Как работать с сетевыми дисками для выделенных серверов

Введение
Ранее я писал статью о базовых операциях в кластере Ceph — она как раз родилась в процессе работы над продуктом.
Наши клиенты используют выделенные серверы в самых разных сценариях. Некоторые из них сложно реализовать в распределенных и масштабируемых системах без постоянного сетевого хранилища высокой производительности. Вот несколько примеров:
- виртуализация,
- оркестрация контейнеров и приложений,
- обучение и хранение ML‑моделей.
Сегодня индустрия предлагает для преодоления вышеназванных ограничений вендорные системы хранения данных (СХД) и различные программно-определяемые альтернативы.
Использование вендорных СХД привносит ряд сложностей и ограничений. Прежде всего сказывается высокая стоимость владения такими системами из‑за затрат на приобретение оборудования, расходов на его обслуживание, обновление и поддержку. Масштабирование продуктов на базе вендорных СХД может быть затруднено из-за особенностей их архитектуры и производительности.
Также привязанность к политике вендора в силах привести к дополнительным рискам изменения условий сотрудничества или к прекращению поддержки. Потенциально такая неоднозначность способна негативно отразиться на наших клиентах. Мы, как сопровождающие инженеры, также сталкиваемся со спецификой инструментов вендора и его системой взаимодействия с потребителями.
Если говорить об SDS (Software-Defined Storage, программно-определяемое хранилище), то Ceph — это уже стандарт в индустрии. Наша компания накопила огромный опыт в проектировании и поддержке больших кластеров. Еще недавно мы использовали Ceph как бэкенд для хранения данных в облачной платформе и объектном хранилище. А теперь встречайте — «Сетевые диски для выделенных серверов», с полным доступом к настройкам из панели управления Selectel.
Кластер Ceph легко масштабируется, а также обеспечивает высокую отказоустойчивость в рамках одного региона и тройную репликацию данных внутри самого кластера. Хороший обзор — в статье «Знакомство с хранилищем Ceph в картинках».
Архитектура продукта
Правильная концепция для нас — предоставлять доступ в клиентскую сеть кластера Ceph только внутри полностью контролируемой инфраструктуры. По этой причине с выделенных серверов клиентов прямой допуск до RBD‑образов невозможен. Для решения в том числе и этой проблемы в Ceph есть утилиты ceph-iscsi и ceph-nvmeof. Их можно запустить рядом с кластером и предлагать клиентам доступ по одноименным протоколам.
Ceph-NVMeoF — способ допуска к хранилищу Ceph RBD (RADOS Block Device) через протокол NVMe over Fabrics (NVMe-oF). Компонент дает более высокую производительность и меньшую задержку при взаимодействии с блочным устройствам Ceph.
Сейчас Ceph-NVMeoF только-только вышел из беты, а сама технология пока еще не очень распространена. Не все дистрибутивы Linux поддерживают его «из коробки», при этом компонент требует версии ядра не ниже 4.16.
С помощью утилиты ceph-iscsi мы настраиваем пограничника — iSCSI Gateway. Хост с сервисом является клиентом кластера с политикой ограниченного доступа, причем находится внутри контролируемой нами части инфраструктуры. Со стороны же клиента конфигурируется iSCSI Target.
iSCSI Target — это экспортируемый в SAN‑сеть объект iSCSI, у которого есть настраиваемые свойства, такие как:
- имена участников iSCSI — IQN;
- список LUN — перечень объектов внутри iSCSI Target;
- данные для аутентификации: Initiators ACL и CHAP.

Взглянем на общую схему.
Если проводить аналогию с классическими СХД, то наш iSCSI Gateway — это программно определяемый контроллер СХД. Коллеги знают, что обычно у СХД два контроллера, два блока питания, а также по два и более сетевых интерфейсов. Дублирование необходимо для обеспечения надежности. Блочное устройство должно оставаться доступным и в случае профилактического обслуживания оборудования, и при нештатных ситуациях — например, при потере питания на одном из вводов или отказе сегмента сети.
Мы научились гарантированно запускать минимум по два экземпляра iSCSI Gateway для анонса iSCSI Target на разных хостах, стойках и наборе сетевых устройств, чем и обеспечивается отказоустойчивость.
SAN‑сеть
Мы подобрались к самой сложной части — к сети. Пришлось продумать и осуществить два действия.
1. Для продукта потребовалось построить новую сетевую плоскость, чтобы гарантировать производительность, отказоустойчивость и независимость сетевого стека. Далее кроме интернета и локальной сети необходимо было обеспечить связность в сети хранения данных.
Работы были масштабные, поэтому новая услуга доступна пока только в ограниченном количестве регионов. При этом поддерживаются все произвольные конфигурации серверов и некоторые фиксированные:
- готовые конфигурации серверов с тегом «Можно подключить сетевые диски»;
- серверы произвольной конфигурации с подключением к SAN‑сети сетевых дисков 10 Гбит/с и дополнительной сетевой картой 2×10 GE, которую можно добавить как при заказе нового сервера, так и при апгрейде уже существующего.
2. На этапе проектирования нужно было решить вопрос сетевой изоляции клиентов, чтобы избежать потенциального пересечения адресации как внутри продукта, так и между сетями потребителей. Мы заложили возможность выбора сетевой адресации самим клиентом, аналогично другому нашему продукту — глобальному роутеру.

Существенные особенности в решении проблемы изоляции клиентов:
- сеть обмена данными построена по классической схеме — Leaf‑Spine,
- каждый сервер подключается к паре коммутаторов фабрики,
- каждый iSCSI Gateway соединяется с одним из коммутаторов фабрики.
Таким образом, мы получаем четыре сегмента сети для обеспечения работы двух независимых маршрутов:
- две связи «коммутатор — выделенный сервер»,
- две связи «коммутатор — iSCSI Gateway».
Используя VxLAN‑маршрутизацию, соединяем выделенный сервер и iSCSI Gateway:

Проблема пересечения сетей решилась следующим образом. Как упомянуто выше, клиент может прямо из панели управления предоставить нам свободную сеть размерностью /20, которая не будет пересекаться с текущей адресацией внутри его инфраструктуры.
В примере я взял сеть 10.130.128.0/20, которая делится на четыре подсети размером /22 для каждого сегмента SAN-сети:
10.130.128.0/22— «левая» подсеть iSCSI-Gateway,10.130.132.0/22— «правая» подсесть iSCSI-Gateway,10.130.136.0/22— «левая» подсеть выделенного сервера,10.130.140.0/22— «правая» подсесть выделенного сервера.
Затем из каждой подсети /22 выделяем подсети /30 для связи хостов с сетевой фабрикой.
Таким образом мы можем масштабировать инициаторы и таргеты, имея предсказуемую адресацию и простые статические маршруты, сохраняя достаточную гибкость для клиентов.
Пример конфигурации netplan на выделенном сервере:
eth2:
addresses:
- 10.130.136.2/30
routes:
- to: 10.130.128.0/22 # левая подсеть iSCSI-Gateway
via: 10.130.136.1 # адрес порта коммутатора
eth3:
addresses:
- 10.130.140.2/30
routes:
- to: 10.130.132.0/22 # правая подсеть iSCSI-Gateway
via: 10.130.140.1 # адрес порта коммутатораПри желании можно использовать ECMP, чтобы дополнительно зарезервировать сетевую связность. К сожалению, netplan в данный момент не поддерживает такую возможность. Ниже — пример настроек вручную:
root@server:~# ip r
---
10.130.128.0/22
nexthop via 10.130.136.1 dev eth2 weight 1
nexthop via 10.130.140.1 dev eth3 weight 1
10.130.132.0/22
nexthop via 10.130.136.1 dev eth2 weight 1
nexthop via 10.130.140.1 dev eth3 weight 1Внимательный читатель заметит, что iSCSI Gateway подключены только по одному пути к SAN‑сети. Это сделано намеренно, так как если хост выводится в обслуживание или происходит авария на оборудовании, экземпляр iSCSI Gateway остановит работу вне зависимости от количества линков. Отказоустойчивость же диска в этом случае обеспечивается инструментами многопутевого доступа multipath.
Такой подход, с одной стороны, позволяет экономить дорогостоящие порты 100 Гбит/с на сетевом оборудовании. С другой — избежать использования дополнительных интерфейсов на каждом хосте (например, двух сетевых карт), что привело бы к увеличению затрат на оборудование. Все это приводило бы к снижению плотности установок в стойках.
Мы выбрали решение, которое максимизирует эффективность использования и сетевых ресурсов, и физического пространства. На первый взгляд может показаться, что затратность портов и дополнительных хостов сопоставима. В действительности же экономия достигается благодаря совокупному эффекту: и оптимизации сетевой инфраструктуры, и плотности размещения оборудования.
Компоненты iSCSI и совместное использование.
iSCSI — это транспортный протокол, который инкапсулирует SCSI‑команды внутри IP‑сети. Вспомним некоторые термины.
- iSCSI Initiator — тот, кто устанавливает соединение с target. В нашем случае это выделенный сервер, который осуществляет ввод‑вывод на блочное устройство.
- iSCSI Target — в зависимости от контекста target’ом называют или целиком экспортирующий узел iSCSI Gateway, или только экспортируемый объект (при этом сам он может делиться на LUN-ячейки).
- Портал — группа целей (targets), которые анонсируются вместе. Чаще всего один узел хранения — один портал. Настраивая подключения к набору target’ов через совокупность порталов, обеспечивается многопутевой доступ (multipath).
- IQN — полное имя участника iSCSI. И у инициатора, и у цели должно быть задано обязательно.
- LUN (Logical Unit Number) — номер объекта внутри цели (target). Ближайшим аналогом является раздел диска или отдельный том.
Для доступа к логическим томам (LUN) хосты-инициаторы объединяются в группы. В рамках одного целевого устройства хранения (target) можно предоставлять как общий набор LUN для группы хостов через несколько сетевых адресов (порталов), так и отдельные LUN для каждого конкретного хоста.
Основные сценарии использования:
- виртуализация: для группы нод compute предоставляется одной или несколькими LUN‑ячейками;;
- контейнеризация: LUN подключается к каждой воркер-ноде и используется как локальный volume или persistent volume через CSI‑драйвер;
- резервное копирование данных: LUN подключается к одному или нескольким хостам и работает как долговременное сетевое хранилище;
- запуск тестовых сред и временных проектов.
Использование iSCSI в Proxmox
Установка и настройка кластера Proxmox останется за рамками статьи — инструкций в интернете множество. Мы же сосредоточимся на подключении узлов кластера к СХД по протоколу iSCSI. Пакет multipath возьмет на себя заботу об отказоустойчивости.
СХД требует определенных параметров для идентификации и авторизации подключающихся узлов: IP-адреса целевых порталов, IQN (iSCSI Qualified Name) инициаторов и целевых устройств, значения для аутентификации CHAP и тому подобное). Они предоставляются системой администрирования СХД, а вы сможете найти их в панели управления Selectel.
Следующие действия необходимо выполнить буквально на каждом узле кластера.
1. Установить пакеты open-iscsi (для подключения серверов к СХД) и multipath-tools (для балансировки соединений с использованием нескольких путей).
2. Настроить в сети SAN IP‑адресацию и статические маршруты (для трафика iSCSI):
ssh root@node1 "cat /etc/networking/interfaces"
---
auto eth2
iface eth2 inet static
address 10.130.136.2/30
up ip route add 10.130.128.0/22 via 10.130.136.1 dev eth2
auto eth3
iface eth3 inet static
address 10.130.140.2/30
up ip route add 10.130.132.0/22 via 10.130.140.1 dev eth3
ssh root@node2 "cat /etc/networking/interfaces"
---
auto eth2
iface eth2 inet static
address 10.130.136.6/30
up ip route add 10.130.128.0/22 via 10.130.136.5 dev eth2
auto eth3
iface eth3 inet static
address 10.130.140.6/30
up ip route add 10.130.132.0/22 via 10.130.140.5 dev eth3
ssh root@node3 "cat /etc/networking/interfaces"
---
auto eth2
iface eth2 inet static
address 10.130.136.10/30
up ip route add 10.1130.128.0/22 via 10.130.136.9 dev eth2
auto eth3
iface eth3 inet static
address 10.130.140.10/30
up ip route add 10.130.132.0/22 via 10.130.140.9 dev eth33. Настроить параметры iSCSI:
## Настраиваем имя iSCSI Initiator для node1 (для других узлов IQN будет отличаться)
ssh root@node1 'echo "InitiatorName=iqn.2001-07.com.ceph-uuid1:node1" > /etc/iscsi/initiatorname.iscsi'
## Настриваем параметры iscsi в файле /etc/iscsi/iscsid.conf.
## Большиство парметров имеют значения по умолчанию, но они должны быть определены.
## Необходимо настроить:
## Авторизацию CHAP (node.session.auth.*)
## Режим подключения к таргету (node.startup)
## Выставить наивысший приоритет (node.session.xmit_thread_priority)
## Увеличить глубину очереди комманд (node.session.queue_depth)
root@node1:# cat /etc/iscsi/iscsid.conf
node.startup = manual
node.leading_login = No
node.session.auth.authmethod = CHAP
node.session.auth.username = MyUserName
node.session.auth.password = My-Password!
node.session.timeo.replacement_timeout = 120
node.conn[0].timeo.login_timeout = 15
node.conn[0].timeo.logout_timeout = 15
node.conn[0].timeo.noop_out_interval = 5
node.conn[0].timeo.noop_out_timeout = 5
node.session.err_timeo.abort_timeout = 15
node.session.err_timeo.lu_reset_timeout = 30
node.session.err_timeo.tgt_reset_timeout = 30
node.session.initial_login_retry_max = 8
node.session.cmds_max = 128
node.session.queue_depth = 64
node.session.xmit_thread_priority = -20
node.session.iscsi.InitialR2T = Yes
node.session.iscsi.ImmediateData = Yes
node.session.iscsi.FirstBurstLength = 262144
node.session.iscsi.MaxBurstLength = 16776192
node.conn[0].iscsi.MaxRecvDataSegmentLength = 262144
node.conn[0].iscsi.MaxXmitDataSegmentLength = 0
discovery.sendtargets.iscsi.MaxRecvDataSegmentLength = 32768
node.session.nr_sessions = 1
node.session.iscsi.FastAbort = Yes
node.session.scan = auto4. Минимальные настройки для multipath следующие:
root@node1:# cat /etc/multipath.conf
defaults {
user_friendly_names yes
find_multipaths yes
}
blacklist {
}5. Перезапускаем сервисы iscsid и multipath:
root@node1:# systemctl restart iscsid.service multipathd.service6. Если все сделано правильно, мы можем подключиться к таргету:
## Отправляем запрос discovery к одному из порталов.
## В ответ получим «карту» таргетов и порталов.
root@node1:# iscsiadm -m discovery -p 10.130.132.2 -t st
## Подключаемся к таргету, который получили выше.
root@node1:# iscsiadm -m node --targetname iqn.2003-01.com.redhat.iscsi-gw:iscsi-gw --login
## В результате мы увидим в ОС блочное устройство /dev/mapper/mpathX
root@node1:# lsblk
---
sdc 100G disk
└─mpatha 100G mpath
sdd 100G disk
└─mpatha 100G mpath 7. Теперь необходимо настроить сетевой диск в самом Proxmox. Добавляем информацию о нашем хранилище в файл /etc/pve/storage.cfg или настраиваем из WebUI:
root@node1:# cat /etc/pve/storage.cfg
iscsi: sharedstorage
portal 10.130.132.2
target iqn.2003-01.com.redhat.iscsi-gw:iscsi-gw
content images
nodes node-3,node-1,node-2
lvm: iscsi-lvm
vgname iscsi-lvm-group
base sharedstorage:0.0.0.scsi-36001405200260da0c384df9a483c517a
content images,rootdir
saferemove 0
shared 1Вот и все! Диск подключен к каждой из трех нод кластера. Можно запускать виртуальные машины, но прежде давайте разберемся, как же организуется соединение серверов и СХД по iSCSI в связке с multipath. Внимания заслуживают следующие моменты.
1. В Proxmox для работы общего LVM используется LVM2 с механизмом блокировок.
2. По умолчанию применяется Locking Type 1 (Clustered Locking), который обеспечивает координацию изменений через кластерный менеджер (в данном случае — Corosync/Proxmox Cluster Manager). Такой подход позволяет гарантировать, что только один узел в кластере может модифицировать структуру LVM в любой момент времени.
3. На общем сетевом диске создается Physical Volume (PV), Volume Group (VG) и Logical Volumes (LV). Когда узел Proxmox подключается к iSCSI и сканирует диски, он находит общий VG по его метаданным. Утилита vgscan сканирует все доступные диски и обновляет локальную информацию о VG. Все узлы видят одинаковый набор VG и LV, поскольку они читают общие метаданные.
Узлы в кластере Proxmox могут создавать и удалять LVs в общем VG.
4. Благодаря кластерным блокировкам, изменения на одном узле синхронизируются с другими узлами.
Далее можно создать виртуальную машину и указать, что ее виртуальный диск будет храниться на iSCSI‑диске. На этом шаге подробно останавливаться не будем — приведем только ее настройки (все значения оставляем по умолчанию, кеширование отключено):
root@node-1:# cat /etc/pve/nodes/node-1/qemu-server/100.conf
boot: order=scsi0;ide2
cores: 4
cpu: x86-64-v2-AES
ide2: none,media=cdrom
memory: 4096
meta: creation-qemu=9.0.2,ctime=1738082340
net0: virtio=BC:24:11:ED:5D:3A,bridge=vmbr100
numa: 0
ostype: l26
scsi0: iscsi-lvm:vm-100-disk-0,iothread=1,size=32G
scsihw: virtio-scsi-single
smbios1: uuid=ebaa87bb-31d8-49be-a5ea-5848afda98a5
sockets: 1
vmgenid: dd0a2b83-b725-47c0-a948-b0098667cfcfТак как диск сетевой, мы можем без даунтайма мигрировать ВМ на соседний хост. Посмотрим:
root@node-1:# qm migrate 100 node-2 --online
Requesting HA migration for VM 100 to node node-2
2025-01-29 13:17:39 starting migration of VM 100 to node 'node-2' (31.129.41.46)
2025-01-29 13:17:39 starting VM 100 on remote node 'node-2'
2025-01-29 13:17:41 start remote tunnel
2025-01-29 13:17:42 ssh tunnel ver 1
2025-01-29 13:17:42 starting online/live migration on unix:/run/qemu-server/100.migrate
2025-01-29 13:17:42 set migration capabilities
2025-01-29 13:17:42 migration downtime limit: 100 ms
2025-01-29 13:17:42 migration cachesize: 512.0 MiB
2025-01-29 13:17:42 set migration parameters
2025-01-29 13:17:42 start migrate command to unix:/run/qemu-server/100.migrate
2025-01-29 13:17:43 migration active, transferred 113.2 MiB of 4.0 GiB VM-state, 111.4 MiB/s
2025-01-29 13:17:44 migration active, transferred 224.8 MiB of 4.0 GiB VM-state, 113.3 MiB/s
2025-01-29 13:17:45 migration active, transferred 337.2 MiB of 4.0 GiB VM-state, 111.2 MiB/s
...
2025-01-29 13:17:57 migration active, transferred 1.6 GiB of 4.0 GiB VM-state, 125.1 MiB/s
2025-01-29 13:17:58 migration active, transferred 1.8 GiB of 4.0 GiB VM-state, 111.7 MiB/s
2025-01-29 13:17:59 migration active, transferred 1.9 GiB of 4.0 GiB VM-state, 113.3 MiB/s
2025-01-29 13:18:00 average migration speed: 228.5 MiB/s - downtime 23 ms
2025-01-29 13:18:00 migration status: completed
2025-01-29 13:18:03 migration finished successfully (duration 00:00:25)Обратим внимание на строку:
2025-01-29 13:17:43 migration active, transferred 113.2 MiB of 4.0 GiB VM-state, 111.4 MiB/sОна говорит о переносе состояния памяти с хоста на хост. Процесс выполнялся медленно, так как кластер у меня настроен на работу по локальной сети с пропускной способностью 1 Гбит/с. Тем не менее, даунтайм по вводу‑выводу составил 23 мс, что, судя по dmesg, не привело к ошибкам на виртуальной машине.
Посмотрим на показатели производительности. На данный момент мы применяем QoS со стороны Ceph и ориентируемся, что можем гарантировать клиентам следующие значения:
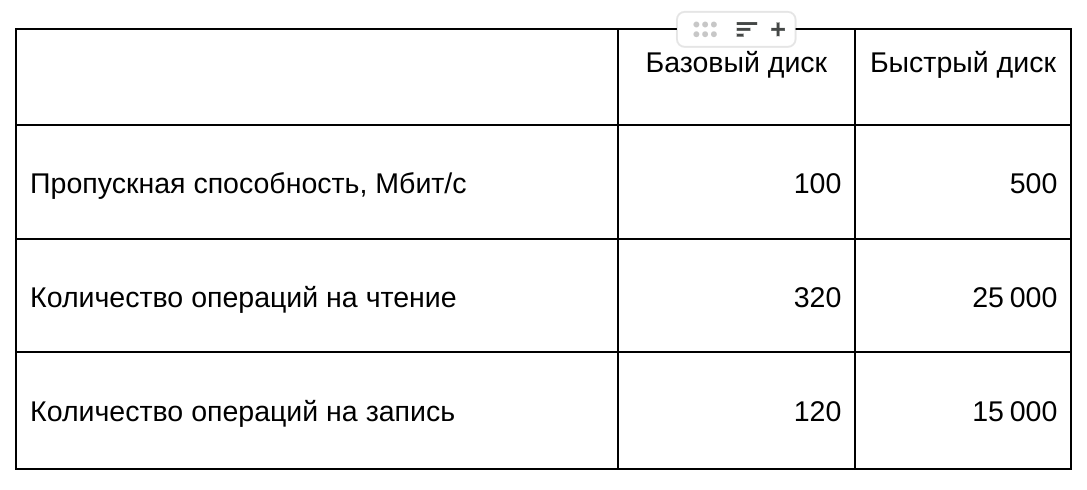
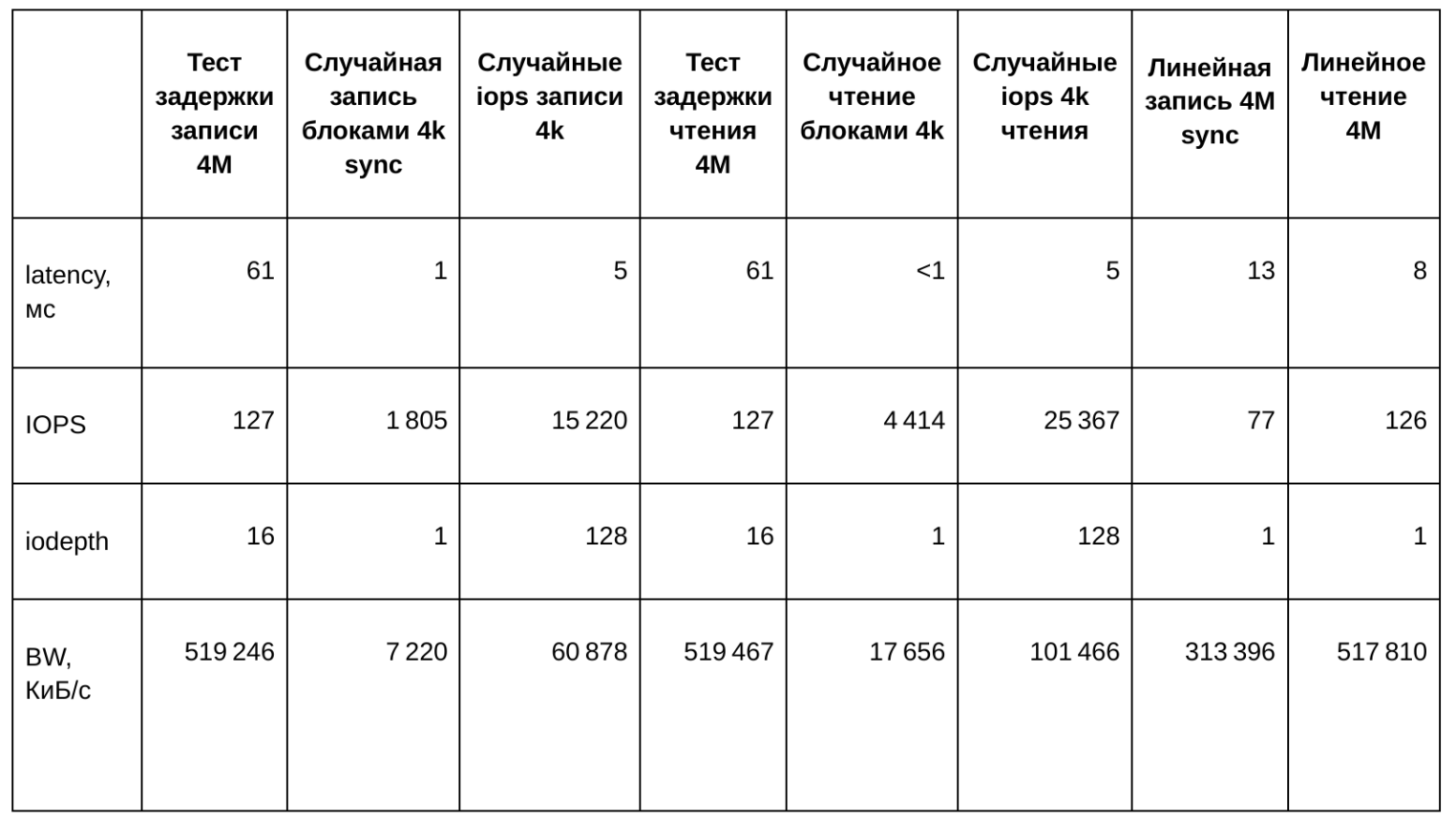
Протестируем диск виртуальной машины:
"Latency test\nwrite 4M": "sudo fio -ioengine=libaio -direct=1 -name=write16 -bs=4M -iodepth=16 -rw=write -runtime=60 -filename=/mnt/testfile --output-format=json",
"Random write\nblocks of 4k sync": "sudo fio -ioengine=libaio -direct=1 -name=randwrite -bs=4k -iodepth=1 -sync=1 -rw=randwrite -runtime=60 -filename=/mnt/testfile --output-format=json",
"Random IOPS\nwrite 4k": "sudo fio -ioengine=libaio -direct=1 -name=randwrite128 -bs=4k -iodepth=128 -rw=randwrite -runtime=60 -filename=/mnt/testfile --output-format=json",
"Latency test\nread 4M": "sudo fio -ioengine=libaio -direct=1 -name=read16 -bs=4M -iodepth=16 -rw=read -runtime=60 -filename=/mnt/testfile --output-format=json",
"Random read\nblocks of 4k": "sudo fio -ioengine=libaio -direct=1 -name=randread -bs=4k -iodepth=1 -rw=randread -runtime=60 -filename=/mnt/testfile --output-format=json",
"Random IOPS\nread 4k": "sudo fio -ioengine=libaio -direct=1 -name=randread128 -bs=4k -iodepth=128 -rw=randread -runtime=60 -filename=/mnt/testfile --output-format=json",
"Sequential write\n4M sync": "sudo fio -ioengine=libaio -direct=1 -name=write -bs=4M -iodepth=1 -sync=1 -rw=write -runtime=60 -filename=/mnt/testfile --output-format=json",
"Sequential read\n4M": "sudo fio -ioengine=libaio -direct=1 -name=read -bs=4M -iodepth=1 -rw=read -runtime=60 -filename=/mnt/testfile --output-format=json",Полученные данные сведем в следующую таблицу:
К сожалению, данный способ подключения блочного устройства к Proxmox не позволяет делать снапшоты виртуальных машин. Вероятно, мы скоро возьмем в работу автоматизацию снапшотов прямо в панели управления — так, как это реализовано в нашей облачной платформе.
У Proxmox есть дистрибутив PBS, который подключается к кластеру PVE и содержит резервные копии. Наш сетевой диск можно задействовать в подобных сценариях как дополнительное долговременное хранилище. Благодаря же алгоритму проверки целостности данных в Ceph можно будет не беспокоиться об их корректности.
Использование iSCSI в VMware ESXi
VMFS (VMware File System) — кластерная файловая система, принятая VMware ESXi для хранения файлов виртуальных машин. Она поддерживает совместный доступ к хранилищу несколькими хостами ESXi. Это безальтернативный тип файловой системы для сетевого хранилища. Версия VMFS6 поддерживает объемы размером до 64 ТБ, однако требует ESXi не ниже 6.5.
VMFS автоматически управляет блокировками и, тем самым, предотвращает одновременное изменение файлов виртуальных машин, что обеспечивает целостность данных. Виды блокировок разные. При создании‑удалении файлов и снапшотов используются блокировки SCSI (VMFS SCSI Locking Mechanism или VAAI), а для операций ввода‑вывода — файловые блокировки, что позволяет нескольким хостам и ВМ параллельно работать с разными файлами на одном LUN.
Ниже приведен листинг команд для настройки сетевого датастора хоста ESXi (на конфигурировании кластера и виртуальных машин останавливаться не будем):
## Создаем два новый vSwitch для iSCSI
esxcli network vswitch standard add --vswitch-name=vSwitch1-SAN
esxcli network vswitch standard add --vswitch-name=vSwitch2-SAN
## Соединяем vSwitch с физическими линками сервера
esxcli network vswitch standard uplink add --vswitch-name=vSwitch1-SAN --uplink-name=vmnic2
esxcli network vswitch standard uplink add --vswitch-name=vSwitch2-SAN --uplink-name=vmnic3
## Создаем порт группы для iSCSI
esxcli network vswitch standard portgroup add --portgroup-name=iscsi-01 --vswitch-name=vSwitch1-SAN
esxcli network vswitch standard portgroup add --portgroup-name=iscsi-02 --vswitch-name=vSwitch2-SAN
## Создаем виртуальные адаптеры в портгруппах
esxcli network ip interface add --interface-name=vmk1 --portgroup-name=iscsi-01
esxcli network ip interface add --interface-name=vmk2 --portgroup-name=iscsi-02
## Настаиваем адресацию и маршрутизацию в SAN-сеть
esxcli network ip interface ipv4 set --interface-name=vmk1 --ipv4 10.130.136.2 --netmask 255.255.255.252 --type static
esxcli network ip interface ipv4 set --interface-name=vmk2 --ipv4 10.130.140.2 --netmask 255.255.255.252 --type static
esxcli network ip route ipv4 add --network 10.130.128.0/22 --gateway 10.130.136.1
esxcli network ip route ipv4 add --network 10.130.132.0/22 --gateway 10.130.140.1
## Настриваем сам iSCSI
## Включаем iscsi и устанавливаем IQN инициатора
esxcli iscsi software set --enabled true
esxcli iscsi adapter set --adapter=vmhba64 --name=iqn.2001-07.com.ceph-uuid1:node1
## Добавляем виртуальные адаптеры к HBA‑контроллеру
esxcli iscsi networkportal add --nic vmk1 --adapter vmhba64
esxcli iscsi networkportal add --nic vmk2 --adapter vmhba64
## Настраиваем авторизацию CHAP
esxcli iscsi adapter auth chap set -A vmhba64 --authname=chap-username --secret=chap-password --level required
## Выполняем запрос discovery в статическому таргету
esxcli iscsi adapter discovery statictarget add -A vmhba64 -a 10.130.128.2:3260 -n iqn.2003-01.com.redhat.iscsi-gw:iscsi-gw
esxcli iscsi adapter discovery statictarget add -A vmhba64 -a 10.130.132.2:3260 -n iqn.2003-01.com.redhat.iscsi-gw:iscsi-gw
esxcli iscsi adapter discovery rediscover -A vmhba64
## Добавляем iSCSI‑сессию
esxcli iscsi session add -A vmhba64 -n iqn.2003-01.com.redhat.iscsi-gw:iscsi-gw
## Настраиваем политику многопутевого доступа (round-robin).
esxcli storage core device list # Найдите в выводе wwid iscsi устройства
esxcli storage nmp device set -d naa.6001405200260da0c384df9a483c517a -P VMW_PSP_RR
esxcli storage nmp psp roundrobin deviceconfig get -d naa.6001405200260da0c384df9a483c517a
## Размечаем и форматируем диск в VMFS6
partedUtil mklabel /dev/disks/naa.6001405200260da0c384df9a483c517a gpt
partedUtil getUsableSectors /dev/disks/naa.6001405200260da0c384df9a483c517a
partedUtil setptbl /dev/disks/naa.6001405200260da0c384df9a483c517a gpt "1 2048 314572766 AA31E02A400F11DB9590000C2911D1B8 0"
vmkfstools -C vmfs6 -S datastore-iscsi /dev/disks/naa.6001405200260da0c384df9a483c517a:1
## Выводим датасторы
esxcli storage filesystem listИспользование iSCSI в Hyper-V
Во время тестирования Windows Failover Cluster, я получил ошибку валидации хранилища:Validate SCSI-3 Persistent Reservation.
Выяснилось, что бэкенд (tcmu-runner, часть ceph-iscsi) не реализует VPD (Vital Product Data). Это препятствует проверке SCSI-3 Persistent Reservations, необходимых для Windows Failover Cluster.
Windows Failover Cluster требует корректной поддержки Persistent Reservation для работы Failover Cluster Hyper-V.
SCSI-3 Persistent Reservations (PR) — механизм управления доступом узлов к общим устройствам хранения в кластерных средах. По сути, это брокер, который управляет резервированием ресурсов со стороны СХД.
Есть интересная статья «Как настроить работу PR» на основе метаданных Ceph, но вряд ли мы возьмемся за подобную функциональность в ближайшее время — реализация выходит неоправданно дорогая и сложная. В качестве альтернативы мы рассматриваем заявленную поддержку NVMeoF в Windows Server 2025, но ее еще предстоит протестировать.
Тем не менее, диск можно подключить к одному хосту с Windows и при испытании он выдает те же значения IOPS и BW.
Использование iSCSI в кластерных файловых системах
Рассмотрим пример работы iSCSI‑диска с GFS2.
GFS2 (Global File System 2) — это кластерная файловая система с совместным доступом к данным. Она позволяет нескольким узлам одновременно работать с одной файловой системой, при этом обеспечивает согласованность и высокую производительность. Ее основные принципы работы следующие.
- DLM (Distributed Lock Manager) предоставляет распределенную блокировку, тем самым — предотвращает конфликты при одновременном доступе разных узлов к одному ресурсу. Поддерживаются различные типы блокировок (например, для чтения‑записи), что гарантирует согласованность данных.
- Журналирование в GFS2. Каждый узел кластера имеет собственный журнал, что снижает конкуренцию при записи. Журналы используются для регистрации изменений метаданных (не данных), что позволяет быстро восстанавливать консистентность при сбоях. Фоновые процессы освобождают устаревшие записи в журналах.
Рассмотрим подробнее две ключевые особенности работы DLM в контексте GFS2.
- Глобальная карта блокировок помогает определить узел, владеющий блокировкой, и тем самым предотвращает конфликты. DLM ведет централизованную таблицу, где регистрируются текущие состояния блокировок для всех объектов файловой системы. Эта карта распределена между узлами и обновляется в режиме реального времени. Каждый узел запрашивает блокировку при операции — например, при чтении или записи.
- Механизм арбитража применяется при конфликтных запросах на блокировки, что гарантирует доступ к ресурсу исключительно одного узла. В случае выхода его из строя DLM перераспределяет его блокировки между оставшимися.
Для работы кластерной файловой системы нужен кластер.
Шаги ниже подразумевают, что и сети, и сам iSCSI‑диск уже подключены к хосту. Как этого добиться, описано выше в разделе про Proxmox.
Установим на каждый хост пакеты, необходимые для работы кластера:
- Corosync — обеспечивает надежную групповую связь между узлами;
- Pacemaker, pcs, resource-agents — для выделения и назначения ресурсов;
- ldmtool, dlm-controld, gfs2-utils — для работы GFS и арбитража.
root@node-1:~# apt install corosync pacemaker gfs2-utils pcs resource-agents ldmtool dlm-controld
## ( необходимо будет выполнить перезагрузку)Кластер собирается на основе Corosync. Настроим его:
## Имена хостов должны быть разрешимы. Заполните соответствующей информацией свой файл /etc/hosts
## Генерируется ключ для авторизации и раскидывается по всем хостам кластера
root@node-1:~# corosync-keygen
root@node-1:~# scp /etc/corosync/authkey root@node2:/etc/corosync/authkey
root@node-1:~# pcs cluster setup HACLUSTER node-1 node-2
root@node-1:~# pcs cluster start --all
## Кластер должен перейти в статус OnLine
## Конфиг коросинка должен принять вид, примерно такой
root@node-2:~# cat /etc/corosync/corosync.conf
totem {
version: 2
cluster_name: HACLUSTER
transport: knet
crypto_cipher: aes256
crypto_hash: sha256
}
nodelist {
node {
ring0_addr: node-1
name: node-1
nodeid: 1
}
node {
ring0_addr: node-2
name: node-2
nodeid: 2
}
}
quorum {
provider: corosync_votequorum
two_node: 1
}
logging {
to_logfile: yes
logfile: /var/log/corosync/corosync.log
to_syslog: yes
timestamp: on
}Теперь мы можем отформатировать наш диск /dev/mapper/mpatha, подключенный ранее, и смонтировать его в ОС на каждом хосте.
root@node-1:~# mkfs.gfs2 -p lock_dlm -t HACLUSTER:iSCSI-SharedStorage -j 2 /dev/mapper/mpatha
## -p lock_dlm - указывает на то что
## HACLUSTER - имя кластера
## iSCSI-SharedStorage - имя тома
## -j 2 - количество журналов, а значит и узлов в кластере (их количество може быть изменено и позднее, но лучше подумать об этом заранее)
root@node-1:~# mount -t gfs2 /dev/mapper/mpatha /mnt/gfsСейчас мы можем описать общий ресурс в Pacemaker, к которому будет предоставлен доступ:
root@node-1:~# pcs resource start dlm
root@node-1:~# pcs property set no-quorum-policy=freeze
## По умолчанию значение no-quorum-policy установлено на stop, что указывает на то, что при потере кворума все ресурсы на оставшемся разделе будут немедленно остановлены.
## Обычно это значение по умолчанию является самым безопасным и оптимальным вариантом, но, в отличие от большинства ресурсов, GFS2 требует кворума для работы.
## При потере кворума как приложения, использующие монтирования GFS2, так и само монтирование GFS2 не могут быть корректно остановлены.
## Любые попытки остановить эти ресурсы без кворума потерпят неудачу, что в конечном итоге приведет к тому, что весь кластер будет остановлен каждый раз при потере кворума.
## Чтобы решить эту ситуацию, установите no-quorum-policyзначение и freeze, если используется GFS2.
## Это означает, что при потере кворума оставшийся раздел ничего не станет делать, пока кворум не будет восстановлен.
## Теперь, когда нужный ресурс определен, мы должны задать параметры подключения ресурса в файловой системе.
root@node-1:~# crm configure primitive ClusterFS ocf:heartbeat:Filesystem device /dev/mapper/mpatha directory /mnt/gfs fstype gfs2В результате мы должны на каждом хосте кластера наблюдать следующий вывод:
oot@node-1:/mnt/gfs# crm status
Cluster Summary:
* Stack: corosync
* Current DC: node-1 (version 2.1.2-ada5c3b36e2) - partition with quorum
* Last updated: Mon Feb 10 11:58:13 2025
* Last change: Fri Feb 7 19:19:07 2025 by root via cibadmin on node-1
* 2 nodes configured
* 2 resource instances configured
Node List:
* Online: [ node-1 node-2 ]
Full List of Resources:
* dlm (ocf:pacemaker:controld): Started [ node-1 node-2 ]
* ClusterFS (ocf:heartbeat:Filesystem): Started [ node-1 node-2 ]
root@node-1:/mnt/gfs# corosync-cfgtool -s
Local node ID 2, transport knet
LINK ID 0 udp
addr = 192.168.1.23
status:
nodeid: 1: connected
nodeid: 2: localhost
root@node-1:/mnt/gfs# dlm_tool status
cluster nodeid 2 quorate 1 ring seq 80 80
daemon now 234888 fence_pid 0
node 1 M add 630 rem 212 fail 60 fence 159 at 1 1738943226
node 2 M add 61 rem 0 fail 0 fence 0 at 0 0
root@node-1:/mnt/gfs# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
----
sdc 8:32 0 150G 0 disk
└─mpatha 252:0 0 150G 0 mpath /mnt/gfs
sdd 8:48 0 150G 0 disk
└─mpatha 252:0 0 150G 0 mpath /mnt/gfs
root@node-1:/mnt/gfs# mount | grep gfs
/dev/mapper/mpatha on /mnt/gfs type gfs2 (rw,relatime,rgrplvb)Не стоит понимать данную конфигурацию как production-ready — это минимальный набор настроек GFS2 для тестирования производительности. В ваших сценариях, возможно, понадобится описать дополнительные ресурсы и условия.
Ознакомиться с полной версией документации GFS2 можно на странице Red Hat.
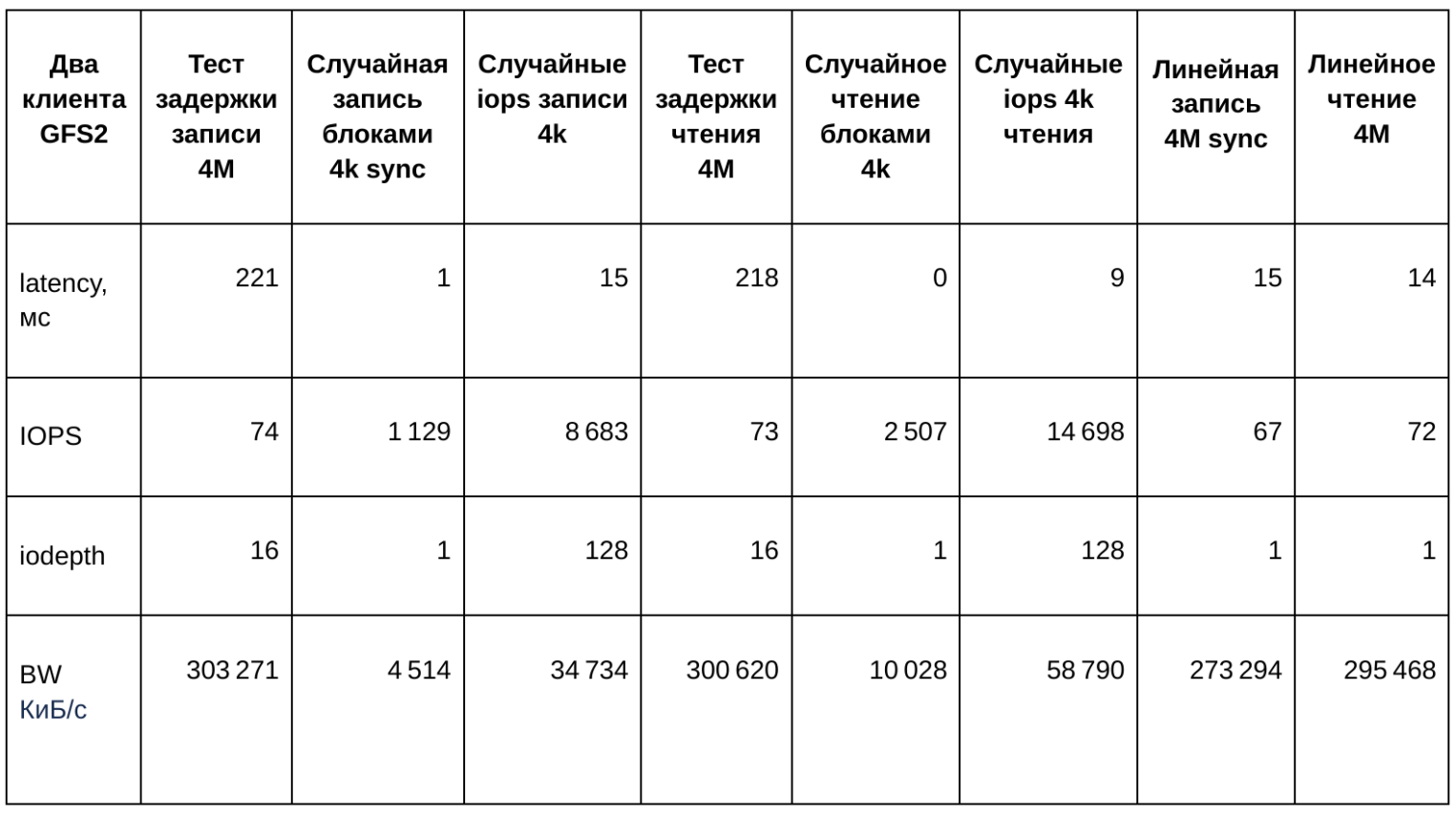
Запустим одновременно на каждом хосте проверку операций чтения и записи, используя fio. Из полученных результатов видно, что полоса квоты для диска распределилась поровну между хостами. В таблице ниже представлено среднеарифметическое значение из двух параллельных тестов:
Рекомендации по настройке и оптимизации iSCSI
Референсные значения по настройке сессий я приводил выше, в примере конфигурации файла /etc/iscsi/iscsi.conf — в главе про Proxmox.
Отказоустойчивость обеспечивается на уровне многопутевого подключения блочного устройства. Конфигурация multipath будет корректной, если вы оставите параметры по умолчанию. Можете настроить политику так, как это необходимо. Однако в любом случае диск должен быть подключен по нескольким путям.
Вы наверняка заметили, что во всех приведенных примерах мы не использовали стандартные файловые системы, такие как EXT4, XFS или NTFS. Это связано с тем, что для работы в схеме many-to-many, для доступа к блочному устройству необходим какой-то арбитраж для разрешения конфликтов при попытках одновременных операций. Это не значит, что подобные файловые системы нельзя использовать на iSCSI‑дисках. Просто стоит воздержаться от их применения одновременно на нескольких хостах в режиме RW.
Заключение
Мы рассмотрели работу с сетевыми дисками на выделенных серверах Selectel. Их можно использовать в самых разных сценариях — таких как виртуализация, оркестрация контейнеров и приложений, обучение ML-моделей и резервное копирование.
В основе решения лежит Ceph — масштабируемая и отказоустойчивая программно-определяемая система хранения данных. Доступ к RBD-образам Ceph осуществляется через iSCSI-Gateway, что обеспечивает совместимость с различными операционными системами. Архитектура включает SAN-сеть, построенную по схеме Leaf-Spine, с использованием VxLAN‑маршрутизации для изоляции клиентов и предотвращения пересечения сетей.
Основные компоненты iSCSI:
- iSCSI Initiator (выделенный сервер),
- iSCSI Target (iSCSI-Gateway),
- Портал (группа Target),
- IQN (полное имя участника iSCSI),
- LUN (номер объекта внутри Target).
Поддерживается совместное использование LUN несколькими инициаторами. Настройка iSCSI рассмотрена на примере Proxmox, VMware ESXi и Hyper-V. Также отметили использование iSCSI в кластерных файловых системах, таких как GFS2.
Рекомендации по настройке и оптимизации iSCSI включают использование многопутевого доступа (multipath) для отказоустойчивости и увеличения производительности за счет распределения нагрузки между несколькими физическими путями.
Вся функциональность, о которой мы рассказали, уже доступна. На очереди — возможность полноценно оперировать группами дисков и серверов через панель управления. Мы постараемся найти другие подходы к проектированию локальных сетей в новых локациях, чтобы дополнительная сетевая карта к сети SAN не требовалась.
Для начала работы с сетевыми дисками на выделенных серверах, достаточно выполнить три простых шага.
1. Зарегистрироваться в панели управления и отправить заявку, ответив на четыре коротких вопроса о своих требованиях и ожиданиях.
2. Заказать сервер с подключением к SAN‑сети или сделать апгрейд существующего. Готовую конфигурацию можно найти по тегу «Можно подключить сетевые диски». Если конфигурация произвольная — добавьте в заказ сетевую карту 2×10 GE + подключение к сети SAN сетевых дисков 10 Гбит/с.
3. Создайте сетевой диск и подключите его.
Квант времени — часовой, то есть применяется модель оплаты pay–as–you–go. В рамках бета-тестирования диски предоставляются бесплатно. Трудно представить более благоприятные условия для тестирования.




