

Разбор будет полезен инженерам и архитекторам, которые выбирают платформу для аналитики и хотят понять, подходит ли облако для аналитических нагрузок на терабайтных объемах данных и как StarRocks ведет себя «вне лаборатории».
Идея развернуть аналитическую базу данных в облаке часто выглядит привлекательно — до того момента, пока администратор не начинает прикидывать реальную нагрузку в продакшене, а бизнес — итоговую стоимость. Именно здесь у многих появляются сомнения, и выбор все чаще смещается в сторону более осязаемых решений — например, выделенной инфраструктуры, где проще заранее оценить пределы производительности и стоимости.
Тестовое окружение и методика
В качестве базового инструмента мы использовали бенчмарк TPC-DS, широко применяемый для оценки аналитических СУБД. При этом фокус тестирования был смещен с попытки продемонстрировать пиковые показатели производительности на практические аспекты эксплуатации: воспроизводимость результатов, стабильность работы кластера, влияние объема данных и характера нагрузки, а также поведение системы при росте параллелизма в рамках фиксированной конфигурации.
Чтобы оценить поведение StarRocks в условиях, максимально близких к рабочим, мы развернули два отдельных стенда в облаке Selectel: один для масштаба TPC-DS 1 ТБ, второй — для 3 ТБ. В обоих случаях использовались типовые конфигурации линейки HighFreq.
Для масштаба 1 ТБ был развернут кластер в конфигурации 3 FE (Frontend) + 30 BE (Backend). Для масштаба 3 ТБ тестировались две конфигурации: 3 FE + 30 BE (для оценки деградации при росте данных без увеличения вычислительных ресурсов) и 3 FE + 60 BE (для анализа масштабирования). При этом требования к ресурсам FE- и BE-узлов подбираются в зависимости от профиля нагрузки и объема данных. Требования к сети также зависят от масштабов системы: в качестве грубой оценки можно ориентироваться на пропускную способность порядка 10 Гбит/с на каждые 100 ТБ данных.
Оба кластера использовали типовые конфигурации линейки без экспериментальных архитектурных решений — такую инфраструктуру можно развернуть «прямо здесь и сейчас». Фронтенд‑узлы (FE) при этом отвечали за подключение клиентов и построение планов запросов, бэкенд‑узлы (BE) — за хранение данных и выполнение вычислений.
Каждый узел кластера был развернут в конфигурации HighFreq (8 vCPU на базе процессоров AMD EPYC 9474F, 32 ГБ оперативной памяти и локальный SSD‑диск объемом 300 ГБ). При этом использование локальных дисков в высокочастотной конфигурации — ключевой фактор для достижения предсказуемо низкой задержки доступа к данным, что критично для аналитических нагрузок.
В линейке HighFreq доступны локальные или сетевые загрузочные диски. В фиксированных конфигурациях доступно от 1 до 64 vCPU, от 2 ГБ до 256 ГБ ОЗУ и от 30 ГБ до 1,5 ТБ локального диска. В произвольных можно выбрать любое соотношение ресурсов до 176 vCPU, 900 ГБ RAM и локальным диском до 2 ТБ. Такие конфигурации подходят для задач, требующих высокой вычислительной производительности и низких задержек, включая базы данных и аналитические системы.
Программное обеспечение и версия StarRocks
В тестировании используется StarRocks Pro версии 3.3.16 — коммерческая платформа для построения корпоративных аналитических хранилищ данных, подготовленная компанией «СР-ТЕХ». В ее основе лежит open-source-СУБД StarRocks той же версии, дополненная компонентами, необходимыми для промышленной эксплуатации: средствами администрирования, управления кластером, мониторинга и поддержки корпоративных сценариев использования. Документация и исходный код базовой open-source-версии StarRocks доступны на официальном сайте проекта.
Серверы кластера работают под управлением CentOS Stream 9. В качестве вспомогательного ПО используем Java 11, Python 3.11, утилиту nmon для мониторинга производительности системы, а также Ansible для управления конфигурацией и развертывания компонентов.
При этом перед тестированием были скорректированы отдельные параметры бэкенд-узлов (лимиты памяти, интервалы очистки и репликации), что соответствует типовой практике эксплуатации аналитических кластеров. Это позволило избежать искажений результатов, связанных с неэффективной утилизацией ресурсов.
Использованные изменения параметров не носили характер глубокой ручной оптимизации и соответствуют типовой практике эксплуатации аналитических кластеров.
Масштабирование кластера и проверяемые конфигурации
В ходе тестирования по умолчанию использовался кластер архитектуры Shared Nothing. Кластер состоит из фронтенд-узлов (FE), отвечающих за подключение пользователей и построение планов запросов, и бэкенд-узлов (BE), выполняющих хранение данных и обработку запросов. Диапазон конфигураций — от 1 FE + 3 BE до 5 FE + 101 BE.
Тестовый кластер разворачивался и масштабировался последовательно — от минимальных конфигураций к более крупным. Для каждой конфигурации проверялись соответствующие масштабы базы данных, что позволяло оценить как производительность, так и поведение системы при росте инфраструктуры.
Конфигурации тестового кластера и масштабы базы данных, которые проверялись в ходе серии тестов:
- создание базового кластера «1 FE + 3 BE» — 8 минут;
- увеличение базового кластера до «1 FE + 10 BE» — 10 минут;
- увеличение кластера «1+10» до «3+30» — 18 минут;
- увеличение кластера «3+30» до «3+60» — 25 минут;
- увеличение кластера «3+60» до «5+101» — 34 минуты.
В рамках кейса, описанного далее, подробно рассматриваются результаты для масштабов 1 ТБ и 3 ТБ, развернутых на фиксированной конфигурации кластера. Более крупные конфигурации использовались для проверки сценариев масштабирования и времени развертывания, но не анализируются по метрикам выполнения запросов.
Подготовка данных
Для тестирования использовался набор TPC-DS — это стандартная методика оценки систем обработки аналитических запросов. Тест имитирует типичную DWH-систему с набором сложных SQL-запросов, которые охватывают широкий спектр бизнес-сценариев: продажи, маркетинг, финансы и т. д.
Масштаб данных
- SF=1000 (1 ТБ) — ~6 млрд строк.
- SF=3000 (3 ТБ) — ~18 млрд строк.
Ниже — фактическое дисковое пространство, занимаемое данными после загрузки в StarRocks Pro с учетом колоночного хранения и сжатия.
| Масштаб | Размер «как есть» | Размер в StarRocks Pro | Коэффициент сжатия |
| 1 ТБ | ~1 000 ГБ | ~305 ГБ | 3.2× |
| 3 ТБ | ~3 000 ГБ | ~950 ГБ | 3.15× |
Сжатие зависит от типов колонок и распределения данных. В рамках теста полученные коэффициенты оказались стабильными и близкими между разными масштабами.
Что и как мы измеряли
При измерениях мы опирались на стандартную методику TPC-DS и использовали как эталонные сценарии выполнения запросов, так и дополнительные эксплуатационные эксперименты, направленные на оценку поведения системы при параллельной нагрузке.
Во всех тестах использовался полный набор из 99 эталонных SQL-запросов TPC-DS без модификаций. Это позволяет корректно сравнивать результаты между разными прогонами и конфигурациями.
В качестве базового ориентира используем Power Test — тест максимальной производительности. В нем запросы TPC-DS выполняются строго последовательно, по одному, без параллелизма. Такой режим позволяет получить чистую картину работы движка и понять, насколько эффективно система исполняет каждый запрос без конкуренции за CPU, память и I/O.
Перед контрольным замером каждый запрос запускается в прогревочном режиме. Это позволяло инициализировать планы выполнения, загрузить метаданные и стабилизировать работу движка перед основным измерением.
Между запросами выдерживалась пауза 500 мс — она использовалась не для «очистки» кэша, а для снижения влияния фоновых процессов и сглаживания накопленных эффектов от предыдущих запусков.
Многопоточные тесты используем для оценки поведения системы под одновременной нагрузкой — в условиях, максимально близких к эксплуатации реального DWH. В таких сценариях несколько пользователей запускают запросы одновременно, при этом каждый из них распределяется по всем бэкенд-узлам кластера. Рост числа параллельных запросов приводит не к локальной перегрузке отдельных узлов, а к увеличению общей нагрузки на кластер — в первую очередь по оперативной памяти и CPU, что особенно характерно для MPP-архитектуры.
При этом задействуем два варианта многопоточных сценариев: полный и короткий. Они различаются по характеру запросов и интенсивности конкуренции за ресурсы. Полный многопоточный тест представляет собой параллельный запуск полного набора из 99 запросов TPC-DS в нескольких потоках (3 и 5). Короткий многопоточный тест построен на подмножестве из 10 «легковесных» запросов (q3, q5, q7, q9, q13, q17, q21, q23, q25, q27).
Эти запросы характеризуются меньшей ресурсоемкостью и быстрым временем выполнения и используются для моделирования интерактивной аналитики — типичной нагрузки от BI-инструментов в рабочее время. Такой профиль нагрузки позволяет оценить поведение системы при всплесках пользовательской активности.
Результаты Power-теста
Power-тест использовался для определения базовой производительности системы — без конкуренции за ресурсы и влияния параллельной нагрузки. На масштабе 1 ТБ результаты были предельно предсказуемыми: общее время выполнения всех запросов практически совпадало между повторными прогонами, а длительность отдельных запросов отличалась незначительно — в пределах естественной вариации планировщика.
Для большинства запросов время выполнения укладывалось в ожидаемые рамки для кластера на виртуальных ресурсах — от долей секунды до нескольких десятков секунд.
Для каждого запроса фиксировалось время выполнения, а также отклонения между повторными прогонами. Полученные значения позволяют оценить как абсолютную скорость выполнения запросов, так и стабильность работы движка.
С полной версией отчета можно ознакомиться на официальном сайте StarRocks Pro. В ней вы найдете в том числе сводные таблицы с результатами Power-теста для каждого масштаба данных.
После Power-теста мы перешли к сценариям, максимально близким к реальной эксплуатации аналитической базы — одновременному выполнению запросов несколькими пользователями. В таких условиях важны не только времена выполнения отдельных SQL-запросов, но и устойчивость кластера в целом: отсутствие сбоев, деградации и неконтролируемого роста времени ответа.
Полный многопоточный тест (TPC-DS)
В этом сценарии каждый поток выполнял полный набор запросов TPC-DS без пауз и предварительного прогрева. Порядок запросов для каждого потока формировался независимо, что исключало синхронизацию по одним и тем же таблицам и лучше моделировало «шумную» рабочую нагрузку.
Масштаб 1 ТБ
На масштабе 1 ТБ при запуске в три потока все запросы выполнились корректно, без ошибок и зависаний. Общее время выполнения выросло по сравнению с Power-тестом, что ожидаемо при конкуренции за CPU и память, однако рост оставался линейным и предсказуемым.
При увеличении параллелизма до пяти потоков завершить тест не удалось: часть запросов перестала укладываться в допустимое время выполнения, из-за чего сценарий был остановлен. При этом важно подчеркнуть, что речь не шла о сбое СУБД или падении кластера — сервисы StarRocks продолжали работать стабильно.
Результат указывает, что при конфигурации кластера 3 FE + 30 BE и ограниченном объеме ОЗУ на каждом BE‑узле увеличение числа параллельных потоков приводило к росту времени выполнения запросов. При планировании производственной конфигурации для «терабайтных» объемов имеет смысл закладывать увеличенный объем ОЗУ на BE‑узел и масштабировать именно их число, тогда как FE можно оставлять более компактными по ресурсам.
Даже один тяжелый аналитический запрос может утилизировать ресурсы кластера практически полностью. При увеличении параллелизма это приводит к ожидаемой деградации производительности: сначала близкой к линейной, а при достижении пороговых значений — к нелинейному падению. Основная причина — нехватка оперативной памяти: промежуточные данные перестают помещаться в ОЗУ, и система начинает активно использовать диск. Дополнительно растут накладные расходы на переключение между задачами, что в пределе может приводить к отказам в обслуживании отдельных запросов.
Масштаб 3 ТБ
На наборе данных объемом 3 ТБ наблюдалась схожая картина. Линейное масштабирование сохранялось примерно до 60 BE-узлов, после чего прирост производительности на каждый добавленный узел снижался.
При конфигурации свыше 60 BE эффективность начала падать из-за роста сетевых обменов и ограничений пропускной способности. Средняя фактическая загрузка сети составляла 6–7 Гбит/с на узел, поскольку узлы активно обмениваются данными по принципу «все со всеми».
В конфигурации 101 BE удельная производительность узла снизилась примерно до 60% от базового уровня. Таким образом, предел эффективной параллельности в инфраструктуре находился на уровне около 60 рабочих узлов. Этот результат ожидаем: при трехкратном росте объема данных конфигурация кластера оставалась прежней, без увеличения числа BE-узлов или объема оперативной памяти.
Недавно в облаке Selectel появилась линейка серверов с поддержкой сети 10 Гбит/с. Такие конфигурации подходят для высоконагруженных веб‑приложений и аналитических систем, где важна высокая пропускная способность при передаче больших объемов данных.
Короткий многопоточный тест
Чтобы отдельно оценить поведение системы при большом числе быстрых аналитических запросов, мы использовали короткий многопоточный тест на подмножестве из десяти SQL-запросов TPC-DS. Эти запросы имеют относительно малое время выполнения и часто встречаются в интерактивной аналитике.
На масштабе 1 ТБ кластер стабильно отрабатывал при 3 и 5 потоках, с незначительным ростом среднего времени выполнения. При 10 потоках нагрузка заметно возрастала, однако StarRocks Pro продолжал обслуживать запросы без сбоев: время ответа увеличивалось, но оставалось управляемым.
Аналогичная картина наблюдалась и на масштабе 3 ТБ. Даже при увеличенном объеме данных кластер выдерживал короткий многопоточный сценарий: при 3 и 5 потоках — стабильное выполнение, при 10 — рост времени ответа без деградации сервиса или остановки запросов.
Этот сценарий показал, что StarRocks лучше масштабируется на коротких аналитических запросах. Ключевая причина — существенно меньшее потребление оперативной памяти на запрос. Низкая доля промежуточных данных и отсутствие тяжелых агрегаций позволяют выполнять большее количество параллельных потоков в рамках фиксированного объема ОЗУ на BE-узлах.
После тестов мы вынесли часть наблюдений и в отдельный практический разбор. 31 марта проведем вебинар, где подробно покажем, как ведет себя аналитическая СУБД в облаке при росте нагрузки — с графиками утилизации CPU, памяти и сети.
Вебинар будет полезен дата-инженерам, архитекторам и DevOps/SRE-инженерам, которые проектируют или уже эксплуатируют аналитические системы. После него будет проще оценить, как спланировать инфраструктуру и избежать лишних затрат на масштабирование.
Что показали тесты в целом
Собранные результаты позволяют сделать несколько практических выводов. СУБД стабильно работает в облачной инфраструктуре Selectel без глубокой ручной оптимизации параметров, а производительность в Power-тесте оказывается предсказуемой и хорошо воспроизводимой между прогонами.
При увеличении числа параллельных запросов в рамках фиксированной конфигурации рост времени выполнения был связан с общей нагрузкой на кластер — в первую очередь по CPU и оперативной памяти бэкенд-узлов. Это особенно заметно в сценариях с тяжелыми аналитическими запросами, тогда как интерактивная аналитика с короткими SQL-запросами демонстрировала более устойчивое поведение под нагрузкой.
Ресурсы кластера во всех сценариях намеренно оставались неизменными, что позволило зафиксировать пределы конкретной конфигурации и понять характер деградации при росте нагрузки. Тесты показали, что система сохраняет стабильность и предсказуемость поведения даже при достижении этих пределов, что важно при планировании дальнейшего масштабирования.
Что получилось в реальности: инженерные наблюдения
Помимо числовых метрик, тесты позволили посмотреть на поведение кластера в типовой облачной среде — под разной нагрузкой и на разных объемах данных.
Наблюдение 1. Кластер вел себя предсказуемо во всех сценариях: от Power-теста до пиковых многопоточных запусков. Не наблюдалось падений FE- или BE-сервисов, повторных выборов лидера или необходимости ручного вмешательства. Даже в сценариях, где нагрузочный тест не завершался, кластер оставался рабочим и доступным.
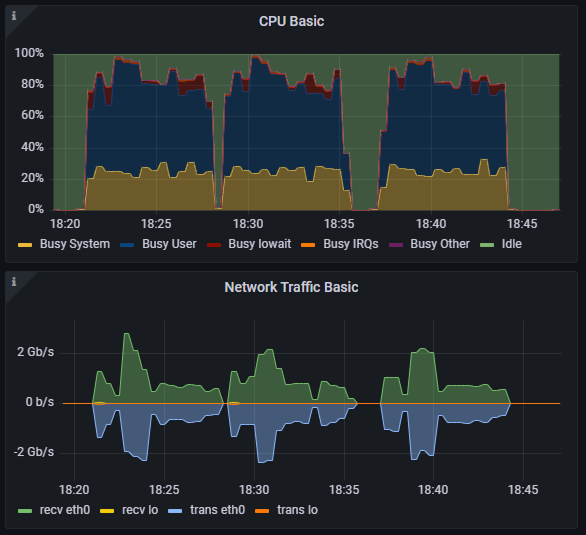
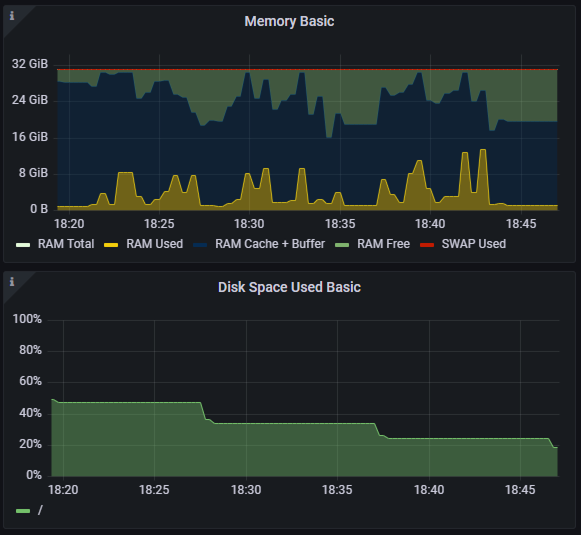
память и свободное место на диске.
Наблюдение 2. Узкое место — ресурсы BE-узлов, а не планировщик. Рост времени выполнения при увеличении числа потоков был напрямую связан с конкуренцией за CPU и память на бэкенд-узлах. Признаков деградации планировщика запросов или проблем с распределением задач между узлами зафиксировано не было — система упиралась именно в доступные ресурсы.
Наблюдение 3. Характер нагрузки критичен. Тяжелые запросы с большими JOIN и агрегациями масштабируются заметно хуже, чем короткие аналитические запросы. Это хорошо видно на разнице между полным и коротким многопоточными тестами: даже на объеме 3 ТБ интерактивные запросы выполнялись устойчиво, без деградации сервиса.
Наблюдение 4. Сжатие данных соответствует ожиданиям. Фактический размер хранилища оказался в 3–3,2 раза меньше исходного объема данных. Это важно учитывать при планировании дискового пространства и стоимости облачной инфраструктуры, особенно на терабайтных масштабах.
Итоги: можно ли строить большое хранилище в облаке и что учесть
Результаты тестирования показывают, что StarRocks подходит в качестве основы аналитического хранилища в облаке на стартовых и растущих объемах данных. Облако хорошо работает в ситуациях, когда хранилище еще развивается: профиль нагрузки не до конца сформирован, а требования к параллелизму меняются со временем. В таких условиях возможность быстро масштабировать вычислительные ресурсы важнее, чем максимальная эффективность на пике.
На раннем этапе важно закладывать не минимально возможную, а «минимально разумную» конфигурацию. Даже для терабайтных объемов данных кластер должен включать несколько бэкенд-узлов с достаточным объемом памяти — иначе система очень быстро упрется в конкуренцию за ресурсы при росте числа пользователей. Полученные в тестах значения сжатия (около 3×) позволяют точнее планировать дисковое пространство, но не отменяют необходимости закладывать запас.
С точки зрения архитектуры StarRocks предусматривает два режима работы:
- Shared Nothing — классическая MPP-архитектура DWH с локальным хранением данных на BE-узлах;
- Shared Data — режим с разделяемым объектным хранилищем (S3-совместимым), где вычислительные узлы (CN) масштабируются независимо от хранения.
На раннем этапе часто выгоднее использовать подход с разделяемым хранилищем. Он снижает стартовые затраты: хранение остается в объектном слое, а вычислительные узлы можно масштабировать независимо — например, добавлять ресурсы только на период пиковых нагрузок или сложных аналитических задач. Это особенно актуально при нерегулярном профиле запросов.
По мере роста и стабилизации нагрузки логика меняется. Если кластер большую часть времени работает близко к высокой загрузке, архитектура Shared Nothing обеспечивает более предсказуемую производительность и стоимость за счет локальности данных и меньших сетевых накладных расходов. В этом режиме проще контролировать задержки и поведение тяжелых запросов.
Возможность выбирать между этими моделями в рамках одной СУБД — редкий для индустрии случай. Это позволяет адаптировать архитектуру под фазу развития проекта, не меняя технологический стек.
При этом важно помнить, что облако — не универсальное решение. Когда суммарный объем оперативной памяти кластера начинает измеряться десятками терабайт, нагрузка становится стабильной, а требования к задержкам — жесткими, экономический и инженерный баланс постепенно смещается в сторону bare metal. На таких масштабах собственная инфраструктура часто оказывается проще в управлении и выгоднее по стоимости.
Независимо от выбранной платформы, ключевым фактором остается понимание собственной нагрузки. Разница между короткими интерактивными запросами и тяжелыми аналитическими джобами в тестах оказалась принципиальной — и это именно тот момент, который стоит учитывать заранее, еще на этапе проектирования хранилища.
Что это значит для инженерных команд
Если рассматривать StarRocks как основу аналитического хранилища в облаке, из этого кейса можно вынести несколько практических рекомендаций.
1. Начинайте с простой конфигурации
Даже базовый кластер из нескольких FE- и BE-узлов позволяет получить предсказуемую производительность и понять реальный профиль нагрузки. На старте важнее наблюдаемость и управляемость системы, чем попытка сразу угадать идеальную конфигурацию.
2. Разделяйте сценарии нагрузки
Интерактивная OLAP-аналитика с короткими запросами и тяжелые batch-отчеты ведут себя по-разному и по-разному масштабируются. Смешивать такие сценарии в одном кластере без расчета и ограничений — рискованно, особенно при росте числа пользователей.
3. Опирайтесь на ресурсы и качество запросов, а не на ручной тюнинг
В ходе тестирования StarRocks показал стабильную работу на дефолтных настройках — без необходимости глубокой ручной оптимизации параметров. Это одно из ключевых преимуществ системы по сравнению с аналитическими СУБД, где производительность сильно зависит от тонкой настройки.
При этом на практике критичную роль по-прежнему играет план выполнения запросов и их структура: даже одна неудачно сформированная аналитика может создать избыточную нагрузку. Важно держать основной фокус на достаточном объеме ресурсов BE-узлов и корректной модели аналитических запросов, а не на попытках компенсировать нехватку ресурсов настройками.
4. Планируйте объем хранилища с учетом сжатия
Фактический размер данных в StarRocks значительно меньше исходных объемов за счет колоночного хранения и сжатия. В тестах коэффициент составил около 3×, однако даже в этом случае необходим запас по дисковому пространству. Минимальный ориентир — не менее 20% сверх расчетного объема данных: на перекосы распределения и spill-файлы в архитектуре Shared Nothing. В режиме Shared Data дополнительно закладывают до 20% локальных дисков под кэши и те же spill-файлы.
В режиме Shared Data при хранении данных в S3 рекомендуется использование глобального роутера для обеспечения сетевой связанности compute и storage через локальную сеть. Такой подход даст производительность канала до 25 ГБ/с вместо стандартных 3-5 ГБ/с при доступе к S3 через интернет.
5. Проверяйте систему под своей нагрузкой
TPC-DS хорошо показывает общую картину и позволяет сравнивать конфигурации, но реальные запросы почти всегда отличаются от эталонных. Перед выходом в продакшн стоит прогнать собственные сценарии и убедиться, что система ведет себя ожидаемо именно под вашей нагрузкой.
При построении аналитических систем важно учитывать не только характеристики СУБД и вычислительных узлов, но и особенности сетевой инфраструктуры. В частности, для StarRocks критична локальность памяти: размещение ресурсов виртуальной машины в пределах одной NUMA-ноды снижает задержки доступа к памяти и повышает общую производительность за счет более высокой пропускной способности.
Сетевая подсистема начинает играть заметную роль при росте масштабов и интенсивности обмена данными. В ряде сценариев (например, при загрузке данных) сеть может становиться узким местом. При выполнении запросов StarRocks стремится минимизировать межузловое взаимодействие, однако на масштабах в десятки терабайт пропускной способности 10 Гбит/с может быть недостаточно.
Дополнительно на производительность влияет настройка MTU: для аналитических систем часто используется Jumbo Frames, что позволяет снизить накладные расходы при передаче больших объемов данных.В ходе тестирования тестирования также потребовалась дополнительная настройка сетевых параметров при участии технической поддержки Selectel, что показало важность ранней оптимизации инфраструктуры.




