
Думаю, у каждого были ситуации, когда специальные инструменты помогали решать сложные рутинные задачи. Например, с помощью обжимки кабеля намного проще нарезать патчкорды, чем ножом и отверткой. Изоляция в Docker избавляет от беспорядка с зависимостями.
Привет! Меня зовут Антон, я DevOps-инженер в Selectel. Мне часто приходится настраивать инфраструктуру для обучения и инференсинга моделей на GPU в Kubernetes. Хочу поделиться волшебным инструментом, который позволяет это делать без костылей и велосипедов, если у вас лапки.
В этой статье расскажу и про боли при настройке видеокарт для ML-задач, и про лекарство — GPU-оператор. Разберемся на примере с GPU NVIDIA, но и для AMD общая концепция будет похожа.
Проблемы при настройке GPU на серверах
Представим ситуацию. Мы хотим обучать модели или инференсить на GPU. Для этого используем PyTorch или Tensorflow, а чтобы фреймворки имели прямой доступ к GPU — устанавливаем CUDA. Основная боль, с которой мы сталкиваемся, — зависимости различных версий фреймворков, CUDA и драйверов друг от друга. А также сложность управления ими в инфраструктуре.
Что учитывать в конфигурации GPU на сервере
Допустим, мы хотим обучать нашу модель на удаленном виртуальном сервере, в каком-нибудь Jupiter Lab с доступом к GPU. Для этого нужно выполнить некий набор действий.
- Подключить GPU непосредственно к серверу. Если это облако, то там также пробрасывается GPU к конкретному хосту.
- Получить нужную версию драйвера для конкретной видеокарты. В случае с NVIDIA можно воспользоваться калькулятором.
- Установить нужную версию CUDA.
- Если работаем с контейнеризацией — настроить NVIDIA container toolkit. Потребуется внести небольшие изменения в конфиг etc/containerd/config.toml нашего демона (docker или containerd) — указать правильное значение параметра default_runtime_name. Либо при запуске прописать в контейнере флаг –runtime=NVIDIA.
При этом нужно помнить про зависимости различных компонентов системы. Разберем пример с GPU Tesla T4.
Совместимость фреймворка

Одна и та же версия PyTorch может быть актуальна для разных версий CUDA. При этом установка через pip может различаться — например, для CUDA 11.8 или 12.4 нужно указывать через флаг –index-url специальный репозиторий:
pip3 install torch torchvision torchaudio \
--index-url https://download.pytorch.org/whl/<cu118 или cu124>
Также для каждой версии CUDA необходимо учитывать, что нужна специальная версия драйвера.
Получается, что версия фреймворка зависит от версии CUDA, а версия CUDA — от версии драйвера. Думаете, что на этом все и можно расходиться?
Совместимость драйвера
На деле нужно учитывать еще несколько факторов. Версия драйвера должна согласовываться с версией ОС и ядра Linux.
Верхняя граница номера версии ограничивается архитектурой. Например, Kepler-архитектура не позволит поставить драйвер выше 475 версии, а значит и новые версии CUDA будут недоступны.

Приходится учитывать и назначение видеокарты — она может быть обычной (GTX 1080, 2080 и т. п., например, для игры в Cyberpunk), а также специализированной (A100, Tesla T4, A2 и т. п., например, для дата-центров). Для разных видов GPU существуют свои версии CUDA и допускаются различные серии драйверов. Подробнее можно прочитать на сайте NVIDIA в разделах для специализированных и обычных драйверов.
Не правда ли, очень трудно держать все эти зависимости в голове? В своем Telegram-канале я собрал ссылки на полезные источники и совместимости компонентов. Изучайте и сохраняйте для своего удобства!
Совместимость ядра ОС
К сожалению, не удалось найти источник, описывающий совместимость драйверов с различными ядрами Linux: есть только CUDA. Такой недостаток информации об особенностях работы видеокарт однажды сказался на возможности использования некоторых наших облачных образов на нодах Kubernetes с предустановленными драйверами.
Согласно политике безопасности, мы обновляем образы раз в неделю. В один прекрасный момент ядро Linux в Ubuntu 22.04 обновилось до версии 5.15.0-113. Вот тут-то неожиданно и выяснилось, что 520-ая версия драйвера, которая использовалась по умолчанию, совместима не со всеми ядрами.

Пришлось экстренно обновлять драйвер до последней версии. Вот почему надо следить за актуальностью драйверов GPU так же внимательно, как и за актуальностью ядра Linux!
Небольшой гайд по выбору драйверов
Чтобы не копаться во всех зависимостях самостоятельно, предлагаю небольшой алгоритм по выбору подходящей версии драйверов GPU.
Представим типовой случай. Мы устанавливаем драйверы последней версии по умолчанию. Все они имеют обратную совместимость с CUDA — работают с ее предыдущими версиями.
Воспроизводим инфраструктуру заказчика. Берем драйвер в точности как в воспроизводимой инфраструктуре.
Если не можем использовать самый свежий драйвер, отталкиваемся от версии ОС и ядра. В списке поддерживаемых версий драйверов разных GPU ищем архитектуру своего видеопроцессора. Ongoing означает, что поддерживается последний (latest) релиз. Если есть верхнее ограничение для номера версии — учитываем.
Не забываем, что и ядра ограничивают доступные версии CUDA. А еще — задачами и фреймворком. Поэтому в своей инфраструктуре для запуска CUDA лучше использовать контейнеры, а на виртуальные серверы устанавливать только драйверы. У NVIDIA контейнеры уже подготовлены.
А что в Kubernetes?
Мы разобрались, как настраивать драйверы и CUDA на виртуальной машине. Теперь узнаем, как это делать в Kubernetes.
В дополнение к описанному выше нужно соблюсти несколько условий.
- На нодах необходимо разметить, где какой GPU аллоцирован. Это можно сделать с помощью labels.
- Важно учитывать емкость ресурсов: если поды размещаются на нодах с GPU, то нужно помечать их занятость.
- Должен быть организован мониторинг GPU с помощью DCGM для получения обратной связи.
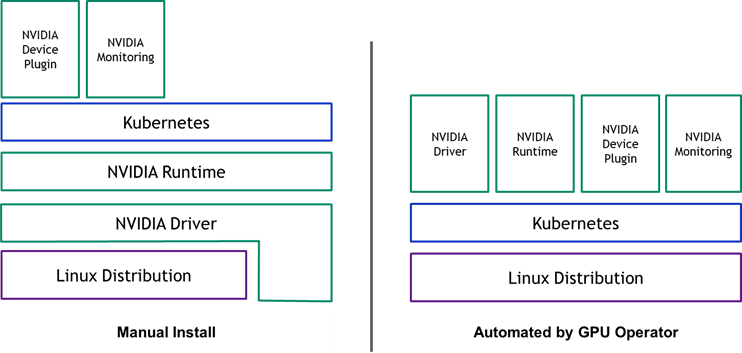
Как видно, основная проблема заключается в том, что если конфигурировать GPU для работы моделей вручную, нужно учитывать взаимозависимость CUDA, фреймворков и драйверов. А также внимательно следить за постоянными обновлениями и управлением кластерами. Но так как мы не хотим «пачкать наши лапки», давайте посмотрим, как с этим справляется GPU-оператор от NVIDIA.
Автоматизируем настройку GPU с помощью оператора
GPU-оператор — это набор сервисов, которые устанавливаются в кластер Kubernetes с помощью Helm-чартов.
Список всех сервисов доступен в документации на сайте NVIDIA, а мы же пробежимся только по основным.
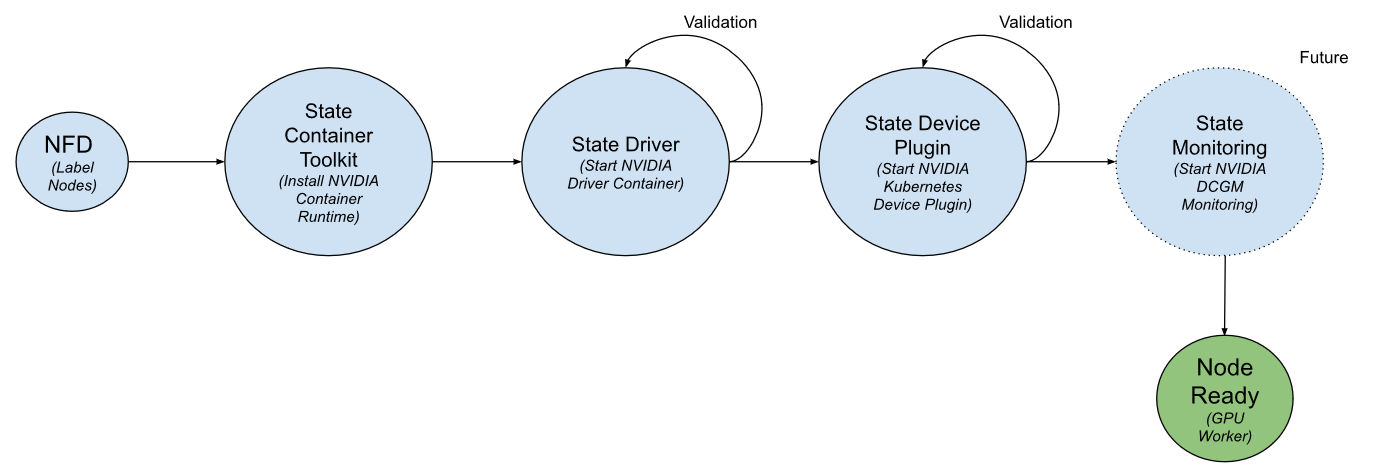
- Nvidia feature discovery с помощью labels автоматически помечает ноды в соответствии с найденными признаками. Например, название GPU, закрепленной за нодой.
- NVIDIA container runtime устанавливает NVIDIA runtime, чтобы наши поды могли использовать GPU.
- NVIDIA driver container устанавливает выбранную версию драйвера на ноду.
- NVIDIA Kubernetes device plugin — сервис, который позволяет управлять емкостью доступных GPU через ресурсы Kubernetes. Он ставит на ноды ресурс nvidia.com/gpu, где целым числом обозначается количество доступных видеопроцессоров.
- NVIDIA dcgm monitoring ставит экспортер от DCGM, где мы отслеживаем GPU, утилизацию и память.
Сервисы запускаются в формате daemon set — на все ноды, которые удовлетворяют выбранным node selector.
Быстрый старт
Для установки всех сервисов можно использовать настройки по умолчанию в values.yaml Helm-чарта, плюс указать необходимую версию драйвера GPU. Этого будет достаточно для кейсов, где требуется кластер, готовый для запуска подов с доступом к видеопроцессору.
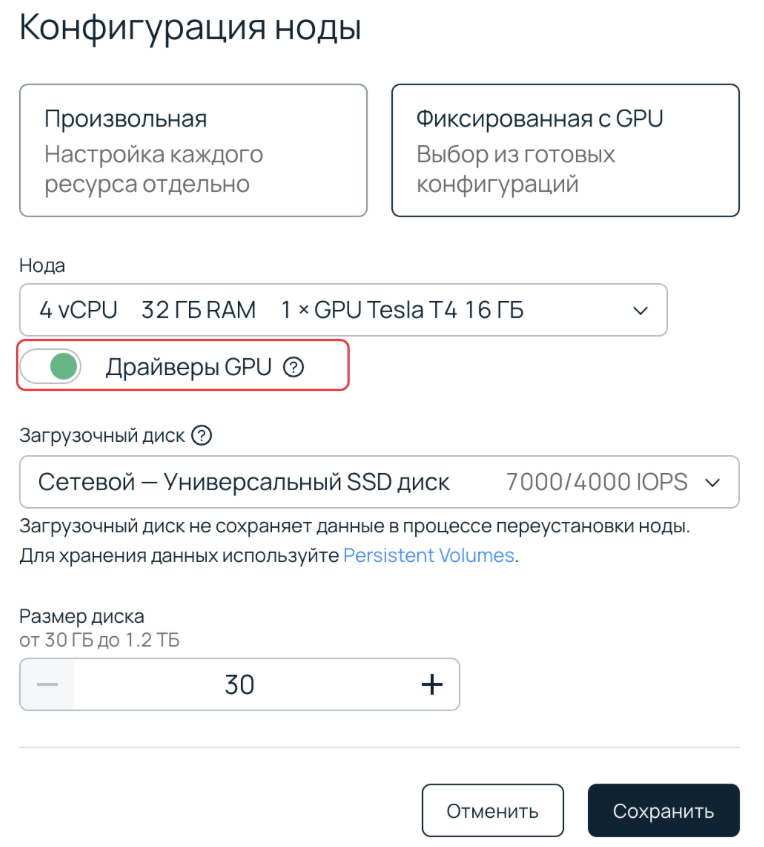
Кстати, недавно вышло обновление в Managed Kubernetes. Теперь есть возможность разворачивать ноды с GPU без предустановленных драйверов! Это значит, что можно установить GPU-оператор и самостоятельно менеджерить конфигурации GPU-нод. Чтобы попробовать, достаточно снять галочку Драйверы GPU при конфигурировании.
1. Добавим официальный репозиторий Helm-чартов от NVIDIA:
helm repo add NVIDIA https://helm.ngc.NVIDIA.com/NVIDIA \
&& helm repo update
2. Установим с выбранной версией драйверы:
helm install --wait --generate-name \
-n gpu-operator --create-namespace \
NVIDIA/gpu-operator \
--set driver.version=<option-value>
Готово! Если кейс достаточно прост, на этом этапе конфигурирование GPU в кластерах уже можно считать автоматизированным.
Важно. GPU-оператор готовит кластер для использования контейнеров с доступом к GPU. Он устанавливает драйвер и container toolkit, но при этом не загружает CUDA — ее версией вы оперируете в контейнерах самостоятельно.
Для тех, кому простые универсальные кейсы не подойдут, предлагаю рассмотреть более сложные варианты применения GPU-оператора.
Мультидрайверность
Не всегда можно установить актуальный релиз драйвера для конкретной инфраструктуры. Поэтому полезно поддерживать установку разных версий на ноды Kubernetes, если они работают с GPU, которые не поддерживают крайние релизы драйверов или используются разные ядра Linux. Для таких кейсов в GPU-операторе предусмотрены CRD, которые позволяют на отдельные ноды поставить драйверы разной свежести. Как это сделать?
1. Создадим CRD с версией драйвера и укажем node selector, чтобы драйверы устанавливались только на ноды, где есть соответствующий лейбл:
apiVersion: NVIDIA.com/v1alpha1
kind: NVIDIADriver
metadata:
name: driver-550
spec:
driverType: gpu
env: []
image: driver
imagePullPolicy: IfNotPresent
imagePullSecrets: []
manager: {}
nodeSelector:
driver.config: "driver-550"
repository: nvcr.io/NVIDIA
version: "550.90.07"
2. Задаем лейбл для требуемой ноды:
kubectl label node <name> --overwrite \
driver.config="driver-550"
3. Ставим чарт с нужными опциями:
helm install --wait --generate-name \
-n gpu-operator --create-namespace \
NVIDIA/gpu-operator \
--set driver.NVIDIADriverCRD.enabled=true
4. С помощью манифеста ниже можно проверить драйвер командой nvidia-smi — она покажет версию драйвера, если все успешно установилось:
apiVersion: v1
kind: Pod
metadata:
name: NVIDIA-smi-550-90-07
spec:
containers:
- name: NVIDIA-smi-550-90-07
image: "nvcr.io/NVIDIA/driver:550.90.07-ubuntu22.04"
command:
- "NVIDIA-smi"
resources:
limits:
NVIDIA.com/gpu: 1
Эффект Манделы в команде nvidia-smi
Когда я впервые столкнулся с этой командой, то испытал тот самый эффект Манделы. Посмотрим на вывод:
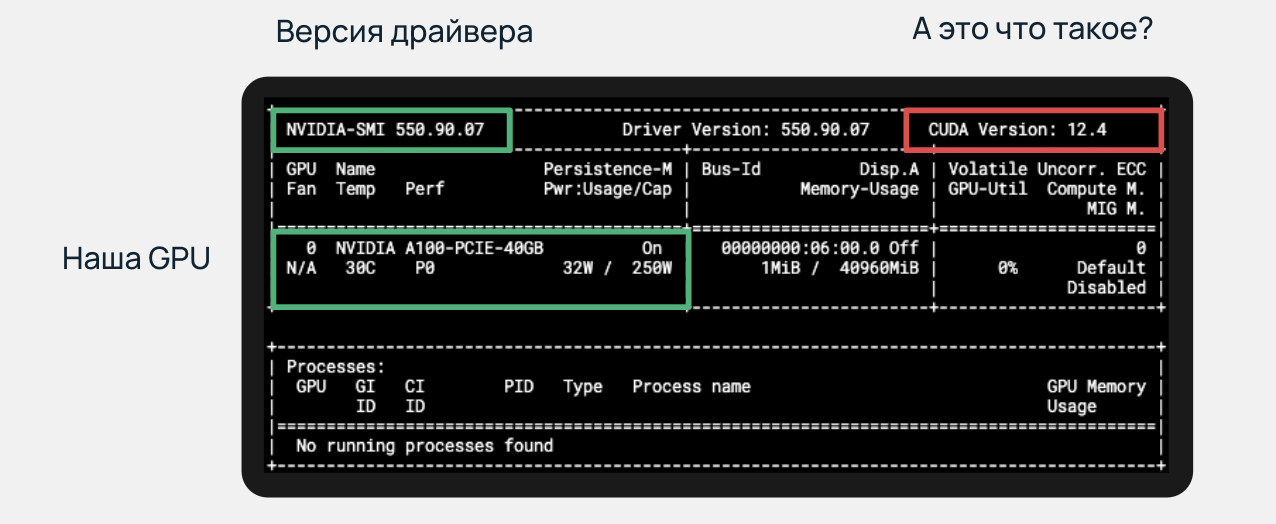
Команда nvidia-smi показывает актуальную версию установленного драйвера, информацию о GPU и, как можно заметить в верхнем правом углу, версию CUDA. Внимание! Это совместимая версия, а не установленная, которую можно узнать с помощью nvcc –version. Вспоминайте об этом каждый раз, когда попадается на глаза эта табличка.
Precompiled Driver Containers
Бывает, что в кластере не хватает вычислительной мощности для обычной установки драйверов, так как компиляция ядра требует ресурсов. Или же нет доступа к интернету в кластере для скачивания в процессе установки дополнительных пакетов из общей сети. В таком случае могут помочь готовые контейнеры от NVIDIA, которые уже содержат скомпилированные драйверы.
Надо заметить, что предложению от NVIDIA присуще несколько ограничений. Оно пока не готово к использованию в production и совместимо только с Ubuntu 22.04. Тем не менее, решение вполне рабочее. Контейнеры можно взять в NGC Catalog и разместить в приватном Docker-репозитории, например в реестре контейнеров Selectel. Также документация NVIDIA подробно описывает самостоятельную сборку контейнеров.
Использовать контейнеры достаточно просто, нужно только указать в Helm-чарте определенные параметры:
helm install --wait gpu-operator \
-n gpu-operator --create-namespace \
NVIDIA/gpu-operator \
--set driver.usePrecompiled=true \
--set driver.version="<driver-branch>"
Также можно использовать контейнеры в паре с CRD для мультидрайверности. Принцип работы хорошо описан в документации.
Как мы применяем GPU-оператор
Обычный кейс использования
Мы в Selectel разрабатываем ML-платформу, где используются сервисы с доступом к GPU, такие как ClearML, JupyterHub, KServe. Разворачиваем их на базе Managed Kubernetes, куда как раз и устанавливаем GPU-оператор.
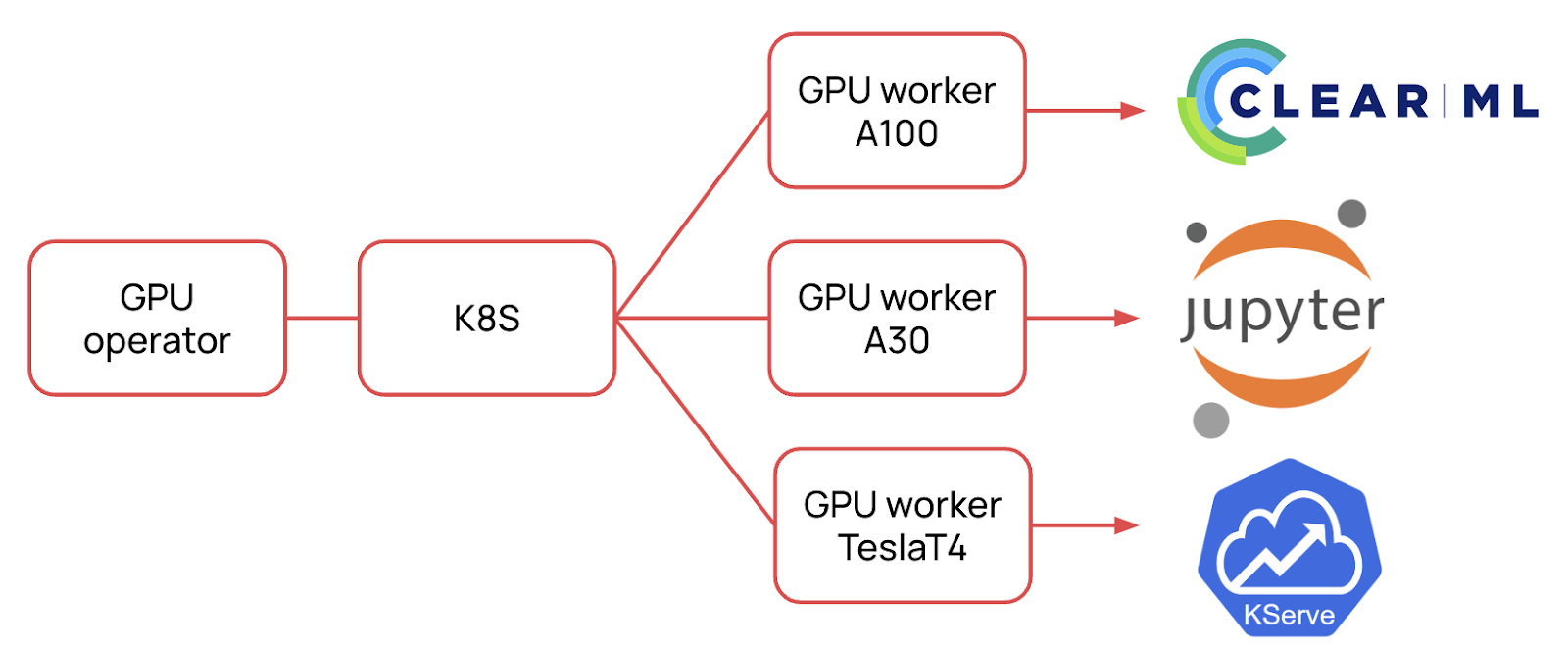
Базовый сценарий прост. С помощью Terraform мы разворачиваем платформу и через Helm-чарты ставим все сервисы. Подробнее о том, как мы это делаем, я рассказывал в статье. GPU-оператор в этом случае размечает ноды, ставит последнюю версию драйвера и объявляет ресурсы nvidia.com/gpu.
Автоскейлинг
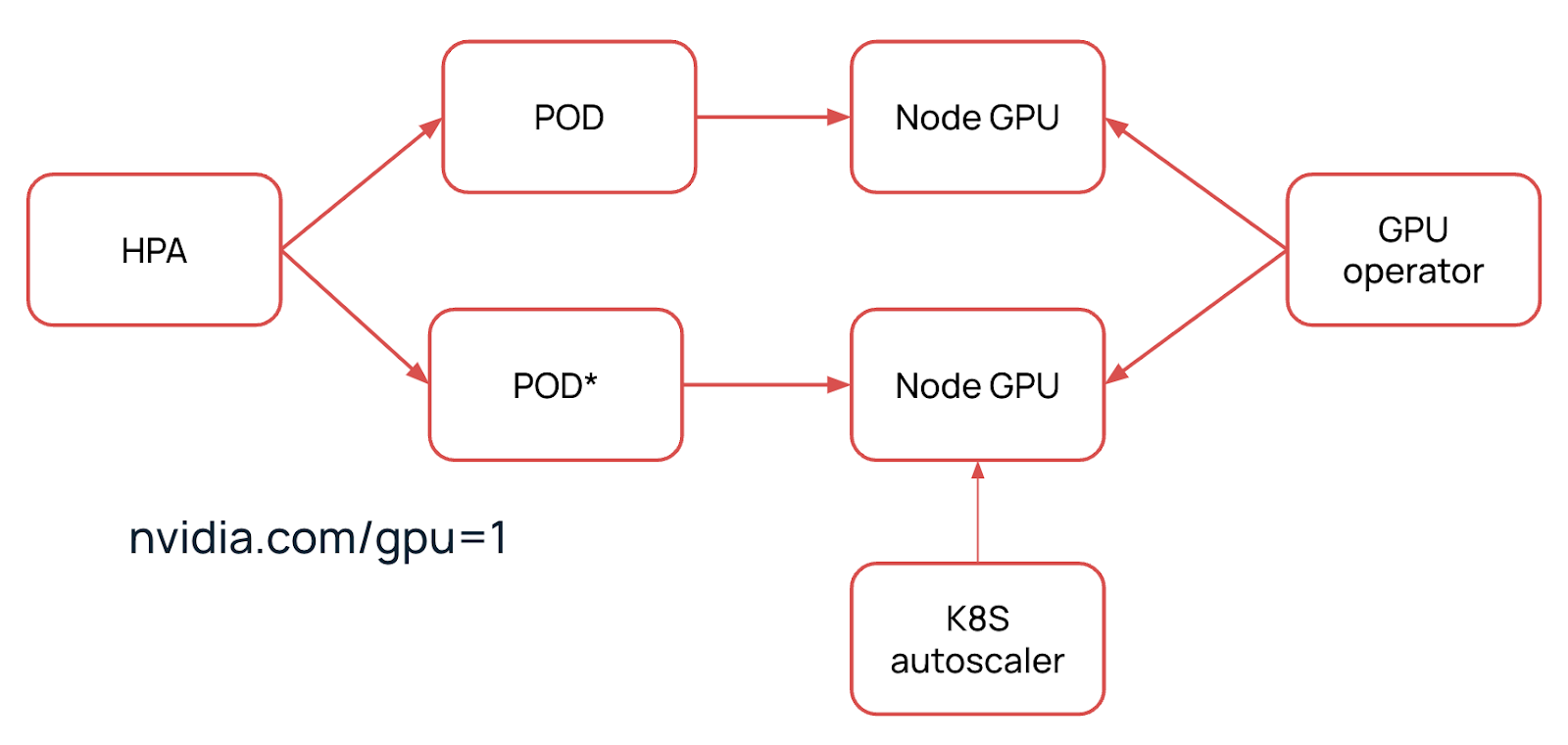
В нашем Managed Kubernetes доступен автоскейлинг GPU-нод. Если у вас настроен Horizontal Pod Autoscaler, то при превышении указанной метрики он поднимет под, которому потребуется ресурс nvidia.com/gpu. При его отсутствии автоскейлер поднимет новую ноду с GPU, а оператор с помощью демонсетов установит внутрь необходимую версию драйвера и container toolkit. Далее ресурс станет доступен, а под аллоцируется на новую ноду.
Шеринг ресурсов на одной видеокарте
Мы также используем GPU-оператор для запуска нескольких ML-инстансов на одной видеокарте. Подробнее о том, как это работает, я писал в цикле статей о шеринге GPU. При этом отмечу, что GPU-оператор теперь официально поддерживает MPS — это значит, что возможностей для шеринга видеокарт стало больше!
Заключение
Конфигурирование серверов для работы с GPU — не самая тривиальная задача, которая требует много ручных операций. И хорошо, что товарищи из NVIDIA смогли автоматизировать этот процесс с помощью специального оператора, работа с которым не требует ни особых усилий, ни знаний Ops-части.





