Как разработать алгоритмы машинного обучения на языке Python
Рассмотрим пример машинного обучения на Python с использованием библиотеки scikit-learn: разберемся, как выбирать алгоритмы под тип задачи и как избежать утечки данных.

Основные компоненты ML-процесса
Машинное обучение — это комплексный процесс, который включает несколько последовательных этапов — от сбора данных до оценки финальной модели. Качество каждого этапа определяет итоговый результат. Понимание основных компонентов ML-процесса важно для построения эффективных и надежных моделей, поэтому далее подробно рассмотрим каждый.
Технические навыки — лишь часть процесса: качество модели зависит и от понимания предметной области и от того, насколько корректно вы умеете объяснять ее выводы.
Сбор данных и формирование датасета
Сбор данных — это первый и один из ключевых этапов, так как качество и количество данных напрямую влияют на результаты работы модели. Данные могут быть собраны из разных источников: баз данных, текстовых файлов, изображений, аудиофайлов, скрейпинга веб-ресурсов.
Существует несколько вариантов получения и сбора данных.
- Использовать внутренние источники — например, результаты опросов, интервью или наблюдений внутри организации. Такие первичные данные обладают высокой релевантностью для конкретной задачи.
- Собрать данные из существующих источников, например существующие датасеты (с учетом условий использования) и скрейпинг веб-ресурсов. Такие вторичные данные предоставляют возможность собрать больше информации, при этом ее специфичность для решаемой задачи может быть меньше в сравнении с предыдущим.
Оба варианта можно автоматизировать за счет непрерывного сбора и обновления информации из разных источников в реальном времени. В зависимости от задачи это могут быть IoT устройства, а также API сервисов и приложений.
После сбора данные нужно преобразовать в подходящий формат — например, CSV (Comma-Separated Values). Также можно проверить данные на релевантность поставленной (решаемой) задаче. В результате получаем датасет из «сырых» данных.
Подготовка данных
Подготовка данных — это процесс преобразования сырых данных в формат, который будет подходить для использования в ML-алгоритмах. Обычно в него включают очистку и преобразование, но выбор конкретных способов зависит от задачи и доступных данных.
Очистка данных включает в себя выявление и исправление ошибок в датасете для повышения его качества. Базовые задачи на этом этапе:
- обработка пропущенных значений,
- удаление дублирующихся записей,
- исправление несогласованности форматов данных.
Преобразование данных подразумевает конвертацию данных в подходящий формат для анализа. Рассмотрим наиболее распространенные методы.
- Feature Engineering (конструирование признаков) — создание новых признаков.
- Feature Selection (выбор признаков)— определение наиболее релевантных признаков для анализа.
- Dimensionality Reduction (сокращение размерности) — уменьшение количества признаков.
Работа с пропусками и выбросами
Пропущенные значения и выбросы — это распространенные проблемы в реальных датасетах. Их наличие может существенно ухудшить результат работы модели.
Обработка пропущенных значений
Рассмотрим ключевые стратегии работы с пропущенными данными.
- Удаление строк (столбцов) с пропущенными значениями — простой, но не всегда оптимальный метод, так как может привести к потере информации.
- Замена средним/медианным значением — снижает потери данных, подходит для числовых признаков, но может искажать распределение данных.
- Forward/Backward Fill — заполнение пропусков ближайшими известными значениями. Применимо для данных с временными метками, так как близость определяется на основе разницы времени.
- Замена значениями, предсказанными с помощью алгоритма K-ближайших соседей. Дает более точные значения, но требует вычислительных ресурсов и может быть чувствительна к масштабу признаков.
Обработка выбросов
Выбросы — это значения, которые значительно отличаются от других наблюдений в датасете. Для обнаружения и обработки выбросов используют различные методы. Ниже — несколько ключевых.
- Z-Score — статистический метод для выявления значений, которые значительно отклоняются от среднего.
- IQR (Interquartile Range) — метод, основанный на квартилях распределения.
- Преобразование выбросов в пропущенные значения с последующим применением одного из методов для обработки.
Категориальные переменные: кодирование, нормализация и стандартизация
Часто алгоритмы машинного обучения требуют, чтобы переменные были представлены в числовом формате. Для этого выполняется кодирование категориальных признаков. Рассмотрим ключевые методы.
Label Encoding. Каждой категории присваивается уникальное целое число. Этот метод создает по одному столбцу для каждой категориальной переменной, где каждая категория представлена числом.
One-Hot Encoding. Для каждой уникальной категории создается новый столбец. Он содержит значение «1», если наблюдение принадлежит этой категории, и «0» — в противном случае.
Другой важный шаг — масштабирование, особенно для алгоритмов, чувствительных к диапазону значений признаков. Для этого этапа также есть несколько методов: нормализация и стандартизация.
Нормализация (Min-Max масштабирование). Масштабирует данные в фиксированный диапазон, обычно от 0 до 1. Метод используют на данных с отличным от нормального распределением, а также для некоторых алгоритмов (KNN, K-Means). Формула нормализации:
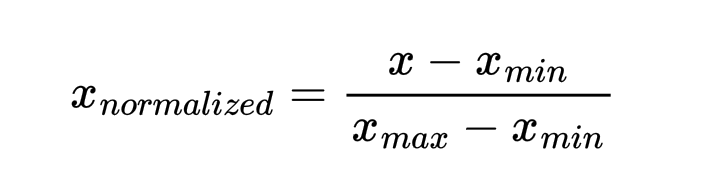
Стандартизация (Standard Scaling). Масштабирует данные, чтобы они обладали средним значением 0 и стандартным отклонением 1. Использование стандартизации предпочтительно, когда данные имеют нормальное распределение и применяются алгоритмы SVM и регресси.
Разделение на обучающую и тестовую выборки
Следующий этап — разделение данных ге несколько выборок. Это помогает повысить способность модели к обобщению, а также уменьшить вероятность переобучения.
Наиболее простой метод подразумевает разделение на обучающую и тестовую выборки (Train-Test Split). Обычно используется соотношение 60-80% для обучающей и 20-40% – для тестовой выборки. Точное соотношение определяется исходя из задачи и данных. В Python такое разделение можно выполнить с помощью функции train_test_split из scikit-learn:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=7)
Для улучшения метрик модели можно на этапе разделения создать еще одну выборку – валидационную (Validation Set). Она часто создается из данных для настройки гиперпараметров без использования тестовой выборки. Типичное разделение:
- 60–80% — обучающие данные;
- 10–20% — валидационные данные;
- 10–20% — тестовые данные.
Важно отметить, что разделение данных на выборки нужно выполнить до всех преобразований и предобработок данных. Так вы сможете избежать утечки данных из обучающей выборки.
Выбор метрик для оценки качества модели
Кроме непосредственно обучения важно уметь оценивать результаты работы модели. Для этого используют различные метрики, список которых разнится в зависимости от типа задачи. Вкратце рассмотрим базовые метрики.
Для задач классификации
Accuracy (точность) — доля правильно классифицированных примеров:
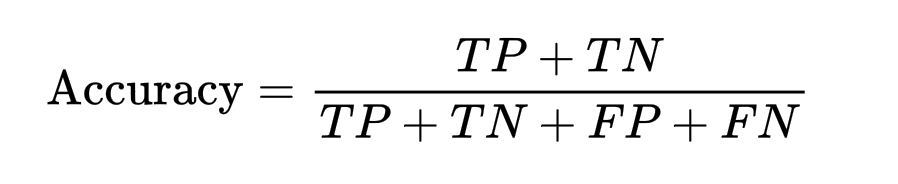
Precision (точность) — доля истинно положительных примеров среди всех предсказанных положительных:
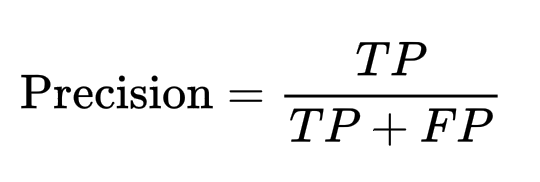
Recall (полнота) — доля правильно предсказанных положительных примеров среди всех истинно положительных:
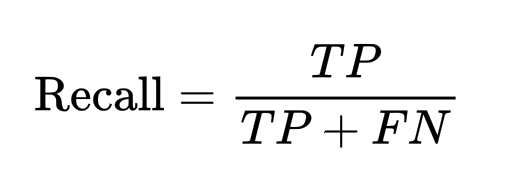
F1 Score — гармоническое среднее точности и полноты:
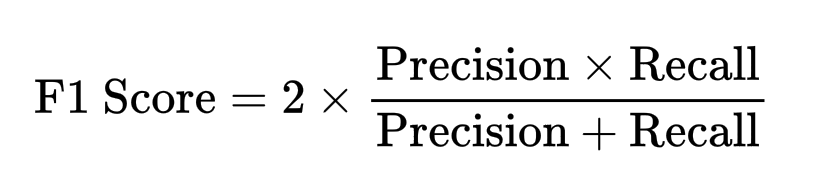
Для задач регрессии:
- MAE (Mean Absolute Error) — средняя абсолютная ошибка.
- MSE (Mean Squared Error) — среднеквадратичная ошибка.
- RMSE (Root Mean Squared Error) — корень из среднеквадратичной ошибки.
- R² Score — коэффициент детерминации.
Алгоритмы машинного обучения на языке Python
Python стал де-факто стандартом для машинного обучения благодаря широкому набору библиотек. Одна из них — scikit-learn — предоставляет унифицированный интерфейс для множества алгоритмов. Остановимся на некоторых из них подробнее.
Линейная регрессия
Линейная регрессия — это алгоритм машинного обучения, основанный на обучении «с учителем». Он моделирует линейную зависимость между входными переменными и непрерывной целевой переменной.
Линейная регрессия с одной переменной:
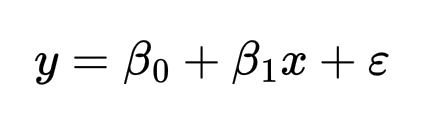
Для множественной линейной регрессии:
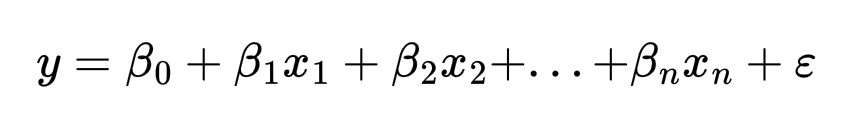
где β0 — смещение (intercept), βi — коэффициенты, а ϵ — ошибка.
Реализация в Python с использованием scikit-learn:
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# Разделение данных
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=7)
# Масштабирование данных
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# Создание и обучение модели
model = LinearRegression()
model.fit(X_train, y_train)
# Предсказание
y_pred = model.predict(X_test)
# Оценка R^2
score = model.score(X_test, y_test)
print(f"R^2 Score: {score}")
Линейная регрессия использует метод наименьших квадратов для минимизации суммы квадратов ошибок между предсказанными и фактическими значениями.
Логистическая регрессия
Логистическая регрессия — это статистический метод для бинарной классификации. Он предсказывает вероятность принадлежности объекта к одному из классов.
Логистическая регрессия использует сигмоидную функцию для преобразования линейной комбинации признаков в вероятность:
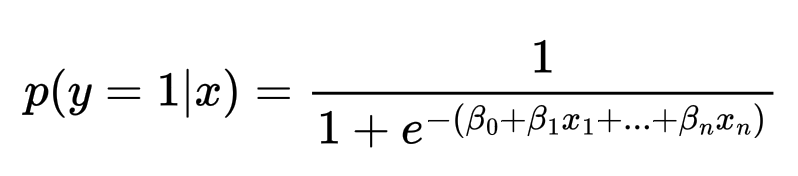
Пример реализации в Python:
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
# Разделение данных
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=7)
# Создание и обучение модели
log_reg = LogisticRegression(max_iter=10000, random_state=7)
log_reg.fit(X_train, y_train)
# Предсказание
y_pred = log_reg.predict(X_test)
# Оценка точности
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy * 100:.2f}%")
Логистическая регрессия использует метод максимального правдоподобия (Maximum Likelihood Estimation) для нахождения оптимальных параметров модели.
Метод опорных векторов
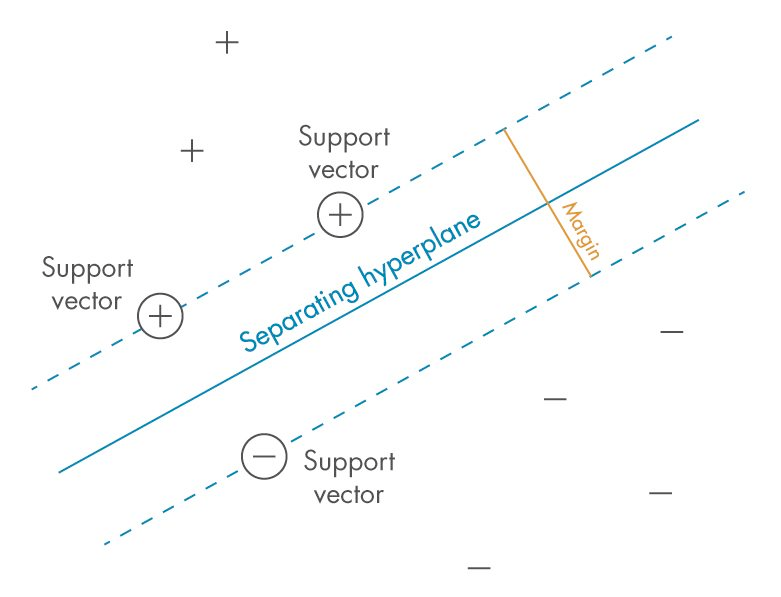
Метод опорных векторов (Support Vector Machine, SVM) — это алгоритм обучения «с учителем», используемый для задач классификации и регрессии.
SVM находит оптимальную гиперплоскость, которая максимизирует расстояние (margin) между ближайшими точками разных классов (опорными векторами).
Для линейно разделимых данных гиперплоскость определяется следующим уравнением, где w — вектор весов, а b — смещение:
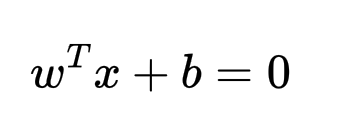
Линейный SVM ищет такую гиперплоскость, которая максимизирует зазор (margin) между классами.
Если данные нелинейно разделимы, используется kernel trick — преобразование исходного пространства признаков в пространство более высокой размерности, где классы могут быть разделены линейно. Наиболее популярные ядра: линейное, полиномиальное, RBF и сигмоидное.
Пример кода (реализации) в Python:
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# Разделение и масштабирование данных
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=7)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# Создание и обучение SVM модели
svm_model = SVC(kernel='rbf', C=1, gamma='scale')
svm_model.fit(X_train, y_train)
# Предсказание и оценка
accuracy = svm_model.score(X_test, y_test)
print(f"SVM Accuracy: {accuracy * 100:.2f}%")
К-ближайших соседей (KNN)
K-Nearest Neighbors (KNN) — это алгоритм машинного обучения «с учителем», который используют для задач классификации и регрессии. Он основан на предположении, что объекты, находящиеся близко друг к другу в пространстве признаков, обладают схожими свойствами.
Алгоритм классифицирует новый объект следующим образом.
- Вычисляет расстояние от объекта до всех точек обучающей выборки.
- Выбирает K ближайших соседей.
- Для классификации — определяет класс по большинству голосов.
- Для регрессии — вычисляет среднее значение целевой переменной среди соседей.
Выбор параметра K напрямую влияет на качество: маленькое значение делает модель чувствительной к шуму, большое — сглаживает различия между классами.
Реализация в Python:
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# Разделение данных
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=7)
# Масштабирование данных
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# Создание и обучение модели
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
# Предсказание
y_pred = knn.predict(X_test)
# Оценка точности
accuracy = knn.score(X_test, y_test)
print(f"KNN Accuracy: {accuracy * 100:.2f}%")
Метод k-средних (K-means)
K-means — это один из наиболее популярных алгоритмов кластеризации. Он разделяет данные на K групп, основываясь на схожести.
K-means стремится минимизировать сумму квадратов расстояний между точками данных и центроидами кластеров. Разберем шаги, из которых состоит алгоритм.
- Инициализация — случайный выбор K начальных центроидов
- Назначение — каждая точка присваивается ближайшему центроиду.
- Обновление — центроиды пересчитываются как среднее значение всех точек в кластере.
- Повторение — шаги 2–3 выполняются до сходимости.
Целевая функция минимизирует внутрикластерную сумму квадратов (WCSS):
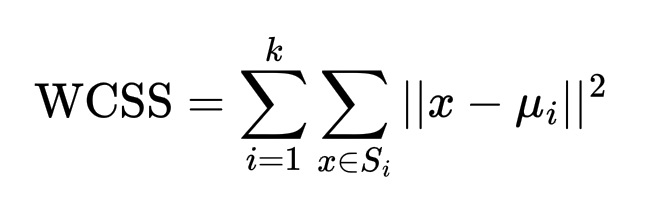
Где μi — центроид кластера Si.
Реализация в Python:
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# Создание и обучение модели K-means
kmeans = KMeans(n_clusters=3, random_state=7)
kmeans.fit(X)
# Получение меток кластеров
labels = kmeans.labels_
centroids = kmeans.cluster_centers_
# Визуализация результатов
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.scatter(centroids[:, 0], centroids[:, 1], marker='X', s=200, c='red')
plt.title('K-means Clustering')
plt.show()
Для определения оптимального числа кластеров можно использовать разные методы. Рассмотрим ключевые — метод «локтя» и метод «силуэта».
Метод «локтя» предполагает построение графика зависимости WCSS от числа кластеров. Оптимальное K находится в точке «локтя», где снижение WCSS замедляется.
Метод «силуэта» (Silhouette Method) измеряет качество кластеризации и оценивает, насколько близко каждая точка находится к своему кластеру по сравнению с другими кластерами.
Сокращение размерности
Сокращение размерности позволяет уменьшить количество признаков, сохранив максимум информации. Один из основных методов — PCA (Principal Component Analysis). Он выделяет направления максимальной дисперсии данных и проектирует исходный набор признаков в новое пространство меньшей размерности.
Процесс PCA
- Стандартизацию данных.
- Вычисление ковариационной матрицы.
- Нахождение собственных значений и векторов.
- Выбор k главных компонент.
- Проецирование данных на новое пространство.
Реализация PCA в Python:
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# Стандартизация данных
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Применение PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
# Дисперсия, объясненная каждой компонентой
print("Explained variance ratio:", pca.explained_variance_ratio_)
Также существует еще один алгоритм — стохастическое вложение соседей с t-распределением (t-distributed Stochastic Neighbor Embedding, t-SNE). t-SNE — это нелинейный метод сокращения размерности, эффективный для визуализации высокоразмерных данных в 2D- или 3D-пространстве.
Реализация t-SNE в Python:
from sklearn.manifold import TSNE
# Применение t-SNE
tsne = TSNE(n_components=2, perplexity=30, random_state=7)
X_tsne = tsne.fit_transform(X)
# Визуализация
plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=y, cmap='viridis')
plt.title('t-SNE Visualization')
plt.show()
На практике чаще всего используют комбинированный подход: сначала применяют PCA для снижения размерности до заданного уровня — например, 50 измерений, а затем — t-SNE, чтобы снизить количество измерений до 2-3 (для визуализации).
Как разработать алгоритм машинного обучения пошагово
В процессе разработки модели машинного обучения можно выделить несколько ключевых этапов.
- Подготовка среды разработки и инструментов.
- Определение целей и задачей.
- Подготовка данных.
- Обучение модели и оценка результата работы.
Инструменты, цель и задачи
Один из основных инструментов — Python и набор различных библиотек. Такой «комплекс» позволяет быстро реализовывать прототипы и проверять гипотезы, поэтому он отлично подходит для экспериментов с различными алгоритмами и подходами. При этом существует несколько «локальных» и «облачных» вариантов работы. Например, можно воспользоваться сервисом Google Colab — это браузерная интерактивная среда для написания и запуска кода на Python, в том числе с использованием графических ускорителей.
Для локального использования подойдет IDE — например Visual Studio Code. О настройке редактора для Python мы рассказывали в отдельной инструкции. При необходимости можно собрать более сложный рабочий процесс — например, использовать Jupyter Notebook в связке с удаленным сервером, однако такие сценарии требуют отдельного детального разборa.
Приглашаем пройти бесплатный курс по Python. В нем рассказываем, что изучать после основ: как настраивать инструменты, работать с базами данных, создавать программы с интерфейсом и использовать Python для парсинга. А еще собрали интересные задачи, чтобы можно было закрепить знания.
Рассмотрим наиболее популярные и оптимальные Python-библиотеки, которые позволяют строить ML-модели.
- NumPy. Фундаментальная библиотека для научных вычислений в Python. Позволяет работать с векторами, матрицами и многомерными массивами.
- Pandas. Библиотека для работы с табличными данными, в том числе в формате DataFrame.
- Scikit-Learn. Предоставляет реализацию широкого спектра современных алгоритмов для задач обучения «с учителем» и без.
- Matplotlib и Seaborn. Библиотеки для визуализации данных. Matplotlib предоставляет низкоуровневый интерфейс для создания различных типов графиков, в то время как Seaborn построен поверх Matplotlib и предоставляет высокоуровневый интерфейс для визуализации.
Все перечисленные библиотеки можно установить с помощью pip:
pip install numpy pandas scikit-learn matplotlib seaborn
Перед началом разработки важно сформулировать цель модели и задачи, которые она должна решать. Это может быть бизнес-метрика, исследовательская гипотеза или прикладная цель.
Также необходимо определить метрики оценки качества и целевые значения, на которые будет ориентироваться модель. После этого можно переходить к подготовке данных.
Подготовка данных
Этап подготовки данных также подразделяется на несколько: загрузка, преобразование и разделение. Ниже приведены примеры для каждого.
Загрузка данных:
# Загрузка данных
df = pd.read_csv('dataset.csv')
# Базовая информация о данных
print(df.head())
print(df.info())
print(df.describe())
Обработка данных:
# Проверка пропущенных значений
print(df.isnull().sum())
# Обработка пропущенных значений - замена на среднее значение
df.fillna(df.mean(), inplace=True)
# Удаление дубликатов
df.drop_duplicates(inplace=True)
# Кодирование категориальных переменных
df = pd.get_dummies(df, columns=['categorical_column'])
Разделение данных:
# Разделение на признаки и целевую переменную
X = df.drop('target', axis=1)
y = df['target']
# Разделение на обучающую и тестовую выборки
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=7
)
# Масштабирование признаков
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
Построение модели
Выбор алгоритма зависит от типа задачи и характеристик данных.
- Для задач регрессии — Linear Regression, Random Forest Regressor.
- Для задач классификации — Logistic Regression, Decision Trees, Random Forest, SVM, KNN.
- Для кластеризации — K-Means, DBSCAN, Hierarchical Clustering.
Часть из этих алгоритмов мы рассмотрели ранее. Используя обработанные на предыдущем этапе данные можно обучить модель:
from sklearn.ensemble import RandomForestClassifier
# Инициализация модели
model = RandomForestClassifier(n_estimators=100, random_state=7)
# Обучение модели
model.fit(X_train, y_train)
В инициализации модели упоминается n_estimators — это один из гиперпараметров модели. Гиперпараметры «настраивают» обучение модели и задаются до начала обучения. Их настройка напрямую влияет на результаты работы.
Grid Search — один из методов поиска оптимальной комбинации гиперпараметров. У каждого алгоритма свой набор гиперпараметров. У использованного выше RandomForestClassifier есть n_estimators, max_depth и min_samples_split (с полным набором и описанием можно ознакомиться в документации). Пример подбора их оптимальных значений:
from sklearn.model_selection import GridSearchCV
# Определение сетки значений гиперпараметров
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [5, 10, 15, None],
'min_samples_split': [2, 5, 10]
}
# Инициализация Grid Search
grid_search = GridSearchCV(
estimator=model,
param_grid=param_grid,
cv=5,
scoring='accuracy',
n_jobs=-1
)
# Поиск оптимальных параметров
grid_search.fit(X_train, y_train)
# Лучшие параметры
print("Best parameters:", grid_search.best_params_)
print("Best score:", grid_search.best_score_)
После нахождения оптимальных значений гиперпараметров модель может быть повторно обучена с предустановкой найденных значений.
Оценить полученное предсказание
Обученную модель нужно протестировать на тестовых данных — той части данных, которая была отнесена к тестовой выборке на этапе подготовки данных, а также вычислить метрики.
# Предсказание на тестовой выборке
y_pred = model.predict(X_test)
# Метрики для оценки точности классификации
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='weighted')
recall = recall_score(y_test, y_pred, average='weighted')
f1 = f1_score(y_test, y_pred, average='weighted')
print(f"Accuracy: {accuracy:.4f}")
print(f"Precision: {precision:.4f}")
print(f"Recall: {recall:.4f}")
print(f"F1 Score: {f1:.4f}")
# Матрица ошибок
cm = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:\n", cm)
Улучшение и настройка модели
После первоначального обучения модели полезно провести итеративное улучшение для достижения заданных оценочных метрик и производительности. Для этого используют различные техники.
- Feature Engineering — создание новых признаков, которые могут улучшить производительность модели. Например, агрегирование признаков.
- Регуляризация — помогает предотвратить переобучение путем добавления штрафа за сложность модели.
- Ансамблевые методы — комбинируют несколько моделей для улучшения предсказаний.
Работа с большими и реальными данными
Работа с большими объемами данных зачастую требует особых подходов и инструментов. Рассмотрим ключевые, которые подходят для больших данных.
Пакетная обработка — загрузка и обработка данных частями вместо загрузки всего датасета в память.
# Использование nrows для работы с подмножеством данных
example_df = pd.read_csv('large_dataset.csv', nrows=10000)
Использование Modin. Это библиотека, которая ускоряет операции Pandas, особенно для больших датасетов.
Реальные данные чаще всего содержат искажения, которые нужно учитывать:
- шумные данные — содержат ошибки и несогласованности;
- несбалансированные классы — количество данных об одном классе значительно преобладает над другими;
- высокая размерность — множество признаков.
Визуализация и интерпретация моделей
Один из основных вопросов при разработке ML алгоритмов — интерпретируемость работы модели. Визуализация и интерпретация моделей крайне важны для понимания и оценки результатов работы.Базовая визуализация данных с использование Matplotlib и Seaborn реализуется следующим образом:
import matplotlib.pyplot as plt
import seaborn as sns
# Распределение признака
plt.figure(figsize=(10, 6))
sns.histplot(df['feature'], kde=True)
plt.title('Feature Distribution')
plt.show()
# Корреляционная матрица - степень взаимосвязи (корреляции) между переменными
plt.figure(figsize=(12, 8))
correlation_matrix = df.corr()
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', center=0)
plt.title('Correlation Matrix')
plt.show()
# Pair plot - сравнение распределения пар числовых переменных
sns.pairplot(df, hue='target')
plt.show()
Интерпретация моделей может быть выполнена с помощью SHAP и LIME. SHAP (SHapley Additive exPlanations) определяет вклад каждого признака в предсказание модели, а LIME (Local Interpretable Model-agnostic Explanations) — создает локальную интерпретируемую модель вокруг конкретного предсказания модели.
Базовые советы и частые ошибки
Кратко остановимся на базовых рекомендациях по выбору алгоритмов и типовым проблемам, которые могут возникнуть при обучении моделей.
Выбор алгоритма
Выбор используемого алгоритма зависит от нескольких факторов.
Тип решаемой задачи
- Регрессия — предсказание непрерывных значений (Linear Regression, Random Forest Regressor).
- Классификация — предсказание категориальных значений (Logistic Regression, Decision Trees, SVM, KNN).
- Кластеризация — группировка схожих объектов (K-Means, DBSCAN).
Размер датасета
Факторы в этом пункте — наименее строгие и могут варьироваться в зависимости от предметной области и типа задачи.
- Маленькие датасеты (KNN, Decision Trees).
- Средние датасеты (Random Forest, SVM).
- Большие датасеты (Linear models, Gradient Boosting).
Линейность данных в датасете
- Линейные зависимости (Linear Regression, Logistic Regression).
- Нелинейные зависимости (SVM с RBF ядром, Neural Networks, Random Forest).
Интерпретируемость
- Высокая интерпретируемость (Linear Regression, Logistic Regression, Decision Trees).
- Низкая интерпретируемость (Neural Networks, Random Forest, XGBoost).
Утечка данных
Одна из распространенных ошибок — утечка данных (data leakage). Она возникает, когда информация из тестовой выборки непреднамеренно используется на этапе обучения. В дальнейшем это приводит к некорректным оценкам работы модели. Выделяют следующие виды data leakage:
- Target Leakage — признак содержит информацию о целевой переменной, которая не будет доступна во время предсказания;
- Train-Test Contamination — информация из тестовой выборки попадает в обучающую.
Все способы предотвращения утечки решают одну задачу — недопущение смешения данных разных выборок. Как избежать утечки:
- сначала разделять данные, затем — выполнять предобработку;
- использовать Pipeline из scikit-learn;
- удалять признаки, недоступные при предсказании;
- проводить мониторинг качества модели (аномально высокая точность — сигнал о возможной утечке).
Другая распространенная проблема относится к результату работы модели — это переобучение и недообучение.
Переобучение и недообучение
Переобучение (Overfitting) возникает, когда модель слишком хорошо изучает обучающие данные (включая шум). Это ухудшает способность к обобщению на новых данных. Основной признак переобучения — высокая точность на обучающей выборке и низкая — на тестовой. Среди частых причин — недостаточный размер обучающих данных и качество данных. Предотвратить переобучение можно с помощью увеличения объема обучающих данных, а также применения регуляризации и кросс-валидации
Недообучение (Underfitting) возникает, когда модель и не может выявить закономерности в данных. Основной признак недообучения — это низкая точность на обучающей и тестовой выборках. Среди частых причин — недостаточное количество признаков и времени обучения, а также чрезмерная регуляризация. Предотвратить недообучение можно с помощью добавления новых признаков (feature engineering), уменьшения регуляризации и увеличения времени обучения.
Заключение
Экосистема Python — в первую очередь библиотека scikit-learn — предоставляет устойчивый набор методов для решения задач классификации, регрессии, кластеризации и предварительной обработки данных. Успешное применение ML требует выбора подходящего алгоритма, внимательного подхода к подготовке данных и оценке результатов, ровно как и предотвращению распространенных ошибок — утечек данных и переобучения.
Развитие машинного обучения продолжается, а новые методы открывают все больше возможностей для решения сложных задач. Важно помнить, что успех зависит не только от технических навыков, но и от понимания предметной области, а также от способности интерпретировать и объяснять результаты модели.





