда запишется бэкап. В типе устройства меняем файл на URL и указываем ссылку вида s3://s3.ru-1.storage.selcloud.ru/<название бакета>/<название файла>.
В моем случае URL выглядит так: s3://s3.ru-1.storage.selcloud.ru/backup/Test_backup_2024_12_31_014707_4715804.bak
Теперь вводим сначала Secret Key и Access Key. Важно их не перепутать местами, поскольку обычно всюду указывается сначала Access key, а затем Secret key. Сложно сказать, почему именно в данном меню их поменяли местами, но как есть.
Особенности
При загрузке через URL в рамках одной задачи можно загружать бэкапы только в один бакет/папку. Хотя при выборе жесткого диска есть возможность сохранения в подпапку с названием базы, что создает нормальную и удобную иерархию. В целом, при сохранении на URL это терпимо. Но когда имеется несколько баз и большое количество бэкапов, это становится крайне неудобно и загружено.
URL-префикс возможно использовать только в нижнем регистре. Хотя на самом S3-ресурсе регистр имеет значение, и если у вас в хранилище бакет называется Backup, то при вводе URL в задачу он будет иметь вид s3://s3.storage.selcloud.ru/backup/.
Вроде бы логично, что нужно проверить, чтобы бакет был в идентичном регистре. Но для меня это оказалось неочевидно и я долго мучался, смотря на ошибку с некорректным путем. Соответственно, пришлось использовать все названия в нижнем регистре.
Подозреваю, что проблема исключительно в визуальном интерфейсе.
Итоги
Работая с 1С, хотелось найти способ безопасно и без сторонних программ загружать резервные копии в облако. И, кажется, это самый безопасный и достаточно надежный способ, который я обнаружил.