

Привет! Меня зовут Антон, я DevOps-инженер в команде Data/ML-продуктов Selectel.
Почему мы действовали без разработчиков? Рынок ML все еще молодой. В его российском сегменте не так много решений, связанных с Inference‑платформами. Перед началом создания полноценного продукта наша команда сначала проверяет технологические гипотезы, не растрачивая существенные ресурсы на разработку. Все делается силами небольшой команды Ops‑инженеров. Мы используем сервисы с открытым исходным кодом на базе инфраструктуры облака Selectel — тем самым достаточно быстро и недорого тестируем предположения, а в случае успеха легко масштабируем до готового продукта. Дальнейшее развитие уже определяется обратной связью от наших клиентов.
Статья дополняет мое выступление на конференции HighLoad 2024 и является частью серии. Сегодня поговорим больше про концептуальные идеи, требования к платформе, почему пришлось отказаться от Seldon и о том, что получилось в итоге. Про техническую составляющую, воплощении главных пяти фичей нашей платформы — в следующей публикации.
Мы не станем заострять внимание на деталях администрирования — например, развертывании своей Inference-платформы. Для этого существуют инструкции и документация. Вместо этого рассмотрим подробнее трудности, которые появляются на пути каждого, кто проектирует и разрабатывает собственные решения или опирается на open-source. Совокупность всех наших исследований за последний год и стала основой для создания платформы.
Для начала обозначим требования к платформе — именно они определили весь путь.
Требования к Inference‑платформе
К будущей Inference‑платформе сформировались определенные запросы. Мы хотели добиться следующего.
Упростить деплой модели для Data Science-инженеров
Наша задача — перенести на себя Ops‑часть Inference‑сервисов, чтобы заказчики спокойно занимались своими профильными задачами, не отвлекаясь на, скажем, рутину администрирования. Например, ML‑инженер работает с данными и обучает модели. Нет смысла делать из него DevOps‑инженера или бэкенд‑разработчика, который конфигурирует и пишет веб-сервисы.
В безупречном варианте хотелось бы прийти к схеме, когда ML‑инженер кладет модель в S3 (или другое объектное хранилище данных) и получает endpoint для работы. При этом вся магия Ops‑составляющей, которую мы раскроем в других требованиях, происходит под капотом платформы.
Деплой без даунтайма
Обновление моделей — частый кейс. На этом этапе закладываются новые фичи, что очень важно для сохранения конкурентоспособности на рынке. Появляется задача: доставить модели до конечного клиента с наименьшим time to market. Возникает требование — максимально бесшовное обновление моделей в коммерческой эксплуатации с предварительным тестированием на трафике. Для этого как нельзя лучше подходит стратегия развертывания, получившая название Canary Deploy.
Canary Deployment — метод развертывания ПО, который позволяет выпускать новые версии продукта постепенно и контролируемо. Название «канарейка» пришло из тех времен, когда шахтеры брали этих птиц в шахты для получения предупреждения об опасных газах.
В контексте DevOps такой подход предусматривает выпуск новой версии сначала для небольшой части клиентов (обычно от 1% до 10% трафика). Только после выявления и устранения всех дефектов приложение или сервис передается всей пользовательской базе.
Организовать автомасштабирование ресурсов
Нагрузка на наши Inference‑сервисы может значительно меняться даже в течение дня. В этом нет каких‑то отличий от функционирования обычных веб-сервисов, особенно с учетом использования облачных технологий. Применение горизонтального масштабирования возможно, но приходится принимать во внимание использование GPU‑ресурсов. В статье «Как справиться с нагрузкой в черную пятницу? Автоскейлинг инференса на GPU в Kubernetes» подробно разбирается пример ChatGPT в новогодний ажиотаж.
OpenAI задействует 3617 серверов HGX A100 для обеспечения MAU (Monthly Active Users) численностью около 100 млн. И даже с такой мощной инфраструктурой SLA в 99,999% остается недостижимым, что видно на панели статуса.
Реализовать Inference Graph
Inference Graph представляет последовательность операций или вычислений, которые выполняются для получения предсказаний от обученной модели. Граф описывает, как данные проходят через различные этапы обработки: предварительную подготовку, применение модели, а также завершающую доводку и коррекцию результатов.
Такая функциональность сейчас не пользуется большим спросом. Интервью с компаниями и клиентами показали, что все хотят просто организовать последовательную цепочку обработки данных моделью — например, preprocessing, processing и postprocessing. Закладывать Inference-граф в архитектуру стоит с учетом развития рынка ML.

Необходимость в подобной визуализации возрастает при составлении цепочек из LLM‑моделей. Такие вычислительные процессы требуют достаточно много ресурсов на видеокартах. Бывает, что нескольким моделям одной GPU не хватает — тогда в случае использования Kubernetes их приходится размещать на разных нодах. Например, для реализации цепочки audio-to-image можно использовать Whisper и Stable Diffusion, которые без дополнительного сжатия не поместятся даже на TeslaT4 16Gb.
Какой вариант реализации выбрать
Есть три пути разработки нового решения.

Облачные SaaS нам не подходят по очевидным причинам — мы сами хотим к такому прийти. Однако можно выделить интересные аналоги, к которым стоит присмотреться:
Разрабатывать собственное решение лишь для proof of concept слишком дорого. Да, можно в целом «обернуть» нашу модель во Flask/Fast API и получить заветный endpoint. Но как удовлетворить все требования без реализации дополнительной функциональности?
Создание своего Inference‑сервиса — отнюдь нетривиальная задача, что подтверждает и Nvidia в одной из своих инструкций.
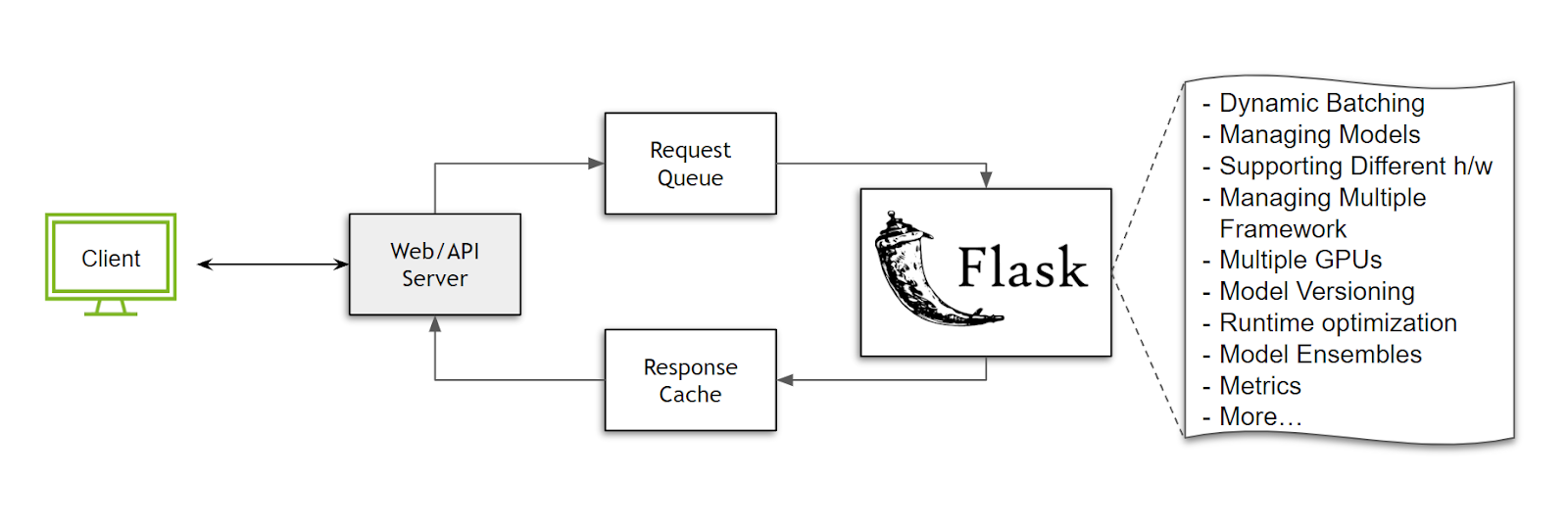
Использовать решения с открытым исходным кодом — тоже достаточно трудозатратно. Потребуется разобраться в коде, документации, и убедиться в том, что все необходимые требования удовлетворяются. При этом важно, чтобы основные фичи, которые закладываются в платформу, не нуждались в дополнительной разработке.
И мы нашли этот путь. О нем и рассказываем.
Как мы начинали разработку платформы
Для построения своей платформы мы рассмотрели множество существующих решений, взвешивали все «за» и «против». Хотелось и задуманные стратегические цели достигнуть, и соблюсти реалистичные сроки их воплощения. Существенно многое: зрелость компонентов, наличие детальной технической документации, активность разработчиков и ясные перспективы проектов. В конце‑концов остановились на двух.
NVIDIA Triton Inference Server
Основные возможности Triton Inference Server и его настройка хорошо описаны в документации. Мы расскажем о фишках, которые запросто можно пропустить, но которые сильно помогают при автоматизации настройки.
Итак, за основу платформы мы выбрали Triton, так как без дополнительной настройки он уже имеет внушительные характеристики.
- NVIDIA Triton Inference Server очень быстр на GPU от Nvidia (C++ под капотом), а в нашем облаке в основном представлены именно такие видеопроцессоры.
- Inference и observability уже встроены: HTTP‑ и GPRS‑протоколы, метрики для Prometheus.
- Есть пакетирование запросов и поддержка многочисленных форматов моделей: PyTorch, TesorFlow, TensorRT, ONNX и OpenVINO.
- Решение отлично работает с фреймворками LLM: vLLM, TensorRT-LLM.
- Ансамбль моделей внутри одной ноды — получаем аналог Inference‑графа.
При этом в базовой функциональности все же не хватает.
- Нет «мультинодального» Inference‑графа: Triton способен организовать цепочку внутри одного инстанса, но нам необходимо предусмотреть создание цепочек моделей на разных нодах.
- Не хватает распределения трафика на разные версии моделей для тестирования обновлений. Triton умеет внутри одного инстанса обновлять модели без downtime, но распределять трафик между разными версиями — задача другого уровня, здесь скорее поможет Service Mesh.
- Отсутствует автомасштабирование инфраструктурных ресурсов — платформа базируется на Kubernetes, а значит необходимо уметь управлять инфраструктурой.
Чтобы удовлетворить требования, которые не охватывает NVIDIA Triton Inference Server, мы изучили рынок инструментов и решили попробовать Seldon Core.
Seldon Core
Seldon — один из самых популярных инструментов для управления deploy‑моделями. Разработчики сосредоточили много функций, которые сильно упрощают жизнь ML-разработчикам.
Важно заметить, что в Seldon отсутствуют серверы для моделей: он использует как привычные внешние решения, так и позволяет подключить свое. Фактически, Seldon — это deploy‑оркестратор в Kubernetes.
Мы разворачивали seldon-core-operator в Kubernetes, который позволяет с помощью CRD создавать необходимые сущности Seldon Deployment, в которых и описываются наши Inference’ы.
CRD (Custom Resource Definition) дает пользователям механизм расширения API Kubernetes, позволяя добавлять свои типы ресурсов. Так можно создавать собственные объекты, которые будут храниться в etcd и управляться практически как и предопределенные: Pods, Services и Deployments.
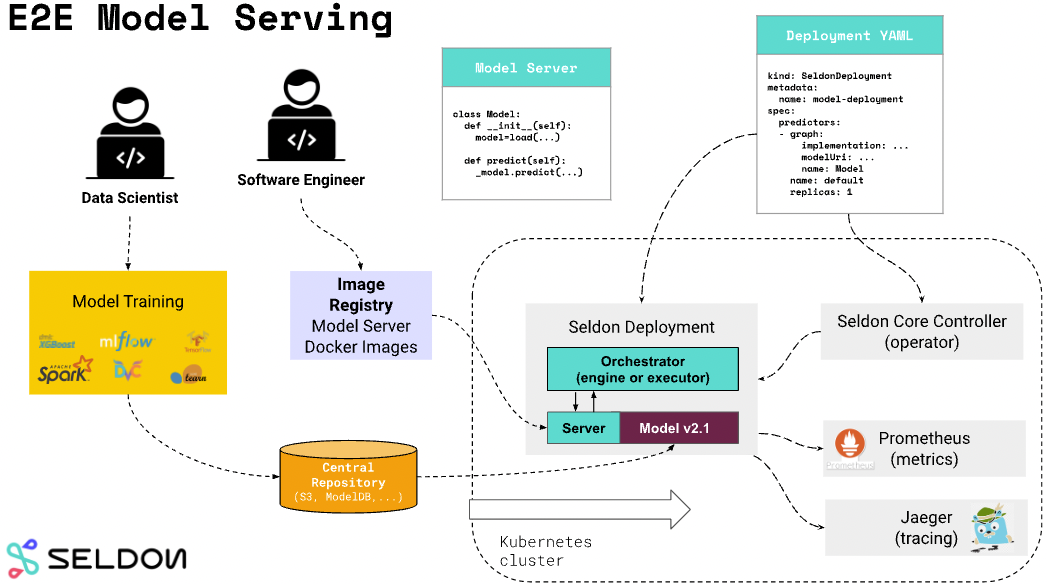
Особенности Seldon
- Service Mesh нужно устанавливать дополнительно. Он может работать в паре с Ambassador или Istio, который мы и выбрали, так как хорошо с ним знакомы.
- Метрики, полученные при разворачивании, собираем в Prometheus, а трейсы запросов упаковываем в Jaeger.
- Канареечный деплой уже реализован в Seldon на базе Istio.
- Inference graph удобно сконфигурировать в CRD.
- Автомасштабирование ресурсов можно организовать с помощью Keda.
- Seldon обеспечивает поддержку манифестов CRD для Triton с помощью протокола V2.
Получилось идеальное решение, которое удовлетворило всем нашим требованиям, да еще и в формате одного продукта! Мы так и думали мы, пока не начали внедрять его.
Проблемы, которые не удалось победить в Seldon Core
Первая проблема, с которой мы столкнулись, описана в issue #5279 — Triton Inference server metrics is not supported.
Суть в том, что в манифесте Seldon Deployment с имплементацией Triton порт с метриками не пробрасывается наружу. Даже если использовать этот манифест с переопределением componentSpecs, то сгенерированный Deployment для Kubernetes не отображает порт метрик 8002. И это несмотря на то, что мы его явно указываем.
Манифест (значимая часть):
apiVersion: machinelearning.seldon.io/v1
kind: SeldonDeployment
metadata:
name: multi
namespace: seldon-triton
spec:
predictors:
- componentSpecs:
- spec:
containers:
- name: multi
image: nvcr.io/nvidia/tritonserver:23.10-py3
args:
- /opt/tritonserver/bin/tritonserver
- '--grpc-port=9500'
- '--http-port=9000'
- '--metrics-port=8002'
- '--model-repository=/mnt/models'
ports:
- name: grpc
containerPort: 9500
protocol: TCP
- name: http
containerPort: 9000
protocol: TCP
- name: metrics
containerPort: 8002
protocol: TCP
graph:
implementation: TRITON_SERVER # проблемная имплементация
logger:
mode: all
modelUri: gs://seldon-models/triton/multi
name: multi
type: MODEL
name: default
replicas: 1
protocol: v2
Сгенерированный Deployment (лишняя часть удалена):
apiVersion: apps/v1
kind: Deployment
metadata:
name: multi-default-0-multi
namespace: seldon-triton
spec:
template:
spec:
containers:
- name: multi
image: nvcr.io/nvidia/tritonserver:23.10-py3
ports:
- name: grpc
containerPort: 9500
protocol: TCP
- name: http
containerPort: 9000
protocol: TCP
Без порта 8002 мы не можем собирать в Prometheus метрики из Triton, что перечеркивает реализацию автомасштабирования наших ресурсов.
Можно убрать implementation: TRITON_SERVER и определить порты явно. Переадресация портов начинает работать, но тогда мы теряем доступ к нашему endpoint по протоколу V2 из‑за нарушения логики работы с Istio. Единственная возможность — переписать CRD для манифеста Triton. Это тоже не выход: вести целую параллельную ветку сложного проекта ради исправления одной особенности неразумно.
Есть и еще одна, пусть и менее критическая проблема — неполная и запутанная документация. Seldon подразделяется на открытый Seldon Core и проприетарный Seldon Enterprise. Упор в разработке делается на поддержку корпоративной версии — для бесплатной же, по‑видимому, не всегда находятся силы, чтобы поддерживать справочные материалы в актуальном состоянии. Например, для деплоя Triton в документации в 2024 года используется версия контейнера 21 года, которая с тех пор претерпела значительные изменения.

К чему мы пришли
Seldon оказался для нас достаточно проблемным и громоздким продуктом. С одной стороны, он отвечает всем пожеланиям от Inference‑платформы. С другой — обременителен в изучении и внедрении.
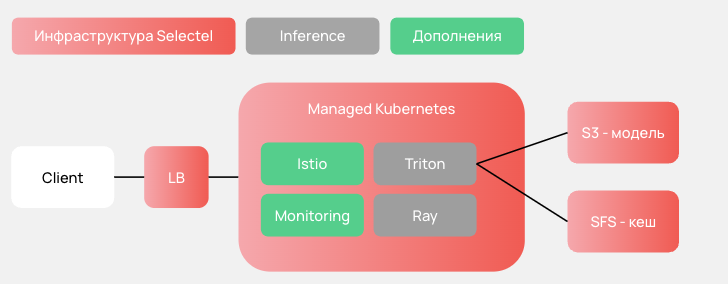
Мы решили упростить нашу схему: выбросить из нее Seldon и оставить Istio для регулирования трафика между Inference’ми и Triton, который остается ядром нашего сервиса.

Что такое Inference‑платформа Selectel
В итоге сформировалась следующая концепция платформы:

Манифест мы взяли из открытого репозитория Nvidia и дополнили его своими пятью основными фичами платформы. Получившийся манифест доступен в нашем открытом репозитории, где указаны все необходимые справочные материалы по работе с Inference‑платформой. Подробнее о репозитарии мы расскажем в следующей статье.
Инфраструктура платформы
Инфраструктура платформы собрана из продуктов Selectel.
- Облачный балансировщик нагрузки — через него проходит весь трафик.
- Managed Kubernetes — оркестратор наших сервисов.
- Amazon S3 — для хранения моделей и их конфигураций.
- Selectel File Storage (SFS) — содержит кэш моделей для общего использования репликами.
Доставка до клиента
Сейчас мы доставляем клиенту платформу таким же образом, как и ML‑платформу. Процесс организован с помощью пайплайна GitLab CI/CD, где каждый инфраструктурный элемент оборачивается Terraform-модулем и версионируется. Также Terraform устанавливает в Kubernetes необходимые Helm‑чарты. Подробнее про такой способ автоматизации развертывания и доставки можно почитать в статье «Как мы ускорили деплой облачной платформы в 20 раз и избавились от панических атак».
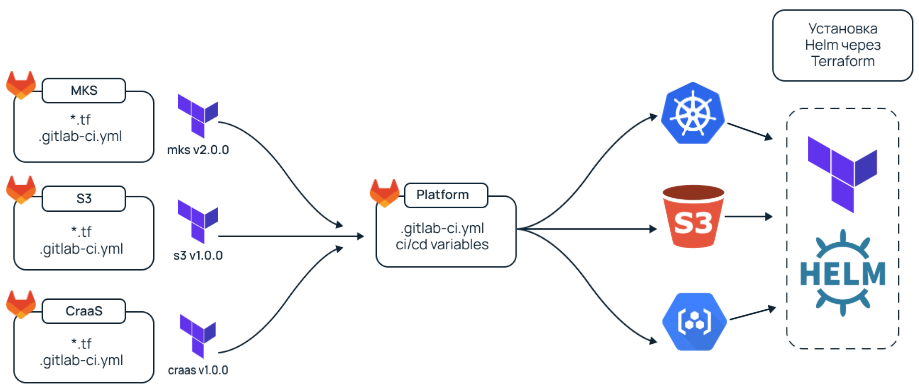
В будущем мы хотим перейти к нашей модели PaaS и пересобрать доставку платформы для клиентов в пользу GitOps‑подхода.
Заключение
В первую очередь мы разрабатываем API для нашей платформы, чтобы клиентам не приходилось разворачивать манифесты в Kubernetes самостоятельно. Деплой платформы и Inference‑сервисов будет доступен в панели управления. Доставку платформы мы собираемся реализовывать с помощью FluxCD.
Без разработчика мы не справимся. Если кого‑то заинтересовал наш продукт и у вас есть опыт программирования на Go — откликайтесь на нашу вакансию. Давайте разрабатывать ML‑проекты вместе!
Также мы собираемся упростить работу с Inference‑графом: правильнее для этого использовать интерфейс, а не прибегать к SDK и написанию кода на Python. Здесь тоже потребуется собственная разработка, так как на рынке готовых решений мы, к сожалению, не нашли.
Еще хотим добавить больше опций по организации безопасности платформы — например, работу с JSON Web Tokens и интеграцией таких готовых решений, как Keycloak.
В конце хотелось бы сказать, что разработка продуктов — особенно тех, у которых нет или мало аналогов — достаточно рискованное занятие. Представить на рынок MVP (Minimum Viable Product, минимально жизнеспособный продукт) без крупных затрат — это очень здорово. Использовать готовое решение, которое решает задачу клиента, — еще лучше. Мы так и сделали: выпустили наш проект в бета‑тестирование, и теперь вы можете подключиться на тест. Заполняйте заявки на сайте и знакомьтесь с Inference‑платформой Selectel.





