Мониторинг в K8s с помощью Prometheus
В этой инструкции рассказываем об основных принципах мониторинга кластера Kubernetes при помощи Prometheus.
Введение
Современный мир IT-технологий ставит перед разработчиками и администраторами высокие требования к надежности и доступности сервисов. Для достижения этих целей необходимо контролировать состояние инфраструктуры и быстро реагировать на возникающие проблемы.
В качестве инструмента мониторинга часто используется Prometheus, который предоставляет средства сбора, хранения, визуализации и анализа метрик. Prometheus — это система мониторинга с открытым исходным кодом, созданная компанией SoundCloud для обеспечения мониторинга и оповещения об изменениях в приложениях и инфраструктуре. Он имеет гибкую архитектуру и может быть настроен для сбора метрик с различных источников, включая серверы, рабочие станции, коммутаторы и системы управления контейнерами, такие как Kubernetes.
В данной статье мы рассмотрим основные компоненты Prometheus, задачи и сценарии его использования в Kubernetes и научимся разворачивать мониторинг кластера и приложения в нем. Также мы изучим процесс запуска Prometheus сервера в K8S, настройку мониторинга Kubernetes через Prometheus, установку Grafana и другие аспекты использования Prometheus.
Основные компоненты Prometheus
Основные компоненты Prometheus включают сервер Prometheus, Alertmanager и Prometheus экспортеры.
Сервер Prometheus и его компоненты
Сервер Prometheus состоит из нескольких основных компонентов, которые взаимодействуют между собой для обеспечения сбора, хранения и представления метрик.
Первый компонент — это TSDB (Time-Series Database), который предназначен для хранения временных рядов метрик. В нем каждый временной ряд представлен в виде набора пар (timestamp, value), где timestamp — это временная метка, а value — значение метрики в этот момент времени. TSDB обеспечивает эффективное хранение метрик и быстрый доступ к ним для последующей обработки и анализа.
Второй компонент — Retrieval worker, отвечает за сбор метрик. Prometheus собирает метрики с помощью механизма pull, который работает следующим образом: каждый определенный интервал времени Prometheus отправляет запрос к конечной точке метрик, чтобы получить последние значения метрик. Retrieval worker отвечает за выполнение этих запросов и получение метрик от целевых приложений.
Третий компонент — HTTP server, представляет собой API для выполнения запросов к сохраненным в TSDB метрикам. С помощью HTTP сервера можно выполнить запрос на получение метрик за определенный период времени, а также применить функции агрегации, фильтрации и преобразования для полученных данных.
Alertmanager
Alertmanager — это компонент системы мониторинга, который отвечает за обработку и отправку оповещений на основе правил оповещения, заданных в конфигурации Prometheus. Alertmanager позволяет отправлять оповещения на различные каналы связи, такие как электронная почта, Slack, Telegram и т. д.
Экспортеры Prometheus
Экспортеры Prometheus — это компоненты, позволяющие собирать метрики с различных источников, которые не могут быть собраны непосредственно сервером Prometheus. Например, Node Exporter позволяет собирать метрики с операционной системы хоста, на котором запущены контейнеры, а Blackbox Exporter позволяет проверять доступность сервисов, работающих на удаленных хостах.
В целом, Prometheus предоставляет широкие средства мониторинга, которые позволяют собирать и анализировать метрики с различных источников. Он имеет гибкую архитектуру и может быть настроен для сбора метрик с систем управления контейнерами, таких как Kubernetes. Давайте перейдем от слов к делу и развернем тестовый мониторинг для нашего кластера и приложения, развернутого в нем.
Создание и настройка кластера Kubernetes
Самым первым шагом для реализации мониторинга кластера будет создание самого кластера, если у вас еще его нет. Для создания кластера мы рекомендуем вам использовать статью из нашей официальной документации: там подробно описаны все способы создания кластера и подсказки для работы с ним.
Отдельно обращаем ваше внимание на то, что для доступа к приложениям из внешней сети, вам потребуется создать Ingress-контроллер и настроить Ingress в кластере. Примеры настройки Ingress мы предоставим в одном из следующих шагов.
Если у вас уже развернут кластер k8s, вы можете пропустить данный шаг и перейти к следующему.
Установка Prometheus в кластер с помощью Helm
В этой инструкции мы будем использовать Helm. Это менеджер пакетов для Kubernetes, который позволяет управлять установкой, обновлением и удалением приложений на Kubernetes-кластерах с помощью «установочных пакетов», называемых Helm-чарты. Использование Helm помогает упростить процесс управления приложениями в кластере. Для установки Prometheus в кластер с помощью Helm необходимо установить Helm на вашу локальную машину. Сделать это можно, выполнив команды:
Для Debian/Ubuntu:
curl https://baltocdn.com/helm/signing.asc | gpg --dearmor | sudo tee /usr/share/keyrings/helm.gpg > /dev/null
sudo apt-get install apt-transport-https --yes
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/helm.gpg] https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.list
sudo apt-get update
sudo apt-get install helm
Для RHEL/CentOS/Fedora:
sudo dnf install helm
Для MacOS:
brew install helm
Для Windows средствами Scoop:
scoop install helm
Для Windows средствами Chocolatey:
choco install kubernetes-helm
Отдельно отметим, что всю актуальную информацию по установке Helm вы можете найти в официальной документации.
После установки Helm, для установки актуальных версий чартов prometheus-community вам необходимо добавить в Helm официальный репозиторий разработчика. Это можно сделать, выполнив команды:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
После того как репозиторий будет подключен к Helm, вы можете выполнить поиск среди доступных вам чартов в нем. Для просмотра доступных пакетов в репозитории с именем prometheus-community, выполните команду:
helm search repo prometheus-community
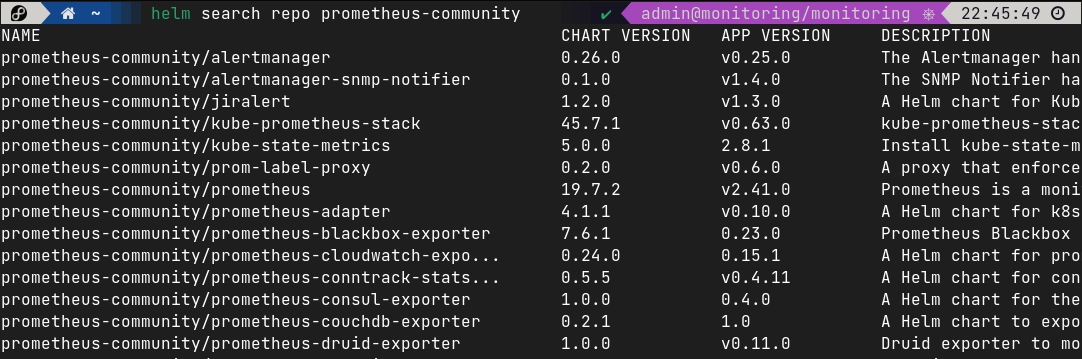
Для установки Prometheus в кластер k8s, нам потребуется установить чарт prometheus-community/kube-prometheus-stack.
Подготовка к установке kube-prometheus-stack
Для корректной установки готового к использованию чарта в кластер, нам необходимо создать конфигурационные файлы для приложений, которые будут развернуты в кластере. Начнем с настройки Alertmanager, компонента, ответственного за отправку уведомлений и алертов от нашего мониторинга. Для настройки конфигурации Alertmanager, создайте файл конфигурации:
nano helm/kube-prometheus-stack/values.yml
В этот файл необходимо ввести следующие данные:
alertmanager:
config:
global:
telegram_api_url: "https://api.telegram.org"
route:
receiver: telegram-alert
group_by: ['alertname', 'cluster', 'service']
repeat_interval: 1h
routes:
- match:
severity: critical
receiver: telegram-alert
continue: true
receivers:
- name: telegram-alert
telegram_configs:
- chat_id: <ChatID>
bot_token: <BotToken>
api_url: "https://api.telegram.org"
send_resolved: true
parse_mode: html
template: |-
{{ define "telegram.default" }}
{{ range .Alerts }}
{{ if eq .Status "firing"}}🔥<b>{{ .Status | toUpper }}</b>🔥{{ else }}✅<b>{{ .Status | toUpper }}</b>✅{{ end }}
<b>{{ .Labels.alertname }}</b>
{{- if .Labels.severity }}
<b>Severity:</b> {{ .Labels.severity }}
{{- end }}
{{- if .Labels.cluster }}
<b>Cluster:</b> {{ .Labels.cluster }}
{{- end }}
{{- if .Labels.service }}
<b>Service:</b> {{ .Labels.service }}
{{- end }}
{{- if .Labels.instance}}
<b>Instance:</b> {{ .Labels.instance }}
{{- end }}
<b>Description:</b> {{ .Annotations.description }}
{{- end }}
После этого сохраните файл. Теперь после развертывания в кластере Alertmanager будет отправлять оповещения в Telegram. Обращаем ваше внимание на то, что это далеко не единственный канал связи алертменеджера: уведомления можно отправлять в Slack, на почту, Rocket.Chat и десятки других каналов коммуникации.
Подробнее о конфигурировании других каналов связи вы можете узнать в официальной документации.
Установка kube-prometheus-stack в кластер
После завершения заполнения дополнительных настроек чарта, мы можем приступить к установке kube-state-metrics в наш кластер Kubernetes. Для начала нам потребуется создать отдельный namespace для мониторинга, поэтому мы подключаемся к кластеру и выполняем команду:
kubectl create namespace monitoring
После этого, мы можем выполнять установку kube-prometheus-stack в наш кластер. Выполняем команду:
helm install kube-prom-stack prometheus-community/kube-prometheus-stack -n monitoring -f values.yaml
После успешного завершения установки, вы увидите сообщение следующего вида:
NAME: grafkube-prom-stack
LAST DEPLOYED: Fri Mar 17 12:09:22 2023
NAMESPACE: monitoring
STATUS: deployed
REVISION: 1
NOTES:
kube-prometheus-stack has been installed. Check its status by running:
kubectl --namespace monitoring get pods -l "release=kube-prom-stack"
Visit https://github.com/prometheus-operator/kube-prometheus for instructions on how to create & configure Alertmanager and Prometheus instances using the Operator.
Это означает, что все установилось корректно. Проверить статус приложения вы можете, также, выполнив команду:
helm status <app-name>Проверяем, что все поды запустились, выполнив команду, которую нам предлагает helm:
kubectl --namespace monitoring get pods -l "release=kube-prom-stack"
Убеждаемся, что все работает корректно и идем далее, к настройке Ingress, чтобы у нас была возможность зайти в веб-интерфейс Grafana из внешней сети. В случае нашей тестовой инсталляции, манифест Ingress выглядит так:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: kube-state-ingress
namespace: monitoring
labels:
name: kube-state-ingress
spec:
ingressClassName: nginx
rules:
- host: grafana.selectel.site
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: kube-prom-stack-grafana
port:
number: 80
Применяем манифест ингресса:
kubectl apply -f ingress.yaml
После применения манифеста, вы сможете обращаться к Grafana через указанное вами доменное имя. В нашем случае это: grafana.selectel.site. Таким образом, чтобы получить доступ к Grafana, вы можете открыть веб-браузер и ввести адрес http://grafana.selectel.site.
Обратите внимание, что для того, чтобы использовать доменные имена, вы должны настроить DNS-записи для указанных доменных имен, чтобы они указывали на IP-адрес вашего кластера Kubernetes.
Если вы используете Managed Kubernetes Selectel, А-записи доменов должны указывать на внешний адрес Балансировщика, который создается вместе с Ingress-Controller. Создание и базовая настройка Ingress Controller подробно описаны в нашей документации.
Переходим по домену, который указывает на сервис Grafana. Если все сконфигурировано правильно, то перед вами будет окно входа. Учетные данные для входа:
login: admin
password: prom-operator
Как вы могли заметить, из всех описанных в чарте сервисов, внешний доступ был настроен только для Grafana. Это, в первую очередь, обусловлено принципами информационной безопасности: мы не рекомендуем вам публиковать такие сервисы, как Prometheus и Alertmanager в открытом доступе. Для того чтобы получить доступ к веб-интерфейсам других сервисов, вы можете воспользоваться механизмом kubectl port-forward. Выполните команду:
pod=$(kubectl get pods --namespace monitoring -l "app.kubernetes.io/name=prometheus" -o jsonpath="{.items[0].metadata.name}") && kubectl port-forward ${pod} 8080:9090 -n monitoring
После выполнения данной команды, kubectl пробросит порт 9090 на локальный порт 8080 вашего компьютера. В командной строке вы увидите следующий вывод:
Теперь вы можете перейти в браузер и зайти в веб-интерфейс Prometheus по адресу:
localhost:8080
Команда для port-forward к поду Alertmanager будет иметь следующий вид:
pod=$(kubectl get pods --namespace monitoring -l "app.kubernetes.io/name=alertmanager" -o jsonpath="{.items[0].metadata.name}") && kubectl port-forward ${pod} 8080:9093 -n monitoring
Далее мы с вами развернем в нашем кластере базу данных Redis и настроим ее мониторинг в кластере Kubernetes.
Мониторинг Redis в Kubernetes
В этой части нашей статьи мы развернем кластер БД Redis в k8s и настроим его мониторинг. Redis – высокопроизводительная key-value база данных, которая широко используется для кеширования данных, управления сессиями и других приложений.
Установка Redis в кластер k8s
Первое, что нам потребуется сделать для развертывания кластера Redis в Kubernetes кластере, — подключить репозиторий bitnami для последующей установки через Helm. Выполняем команды:
helm repo add bitnami https://charts.bitnami.com/bitnami
helm repo update
Создаем отдельный неймспейс для кластера Redis:
kubectl create namespace redis
После этого создаем сам кластер. Для этого необходимо выполнить команду:
helm install redis bitnami/redis -n redis --set replica.replicaCount=3 --set master.persistence.enabled=false --set replica.persistence.enabled=false
Эта команда запускает установку Redis в кластерном режиме. Заданные значения параметров определяют, что в этом кластере Redis будет работать с тремя репликами, а также отключает использование постоянного хранилища для мастера и реплик. Важно понимать: это сделано для целей демонстрации работы Redis, но на реальном проекте необходимо настроить постоянное хранилище для данных.
Ждем какое-то время после выполнения команды и проверяем, что все поды запущены:
kubectl get pods -n redis
NAME READY STATUS RESTARTS AGE
redis-master-0 1/1 Running 0 90s
redis-replicas-0 1/1 Running 0 90s
redis-replicas-1 1/1 Running 0 59s
redis-replicas-2 1/1 Running 0 34s
Далее нам потребуется настроить взаимодействие между развернутым кластером Redis и Prometheus.
Настройка redis-exporter для сбора метрик СУБД
В развернутом нами чарте по умолчанию доступно создание дополнительных контейнеров в подах с СУБД — redis-exporter, специальной программы, собирающей показания с СУБД, чтобы Prometheus мог забрать метрики себе.
Для того чтобы включить данную функциональность в нашем чарте, нам потребуется создать файл redis.yaml: nano redis.yaml. Этот файл потребуется заполнить следующими значениями:
##
## Redis Master parameters
##
master:
persistence:
enabled: false
extraFlags:
- "--maxmemory 256mb"
replica:
persistence:
enabled: false
replicaCount: 3
extraFlags:
- "--maxmemory 256mb"
##
## Prometheus Exporter / Metrics
##
metrics:
enabled: true
## Metrics exporter pod Annotation and Labels
podAnnotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9121"
После сохранения файла выполняем команду:
helm upgrade redis -f redis.yaml bitnami/redis -n redis
При ее выполнении helm выставит новые значения вместо значений по умолчанию в настройках чарта и выполнит обновление ревизии нашего приложения. Отдельно отметим, что узнать все стандартные значения чарта можно с помощью команды:
helm show values <repo>/<chart-name>
Вы также можете найти новые чарты или посмотреть значения по умолчанию на сайте ArtifactHUB, где собрано огромное множество различных репозиториев и чартов: от крупных корпоративных репозиториев вроде bitnami, до чартов, которые разрабатываются энтузиастами.
Поды, содержащие в себе мастер и реплики нашей СУБД должны перезапуститься через какое-то время после обновления чарта, и в них появится новый контейнер для сбора метрик.
NAME READY STATUS RESTARTS AGE
redis-master-0 2/2 Running 0 96m
redis-replicas-0 2/2 Running 0 95m
redis-replicas-1 2/2 Running 0 96m
redis-replicas-2 2/2 Running 0 96m
После того как все поды стали активны, нам потребуется выполнить обновление другого нашего чарта — kube-prometheus-stack, его мы разворачивали в первой части данной статьи.
В данном случае нам потребуется немного изменить конфигурацию сервера Prometheus, чтобы он снимал метрики с экспортера, который мы развернули.
Открываем файл values.yaml, в который мы ранее вносили изменения для корректной работы Alertmanager:
nano values.yaml
В конец этого файла необходимо внести конфигурацию kubernetes_sd_configs, позволяющую динамически подключаться к новым подам и собирать метрики с них. Подробнее о механизме service discovery вы можете почитать в официальной документации. Заполняем файл значениями:
prometheus:
prometheusSpec:
additionalScrapeConfigs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
Сохраняем файл и выполняем команду:
helm upgrade kube-prom-stack -f values.yaml
prometheus-community/kube-prometheus-stack -n monitoring
После этого наше приложение для сбора метрик обновится и будет автоматически забирать метрики с подов Redis.
Переходим в веб-интерфейс prometheus и проверяем, все ли метрики собираются корректно. Для примера можно использовать метрику redis_up:
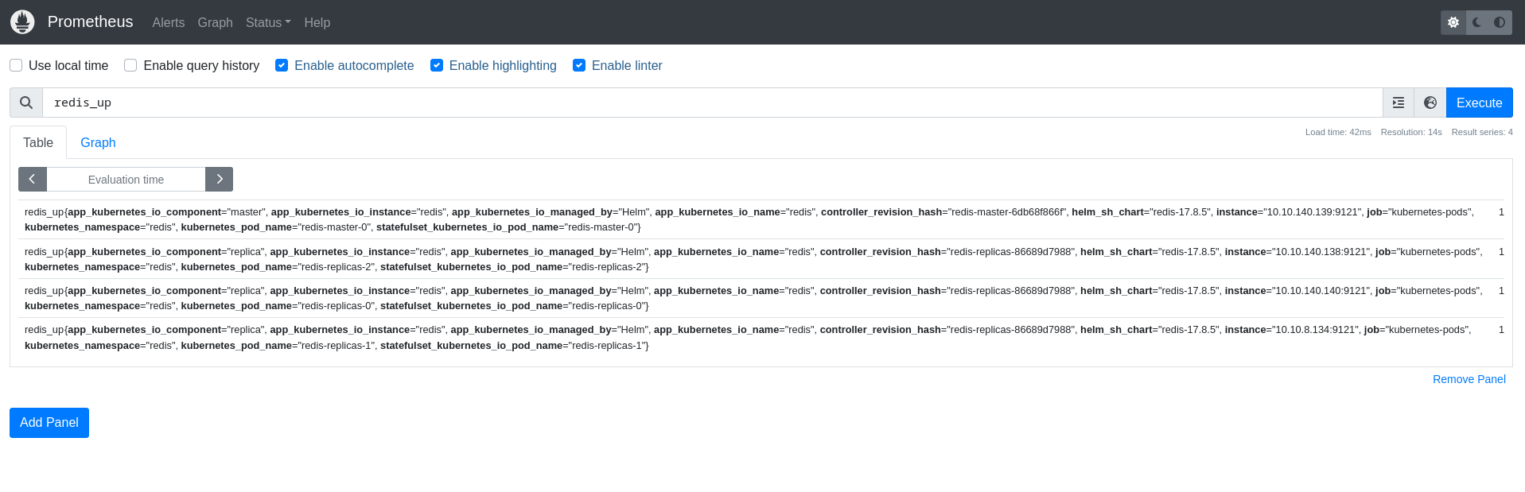
Когда мы убедились, что метрики собираются корректно, нам необходимо обновить правила алертинга для нашего чарта kube-prometheus-stack. Дополняем файл values.yaml следующим содержимым:
additionalPrometheusRulesMap:
rule-name:
groups:
- name: redis_group
rules:
- alert: redis_is_running
expr: redis_up == 0
for: 30s
labels:
severity: critical
annotations:
summary: "Critical: Redis is down on the host {{ $labels.instance }}."
description: "Redis has been down for more than 30 seconds"
- alert: redis_memory_usage
expr: redis_memory_used_bytes / redis_memory_max_bytes * 100 > 40
for: 5m
labels:
severity: warning
annotations:
description: "Warning: Redis high memory(>40%) usage on the host {{ $labels.instance }} for more than 5 minutes"
summary: "Redis memory usage {{ humanize $value}}% of the host memory"
- alert: redis_master
expr: redis_connected_clients{instance!~"server1.mydomain.com.+"} > 50
for: 5m
labels:
severity: warning
annotations:
description: "Warning: Redis has many connections on the host {{ $labels.instance }} for more than 5 minutes"
summary: "Redis number of connections {{ $value }}"
- alert: redis_rejected_connections
expr: increase(redis_rejected_connections_total[1m]) > 0
for: 30s
labels:
severity: critical
annotations:
description: "Critical: Redis rejected connections on the host {{ $labels.instance }}"
summary: "Redis rejected connections are {{ $value }}"
- alert: redis_evicted_keys
expr: increase(redis_evicted_keys_total[1m]) > 0
for: 30s
labels:
severity: critical
annotations:
description: "Critical: Redis evicted keys on the host {{ $labels.instance }}"
summary: "Redis evicted keys are {{ $value }}"
Сохраняем файл и выполняем обновление чарта в кластере:
helm upgrade kube-prom-stack -f values.yaml
prometheus-community/kube-prometheus-stack -n monitoring
Проверяем, что все наши правила добавились корректно:
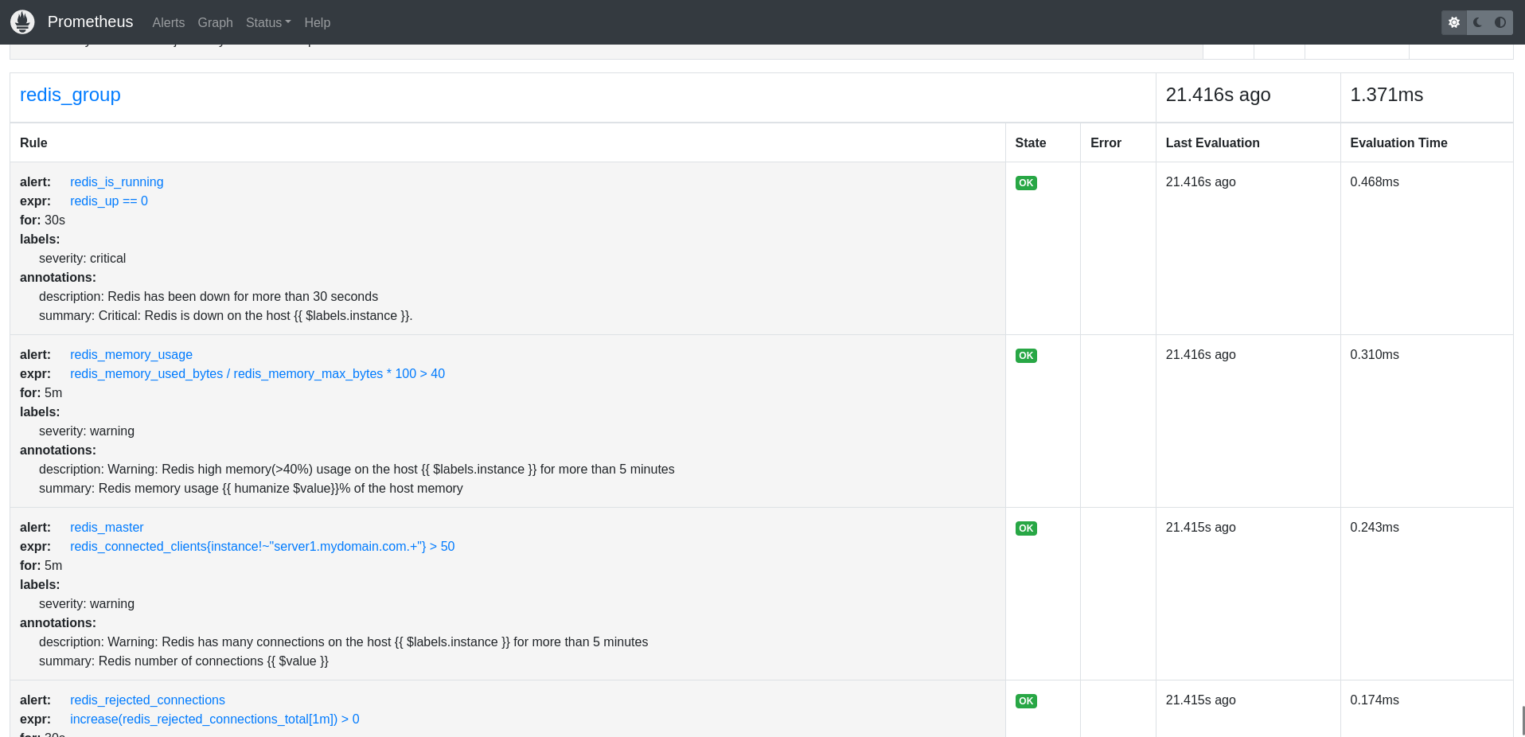
Если на своем экране вы видите такую же картину, то все сделано правильно. На этом этапе можно смело добавлять дашборд для Grafana. Переходим на http://grafana.your.domain.com/dashboard/import (вместо grafana.your.domain.com необходимо вставить доменное имя, которое используется вами для доступа в Grafana).
Вводим в поле для ID дашборда номер 14091 и нажимаем Import.
В этом блоке статьи мы рассмотрели установку Redis в кластер Kubernetes с помощью Helm, а также настройку мониторинга Redis с помощью Prometheus и Redis-exporter. Мы установили Redis и Redis-exporter в кластер с помощью Helm, настроили метрики Redis-exporter и добавили их в Prometheus.
Теперь мы можем отслеживать работу Redis с помощью Prometheus и Grafana, а также использовать Alertmanager для получения уведомлений о возможных проблемах в работе Redis.
Настройка Blackbox Exporter в кластере k8s
В этой части статьи мы рассмотрим развертывание и настройку Blackbox Exporter для мониторинга домена example.org.
Blackbox exporter 一 инструмент, предназначенный для мониторинга внешних систем и сервисов. Этот инструмент используется для проверки доступности и работоспособности этих систем через различные протоколы HTTP, DNS, TCP, ICMP и другие. В основном он используется для мониторинга внешних систем и сервисов, которые не могут быть обработаны через обычные инструменты мониторинга.
Установка Blackbox Exporter в кластер Kubernetes
Для установки Blackbox exporter в namespace monitoring с помощью helm нужно выполнить следующую команду:
helm install blackbox-exporter
prometheus-community/prometheus-blackbox-exporter -n
monitoring
Проверяем, что поды работают корректно:
kubectl get pods -n monitoring | grep blackbox
Настройка Blackbox Exporter
После того как мы убедились, что под с blackbox exporter запустился и работает, нам потребуется в очередной раз внести изменения в values.yaml для чарта kube-prometheus-stack, чтобы добавить blackbox-exporter в конфигурацию prometheus.
Важно: добавлять новую конфигурацию необходимо в том же месте, где вы добавляли конфигурацию для Service Discovery, начав с нового job-name. Добавляем в файл следующие данные:
- job_name: 'prometheus-blackbox-exporter'
metrics_path: /probe
params:
module: [http_2xx_check]
static_configs:
- targets:
- https://example.org
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: blackbox-exporter-prometheus-blackbox-exporter.monitoring.svc.cluster.local:9115
Данные изменения описывают конфигурацию job_name в Prometheus для мониторинга с помощью Blackbox exporter. Разберем структуру файла немного подробнее: metrics_path указывает, что метрики будут доступны по пути /probe, а параметры module указывают, что мониторинг будет проводиться модулем http_2xx_check, который проверяет код ответа HTTP на равенство 200 и содержание определенного текста в теле ответа.
В static_configs определен список целевых объектов, в данном случае объект будет только один 一 https://example.org.
Список relabel_configs содержит правила перенаправления и замены меток. Первое правило указывает, что значение метки address будет использоваться как значение параметра target, второе правило 一 значение параметра target будет скопировано в метку instance.
Третье правило заменяет значение метки address на адрес Blackbox exporter, который находится в кластере Kubernetes и будет использоваться для сбора метрик.
Сохраняем данный файл и применяем изменения:
helm upgrade kube-prom-stack -f values.yaml
prometheus-community/kube-prometheus-stack -n monitoring
Теперь нам потребуется изменить values для чарта blackbox-exporter. По аналогии с предыдущими чартами, создаем файл blackbox.yaml.
nano blackbox.yamlЗаполняем файл следующими значениями:
secretConfig: false
config:
modules:
http_2xx:
prober: http
timeout: 5s
http:
valid_http_versions: ["HTTP/1.1", "HTTP/2"]
no_follow_redirects: false
preferred_ip_protocol: "ip4"
valid_status_codes: [200]
http_2xx_check:
prober: http
timeout: 5s
http:
method: GET
fail_if_body_not_matches_regexp:
— "Example Domain"
fail_if_not_ssl: true
preferred_ip_protocol: ip4
valid_http_versions: ["HTTP/1.1", "HTTP/2"]
valid_status_codes: [200]
Здесь задаются настройки для двух модулей, которые могут использоваться для проверки доступности и работоспособности системы через протокол HTTP.
В параметрах модуля http_2xx указывается, что для проверки будет использоваться протокол HTTP, таймаут на проверку составляет 5 секунд, а также указывается, какие версии HTTP будут допустимы для проверки. Также задаются коды состояния HTTP, которые считаются успешными (в данном случае это только код 200).
Модуль http_2xx_check также использует протокол HTTP для проверки, но в нем задается метод GET для запроса, а также регулярное выражение, которое должно соответствовать ответу сервера (в данном случае должно присутствовать слово Example Domain).
Также указывается, что проверка должна выполняться только для HTTPS-серверов, и задаются допустимые версии HTTP и коды состояния, которые считаются успешными.
Обновляем конфигурацию экспортера:
helm upgrade blackbox-exporter prometheus-community/prometheus-blackbox-exporter -f
blackbox.yaml -n monitoring
Осталось только обновить правила алертинга в конфигурации Prometheus. Открываем файл values.yaml и добавляем следующие значения в список правил алертинга. Код, который мы будем добавлять выглядит так:
additionalPrometheusRulesMap:
rule-name:
groups:
- name: redis_group
#<тут правила алертинга, которые мы с вами писали для мониторинга Redis>
rule-name2:
groups:
- name: http_probe
rules:
- alert: example.org_down
expr: probe_success{instance="https://example.org",job="prometheus-blackbox-exporter"} == 0
for: 5s
labels:
severity: critical
annotations:
description: '{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes.'
summary: 'Instance {{ $labels.instance }} down'
Сохраняем файл и выполняем обновление kube-prometheus-stack:
helm upgrade kube-prom-stack -f values.yaml
prometheus-community/kube-prometheus-stack -n monitoring
Чтобы проверить работу blackbox-exporter, можно изменить в файле blackbox.yaml значение текста, которое должен искать модуль http_2xx_check в теле ответа, а затем обновить сам blackbox-exporter. При успешном выполнении должны прийти уведомления в Slack.
Заключение
В данной статье мы рассмотрели основные принципы мониторинга кластера Kubernetes при помощи Prometheus, изучили основы мониторинга приложений в кластере при помощи экспортеров приложений и blackbox exporter. Мы настроили Service Discovery и правила алертинга, а также научились разворачивать приложения в кластере с помощью Helm. Надеемся, этот материал поможет вам в выстраивании надежной и эффективной системы мониторинга.