Парк юрского периода: как развернуть Diffusers для генерации изображений
Рассказываем, как настроить шаблон для генерации Тирексов c помощью библиотеки от Hugging Face и задеплоить его на сервер с GPU.
Как часто бывает: появляется немного свободного времени, хочется отдохнуть и написать картину… но его то ли недостаточно, то ли просто лень размахивать кистью. Но можно делегировать задачу нейросети — для этого необязательно использовать Midjourney или DALL-E.
Один из вариантов — развернуть собственного помощника на готовом сервере с помощью библиотеки Diffusers и моделей Hugging Face. Мы попробовали и сгенерировали целый «Парк юрского периода» с разными тирексами. Что из этого получилось и как повторить наши творения, рассказываем в статье.
Что понадобится
Построить свой «Парк юрского периода» не так сложно. Понадобится «всего лишь» сервер с GPU и настроенное рабочее окружение с библиотекой Diffusers.
Инструменты
Если вы ранее не работали с Diffusers, самое время с ней познакомиться.
Diffusers — это библиотека от Hugging Face, которая позволяет работать с сотнями обученных Stable Diffusion-моделей для генерации изображений, аудио и даже объемных молекулярных структур. Ее можно использовать как для экспериментов с существующими моделями, так и для обучения своих.
Разработчики из Hugging Face утверждают, что их детище — это простой модульный проект. Профессиональных знания об устройстве нейронных сетей и «тензорной магии» для работы с Diffusers не нужны.
Остальной набор инструментов — классический. Мы будем использовать:
- JupyterLab — среду разработки для DataScince- и ML-специалистов,
- Python и специализированные библиотеки — TensorFlow и PyTorch.
Сервер
Генерация даже одной картинки может потреблять много виртуальных ресурсов и времени. Если вы хотите оптимизировать процесс и в будущем, например, «прикрутить» к нейросети интерфейс в виде Telegram-бота, локальная машина не подойдет. Понадобится сервер с GPU — выделенный или облачный.
Выделенный сервер можно более гибко настроить, в том числе и на уровне железа. Ресурсы ни с кем делить не нужно — вычислительные мощности работают только на вас.
С другой стороны, если с выделенным сервером что-то случится, то восстановление всех компонентов может занять много времени. Облачные серверы же не привязаны к конкретному хосту и могут мигрировать, если тот выйдет из строя. Кроме того, всегда можно сделать образ облачного сервера, из которого проще восстановить рабочее окружение. Поэтому для небольших проектов это более предпочтительный вариант.
Чтобы не тратить время на настройку инструментов, можно развернуть DAVM (Data Analytics Virtual Machine) — облачный сервер с предустановленным набором инструментов для анализа данных и машинного обучения. Среди них — Jupyter Lab, Superset и Prefect.
Подготовка облачного окружения
Поднимаем сервер
Запустить сервер DAVM можно всего за несколько шагов:
1. Переходим в раздел Облачная платформа внутри панели управления.
2. Выбираем пул ru-7a и создаем облачный сервер с дистрибутивом Ubuntu 20.04 LTS Data Analytics 64-bit и нужной конфигурацией.
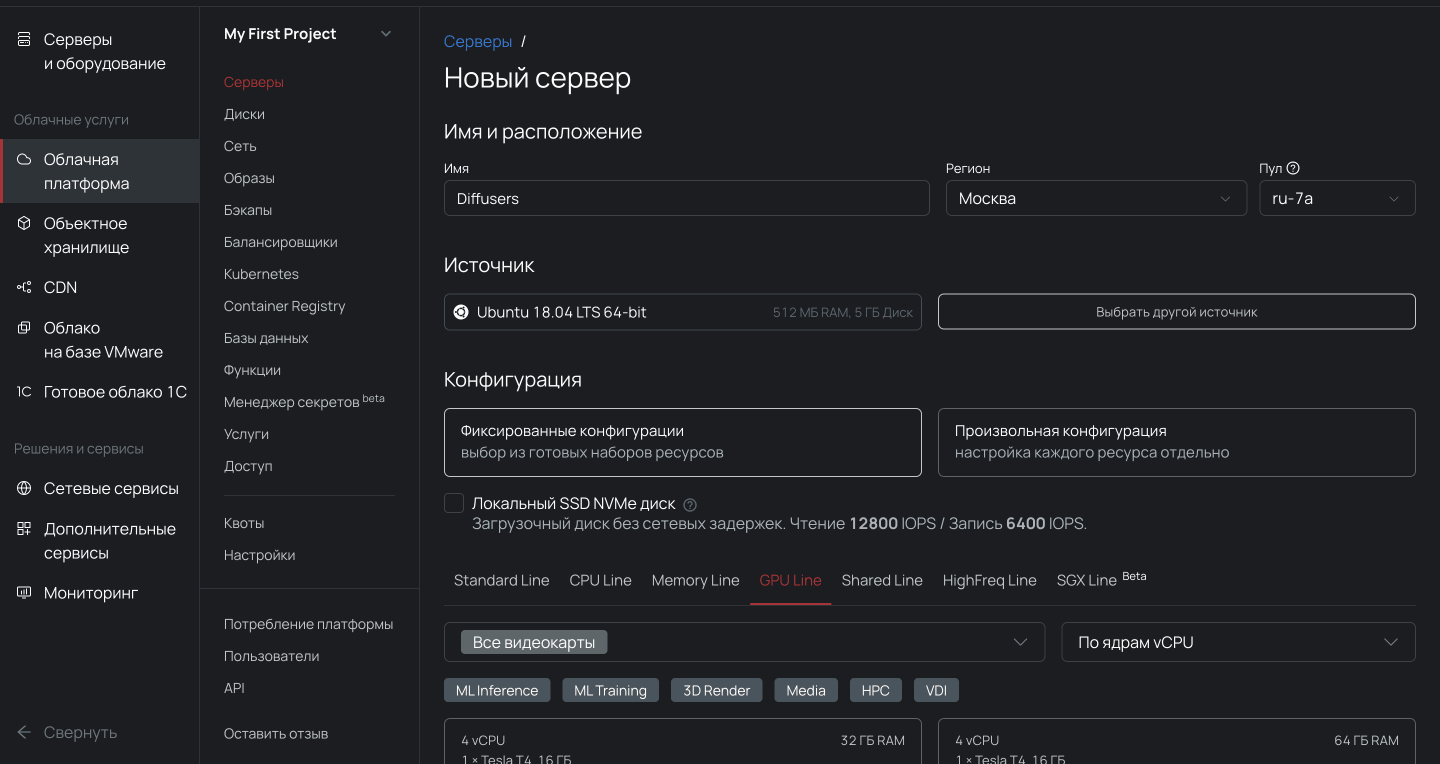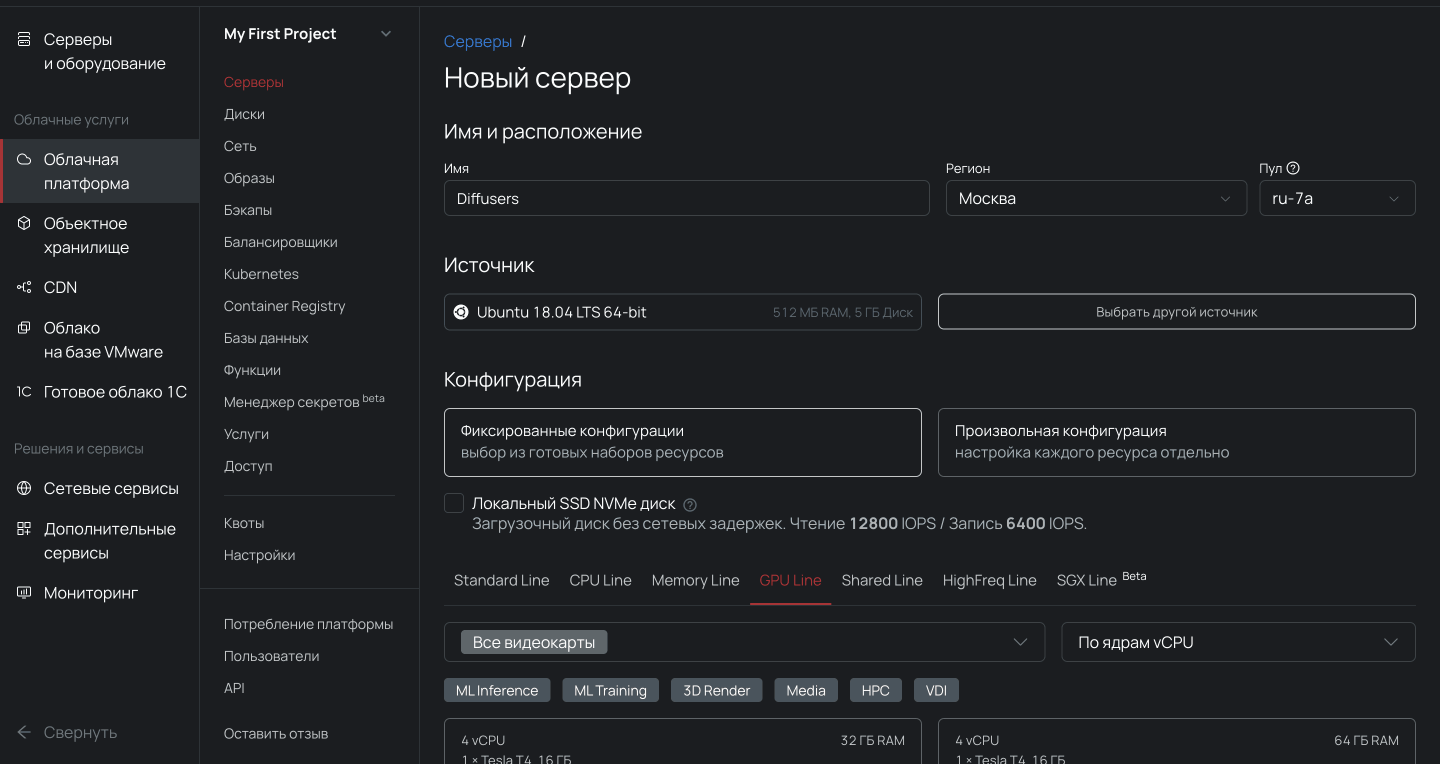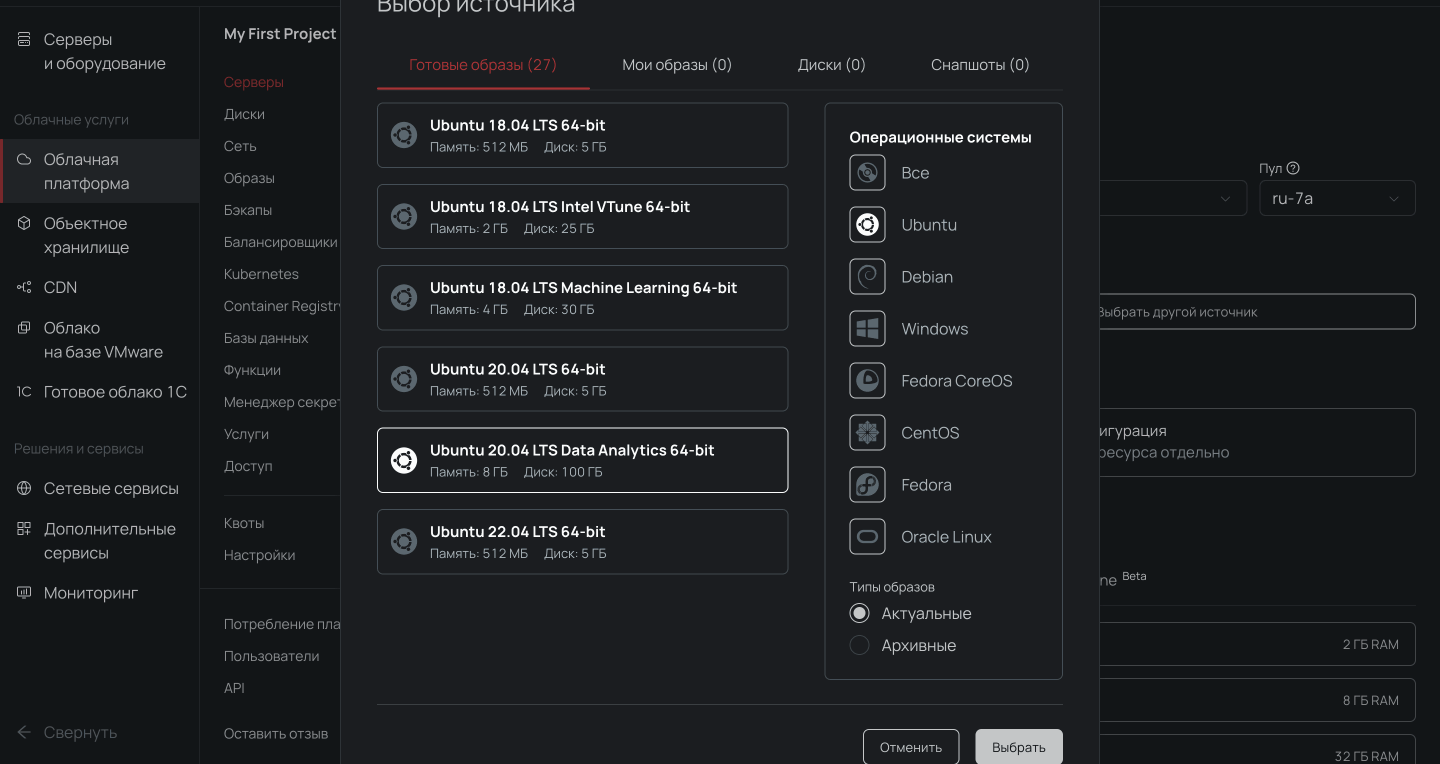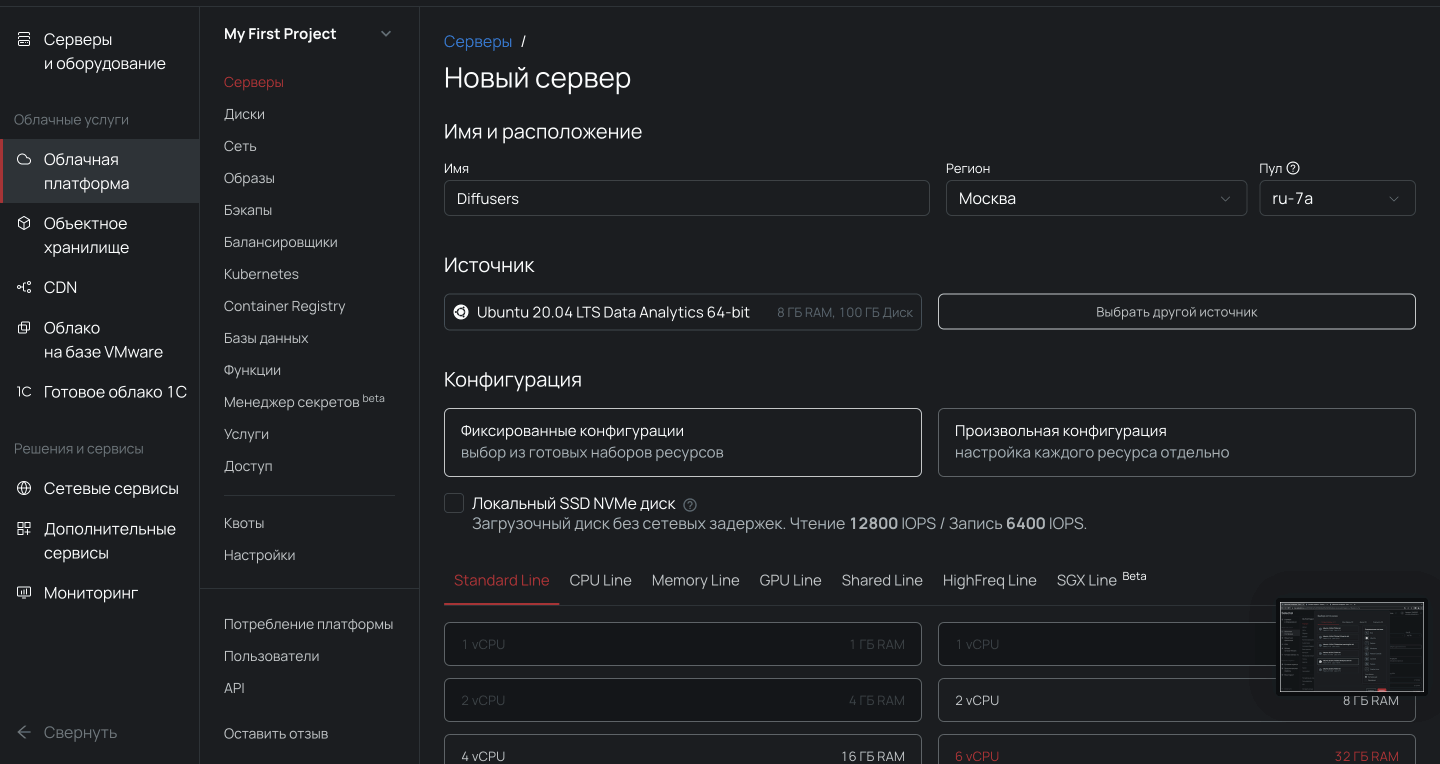
Важно, чтобы сервер был доступен из интернета, иначе с компьютера не подключиться. Для этого во время настройки конфигураций выберите новый публичный IP-адрес.
Нужно дать системе пару минут на загрузку. После — подключиться к серверу по SSH. Вы увидите в консоли данные для авторизации в окружении DAVM.
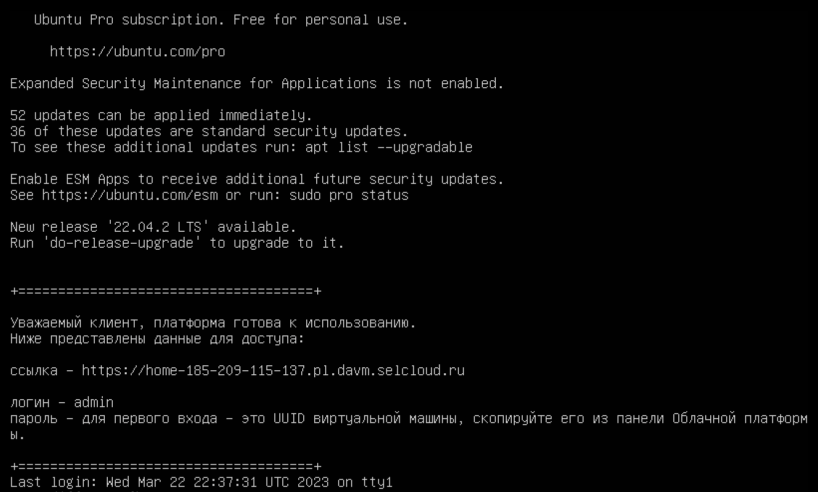
Теперь, если перейти по ссылке из сообщения и авторизоваться в DAVM, можно запустить JupyterLab, Keycloak, Prefect или Superset.
Подключение к DAVM

В DAVM можно создавать пользователей, управлять ими и авторизацией во внутренних приложениях с помощью Keycloak. Обратите внимание, что после первичной смены стандартного пароля на собственный, его удаленный сброс силами технической поддержки невозможен.
Генерация динозавров
Логика работы с моделями Diffusers сильно упрощает реализацию проекта. Шаблон можно условно разбить на несколько блоков — импорт нужных библиотек (Diffusers, в том числе), загрузку модели для генерации динозавров, настройку пайплайна и вывод изображения.
Установка зависимостей
Для начала установим библиотеку Diffusers, а также сопутствующие ей зависимости — transformers, scipy, accelerate.
! pip install diffusers transformers scipy
! pip install accelerate
Обратите внимание: пакетный менеджер pip предварительно обновлять не нужно, все уже настроено и упаковано в Docker-контейнер. Ошибки типа Could not install packages due to an OSError исключены.
Загрузка модели и подготовка пайплайна
Далее импортируем модули и загрузим модель для генерации динозавров — например, dreamlike-art/dreamlike-diffusion-1.0. Это можно сделать с помощью указания model_id — переменной-ссылки на модель в Hugging Face — и метода StableDiffusionPipeline.from_pretrained(), который базово подготовит пайплайн:
model_id = "dreamlike-art/dreamlike-diffusion-1.0"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
Небольшое уточнение: вы можете использовать любую генеративную модель из списка. Например, если вы хотите получить изображение в стилистике Midjourney, загрузите prompthero/openjourney. Галерею каждой модели можно посмотреть на Civitai и в официальной библиотеке.
Супер — модель выбрали, загрузили в пайплайн. Далее нужно указать, на каких ядрах — процессора или видеокарты — мы хотим генерировать изображения. Это можно сделать с помощью метода pipe.to().Если вы используете сервер с GPU, должно быть pipe.to(“cuda”), если только процессорные мощности — pipe.to(“cpu”).
model_id = "dreamlike-art/dreamlike-diffusion-1.0"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
Далее пайплайн можно настроить: подать на вход промт-запрос, скорректировать параметры — например, количество изображений, которое нужно сгенерировать за один запрос, число итераций в инференсе и другое.
images = pipe(
prompt = "photorealistic front view soft toy green dinosaur rex in a white T-shirt sat down behind a desk with computers and servers background is data centre",
height = 512,
width = 1024,
num_inference_steps = 100,
guidance_scale = 0.5,
num_images_per_prompt = 1
).images
#вывод изображения
display(images[0])
Готово — после запуска программа выведет внутри Jupyter изображение. Всего за несколько минут мы подняли сервер с GPU и развернули нейросеть для генерации изображений — в нашем случае, динозавров. Давайте же посмотрим, какие красавчики получились.
Что получилось
На ML-стенде Selectel Tech Day мы предлагали участникам с помощью нейросети сгенерировать промт для создания нашего маскота Тирекса. Вот самые прикольные варианты, которые у нас получились:


Получился даже Тирекс, максимально похожий на плюшевую версию:

А еще пара динозавров, которые играют в шахматы:

Тирекс, работающий в продуктовом магазине, получился сильно уставшим:

Примерно настолько же «хорошо» получился и тирекс, который работает с сервером Эльбрус и аниме-девочками:

Сильнее всех устал уставший тирекс после работы:

С учетом того, что участники конференции не были промт-инженерами и работали с неизвестной для себя моделью, некоторые иллюстрации можно даже установить в качестве обоев на экран компьютера.





