Алгоритмы машинного обучения: основные способы тренировки моделей в ML
Популярные алгоритмы обучения ML-моделей: рассказываем про основные методики тренировки в машинном обучении
Когда-то ученые только мечтали о том, чтобы машины учились, как люди, то сейчас алгоритмы машинного обучения окружают нас ежедневно в нашей цифровой жизни. Они помогают составлять рекомендации в ленте, прогнозировать цены квартир, распознавать породу кота по фотографии, делать саммари целых книг и много чего еще. Самое время разобраться, как это устроено на самом деле.
Что такое алгоритмы машинного обучения
Начнем с того, что такое алгоритм. В самом общем случае — это четкая конечная последовательность шагов или инструкций, которые необходимо выполнить для решения конкретной задачи и получения заданного результата.
В программировании под алгоритмом обычно понимают код, который решает какую-нибудь задачу, например, считает сумму двух чисел. Чтобы написать, как именно сложить эти два числа, человек анализирует проблему, придумывает логику и записывает ее в виде кода. Если вдруг вместо двух чисел нужно будет сложить три, код надо будет переписать вручную (или заранее предусмотреть, чтобы можно было вводить больше чисел).
Главное, что здесь и проектированием, и написанием, и внесением изменений занимается человек. А результат такого алгоритма всегда детерминирован, то есть одинаков при одинаковых данных. Например, если дать программе-сумматору на вход 1 и 1, то он всегда получит 2, сколько раз вы бы ни вводили в программу 1 и 1.
Алгоритмы машинного обучения отличаются от обычных тем, что автоматически улучшаются благодаря опыту или новой информации. Алгоритм самостоятельно находит закономерности в данных. Программист не пишет правила «вот возьми столько чисел, сложи их, выведи результат». Вместо этого он дает машине много примеров сумм (данных) и говорит: «Вот исходные данные, а вот правильный результат. Найди связь».
Алгоритмы машинного обучения — это способы показать компьютеру, как именно нужно искать связи и учиться. Соответственно, их нужно обучить. О том, как именно это делается, мы поговорим в следующей главе. А пока просто запомним, что результатом работы алгоритма после обучения становится натренированная модель. Именно обученная модель может предсказывать результат для новых, ранее не виденных данных.
Результат ее работы может отличаться, так как модель находит не «правильный ответ», а только значение с наибольшей вероятностью того, что правильный ответ будет именно таким. То есть если ей ввести «посчитай 1+1», то модель вычислит, что с вероятностью 99% ответ будет 2, а с вероятностью 1% — какой-то другой.
Благодаря вероятностным, а не однозначным ответам алгоритмы машинного обучения помогают решать задачи, для которых может быть несколько правильных решений или нет однозначно верного ответа.
Например, нам нужно сделать резюме текста. Это возможно несколькими способами, но смысл получится передать один и тот же. Допустим, нужно в одном предложении выразить сюжет «Колобка».
Или, например, нам нужно предсказать цену квартиры через пять лет. Однозначно верного ответа у нас еще нет, так как он появится только через пять лет. Но на основе данных за прошлые 20 лет модель может предсказать какое-то число, которое может даже оказаться верным.
Так, а от чего зависят ответы модели? Ответы и их качество напрямую зависят от алгоритмов в основе и построении процесса обучения. Дальше как раз о них и поговорим.
Типы машинного обучения
Прежде чем модель сможет решать задачи, ее нужно обучить. Но чему? Как? Сейчас разберемся. В зависимости от задачи, которую нужно решить, выбираются и методы обучения моделей. А сами данные для обучения моделей называются датасетом. Дальше датасет делится на две части:
- данные, на которых учится модель — это обучающая выборка,
- данные, на которых модель тестируют — это тестовая выборка.
Само по себе обучение — это процесс того самого поиска связей между данными.
Обучение с учителем (Supervised Learning)
Применяется, когда модель можно обучить на примерах. В этом случае в датасете должны быть заранее известные ответы для каждой единицы данных. Причем они могут быть выражены по-разному, это зависит от задачи.
Например, нам нужно распознать, кто на фото: кот или мышь. Тогда в нашем наборе данных будут 1 000 фотографий с подписью «кот» и 1 000 фотографий с подписью «мышь». И модель в процессе обучения выявляет закономерности, по которым в будущем будет выдавать свой вердикт на основе того, что она уже видит примеры, что есть что.
Тем не менее при таком подходе все равно есть шансы, что модель перепутает кота и мышь, потому что у животного в любом случае могут быть шерсть, усы, четыре лапы, хвост или очень похожие очертания на конкретном фото.
Другой пример. Банкам нужно оценивать, вернет ли человек займ. В этом случае единицами данных могут быть пол, семейное положение и заработок предыдущих клиентов банка, а ответами — отметка, вернули ли они займ. Рассмотрим задачи, для которых применяется обучение с учителем.
Бинарная классификация
Модель учится определять ровно два класса. Давайте расскажу все на примере тех же котиков. Пользователь отдает модели изображение и спрашивает, кот на нем или нет. Модель может ответить только в духе «Да, это кот» или «Нет, это не кот». То есть весь мир такой модели состоит из двух сущностей: коты и не коты.
При качественном обучении она без труда отличит котика от чего угодно, но при этом для нее не будет разницы, скажем, между кроватью и самолетом. И то и другое для нее просто «не кот». На практике бинарная классификация часто применяется банками.
Мультиклассовая классификация
А вот в этом случае модель уже способна различать несколько классов. Если вернуться к предыдущему примеру, то она сможет не просто отличить кошку от всего остального, но и, к примеру, назвать ее породу. А, скажем, sentiment-модели могут определить тональность текста: негативный, позитивный или нейтральный.
Еще выделяют мультиклассовую классификацию с пересекающимися классами. Это актуально, когда одна сущность имеет несколько классов. Например, ML-модели могут проанализировать текст отзыва о товаре и создать для него подходящие теги (приятный продавец, качественная упаковка, долго служит и т. д.).
Регрессия
Модель учится предсказывать конкретное значение. Например, погоду в городе завтра или цену на квартиру через пять лет. Подробнее рассмотрим чуть ниже.
Ранжирование
Модель учится предсказывать ранги объектов. Например, у нас есть две рекламы: реклама зонтиков и панамок. Какую мы покажем именно сегодня? Нам важнее, чтобы в дождливый день показывалась реклама зонтиков, а не панамок.
А как это предсказать? По факту модель предскажет числа для каждой из реклам. Тот вариант, у которого число больше, — самый релевантный или подходящий. И тут не важно, какое именно число будет предсказано. Важно, чтобы оно было больше или меньше, чем другие предсказанные числа.
Так, отвечая на вопрос «какую рекламу показать в дождливый день?» модель должна предсказать для зонтиков, скажем, 52, а для панамок — 9. Ну или 84 для зонтиков и 61 для панамок. Раз сами цифры не важны, то в нашем примере число для зонтиков должно быть больше, чем для панамок. А в солнечную погоду, соответственно, наоборот.
Обучение без учителя (Unsupervised Learning)
Этим типом обучения решаются задачи, если у нас имеется набор данных, но нет для них ответов. Чаще всего так решаются задачи кластеризации: когда модель должна разделить наши данные на группы по некоторым признакам или свойствам. Например, кластеризация логов для выявления аномалий.
Обучение с подкреплением (Reinforcement Learning)
В этом случае алгоритм моделирует обучение методом проб и ошибок. И вместо заучивания данных и ответов модель работает с некоторой средой, а вместо ответов получает награду или наказание. Так модель «понимает», успешно она справляется с задачей или нет.
Например, вам нужно научить робота ездить на велосипеде и проезжать 100 метров. Модель внутри робота будет совершать некоторую последовательность действий вслепую. Если проедет один метр, ей будет начислен +1 балл. Но за каждое падение начисляется штраф в -1 балл.
Действия, которые привели к падению, алгоритм будет считать неудачными и меньше их использовать в своем движении к результату. Так, рано или поздно алгоритм подберет необходимую последовательность действий, чтобы все-таки проехать 100 м.
Что такое переобучение и недообучение
Модели учатся итеративно (эпохами). Если число эпох будет подобрано неверно, то можно столкнуться с несколькими проблемами.
Недообучение (Underfitting)
Если итераций будет слишком мало, модель не сможет достаточно хорошо научиться определять признаки. Тогда она будет плохо работать на любых данных: и тестовых, и тренировочных.
Переобучение (Overfitting)
Если итераций будет слишком много, то модель выявит, напротив, микропризнаки, по которым будет практически идеально ориентироваться в обучающих данных, но абсолютно теряться на тестовых.
Сколько итераций нужно для успешного обучения? Это определяется экспериментально или математически.
А успешное обучение — это что? Чтобы на первых этапах (до ввода в эксплуатацию) оценить качество модели, существуют различные метрики. Например, точность, расхождение ожидаемого и предсказанного значения, доля верно и неверно предсказанных значений и прочее.
Стоит учитывать, что для каждой задачи будут полезны разные метрики. Например, для предсказания погоды важнее, чтобы реальное и предсказанное значение расходились как можно меньше, а предсказания дождя или снега были высокой точности. Хотя на практике значения бывают редко близки к идеалу, поэтому важнее найти оптимально решающую задачу модель, а не стремиться к 100% точности.
Значимость датасета для корректного обучения
Успешное обучение модели и ее качество зависят не только от того, будет ли модель учиться с учителем или без и как долго. Датасет (напомним, это данные для обучения и тестирования модели) играет основополагающую роль в машинном обучении. Про нехватку или полное отсутствие данных мы уже сказали, а ведь бывает и так, что данные есть, но они плохие. В открытых датасетах могут встречаться ошибки, пропуски, выбросы или неточности, из-за которых качество модели будет неумолимо падать.
Подобные проблемы можно решать по-разному, в зависимости от качества датасета и того, какая модель будет использоваться в дальнейшем. Например, некоторые алгоритмы умеют работать с пропусками сами. Для других же данные придется удалить или заменить (например, медианным значением).
С выбросами (излишне отличающимися данными — вроде роста в 50 или 220 см) можно работать как с аномалиями и обрабатывать отдельно или просто удалять их и не использовать при обучении.
Для обучения модели данным нужны метки, например, подписи «кот» или «мышь» на фото. Этот процесс называют разметкой. Иногда на этом этапе возникают ошибки, которые часто становятся заметны постфактум, когда модель показывает плохие результаты при тестировании.
Если ошибок разметки слишком много, то датасет, вероятно, придется переделывать. Если ошибок немного, то, вероятно, их влияние на модель может быть незаметно или если мы их все же обнаружили, их стоит удалить.
Для предсказаний модель должна опираться на некоторые свойства или, как их еще называют, признаки данных. Например, признаками могут быть цвет пикселей, если пытаемся найти кота на фото, или доход человека, если пытаемся предсказать, вернет ли он займ.
Признаки могут быть самыми разными:
- численные — например, доход, вес, длина, время;
- категориальные — например, имена, цвета, названия пород (их можно также задать в виде чисел, например, красный — 1, а зеленый — 2);
- бинарные — «да» и «нет», «0» и «1». И с ними можно работать и как с численными значениями, и как с категориальными.
Представить данные также можно в нескольких форматах. Удобнее всего, если все признаки численные. Так можно работать с данными как с матрицей объектов и признаков.
Стоит помнить, что данные со временем тоже могут меняться, и это нормально. Это называется дрифт данных, или Data Drift. Например, у вас был сервис по распознаванию породы котов, но со временем люди стали присылать вам и фото собак. Такие изменения стоит мониторить и, например, менять подход к сбору таких данных (и запрещать отправлять фото не-котов) или переобучать модель, в том числе и на собак.
Популярные алгоритмы
Обучение с учителем
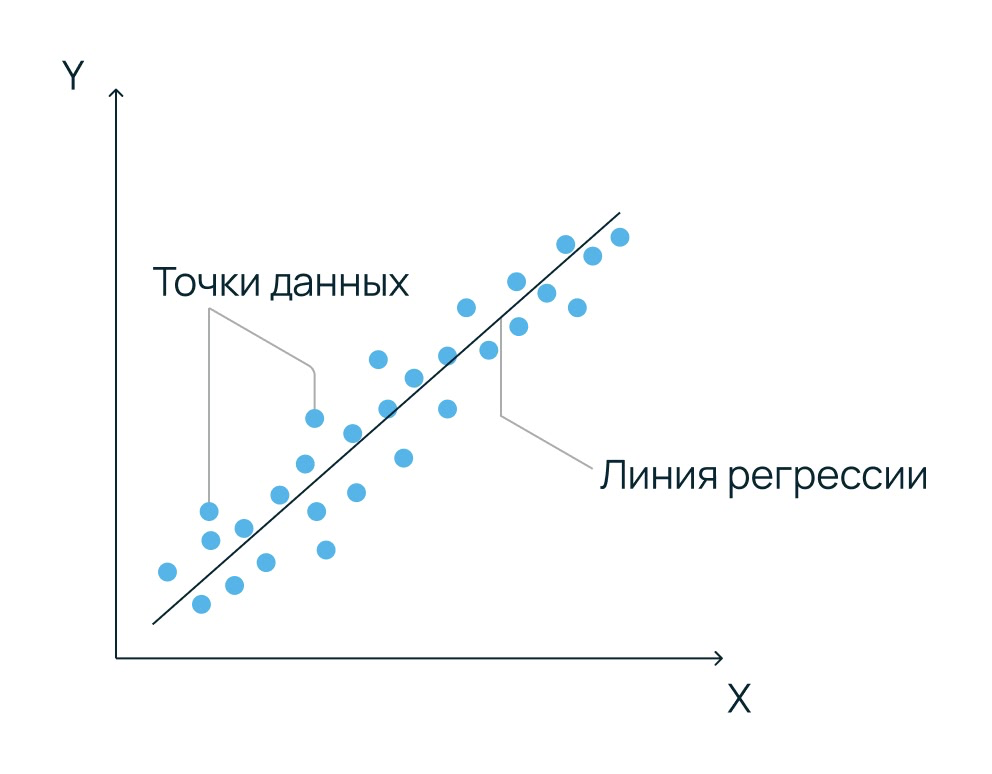
Линейная регрессия (Linear Regression)
Предсказывает непрерывное значение Y на основе признаков X. Алгоритм строит прямую (или гиперплоскость), минимизирующую отклонение данных от предсказания. Этот алгоритм эффективен только при наличии линейной зависимости. Для нелинейных трендов требуется трансформация признаков.
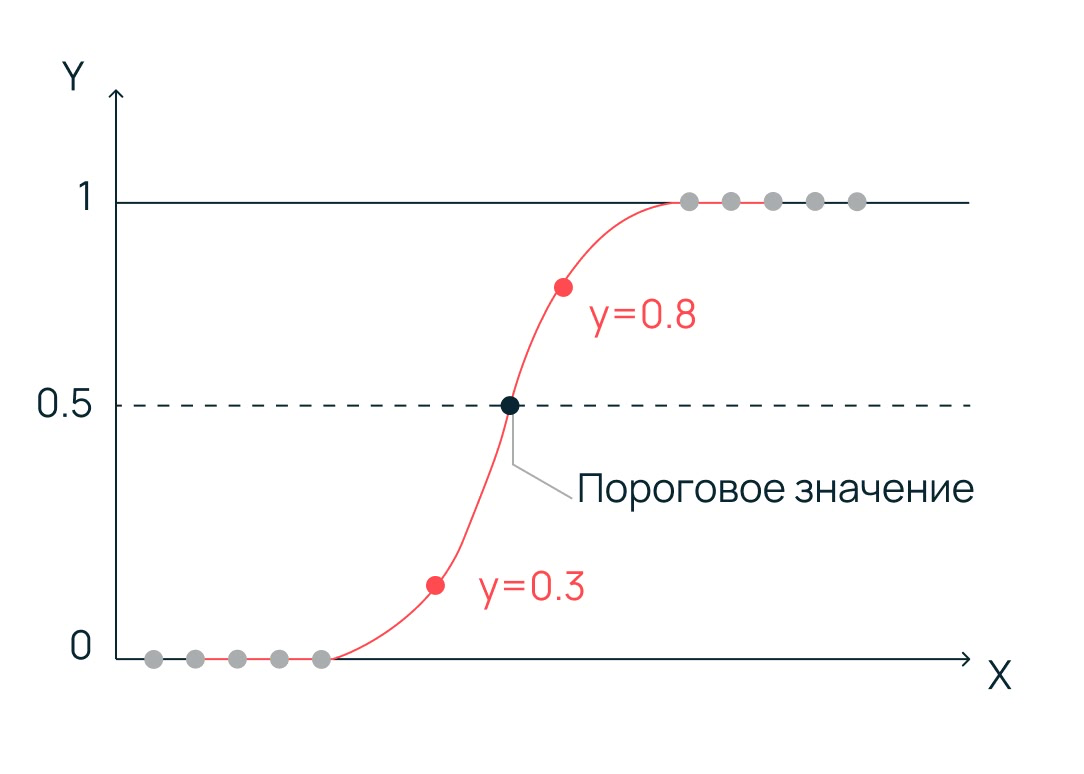
Логистическая регрессия (Logistic Regression)
Несмотря на название, это алгоритм классификации, а не регрессии. Результат предсказания представлен в виде числа в промежутке от нуля до одного. Если предсказание ниже порога значения, объект определяется как первый класс, а если выше — как второй.
Само же пороговое значение подбирается в ходе настройки алгоритма. Он отлично справляется с большим количеством признаков и сложными объектами, если данные линейно разделимы. Порог (threshold) обычно равен 0,5, но может настраиваться для баланса метрик точности и полноты.
Алгоритм k-ближайших соседей (K-Nearest Neighbors)
Относит объект к тому классу, который наиболее часто встречается среди k ближайших соседей в пространстве признаков. Например, у нас есть синяя точка. Мы решаем, что будем ориентироваться на пять ближайших соседей. Зеленых соседей два, а красных — три. Значит, и наша точка будет предсказана как красная.
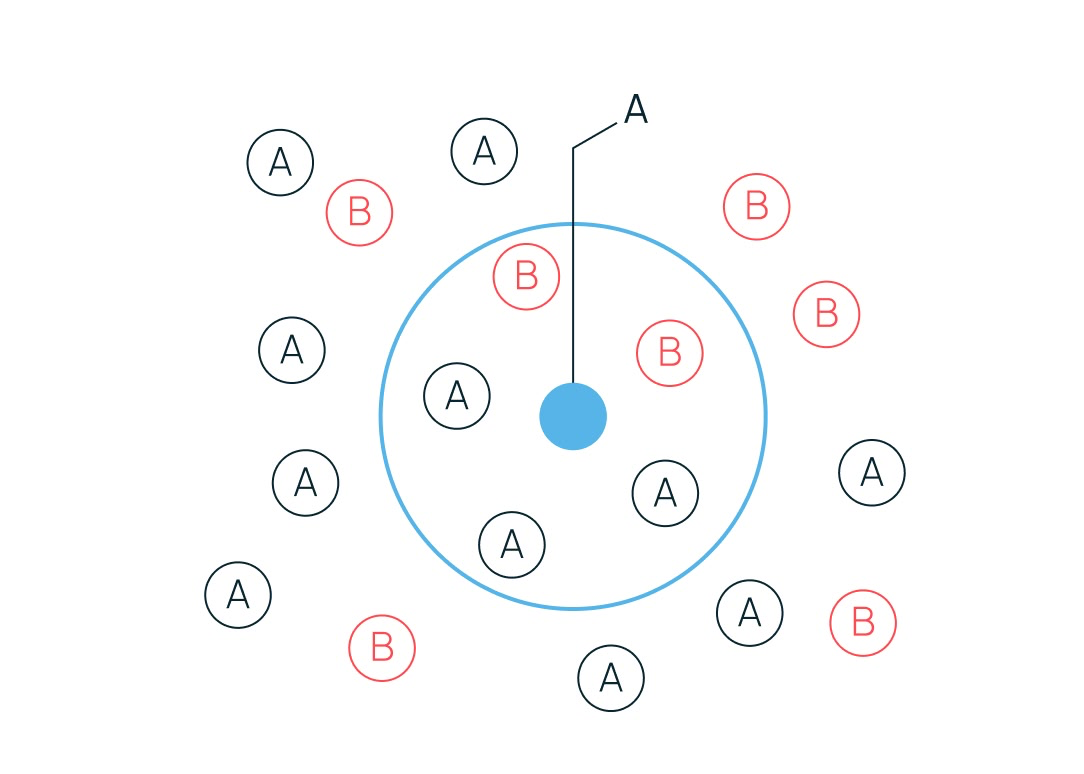
Из-за этого механизма опоры на ближайших соседей алгоритм очень чувствителен к масштабу данных (требуется нормализация) и «проклятию размерности». Проще говоря, если один параметр измеряется в тысячах, а другой — в единицах, алгоритм будет учитывать только «большие» цифры, ошибочно считая их более важными.
Представьте, что мы выбираем квартиру по двум признакам: цене (в миллионах) и количеству комнат. Если не сделать нормализацию, разница в 100 000 рублей будет для алгоритма в тысячи раз значимее, чем разница между однокомнатной и пятикомнатной квартирой, хотя для человека это не так.
Что касается размерности, при слишком большом количестве признаков объекты в пространстве становятся настолько далекими друг от друга, что само понятие «соседства» теряет смысл, так как все кажутся одинаково далекими.
В 2D-пространстве (на плоскости) найти соседа легко. В 3D — сложнее. А объем 100-мерного пространства (100 признаков) настолько велик, что данные будут распределяться по нему с крайне низкой плотностью. В итоге ближайший сосед может находиться чрезвычайно далеко.
Дерево принятия решений (Decision Tree)
Алгоритм представляет состояния объекта в виде дерева. Он разбивает данные на подмножества на основе логических правил (если признак A > значения X, то…). Каждая точка принятия решения называется узлом, а варианты выбора — ветвями. В самом низу находятся листья — это и есть итоговые ответы (классы или числа).
Алгоритм ищет такой признак A и такое пороговое значение X, которые лучше всего разделят данные на две максимально чистые группы.
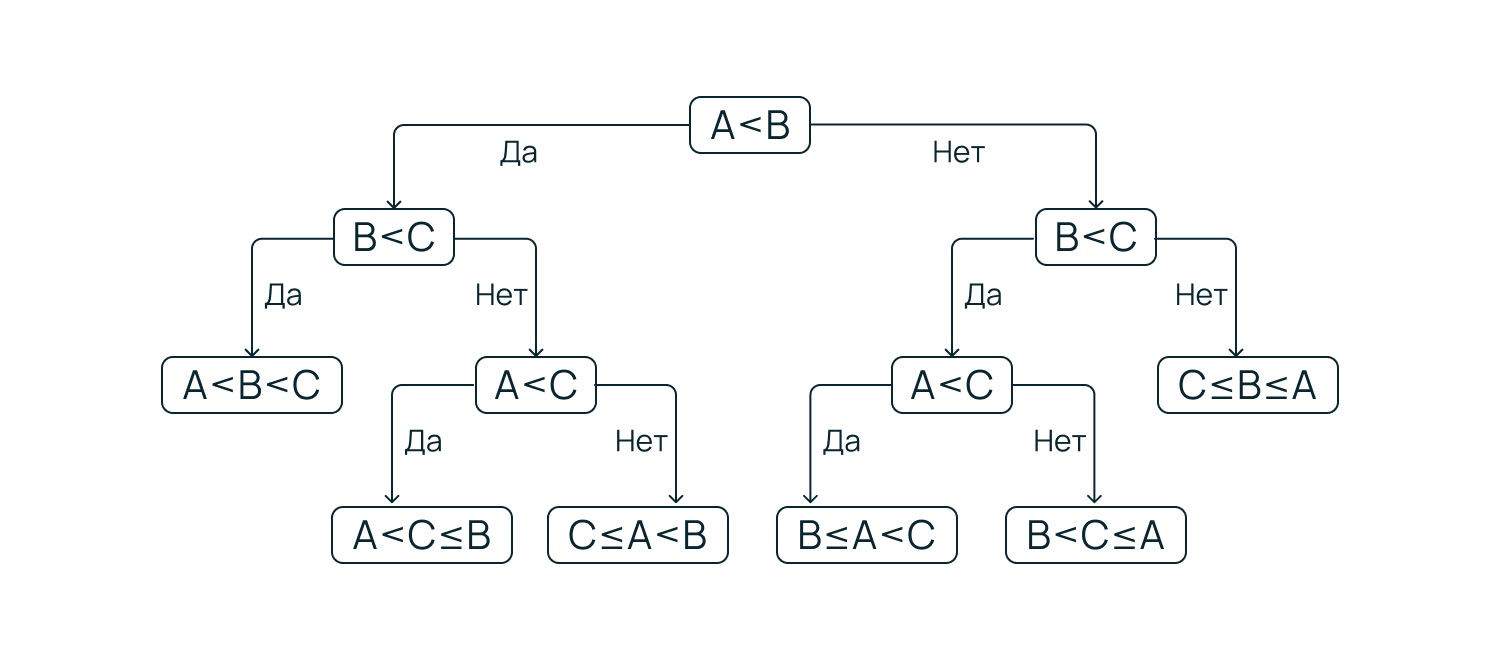
Он легко интерпретируется (что важно в банковской и медицинской областях), но склонен к переобучению. Если не ограничивать рост дерева, оно будет создавать новые и новые ветки до тех пор, пока в каждом листе не останется всего по одному объекту из обучающей выборки.
Случайный лес (Random Forest)
Из простых деревьев строится ансамбль из множества независимых деревьев, обучаемых на случайных подвыборках данных (бэггинг). Итоговое решение принимается путем голосования деревьев (для классификации) или усреднения (для регрессии). А применяются они там же, где и простые решающие деревья — для предсказаний на основе параметров и для классификации.
Градиентный бустинг
Метод построения ансамбля, где модели (обычно слабые деревья) обучаются последовательно. Каждая новая модель минимизирует ошибки предыдущих. Так продолжается до тех пор, пока не удастся достичь минимума функции потерь, не допустив переобучения. Сегодня это стандарт для табличных данных (библиотеки XGBoost, CatBoost, LightGBM).
Метод опорных векторов (Support Vector Machine)
Метод опорных векторов ищет идеальную границу — гиперплоскость, которая разделяет данные на разные классы. Его ключевое отличие от других алгоритмов в том, что он не просто проводит линию, а стремится создать вокруг нее максимально широкий «коридор» или зазор. Чем шире этот зазор, тем меньше вероятность, что новый объект попадет не в ту категорию из-за случайных шумов или отклонений в данных.
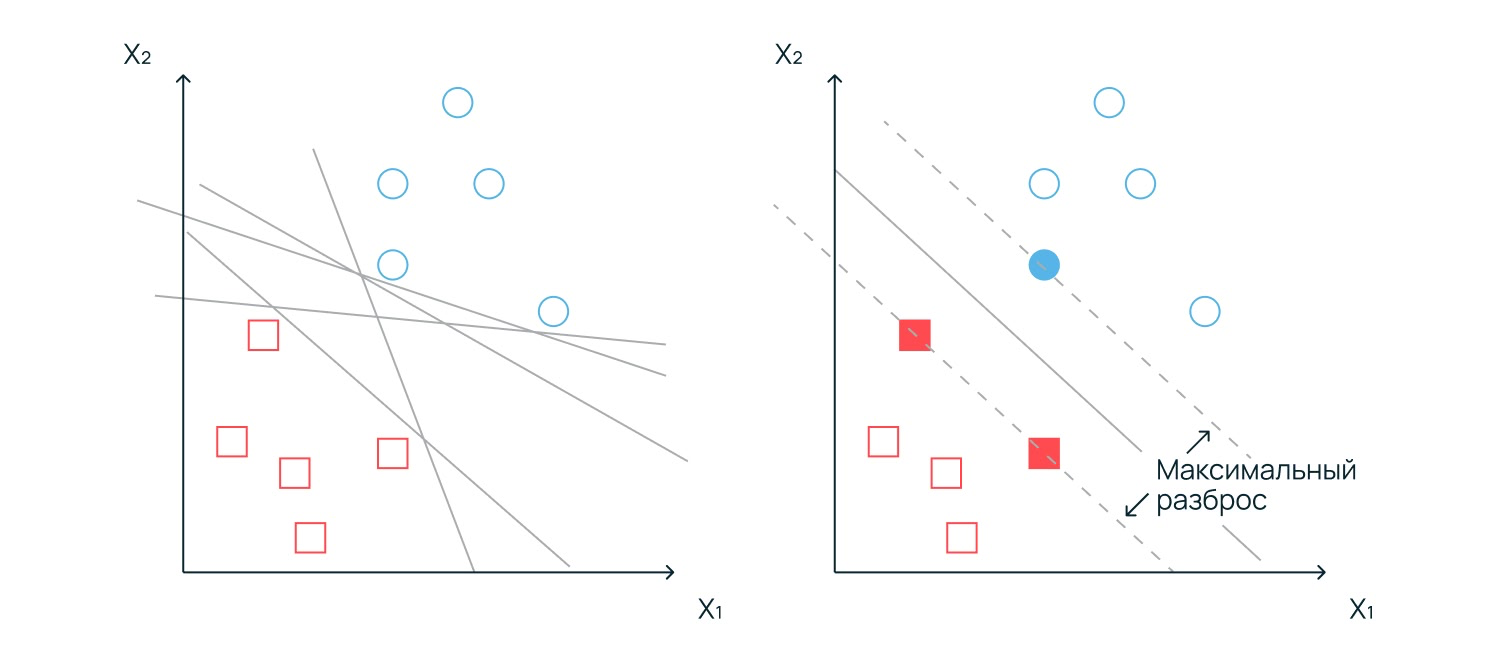
Свое название метод получил благодаря опорным векторам — это точки данных, которые находятся на самом краю своих групп, ближе всего к границе. Именно на них, как на опорах, держится вся разделительная полоса. Если мы изменим положение любой другой точки в глубине группы, модель не изменится, но если сдвинется хотя бы один опорный вектор, алгоритму придется перестраивать всю границу заново.
Наивный байесовский классификатор
Алгоритм основан на теореме Байеса, а называется «наивным», так как предполагает, что все признаки независимы друг от друга (что в реальности редкость). Он определяет класс, к которому принадлежит объект, на основе расчета вероятности, с которой объект относится к той или иной группе. Несмотря на это, он крайне эффективен в задачах вроде фильтрации спама.
Обучение без учителя
Напомним, что в обучении без учителя алгоритм не знает, что именно он видит, поэтому его задача — самостоятельно найти в массиве информации скрытые закономерности, структуру или схожие признаки.
К-средних (K-Means Clustering)
Разделяет данные на заранее заданное число кластеров «k». Он случайным образом выбирает центральные точки (центроиды), а затем итеративно «притягивает» их к центрам групп объектов. Процесс повторяется до тех пор, пока каждый объект не окажется в группе с максимально похожими на него соседями.
Важно помнить, что это именно кластеризация, а не классификация. В классификации (с учителем) мы заранее знаем названия групп, например, «спам» и «не спам». В кластеризации алгоритм действует проще: «вот эти объекты похожи между собой, поэтому я объединил их в группу №1, а эти — в группу №2». Что это за группы и по какому признаку произошло разделение, предстоит решить человеку.
Применяется для сегментации клиентов, сжатия изображений и анализа аномалий.
Глубокое обучение
На сегодняшний день именно эти алгоритмы лежат в основе распознавания лиц и персональных лент в соцсетях. Это подмножество машинного обучения, которое использует многослойные структуры, вдохновленные устройством человеческого мозга, что позволяет решать сложные задачи вроде обработки изображений и поиска сложных паттернов.
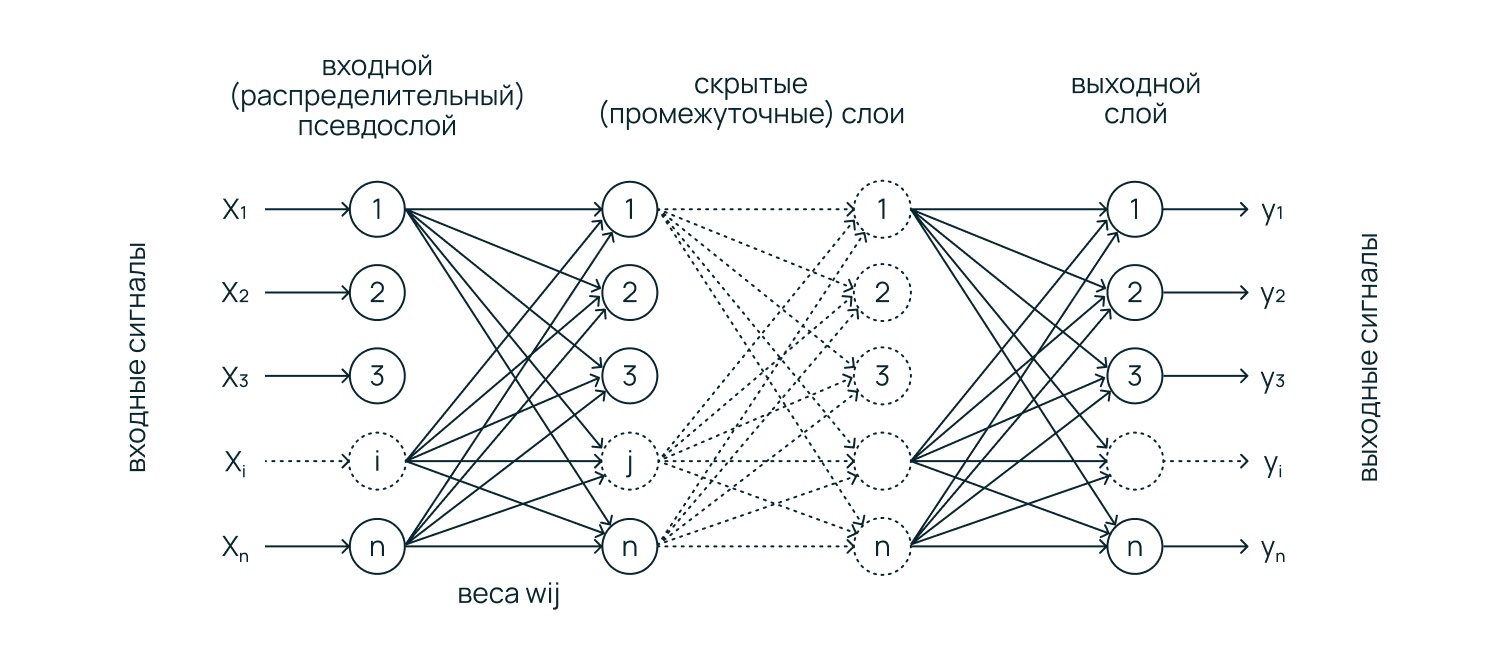
Нейросеть
Базовая нейросеть (перцептрон) состоит из слоев «нейронов». Каждый нейрон принимает данные, умножает их на определенный вес (степень важности) и передает результат дальше. В процессе обучения нейросеть подбирает эти веса так, чтобы на выходе получался некоторый правильный ответ. Такая имитация работы человеческого мозга позволяет решать задачи на поиск сложных, нелинейных связей в огромных массивах данных.
Как именно работают нейроны? Каждый нейрон выполняет простую математическую последовательность:
- нейрон получает сигналы. Каждый сигнал умножается на свой вес w, который определяет его важность;
- к сумме добавляется специальное число (смещение или bias, b), которое позволяет модели быть гибче и подстраиваться под данные, даже если все входные сигналы равны нулю;
- внутри нейрона происходит расчет;
- пропускает результат через функцию активации (например, ReLU или Sigmoid). Именно эта «математическая нелинейность» и позволяет нейросети распознавать сложные образы: от контуров лиц до смысла в тексте.
Нейроны объединяются в слои, через которые данные проходят как через фильтры. Сначала входной слой принимает сырые данные. Затем скрытые слои «обучаются» на некоторых признаках.
Первый скрытый слой может находить простые зависимости, второй — объединять их в более сложные детали, третий — в еще более сложные. Завершает процесс выходной слой, который выдает финальный результат, например, вероятность 0,98, что человек вернет кредит.
Само же обучение — это процесс автоматической подстройки весов w и смещений b. Упрощенно процесс выглядит так:
- сеть делает предсказание;
- функция потерь (loss function) вычисляет, насколько сильно сеть ошиблась. Фактически функция — это разница ожидаемого и предсказанного значения;
- алгоритм обратного распространения ошибки (backpropagation) проходит от выхода ко входу и раздает штрафы за ошибку каждому нейрону, немного корректируя их веса так, чтобы в следующий раз ошибка стала меньше.
Сверточная нейросеть
Это специализированный тип нейросетей, созданный специально для обработки изображений. Алгоритм не смотрит на все пиксели сразу. Сначала он ищет простые детали (линии, углы), затем объединяет их в более сложные фигуры (круг, квадрат) и, наконец, распознает целые объекты (лицо, машина).
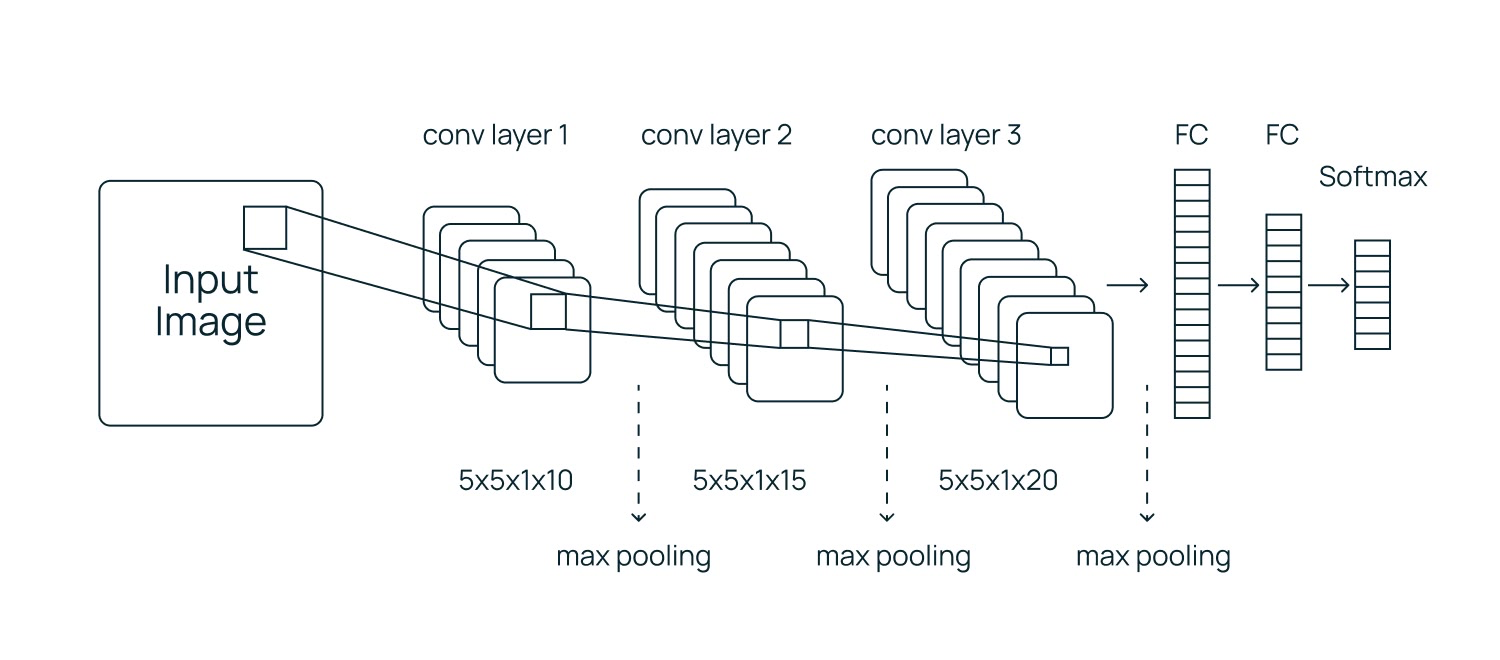
Эта архитектура позволяет нейросети «понимать», что глаз остается глазом, в какой бы части картинки он ни находился.
Что такое библиотеки машинного обучения
Библиотеки — это наборы готового кода, которые берут на себя всю сложную математику от перемножения огромных матриц до вычисления производных.
Для подготовки данных обычно используют:
- NumPy — позволяет работать с многомерными массивами (тензорами) и выполнять сложные математические операции. Вместо циклов Python, NumPy использует векторизацию;
- Pandas — главный инструмент для работы с таблицами. Он позволяет очищать данные, заполнять пропуски и быстро объединять таблицы;
- Matplotlib/Seaborn — библиотеки для визуализации. Помогают увидеть зависимости в данных через графики и тепловые карты.
Для классических моделей машинного обучения используют: Scikit-learn (sklearn). Это самая популярная библиотека для классических алгоритмов (все те, что мы обсуждали выше: регрессии, деревья, кластеризация).
Чтобы обучить любую модель, достаточно вызвать команду fit(), а чтобы получить предсказание — predict(). Она также содержит инструменты для оценки точности моделей (метрики).
А для задач глубокого обучения применяют:
PyTorch или TensorFlow. Это фреймворки для создания нейросетей любой сложности. Они автоматизируют большую часть вычислений, например, градиенты (те самые «поправки» для весов), используя алгоритм обратного распространения ошибки.
И Transformers (Hugging Face). Библиотека, которая предоставляет доступ к уже обученным моделям-трансформерам, которых можно доучить под свои нужды
Чем может помочь Selectel
Для ML-задач нужна подходящая инфраструктура, способная выдерживать высокие вычислительные нагрузки — и Selectel может ее предоставить.
Серверы с GPU (облачные или bare metal) ускорят работу алгоритмов и помогут быстрее выполнять сложные вычисления. Они легко справятся с классификацией изображений и распознаванием речи. С GPU вы сможете обучать нейронные сети и работать с deep learning.
Преднастроенная ML-платформа упростит тестирование, обучение и развертывание моделей в продакшен. Перед стартом мы покажем, как с ней работать, и будем сопровождать вас в процессе ее использования. С помощью платформы можно автоматически генерировать API для ML-моделей, отслеживать обращения к ним и настраивать пайплайн обработки запросов — практически без написания кода вручную. Она также позволит автоматизировать запуск и управление ML-pipelines, кэшировать датасеты и окружения для экспериментов.
Data Science Virtual Machine — это облачный сервер с готовым образом для машинного обучения (ML) и анализа данных. Он поможет упростить подготовку окружения для обучения ML-моделей, ускорить обработку и анализ данных. А еще — сократить расходы на GPU за счет разделения одной карты между разными задачами и гибкого использования ресурсов в зависимости от потребности.





