Как проводить сложные исследования в Google Таблицах и Excel? Работаем с формулой QUERY
Рассказываем, как работать с данными и фильтровать их в таблицах по заданным условиям — тем, которые вам нужны.
Привет! Меня зовут Александр, я работаю в отделе пользовательских исследований. Раньше ни один мой рабочий день не проходил без Google Таблиц, теперь продолжаю использовать инструмент только в личных целях. В этой статье объясню, как и какие формулы использовать в таблицах, чтобы работать с большими объемами данных.
Предыстория: почему таблицы, а не Python
Большинство моих задач связаны с таблицами. Они выглядят так: несколько столбцов с данными вроде ID клиента, даты его регистрации в панели управления Selectel, количества серверов и т. д. Чаще всего я составляю всевозможные списки и выгрузки и провожу базовые вычисления, которые можно выполнить всем известными формулами SUM, AVERAGE и др.
Не обходится и без масштабных задач, когда необходимо объединять несколько выгрузок с десятками столбцов и десятками тысяч строк. Например, на одном из этапов аналитики опроса CSAT (о нем, кстати, писала подробнее моя коллега) я встретился с такой ошибкой. Данных оказалось слишком много — документ вырос настолько, что превысил свой максимальный размер в 10 000 000 ячеек.
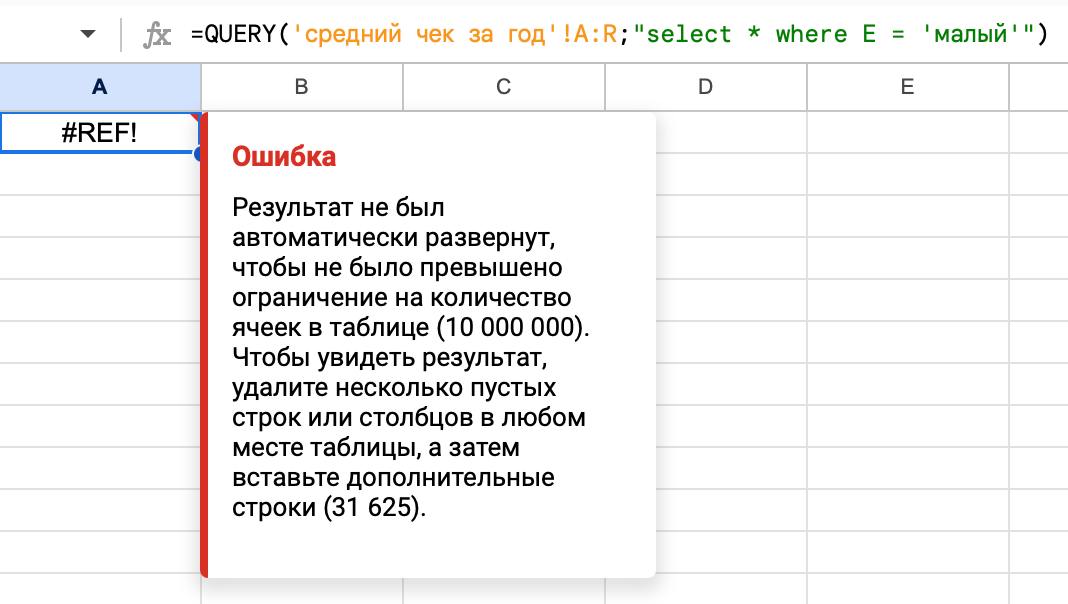
В этот момент я понял, что задачи стали слишком сложные для Excel и Google Таблиц. Была мысль использовать Python или R, но я вспомнил слова друга: «Ты даже не представляешь, какое количество науки делается в простых таблицах». Действительно, у готовых решений есть множество преимуществ перед программистским подходом:
- таблицы доступны всем коллегам,
- для их использования не требуются навыки программирования,
- команда получает мгновенный результат,
- данные легко рассчитывать и визуализировать,
- удобно вводить формулы,
- один документ в Google Таблицах можно использовать совместно всей командой,
- таблицы интегрируются с другими инструментами.
С учетом этих преимуществ я решил, что стоит познакомиться с Google Таблицами еще ближе. При этом я считал себя достаточно продвинутым пользователем площадки: меня не пугали сводные таблицы, вертикальный просмотр (ВПР/VLOOKUP), многоэтажные «ЕСЛИ», импорт таблиц с помощью IMPORTRANGE и работа со статистическими функциями. Я захотел сделать аналитику лучше и удобнее. Расскажу и покажу, что у меня получилось.
Варианты работы с данными в таблицах
Представим, что у вас есть таблица, в которую вы собираете результаты опроса. Опрос все еще активен: новые ответы приходят в таблицу и меняют ее, но предварительные результаты нужны вам уже сейчас. К тому же хочется, чтобы формулы продолжили работать дальше — до окончания опроса. Есть несколько способов решить эту задачу.
| Решение | Недостатки |
| Просмотр результатов с помощью «Данные > Статистика по столбцам» | Только сжатая аналитика |
| Протягивание формул | Формулы могут быть перезаписаны новыми данными; Необходимо перепротягивать для новых данных |
| Копирование таблицы и работа с данными на другом листе документа | Данные не будут обновляться |
Формула QUERY — ключ к поиску нужных данных
QUERY — это формула, написанная на языке запросов. Вы пишете обычную формулу в Google Таблицах (стандартно, начиная со знака “=”), а внутри нее используется язык, похожий на SQL.
Пример:
=QUERY(A1:D6;"select C, A, B order by B desc")Первая часть =QUERY(A1:D6 — это просто функция и выбранный диапазон данных. Вторая часть — тот самый язык запросов. В приведенном примере используются операторы select (выбрать), order by (сортировать по) и ключевое слово desc (обратное направление сортировки).
Покажу на конкретном кейсе. Допустим, вам необходимо создать связанную таблицу с другим порядком столбцов. Данные должны отсортироваться по убыванию значения «Дата регистрации», причем сама дата отображаться не должна.
Применим формулу:
=QUERY(A1:D6;"select D, A, C order by B desc")
Формула вывела таблицу с тремя из четырех имеющихся столбцов: D — «Тип лица», A — «Клиент» и C — «Продукт». Здесь данные отсортированы по столбцу B в обратном порядке — по убыванию. Чтобы отсортировать по возрастанию, нужно удалить desc.
В контексте задачи про опрос и постоянное изменение таблицы, выделение фиксированного диапазона A1:D6 не подходит. Будут учитываться только изменения в области A1:D6. Та же формула выведет такой результат:

Если будет указан диапазон A:D, а данные будут отсортированы по умолчанию (т. е. по возрастанию), получим следующий результат:

Это произошло, потому что были учтены пустые строки, в которых нет данных. Если ключевое слово desc отсутствует, то по умолчанию таблица сортируется по возрастанию. Так как пустая ячейка — наименьшее возможное значение, то оно выводится формулой =QUERY(A:D;”select В, A, С order by B”) в первую очередь.
Чтобы избежать этого, необходимо не учитывать пустые строки в исходной таблице. Этого возможно добиться двумя способами. Первый — просто удалить пустые строки. Новые строки с данными будут добавляться автоматически в конец таблицы. Второй — использовать фильтрацию данных.
Пример:
=QUERY(A:D;"select D, A, C where A is not null order by B")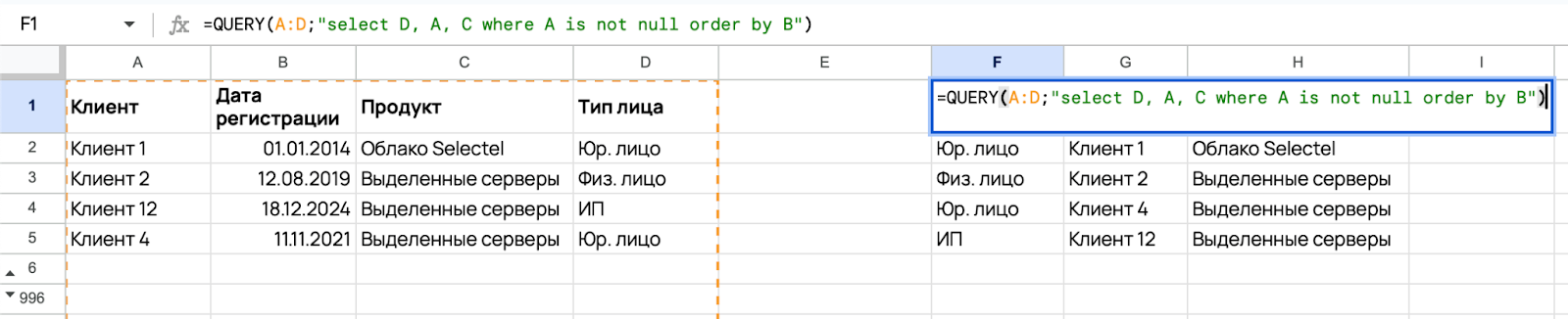
Совет! Используйте защищенные диапазоны, которые нельзя редактировать — это обезопасит вас от случайного удаления данных.
Справка. Защищенные ячейки, листы и диапазоны позволяют запретить другим пользователям редактировать данные. Для этого нажмите Данные > Защитить листы и диапазоны. Выберите Добавить лист или диапазон.
Фильтрация данных
Часто в опросах присутствуют необязательные вопросы. Респондент может пропустить их и оставить без ответа. Чтобы отфильтровать только тех респондентов, кто ответил на вопрос, необходимо использовать ключевое слово WHERE и оператор is not со значением null (полный список ключевых слов — в документации). Так как же работает WHERE?
WHERE
WHERE — оператор в запросе QUERY, который используется для фильтрации строк по заданным условиям.
Он позволяет отфильтровать строки на основе условий, таких как равенство, больше или меньше, и другие логические операторы. WHERE фильтрует строки, которые соответствуют указанным критериям. Если условия не соблюдаются, строки исключаются из результата.
Например, с помощью вот этой формулы была выведена таблица только с теми клиентами, кто ответил на вопрос про опыт использования провайдеров (строки, в которых значение в столбце D было ненулевым, то есть содержащим ответ).
=QUERY(A:D;"select A, C, D where D is not null")Вот что мы получили:

AND и OR
AND и OR — логические операторы, используемые в QUERY для комбинирования условий. Они позволяют создавать сложные условия фильтрации, комбинируя несколько критериев.
AND требует выполнения всех условий, а OR требует выполнения хотя бы одного из условий.
Можно использовать несколько операторов, объединяя их в один запрос. Например, если вы хотите посмотреть список клиентов, которые пользуются облаком Selectel и одновременно с этим не имеют опыта использования других провайдеров — примените следующую формулу:
=QUERY(A:D;"select A, C, D where D is not null and C = 'Облако Selectel'")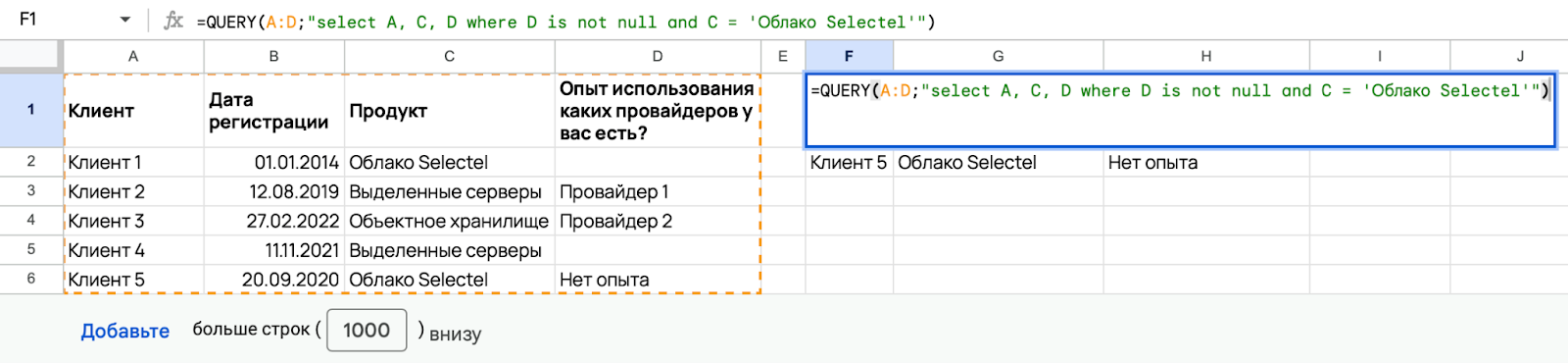
Операторы сравнения
Вместе с «И» и «ИЛИ» используется не только =. Можно подключать и другие операторы:
- больше >
- меньше <
- больше или равно >=
- меньше или равно <=
- не равно !=
Представим, что к таблице выше вы подгрузили данные о выручке за последний месяц. Получили следующее:
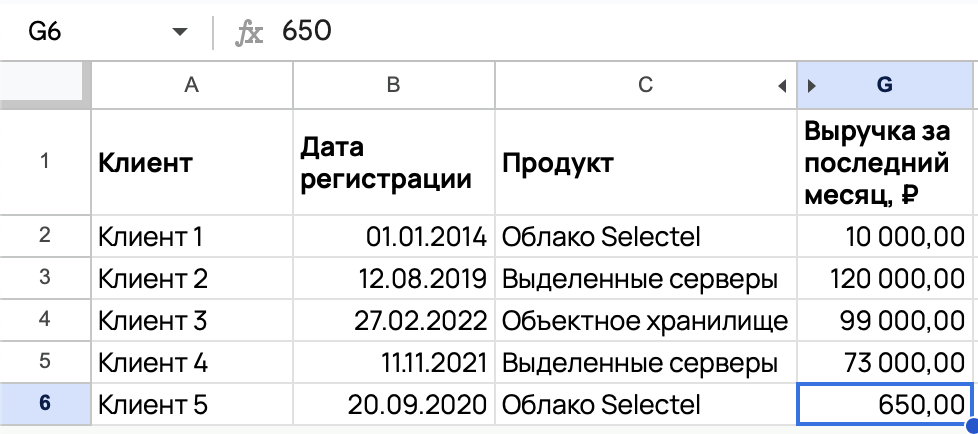
Задача: оставить только тех клиентов, кто пользуется облаком Selectel и имеет выручку за последний месяц больше или равную 10 000 ₽. Воспользуемся формулой:
=QUERY(A:D;"select * where C = 'Облако Selectel' and D >=10000")
Разберем эту формулу:
- select * означает то, что в исходной таблице будут выведены все столбцы;
- where C = ‘Облако Selectel’ — первое условие: клиент пользуется только Облаком Selectel;
- and — объединяет первое условие со вторым;
- D >=10000 — второе условие: выручка за последний месяц больше или равна 10 000 ₽.
А если коллега тоже использует вашу таблицу? Допустим, он пришел, чтобы отфильтровать всех клиентов, выручка которых за последний месяц была больше 50 000 ₽. Но он не знаком с тем, как работает ваша формула. Для этого случая пригодятся внешние ячейки.
Внешние ячейки
Внешние ячейки — любые пустые ячейки, в которых не указаны данные. Их можно использовать в QUERY-запросах для динамического задания параметров фильтрации и сортировки. Ячейки позволяют изменять параметры запроса, не редактируя саму формулу.
Значения из внешних ячеек передаются в QUERY-запрос, и формула обновляется автоматически при изменении содержимого ячеек.
Предположим, вам нужно создать динамическую (интерактивную) таблицу для коллег, которые бы могли отфильтровать данные по условию с произвольным значением. Как из примера выше, когда коллеге нужны все клиенты с выручкой более 50 000 ₽. Для этого нужно просто выбрать ячейку вне диапазона исходной таблицы (в нашем случае, это любая ячейка вне диапазона A:D), в которую каждый, у кого есть доступ к вашему документу, сможет вписать необходимое значение.
Сделаем это с ячейкой F2:
=QUERY(A:D;"select * where D > "&F2)
Примечание. В зависимости от того, какой формат данных вы используете во внешней ячейке, отличается синтаксис формулы. Для числового формата это “&[ячейка], а для текстового ‘“&[ячейка]&”’. Его мы разберем дальше.
Внешние ячейки удобно использовать с раскрывающимися списками, чтобы быстро фильтровать таблицы. Например, в таблице ниже ячейка D1 содержит список из названий продуктов: облако Selectel, выделенные серверы, объектное хранилище и т. д. Чтобы использовать внешнюю ячейку D1, следует добавить ее в формулу QUERY, используя синтаксис ‘”&[ячейка]&”‘.
Пример:
=QUERY(A:C;"select * where C = '"&D1&"'")Формула выше позволяет отфильтровать только тех клиентов, кто использовал выделенные серверы, так как это значение ячейки D1.
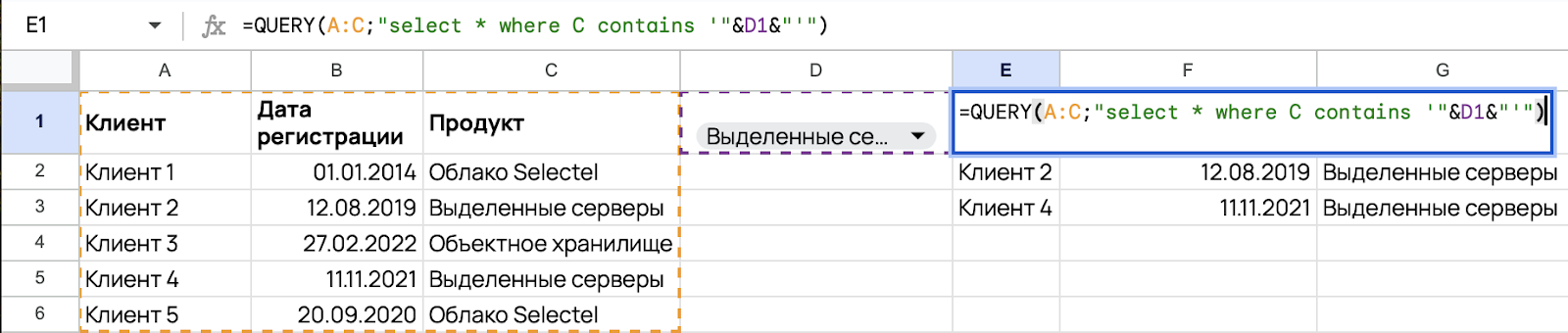
В примере выше логический оператор = ищет строгое соответствие данному значению ячейки. Если в ячейке D1 содержалось бы значение «Выделенные» или «Выделенные серверы», то формула бы не вернула ничего, так как оператор чувствителен к регистру.
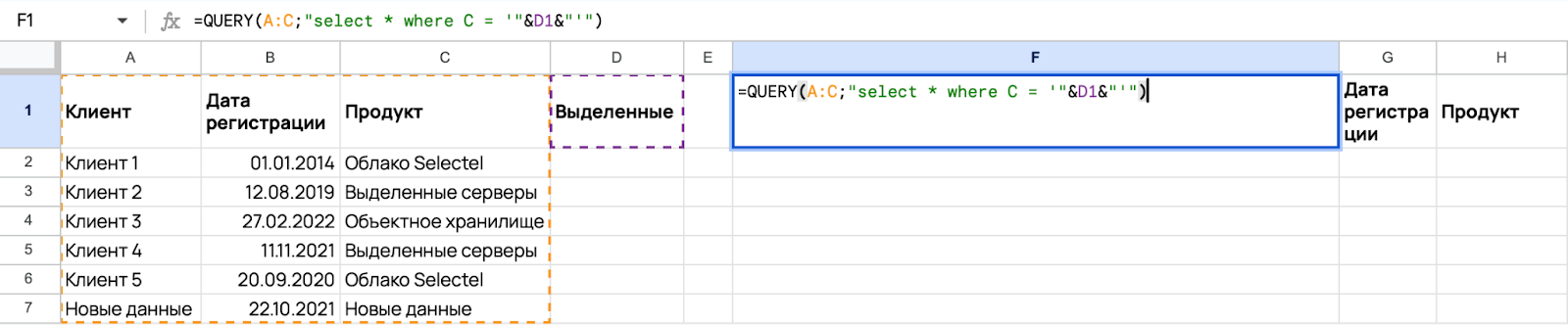
Для нестрогого поиска по тексту следует использовать операторы CONTAINS и LIKE.
CONTAINS и LIKE
Предположим, что вы решили изменить значение ячейки D1 и вписали туда «Облако», чтобы найти клиентов, которые его использовали. Результат будет такой:
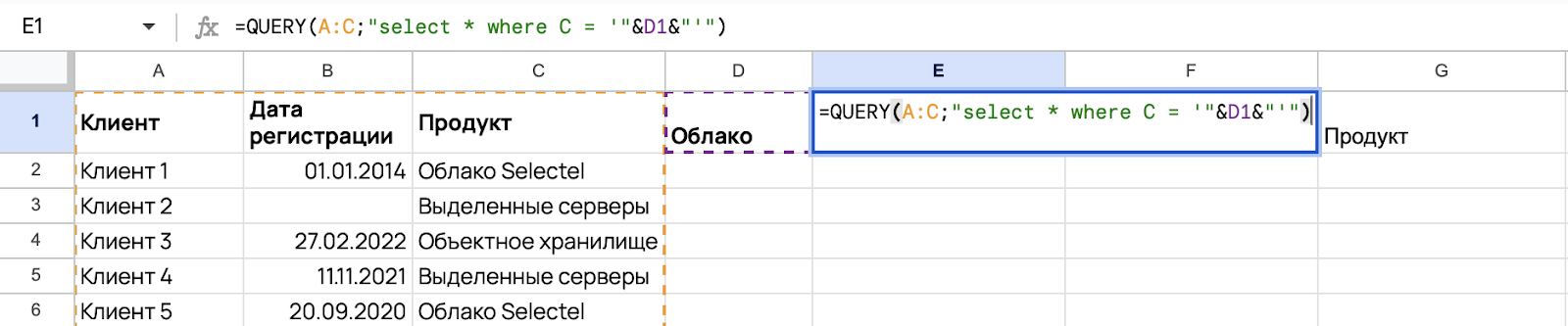
В этом вам помогут операторы CONTAINS и LIKE, которые используются для фильтрации данных в запросах QUERY. Эти операторы позволяют отфильтровать строки по различным критериям, таким как наличие подстроки или соответствие шаблону.
CONTAINS ищет строки, содержащие заданную подстроку, а LIKE используется для поиска по шаблону с использованием подстановочных знаков.
Пример:
=QUERY(A:C;"select * where C contains '"&D1&"'")
Знаки подстановки
Подстановочные знаки, такие как % и _, используются вместе с оператором LIKE для создания шаблонов поиска. Они позволяют искать строки, соответствующие частичному совпадению или определенному шаблону. Знак % соответствует любой последовательности символов, а _ соответствует любому одному символу.
Использование LIKE вместе со знаками подстановки выручит в ситуации с «бэкапами» и «фидбеком» (они же «бекапы» и «фидбэк»).
Простой пример: два клиента оставили фидбек про бэкапы. Этой формулой можно вывести обе строки вне зависимости от написания первой гласной буквы в слове «бэкап»:
=QUERY(A:D;"select * where D like '%б_кап%'")А вот эта формула выведет одно конкретное написание, заданное условием:
=QUERY(A:D;"select * where D contains 'бекап'")Посмотрим вывод формулы:
=QUERY(A:D;"select * where D like '%б_кап%'")
Преимущества использования QUERY для фильтрации данных:
- исходная таблица не изменяется,
- сохраняется структура данных,
- данные обновляются автоматически,
- нет необходимости применять фильтры, которые скрывают часть данных.
После того, как данные отфильтрованы и отсортированы, необходимо их агрегировать, то есть сгруппировать.
Агрегирующие функции
Ни одна из исследовательских и аналитических задач не обходится без арифметических операций, например, когда нужно посчитать среднюю выручку за период или найти количество пользователей определенного продукта. Но и здесь QUERY может прийти на помощь, так как функция поддерживает основные операции: сложение, расчет минимального, среднего и максимальных значений и подсчет количества значений.
Агрегирующие функции предназначены для группировки данных по категориям. Они позволяют обобщать данные, вычисляя общую сумму или среднее значение по столбцам. Категории объединяются и выводится результат арифметической операции.
SUM складывает все значения в указанном столбце, AVG вычисляет среднее значение, COUNT подсчитывает значения, а MAX и MIN ищут максимальное и минимальное значение соответственно. Эти функции, используются вместе с GROUP BY, о которой я расскажу дальше.
Представим, что требуется вывести таблицу, в которой будет подсчитана сумма серверов у клиента (выделенных и облачных вместе). Мы можем воспользоваться формулой =SUM, протянутой до конца нашей исходной таблицы. Двойной нажатие на правый нижний угол ячейки работает только в том случае, если в соседней слева ячейке есть данные. Также можно растянуть формулу на весь столбец, даже если слева есть пустые ячейки, но далеко не все знают, как это сделать (ответ: сочетанием cmd+D и нажатием на стрелку столбца). Но есть способ сделать это с помощью QUERY, понимание которого пригодится нам в дальнейшем для группировки данных.
Пример: вам нужно рассчитать сумму облачных и выделенных серверов для каждого клиента и отсортировать их по сумме серверов.
=QUERY(A:D;"select A, C+D order by C+D")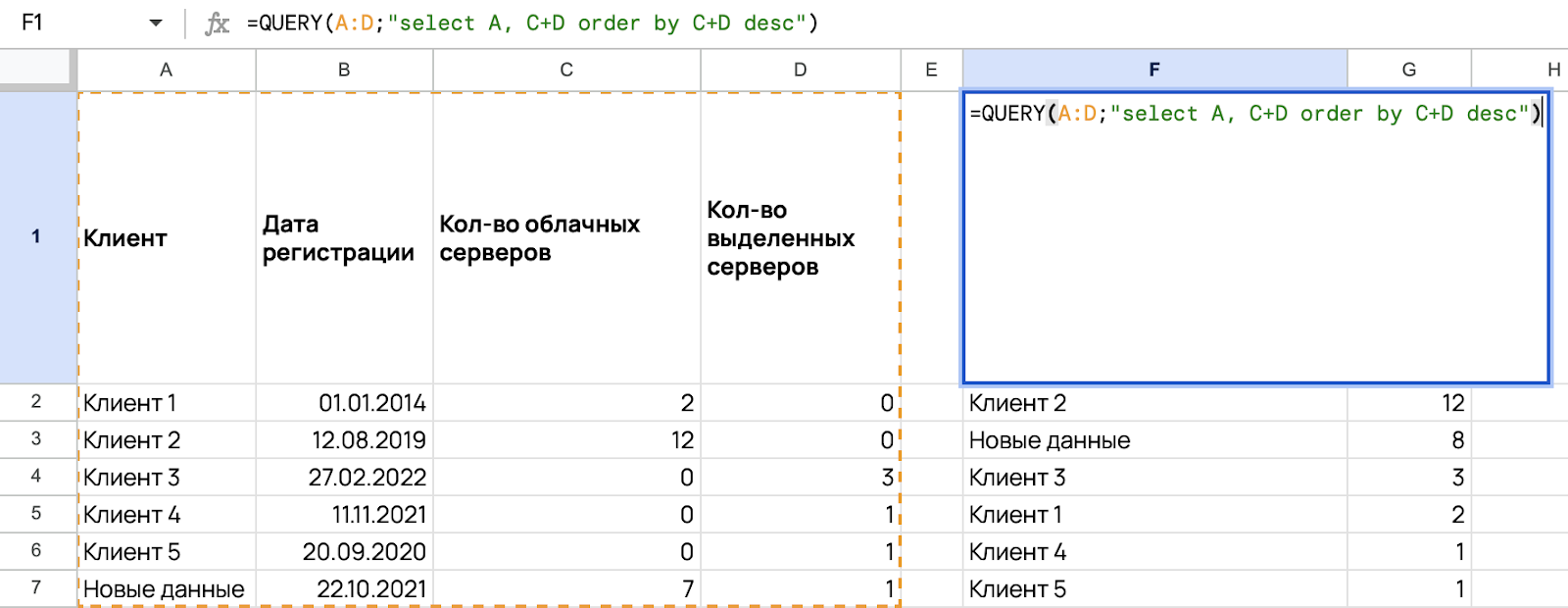
В данном примере C+D является столбцом, в котором и происходит операция сложения.
Также можно вывести несколько столбцов. Достаточно перечислить их через запятую:
SELECT: =QUERY(A:D;"select avg(C), max (C), max(D)")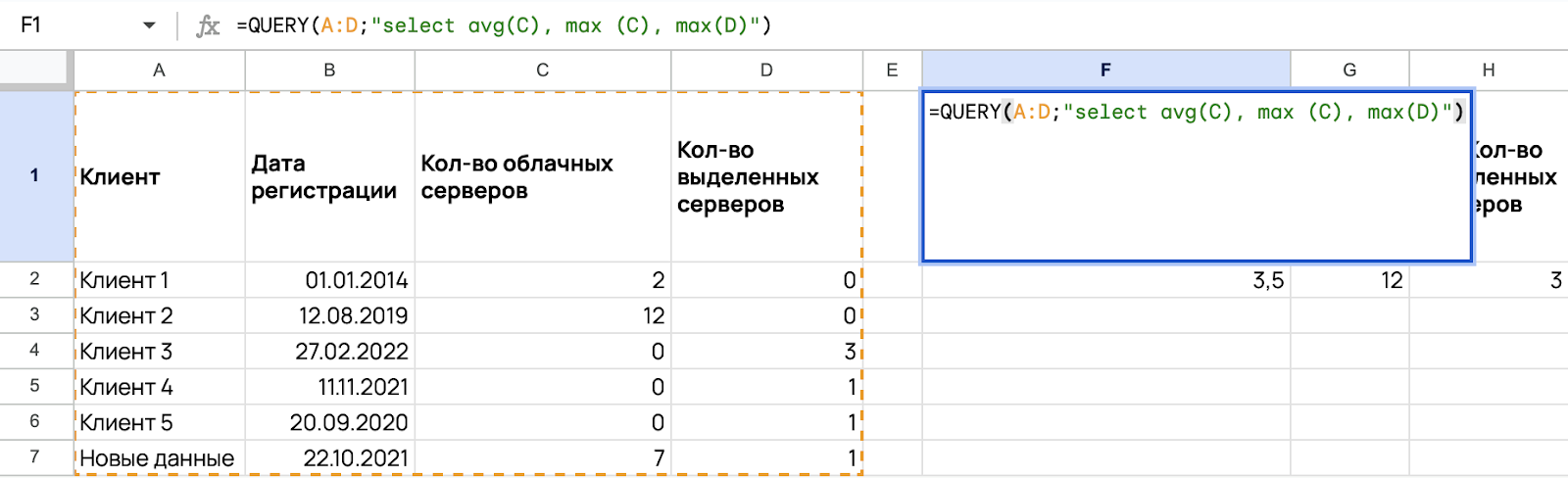
Важное замечание: агрегирующие функции работают только с одним столбцом. Не получится посчитать максимальное значение в двух столбцах.
Это неосновное применение агрегирующих функций. Главное — использование их для группировки данных.
Больше полезных материалов для исследователей
GROUP BY
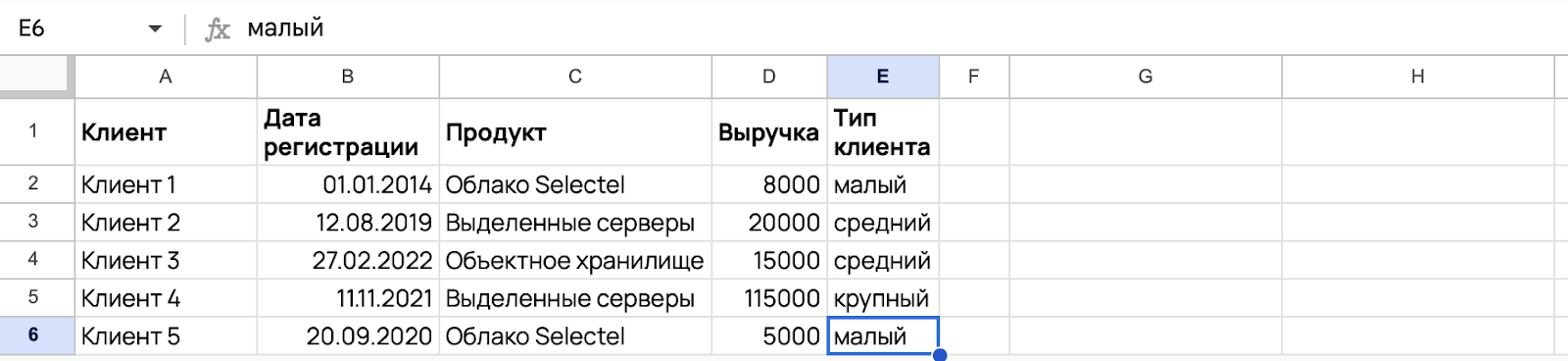
Задача: вы выгрузили данные о выручке клиентов, распределили их по категориям на малых, средних и крупных. Теперь вам нужно найти суммарную выручку по каждой группе.
GROUP BY — оператор в QUERY, который группирует строки с одинаковыми значениями в определенном столбце и позволяет применять агрегирующие функции к этим группам. Он используется для создания сводных данных, таких как общая сумма или среднее значение по группам.
GROUP BY объединяет строки с одинаковыми значениями в указанных столбцах и выполняет агрегирование данных в этих группах.
Чтобы сгруппировать данные, необходимо выбрать столбец со значениями, по которым данные будут объединены (в нашем случае столбец E), указать агрегирующую функцию (например, sum), а также выбрать данные для агрегирования (столбец D). После этого необходимо указать саму группировку group by и столбец, указанный в select (то есть E).
Пример:
=QUERY(A:E;"select E, sum (D) group by E order by sum (D)")
Примечание. В QUERY в Google Таблицах SELECT и GROUP BY могут использовать разные столбцы, но важно помнить, что все столбцы в SELECT, отсутствующие в GROUP BY, должны быть агрегированы.
Объединять данные можно оператором COUNT. Тогда мы найдем количество строк (то есть клиентов), у которых присутствуют значения в указанном столбце.
Пример:
=QUERY(A:E;"select E, count (D) group by E order by count (D)")
Неважно, значения какого столбца будут использоваться для подсчета значений в случае оператора COUNT. Но стоит обращать внимание на отсутствующие значения в столбце. Например, если мы выберем столбец B для COUNT, то строка 3 («Клиент 2») не посчитается.

Заключение
Это лишь небольшая часть возможностей QUERY. Формула значительно расширяет функциональность таблиц. Благодаря этому далеко не всегда нужно переходить к программированию и погружаться в код.
Таблицы обладают большим потенциалом для решения разнообразных задач: от простых расчетов до работы с большими массивами данных и создания автоматизированных отчетов. Уверен, что использование QUERY ускорит ваши рабочие процессы и повысит качество аналитики.