

Всегда хочется увидеть результаты работы на практике, когда речь заходит об ML. Если с IT-гигантами все понятно, то зачем машинное обучение, скажем, компаниям из индустрии развлечений? В статье попробуем разобраться с этим на примере Netflix.
Где еще узнать про ML в Netflix?
Netflix накопил большой опыт в использовании машинного обучения и анализа данных. Компания охотно делится полученными знаниями, так что я решил сделать подборку источников, из которых можно узнать об интересных сценариях применения ML и улучшить понимание темы в целом.
Например, в статье «Causal Machine Learning for Creative Insights» описывается то, как через A/B-тестирование осуществляется проверка количества людей на постере фильма, цвета фона, выражений лиц и т. д.
Ниже я рекомендую источники, с помощью которых каждый сможет найти для себя интересные сценарии с применением ML от Netflix.
Блог Netflix на Medium
Компания ведет живой и местами внушающий трепет технический блог о том, как различные нововведения позволяют им улучшать пользовательский опыт.
Разнообразие тем статей выходит далеко за пределы рассматриваемого вопроса. Ограничусь наиболее интересными публикациями о ML на мой взгляд:
- «New Series: Creating Media with Machine Learning»,
- «What is an A/B Test?»,
- «Interpreting A/B test results: false positives and statistical significance»,
- «Interpreting A/B test results: false negatives and power»,
- «Selecting the best artwork for videos through A/B testing».
YouTube
Небольшие демонстрации работы ML можно найти на YouTube-канале компании, но я советую ознакомиться с более детальными разборами. Например, доклады «Trends in Recommendation & Personalization at Netflix» и «Why your ML Infrastructure team need ML practitioners».
Зачем в Netflix применяется ML?
Здесь буду краток. Netflix существует для того, чтобы приносить прибыль, так что ключевая цель использования ML — ее максимизация.

Ким Фальк в книге «Рекомендательные системы на практике» утверждает следующее:
«Как вы, вероятно, знаете, Netflix — это стриминговый сервис. Его основной контент — это фильмы и сериалы, подборка которых постоянно обновляется. Задача, которую выполняют рекомендации Netflix, состоит в том, чтобы поддерживать ваш интерес к представленному контенту как можно дольше, стимулируя вас оплачивать подписку из месяца в месяц».
Пожалуй, здесь нечего добавить. Можем двигаться дальше.
Как в Netflix применяется ML?
Это тот случай, когда простота вопроса с лихвой компенсируется сложностью и объемом ответа. Я не осмелюсь давать исчерпывающее описание, учитывающее все возможные нюансы, но постараюсь рассказать о принципе работы в общих чертах.
Если же вы хотите погрузиться в устройство ML в Netflix с головой, то рекомендую ознакомиться с докладами «Artwork Personalization at Netflix» и «Learning a Personalized Homepage».
Большинство аспектов пользовательского опыта формируется с помощью алгоритмов машинного обучения. Примером тому могут послужить статьи о формировании персонализированной домашней страницы и выборе персонализированного постера для контента.
Любые изменения и нововведения в платформе пропускаются через процедуру A/B-тестирования. Давайте рассмотрим этот аспект чуть более детально.
Как уже было сказано, одна из основных задач сервиса — удерживать ваш интерес и побуждать продлевать подписку. Для этого необходимо иметь возможность гибкой и детализированной настройки сервиса, например:
- На главном экране лучше показывать отрывок фильма или постер?
- Где должно быть меню?
- Сколько уровней вложенностей должно быть в меню?
- Где расположить заголовок фильма, а где — его описание?
- Какой фильм показывать при входе?
- Звук по умолчанию должен быть включен или выключен?
Как говорится в первой статье цикла по A/B-тестам в Netflix: «The list goes on».
В этой же статье есть меткое замечание: «Принимать решения легко — сложно принимать правильные решения». Следом приводится список возможных подходов к принятию решений, который можно свести к четырем пунктам:
- решение идет сверху вниз от менеджмента, бизнес-аналитиков и т. д. ;
- решение вырабатывается на основе внутренних дискуссий, участие в которых будут принимать специалисты с разной степенью понимания проблематики. В идеале — эксперты соответствующей области;
- решение вырабатывается на основе наблюдений за конкурентами;
- решение вырабатывается в результате комбинации подходов, перечисленных выше.
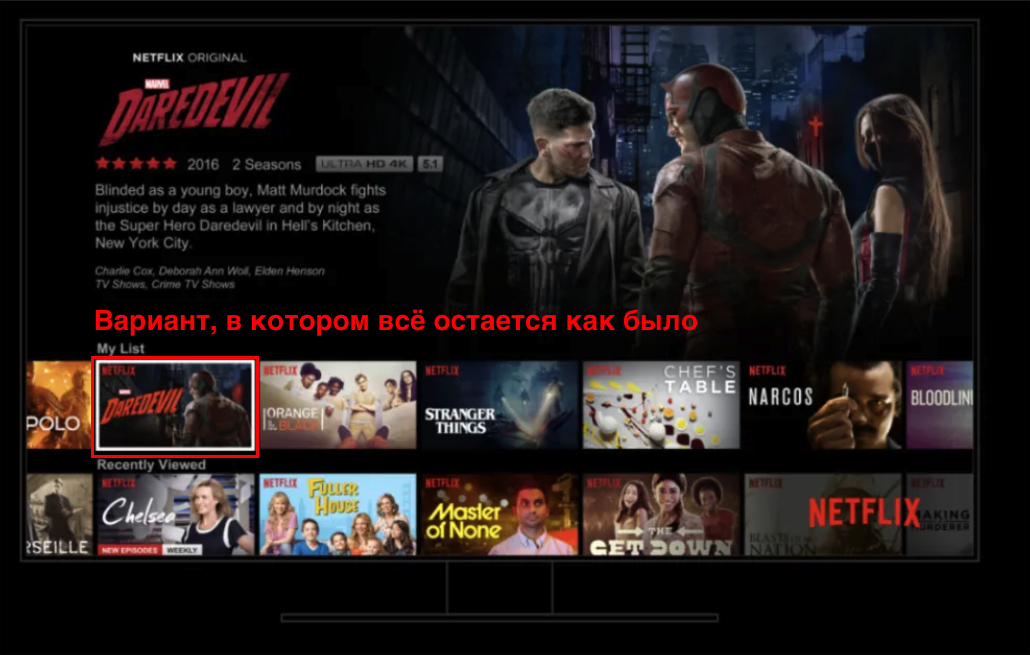
Как было справедливо подмечено в материале, во всех вариантах количество мнений и их разнообразие радикально ограничено. Собственно, тут в игру и вступает A/B-тест. Как это выглядит на практике? Здесь к нам на помощь приходит вторая статья из цикла. В ней описывается гипотеза: полезна ли версия продукта, в которой всю обложку переворачивают вверх дном?
И вот у вас есть вариант A:
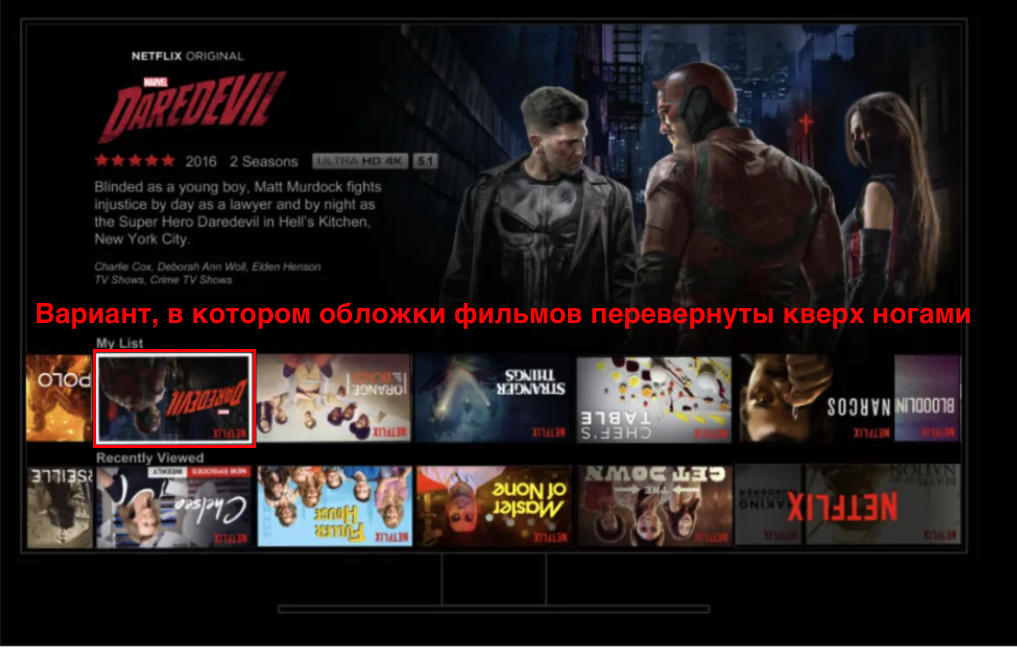
И вариант B:
Далее мы раскидаем варианты A и B на две группы пользователей и смотрим на то, как они отреагируют:
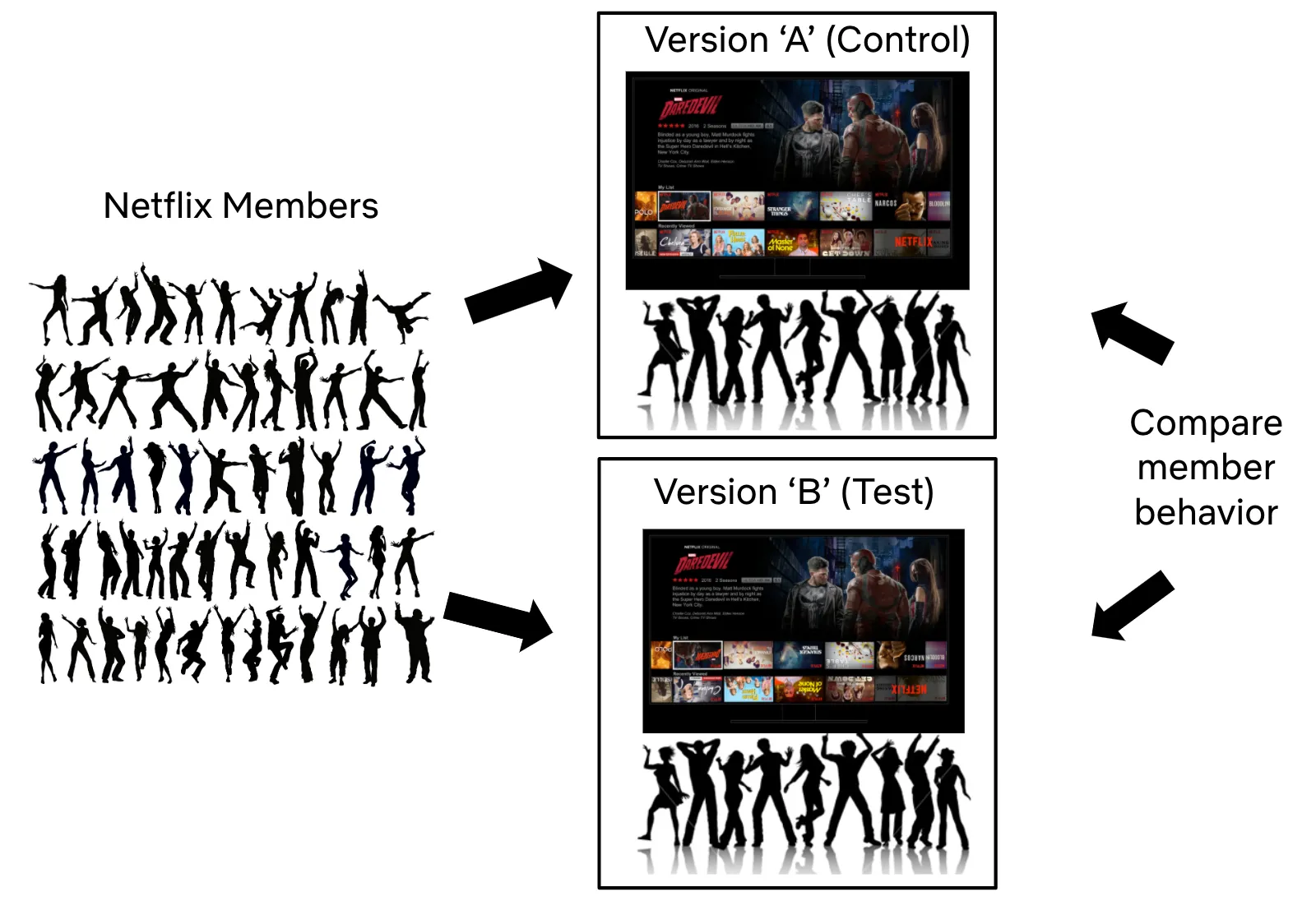
Масса вопросов возникает, когда начинаешь задумываться о проведении эксперимента.
- Сколько нужно участников тестирования, чтобы считать результаты достоверными?
- Как убедиться, что в двух выборках отличается только тестируемое изменение?
- Какие метрики имеет смысл рассматривать при проведении конкретного A/B-теста?
- Если наблюдается статистически значимое изменение интересующей нас метрики, то как быть уверенным в том, что оно произошло именно по причине нового интерфейса?
- Что считать статистически значимым изменением?
Далее в главе «Holding everything else constant» приводится отличный пример того, как неверная постановка эксперимента может привести к неверным выводам.
Список статей на тему A/B-тестирования в Netflix:
- «Decision Making at Netflix»,
- «What is an A/B Test?»,
- «Interpreting A/B test results: false positives and statistical significance»,
- «Interpreting A/B test results: false negatives and power»,
- «Building confidence in a decision»,
- «Experimentation is a major focus of Data Science across Netflix»,
- «Netflix: A Culture of Learning»,
- «It’s All A/Bout Testing: The Netflix Experimentation Platform»,
- «Selecting the best artwork for videos through A/B testing»,
- «A/B Testing and Beyond: Improving the Netflix Streaming Experience with»,
- «Experimentation and Data Science»,
- «Decision Making at Netflix».
В упомянутых сценариях для обучения используются массивные выборки данных. Как вы понимаете, это накладывает ограничения на выбор инструментов и способ их использования.
Какие данные могут использоваться?
Здесь я снова сошлюсь на книгу Кима, поскольку в ней присутствует целая глава, посвященная заданному вопросу. В ее начале есть интересный фрагмент:
«Книга Рона Закарски “Руководство по поиску и анализу данных для программистов” (A Programmers Guide to Data Mining) — это отличное пособие, в котором объясняется различие между явными и неявными фактами. Он приводит пример явной обратной связи со стороны человека по имени Джим.
Джим указал, что является вегетарианцем и любит французские фильмы, но в его кармане лежит чек за прокат фильма «Мстители» от Marvel и чек за покупку упаковки из 12 банок пива. Ha основе какой информации вы будете формировать рекомендации?
С моей точки зрения, выбор очевиден. Как по-вашему, что Джим ожидает увидеть в рекомендациях, открывая сайт со списком местных ресторанов, предлагающих еду на вынос: вегетарианскую еду или фаст-фуд? Собирая данные о поведении пользователей, можно понять, что нужно пользователям вроде Джима.
Вы поймете, что надежные факты ничем заменить нельзя. Давайте посмотрим, какие данные мог бы извлечь Netflix, и как он мог их истолковать».
Постскриптум: вероятно, автор книги имел в виду не вегетарианцев, а людей, придерживающихся здорового образа жизни.
С одной стороны, неявные факты о поведении пользователя дают рекомендательной системе гораздо больше полезной информации. Однако, такая информация подчас вскрывает, как сильно могут отличаться реальные интересы пользователя от тех, которые ему хотелось бы иметь.
Netflix в данном случае не является плохой или хорошей. Она кормит нас тем, о желании чего свидетельствует наша неявная обратная связь. На ум приходит кадр:

Как уже упоминалось, все элементы пользовательского интерфейса в платформе Netflix персонализируются под пользователя. Об этом же говорит и Ким Фальк:
«Говоря о фактах, снова вернемся к сервису Netflix. Все, что находится на главной странице Netflix, персонализировано (заголовки категорий и их содержимое), за исключением верхней категории, где размещается реклама, которую, вероятно, видят все пользователи или пользователи, похожие на меня. На рисунке ниже показана моя персонализированная страница Netflix.
Каждый пользователь видит свои категории. Заголовки варьируются от стандартных описаний жанров, например, “Комедии” и “Драмы”, до максимально подогнанных под интересы человека названий — например, “Фантастические фильмы про путешествия во времени 1980-х годов”.
Первые несколько категорий на моей странице содержат новый и популярный контент. На момент, когда был сделан снимок экрана, первая персонализированная категория — “Dramas” (Драмы), из чего можно сделать вывод, что, по мнению Netflix, из всех жанров именно драмы заинтересуют меня в первую очередь. В категории Dramas отображается тот материал, который Netflix считает наиболее интересным для меня в этой категории».
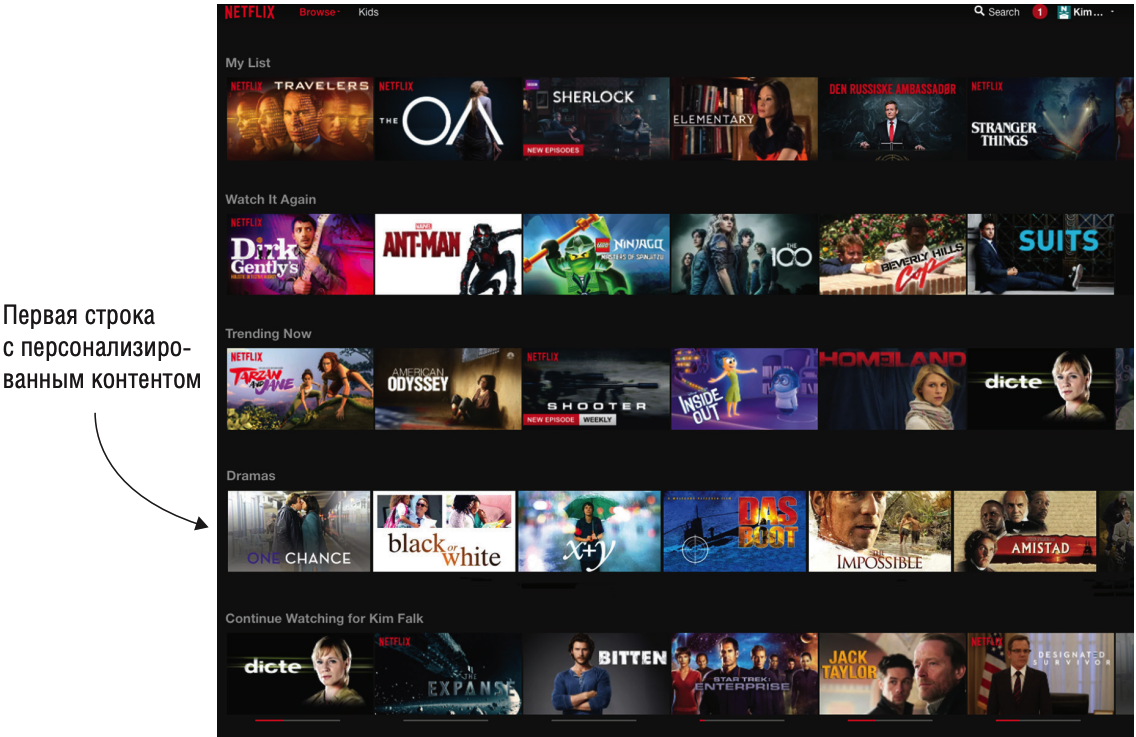
«Что можно понять обо мне, когда я прокручиваю контент в категории Dramas? Это может означать, что я пишу книгу и пытаюсь сделать снимки экрана, но с большей степенью вероятности из этого следует, что я люблю драмы и хочу посмотреть, что еще есть в этой категории.
Если я вижу фильм, который кажется мне интересным, я могу навести на него курсор и прочитать описание. Более того, если оно меня заинтриговало, я могу перейти на страницу фильма. Если мне по-прежнему все нравится, я либо добавляю его в свой список, чтобы посмотреть позже, либо начинаю смотреть сразу.
Можно возразить, что на любом коммерческом сайте подробное изучение информации означает, что человек заинтересовался, сам факт просмотра фильма (до конца) — это эквивалент покупки товара. Но когда речь идет о стриминговом сервисе, на этом этапе рано ставить точку.
Если посетитель начинает смотреть фильм, это хорошо, но, если он останавливает просмотр на четвертой минуте и больше не возвращается к фильму, это говорит о том, что ему не понравилось увиденное. Если пользователь пересматривает фильм через какое-то время, значит, ему понравился этот фильм — возможно, даже больше, чем при первом просмотре».
Получается, что речь идет о сборе разнообразных событий взаимодействия пользователя с элементами платформы. Далее у Кима идет более конкретный раздел «Какие факты собирает Netflix?»:
«Давайте попробуем представить, что происходит в кулуарах Netflix и какие данные собирает этот сервис. Допустим, сейчас вечер субботы и Джимми сидит дома. Пользовательский идентификатор Джимми в сервисе — 1234. Он приготовил себе попкорн в микроволновке, загрузил Netflix и сделал следующее:
- прокрутил контент в категории с драмами (идентификатор 2);
- навел курсор на один из фильмов (идентификатор 41335), чтобы прочитать описание;
- щелкнул курсором, чтобы получить более подробное описание фильма (идентификатор 41335);
- начал смотреть этот фильм (идентификатор 41335).
Пока он смотрит фильм, попробуем представить, что происходит на сервере Netflix. В таблице 1 указано несколько событий, которые могли заинтересовать систему при анализе поведения данного пользователя, а также вероятные трактовки этих событий. Кроме того, я добавил столбец с названиями событий, чтобы было видно, как данные в таблице связаны с журналом, о котором говорится позже».
| Событие | Значение | Название события |
| Прокручивание тематической категории | Пользователю интересна эта тема, в данном случае – драмы | genreView |
| Наведение курсора на фильм для просмотра краткого описания | Пользователя заинтересовал фильм (драма), что подтверждает его интерес к категории в целом | details |
| Щелчок по фильму для просмотра подробного описания | Пользователя еще сильнее заинтересовал фильм | moreDetails |
| Добавление фильма в список My List (Мой список) | Пользователь хочет посмотреть фильм позже | addToList |
| Начало просмотра фильма | Пользователь «покупает» фильм | playStart |
Таблица 1. Примеры событий на сервисе Netflix.
Как видно из таблицы 1, события воспринимаются системой как опорные факты, поскольку они помогают выявить интересы пользователя. Таблица 2 показывает, в каком виде эти факты мог зафиксировать сервис Netflix.
| Идентификатор пользователя | Идентификатор контента | Событие | Дата |
| 1234 | 2 | genreView | 2017-06-07 20:01:00 |
| 1234 | 1234 41335 | details | 2017-06-07 20:02:21 |
| 1234 | 1234 41335 | moreDetails | 2017-06-07 20:02:30 |
| 1234 | 1234 41335 | addToList | 2017-06-07 20:02:55 |
| 1234 | 1234 41335 | playStart | 2017-06-07 20:03:01 |
Таблица 2. Как Netflix записывает факты (вероятный вариант).
Думаю, что тут имеет смысл закончить с обозначенным вопросом, поскольку маловероятно, что мы сможем привести более подробное описание. Разумеется, информация выше — это гипотетическое предположение автора книги. Однако у нас пока нет возможности устроить аудит баз данных Netflix, так что будем довольствоваться тем, что есть.
О нюансах
Согласно порталу Netflix для инвесторов, на 21.07.2023 количество пользователей Netflix достигло 238 миллионов. Что если посчитать, сколько событий будет сгенерировано ими за один вечер? Допустим, в среднем каждый пользователь за вечер посмотрит парочку фильмов:
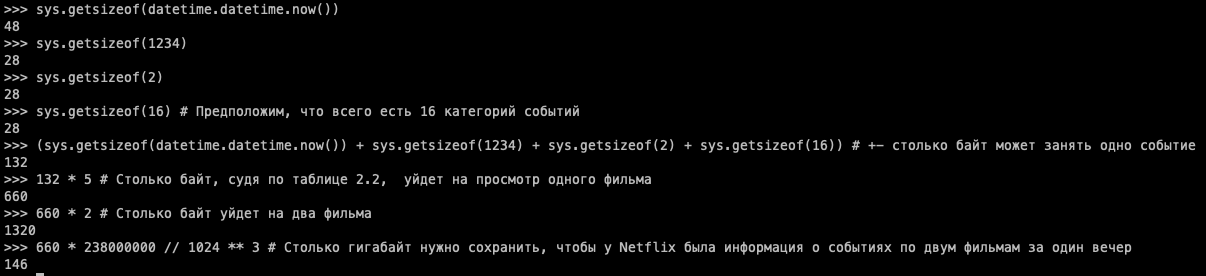
146 ГБ! И это в ситуации, когда пользователи зашли, сразу же выбрали и посмотрели два фильма подряд. А если они перед этим немного полистают каталог?
Например, каждый пользователь перед просмотром пролистал 15 фильмов. Получится 146/2*15=1095 ГБ, т. е. свыше терабайта за один вечер. Это при условии, что событий в пересчете на один фильм будет всего пять. Вдобавок, мы не говорим о том, сколько весят сами фильмы, логи, которые генерируются компонентами сервиса, пользовательские базы и т. д.
Конечно, в этих подсчетах не учитывается масса вещей, но основная их цель в другом. Мы проиллюстрировали, что у Netflix есть реальная потребность в умении работать с самой что ни на есть Big Data.
Второй момент. Вернемся к тому, что в платформе персонализируется каждый ее элемент и выбор проходит через фильтр A/B-тестов. Но дело в том, что такой уровень адаптивности платформы может быть достигнут только если команды UI-, UX-, Backend-разработки будут проникнуты этой идеей.
Все процессы разработки должны быть выстроены так, чтобы было легко формировать выборки пользователей, на которых можно будет проводить A/B-тесты. Сама же платформа должна быть построена таким образом, чтобы можно было быстро вносить изменения в целях A/B-теста.
Третий момент: такой объем фильмом и сериалов (большую часть из которых, разумеется, производит не Netflix) предполагает соответствующий набор контрактов на право проката. Каждый из них может отличаться, например, в силу того, что один заключен в Германии, а другой в Китае.
Четвертый момент: какую-то часть контента Netflix производит сам. Сколько средств на это можно и нужно направить? Как это организовать? Каких специалистов нанять и какие условия работы им необходимы?
Пятый момент: устройство пользователя. Ведь он может смотреть фильм на телефоне, ноутбуке, телевизоре и т. д. Насколько у него хорошее интернет-соединение?
Это лишь часть той головной боли, которая в подобных компаниях (по моему видению) может возникнуть. Также понятно, что в каждом случае можно в той или оной манере попытаться извлечь пользу из методов ML. Например, в статье «Using Machine Learning to Improve Streaming Quality at Netflix» авторы описывают использование машинного обучения для улучшения качества стриминга.
Заключение
Итак, мы мельком посмотрели на применение методов машинного обучения в Netflix. Само собой, у нас не было цели покрыть весь объем ML-деятельности, которая осуществляется в компании. Беглого взгляда на их блог будет достаточно для того, чтобы понять, что это займет очень много времени.
Тем не менее, можно сделать вывод на основе рассмотренных примеров: ML — это чертовски важная составляющая процессов в Netflix, которая со временем, вероятно, станет еще более важной.





