

Я Антон Алексеев, DevOps-инженер в Selectel. В апреле у нас проходил ML-митап, где я и мой коллега, ML-Ops инженер Ефим Головин, рассказали, как подбираем конфигурацию ML-инфраструктуры и повышаем утилизацию GPU. Материал вышел интересным, поэтому мы решили оформить пересказ в текстовый формат.
Что можно переиспользовать в ML от заводских промышленных линий
Где лучше всего отточены технологии и методологии автоматизации? Конечно, на заводах и промышленных предприятиях. Мы вдохновляемся бережливым производством, следуем Кайдзен Toyota, соблюдаем и используем теорию ограничений Голдратта. И переносим этот опыт в разработку ML-систем.
Как выглядит ML-система для клиента
ML-система для конечного клиента — «черный ящик», в котором происходит магия. Он выполняет определенные задачи и выдает результаты на основе входных данных. Клиент взаимодействует с системой через интерфейсы и API, не вникая в сложные внутренние процессы.
Пример такого взаимодействия — распознавание текста на фотографии со знаком STOP. Это может быть часть системы автономного вождения. Рассмотрим простой пример инференс-графа.

Вот что здесь происходит.
- Модель 1 детектирует текст на изображении.
- Модель 2 обрезает изображение, чтобы оставить только текст.
- Модель 3 распознает текст на знаке (в нашем случае, слово «STOP»).
Для клиента вся цепочка представляет собой черный ящик, куда на вход он подает изображение, а на выходе получает слово «STOP». Он не вдается в подробности, как система выглядит изнутри. Аналогично: когда мы покупаем банку кофе в магазине, мы не думаем, как кофе оказался в банке и что за этикетка там наклеена. Мы берем готовый товар и используем его.
Возникает вопрос: если мы хотим сделать систему эффективнее, нам нужно улучшать работу моделей в инференс-графа? На самом деле необходимо рассматривать систему в целом.
Как выглядит ML-система целиком
Продолжу аналогию с производством: улучшение только одного этапа может не дать значительного эффекта, если не учитывать взаимодействие всех компонентов. Помимо самих инференсов нужно помнить о различных стадиях и компонентах ML-системы. Рассмотрим, как это выглядит с точки зрения MLOps.org.
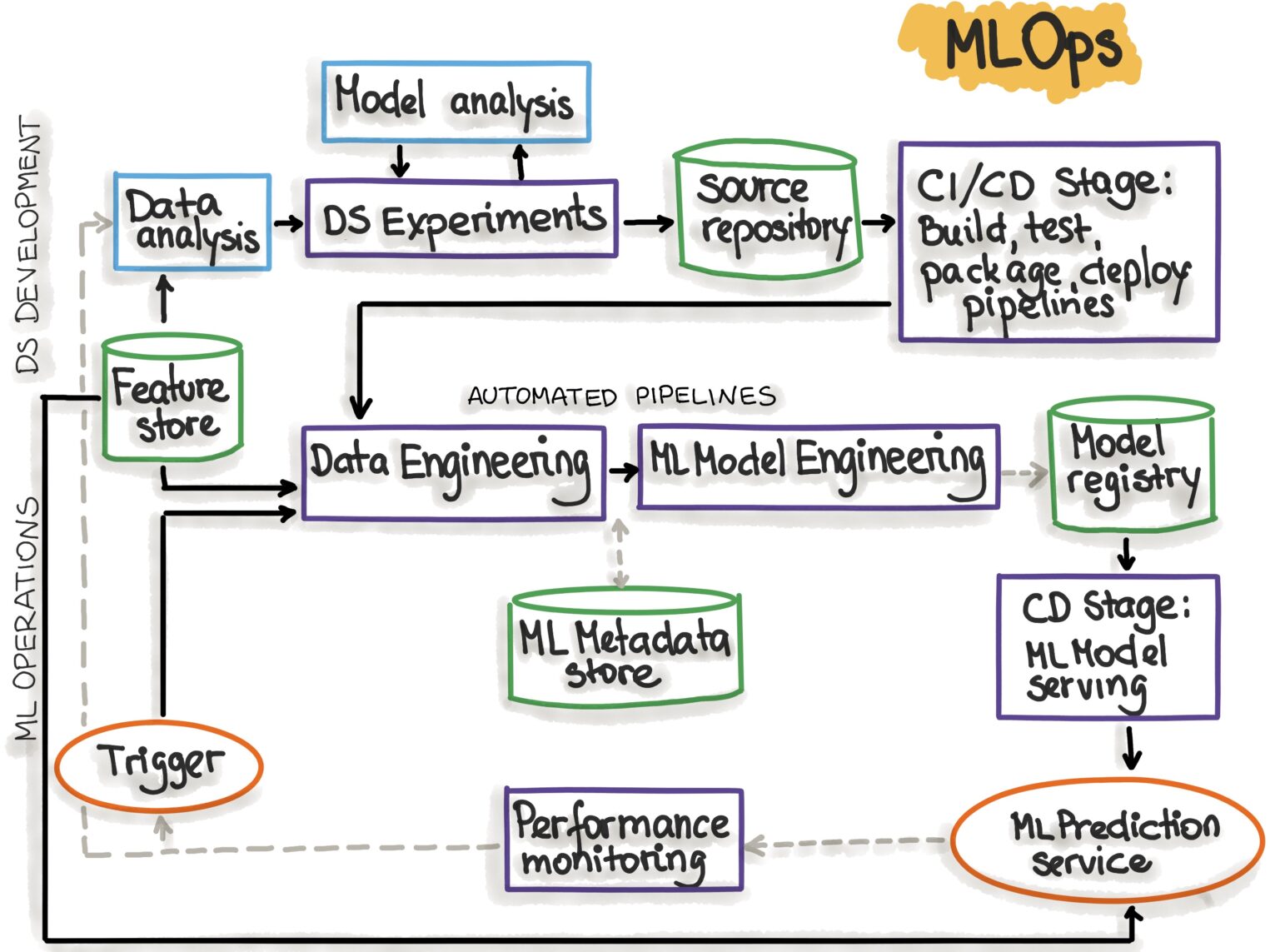
Рассмотрим основные компоненты системы:
| Этап MLOps | Результат выполнения этапа |
| Разработка и эксперименты (ML-алгоритмы и ML-модели). | Исходный код для конвейеров: извлечение данных, валидация, подготовка, обучение, оценка и тестирование модели. |
| Непрерывная интеграция конвейера (сборка исходного кода и запуск тестов). | Развертываемые компоненты конвейера: пакеты и исполняемые файлы. |
| Непрерывная доставка конвейера (развертывание конвейеров в целевой среде). | Развернутый конвейер с новой реализацией модели. |
| Автоматизированный триггер (конвейер автоматически выполняется в производстве; используется расписание или триггер). | Обученная модель, которая хранится в реестре. |
| Модель непрерывной доставки (модель, служащая для прогнозирования). | Развернутый инференс. |
| Мониторинг (сбор данных о работе модели на реальных данных). | Триггер для выполнения конвейера или начала нового цикла эксперимента. |
В Nvidia полную схему конвейера видят чуть иначе, хотя ключевые компоненты в основном представлены такие же:
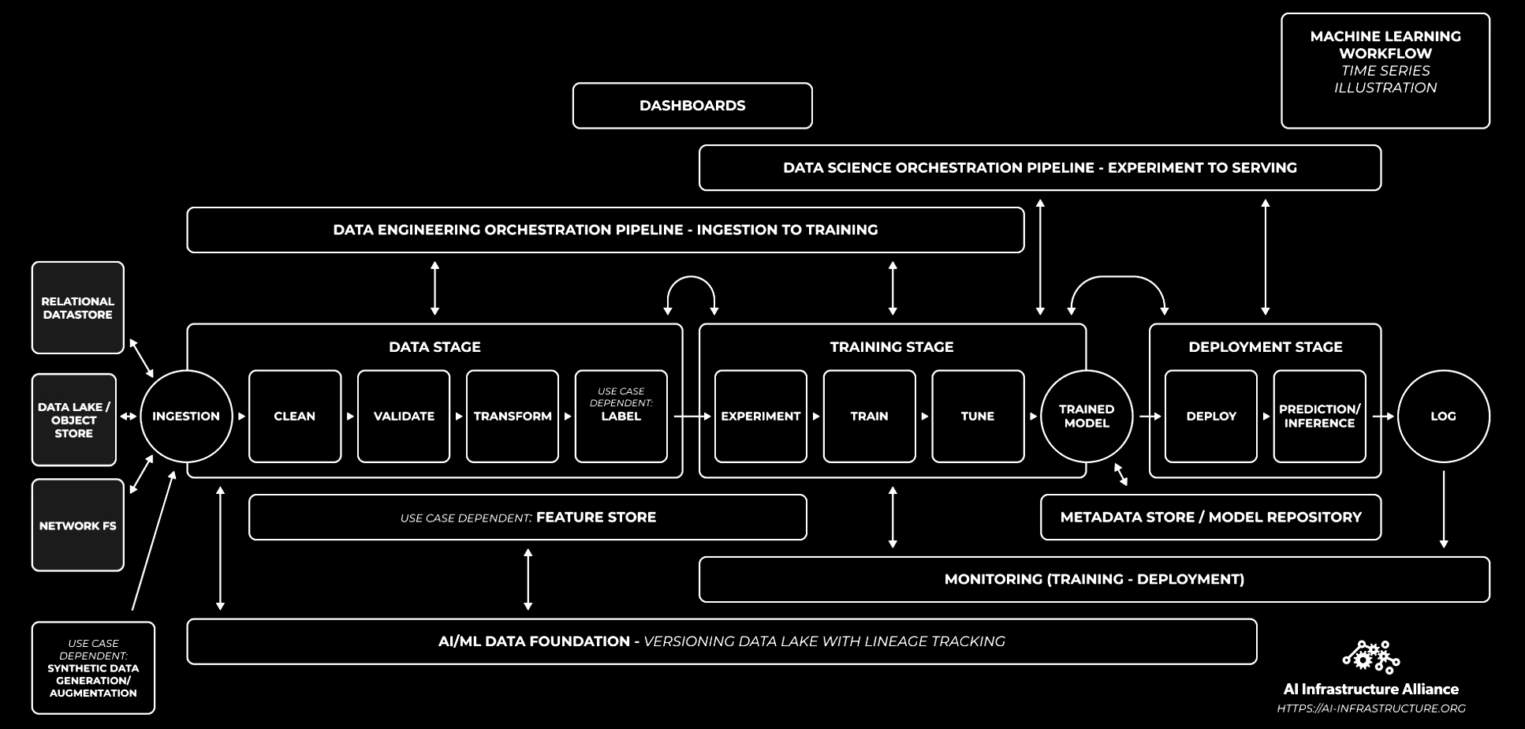
Используя эти источники, доведем нашу исходную схему до цельного вида:
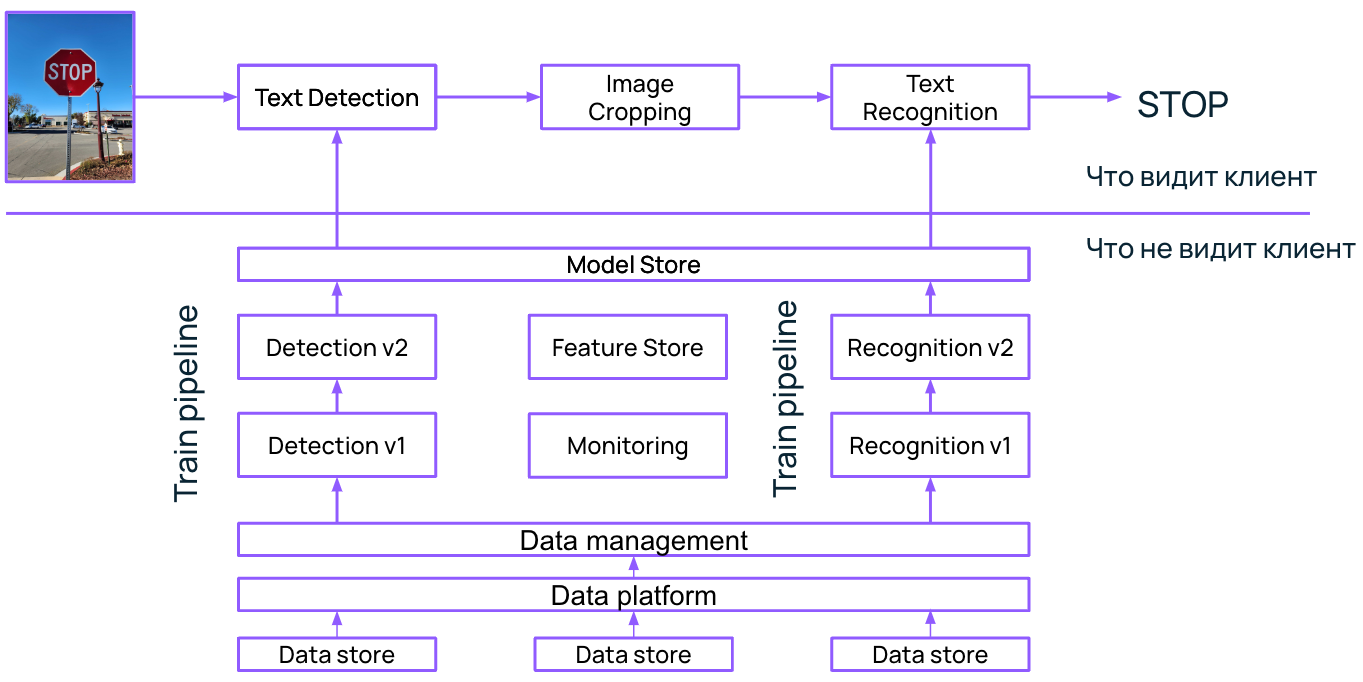
В итоге помимо самого инференс-графа видим, что в нашей схеме важно учитывать хранилища и конвейеры обучения моделей, а также слой data management. В данном случае все этапы распознавания текста на знаке «STOP» важны для конечного результата, поэтому необходимо рассматривать систему в целом.
Как верхнеуровнево выглядит завод
Заметили, что мы много говорим про конвейеры? Давайте вспомним, откуда они к нам пришли. Верхнеурово рассмотрим схему конвейера с кафедры Санкт-Петербургского Политехнического университета. Представим, что на нем упаковываются банки кофе.
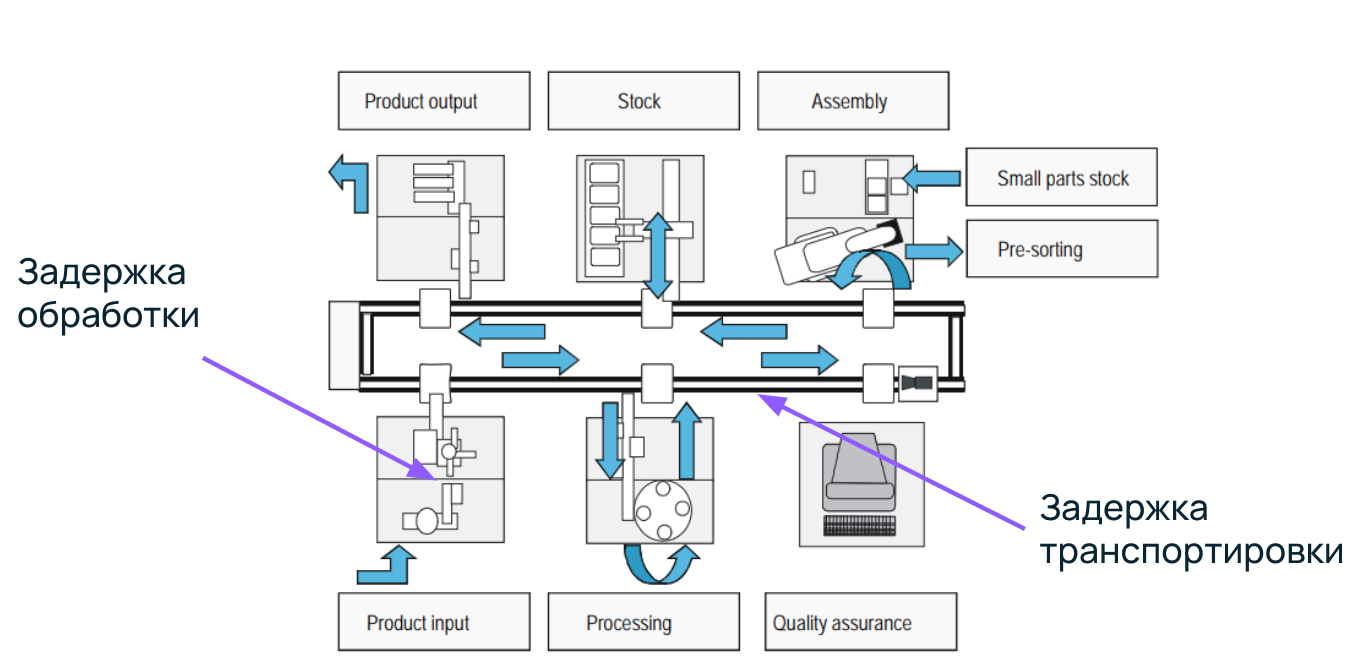
Конвейерная линия состоит из нескольких этапов, каждый из которых выполняет определенные функции для создания конечного продукта.
- Получение сырья: пустая банка поступает на конвейер.
- Станция 1: заполнение банки кофе.
- Cтанция 2: закрытие крышки.
- Станция 3: наклеивание этикетки.
- Упаковка и транспортировка: банки сортируются и отправляются клиентам.
На каждой станции будет задержка обработки, потому что требуется время, чтобы насыпать кофе в банку или закрутить крышку. А еще банки передвигаются между станциями — на это тоже тратится время. Здесь возникает задержка транспортировки.
Отмечу, что каждая станция состоит из хардварной и софтварной частей. Хардвар — манипулятор, который перетаскивает банку. Софтвар — алгоритмы, которые вшиты в контроллер. К чему вся эта аналогия, спросите вы? Попробуем перенести эту мысль на ML-системы.
ML-системы как конвейер завода
Начнем с хардварной части и рассмотрим популярный сервер DGX H100 в качестве хардварной площадки для ML-системы.
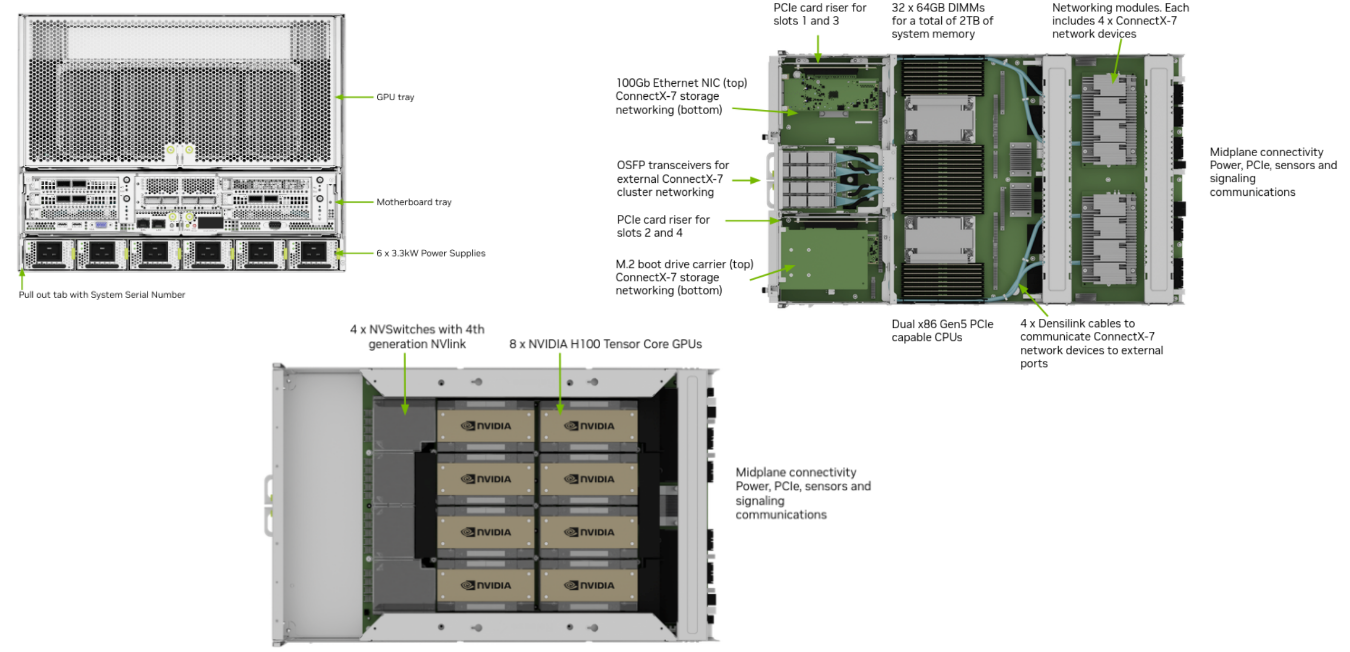
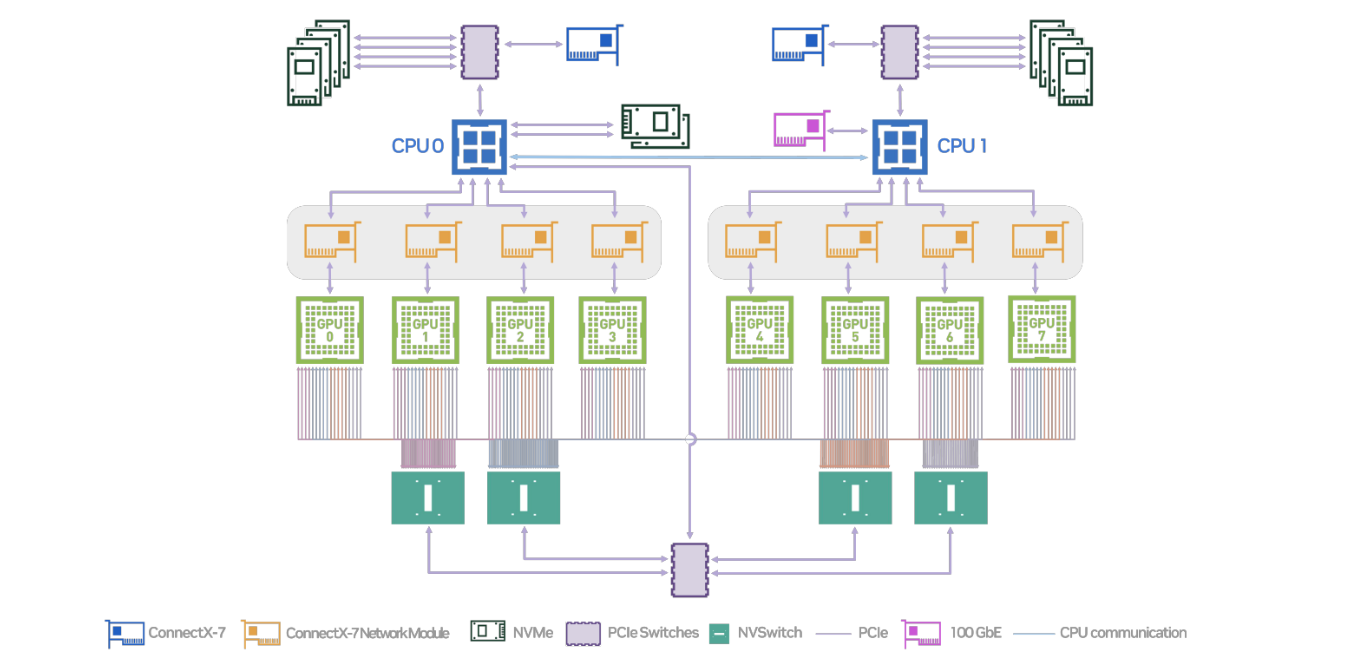
Основные компоненты, которые представлены на логической схеме:
- два блока CPU (CPU0 и CPU1), которые координируют работу системы;
- восемь GPU, распределенных между двумя CPU;
- PCIe — высокоскоростное соединение между компонентами;
- NVLink — соединение между GPU для быстрой передачи данных;
- NVSwitch — коммутаторы NVLink для объединения всех GPU в единую сеть;
- сетевые модули ConnectX-7 и NVMe для сетевых соединений и хранения данных.
Если выделить общие основные компоненты, из которых состоит сервер и где могут быть задержки, все будет выглядеть примерно так:
| Компонент сервера | Фактор, влияющий на возникновение задержек |
| CPU | Количество процессоров/ядер, их тактовая частота, поддерживаемые инструкции, размер кэшей и т. д. |
| GPU | Количество SM, их тактовая частота, наличие тензорных ядер, объем памяти и т. д. |
| RAM | Объем, пропускная способность, способ подключения и т. д. |
| PCI | Частота, разрядность, пропускная способность и т. д. |
| Storage | Объем, пропускная способность, способ подключения и т. д. |
| Network | Скорость передачи, физическое расстояние до источника данных, наличие RDMA и т. д. |
При этом мы рассматривали сервер on-premise. А что если мы перейдем в облако?
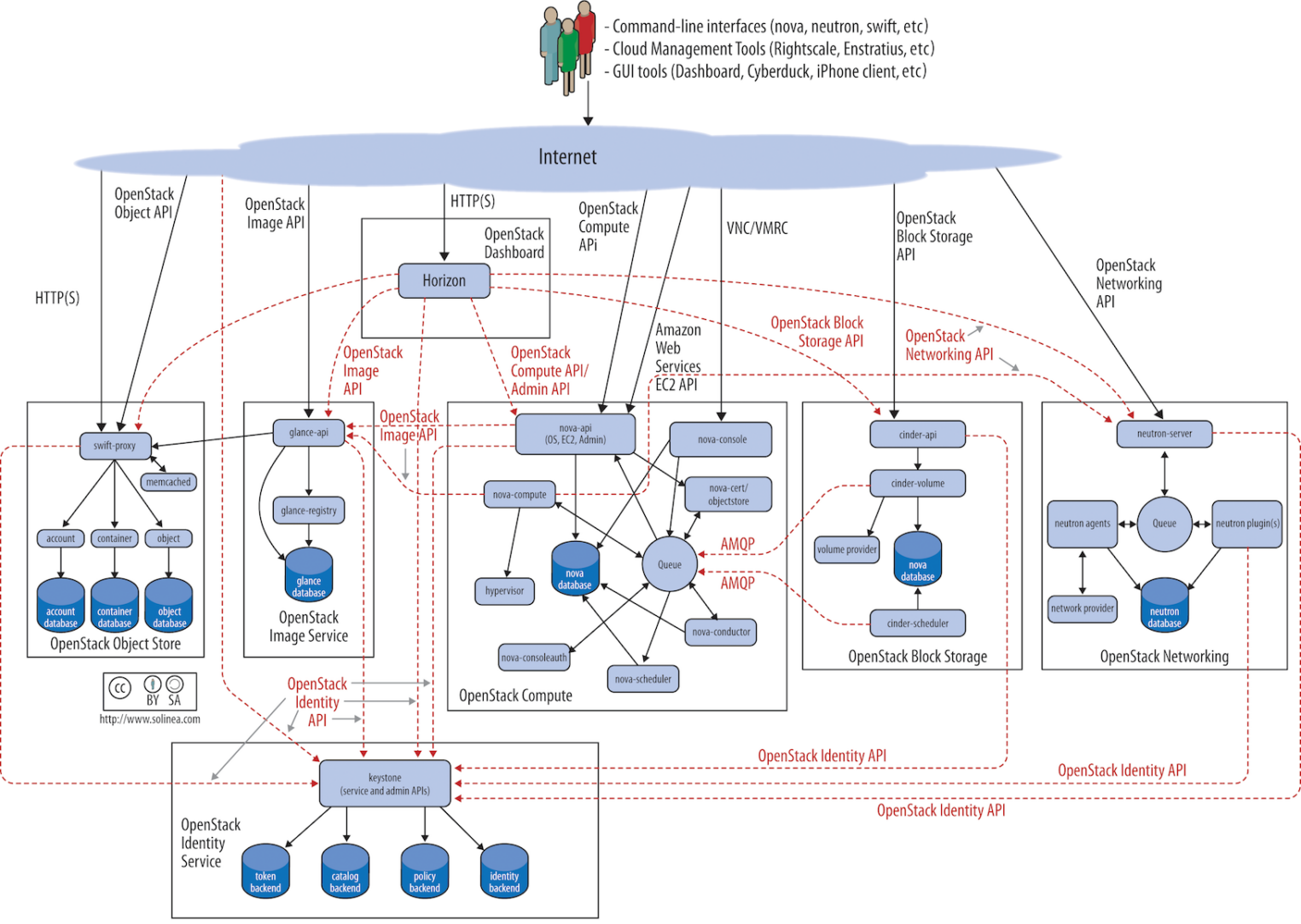
Облако для создания ML-системы дает свои преимущества, но вместе с тем вызывает сложности. Рассмотрим их подробнее.
Преимущества
- С инфраструктурой можно работать как с кодом (IaC).
- Можно задать лимиты и квоты для ресурсов.
- Ресурсы можно использовать по модели pay-as-you-go, т. е. по фактическому потреблению.
Сложности
- Вместо физических компонентов используются их виртуальные клоны.
- Возникают дополнительные задержки из-за виртуализации и ограничений сети.
- Отсутствует непосредственный доступ к физическим хостам, если используем managed-облако.
Но это мы говорили про хардварную часть. А что на уровне софта? Вспоминаем наш инференс-граф и ML-систему в целом, особенно пайплайн обучения:
На каждом этапе могут быть задержки, которые влияют на систему в целом. И это снова задержки обработки и транспортировки, как на заводе.
Итак, в общих чертах мы разобрались, из чего состоит ML-система, немного копнули в хардварную и софтварную части, а также выясняли, что она похожа на заводские конвейеры (из моей предыдущей статьи можно понять, что я в прошлом заводской работяга). Возникает вопрос: какие минимальные технические требования могут быть предъявлены к этому конвейеру? Попробуем разобраться.
Как конфигурировать инфраструктуру под ML-нагрузки
Ищем минимальный набор ресурсов
В нашем случае речь идет о данных, на которых мы будем проводить обучение, о моделях, которые мы хотим протестировать, о способах обучения и так далее. То есть нам нужно выбрать, какое минимальное количество ресурсов необходимо, чтобы обучать модели.
Мы опирались на Hugging Face и Coursera. Эти источники детально описывают, куда будет расходоваться память в цикле обучения.
Рассмотрим пример, в котором есть:
- инференс LLM на миллиард параметров,
- full precision (32-bit float),
- сохранение LLM в видеопамяти GPU.
Расчеты говорят о том, что на каждый параметр LLM требуется четыре байта видеопамяти. То есть на модель с миллиардом параметров нужно выделить 4 ГБ видеопамяти. Звучит не так уж и страшно.
1 параметр = 4 байта (32-bit float)
1B параметров = 4 ГБ
Но модель же нужно не только сохранить. Ее еще нужно обучать, поэтому потребуется optimizer, расчет промежуточных значений активационных функций и т. д. Все это добавит еще какое-то количество памяти:
- optimizer — 8 байт на параметр,
- градиенты — 4 байта на параметр,
- активационные функции — 8 байт на параметр.
Итого: обучение модели требует дополнительно 20 байт видеопамяти на каждый ее параметр.
И это мы еще не учитываем батч данных, который тоже нужно положить на видеокарту. Сделав несложный расчет, понимаем: чтобы просто обучать модель, нужно иметь 24 ГБ видеопамяти на каждый миллиард ее параметров.
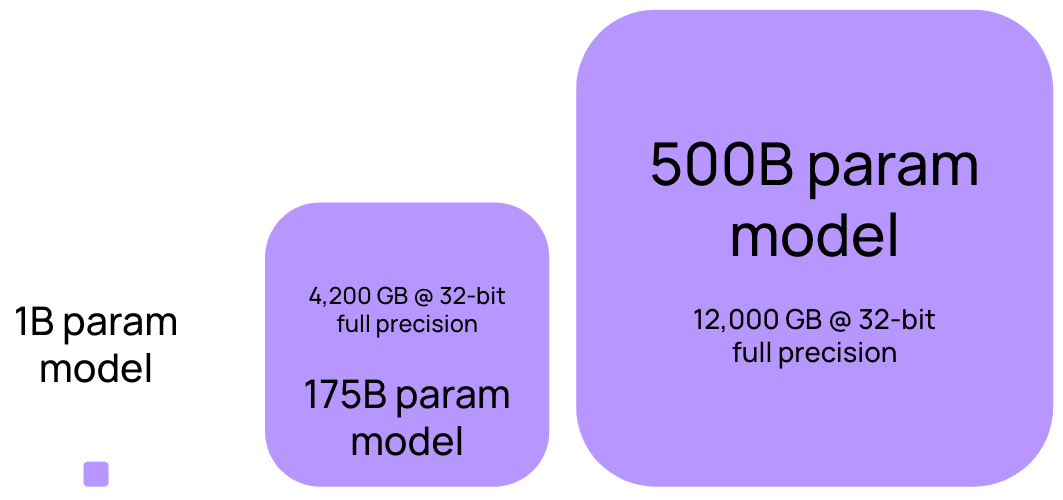
Подобный гайд можно использовать, чтобы рассчитать ресурсы для обучения модели: сколько понадобится памяти видеокарты, оперативной памяти, данных для сохранения промежуточных весов сети и данных, на которых будем обучать модель.
Получается, для любых задач просто берем видеокарту помощнее? Нет. Мы рассмотрели достаточно поверхностный и не оптимальный случай. В реальной жизни такой расчет используется только для обучения LLM с нуля.
Если же мы файнтюним модель, можно применить адаптеры. Для инференсов применимы квантизация, дисцилирование и другие способы оптимизации. Подробнее об этом можно почитать в статье Nvidia.
Применяем теорию Голдратта — ищем узкие горлышки
Хорошо, мы подобрали минимальную конфигурацию, от которой можно отталкиваться. Что дальше?
Вновь обратимся к заводам. Мне очень нравится книга «Цель» Элияху Голдратта. В ней автор доступно объясняет, как выглядит процесс непрерывного совершенствования на основе теории ограничений. Она предусматривает следующие этапы (распишу с примерами из книги):
- Поиск ограничений — узких горлышек. Главный герой Алекс и его команда анализируют производственный процесс и обнаруживают, что основным ограничением является печь для обработки деталей. Она работает медленно и является узким местом, которое замедляет весь процесс.
- Максимально эффективное использование узкого места. Команда планирует работу таким образом, чтобы печь была загружена постоянно. Это минимизирует время ожидания между ее загрузками.
- Подчинение остальных элементов системы ограничению. Весь производственный процесс перестраивается вокруг работы печи. Это включает в себя организацию работы так, чтобы другие процессы не создавали излишнего запаса перед печью и не задерживали работу после печи.
- Увеличение пропускной способности ограничения. Алекс рассматривает возможности для повышения производительности печи: модернизацию оборудования, улучшение методов работы, добавление дополнительной печи.
- Проверка, осталось ли данное звено ограничением, и возврат к первому шагу. После устранения или ослабления ограничения с печью команда анализирует процесс заново, чтобы выявить новое ограничение и повторить цикл улучшения.
На заводах это работает классно! Что ж, применим эту теорию на наших ML-системах? Начнем с поиска узких мест. И в этом нам поможет профайлинг.
Ищем узкие горлышки с помощью профайлинга
Профайлинг — это процесс анализа и оптимизации производительности программного обеспечения. В контексте машинного обучения профайлинг помогает выявлять узкие места в коде, которые замедляют обучение или инференс моделей. Существует несколько инструментов для профайлинга, каждый из которых имеет свои особенности и преимущества.
| Профайлер | Описание | Особенности |
| PyTorch Profiler | Позволяет анализировать производительность моделей, написанных на PyTorch. Предоставляет информацию о затратах времени на выполнение различных операций, что помогает выявить узкие места и оптимизировать код. | Интеграция с TensorBoard для визуализации данных. Поддержка профайлинга на CPU и GPU. Поддержка анализа данных в формате Chrome Tracing. Для отображения трейсинга лучше использовать Perfetto UI или FlameGraph Также используем TensorBoard + PyTorch Profiler TensorBoard Plugin |
| TensorFlow Profiler | Инструмент для анализа производительности моделей, созданных на TensorFlow. Помогает оптимизировать обучение и инференс, предоставляя подробные отчеты о производительности. | Визуализация данных в TensorBoard. Анализ использования памяти и вычислительных ресурсов. Поддержка различных профайлинговых режимов для детального анализа. Как и с PyTorch, для отрисовки используем TensorBoard + TF Profiler |
| NVIDIA Nsight Systems | Инструмент для системного профайлинга, который предоставляет подробные данные о производительности всего приложения. Помогает выявлять узкие места на уровне системы и оптимизировать использование ресурсов. | Подробный анализ производительности CUDA-ядер. Поддержка различных метрик и визуализация данных. Интеграция с другими инструментами NVIDIA. |
| NVIDIA Deep Learning Profiler (DLProf) | Инструмент для высокоуровневого профайлинга моделей глубокого обучения. Помогает оптимизировать обучение и инференс, предоставляя отчеты о производительности и использовании ресурсов. | Высокоуровневый анализ производительности моделей глубокого обучения. Интеграция с Nsight Systems для детального анализа. Поддержка анализа данных в TensorBoard. |
| eBPF (Extended Berkeley Packet Filter) | Технология для анализа производительности на уровне ядра операционной системы. Позволяет собирать данные о производительности системы в реальном времени и помогает выявлять узкие места в коде. | Низкоуровневый анализ производительности. Поддержка реального времени. Интеграция с различными инструментами для анализа данных. |
Отлично, мы нашли узкие горлышки в нашей системе. Дальше по теории ограничений необходимо максимально эффективно утилизировать их.
Как эффективно утилизировать подобранную конфигурацию ML-инфраструктуры
Конвейер обучения
Посмотрим на типичные узкие горлышки в конвейере обучения.
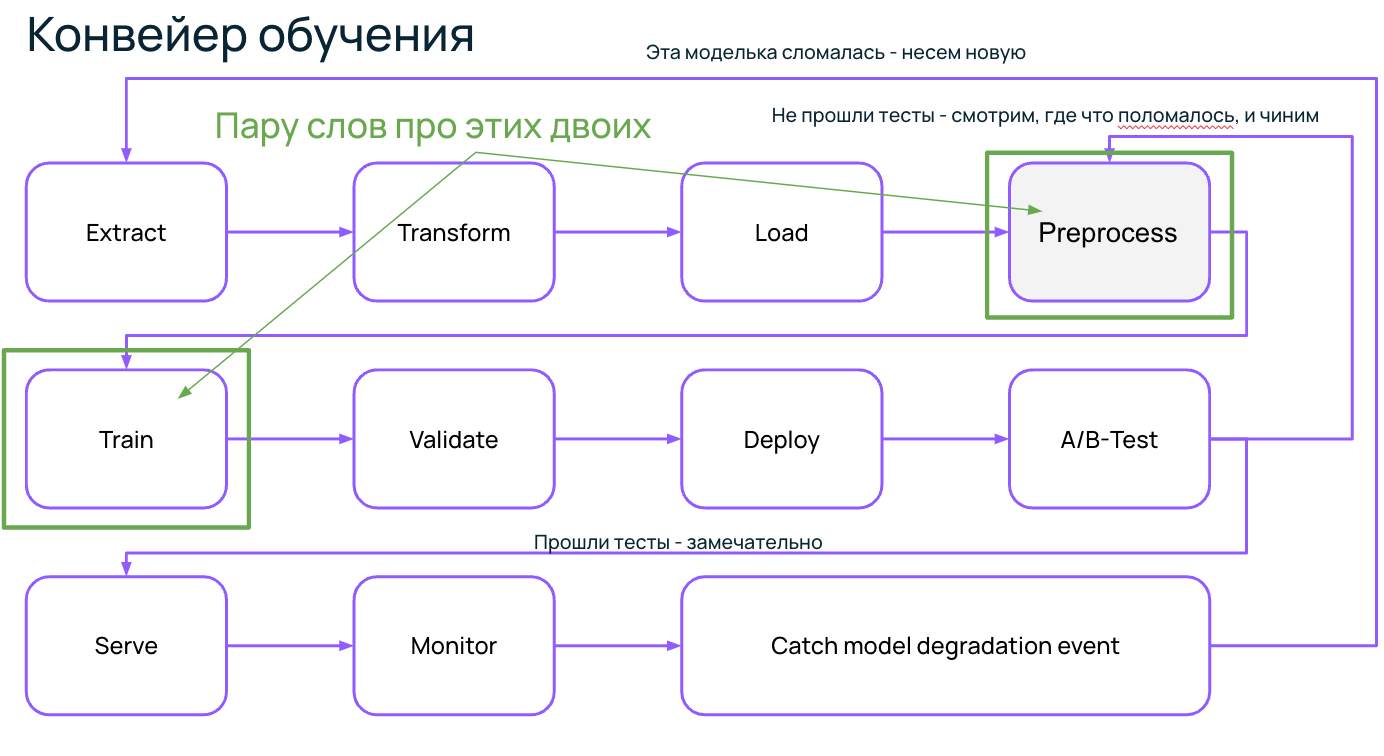
Больше всего, конечно, хочется сказать про Preprocess и Train. Допустим, мы решаем CV-задачу, где нужно часто играться с изображениями: покрутить, повертеть, наложить фильтры и т. д. В фреймворке MMCV такие трансформации выполняются на CPU. Но в это время процессор простаивает, а это самый дорогой ресурс, который хочется использовать рационально.
Поэтому если можно вынести что-то из цикла тренировки модели, мы это делаем. А если не получается, то хотя бы пробуем перенести трансформации с CPU на GPU.
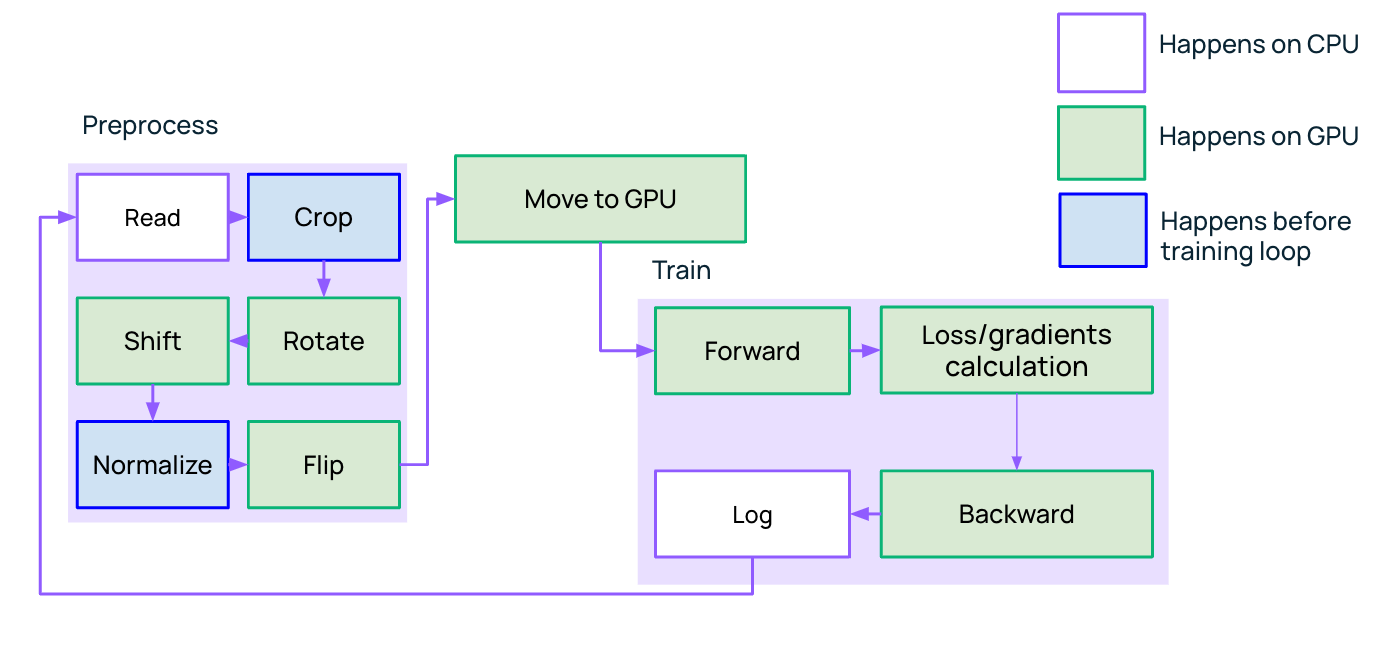
Кстати, для такой задачи могут быть полезны инструменты из экосистемы RAPIDS от Nvidia. Например, фреймворк QDF, который позволяет работать с табличными данными. Или, если необходимо работать с изображениями, то можно использовать Data Loading Library от NVIDIA. С ее помощью можно составлять пайплайны с трансформациями: повернуть, развернуть, обрезать, центровать и т. д.
Итак, выстраиваем обучение LLM, вдохновившись заводом. То есть ставим дополнительный конвейер. Параллелить обучение можно различными способами, например с помощью Data Parallelism.
Конвейер инференса
Мы обучили модель. Теперь нужно обернуть ее в удобный интерфейс, чтобы клиенту было комфортно работать с LLM. Подойдет, например, gRPC или HTTP веб-сервер. Его можно написать самостоятельно, взяв Flask или Fast API. А можно взять готовое open source решение Triton Server — ребята из Nvidia точно знают, как по максимуму утилизировать в инференсе свои GPU.
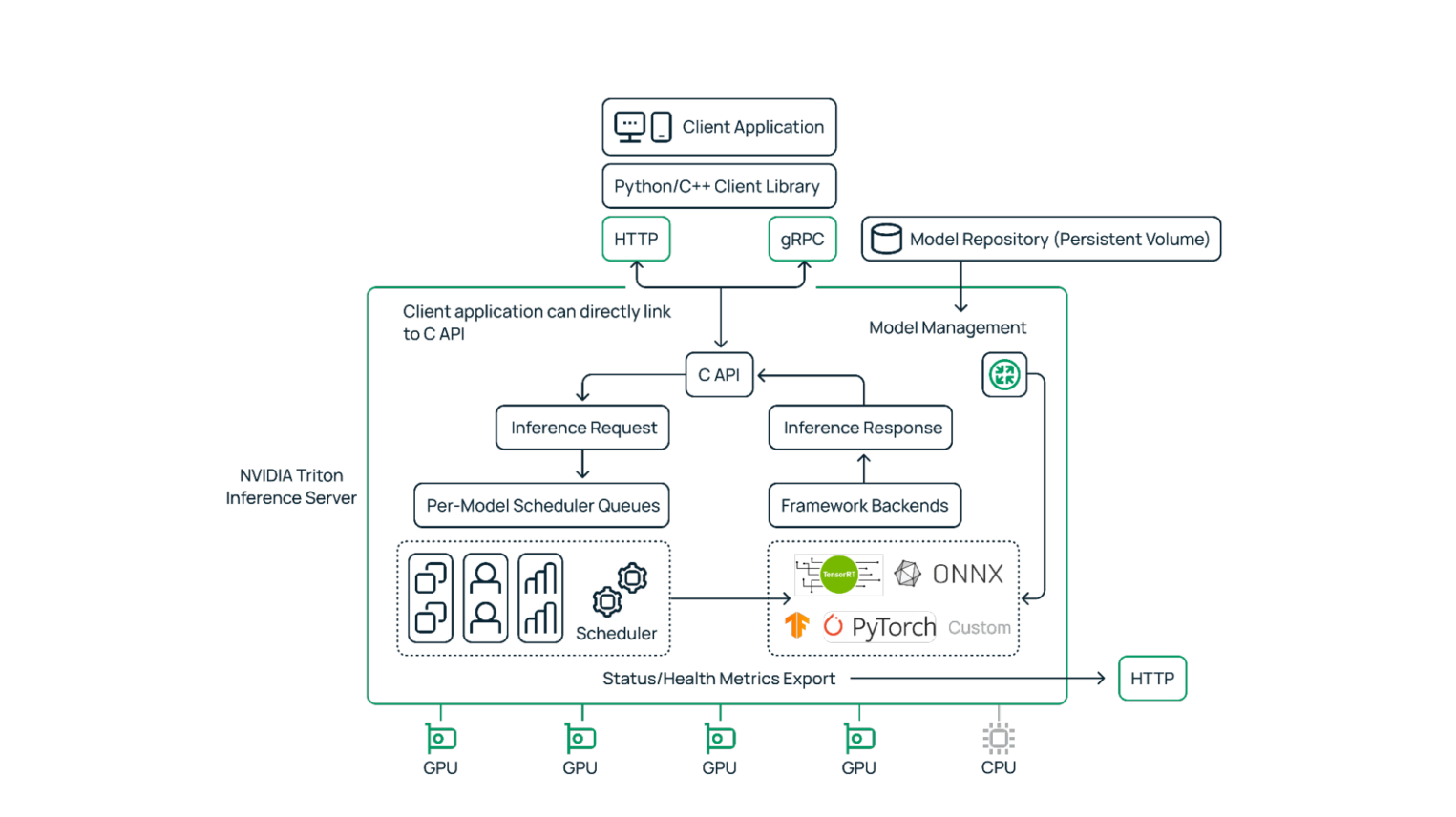
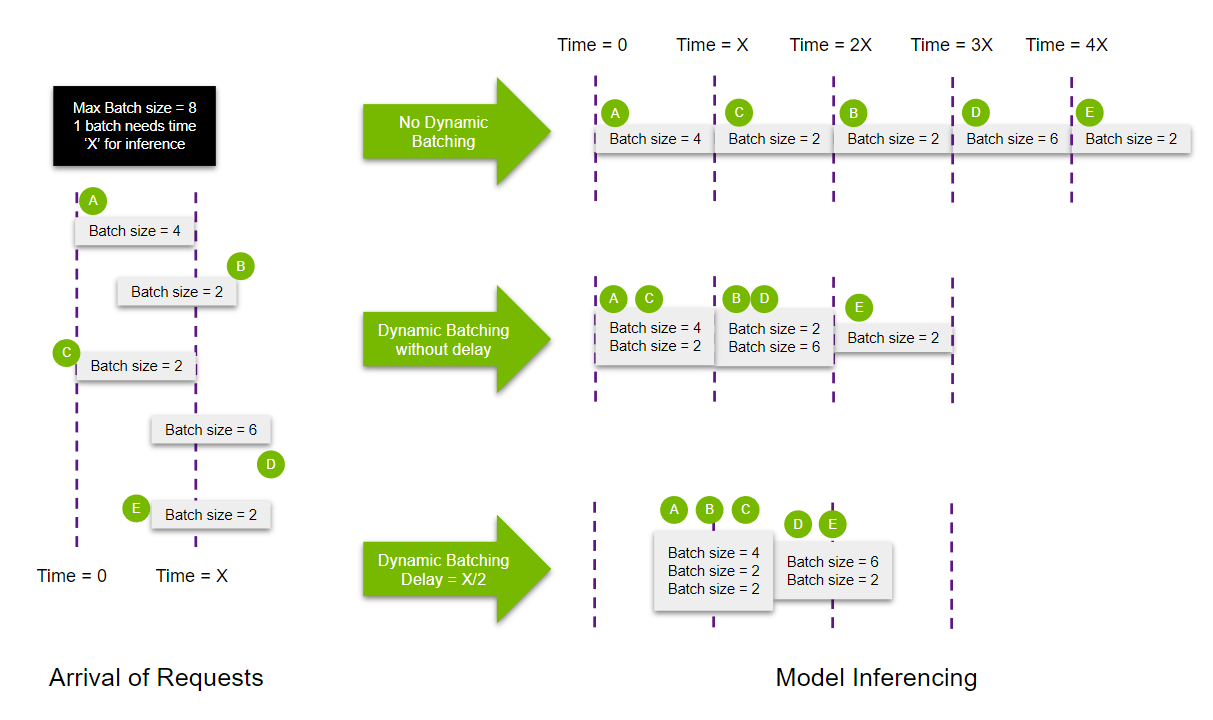
Оптимизация моделей + правильно подобранная конфигурация Triton Server = максимальная утилизация инференса на инфраструктуре. Triton позволяет настроить динамический батчинг запросов, который увеличивает пропускную способность сервера. Мы получили следующие результаты на небольшой модели:
- было: 216 infer/sec без батчинга,
- стало: 300 infer/sec с динамическим батчингом.
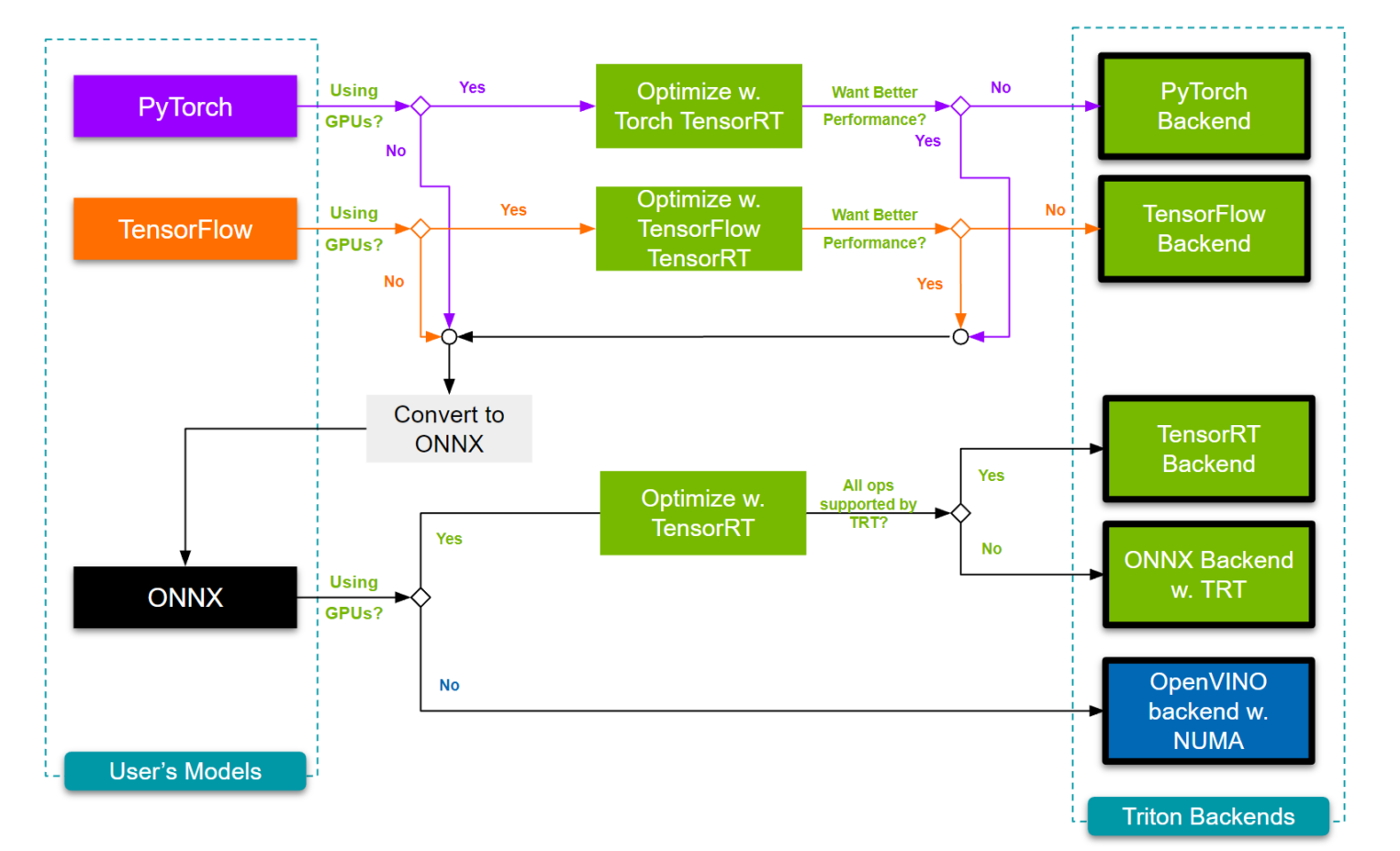
Так же можно конвертировать модель в различные форматы:
- было: ONNX FP32 — 450 infer/sec,
- стало: TensorRT FP16 — 2600 infer/sec.
Когда один Triton Server не будет справляться, применим лайфхак с завода — поставим еще одну реплику. Но для инференсов не нужно иметь мощные GPU, так как мы можем сжимать модели (вспомним пример выше, где на миллиард параметров модели занимает 4 ГБ).
Соответственно, возникает вопрос: как параллельно запустить несколько инференсов на одной GPU? Ответ вы найдете в цикле моих статей про шеринг GPU:
- «Практическое пособие по работе с MIG»,
- «ШерингGPU с помощью MIG и TimeSlicing»,
- «Динамический шеринг GPU в Kubernetes с помощью MIG, MPS и TimeSlicing».
Сейчас же рассмотрим возможные решения:
| Технология | Архитектура GPU | Изоляция памяти | Максимальное количество реплик |
| MIG | Nvidia Ampere + | Изоляция памяти на уровне железа | Семь партиций максимум на A100 |
| MPS | Nvidia Volta + | Изоляция памяти на уровне CUDA | 48 потоков максимум |
| TimeSlicing | Nvidia GPU | Нет изоляции по памяти | Любое количество |
При этом Triton Server внутри одной реплики также может управлять различными моделями. Если он справляется с нагрузкой, можно деплоить LLM в один сервер. Как только перестает справляться, начинаем параллелить реплики.
Заключение
Возможно, вы задаетесь вопросом: зачем было вообще рассказывать про заводы и производства в материале об ML? Отвечу вам цитатой из книги «Совершенный код» С. Макконнелла:
Проведение аналогий часто приводит к важным открытиям. Сравнив не совсем понятное явление с чем-то похожим, но более понятным, вы можете догадаться, как справиться с проблемой.
ML-системы достаточно сложны и объемны. Подбор конфигурации и ее максимальная утилизация — нетривиальные задачи. Универсального алгоритма для этого пока нет, но решение конкретной проблемы всегда можно найти в дискуссии. Приглашаю вас в комментариях обсудить, как вы подбираете конфигурацию инфраструктуры и утилизируете ее в своих задачах.
И напоследок поделюсь небольшими рекомендациями и источниками:
Обучение
- Книга Таненбаума и Остина «Архитектура компьютера».
- Hugging Face: «Model training anatomy».
- Hugging Face: «Quantization».
- Hugging Face: «A Gentle Introduction to 8-bit Matrix Multiplication for transformers at scale using Hugging Face Transformers, Accelerate and bitsandbytes».
- Hugging Face: «Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA».
- Ahead of AI: «Improving LoRA: Implementing Weight-Decomposed Low-Rank Adaptation (DoRA) from Scratch».
- Туториал от PyTorch: «Profiling your PyTorch Module».
- Туториал от PyTorch: «PyTorch Profiler With TensorBoard».
- Документация от PyTorch: «Profiling to understand torch.compile performance».
- Гайд от TensorFlow: «TensorFlow Profiler: производительность модели профиля».
- Видео: «Profiling Deep Learning Applications with NVIDIA NSight».
- Видео: «CUDA Developer Tools | Memory Analysis with NVIDIA Nsight Compute».
- Видео: «Profiling with DLProf Pytorch Catalyst part 1».
- Гайд по eBPF на GitHub.
- Документация по RAPIDS.
- Документация по Data Loading Library от Nvidia.
- Hugging Face: «Efficient Training on Multiple GPUs».
- Серия видео о параллелизме и распределении данных.
- Серия видео по PyTorch FSDP.
Инференс
- NVidia: «What Is MLOps?».
- ml-ops.org: «MLOps Principles».
- Видео: «Mastering LLM Techniques: Inference Optimization».
- Туториал на GitHub: «Dynamic Batching & Concurrent Model Execution».





