Как развернуть Mistral 7B на GPU-сервере через vLLM
Пошаговая инструкция по развертыванию языковой модели Mistral 7B на облачном GPU-сервере с использованием фреймворка vLLM для создания OpenAI-совместимого API.
В этой инструкции развернем Mistral-7B-Instruct-v0.3 на облачном GPU-сервере и запустим модель через vLLM. На выходе получим инференс-эндпоинт в формате OpenAI-compatible API и проверим его работу запросом из терминала.
Mistral-7B-Instruct-v0.3 — инструкционная версия модели Mistral 7B от Mistral AI. Она предназначена для задач, где модель должна следовать пользовательским инструкциям: отвечать на вопросы, объяснять текст, суммаризировать информацию, генерировать черновики или работать как основа для внутреннего ассистента.
Модель достаточно компактная по меркам LLM: ее удобно использовать для первого self-hosted-развертывания, потому что она не требует нескольких GPU и позволяет быстро проверить полный контур инференса.
В статье мы пройдем путь от создания пустого сервера до первого ответа модели: выберем конфигурацию с одной видеокартой NVIDIA RTX A5000 24 ГБ, проверим, что система видит GPU, подготовим Python-окружение, установим vLLM, запустим модель и отправим тестовый запрос через API.
Сначала соберем воспроизводимый сценарий установки, а после запуска снимем базовые метрики, которые помогают оценить выбранную конфигурацию.
На скриншоте ниже — расчет для одиночного запуска на NVIDIA RTX 3090 24 ГБ. Он нужен как ориентир по требованиям к видеопамяти: при выбранных параметрах модель помещается в 24 ГБ VRAM. В облаке развернем ее на сервере с NVIDIA RTX A5000 24 ГБ и после запуска проверим фактическую занятость VRAM, доступность API, время до первого токена и базовую скорость генерации.

В продакшен-сценариях такая модель может быть основой для прототипа внутреннего ассистента, RAG-сценария, автоматизации поддержки или API для тестовой интеграции. Но в этой статье нас интересует развертывание модели на сервере и первичная техническая проверка того, что инференс-сервис запущен, помещается в выбранную GPU-конфигурацию и отвечает на запросы.
Подбор сервера
Заходим в панель управления Selectel → Продукты → Облачные серверы.

В разделе серверов кликаем на Создать сервер. На странице создания сервера выберите локацию: ru-3b, ru-7a или ru-7b. Актуальную информацию о доступности по локациям можно узнать в документации.
Для запуска нашей LLM нужен сервер с GPU. Основная нагрузка при инференсе будет идти на видеокарту: в ее памяти размещаются веса модели, KV-кэш и служебные структуры инференс-фреймворка. CPU, RAM и диск тоже важны, но в этой задаче они скорее обеспечивают стабильную работу окружения, чем определяют скорость генерации.
Итак, берем сервер с одной NVIDIA RTX A5000 24 ГБ. Ее достаточно для воспроизводимого запуска модели 7B-класса. Да и по предварительному расчету модель помещается в 24 ГБ VRAM.
Прокрутите страницу вниз до выбора конфигурации и перейдите во вкладку GPU.

Для системных ресурсов возьмем 8 vCPU, 32 ГБ RAM. На диске лучше оставить запас.
Помимо операционной системы, место понадобится для Python-зависимостей, кэша Hugging Face, файлов модели и временных файлов, которые могут появляться при установке и первом запуске. Для этой инструкции берем 100 ГБ SSD — этого достаточно для выбранной модели и окружения.
В качестве образа используем GPU Optimized Ubuntu. Такой образ сокращает подготовительный этап: сервер уже создается с окружением, рассчитанным на работу с GPU NVIDIA. После подключения останется проверить видеокарту через nvidia-smi, установить зависимости и запустить vLLM.
Если вы подбираете сервер для продакшен-нагрузки, нужно отдельно учитывать длину контекста, число параллельных запросов, требуемую задержку, пропускную способность, параметры vLLM, prefix caching, формат весов и стоимость одного млн токенов.
Подготовка окружения
После создания сервера подключаемся к нему по SSH:
ssh root@
Проверяем, что сервер видит GPU:
nvidia-smi
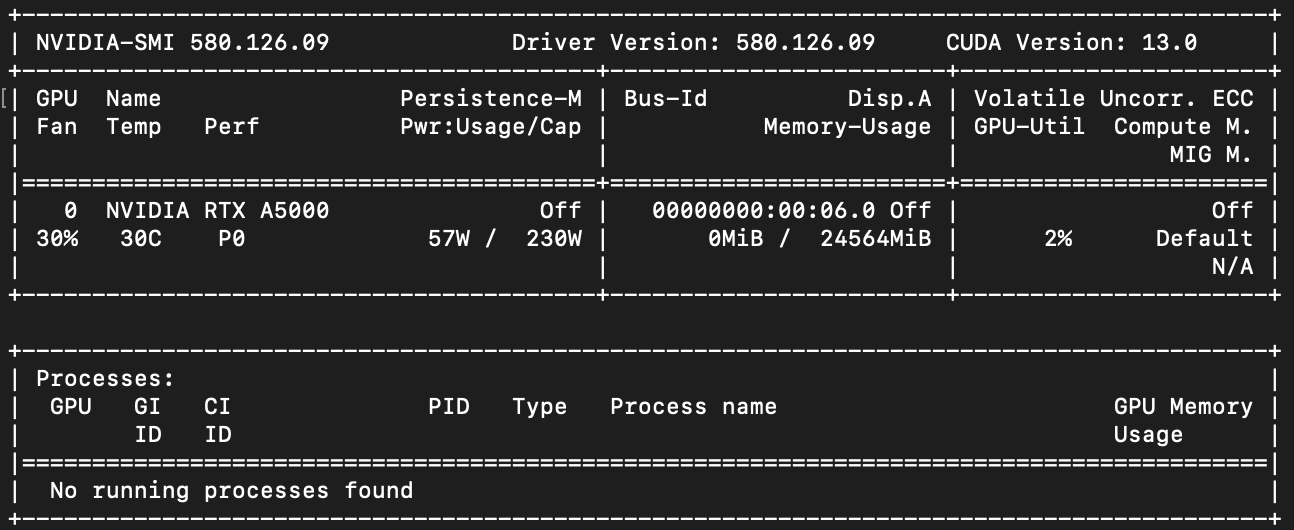
После проверки GPU обновляем системные пакеты. Это снижает риск конфликтов при установке Python-зависимостей и вспомогательных утилит:
apt update && apt upgrade -y
Ставим базовые утилиты:
apt install -y python3 python3-pip python3-venv python3.12-dev build-essential git \
curl htop tmux
tmux пригодится, если позже вы захотите оставить vLLM работать после разрыва SSH-сессии. В этой инструкции запускаем сервер в активном терминале, чтобы видеть логи загрузки модели. Здесь важно не пропустить python3.12-dev и build-essential. При первом запуске vLLM может компилировать вспомогательные CUDA/Triton-модули.
Создаем рабочую директорию:
mkdir -p /opt/mistral-vllm
cd /opt/mistral-vllm
Все дальнейшие команды будем выполнять из директории /opt/mistral-vllm.
Создаем виртуальное окружение:
python3 -m venv venv
source venv/bin/activate
Виртуальное окружение помогает изолировать зависимости vLLM и упростить повторяемость установки.
Обновляем pip командой:
pip install --upgrade pip
Свежая версия снижает вероятность ошибок при установке крупных ML-библиотек и их зависимостей.
Далее ставим vLLM:
pip install vllm
vLLM выбран потому, что он подходит для server-side инференса: умеет эффективно обслуживать запросы к LLM, работать с batching и поднимать OpenAI-compatible эндпоинт.
Создаем переменные окружения
Здесь зададим название модели и API-ключ, которым будем защищать эндпоинт. Ключ можно сгенерировать на сервере и использовать его далее.
export MODEL_ID="mistralai/Mistral-7B-Instruct-v0.3"
export VLLM_API_KEY=$(openssl rand -hex 32)
echo "$VLLM_API_KEY"
Сохраните значение ключа: оно понадобится позже для тестовых запросов.Не публикуйте реальное значение ключа в скриншотах, логах и репозиториях.
Запускаем vLLM
При запуске сразу учтем настройки инференса:
vllm serve "$MODEL_ID" \
--host 0.0.0.0 \
--port 8000 \
--api-key "$VLLM_API_KEY" \
--dtype auto \
--max-model-len 32768 \
--enable-prefix-caching
После запуска команда не должна завершиться. vLLM остается работать в foreground и пишет логи в терминал.
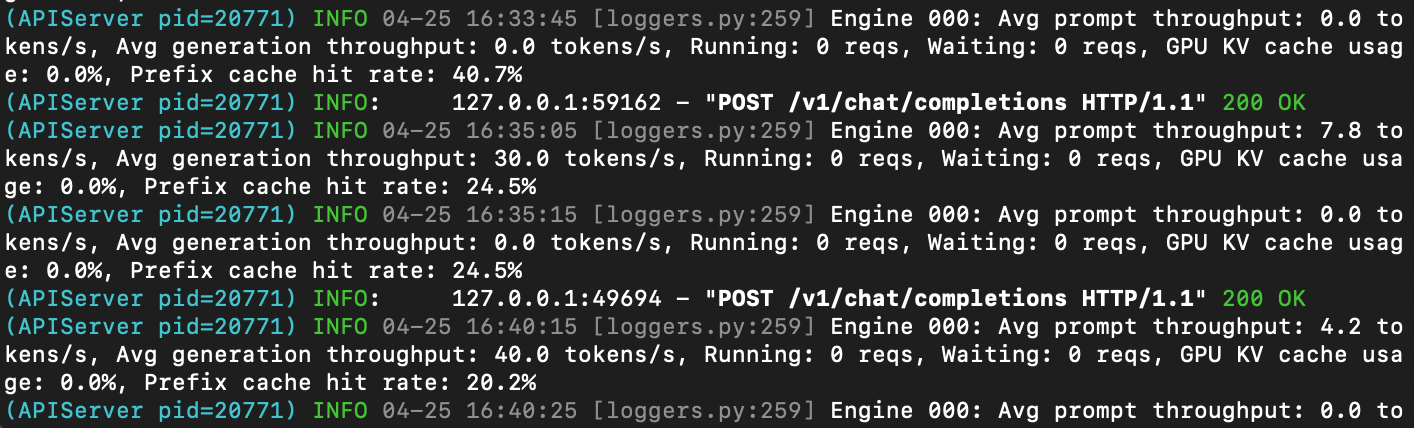
Prefix caching полезен, когда в запросах повторяется большая часть промта: например, один и тот же системный промт, шаблон инструкции или RAG-контекст. Это может снизить накладные расходы на обработку повторяющейся части запроса. Для первого развертывания Prefix caching не обязателен, но мы включаем его сразу, чтобы не упустить типовую оптимизацию.
При запуске vLLM может несколько десятков секунд прогревать модель и создавать KV-кэш. После этого API-сервер становится доступным на порту 8000. В логах в процессе также видна информация о модели:
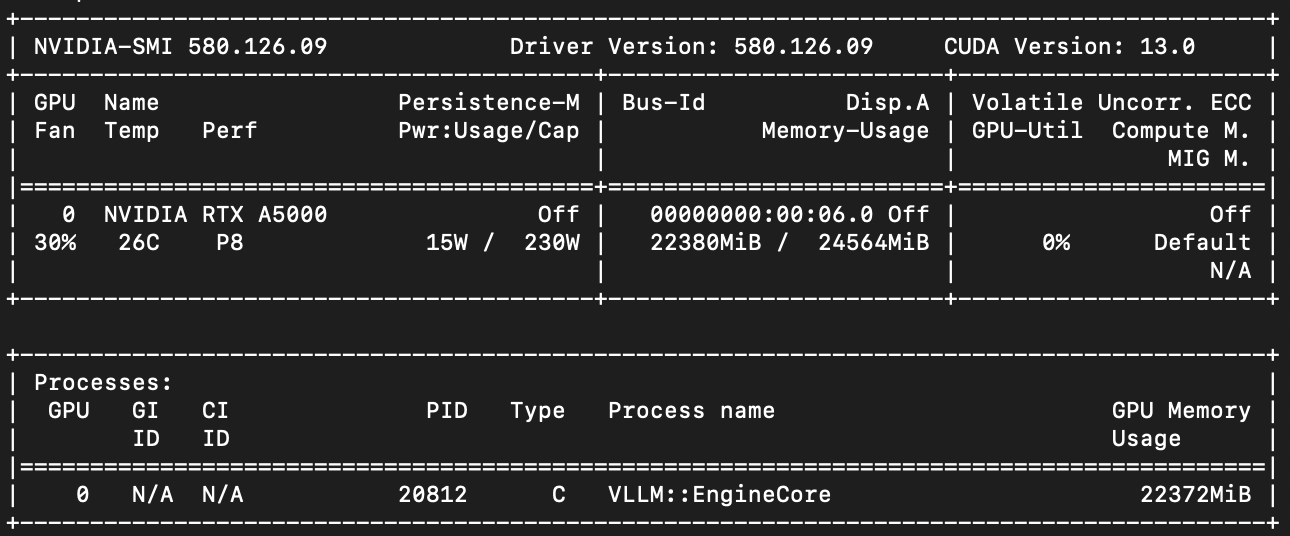
- веса модели заняли 13.51 ГБ памяти GPU;
- доступная память под KV-кэш составила 7,32 ГБ;
- размер GPU KV-кэш — 59 936 токенов;
- максимальная конкурентность для запросов длиной 32 768 токенов — 1,83x;
В отдельном SSH-окне можно проверить GPU:
nvidia-smi
Проверка API-сервера
После запуска vLLM сначала проверим служебный эндпоинт /health:
curl -i http://127.0.0.1:8000/health
Если сервер запущен корректно, в ответе будет статус HTTP/1.1 200 OK. Эта проверка показывает, что API-сервер vLLM поднялся и принимает запросы на порту 8000. После этого можно проверять уже модельный эндпоинт /v1/models.
Проверка, что модель доступна через API
Сначала проверим, что vLLM-сервер видит загруженную модель:
curl -s http://127.0.0.1:8000/v1/models \
-H "Authorization: Bearer $VLLM_API_KEY" | python3 -m json.tool
В ответе должна появиться модель:
Осталось проверить модель тестовым запросом. Создадим файл с запросом:
cat > request.json <<'EOF'
{
"model": "mistralai/Mistral-7B-Instruct-v0.3",
"messages": [
{
"role": "user",
"content": "Return exactly three bullet points that explain what an inference server does."
}
],
"max_tokens": 120,
"temperature": 0
}
EOF
Отправим запрос в эндпоинт /v1/chat/completions:
curl -sS http://127.0.0.1:8000/v1/chat/completions \
-H "Authorization: Bearer $VLLM_API_KEY" \
-H "Content-Type: application/json" \
-d @request.json | python3 -m json.tool
Если все настроено корректно, API вернет JSON с ответом:

Тестируем работоспособность
Для smoke-теста лучше использовать короткий технический запрос на английском языке. Так мы проверяем именно работу инференс-эндпоинта:
- модель загружена,
- OpenAI-compatible API принимает запрос,
- авторизация проходит,
- сервер возвращает сгенерированный ответ.
Оценку качества модели для конкретного языка или бизнес-сценария нужно проводить отдельно — на целевых промтах и данных.
После smoke-теста измерим базовые метрики инференса через streaming-запрос к OpenAI-compatible эндпоинту. Это не полноценный нагрузочный тест, просто контрольный прогон, который показывает порядок метрик для выбранной конфигурации.
| Метрика | Значение |
| GPU | NVIDIA RTX A5000 24 ГБ |
| Модель | mistralai/Mistral-7B-Instruct-v0.3 |
| Контекст модели | 32 768 токенов |
| Prompt tokens | 42 |
| Completion tokens | 200 |
| Total tokens | 242 |
| Total latency | 4.920 сек |
| TTFT | 0,479 сек |
| Decode time | 4,441 сек |
| Output speed (скорость генерации выходных токенов в одиночном запросе) | 45,03 токена/сек |
В этом прогоне модель начала отвечать через 0,479 секунды, а затем сгенерировала 200 токенов за 4,441 секунды. Итоговая скорость генерации составила 45,03 токена/сек.
Заключение
В рамках инструкции результат достаточный: модель помещается в 24 ГБ VRAM NVIDIA RTX A5000 и комфортно себя там чувствует. Эндпоинт стабильно отвечает, а TTFT не превышает секунды. Скорость генерации в районе 45 токенов/сек на одиночном запросе — хороший показатель для конфигурации такого уровня.Этого более чем достаточно, чтобы использовать конфигурацию как тестовый стенд, прототип API или демонстрацию self-hosted LLM.
Конечно, для продакшен-нагрузки и сотен одновременных юзеров потребуется полноценный бенчмарк с параллельными запросами и расчетом стоимости миллиона токенов. Но база для старта у нас уже есть.
А какие модели вы планируете развернуть в облаке в ближайшее время? Если уже пробовали Mistral в связке с vLLM — делитесь своими замерами и впечатлениями в комментариях.