

Несмотря на то, что статья об AI, начать я хочу с тренеров. Принято считать, что лучший тренер — это тот, кто сам прошел путь игрока. Например, сэр Алекс Фергюсон не был звездой на поле, но именно понимание «кухни» изнутри позволило ему стать величайшим тренером в истории британского футбола. Конечно, бывают исключения вроде Карла-Хайнца Хеддерготта, который успешно тренировал без спортивного прошлого. Но на мой взгляд такие исключения лишь подчеркивают общее правило.
О каком правиле идет речь и какое отношение оно имеет к корпоративному AI — рассказал ниже.
Зачем бизнесу AI и почему начинать сейчас еще не поздно
Нужно ли тренеру, который воспитывает чемпионов, самому быть чемпионом? Необязательно. Но без практического опыта занятий профильным спортом он неизбежно будет принимать решения на уровне теории. В инфраструктурных продуктах это особенно заметно: пока ты сам не эксплуатируешь систему под нагрузкой, не упираешься в особенности запуска, лимиты GPU и стоимость владения, сложно делать осмысленные рекомендации клиентам.
Именно поэтому Selectel как инфраструктурный провайдер идет по пути «играющего тренера». Мы запустили собственные AI-сервисы. Они включают внешнюю LLM-платформу и внутренний сервис векторного поиска Kaken. Это был не маркетинговый эксперимент, а попытка пройти весь путь корпоративного внедрения AI на своей инфраструктуре — от архитектуры до эксплуатации. Спойлер: попытка оказалась успешной.
Дело здесь не только в опыте. У любого бизнеса цель одна — увеличить эффективность и снизить издержки. Еще проще — заработать больше, чем потратить.
В корпоративном IT искусственный интеллект в 2026 году — это уже не «инновация ради инновации», а утилитарный инструмент. Увеличение производительности работы сотрудников, автоматизация рутинных операций, ускорение разработки, снижение времени реакции в поддержке — это все, с чем он призван помочь.

Почему компании не спешили с AI раньше — понятно. До недавнего времени рынок выглядел так: закрытые модели с непрозрачной экономикой, отсутствие стабильных open-source альтернатив и сложность инфраструктуры для инференса. А также высокий операционный риск и непредсказуемая стоимость, особенно на фоне необходимости обучения моделей с нуля.
Но за последние один–два года ситуация принципиально изменилась. Появились зрелые open-source LLM, пригодные для использования в проде. Устоялись архитектурные паттерны: RAG, inference-only, без обязательного файнтюнинга. GPU стали доступнее как по аренде, так и по масштабированию. И стало проще считать TCO (total cost of ownership), то есть совокупную стоимость владения и управлять рисками.
Фактически входной порог снизился: компании больше не обязаны обучать модели с нуля или отдавать данные внешним SaaS-вендорам. AI стал обычным сервисом в инфраструктуре — с понятной архитектурой, SLA и моделью владения. Буквально возможно зайти на huggingface, скачать понравившуюся модель и развернуть ее on-premise для собственного использования.
Токенизированные сервисы vs on-premise AI
Самый простой способ начать работу с ИИ — токенизированные AI-сервисы. Подписка, API, быстрый старт. Это удобно, но в корпоративном контуре такой подход почти сразу упирается в ограничения.
Основные риски облачных AI-сервисов начинаются с безопасности, то есть передачи корпоративных данных стороннему вендору без полного контроля над логами, обучением и хранением данных. И заканчиваются операционными угрозами — вендоролоком и непредсказуемыми затратами при отсутствии жесткого FinOps-контроля.
Альтернатива — собственный инференс на арендованных или купленных серверах с GPU и использованием open-source моделей.
Преимущества on-premise (или private cloud) подхода с самостоятельно развернутой моделью:
- данные остаются внутри корпоративного контура;
- полный контроль модели и ее жизненного цикла;
- соответствие требованиям ИБ и регуляторов;
- предсказуемая экономика (фиксированная стоимость инфраструктуры);
- линейное масштабирование ресурсов при росте нагрузки.
С точки зрения эксплуатации для информационной безопасности и IT-служб — это не «что-то особенное», а еще один сервис в инфраструктуре: с доступами, логированием, мониторингом и контролем изменений.
Дополнительно компания получает полный контроль над моделью и дополнительные возможности. Например, дообучение под свои данные, разграничение доступа между пользователями и командами и построение мультиагентных и композиционных сервисов поверх LLM.
Именно такой подход сегодня выглядит наиболее рациональным для корпоративного AI: минимальные риски, управляемая стоимость и понятная интеграция в существующий IT-ландшафт.
Kaken и четыре AI-сервиса
После теоретической части логично перейти к практике — что именно запустили и зачем. В Selectel мы развернули четыре внутренних AI-сервиса, которые сегодня используются сотрудниками на ежедневной основе:
- Kaken — сервис векторного поиска по внутренней базе знаний;
- Selectel AI — on-premise LLM общего назначения;
- сервис транскрибации и аналитики встреч;
- Copilot для разработчиков.
Для двух последних сервисов мы сознательно не фокусируемся на брендинге — это инфраструктурные инструменты, встроенные в рабочие процессы. Ниже — кратко о каждом.
Дисклеймер: я менеджер продукта, поэтому в качестве примеров приведу свои реальные задачи.
Kaken — векторный поиск по корпоративным знаниям
Kaken — это сервис семантического поиска по внутренним источникам знаний Selectel. На текущий момент он индексирует Confluence и публичную документацию, в ближайших планах — интеграция с Jira для поиска по задачам.
Важное уточнение для тех, кто уже начал улыбаться: название читается как «кейкен». Название англоязычное, так что все лингвистические совпадения с русским языком мы считаем случайными.
Ключевое отличие от классического поиска — использование эмбеддингов и retrieval-подхода. Запрос формулируется на естественном языке и преобразуется в векторы, после чего производится поиск в векторном хранилище. Результат запроса возвращается в виде сжатого, подходящего по смыслу ответа с указанием источников.
С точки зрения эффективности это решает сразу несколько задач: снижает время поиска информации, уменьшает количество контекстных переключений (когда пользователю нужно открыть десяток ссылок и понять содержание каждой страницы по ним). А еще снижает нагрузку на экспертов и командные чаты, в случае если пользователь не нашел нужную информацию и решил обратиться с запросом к коллегам.
On-premise модель изолирована на нашем выделенном сервере и все ее общение с внешним миром мы полностью контролируем. Это безопасный сценарий использования LLM в корпоративной среде в отличие от случаев, когда в инфраструктуре компании оказывается публичная модель.
В среднем Kaken используют 60 сотрудников в день.
Пример использования
Запрос:
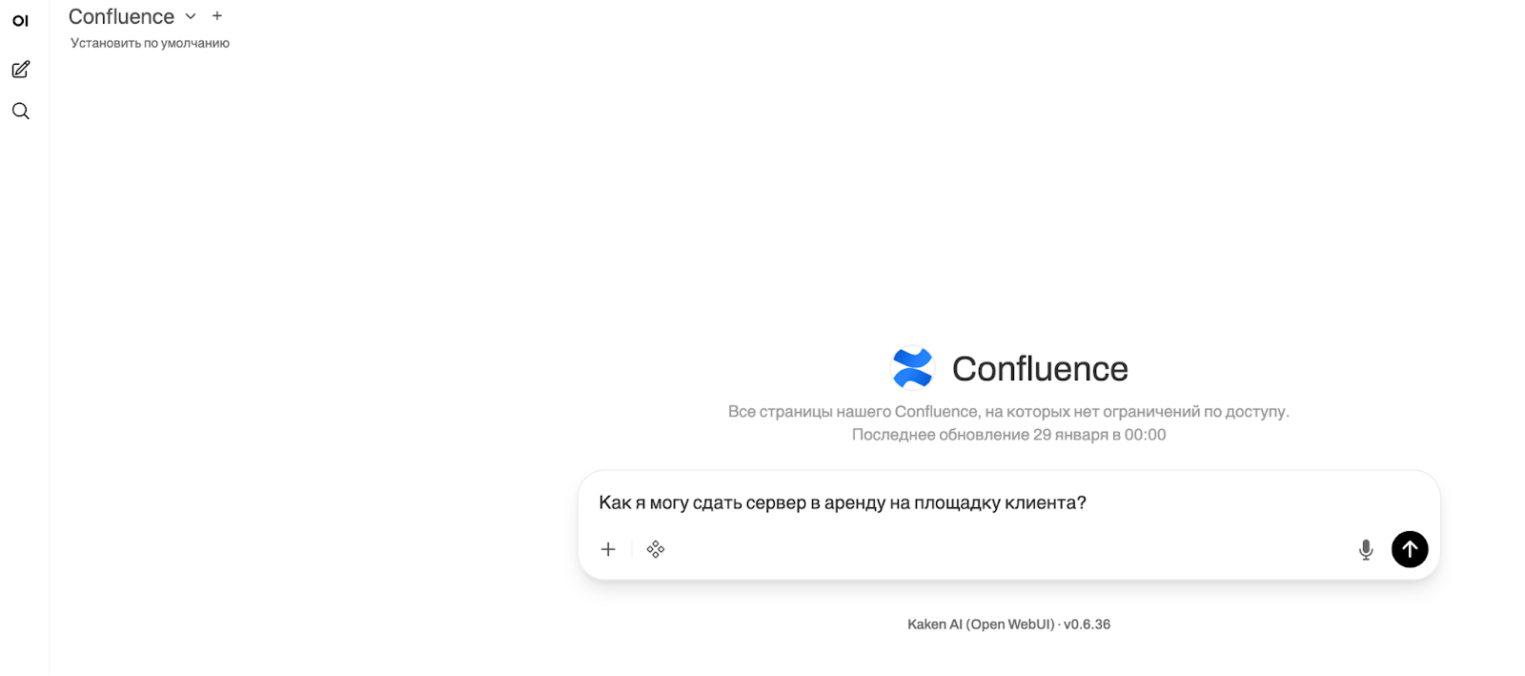
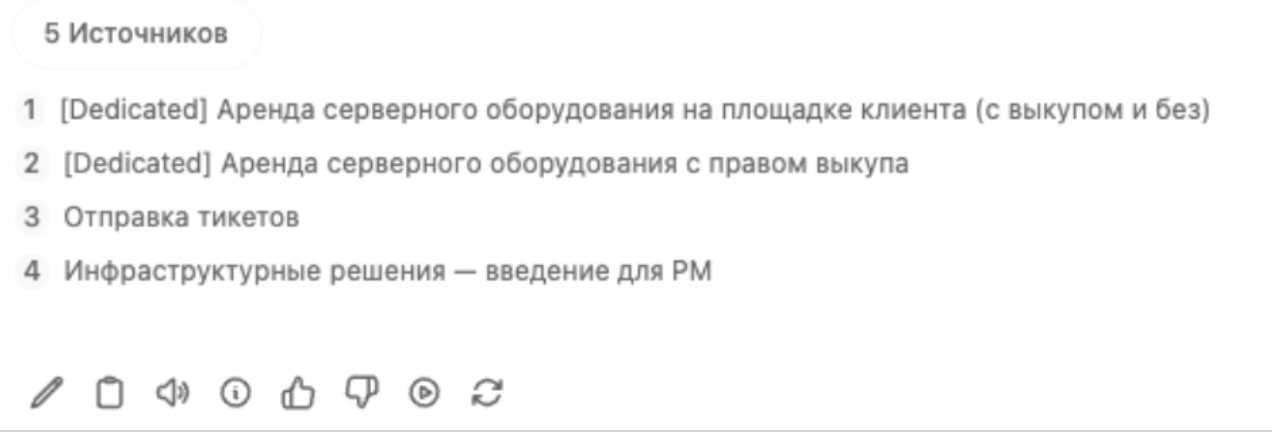
Ответ:

Ссылка на источники:
Selectel AI — LLM общего назначения
Selectel AI — это on-premise сервис на базе open-source LLM, предназначенный для широкого круга задач: работы с текстами, анализа данных, структурирования информации, подготовки черновиков документации.
Сервис построен как универсальный инференс-слой, который может использоваться как напрямую сотрудниками, так и как компонент других внутренних продуктов. За счет контекста и системных инструкций модель адаптируется под типовые корпоративные сценарии и запросы пользователя.
С продуктовой точки зрения его ценность — в снижении когнитивной нагрузки. Рутинные операции делегируются модели, а сотрудник фокусируется на принятии решений, оценке рисков и работе с контекстом, где автоматизация пока неэффективна. Например, в модель все еще сложно загрузить весь контекст сегодняшнего рынка и отдельных клиентов, а также эмоциональные оценки различных событий. Здесь человеческая экспертиза остается ключевой.
Сервис можно использовать для разных прикладных задач: подготовки и актуализации документации по фичам, формализации требований и написания задач в Jira. Также в работе менеджера продукта я использую Selectel AI для составления списков вопросов для интервью, а также анализа и структурирования полученных ответов от респондентов.
В среднем Selectel AI используют 150 сотрудников в день.
Пример использования:

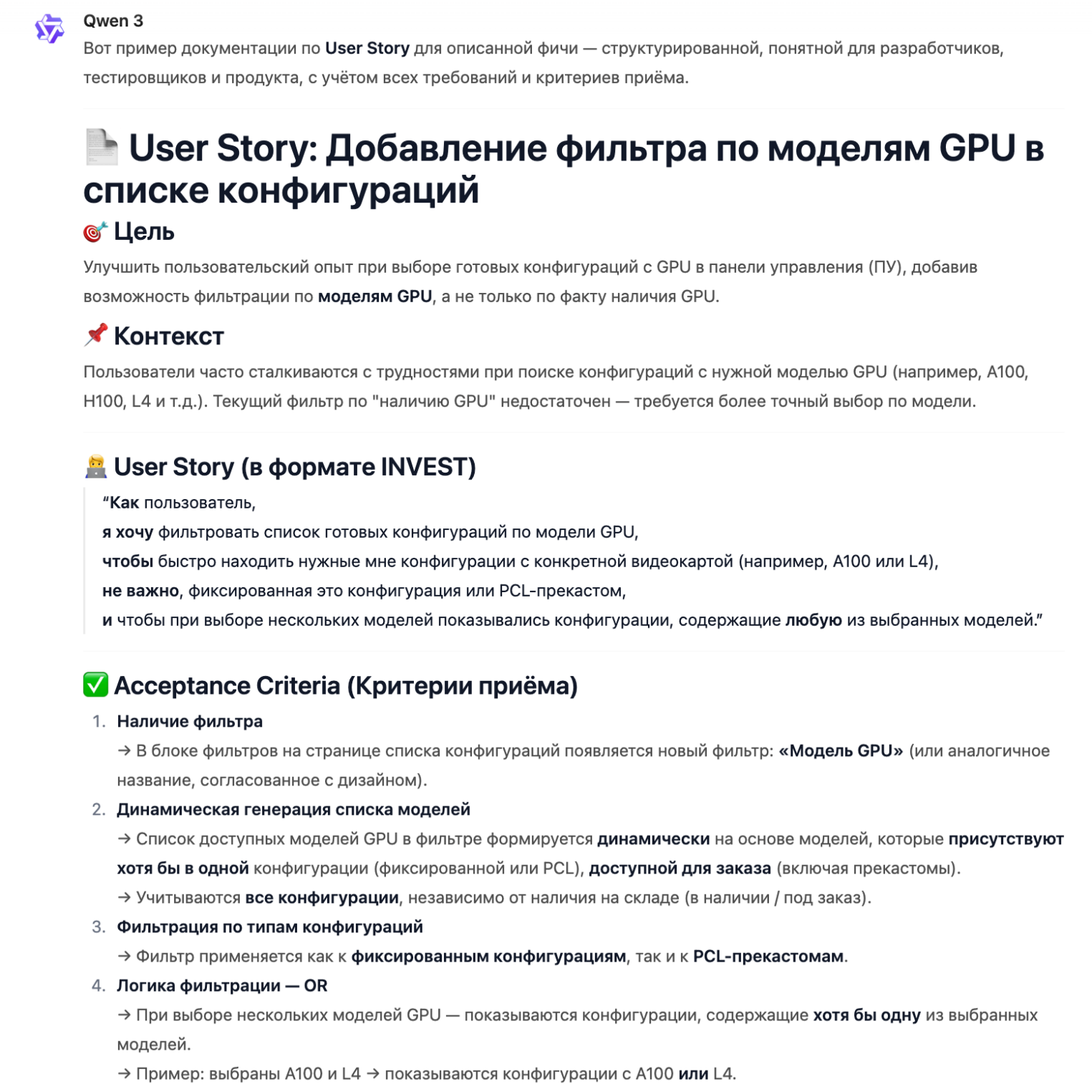

Также периодически мы тестируем в прикладных задачах и сравниваем между собой различные модели:

Транскрибация и аналитика встреч
Этот сервис интегрирован с корпоративной платформой видеозвонков Selectel Meet и решает уже ставшую классической задачу обработки встреч.
На первом этапе происходит распознавание речи и создание текстовой расшифровки. Далее подключается LLM-слой для постобработки: структурирование, выделение ключевых тем, формирование итогов и задачи (action items).
С точки зрения бизнеса это один из самых очевидных AI-кейсов:
- снижается необходимость вести ручные заметки;
- сокращается время на постанализ встреч;
- повышается прозрачность договоренностей.
При этом на ключевых встречах все еще имеет смысл фиксировать договоренности и action items непосредственно в ходе обсуждения. Однако использование сервисов транскрибации и последующей аналитики существенно снижает нагрузку на участников. Это позволяет сместить фокус с технической фиксации разговора на содержание обсуждения и принятие решений.
Пример использования — записана тестовая встреча в свободном формате:

Copilot для разработчиков
Copilot — это ассистент, встроенный в IDE и работающий в режиме реального времени с кодом. Он анализирует текущий файл, комментарии и контекст проекта, предлагая автодополнение и подсказки.
Основная ценность — ускорение работы с типовыми конструкциями и шаблонным кодом. Это не замена разработчика, а инструмент для снижения нагрузки при решении тривиальных задач.
В рамках сервиса используется компактная модель, ключевое преимущество которой — быстрый отклик. Она не рассчитана на большой контекст и глубокое понимание кодовой базы и применяется в вспомогательном «легком» режиме.
Дополнительно используется Selectel AI — универсальная LLM, обладающая более глубоким пониманием кода и типовых конструкций. Она также подключается к IDE и может использоваться с заданными промптами в агентном режиме. В этом сценарии ее возможности существенно превосходят возможности базовой модели.
Модели и инфраструктура
Что «под капотом» у наших сервисов и на каких серверах они развернуты.
| Сервис | Модель и софт | Сервер |
| Kaken | Qwen3 30b + vLLM + Qdrant | Сервер с 2 х GPU NVIDIA A100 40GB и 2 х GPU NVIDIA Tesla T4 16GB |
| Selectel AI | Qwen3 235b-a22b-fp8-instruct (VL)Firecrowl API + SeasrXNG | Сервер с 4 х GPU NVIDIA H100 80GB |
| Kaken + Selectel AI | Qwen3-embedding-8bQwen3-reranker-8b | Cервер с 4 х GPU NVIDIA A5000 24GB |
| Транскрибатор | Faster-whisper-large-v3 | |
| Ассистент кода | Qwen3 coder 30b (контекст 32k) |
Kaken
Для сервиса используется развернутая на отдельном сервере модель Qwen 3-30B для генерации ответов и фреймворк llama.ccp для быстрого инференса. Также используется векторная база данных Qdrant.
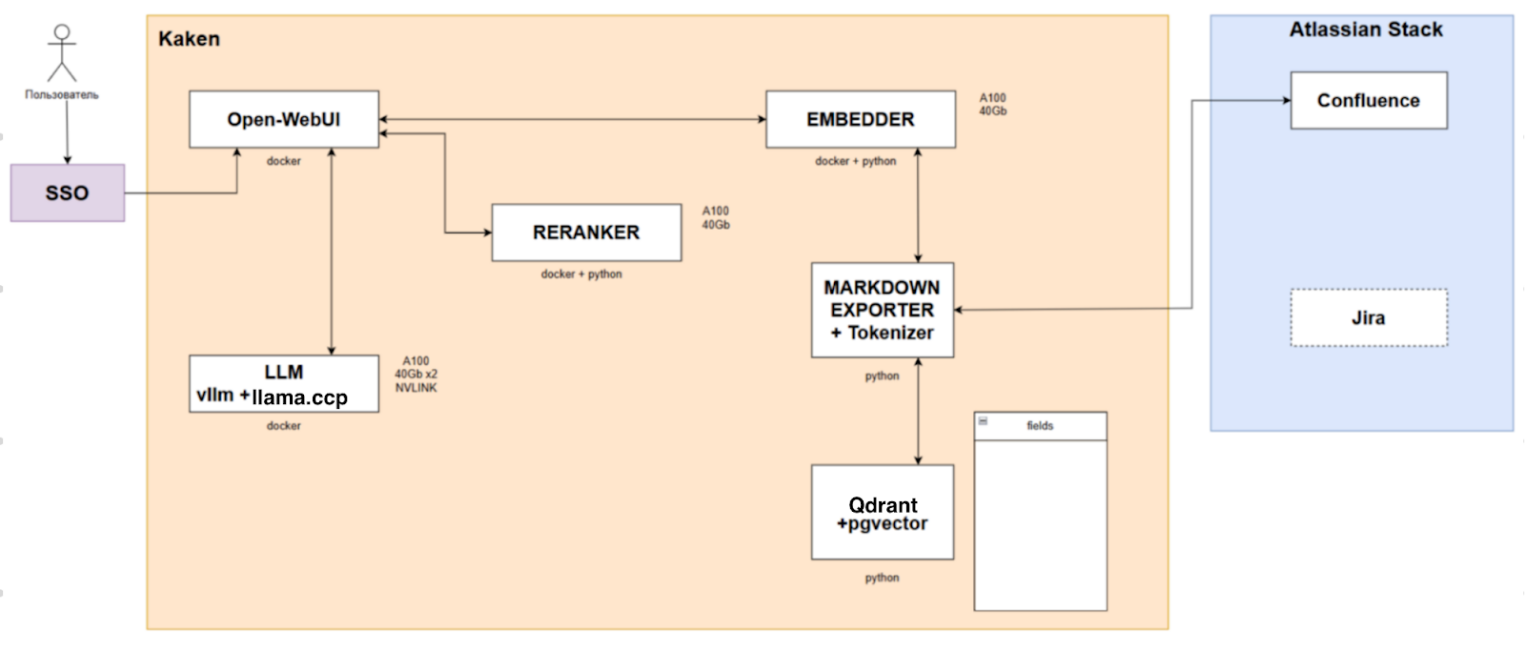
Selectel AI
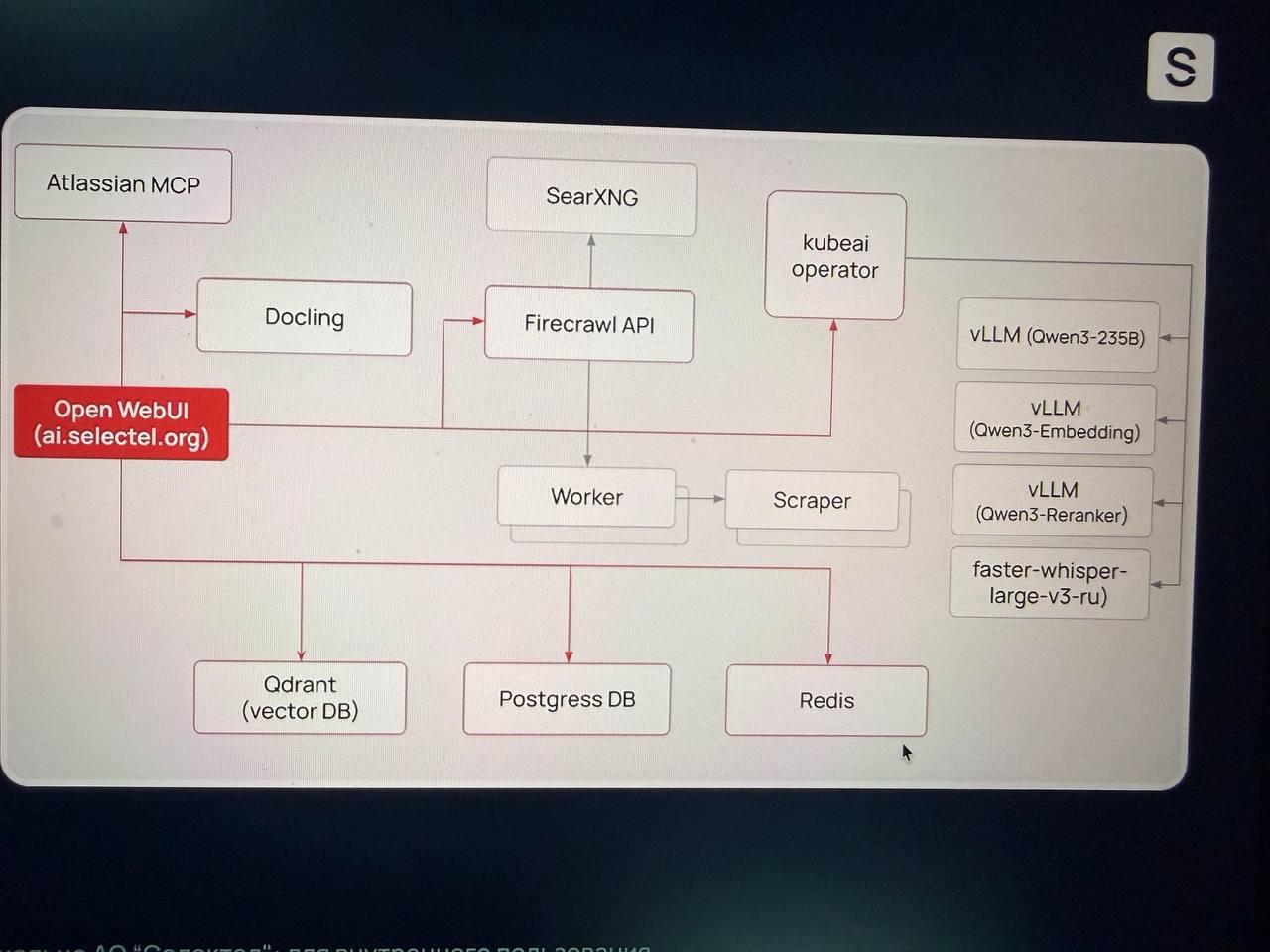
Особенности:
- используется модель Qwen3-235b, в момент обработки активно 22b параметров (архитектура MoE). Модель в формате instruct, работает без режима рассуждения;
- применяется VL (vision language) для распознавания изображений;
- модель многоязычная, лимит контекстного окна 65 000 токенов.
Модель также используется для внутреннего чат-бота Trex.
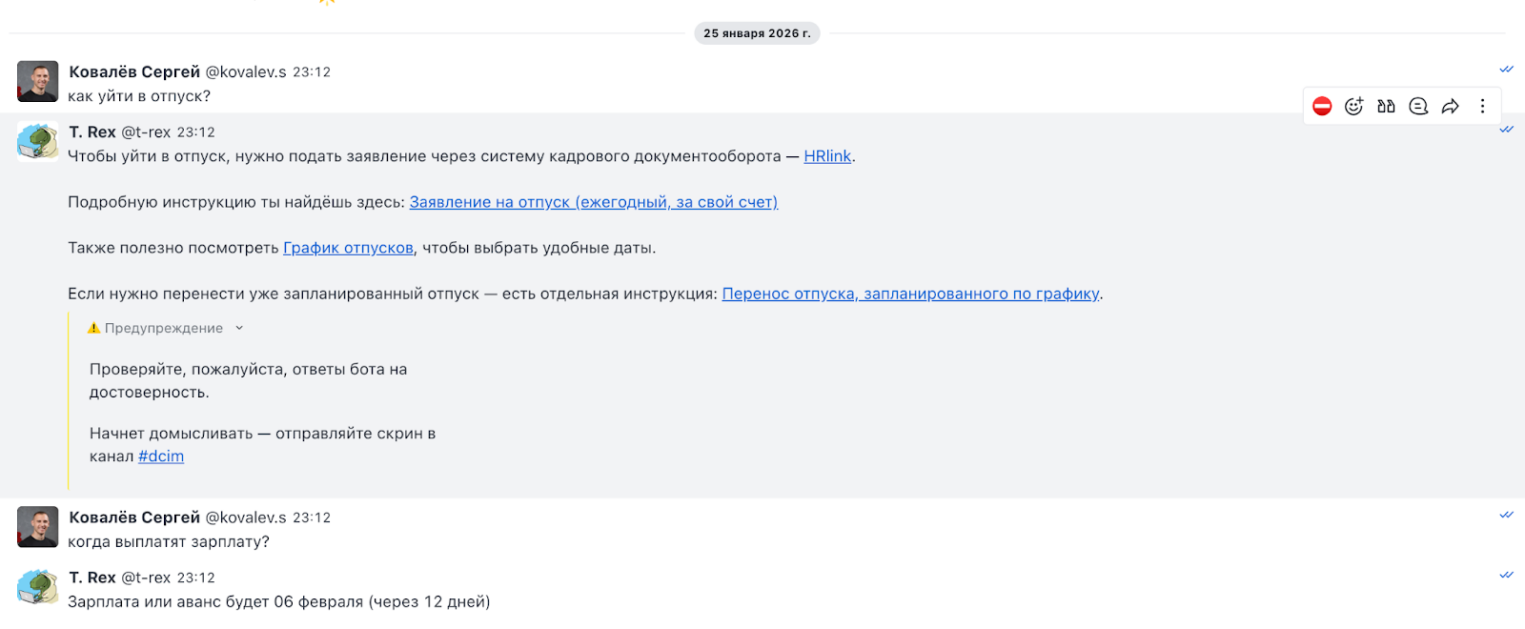
Экономика продукта и окупается ли сервис
Короткий спойлер — да, окупается. При этом остается пространство для оптимизации и роста эффективности. Цель любого бизнеса проста: зарабатывать больше, чем тратить. В этом смысле AI-сервисы не являются исключением — затраты на инфраструктуру и эксплуатацию продукта должны быть ниже той ценности, которую они создают. В корпоративном AI эта ценность, как правило, выражается в экономии времени сотрудников и росте их производительности.
В рамках этой статьи я не стал углубляться в формальные методики оценки ROI и продуктивности до и после внедрения. Вместо этого посмотрим на экономику с более прикладной стороны — через инфраструктурные затраты и верхнеуровневую оценку стоимости одного запроса.
Отдельно замечу, что, говоря об эффективности, сложно не вспомнить известную сатирическую статью про внедрение AI в компании, где главным KPI рекомендовалось рисовать графики «вверх и вправо». В реальности все, конечно, несколько сложнее.
Selectel AI
Наши внутренние AI-сервисы развернуты на трех серверах:
| Сервер | Назначение | Цена аренды в месяц |
| Сервер с 2 х GPU NVIDIA A100 40GBСервер с 2 х GPU NVIDIA Tesla T4 16GB | Kaken | от 150 000 ₽ |
| Сервер с 4 х GPU NVIDIA H100 80GB | Selectel AI | от 1,3 млн ₽ |
| Cервер с 4 х GPU NVIDIA A5000 24GB | Selectel AI +вспомогательные сервисы | от 150 000 ₽ |
Для упрощения расчетов будем считать, что мы арендуем эту инфраструктуру сами у себя и берем публичную цену аренды. Совокупные затраты на инфраструктуру составляют порядка 1,6 млн ₽ в месяц.
Формально Kaken работает на отдельном сервере и его экономику можно считать отдельно — об этом чуть позже. Для контекста: в Selectel работает более 1 200 сотрудников.
В самом упрощенном варианте экономику можно оценить, подсчитав стоимость одного запроса или сопоставив ее с экономией рабочего времени сотрудника.
Предположим, в систему поступает в среднем 20 запросов в час, это 160 запросов в день или около 3 200 запросов в месяц. При месячных инфраструктурных затратах в 1,6 млн ₽ стоимость одного запроса составляет порядка 500 ₽.
Теперь допустим, что один запрос экономит сотруднику 15 минут рабочего времени. В таком случае gross-стоимость часа работы сотрудника для компании должна быть не ниже 2 000 ₽, чтобы система выходила в ноль.
Для разработчиков, ML-инженеров, SRE и senior-менеджмента такой уровень стоимости часа не выглядит завышенным. При этом приведенный выше расчет — далеко не предел эффективности.
В сценарии плотного и равномерного использования стоимость одного запроса снижается кратно и перестает быть критичным параметром. Фактически инфраструктура начинает работать ближе к своему оптимальному режиму загрузки. Здесь появляется эффективность и значительное, ощутимое для бизнеса снижение костов.
Дополнительно потенциал снижения стоимости запроса заложен в оптимизации самой инфраструктуры инференса: выборе более подходящих GPU под конкретные нагрузки, использовании квантизации, более эффективном управлении очередями и ресурсами. Эти меры позволяют повысить утилизацию GPU без ухудшения пользовательского опыта.
Kaken — подробная экономика
Для сервиса Kaken коллеги провели точный расчет экономики, основанный на реальных данных использования.
Стоимость аренды сервера в месяц по рыночной цене, разделенная на число сотрудников, воспользовавшихся сервисом, дает следующие показатели: стоимость на одного активного пользователя в день — 138 ₽, при среднем количестве пользователей в день 60 человек.
Сравним с закупкой аналогичного сервера для собственного дата-центра. Стоимость сервера — около 2,7 млн ₽, в расчете не учтены операционные расходы на размещение и обслуживание сервера, а также стоимость финансирования. При текущем количестве пользователей и стоимости аренды срок окупаемости сервера составит 330 дней (без учета операционных расходов). А с учетом размещения и стоимости привлечения финансирования (ключевая ставка — 16%) срок окупаемости увеличивается до полутора лет.
On-premise инфраструктура, безусловно, имеет право на жизнь, однако стоит учитывать скорость обновления моделей и их требования к серверам и GPU. В случае аренды апгрейд или полная замена сервера выполняются гораздо проще и быстрее. Аналогичные преимущества аренды проявляются и при запуске пилотных проектов, когда заранее неизвестно, насколько сервис будет эффективен.
Токенизированные сервисы от ведущих вендоров, например — ChatGPT, могут показать лучшую экономику на одного пользователя, однако в этом случае потребуется предоставить им полный доступ к базе знаний и полностью зависеть от поставщика услуг.
Особенности расчетов
Основные трудности при корректной оценке экономики AI-сервисов лежат не в инфраструктуре, а в эвристиках: Как точно оценить экономию времени одного сотрудника? Какую стоимость часа считать усредненной по компании? Как интерпретировать высвобожденное время?
Например, пошло ли оно на выполнение более ценных задач или было потрачено на дополнительный кофе. Но даже с учетом этих неопределенностей мы видим, что при использовании сервисов высококвалифицированными специалистами экономическая эффективность может быть существенной.
Отдельно отмечу, что после внедрения AI-сервисов внутри Selectel ведется активный внутренний промоушен и привлечение пользователей. Это осознанная стратегия: без вовлечения сотрудников даже технически сильный продукт не сможет раскрыть свой экономический потенциал.
В итоге, несмотря на сложности точного расчета ROI, на мой взгляд, для корпоративного AI ключевым фактором становится не абсолютная стоимость инфраструктуры, а объем использования сервиса, ценность для пользователей и их уровень, определяющий затраты на оплату труда таких сотрудников.
Мы идем дальше и нашим клиентам имеет смысл идти с нами
Запуск внутренних AI-сервисов не стал для нас финальной точкой — скорее рабочей базой для дальнейших экспериментов. Мы продолжаем тестировать инфраструктуру инференса: пробуем разные модели, конфигурации GPU, проводим собственные бенчмарки, сравниваем latency, пропускную способность, количество одновременных пользователей и объем обрабатываемых токенов.
Одни и те же сервисы разворачиваем на новом железе и смотрим, как они ведут себя в одинаковых сценариях нагрузки. В том числе для того, чтобы накапливать практическую экспертизу и предлагать клиентам подходящую инфраструктуру под задачи AI-инференса, а не универсальные рекомендации.
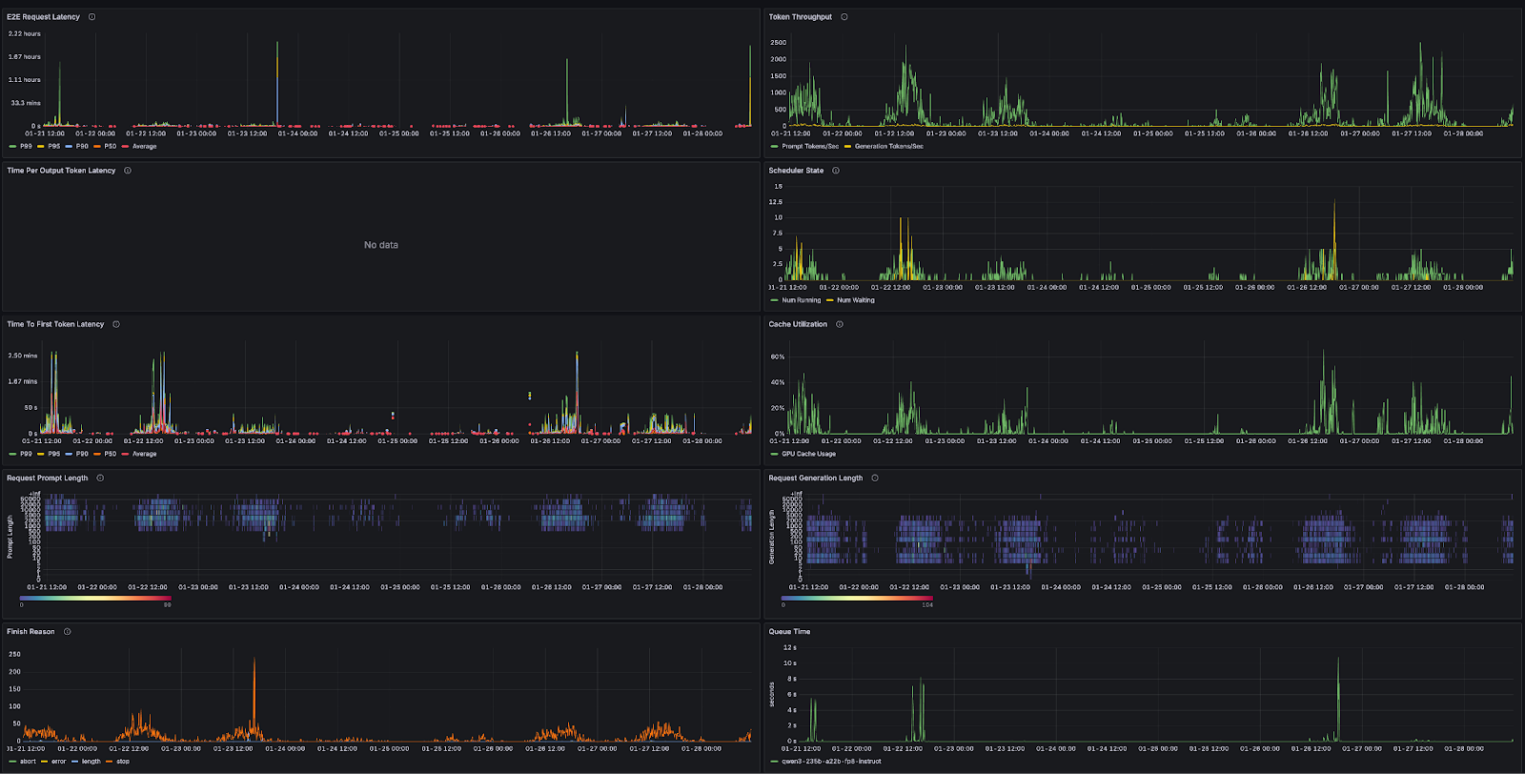
Неформальный пример результатов тестов:

Пример формализованных результатов тестов (2 x GPU NVIDIA RTX Pro 6000 Blackwell):
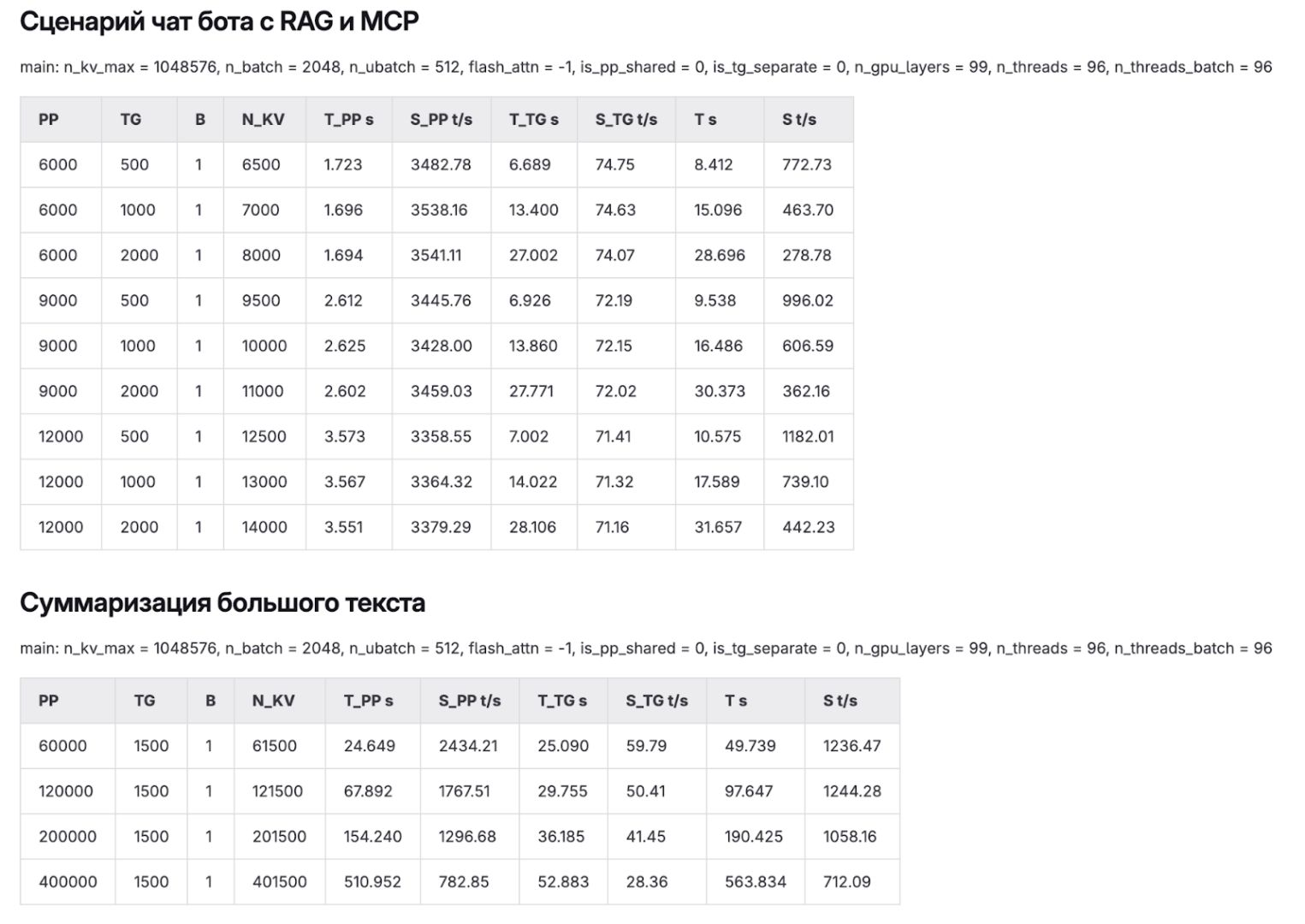
С точки зрения применения, помимо уже запущенных сервисов, мы видим потенциал использования AI:
- расширение Kaken для Jira*;
- использование в тикет-системах для аналитики*;
- использование в CRM и внутренних сервисах поддержки.
*сервисы уже развернуты и находятся в предпродакшн-тестировании.
При этом мы достаточно консервативны в выборе сценариев автоматизации. Надежность инфраструктурных продуктов напрямую влияет на бизнес клиентов, поэтому, внедрение чат-ботов в тикет системах мы сейчас не рассматриваем. В вопросах поддержки, особенно в инфраструктуре, клиенту практически всегда важно получить ответ от инженера, а не от модели.
Аналогичный подход мы применяем и во входящих продажах. Здесь мы опираемся на экспертизу живых специалистов. В Selectel это, как правило, бывшие инженеры, которые понимают архитектуру и могут корректно помочь с выбором инфраструктуры под конкретную задачу.
То же касается разработки. Мы используем AI как вспомогательный инструмент, но не передаем ему полноценную разработку. Для инфраструктурных продуктов критичны качество кода, его читаемость и прозрачность, поэтому на текущем этапе полноценную разработку без участия разработчиков мы считаем преждевременной.
Все описанные сервисы объединяет одно: они работают на нашей собственной инфраструктуре, под реальной нагрузкой и с реальными ограничениями по стоимости, производительности и отказоустойчивости.
Это дает практические преимущества:
- мы видим, как GPU ведут себя в инференс-нагрузке;
- понимаем реальные узкие места — от сети до памяти;
- умеем считать совокупную стоимость владения (TCO) не в теории, а на основе эксплуатации.
Использование собственной LLM дополнительно дает контроль над данными и логами в замкнутом контуре, возможность управлять производительностью и проводить осмысленные эксперименты, а также понимать реальную экономику инференса и профиль загрузки GPU.
Хочу вернуться к повествованию в лиде. Именно этот опыт «играющего тренера» позволяет нам развивать GPU-инфраструктуру не абстрактно, а исходя из реальных сценариев эксплуатации. Мы продвигаем GPU-серверы не как универсальное решение «для всего AI», а как инструмент, лично проверенный в работе и понятный с точки зрения эффективности и экономики.
Разумеется, мы не претендуем на роль первооткрывателей в области внедрения ИИ в рабочие задачи. Попытки скрестить нейросети с корпоративным софтом предпринимались многими, но дьявол, как обычно, кроется в деталях.
В каких типовых задачах компании используют AI
Если смотреть на исследования рынка, то в топе обычно фигурируют;
- автоматизация процессов: ускоряет обработку данных и рутинные задачи;
- чат-боты в клиентском сервисе: сокращают время ответа в поддержке;
- аналитика данных: ускоряет принятие решений;
- обнаружение мошенничества: улучшает точность на 84% в финансах;
- персонализированный маркетинг: повышает конверсию.
Все эти кейсы имеют право на жизнь, но их описание достаточно общее. На мой взгляд, в корпоративной среде быстрее всего «взлетают» более прикладные сценарии с низким риском и понятным ROI:
- Copilot для кода — ускорение разработки, помощь с шаблонным-кодом, ревью и навигация по репозиториям;
- работа с внутренними знаниями (RAG) — поиск по документации, регламентам, Confluence, Git, внутренним Wiki;
- помощь IT-поддержке и инженерам — диагностика инцидентов, подсказки по runbook’ам, сокращение времени реагирования;
- обработка встреч и коммуникаций —транскрибация, резюме, поиск по истории обсуждений;
- чат-боты в продажах и внутреннем сервисе — ответы на типовые вопросы, первичная квалификация, работа с базой знаний.
Именно эти кейсы дают быстрый эффект и хорошо масштабируются внутри компании и за ее пределами.




