Привет! С вами Антон Алексеев, DevOps-инженер в Selectel. Недавно на DevOps Conf я рассказал, как мы в отделе DataML-продуктов используем GitLab и Terraform, чтобы деплоить облачную платформу за 24 минуты вместо восьми часов, избавиться от костылей на серверах и получать больше удовольствия от работы. Вот ссылка на сам доклад. В этой статье я поделюсь этим опытом и дополню свой рассказ примерами. А для самых терпеливых оставлю ссылку на бесплатный двухнедельный тест той самой платформы.
Как я вдохновился IaC
Попытки удержать Dev и Prod в одной среде
На прошлой работе я поддерживал инфраструктуру и разрабатывал различные продукты. Иногда наша команда проводила незапланированные демо. Нас просто ставили перед фактом: через четыре часа придут заказчики, нужно показать им продукты, которые мы разрабатываем.
Проблема была в том, что у нас и Dev, и Prod, по сути, были в одном окружении: там мы вели и разработку, и показы. Соответственно, из-за запуска демо во время активной разработки что-то могло отвалиться и приходилось вручную это исправлять. А если исправляешь руками что-то на сервере, получаешь нечто, что можно назвать «сервером-снежинкой». Снежинка, потому что это что-то уникальное. Второго такого сервера нет и не было, он доступен в понимании только тебе и больше никому. И ты превращаешься в узкое горлышко внутри отдела, а это плохо: если уйдешь в отпуск или уволишься, коллеги начнут выполнять ежедневные квесты, пытаясь понять, как там на сервере все устроено.

Но ведь можно же было каждое ручное изменение на сервере описывать в документации? Теоретически да, но на деле это не считалось чем-то важным и нужным. Приоритезация задач велась по модели «кто громче попросит», поэтому вместо описания изменений мы просто шли делать новые изменения, создавая очередной «сервер-снежинку». Возможно, вы узнали себя в этом опыте. А также заметили, что похожую историю проживает персонаж по имени Брент Геллер в книге «Проект “Феникс”. Роман о том, как DevOps меняет бизнес к лучшему».

Рекомендую ее к прочтению для вдохновения и изучения DevOps и IaC. Ведь именно эта книга во многом дала мне понять, что текущие процессы весьма сомнительны и что нужно что-то менять в этой жизни.
Как я получил страх деплоя в прод
С одной стороны, наступая на промышленные грабли, я вдохновился изучать новые подходы к управлению инфраструктурой. С другой — приобрел страх деплоить сразу в прод. Возможно, кому-то из вас это знакомо, но я хочу описать свой опыт.
Этот страх, или даже психологическая травма, у меня еще со времен магистратуры. Ее я получил на заводе, где программировал контроллеры. Предприятие производило кофе, там была упаковочная конвейерная линия: по ней шли пустые банки, в них насыпался кофе, сверху закручивались крышки, все это упаковывалось в паллеты. И вот, мне нужно было внести изменение в программу контроллера.
Оговорюсь, что в АСУТП (автоматизированной системе управления технологическим производством) на многих производствах применяются весьма специфичные подходы к разработке. Регламенты отсутствуют, оборудование покупают сразу с софтом у разных поставщиков, каждый из которых программирует как хочет. В общем, все происходит в хаосе. Деплой новых изменений выглядел так: я приходил на упаковочную линию, вставал возле шкафа управления, через витую пару подключал к контроллеру ноутбук и заливал изменения без автотестов или проверок.
Однажды я залил изменения, где ссылался на несуществующий участок памяти. Из-за отсутствия блока try-catch контроллер ушел в стоп, конвейерная линия остановилась, попадали банки, операторы и инженеры начали бегать и кричать. Одно дело, когда у тебя в логах слово «error», совсем другое — когда видишь, что это оборачивается хаосом, остановкой оборудования и полным непониманием, что тебе делать.

После того случая я стал тратить больше времени на проверки даже незначительных изменений. Время разработки увеличилось в несколько раз, уровень стресса заметно повысился, я столкнулся с выгоранием, усталостью и болезнью.
Итак, резюмирую свой опыт.
- Если у вас нет отдельной инфраструктуры для теста, стейджа и продакшена, вы будете делать «серверы-снежинки» с ручными костыльными переделками и получать что-то уникальное, что доступно только вам.
- Решение в голове одного человека — узкое горлышко. Если этот человек уйдет в отпуск или уволится, у команды будут проблемы.
- Деплоить в прод без автотестов и регламентов — верный путь к паническим атакам.
Как я познал IaC и DevOps
Чуть больше года назад, уже в Selectel, я познакомился с подходом IaC, Infrastructure as a Code. Главное, что я отметил: инфраструктура, описанная кодом, легко воспроизводится. Например, первый проект, с которым я столкнулся в Selectel, — деплой файлового хранилища Selectel, или SFS (кстати, сейчас мы используем уже обновленную версию). Как происходило подключение клиентов в SFS? У нас был заготовлен пайплайн в GitLab, который поднимал виртуальную машину в нашем облаке с помощью Terraform — далее джоба с Ansible настраивала ее под NFS- или SMB-хранилище. Именно эта связка познакомила меня с реализацией IaC.
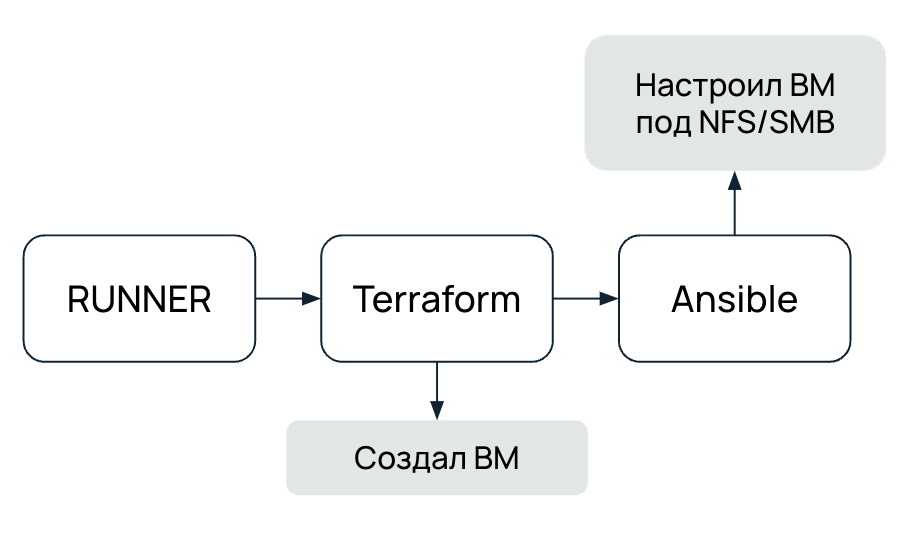
Я заметил такую вещь: если подключение нового клиента произошло с ошибкой, нам проще задестроить установленное хранилище и задеплоить его заново, чем искать проблему в неправильно установленном SFS. Такой подход создает полную противоположность «серверов-снежинок» — «серверы-фениксы». После смерти они могут полностью повторить свое состояние, если родятся заново.

Наконец, при таком подходе решается проблема с отсутствием документации. Я пишу код, закидываю в GitLab, спокойно ухожу в отпуск, а мой коллега читает этот код-документацию и понимает, как все работает. Подход также отлично решает проблему онбординга новых сотрудников. К нам вышел стажер и спустя неделю уже разобрался в проекте, освободив инженеров от операций с файловым хранилищем.
Но при этом на другом нашем проекте я столкнулся с таким антипаттерном, как ClickOps. Далее я расскажу, что это такое.
Что такое ClickOps. Разбираемся на примере ML-платформы
На второй месяц работы я наконец-то начал разбираться в новом продукте нашего отдела — ML-платформе. На ней специалисты обучают свои модели и деплоят их в продакшен. Частные инсталляции должны полностью выделяться конкретному клиенту внутри облака Selectel и подниматься в любом регионе в неограниченном количестве.
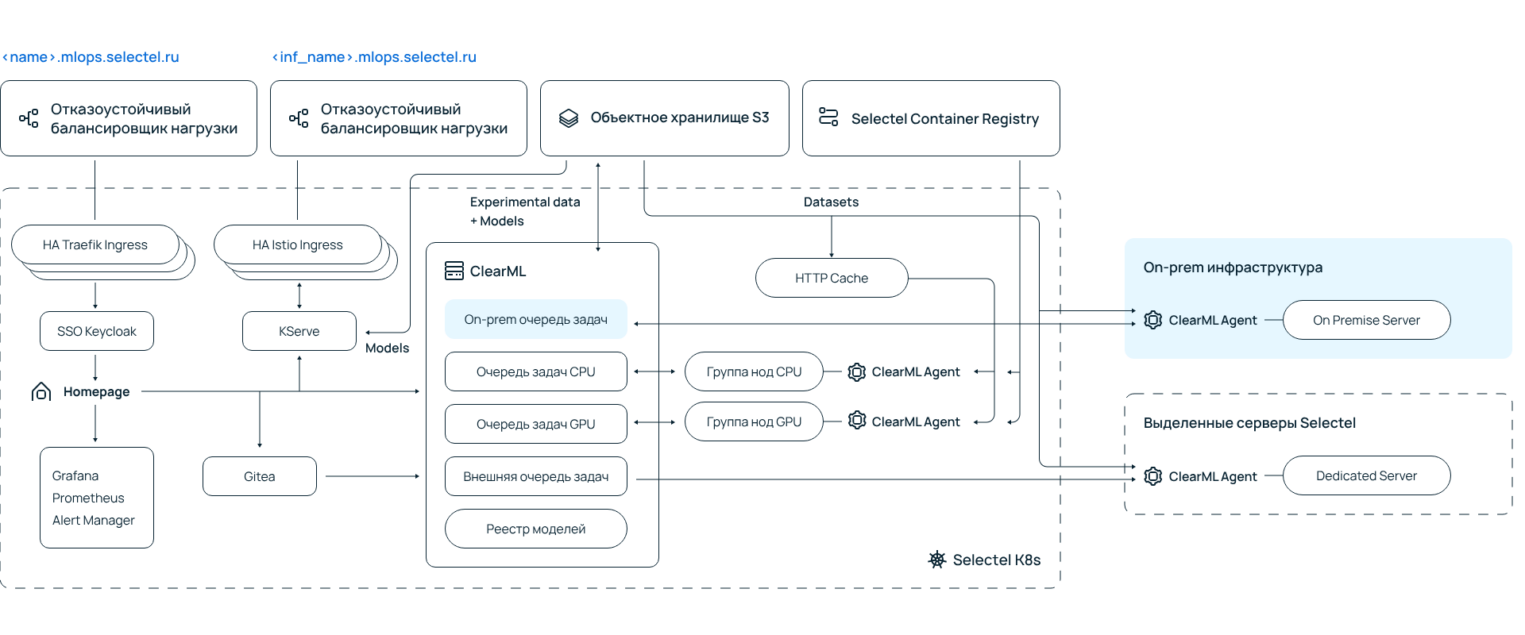
В архитектуре платформы в качестве инфраструктурных компонентов применяются объектное хранилище S3, файловое хранилище Selectel, реестр контейнеров (CRaaS) и Managed Kubernetes. Каждый из этих компонентов мы можем кастомизировать по требованиям клиентов.
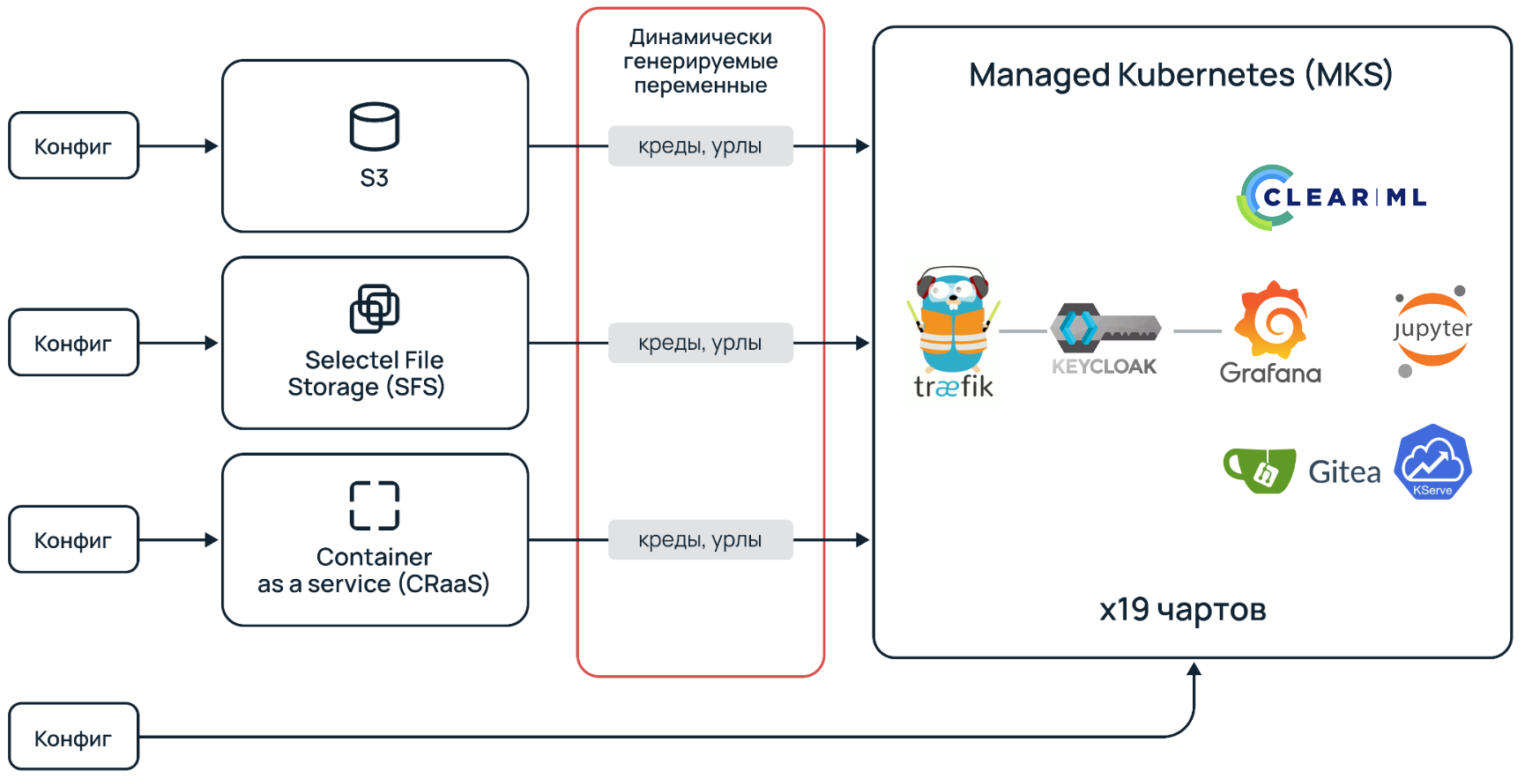
В Managed Kubernetes мы заливаем в среднем 19 чартов, которые должны настраиваться в определенной последовательности. И в эти чарты нам надо как-то передавать динамически генерируемые переменные из всех наших инфраструктурных компонентов.
В итоге мы имеем гигантскую портянку зависимостей. Это достаточно сложная схема, и, например, Helm-dependency в ней нормально не отработает. Нужно решение для динамического управления.
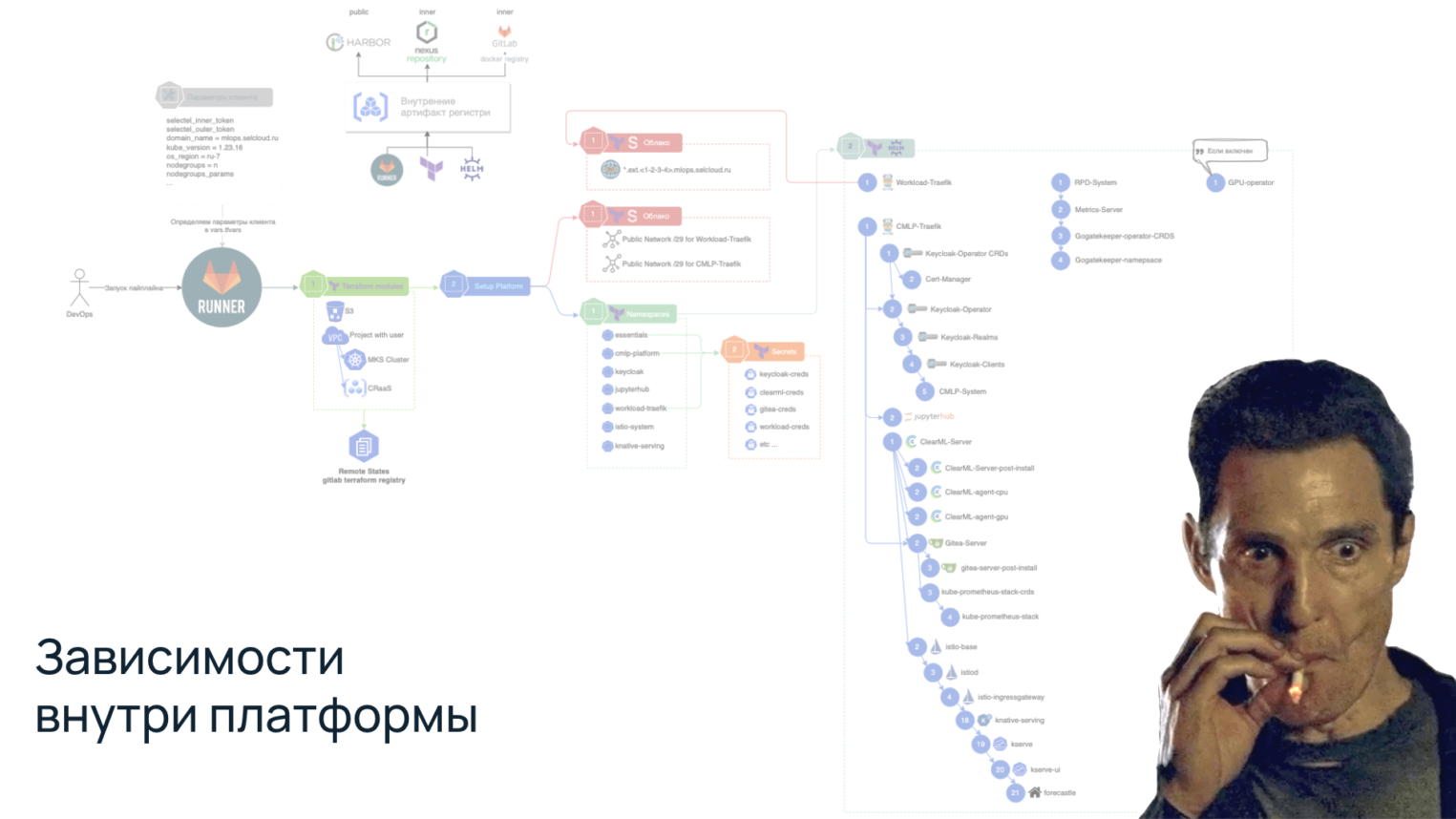
Познакомившись с платформой поближе, можно переходить к началу моей работы с ней. Первая задача заключалась в том, чтобы пойти в облако и ручками развернуть наши инфраструктурные компоненты: MKs, SFS, S3 и CRaaS. Затем взять конфигурацию K8s и положить в наш пайплайн, где уже Helm-ы будут накатывать наши сервисы в Managed Kubernetes.
Это занимало примерно два дня. При этом огромную роль здесь играет человеческий фактор, а также то, что это, по сути, рутинные повторяющиеся ручные операции. Вот мы и обнаружил так называемый антипаттерн ClickOps.
ClickOps — это подверженный ошибкам и трудоемкий процесс. Он сводится к тому, что выбор и настройка правильной автоматизированной вычислительной инфраструктуры выполняется вручную прокликиванием различных пунктов меню на сайтах поставщиков облачных услуг.
После того, как я получил психологические травмы на предыдущих местах работы (хорошо, что Selectel оплачивает депозиты на психотерапию своим сотрудникам) и вдохновился IaC и DevOps, мы начали автоматизировать деплой нашей платформы.
Избавляемся от ClickOps и автоматизируем деплой платформы
Итак, я выделил три этапа ухода от ClickOps к той схеме, которую мы используем сейчас. Думаю, в каждом из этих этапов вы сможете найти для себя что-то полезное.
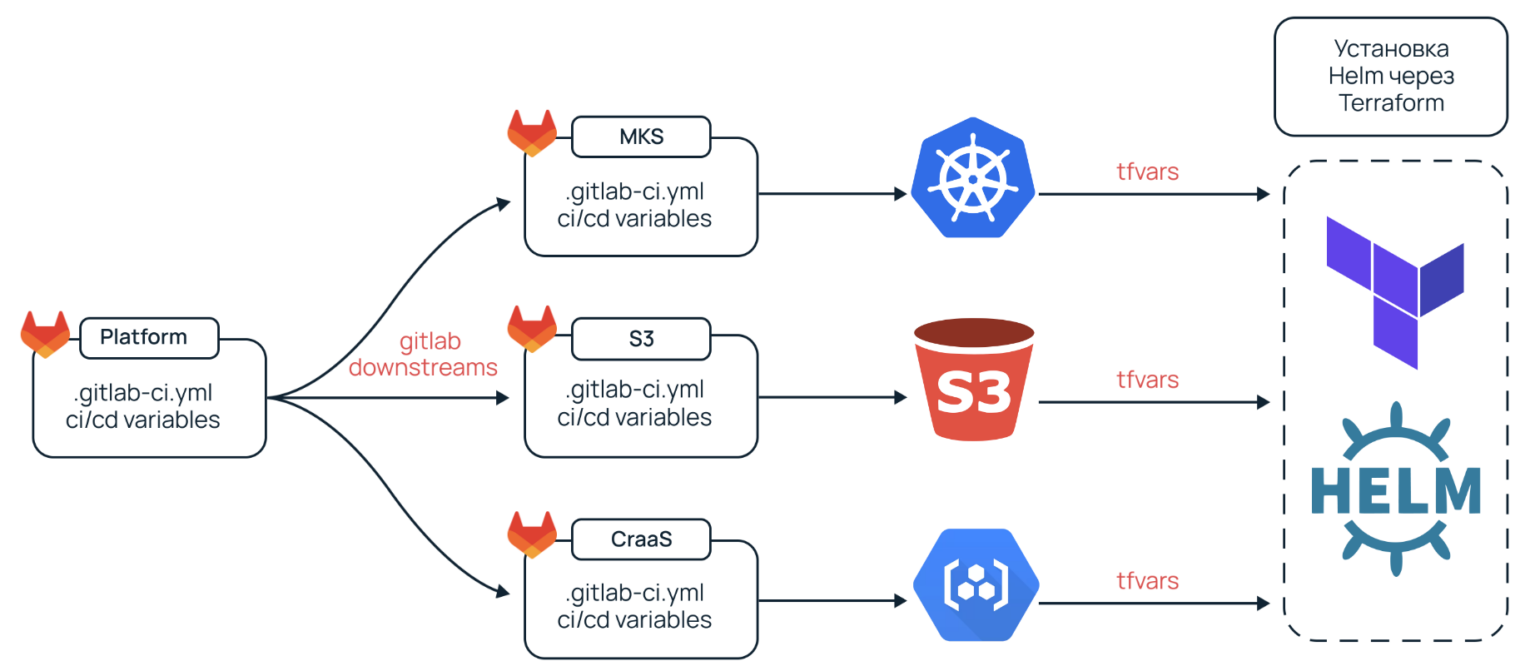
Первый этап. Даунстримы GitLab
Первым делом нужно было уйти от «накликивания» инфраструктуры в панели управления. Вот что мы сделали.
- Для каждого компонента завели отдельный репозиторий с Terraform-ом, который с помощью пайплайна по отдельности разворачивал каждый компонент.
- Добавили главный репозиторий с нашей платформой. Основной пайплайн в нем вызывал с помощью даунстрима каждый из пайплайнов наших компонентов.
- Из создаваемой инфраструктуры нужно было как-то передать сгенерированные динамические переменные (креды, ссылки и т. д.) в наши Helm-чарты, которые ставились в K8s.
- Каждый из чартов нужно было ставить в определенной последовательности. Для этого мы использовали Terraform.
Установка Helm через Terraform
Рассмотрим пример одного Helm-релиза, который мы устанавливаем в платформу. Структура достаточно проста, она повторяет обычный вызов консольной утилиты helm install. При этом в values мы переопределяем именно те параметры, которые кастомизируются в нашей платформе. По умолчанию стоят дефолтные параметры из чарта, который мы собрали в нашем отдельном репозитории.
В данном случае показан пример, как можно передавать динамически сгенерированные переменные, созданные в S3-хранилище, просто оперируя переменными Terraform. Все в одном формате, что очень удобно. Мы передаем tfvars-файлик в качестве артефакта из даунстрима пайплайна, который создал S3-бакет, и используем его при создании чартов в K8s. Также удобно передавать секреты, делая sensitive-переменные.
resource "helm_release" "clearml-server" {
name = "clearml-server"
repository = var.helm_repo_url
repository_username = var.helm_repo_user
repository_password = var.helm_repo_password
chart = "clearml"
version = "6.1.0"
atomic = true
wait = true
wait_for_jobs = true
namespace = kubernetes_namespace_v1.main-ns.metadata[0].name
create_namespace = true
timeout = 600
values = [
<<-EOT
clearml:
clientConfigurationFilesUrl: "s3://${var.s3_url}/${var.s3_bucket_name}"
EOT
]
depends_on = [
kubernetes_namespace_v1.main-ns,
helm_release.traefik,
helm_release.keycloak
]
}
Для управления зависимостями используется атрибут depends_on. Например, можно указать, что наш чарт должен установиться только после traefik и keycloak.
Добавлю, что такое использование Terraform-а можно сочетать с другими облачными ресурсами, например, в traefik, где для чарта необходимо создать запись в DNS. По сути, это делается с помощью ресурса облачного провайдера. Далее передаем результат сразу в Helm-release.
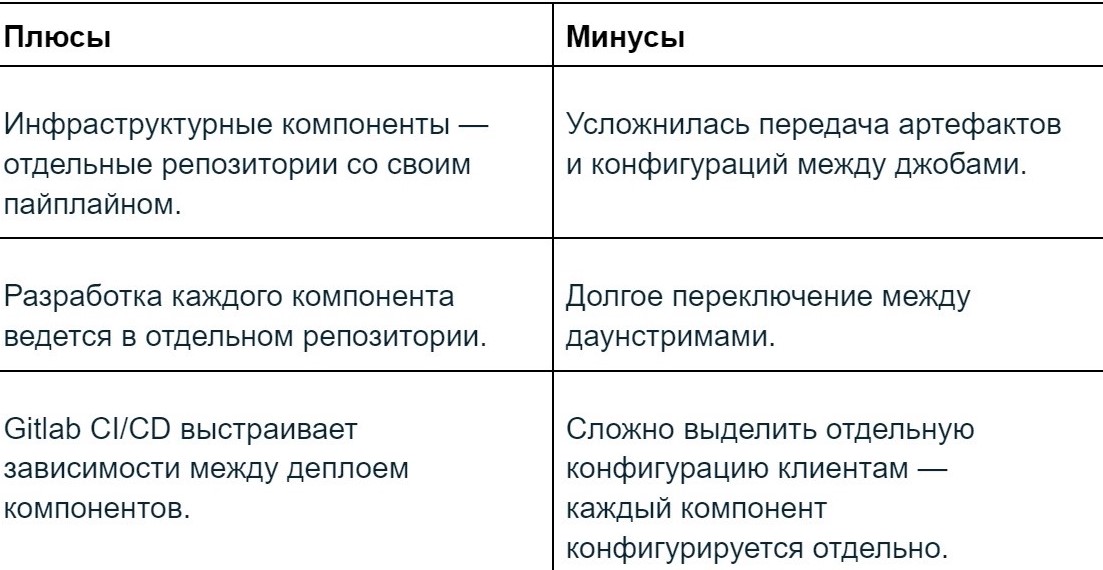
Выводы по первому этапу
Казалось бы, у нас появилась автоматизация, руками мы уже ничего не настраиваем. Но даунстримы очень тяжело передают между собой переменные. Чтобы их конвертировать, пришлось запускать дополнительные джобы. В итоге пайплайн сильно разросся и буквально перестал помещаться в экран. Пришлось закупить 34-дюймовые мониторы), а также появилось долгое переключение между джобами. Кроме того, в каждый компонент надо было заводить свой уникальный конфиг, а мы хотели найти унифицированное решение.
Далее мы решили избавиться от даунстримов GitLab.
Второй этап. Монолитная Terraform-джоба
Мы сохранили концепцию, при которой под каждый компонент есть отдельный репозиторий, но уже не вызывали их пайплайн, а запекали Terraform-код в отдельные модули и версионировали их. А модули, в свою очередь, запекали как артефакты в наш GitLab Registry. Так у нас появилась единая джоба, которая с помощью Terraform поднимает и инфраструктуру, и сервисы в ней. Мы привели все к единому стилю и упростили передачу динамически создаваемых переменных. Так Terraform стал передавать свои переменные, например, из S3 сразу в Helm-чарт).
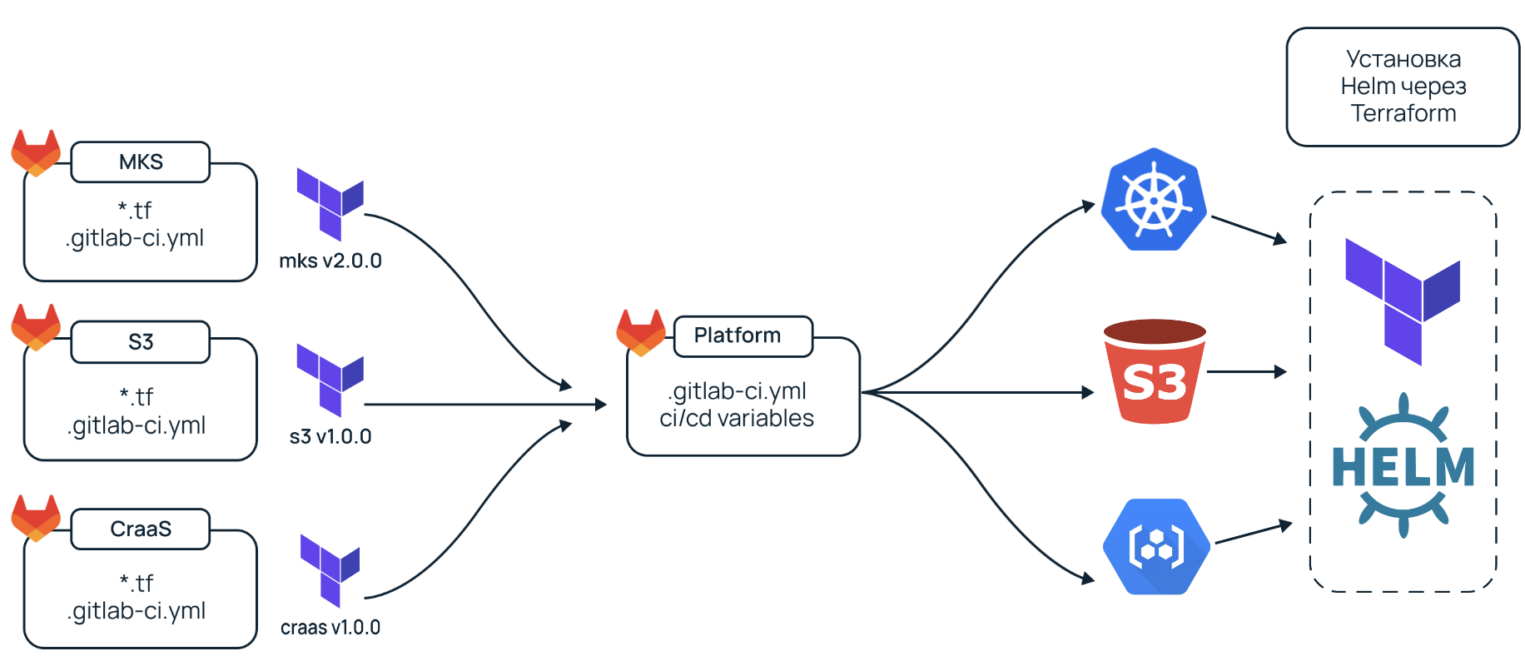
Запекание Terraform модулей
Запекание модулей означает, что мы весь Terraform конкретного компонента оборачиваем в модуль, версионируем и загружаем его в удаленный Registry. Далее в основной джобе вызываем конкретную версию модуля и передаем ему входные параметры.
module "mks" {
source = var.ci_registry
version = "2.0.0"
cluster_name = var.cluster_name
kube_version = var.kube_version
os_availability_zone = var.os_zone
…
}
Это также позволило нам вынести всю конфигурацию платформы в один файлик, откуда и забираются все переменные. Зависимости мы также регулируем через depends_on, но теперь помимо Helm-чартов Terraform контролирует и зависимости инфраструктурных компонентов друг от друга.
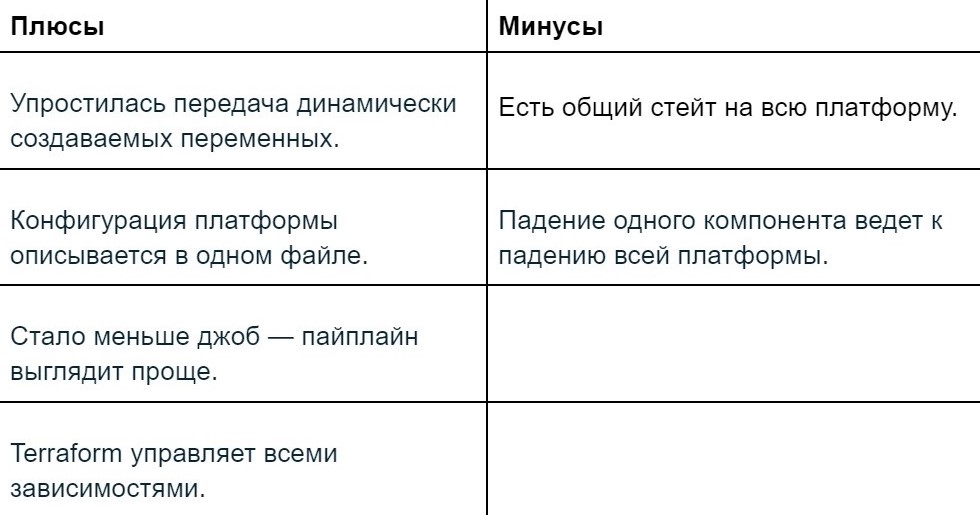
Выводы по второму этапу
Отлично — у нас все ставится с помощью Terraform, но мы получили монолит. Он, конечно, бывает удобен — например, там можно сформировать один конфигурационный файл, описать в нем все наши компоненты (допустим, размер SFS или S3), и одной конфигурацией передать в джобу, и в ней настроить Terraform-ом передачу переменных и зависимости. Допустим, чтобы первый Helm-чарт установился только после второго, третий — после поднятия инфраструктуры и так далее.
Так как мы хотели больше гибкости в отладке и деплое компонентов по отдельности, мы решили распилить наш монолит.
Третий этап. Как мы распилили монолит
Мы перешли к конечной версии нашего пайплайна. В ней монолитную джобу разбили на несколько. Теперь мы готовим конфигурационный файл и передаем его на каждую джобу отдельно, а она поднимает все инфраструктурные компоненты. При этом модули Terraform берутся из GitLab и версионируются, а для каждого компонента создается отдельный стейт.
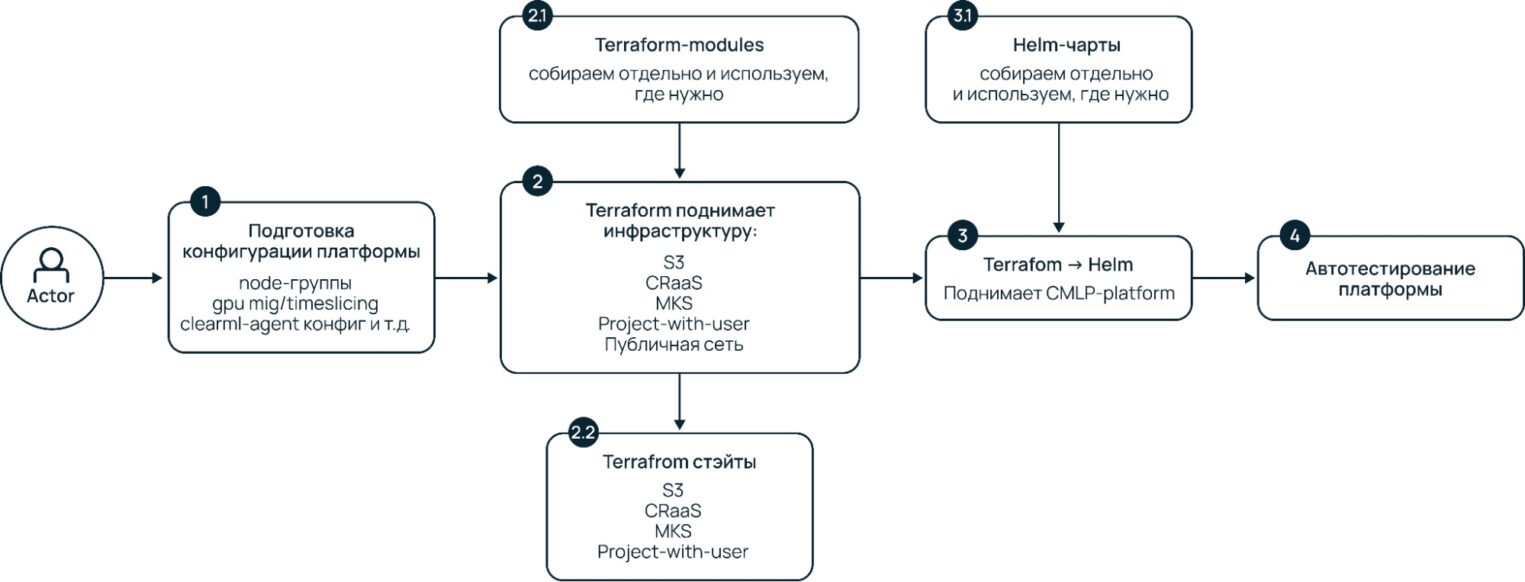
Но как мы теперь передаем генерируемые переменные в Helm-чарты от инфраструктурных компонентов? Мы используем Terraform remote state.
Terraform remote state
Так как мы храним отдельно стейт каждого компонента, теперь мы можем из его вывода просто забирать необходимые переменные. Terraform делает это (url, креды и прочее) через атрибут terraform remote_state и закидывает в Helm-ы. Пример такого data-ресурса представлен ниже.
data "terraform_remote_state" "s3_bucket" {
backend = "http"
config = {
address = var.CI_REGISTRY_URL
username = var.CI_TOKEN
password = var.CI_JOB_TOKEN
}
}
Это позволяет удобно передавать динамически генерируемые переменные между зависимыми компонентами.
Выводы по третьему этапу
Распилив монолит, мы смогли гибче отлаживать каждый компонент инфраструктуры, а деплой платформы теперь не валится при ошибках деплоя.
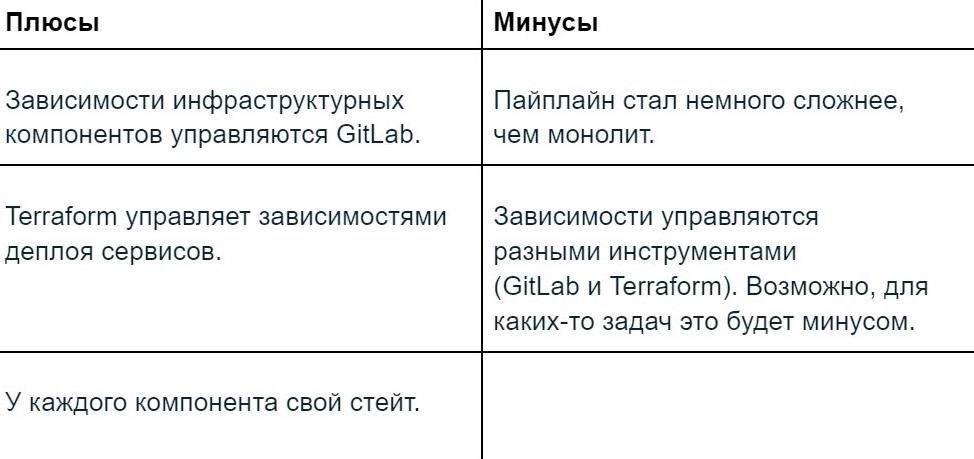
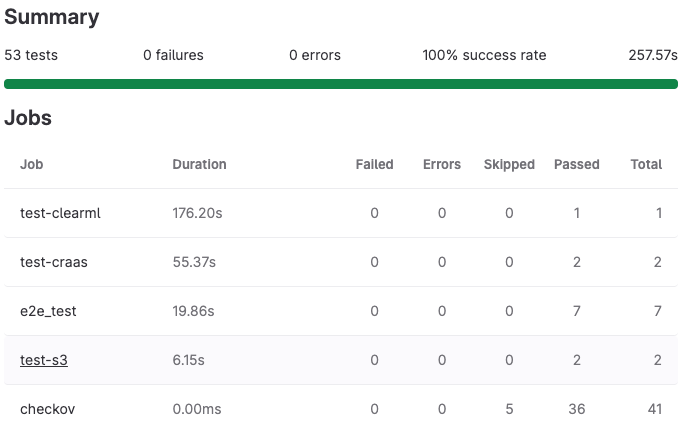
Добавили автотестирование
Итак, мы умеем автоматически дестроить и деплоить в облако инфраструктуру. Но перед тем, как отдать ее в эксплуатацию, нужно все проверить. Мы же не хотим снова получить психологические травмы.
Чтобы избежать рутинных проверок, мы ввели несколько автотестов с помощью pytest. По функциональной части мы проверяем:
- возможность обучения моделей на GPU и CPU,
- возможность загрузки артефактов в S3,
- возможность загружать образы контейнеров в CRaaS.
Дополнительно с помощью Selenium мы ходим на веб-интерфейс каждого сервиса и проверяем его доступность.
GitLab предоставляет информативный инструмент для работы с отчетами и не дает смержить те изменения, которые не прошли тесты.
Почему мы используем GitLab environments вместо Terragrunt
Terragrunt можно применять для создания различных окружений: dev, stage, prod. То есть, генерировать под каждое окружение отдельный Terraform-код. Мы же для этого используем Gitlab environments.
Вот как это происходит при разработке.
- Инженер создает отдельную ветку в нашем проекте.
- Под эту ветку создается свой environment и уникальная кастомизированная платформа.
- В ней инженер добавляет фичи, работает изолированно от коллег и никому не мешает.
- После добавления фичи, проверки автотестами и апрува мы дестроим платформу и мерджим в мастер.
Чтобы сделать кастомную конфигурацию для платформы, мы для каждого окружения создаем отдельный файл и указываем в нем все настройки нашей платформы.

Что по времени
В итоге время деплоя сократилось в 20 раз: с восьми часов до 24 минут. Если раньше было много ручных действий и мало емкости для полезных задач, то теперь я просто нажимаю кнопку и иду пить кофе.
| Проверка Terraform-кода на мусор, креды, формат. | 30 секунд |
| Деплой платформы: разворачивается сначала проект в облаке Selectel, потом — инфраструктурный компонент и последним — Managed Kubernetes. Одни джобы при этом идут параллельно, другие — последовательно. | 17 минут |
| Автотестирование платформы. Проверяем возможность обучения моделей и смотрим доступность веб-интерфейсов. | 6 минут |
| Дестрой платформы. По сути, мы просто удаляем проект в облаке. Но также добавили и дестрой каждого компонента по отдельности, чтобы была возможность отладки. | 1 минута |
| Итого. | ~24 минуты |
Пайплайн тоже преобразился и теперь выглядит так:
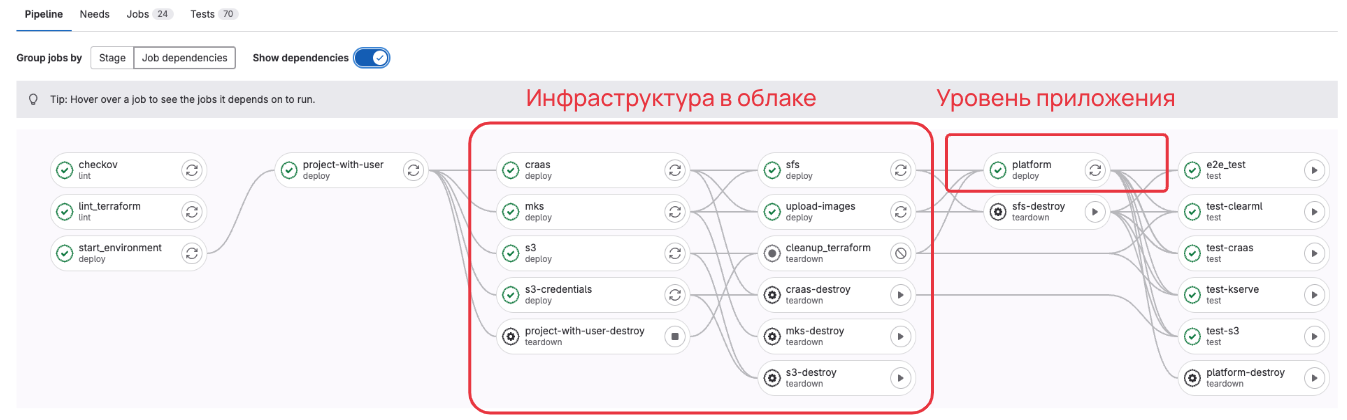
Выводы
Использовать IaC и автотесты — хорошая практика. Вот что это дало нашей команде.
- Ускорили деплой платформы в 20 раз: наша команда теперь меньше занимается деплоем, больше — разработкой новых фичей.
- Избавились от выгорания благодаря автотестам: когда мы деплоим изменения в прод после тестов, мы получаем удовольствие, а не страдаем.
- Стали описывать всю инфраструктуру кодом: избавились от узких горлышек, спокойно уходим в отпуска.
- Создаем «серверы-фениксы» вместо «серверов-снежинок»: если что-то пойдет не так, можно все задестроить, а потом задеплоить заново. Это будет наиболее продуктивный и наименее затратный подход при инициализации инфраструктуры.
Мы вынесли примеры наших модулей, которые используем для построения платформы, в открытый репозиторий. Стараемся держать их в актуальном состоянии, проверяем каждый день пайплайн на создание инфраструктуры. Вы можете переиспользовать Terraform-модули для своих проектов в Selectel! Пробуйте и оставляйте обратную связь, а также добавляйте свои модули для работы с нашим облаком.
В комментариях с удовольствием отвечу на ваши по статье. Будет здорово, если вы опишете свой опыт применения IaC. Также можно обсудить, какие инструменты вы используете для автоматизации деплоя инфраструктуры и ваших приложений. Crossplane? Terragrunt? Переходили ли вы на OpenTofu? Pulumi? ArgoCD/ FluxCD? Atlantis?
Интересно, как работает ML-платформа, про которую мы говорили в статье? Записывайтесь на двухнедельный бесплатный тест. Оставляйте заявку и вперед на тестирование!