

10 апреля 2019 года человечеству показали оранжевый бублик. Журналисты назвали его «первой фотографией черной дыры». Через час картинка была у всех — мемы про глаз Саурона, шутки про пончик, антропоморфизация, заголовки «ученые сфотографировали невидимое».

Проблема в том, что это не совсем фотография.
Точнее сказать, это очень странная фотография: если бы вы использовали телескоп горизонта событий (англ. EHT — далее по тексту) «как камеру» и нажали кнопку, вы бы получили черный квадрат и никакого бублика. Потому что он делает измерения, из которых алгоритм уже собирает изображение… которого нет.
Вот про этот алгоритм, а также про то, как 3,5 петабайта данных летели в Бостон самолетом, и пойдет речь.
Зачем восемь телескопов, если можно один большой
Чтобы увидеть тень черной дыры в галактике M87 — той самой, в 55 млн световых лет от нас, — нужно угловое разрешение порядка 20 микросекунд дуги. Это, грубо говоря, как из Москвы разглядеть апельсин в Нью-Йорке. С точностью до косточки.
Угловое разрешение телескопа определяется простой формулой:
θ ~ λ/D
λ — длина волны наблюдения, D — диаметр апертуры. EHT работает на 230 ГГц, то есть λ ≈ 1,3 мм.
Подставим целевое разрешение:
D ~ λ/θ = (1,3 · 10⁻³ м) / (10⁻¹⁰ рад) ≈ 1,3 · 10⁷ м
13 000 км — это диаметр Земли (ну, чуть меньше на самом деле). Тарелку диаметром с Землю никто не построит, но есть другой путь.
VLBI: тарелка-призрак
Идея интерферометрии со сверхдлинной базой звучит так: если у нас есть два телескопа, разнесенные на расстояние B, то они вместе работают как кусок виртуальной тарелки диаметром B. Но не вся тарелка целиком — только одна, скажем так, «полоска» от нее.
Восемь телескопов EHT (от Чили до Южного полюса, от Мексики до Испании) дают C (8,2) = 28 парных базовых линий. Самая длинная — от Южного полюса до Испании — около 11 000 километров. Это и есть наш виртуальный диаметр.
Но «28 полосок от тарелки» — это совсем не то же самое, что цельная тарелка. И тут пригождается наша любимая математика.
Каждая пара телескопов измеряет одну точку Фурье-плоскости
Это ключевой момент, который ломает привычную логику (по крайней мере мою). Радиоинтерферометр измеряет Фурье-компоненты распределения яркости.
Если I (l, m) — это яркость неба в небесных координатах (l, m), то пара телескопов с базовой линией, проектируемой на небо как (u, v) (в единицах длины волны), измеряет величину, которая называется видимостью:
V(u, v) = ∬ I(l, m) · e^(−2πi(ul + vm)) dl dm
Это в точности двумерное Фурье-преобразование I. Каждая пара телескопов в каждый момент времени дает одну комплексную точку V(u, v).
Когда Земля вращается, проекция базовой линии на плоскость, перпендикулярную направлению на источник, меняется — каждая пара рисует на (u, v)-плоскости эллиптическую дугу. Это называется апертурный синтез: мы используем вращение Земли, чтобы заметать больше точек Фурье-плоскости, не двигая телескопы физически.
99,9% данных отсутствует
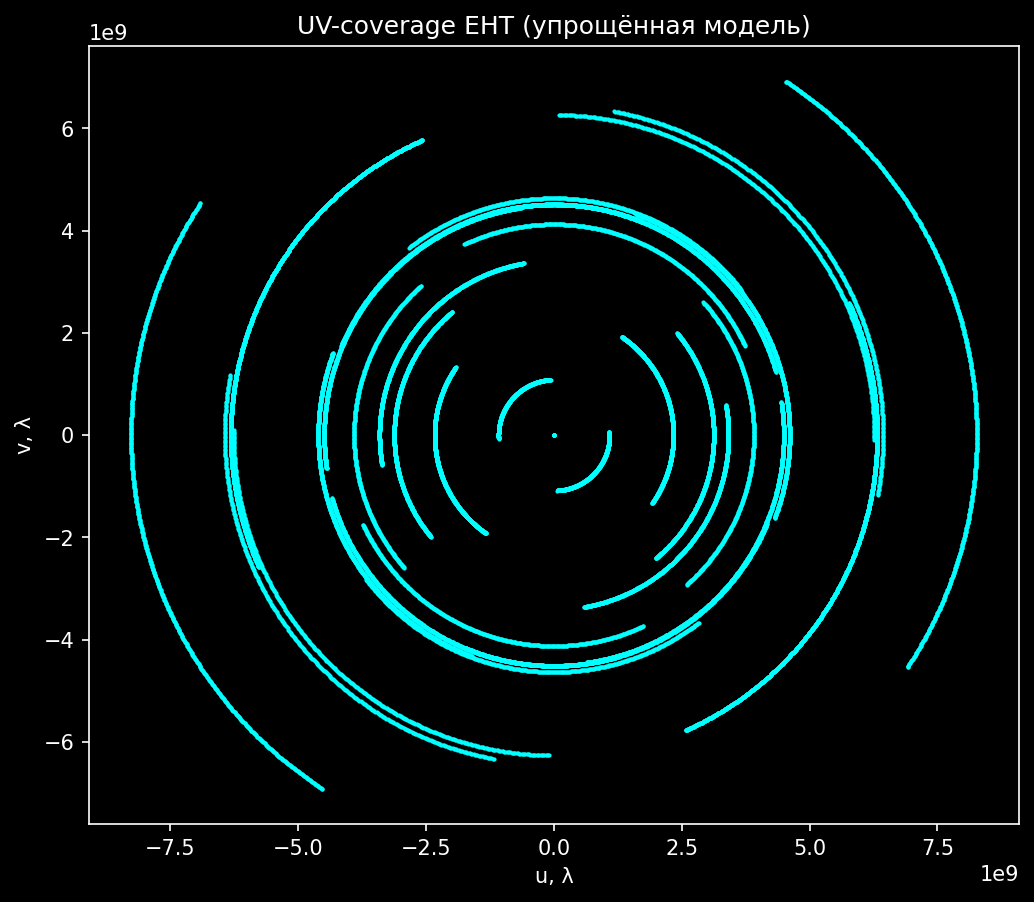
Чтобы восстановить изображение по обратному Фурье, в идеале нужно знать V(u, v) во всех точках плоскости. У EHT же несколько изогнутых линий, нарисованных на огромной плоскости.
Если оцифровать (u, v)-плоскость в сетку 1 024×1 024, то у нас будет порядка 10⁶ ячеек. Реальные данные покрывают, дай бог, тысячу из них. Это и есть тот самый «99,9% данных нет» из заголовка.
Картинку покрытия легко получить руками:
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('dark_background')
# Положения станций EHT (долгота, широта в градусах)
stations = {
'ALMA': (-67.75, -23.03), 'APEX': (-67.76, -23.01),
'JCMT': (-155.47, 19.82), 'SMA': (-155.48, 19.82),
'SMT': (-109.89, 32.70), 'LMT': ( -97.31, 18.99),
'IRAM': ( -3.39, 37.07), 'SPT': ( 45.00, -90.0),
}
R_earth = 6.371e6
def ecef(lon, lat):
lon, lat = np.radians(lon), np.radians(lat)
return R_earth * np.array([np.cos(lat)*np.cos(lon),
np.cos(lat)*np.sin(lon),
np.sin(lat)])
coords = np.array([ecef(*ll) for ll in stations.values()])
# Все 28 базовых линий
baselines = np.array([coords[i] - coords[j]
for i in range(8) for j in range(i+1, 8)])
# Эмулируем 6 часов наблюдения: вращаем Землю относительно источника
hours = np.linspace(-3, 3, 400) * np.pi / 12 # часовой угол в радианах
uv = []
for h in hours:
Rz = np.array([[ np.cos(h), np.sin(h), 0],
[-np.sin(h), np.cos(h), 0],
[ 0, 0, 1]])
uv.append((baselines @ Rz.T)[:, :2])
uv = np.concatenate(uv) / 1.3e-3 # в длинах волн при λ = 1.3 мм
# Эрмитова симметрия V(-u,-v) = V*(u,v) дает зеркальную копию покрытия
plt.figure(figsize=(7, 7))
plt.scatter( uv[:, 0], uv[:, 1], s=1, c='cyan')
plt.scatter(-uv[:, 0], -uv[:, 1], s=1, c='cyan')
plt.gca().set_aspect('equal')
plt.title('UV-coverage EHT (упрощенная модель)')
plt.xlabel('u, λ'); plt.ylabel('v, λ')
plt.show()
Запустите и увидите редкие изогнутые лепестки на огромной черной плоскости. Вот это и есть «фото», которое мы получаем напрямую: где телескопы намерили, там данные есть. А между лепестками миллионы неизвестных Фурье-компонент.
Грязное изображение и грязный пучок
Что будет, если просто взять обратное Фурье от того, что есть? Формально наш набор измерений можно записать так:
V_obs(u, v) = S(u, v) · V(u, v)
где S(u, v) — выборочная функция (sampling function), равная одному там, где мы намерили, и 0 везде остальное.
По теореме о свертке, обратное Фурье от произведения — это свертка обратных Фурье сомножителей:
I_dirty(l, m) = I_true(l, m) * B_dirty(l, m)
где B_dirty — обратное Фурье от S, известное как грязный пучок или PSF данной конфигурации. Это та функция размытия, через которую инструмент «смотрит» на небо.
И вот тут начинаются трудности: B_dirty выглядит ужасно. У него есть центральный пик, но вокруг — длинный шлейф боковых лепестков, артефактов и звезда Давида от регулярной структуры базовых линий. Если просто взять обратное быстрое преобразование Фурье, получится не M87 с тенью, а размазанная чертовщина, которую невозможно интерпретировать.
Нужна деконволюция. Нужно решить уравнение I_dirty = I_true * B_dirty относительно I_true. Только это уравнение не решается — оно недоопределено. Есть бесконечно много I_true, дающих то же самое I_dirty, просто потому что S(u, v) — нули в большинстве точек, и любая функция, которая в этих точках Фурье-плоскости делает что угодно, а в остальных совпадает с истинной видимостью, будет валидным решением.
Это классическая обратная задача и решается она, как все подобные задачи: введением априорных предположений о том, как должно выглядеть «правильное» изображение.
CLEAN: алгоритм 1974 года, который все еще работает
В 1974 году Ян Хегбом из Гронингенского университета предложил гениально простой алгоритм. Он называется CLEAN, и его до сих пор используют — в том числе одна из команд EHT.
Идея в следующем: предположим, что небо состоит из множества точечных источников. Если это так, то можно итеративно «выковыривать» их из грязного изображения.
def clean(dirty_image, dirty_beam, gain=0.1, threshold=1e-3, max_iter=10000):
residual = dirty_image.copy()
components = np.zeros_like(dirty_image)
for _ in range(max_iter):
# 1. Найти самый яркий пиксель в остатке
peak_pos = np.unravel_index(np.argmax(np.abs(residual)),
residual.shape)
peak_val = residual[peak_pos]
# 2. Если он сравним с шумом — стоп
if np.abs(peak_val) < threshold:
break
# 3. Записать долю этого пика как «найденный точечный источник»
components[peak_pos] += gain * peak_val
# 4. Вычесть из остатка эту долю, свернутую с грязным пучком
residual -= gain * peak_val * shifted(dirty_beam, peak_pos)
# 5. Свернуть найденные компоненты с «чистым пучком» — обычно гауссиан
return convolve(components, clean_beam) + residual
Что здесь происходит:
- мы предполагаем, что в самом ярком пикселе действительно сидит точечный источник;
- также мы знаем, как один точечный источник выглядит после свертки с PSF — он выглядит как сам PSF, сдвинутый в эту точку;
- мы вычитаем небольшую долю этого «теоретического вклада» из изображения;
- повторяем тысячи раз;
- в конце свертываем найденный список точечных источников с чистым (гауссовым) пучком — получаем «правильно размытое» изображение, где артефакты грязного пучка убраны.
CLEAN — алгоритм жадный. Он работает потому, что для типичных радиоастрономических картинок (несколько ярких квазаров на пустом небе) предположение «все состоит из дельта-функций» оказывается отличной аппроксимацией.
Для тени черной дыры — уже совсем не так. Поверхность яркости вокруг M87* гладкая, ассимметричная, с кольцевой структурой. Хотя CLEAN все равно работает, но требует вариантов и тонкой настройки. Поэтому EHT использует и кое-что поновее.
Альтернатива — байесовский подход
Мы хотим найти такое изображение I, которое (а) согласуется с измерениями и (б) удовлетворяет нашим представлениям о том, что такое «разумная картинка».
Формально, минимизируем:
L(I) = χ²(I, V_obs) + Σ_k λ_k · R_k(I)
Первое слагаемое — это правдоподобие: насколько изображение согласуется с измеренными видимостями.
χ²(I, V_obs) = Σ_(u,v) |V_model(u, v) − V_obs(u, v)|² / σ²(u, v)
где V_model — Фурье-преобразование текущего изображения I, посчитанное в тех точках, где мы намерили.
Второе слагаемое — это регуляризаторы. Их обычно несколько, и они кодируют априорные предположения. Самые ходовые в EHT:
Гладкость: R_TV(I) = Σ |∇I| — штрафует резкие переходы.
Разреженность: R_ℓ₁(I) = Σ |Iᵢ| — штрафует ненужные ненулевые пиксели.
Энтропия (MEM): R_MEM(I) = −Σ Iᵢ · log(Iᵢ / mᵢ) — заставляет изображение быть «как можно более похожим на дефолтную модель m при равных χ²».
Положительность: I ≥ 0 — отрицательной яркости не бывает.
Коэффициенты λ_k — гиперпараметры, которые нужно настраивать.
Слепые команды
У вас есть набор измерений с базовых линий. У вас есть алгоритм с десятком гиперпараметров. У вас есть ожидание того, как должна выглядеть тень черной дыры (ОТО предсказывает асимметричное кольцо такого-то размера, симуляции GRMHD дают конкретный профиль яркости).
Что произойдет, если крутить ручки регуляризаторов до тех пор, пока картинка не «станет похожа на ожидаемое»? Правильно — она станет похожа на ожидаемое. И в науке такой подход очень рискован.
Команда EHT поступила красиво. Они разбились на четыре независимые группы. Каждая получила одни и те же данные, но не имела права обсуждать промежуточные результаты с другими группами. Группы использовали разные пайплайны и разные настройки гиперпараметров:
- DIFMAP с CLEAN — классика, написанная еще в 90-е;
- eht-imaging — RML на Python, разработанный командой Гарварда;
- SMILI — независимая RML-имплементация, в основном японская;
- внутри RML-команд — разные комбинации регуляризаторов.
Четыре группы работали параллельно семь недель. Только после этого они встретились и сравнили результаты.
Все четыре получили оранжевый бублик. С одним и тем же диаметром (~40 микросекунд дуги), с одной и той же асимметрией яркости (южная сторона ярче — следствие релятивистского эффекта вращающейся плазмы), с теневой структурой в центре. Это и есть основание утверждать: то, что вы видите на «фото», — не артефакт алгоритма. Четыре независимые имплементации дают один и тот же результат.
Если бы у одной команды получилось одно, у другой — другое, у третьей — третье, то статью бы просто не выпустили.
3,5 петабайт самолетом
Теперь о приземленном. Каждая станция EHT пишет четыре канала (две поляризации × две боковые полосы) с двухбитной оцифровкой. Грубая прикидка потока с одной станции:
4 ГГц × 2 (Nyquist) × 2 бита × 2 поляризации = 32 Гбит/с
С полным стеком из четырех Mark 6 в тандеме станция выходит на 64 Гбит/с агрегатной записи. За семь ночей наблюдений в апреле 2017 года с восьми телескопов так и набрались те самые ~3,5 петабайта.
Передать это по интернету тогда было физически невозможно. Гигабитный канал тащил бы эти данные больше года. Даже 10-гигабитный — больше месяца, а у Южного полюса никаких 10 Гбит и в помине не было (там и сейчас спутниковый узкий канал).
Поэтому данные писали на массивы Mark 6 — стойки с десятками жестких дисков. Стойки физически грузили в самолеты и везли в два корреляционных центра: Хейстекскую обсерваторию (MIT) и Институт радиоастрономии Макса Планка в Бонне.
С Южного полюса диски лететь не могли восемь месяцев — там антарктической зимой ничего не садится и не взлетает. Ученые сидели в Бостоне и Бонне с 7/8 данных и ждали лета в Антарктиде.
Когда диски наконец прилетели, их прогнали через корреляторы — специализированные компьютеры, которые сводят сигналы со всех восьми станций и для каждой пары вычисляют ту самую видимость V(u, v) в куче временных окон. После корреляции 3,5 петабайта сжимаются до условных «гигабайт точек на (u, v)-плоскости с погрешностями». Уже эти гигабайты стали входом для CLEAN и RML.
Кстати, это классический пример теоремы Таненбаума: «никогда не недооценивайте пропускную способность универсала, набитого магнитными лентами и едущего по шоссе». 3,5 петабайта за неделю на самолете — это в среднем около 46 Гбит/с непрерывного потока. Никакой кабель из Антарктиды этого не даст.
Это не фотография
Теперь можно вернуться к началу.
Знаменитое изображение M87 — это численное решение обратной задачи I_dirty = I_true * B_dirty. С регуляризацией, кодирующей физически разумные предположения о небе. На входе у которого — 28 наборов точек на (u, v)-плоскости, полученных корреляцией сигналов с восьми разнесенных антенн. И с предобработкой длиной в два года и пятью петабайтами исходных данных.
Если бы у вас был глаз диаметром с Землю, чувствительный на 1,3 мм, и вы посмотрели бы в сторону Девы — вы увидели бы примерно то же самое. Такого глаза не существует, но его сумели построить, точнее его математический аналог из восьми кусков, разделенных тысячами километров, и решением обратной задачи.
Это не делает картинку менее реальной, просто это другой способ видеть. Половина того, что мы знаем о Вселенной — от первых снимков пульсаров в 60-х до карт реликтового излучения с Planck — получена решением обратных задач разной степени жесткости.
На мой взгляд, EHT — это самый красивый и самый недооцененный пример ,когда четыре независимые команды с четырьмя разными алгоритмами сходятся к одному и тому же результату — это значит, что бублик правда там, в 55 млн световых лет, и весит шесть с половиной миллиардов Солнц.
Вот это и есть фото того года.




