ML в Managed Kubernetes: для каких задач нужен кластер с GPU
Рассказываем, для чего нужны производительные видеокарты в кластерах Managed Kubernetes и как они ускоряют продакшн ML-сервисов.

Машинное обучение используют в разных сферах: от бизнес-аналитики до астрофизики. Для грамотного потребления ресурсов модели развертывают в контейнерах на выделенных серверах или в облаках. Теперь с ML можно эффективно работать в готовых кластерах Kubernetes — в них появились производительные видеокарты.
Рассказываем, для чего нужны GPU в кластерах Managed Kubernetes и как они ускоряют продакшн ML-сервисов.
Преимущества GPU перед CPU
Графический процессор нужен в работе с 3D, рендерингом и не только. Вычисления, с которыми лучше справляется GPU, встречаются в сложной аналитике и машинном обучении.
Большинство вычислений при обучении ML-моделей — матричные. Для работы с ними подходят Tensor и CUDA — специальные графические ядра, интегрированные в GPU. Это дает ему преимущества перед CPU в машинном обучении.
Выделим самые частые задачи, где эффективнее GPU.
Обучение простых моделей
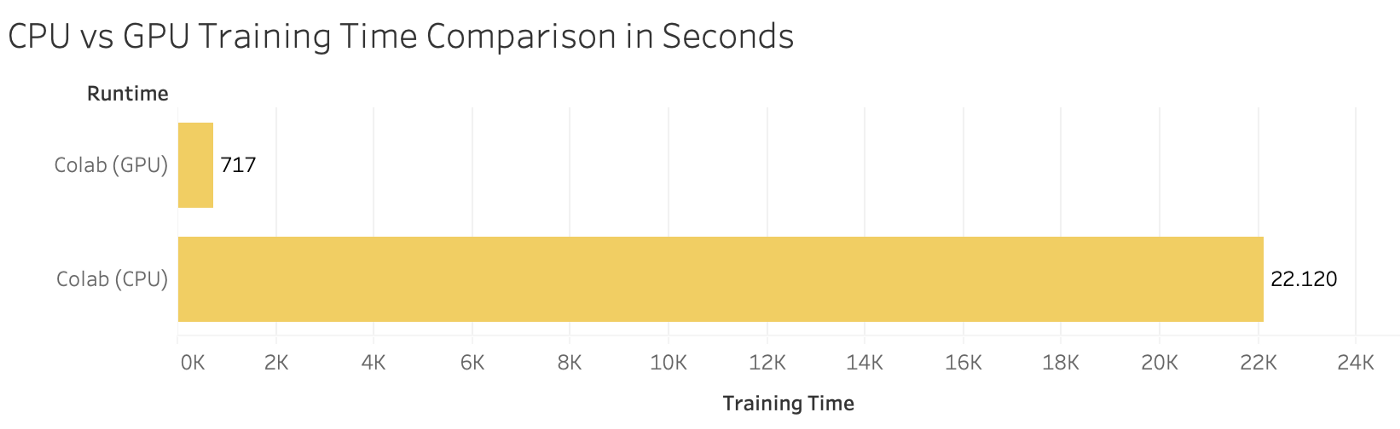
Представьте, что нужно обучить модель для прогнозирования цен на жилье в Бостоне. Она должна учитывать уровень преступности, количество парков в районе, благоустройство и прочее. Чтобы модель научилась прогнозировать, ей нужно «скормить» историю — большой набор данных из разных факторов и наблюдений об изменениях цен на жилье.
С обработкой истории быстрее справится GPU, так как каждый датасет — это матрица из факторов и наблюдений. Чем их больше, тем заметней разница в скорости обучения на GPU и CPU.
Глубокое обучение: работа с медиаданными
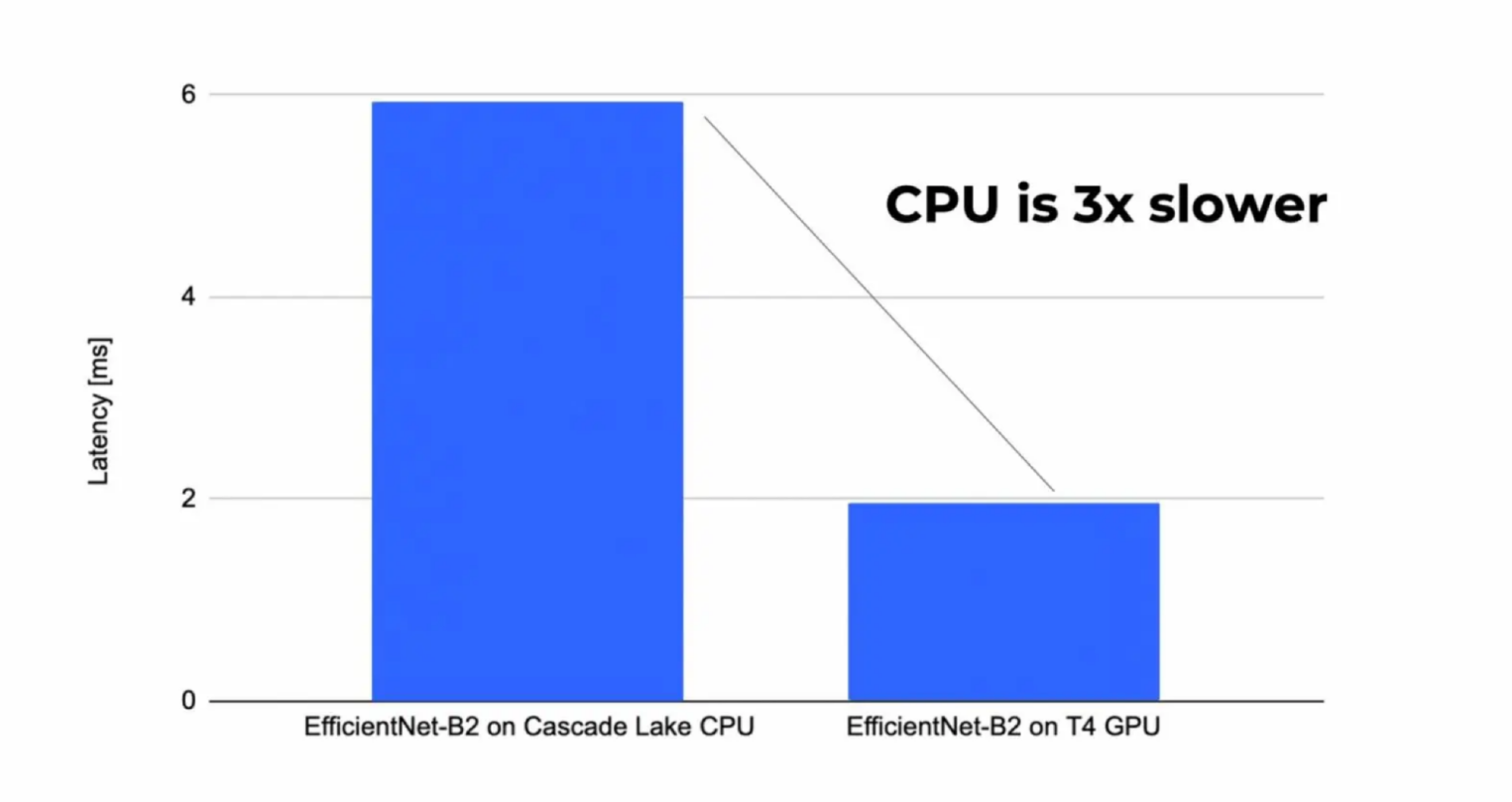
Особенно остро GPU нужны для работы с медиаданными: изображениями, видео, речью — их можно представить в компьютере с помощью тензоров. С ними сталкиваются в задачах классификации и обработки изображений, компьютерном зрении и в генеративно-состязательных сетях.
Допустим, нужно обучить нейронную сеть генерировать фото несуществующих пород кошек. Для этого ее нужно тренировать на большом датасете из изображений. Это сложный вычислительный процесс. Чтобы сеть могла работать с изображениями, они преобразуются в трехмерные матрицы (тензоры) из ячеек с параметрами пикселов.
Для работы с тензорами используют матричные вычисления — аффинные преобразования, смещения, развороты и прочее. С ними эффективней справляется GPU. Кроме того, существует большое количество архитектур нейронных сетей, которые реализованы на базе операций с тензорами.
Популярные библиотеки для работы с изображениями (OpenCV, PyTorch, TensorFlow) также эффективней на графических процессорах. Даже с учетом оптимизации работы CPU с помощью специального ПО (OpenVINO и др).
Производительность ML-моделей в продакшене
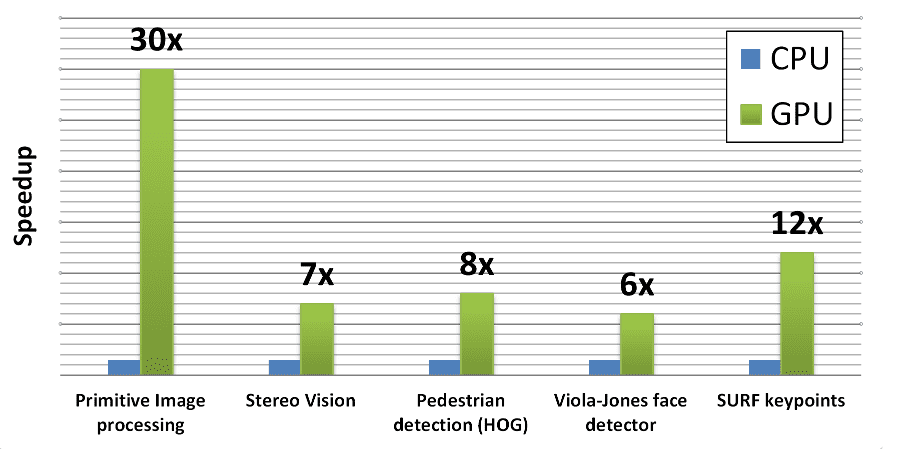
GPU нужны не только на этапе обучения, но и при работе в продакшене. Если ваш ML-сервис работает с медиаданными, то с видеокартой скорость обслуживания пользователей будет выше. К тому же нередко модели обучаются повторно во время работы с клиентскими запросами.
Допустим, компания развивает приложение, которое определяет название блюда по фотографии. Когда сервис только запустили, модель часто ошибалась. Пользователи помогали ей классифицировать блюда. Одновременно сервисом могли пользоваться тысячи человек. Однако приложение не тормозило, так как работало на мощностях GPU.
Можно ли обучать на CPU?
Не в каждой ML-задаче заметна разница в скорости между CPU и GPU. Для моделей на небольших выборках из численных данных (например, для простого прогнозирования или регрессионного анализа) неважно, на каком процессоре работать.
Качество обучения не зависит от выбранного типа процессора. При сбалансированной репрезентативной выборке качество модели не изменится. Но процесс обучения будет медленнее. Могут уйти месяцы — время, которое не всегда есть у компаний в условиях конкуренции.
Почему для ML-задач используют контейнеры
Тенденции показывают, что для запуска ML-моделей лучше использовать контейнеры, которые можно развернуть как в облаках, так и на выделенных серверах. Для управления контейнерами есть оркестратор Kubernetes. С момента появления он «оброс» нужным для ML софтом.
«Инструменты K8s позволяют специалистам ML использовать скорость GPU в работе контейнеров», — Аджит Райна, старший менеджер по развитию Redis.
Выделим основные преимущества Kubernetes, которые важны для развертывания ML-сервисов.
Обособленное рабочее окружение
У каждой ML-модели должно быть окружение — модули, библиотеки и др. А версии библиотек зависят от версий драйверов на ноде. В Kubernetes можно запускать модели на нодах с предустановленными версиями драйверов. Притом делать это автоматически.
Простое администрирование контейнеров
Управление контейнерами реализовано удобнее и проще, чем в том же Docker Swarm. Более того, контейнеры автономны. K8s сам управляет ресурсами, в зависимости от «потребностей приложения».
«Kubernetes обеспечивает простую, быструю в организации и управлении работу контейнеров и приложений. Технология позволяет автоматизировать операционные задачи — управление доступностью приложений и их масштабирование»
— Томас Ди Джакомо, директор по технологиям и продуктам SUSE.
Наличие инструментов для ML-экспериментов
За обучение, сравнение и выбор оптимальных моделей отвечает Kubeflow — платформа машинного обучения, запускающая ML-конвейеры в кластерах Kubernetes. Kubeflow позволяет «изолировать» проведение различных экспериментов с помощью создания подов, а также автоматизировать выбор эталонных моделей.
Это важно, так как на практике неизвестно, какой подход и какую математическую модель выбрать для решения задачи. Это определяют результаты экспериментов.
Несколько ML-инженеров и математиков могут проверять свои гипотезы и результаты на одном датасете, отбирать лучшие модели и не бояться «конфликтов» между экспериментами в пространстве имен. Но это лишь одно из преимуществ.
Автомасштабирование
Kubernetes может автоматически регулировать число используемых ресурсов в зависимости от рабочих нагрузок. Автомасштабирование осуществляется в связке с масштабированием приложения (уровень подов) и регулировкой количества узлов внутри кластера (уровень кластеров).
Безопасность
Также в K8s активно развивается система настроек сетевых политик и использование пространств имен. В последних версиях оркестратор консолидировал защиту на всех уровнях. Об этом мы подробнее говорили в нашей статье.
Как Managed Kubernetes помогает в машинном обучении
Деплой сервисов сильно усложняется из-за специфики Kubernetes. Для помощи администраторам в работе с контейнерами есть Managed Kubernetes, который позволяет автоматизировать основные задачи, связанные с поддержкой приложений. Кроме того, обработка заявок на кластеры сокращается до нескольких минут.
Рассмотрим свойства готовых кластеров Kubernetes, которые также облегчают деплой ML-сервисов.
Отказоустойчивость
В Managed Kubernetes можно «резервировать» реплики приложения. Перед деплоем приложения достаточно обозначить количество запущенных реплик, которые будут работать «на подхвате».
Это полезно для высоконагруженных ML-сервисов. Если произойдет неожиданный приток входящих запросов от клиентов, сервис будет скейлиться под нагрузками — автоматически запускать новые реплики, чтобы избегать даунтаймов.
Широкий выбор видеокарт
В Managed Kubernetes доступны все GPU облачной платформы. Можно создавать ноды готовых конфигураций с видеокартами NVIDIA Tesla T4, A2, A30, A100, A2000 и A5000. Из них A2, A30 и A100 — ускорители, разработанные для задач AI. Если нужно обучить большую модель, оптимальный вариант — A100. Для «самых маленьких» моделей подойдет T4.
Благодаря выбору можно сэкономить деньги и «реконфигурировать» кластер по случаю. Например, во время обучения модели использовать группу нод с мощной видеокартой, а во время инференса — ноды с видеокартой послабее.
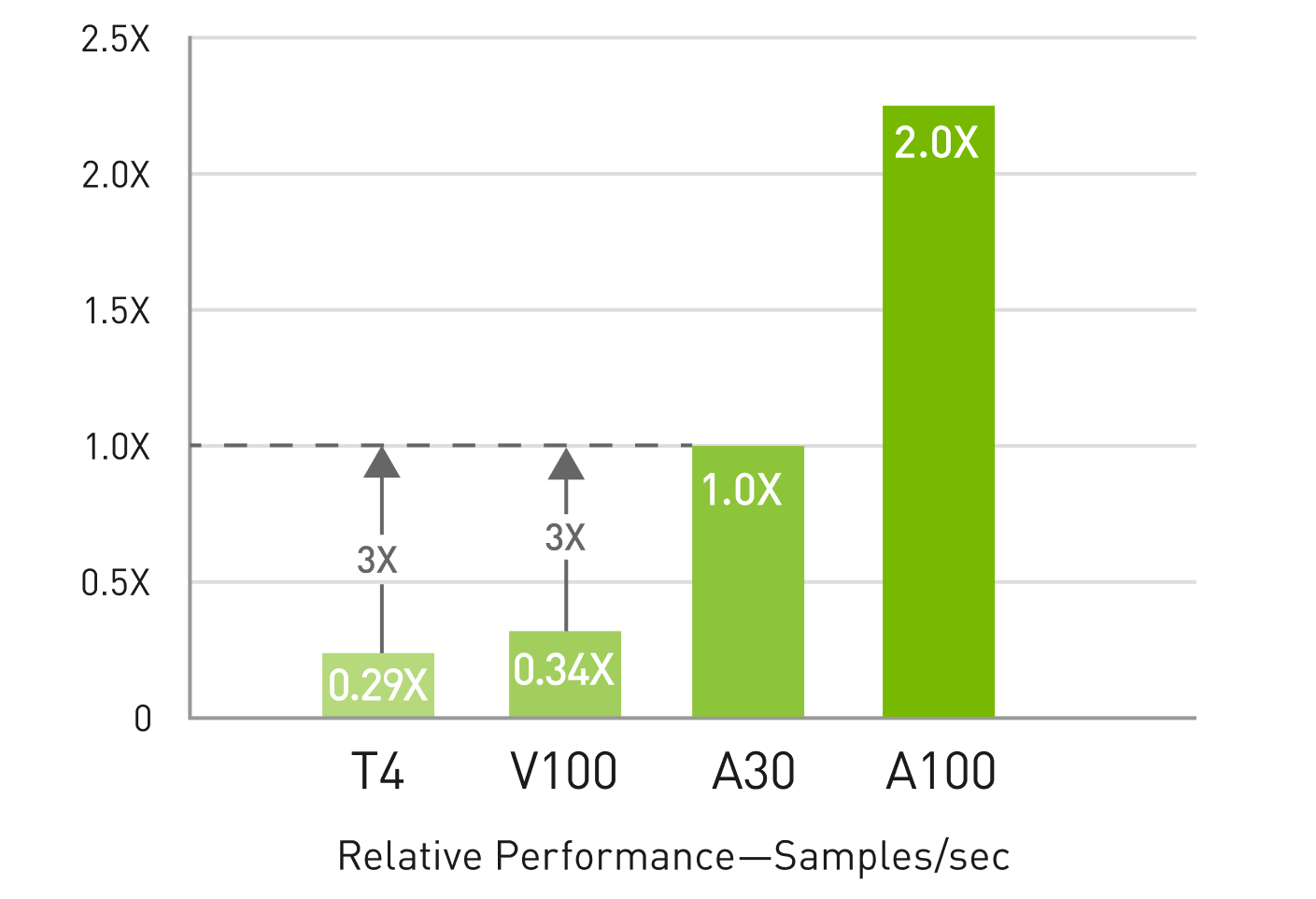
В каждой из видеокарт есть определенное количество тензорных и CUDA- ядер. Чем их больше, тем быстрее высокопроизводительные вычисления, обучение модели и работа в инференсе. На схеме вы можете ознакомиться с характеристиками каждой из видеокарт.
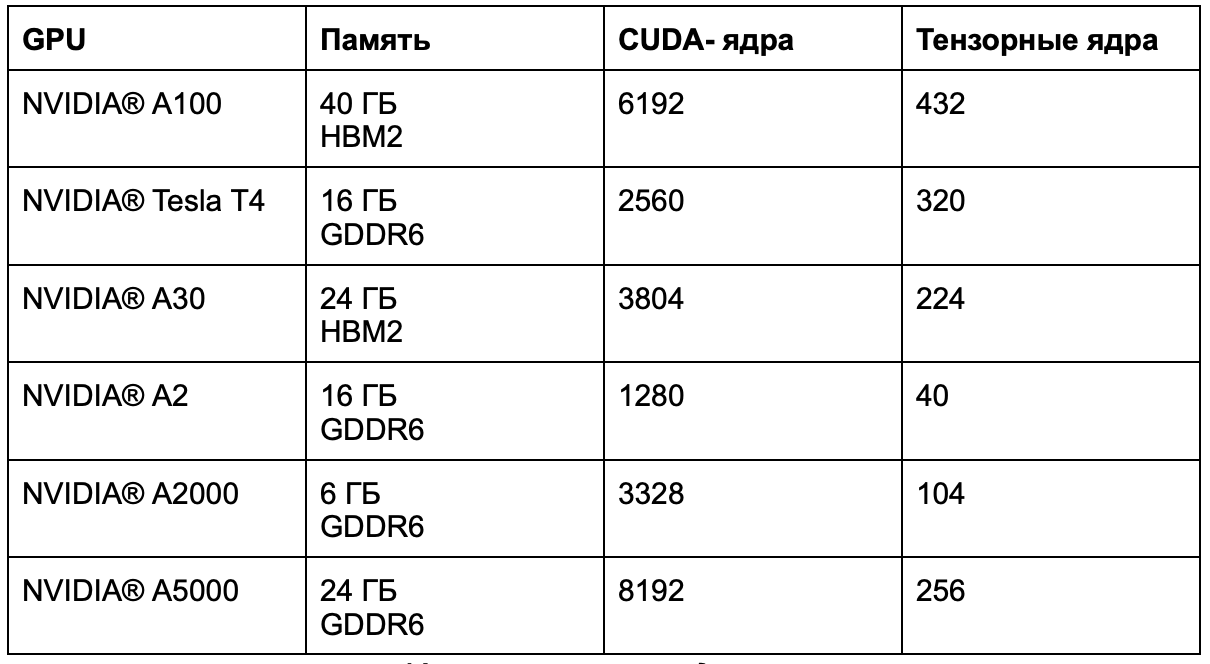
Наиболее полная информация о доступных видеокартах в кластерах Managed Kubernetes — по ссылке. Рассчитать стоимость кластера с GPU можно в калькуляторе.
На данный момент автомасштабирование для групп нод с GPU недоступно, поскольку сегодня это редкий запрос. Даже относительно слабые видеокарты могут выдержать большие нагрузки.
Кому может понадобиться кластер с GPU
При создании ML-сервисов уходит много времени на сбор и разметку данных.
Кроме того, модель нужно обучить и выкатить в продакшен.
Пример — история создания голосового помощника «Олег» от Tinkoff. Чтобы учесть все текстовые запросы клиентов, разработчики собирают большие данные. Чем больше данных, тем точнее языковая модель определяет смысл сказанного.
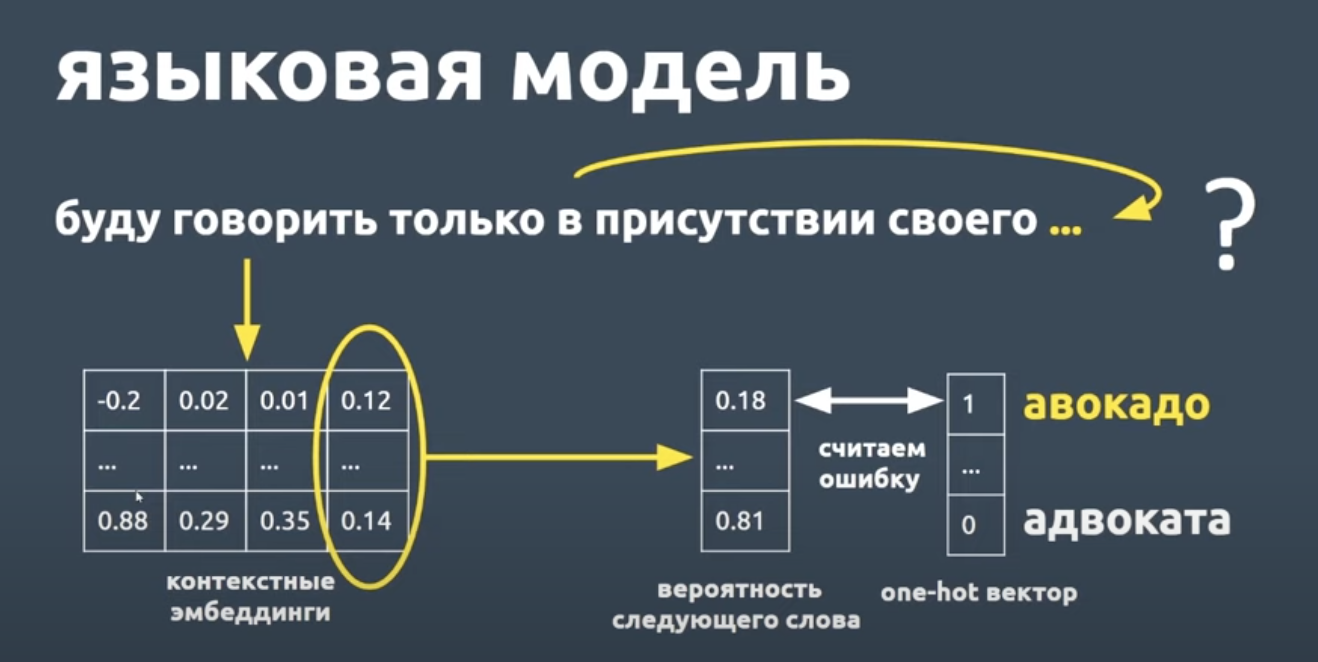
Сложно сказать, сколько должна обучаться подобная модель до выхода «первой версии». Процесс может длиться сотни часов на GPU. А на CPU и вовсе — тысячи. Также нужно периодически оценивать результаты и проводить дообучение модели при необходимости.
Некоторые компании могут себе позволить большие временные издержки, а некоторые — не могут. Поэтому релиз GPU в Managed Kubernetes особенно актуален компаниям, которым важна скорость разработки: вместо того, чтобы тратить время и деньги на дорогие процессорные мощности в ML, лучше использовать GPU.
Запуск кластера с видеокартой
В Managed Kubernetes можно создать кластер с GPU за несколько действий.
1. Зарегистрируйтесь в панели управления Selectel и создайте кластер в нужном регионе.
2. Выберите одну из фиксированных конфигураций нод с GPU.
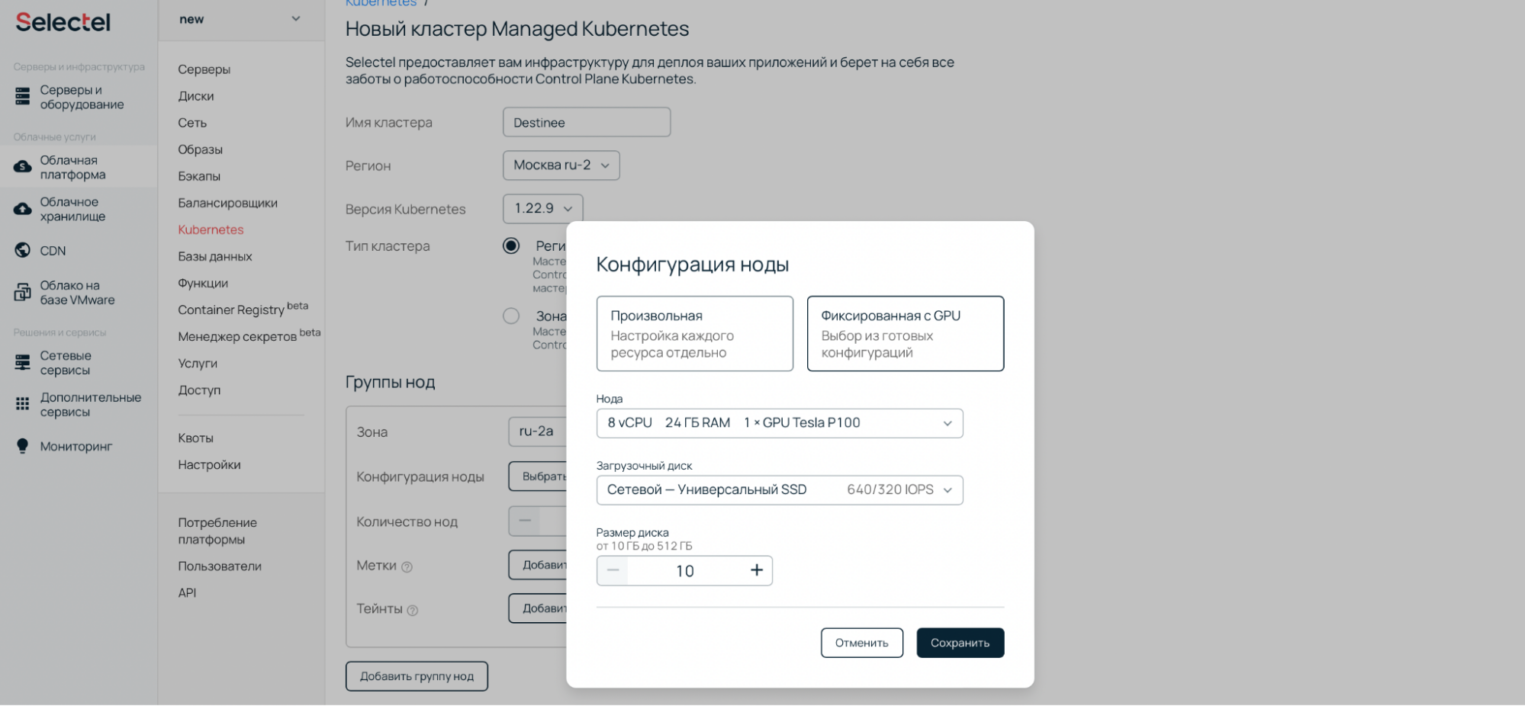
После создания кластера вы получите доступ к нодам с установленными драйверами для корректной работы GPU.





