

Статью поделили на два уровня. Первая часть (без которой сложно понять вторую) — для тех, кто слышал слово «эмбеддинг», но не трогал его руками: разберем на пальцах и со стрелочками, что модель держит внутри своего цифрового серого вещества, в общем объясню простые вещи простыми словами. Вторая часть — для тех, кому интересно копнуть чуть дальше базы: туда я поместил grokking, фурье-частоты и суперпозицию, и там мы вытащим реальное пространство обученной модели и посмотрим, как оно устроено.
Часть 1. Для тех, кто слышал слово «эмбеддинг»
Модель не видит букв
Первое, что стоит обозначить: модель не работает с текстом в привычном нам с вами смысле (даже если название «большие языковые модели» заставляет вас думать обратное). Сначала текст режется на токены — на куски из символов. Иногда токен это целое слово, а иногда и полслова. Каждому токену присвоен номер, и дальше внутрь модели идет только последовательность номеров. Даже слова «токен» для нее не существует, зато есть условный токен номер 8421.
Но с номерами тоже не выйдет нормально работать, ведь номер — это просто бессмысленный ярлык: токен 8421 не «больше» и не «лучше» токена 8425. Поэтому каждому токену сопоставляют вектор — список из нескольких десятков или сотен чисел. Вот этот список и называется эмбеддингом.
Вектор — это просто стрелка
Не пугайтесь слова «вектор». Вектор из двух чисел, например (3, 5) — это стрелка из начала координат в точку (3, 5): три базисных (единичных) вектора вправо, и пять вверх.
Вектор из трех чисел — стрелка в пространстве. Вектор из 128 чисел — стрелка в 128-мерном пространстве, вот только его невозможно представить (углеродным формам жизни уж точно, зато кремниевым…), но проводить расчеты с ним в его пространстве все равно можно: есть длина стрелки, есть направление, есть угол между двумя стрелками.
Вот так выглядят векторы чисел в нашей будущей модели, спроецированные на плоскость:
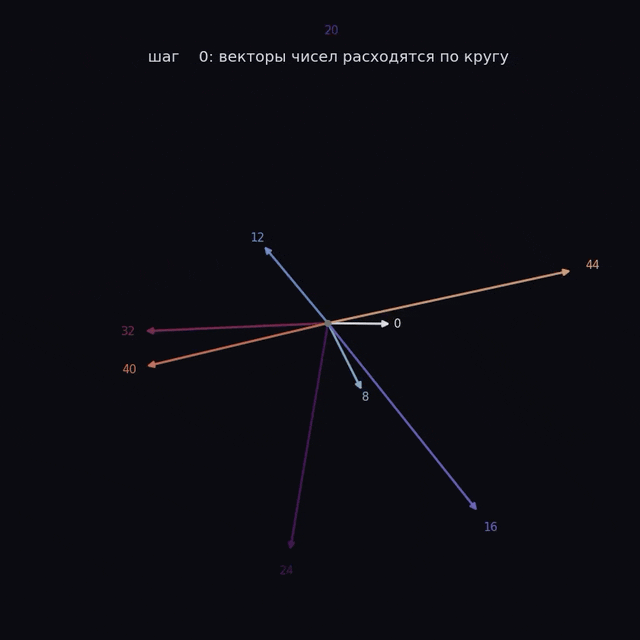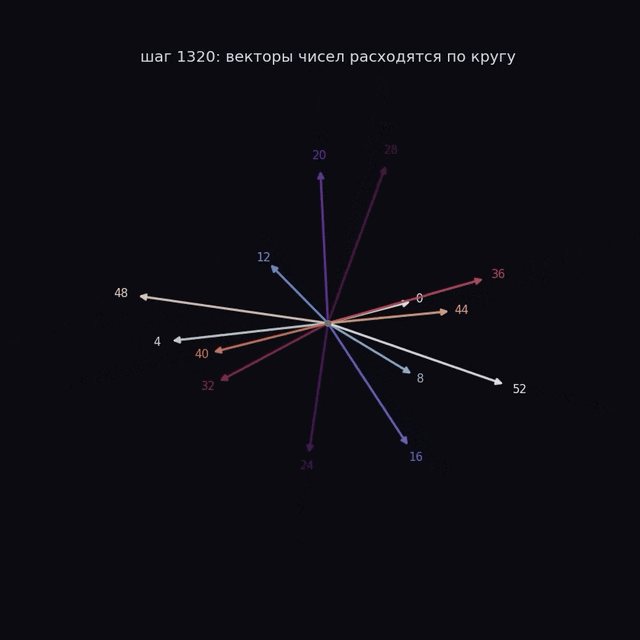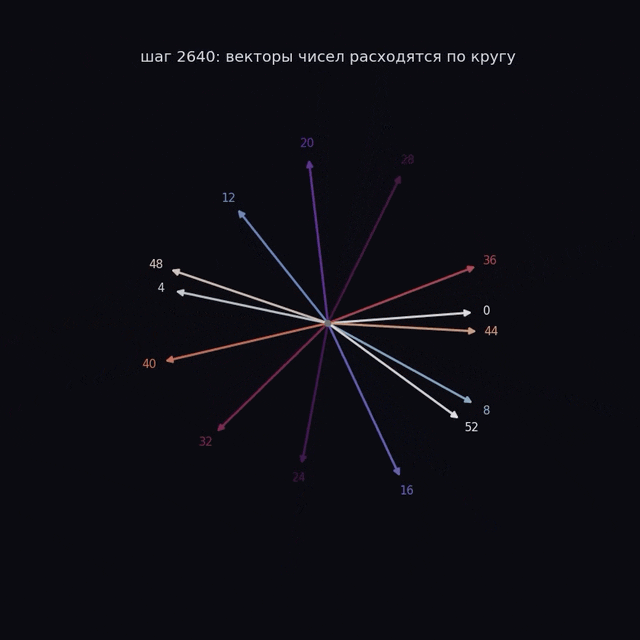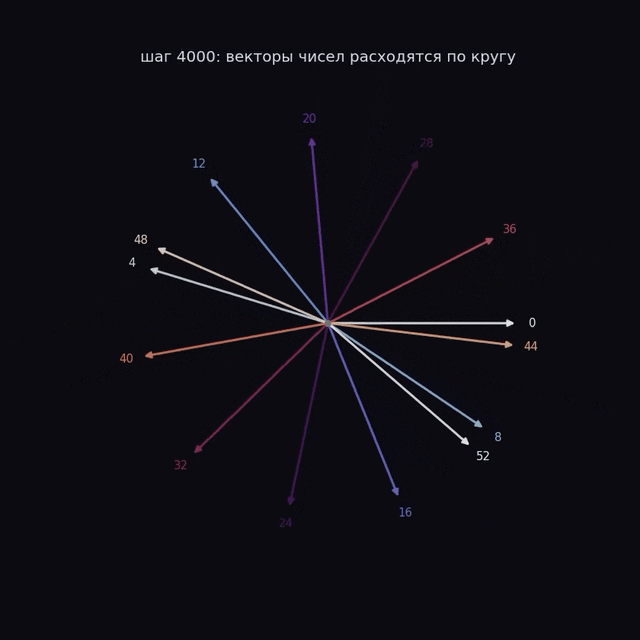
Каждая стрелка соответствует одному числу. Смысл числа теперь в том, куда смотрит стрелка. И вот это «куда смотрит» модель определяет сама.
Откуда у стрелок берется направление
Тут самое важное место первой части. В начале обучения все эти векторы случайные. Каждому токену выдали стрелку, смотрящую в произвольную сторону (чистый шум и никакого смысла). Если в этот момент посмотреть на пространство, это просто облако точек без структуры.
Смысл появляется во время обучения. Модель решает свою задачу, ошибается, и после каждой ошибки чуть-чуть подкручивает векторы, чтобы в следующий раз ошибаться меньше. Миллионы таких подкручиваний, и стрелки (которые были случайными, напоминаю) разворачиваются в осмысленные — для нас и для модели — стороны. Похожие по роли токены начинают смотреть в близкие стороны, а разные — соответственно в разные.
Это главная идея, на которой держится вся тема: модель расставляет точки в пространстве так, чтобы геометрия этого пространства отражала смысл. Близко = похоже, а направление = свойство.
Дальше я покажу это на работающей модели. Если первая часть зашла и хочется глубже, то добро пожаловать в кроличью нору.
Часть 2. Для тех, кто хочет копнуть поглубже
Эксперимент: учим модель складывать по модулю
Давайте возьмем задачу попроще, чтобы мы смогли препарировать нашу модель. Берем числа от 0 до 52 и учим модель складывать их по кругу. То есть у нас будет круг из 53 делений: дошли до 52, и следующий шаг возвращает в 0. Математики пишут это как (a + b) mod 53, но за значком mod прячется та самая идея циферблата.
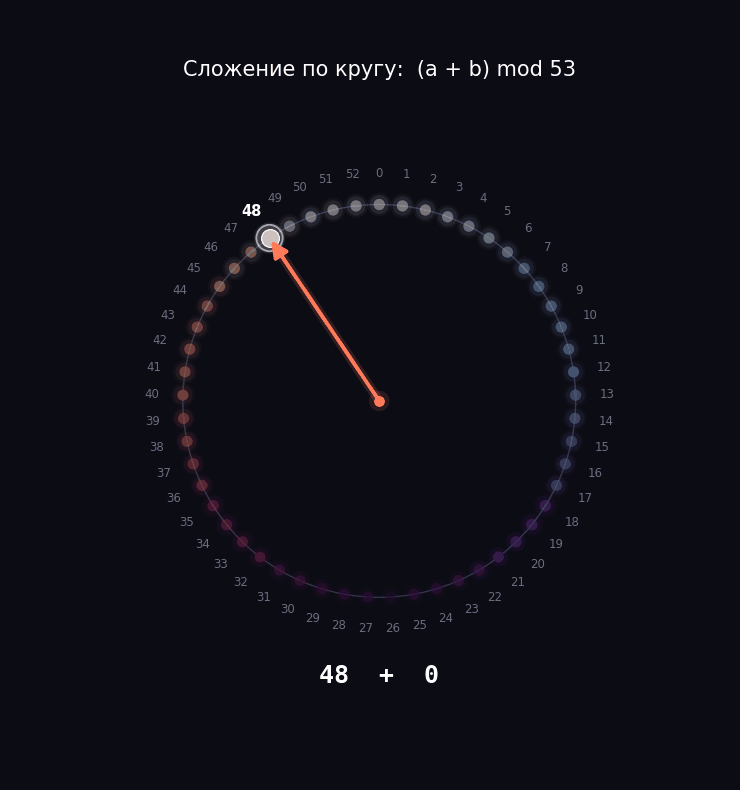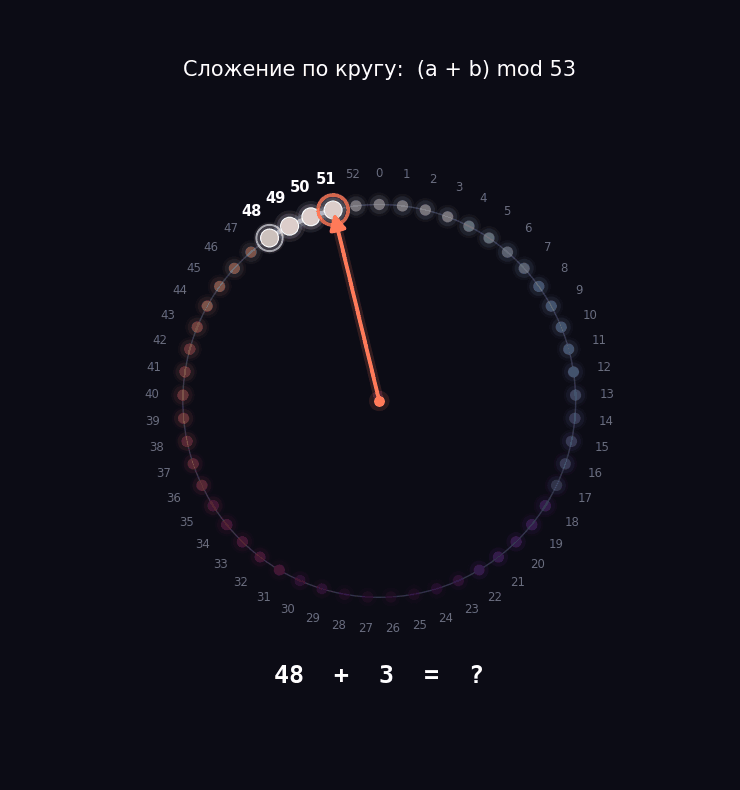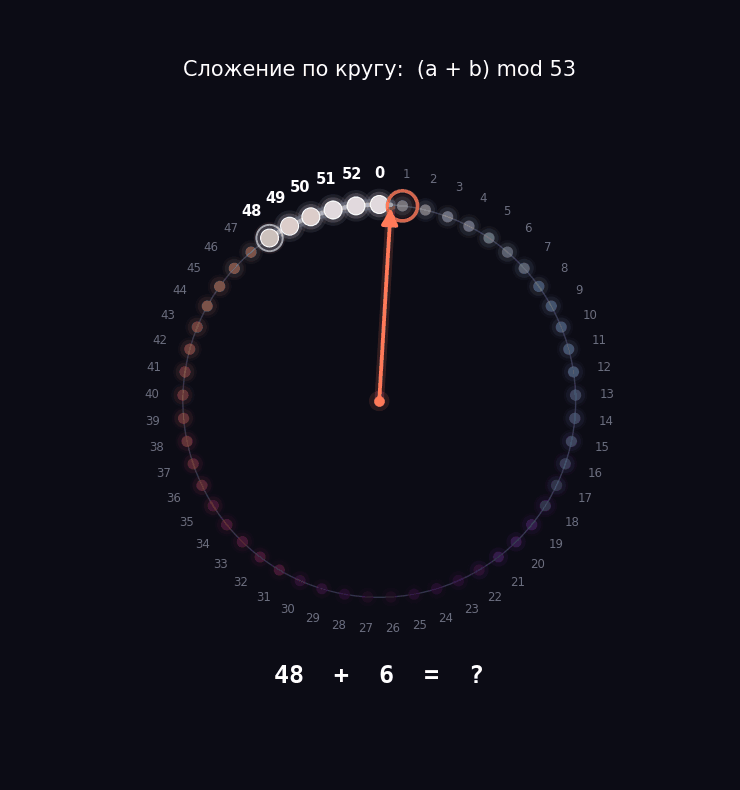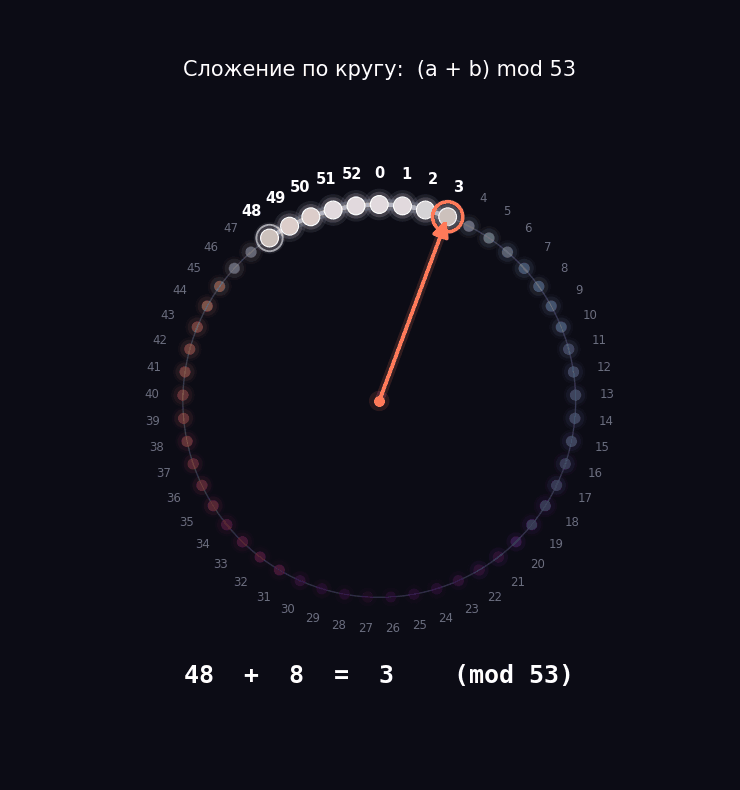
Почему именно 53, а не круглые 50 или 100? Потому что 53 — простое число, оно не делится ни на что, кроме себя и единицы. Из-за этого у модели не будет соблазна схитрить и разбить круг на аккуратные половинки или четвертинки.
Сам опыт, о котором идет речь, много раз показывали в англоязычном интернете. Но по-русски, чтобы с кодом и анимацией и разжевано я ничего толкового не нашел, поэтому собрал свое.
Модель я нарочно сделал примитивной: только таблица стрелок из первой части плюс пара слоев, которые перемалывают числа. Никакого внимания и никаких трансформеров для большей наглядности работы модельки. И половину всех пар чисел я показываю модели на обучении, а вторую половину прячу и держу для экзамена.
import numpy as np, torch, torch.nn as nn
import matplotlib.pyplot as plt
from matplotlib import cm
torch.manual_seed(0); np.random.seed(0)
N, DIM, STEPS = 53, 128, 4000
a = np.repeat(np.arange(N), N); b = np.tile(np.arange(N), N)
A = torch.tensor(a); B = torch.tensor(b); Y = torch.tensor((a + b) % N)
idx = np.random.permutation(len(a)); cut = len(a) // 2
tr = torch.tensor(idx[:cut])
class Model(nn.Module):
def __init__(s):
super().__init__()
s.emb = nn.Embedding(N, DIM)
s.mlp = nn.Sequential(nn.Linear(2*DIM,256), nn.ReLU(),
nn.Linear(256,256), nn.ReLU(), nn.Linear(256,N))
def forward(s, a, b):
return s.mlp(torch.cat([s.emb(a), s.emb(b)], -1))
m = Model()
opt = torch.optim.AdamW(m.parameters(), lr=1e-3, weight_decay=1.0)
lossf = nn.CrossEntropyLoss()
for step in range(STEPS+1):
loss = lossf(m(A[tr], B[tr]), Y[tr])
opt.zero_grad(); loss.backward(); opt.step()
E = m.emb.weight.detach().numpy(); X = E - E.mean(0); ns = np.arange(N)
k = max(range(1, N//2+1),
key=lambda k: np.sum((np.cos(2*np.pi*k*ns/N) @ X)**2) +
np.sum((np.sin(2*np.pi*k*ns/N) @ X)**2))
c, s = np.cos(2*np.pi*k*ns/N), np.sin(2*np.pi*k*ns/N)
coef = np.linalg.lstsq(X, np.stack([c, s], 1), rcond=None)[0]
P = X @ coef
plt.style.use("dark_background")
fig, ax = plt.subplots(figsize=(7,7))
ax.plot(P[:,0], P[:,1], color="#3a3a55", lw=.8)
ax.scatter(P[:,0], P[:,1], c=cm.twilight(np.linspace(0,1,N)), s=130)
for i in range(N):
ax.annotate(str(i), P[i], color="white", fontsize=7, ha="center", va="center")
ax.set_aspect("equal"); ax.set_xticks([]); ax.set_yticks([])
plt.tight_layout(); plt.savefig("ring.png", dpi=130); print("freq k =", k)
Вес weight_decay не для красоты. Без сильной регуляризации модель просто выучит обучающие пары и не станет строить никакую структуру — ей это будет не нужно. Под регуляризацией здесь понимается искусственный штраф за сложность, который притягивает значения внутренних параметров модели к нулю и не дает им бесконтрольно расти.
Регуляризация давит на зубрежку и заставляет искать обобщающее решение. Дело в том, что для запоминания тысяч отдельных фактов модели требуются огромные рандомные веса.
Штраф же принудительно сжимает их, буквально вынуждая систему искать самое компактное и красивое математическое правило. Именно поэтому здесь и проявляется grokking — озарение.
Зубрежка, плато, озарение
Давайте теперь следить за двумя цифрами по ходу обучения:
- первая — насколько хорошо модель отвечает на тех парах, что ей показывали;
- вторая — насколько хорошо она отвечает на спрятанных парах.
И вот что мы увидим. На показанных парах модель почти сразу отвечает отлично — ну еще бы, она их просто запомнила. А на спрятанных долго не может ничего, тычет наугад, цифра лежит на нуле. Логично: заученное знает, а правил не понимает, поэтому и валится.
А потом идет озарение. Где-то после полутора-двух тысяч шагов цифра на спрятанных парах вдруг резко идет вверх и догоняет показанные.
Вот как все это выглядит:
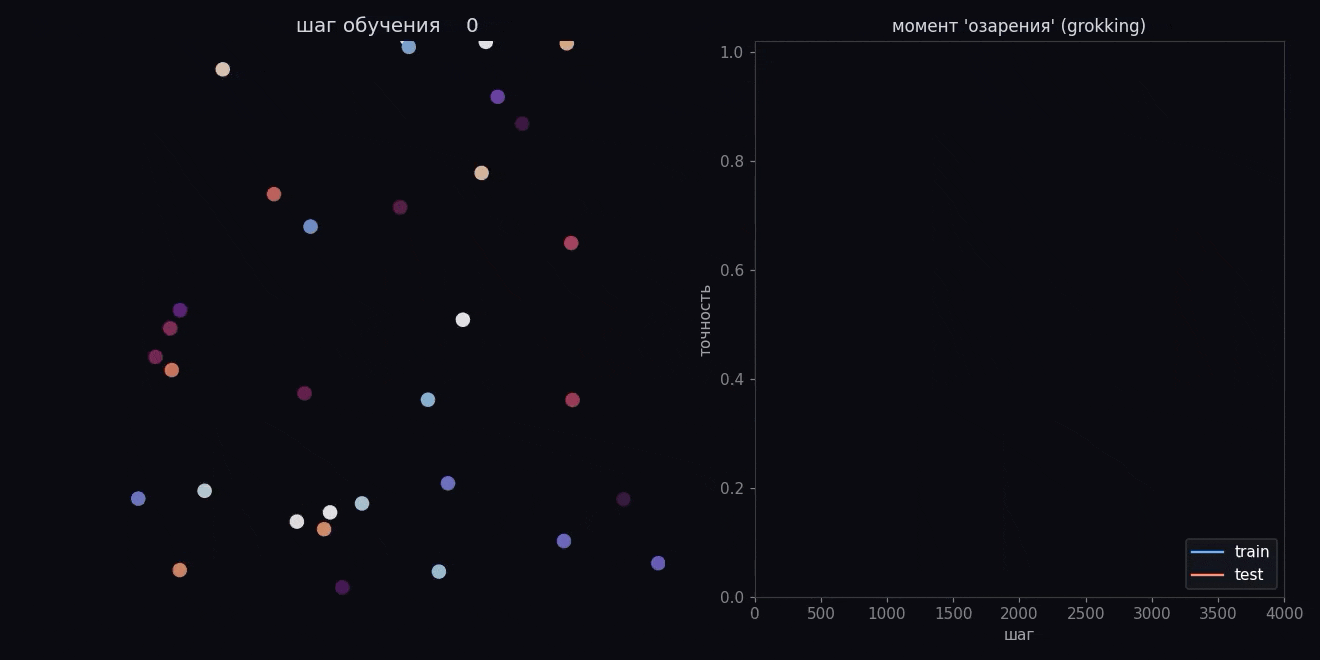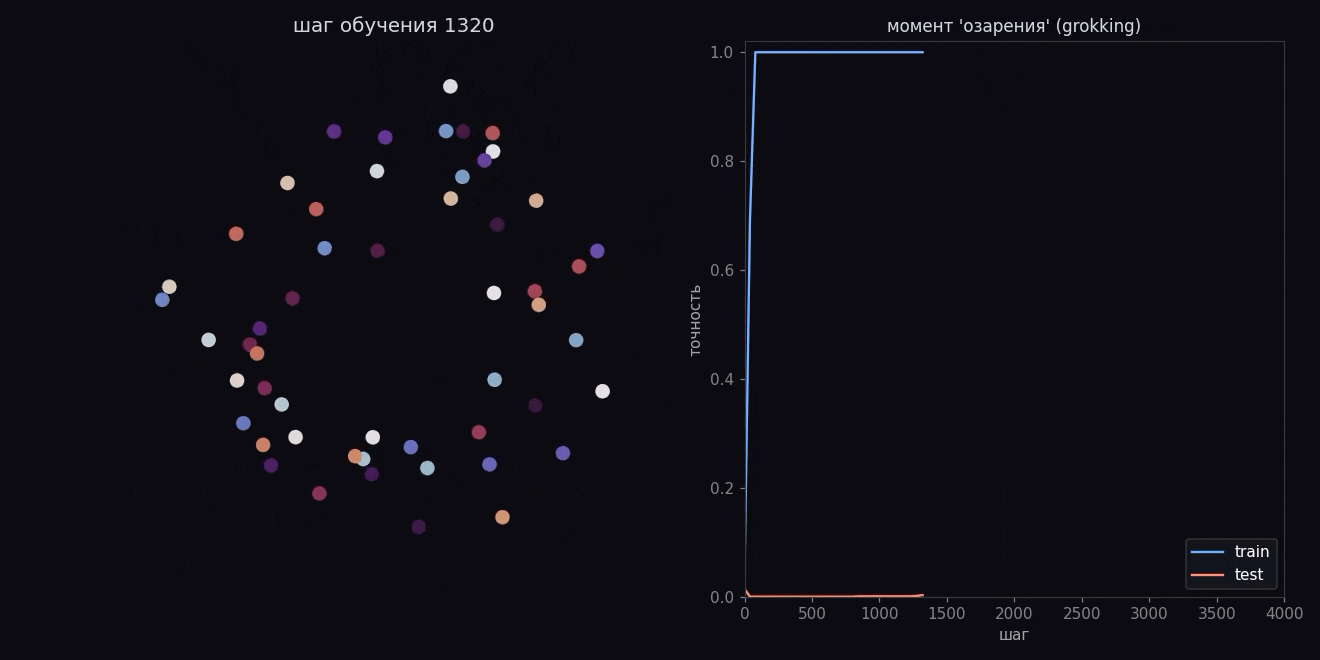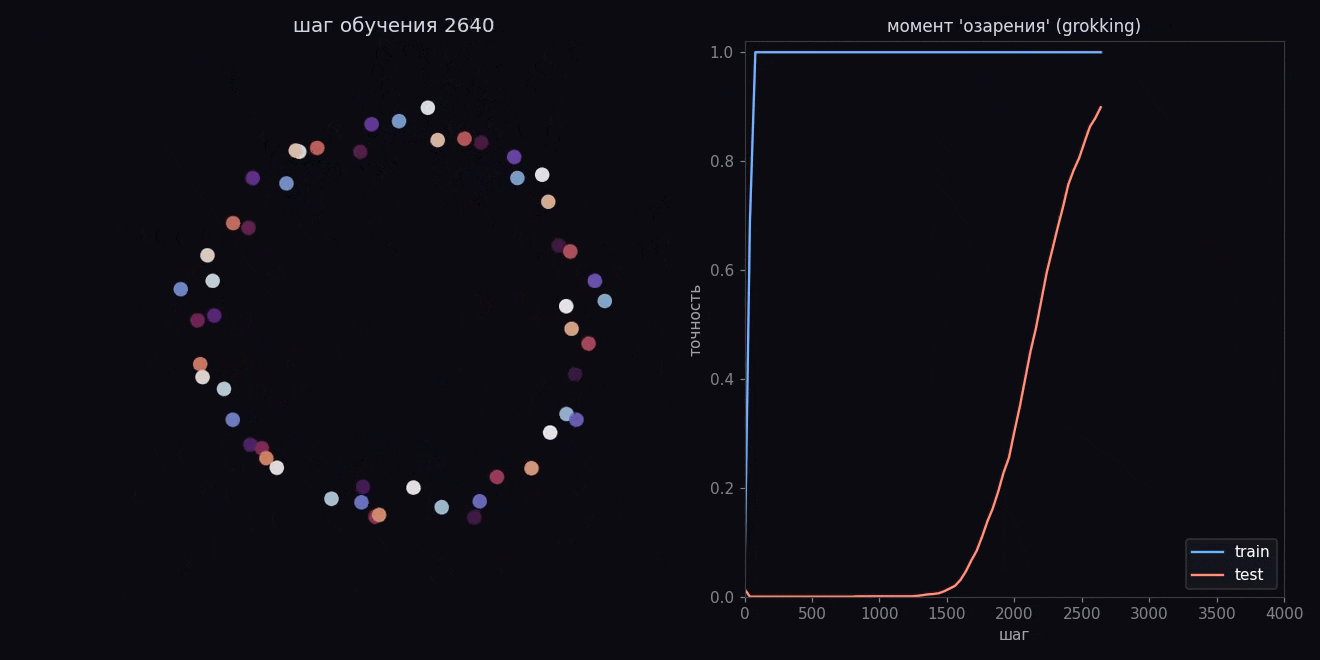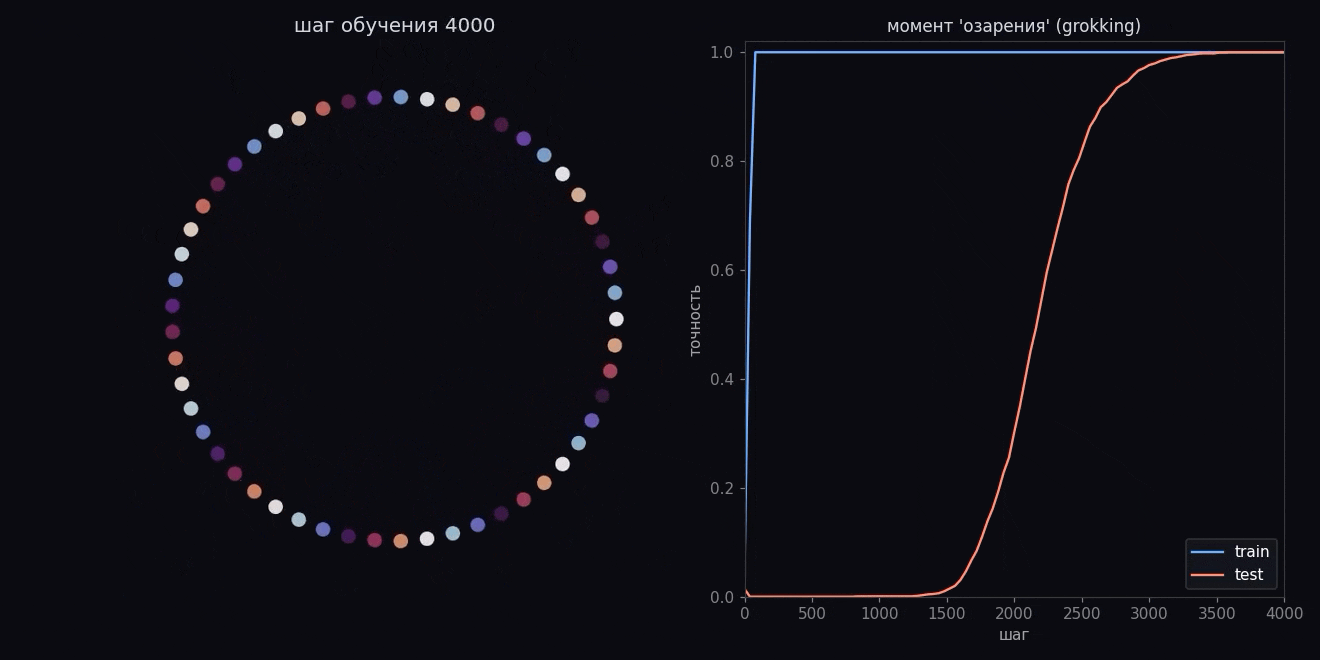
Никто модели ничего не подсказывал в эту секунду. Она просто достаточно долго крутилась под прессом регуляризации, и в какой-то момент зубрежка надломилась и превратилась в понимание (или просто в grokking).
А что в эту же секунду происходит с эмбеддингом?
Числа складываются в кольцо
Помните, в начале все стрелки смотрели куда попало? Так вот, к моменту озарения числа перестают быть стохастически направлены и встают аккуратным кольцом:
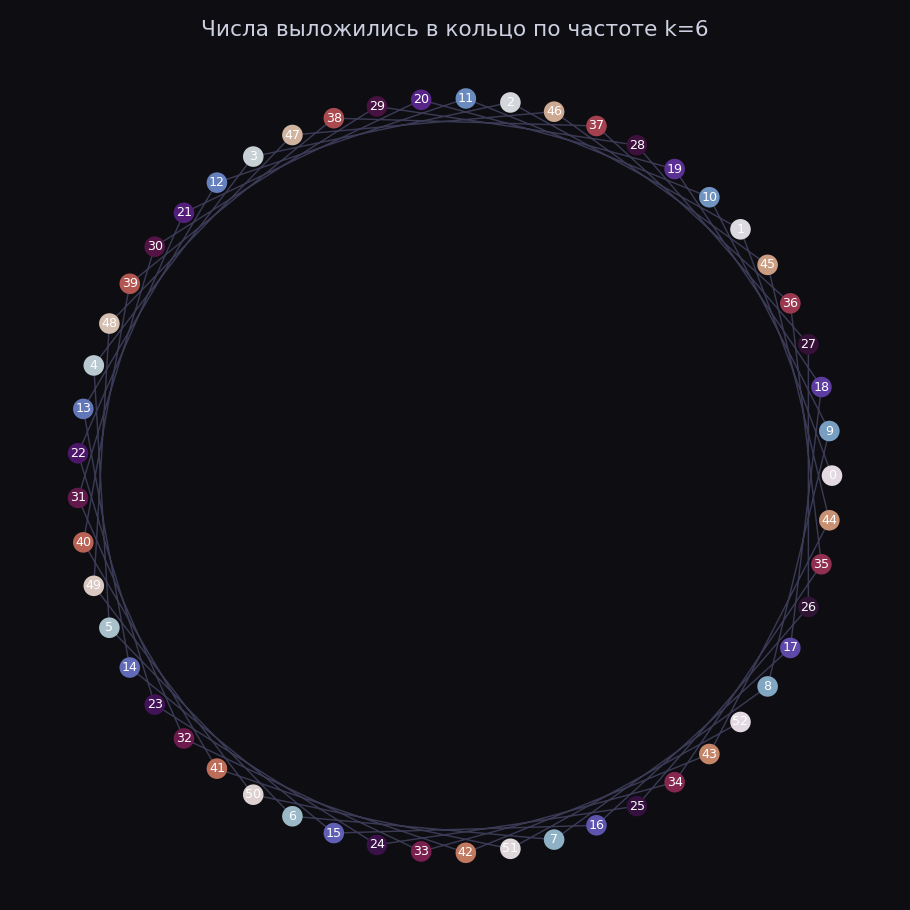
Посмотрите внимательно на порядок. Числа по кругу идут не подряд, а через постоянный шаг, и если соединить их линией, рисуется многоконечная звезда. Модель сама поняла, что числа замкнуты в круг, и разложила их по окружности, потому что на круге складывать проще всего. Сложить два числа теперь значит просто повернуться на два угла и посмотреть, куда мы попали.
Никто не давал модели окружность. Ей вообще не давали геометрии, только пары чисел и правильные ответы. Круг она построила сама, потому что для модульного сложения это вычислительно самое дешевое представление.
Оговорка про частоту
Теперь надо прояснить одну вещь, иначе картинка выйдет приукрашенной. Стрелки у нас обитают не на плоскости, а в пространстве из 128 направлений. А я показываю вам плоскую картинку. Все потому что я взял это многомерное облако и спроецировал его на плоскость. И проекцию я выбрал не случайную, а ту, на которой кольцо видно отчетливее всего.
И тут, прошу внимания — главная мысль второй части. Кольцо не одно. Если аккуратно разобрать на сколько разных кругов модель разложила свои числа, окажется, что кругов сразу несколько, и они вложены друг в друга в одном и том же пространстве.
Один круг с крупным шагом, другой с мелким, третий с еще каким-то. Если уж и спускаться в кроличью нору с часами, то представьте циферблат, на который наложили второй циферблат с другим числом делений, а сверху третий, и все они работают одновременно. Модель считает сложение сразу на всех этих часах параллельно, а потом сводит ответы в один.
У этого тоже есть имя в науке. Разложить сигнал на набор круговых волн разной частоты — это и есть преобразование Фурье, та самая штука, которой раскладывают звук на ноты. Модель, по сути, переоткрыла Фурье сама, никто ее этому не учил. Именно это Nanda и соавторы разобрали в своей работе про grokking.
А на плоской картинке мы видим только один круг, самый громкий. Остальные просто лежат в других проекциях того же пространства, и на одной плоскости их сразу не показать.
Зачем это все, если модель игрушечная
Справедливый вопрос. У нашей крохи 128 направлений на 53 числа — вроде бы вагон места, можно было бы каждому числу выделить отдельную полку и не мучиться. А она все равно не стала, а упаковала числа внахлест в несколько кругов. Запомните этот факт, он сейчас выстрелит.
Теперь давайте подумаем о настоящих, больших LLM-ках. Сколько всего им надо удержать в голове: каждое слово языка, каждый оттенок смысла, грамматику, факты про мир, имена, даты. Этого добра в миллионы раз больше, чем у модели есть направлений в пространстве. Выделить каждому понятию по личной полке физически невозможно.
И что делает модель? Ровно то же, что и наша: кладет несколько смыслов внахлест. Это называют суперпозицией, когда на одном месте лежит сразу несколько вещей, и нужную достаешь по точному адресу.
Отсюда же вытекает и другой факт. Хочется ведь ткнуть пальцем в один нейрон модели и сказать: вот этот отвечает за белки, а вот тот за глаголы — а не выйдет. Тот же самый нейрон у вас будет отвечать и за белки, и заодно за что-нибудь про юридические тексты, и еще за пару вещей, между собой никак не связанных, которые модель просто сложила на одну полку из экономии. Распутать этот клубок обратно — тема для отдельной статьи.
А вывод простой и он переносится с нашей игрушки на любую серьезную модель. У нее (в смысле, у серьезной модели) смыслов всегда больше, чем измерений в пространстве, поэтому она держит их внахлест, а различает по тому, куда смотрит вектор.
Возвращаемся к иероглифам
Вот теперь, со всем этим багажом, понятно, чем опасен недоученный токен. Это кусочек, который в словаре модели есть, но в текстах, на которых ее учили, почти не попадался. Так бывает с редкими иероглифами и обрывками юникода, когда корпус собран из кучи языков вперемешку. Раз примеров почти не было, модель не получила сигнала, куда его двигать, и его стрелка так и осталась торчать там, где ее бросили в самом начале.
Пока этот токен не всплывает, все тихо. Но вспомните, как модель вообще выбирает следующий кусочек текста: она прикидывает вероятности сразу для всего словаря и тянет жребий.
Обычно правильный кусочек забирает себе почти всю вероятность, и жребий честно выпадает на него. А вот на стыке языков или в каком-нибудь редком, кривом контексте модель плывет, вероятности размазываются тонким слоем по множеству вариантов — и в этом хвосте оказывается наш иероглиф. Достаточно одного неудачного броска жребия, чтобы он вылез наружу прямо посреди текста. А дальше хуже: модель видит его уже как часть написанного и может с этого места поехать, и дальше.





