

В обзоре расскажем, что такое и зачем нужен Redis, рассмотрим его применение и преимущества, поддерживаемые типы данных. Подробно остановимся на конфигурациях, моделях работы, а также примерах использования этой системы управления базами данных.
Что такое и для чего используется СУБД Redis
Простыми словами Redis — система хранения данных в виде структур. Это нереляционная СУБД с открытым исходным кодом, организованная по принципу «ключ – значение». Она является вспомогательной и выполняет функцию хранилища (Redis storage) и кеша для основной, центральной базы данных. В качестве последних могут использоваться, например, PostgreSQL или MySQL.
Название СУБД произошло от аббревиатуры «Remote Dictionary Server» — ReDiS. Разработал продукт итальянский программист С. Санфилиппо, которого не устраивала производительность обычных баз данных при масштабировании. Первая версия вышла в 2009 году, и с тех пор система обновляется регулярно.
Последняя стабильная версия, выложенная на официальном сайте Redis.io на момент написания статьи, — 7.0.5.
Преимущества работы с базами данных Redis
Благодаря тому, что БД не использует язык структурированных запросов SQL, у хранилища Redis есть ряд плюсов.
Среди них:
- Производительность. Поскольку данные хранятся в оперативной памяти сервера, базы NoSQL работают гораздо быстрее в сравнении с реляционными СУБД. Это позволяет снижать нагрузку на главные БД за счет обработки в оперативной памяти постоянных данных, а также тех, которые часто меняются, но не являются важными.
- Гибкость структур данных. Базы NoSQL позволяют работать с неструктурированными данными — они хранятся не в традиционном табличном виде, а по типам. Кроме того, объемы хранимых данных фактически не ограничены, а при необходимости можно добавлять новые типы данных.
Какие типы данных поддерживает Redis DB
Основные типы данных, поддерживаемые по умолчанию:
- строковые (в виде текста или двоичного кода с максимальным размером 512 МБ),
- битовые массивы и поля (дают возможность выполнять побитовые операции),
- хеш-таблицы (в них хранятся списки полей и значений),
- списки (упорядоченные коллекции строковых значений),
- множества, в том числе упорядоченные (коллекции уникальных элементов),
- потоковые (для хранения информации из логов),
- геоданные (географические координаты),
- HyperLogLog (структурированная информация для определения вероятностей нахождения определенных элементов в наборах данных).
Языковая поддержка Redis
Система поддерживает практически все популярные языки программирования, включая Python, Golang, семейство C, Java, Ruby, Perl, а также PHP и JavaScript.
Конфигурации Redis
Развертывание Redis DB можно проводить по-разному. Приведем описание основных решений, или конфигураций Redis.
Единственный экземпляр Redis Database
Такое использование Redis подойдет для тех, кому нужно организовать ограниченное по объему хранилище: как правило, небольшую базу данных для приложения. Развернутый экземпляр Redis в этом случае поможет организовать кеширование, что положительно скажется на производительности приложения. Если ресурсы сервера позволяют, то Redis обычно разворачивают на тех же мощностях, что и приложение.
Из минусов такого подхода можно отметить снижение отказоустойчивости системы (особенно если нет дополнительно реляционной базы данных). При наличии проблем в Redis Database доступ к приложению может быть затруднен.
Redis HA
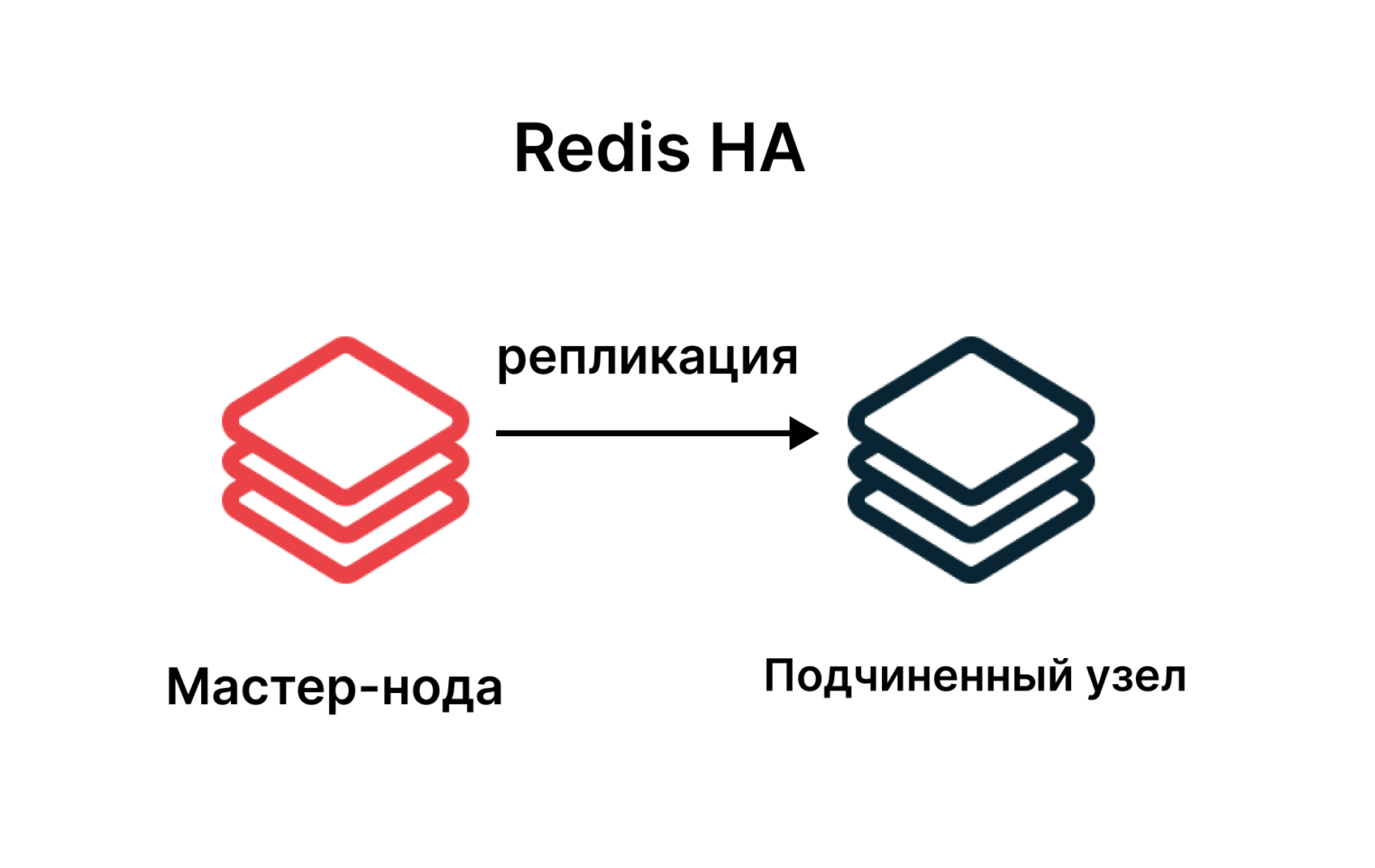
Аббревиатура HA расшифровывается как High Availability, то есть повышенная доступность. В этой схеме задействуется два и более узлов: главный и подчиненные, а их синхронизация реализуется с помощью репликации. Такая система позволяет существенно повысить ее отказоустойчивость, поскольку здесь нет единой точки отказа, как в предыдущем варианте с единственной СУБД.
В результате сбои устраняются очень быстро, в том числе за счет их автоматического обнаружения и схемы восстановления системы. А благодаря надежным каналам связи исключена потеря данных.
О репликации данных в БД Redis
Под репликацией понимается дублирование данных, которые пересылаются и записываются всеми узлами системы, что многократно снижает риски потери данных. Также благодаря репликации увеличивается производительность и скорость работы сервиса, поскольку реплицированные данные доступны для чтения с любого узла системы.
Redis Sentinel
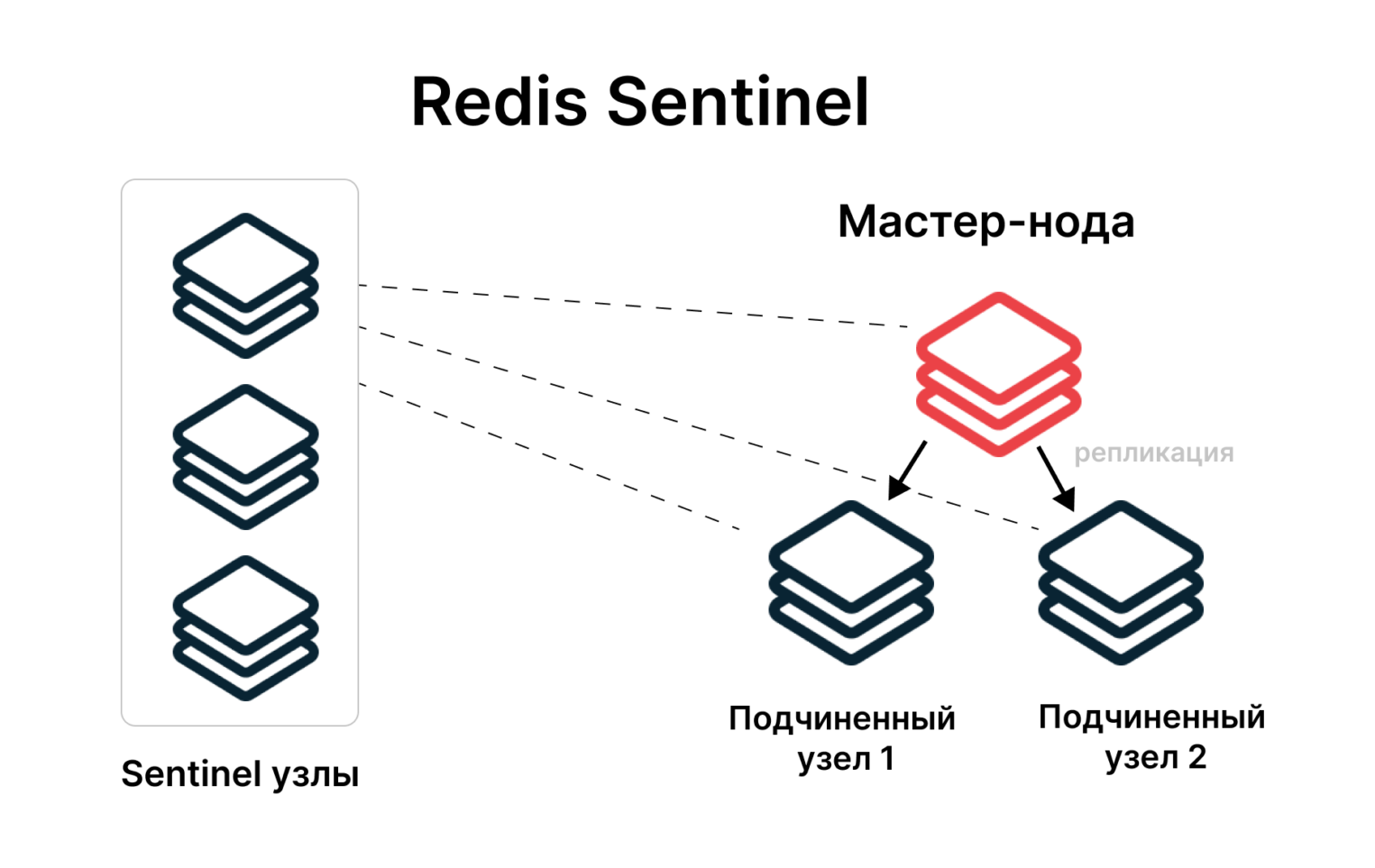
Sentinel, добавленный в СУБД с версии 2.4, представляет собой сервис для создания распределенных систем и мониторинга состояния их узлов. Это решение можно выбрать, когда репликация выполняется при отсутствии полноценного кластера, элементы которого надежно связаны между собой. Sentinel как раз и выступает в роли такой связки.
Sentinel-процессы запускаются в момент потери связи между узлами. Кроме того, узлы Sentinel выполняют и такие функции, как восстановление сервиса после отказа, отправка уведомлений, а также конфигурирование системы: они сообщают, какой экземпляр Redis в данный момент является ведущим.
Redis Cluster
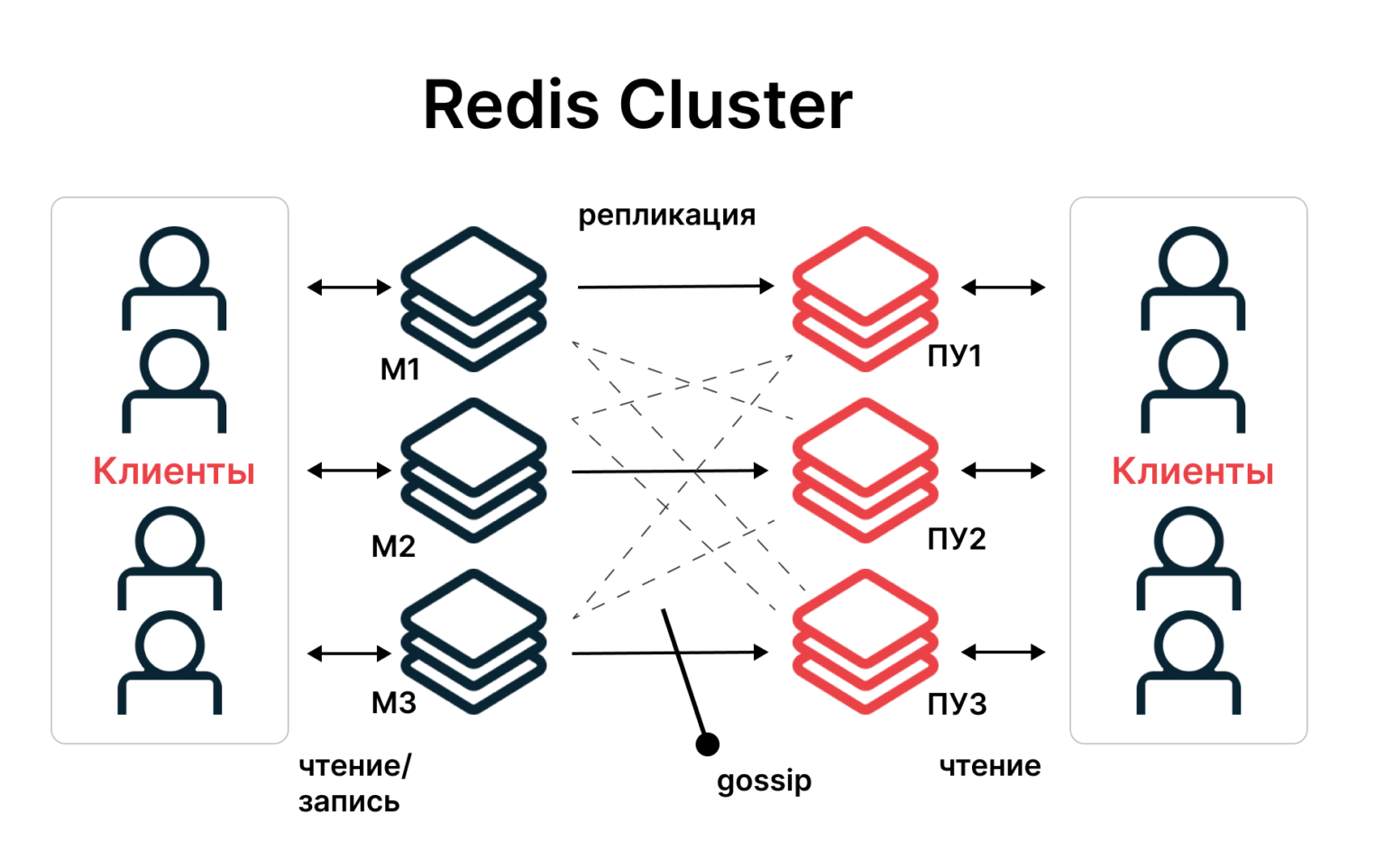
Добавленный в Redis 3.0 Cluster предназначен для горизонтального масштабирования системы, когда нагрузка равномерно распределяется по всему хранилищу. Классическая схема на основе Cluster представляет собой несколько ведущих и несколько подчиненных узлов с распределением данных между всеми узлами системы. А для мониторинга состояния системы обычно используют протокол Gossip.
Одна из главных особенностей Redis Cluster заключается в его механизме работы: он радикально отличается от того, который используется в схемах HA и Sentinel. Если там это репликация, то здесь — шардирование, или шардинг. Шардинг — сегментирование данных, которые в таком виде равномерно распределяются по элементам кластера. Это позволяет существенно снизить нагрузку на хранилище.
Протокол Gossip
При помощи протокола осуществляется мониторинг состояния узлов системы, работающих по механизму шардинга. Если какой-то из основных узлов перестает отвечать на запросы, Gossip передает его права одному из подчиненных узлов. За счет этого существенно повышается отказоустойчивость системы в целом.
Постоянное хранение данных в Redis
СУБД Redis не рассчитана на постоянное хранение данных. Дело в том, что приоритетными задачами Redis являются не надежность хранения, а организация скоростного и бесперебойного доступа к данным. Поэтому для надежного хранения данных рассмотрите решения, совместимые с Redis. Это могут быть классические реляционные базы — PostgreSQL, MySQL или Oracle.
Модели резервирования данных для Redis: файлы RDB и AOF
Пользователи Redis советуют использовать в production как бэкапы данных, так и встроенные инструменты/модели резервирования СУБД.
Таких моделей три:
- Файлы RDB. Подразумевает использование снапшотов — регулярных снимков состояния хранилища (временные интервалы задаются в конфигурации). Главный недостаток этой схемы: если сбой Redis произошел в интервале между созданием снапшотов, то данные потеряются.
- Файлы AOF (Append Only File). Более надежный способ организации хранения данных, поскольку файлы AOF представляют собой независимые журналы для записи команд на восстановление. По умолчанию Redis пишет данные на диск каждую секунду, что позволяет терять минимум информации в случае сбоев.
- RDB и AOF. Комбинирование двух моделей — самое надежное решение, однако в качестве платы за стабильность здесь придется несколько пожертвовать скоростью. Также учтите, что при перезагрузке системы Redis будет использовать файлы AOF.
Как устроено хранение данных в Redis: создание форков процессов
Форком называется создание нового процесса в системе путем копирования родительского. И эти процессы затем могут взаимодействовать между собой. Перегрузки системы удается избежать благодаря совместному использованию памяти по принципу Copy-On-Write. В результате дополнительная память выделяется только при каких-либо изменениях процесса, но объемы этой памяти незначительны.
Сравнение Redis с хранилищем Memcached
Главным конкурентом Redis является СУБД Memcached, которая появилась на 6 лет раньше.
«Почтенный» возраст — основная причина ограничений Memcached. В отличие от Redis это хранилище не поддерживает продвинутые структуры данных, снапшоты, репликацию, некоторые типы данных (например, геоданных) и имеет ряд других ограничений.
С другой стороны, Memcached — многопоточное хранилище, а Redis — нет, что дает первому некоторые преимущества в производительности. Тем не менее, наличие продвинутых инструментов работы с данными делает Redis предпочтительнее, чем использование Memcached, для большинства проектов.
Примеры использования базы данных Redis
Благодаря новым моделям хранения данных сфера применения Redis широка. Вот несколько областей, где востребовано это хранилище:
- Machine Learning. Современные модели машинного обучения работают с большими объемами данных, должны быстро создаваться и развертываться. Redis обеспечивает хранилище данных непосредственно в памяти, что обеспечивает высокую скорость работы моделей Machine Learning.
- Аналитика в режиме реального времени. Примерами такой аналитики могут служить таргетированная реклама, системы рекомендаций в социальных сетях, а также данные, собираемые с устройств IoT. Redis совместим с различными системами потоковой передачи (например, Apache Kafka, Amazon Kinesis) и обеспечивает высокую скорость обработки данных (задержка не более нескольких мсек).
- Кэширование. Создаваемый в памяти кэш значительно увеличивает скорость работы и производительность любой базы данных (как SQL, так и NoSQL) или приложения. Redis обеспечивает высокую скорость доступа к кэшированным данным без необходимости увеличения серверных мощностей.
Подробнее про кэширование в Redis →
- Хранилище сессий. Сессионные данные, включающие пользовательские профили, настройки, состояния, могут снижать скорость работы приложения. Redis решает эту проблему за счет хранения этих данных в кэшированном виде в памяти.
- Системы очередей в мессенджерах и чатах. Redis является однопоточной БД, поэтому команды обрабатываются только в определенной последовательности. Это делает его удобным для выстраивания системы очередей.
- Потоковая передача мультимедиа. Благодаря возможностям передачи данных в режиме реального времени Redis расширяет возможности сетей CDN по трансляции медиаконтента. В результате сети доставки контента реализуют одновременную передачу потоков видео миллионам пользователей.
Также Redis используют для работы с геопространственными данными, анализа продаж и поведения покупателей и клиентов, фильтрации контента. Кроме того, это хранилище задействуется в социальных сетях для потоков сообщений и для связи данных с профилями пользователей.
Redis в облачных базах данных Selectel
В числе готовых кластеров баз данных, которые поддерживает Selectel, есть и Redis. Вы можете создать кластер Redis версии 6 за несколько минут.
Подробнее о том, как работают облачные базы данных и кому нужен Redis:
- Как использовать облачные базы Redis
- Redis: как работать, где применять, какие ограничения (видео)
- Облачные базы данных: что это такое
- Старт работы с облачными базами данных
Заключение
Redis предлагает высокую скорость обработки данных благодаря их хранению в ОЗУ. Это делает эту СУБД одним из лучших решений для систем и приложений с большими объемами данных при необходимости непрерывного доступа к ним.
Автор: Роман Андреев





