

Представим ситуацию: у нас есть сервисы, которые пишут логи событий и сообщения из очередей (Kafka, RabbitMQ) в формате Avro для гарантии схемы и потоковой доставки. В это же время отдел машинного обучения работает с датасетами в Parquet — ребята ценят столбцовое хранение и производительность на скалярных чтениях. Соседняя команда фиксирует фактовые таблицы в ORC, поскольку этот формат подходит для тяжелых аналитических агрегаций.
Пока объемы данных измерялись гигабайтами, такой «зоопарк форматов» был терпим: каждый отдел использовал свой инструмент, а данные копировались между ними через ETL-конвейеры. Но с ростом до терабайтов и выше эта архитектура начинает ломаться: запросы становятся медленными, стоимость хранения и вычислений стремительно растет, а главное — теряется единый источник истины. Теперь одна и та же бизнес-сущность существует в трех разных форматах, схемах и состояниях.
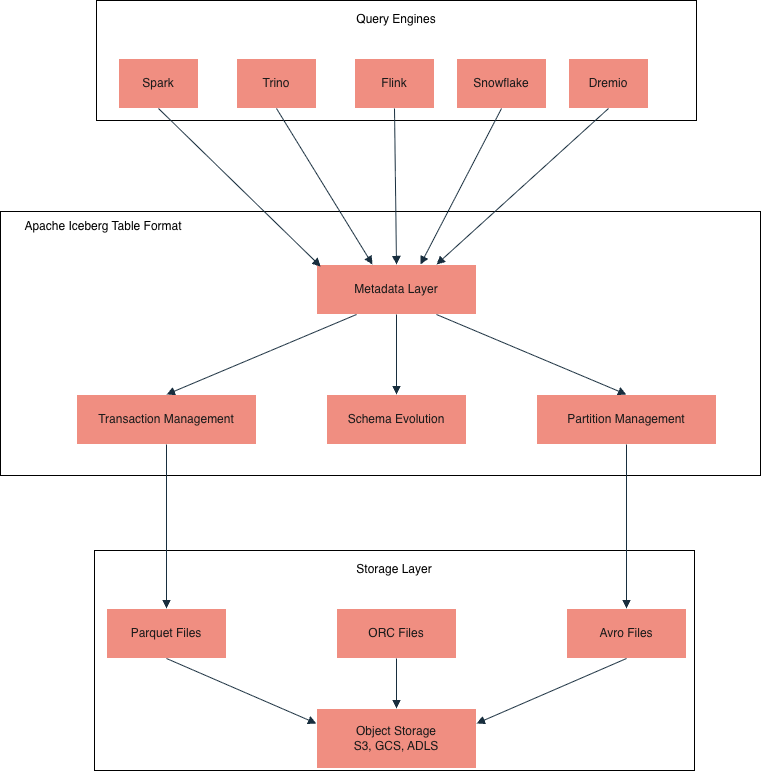
В этот момент возникает потребность не в очередном хранилище, а в табличной абстракции поверх существующих форматов. Такой слой должен обеспечивать ACID-транзакционность, централизованное управление схемой и единый каталог для всех потребителей — от потоковой инженерии до машинного обучения и BI. Именно так и приходят к Apache Iceberg и к идее построения собственной платформы данных.
Классические проблемы Data Lake без табличного формата
Можно заметить, что классический Hive Metastore уже предоставляет абстракцию таблицы над файлами Parquet и ORC. Зачем нужен еще один слой? Дело в том, что Hive — тонкая прослойка, которая сопоставляет имя таблицы с директорией в S3 или HDFS, а вся логика работы с данными ложится на движок (Spark, Trino) или плечи разработчика.
С ростом объемов и требований к надежности эта модель начинает давать сбои — остановимся на них подробнее.
Отсутствие ACID-транзакционности («грязное чтение»)
При конкурентной записи в одну таблицу (например, из двух потоковых приложения или батч-джоб во время чтения) читатели видят частично записанные данные. Если процесс записи упал на середине, файл остается в директории — запрос его подхватит и результат будет некорректным.
Hive поддерживает ACID, но только для управляемых (managed) таблиц в формате ORC с серьезными ограничениями по производительности и совместимости. На практике большинство пользователей Hive отключают эту функцию и продолжают работать с риском «грязных чтений».
ACID (аббревиатура от англ. atomicity, consistency, isolation, durability) — это набор требований к транзакционной системе. Подробнее на нем мы еще остановимся чуть позже.
Медленный поиск данных (O(N) сканирование директорий)
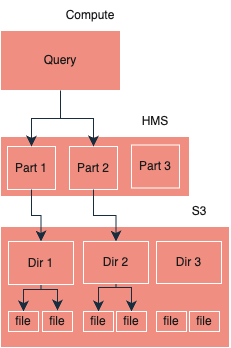
В классической Hive-таблице партиции — это физические поддиректории в хранилище, например, /logs/year=2025/month=03/day=22/. Чтобы понять, какие данные читать, движок (Spark или Trino) вынужден сначала запросить список всех партиций из метастора, а затем выполнить рекурсивный листинг файлов в каждой директории через API хранилища (S3 ls или HDFS ls).
Когда партиций становится с десяток тысяч, а файлов — с миллион, процесс планирования запроса (query planning) может занимать минуты. И это до того, как начнется чтение данных. Кроме того, при отсутствии фильтра — например, WHERE, по колонке партиции запрос может превратиться в полное сканирование таблицы (Full Table Scan).
Изменение схемы требует перезаписи всего датасета
Захотели переименовать колонку user_id в uid? В Hive это сделать нельзя. Конечно, вы можете изменить метаданные таблицы, но файлы Parquet/ORC внутри останутся со старой схемой. В результате это приведет к ошибкам или появлению NULL-значений при чтении. Единственный безопасный способ — создать новую таблицу, переписать все данные (напоминаю, что это могут быть сотни гигабайт) и удалить старую.
Даже операции вроде изменения типа данных или добавления колонки с дефолтным значением в реальных сценариях требуют полного переписывания датасета (Create Table As Select). На объемах в сотни терабайт это превращается в дорогостоящую операцию, которая занимает часы, а иногда и дни.
Отсутствие истории изменений
Запрос вида «покажи мне, как выглядела таблица на начало дня, до того, как стажер внес свои изменения» в классическом Data Lake не поддерживается. Если только вы не сделали снапшот вручную.
Единственный вариант — перед каждым изменением копировать всю таблицу в отдельную директорию, что приводит к экспоненциальному росту стоимости хранения и неоправданной сложности управления.
Отсутствие единого каталога и изоляции
Сервис Hive Metastore (HMS) исторически являлся единственной точкой истины (Single Source of Truth) для построения платформ данных, однако он не поддерживает мультитенантность на уровне row/column security. К примеру, невозможно сделать так, чтобы один пользователь мог читать только половину таблицы, а второй — всю (можно это реализовать только на уровне таблиц). Кроме того, HMS требует отдельной инфраструктуры (база данных, metastore-сервис), которая становится единой точкой отказа (Single Point of Failure, SPOF), а работа с несколькими хранилищами или облаками в рамках единого каталога ограничена.
Начиная с объемов в несколько терабайт эти ограничения перестают быть «техническими деталями» и превращаются в реальные блокеры: они замедляют разработку, усложняют поддержку и повышают риск инцидентов с качеством данных. В этот момент возникает потребность в табличном формате, который берет на себя управление метаданными, транзакционностью и возможностью изменять схему данных, а не перекладывает эту ответственность на прикладные программы.
Apache Iceberg как реализация табличного формата
Одно из распространенных заблуждений при знакомстве с Iceberg — попытка воспринимать его как очередной движок обработки данных (аналог Spark или Trino) или как формат хранения (аналог Parquet, Avro). На самом деле Iceberg занимает другой уровень архитектуры.
Iceberg — это табличный формат: спецификация того, как метаданные описывают физическую структуру данных. Если провести аналогию, Parquet и ORC определяют, как организован отдельный файл как применяется сжатие, как хранится статистика по страницам. Iceberg же определяет, как организована таблица целиком: какие файлы в нее входят, в каком порядке они добавлены, какие транзакции применены, как менялась схема.
Поскольку Iceberg работает только на уровне метаданных, он сохраняет главное преимущество Data Lake — разделение хранения и вычислений. Данные можно выгодно держать в объектном хранилище в нативных форматах (Parquet, ORC, Avro), а разные движки будут работать с ними независимо.
Например, Spark может записывать данные в Iceberg, атомарно заменяя один Metadata File. Trino может читать те же данные через REST Catalog, без жесткой привязки к Hive Metastore. Flink — стримить данные в эту таблицу, регулярно создавая новые снапшоты. Именно возможность использовать один табличный формат из любого движка без дублирования данных и привязки к конкретному вендору делает Iceberg одной из ключевых составляющих современных платформ данных.
При этом Iceberg не заменяет привычные инструменты, а добавляет слой: он стандартизирует работу с данными и превращает Data Lake в управляемую, транзакционную систему с поддержкой эволюции схемы.
Основные свойства и гарантии
После того как мы разобрались с тем, что Iceberg представляет собой табличный формат, важно понять, какие гарантии он дает на практике. Именно эти свойства позволяют использовать Data Lake не как классическое хранилище файлов, а как полноценную систему управления данными.
Рассмотрим ключевые возможности: набор фундаментальных свойств (ACID), работу со снимками состояния, эволюцию схемы и прозрачное партиционирование.
ACID
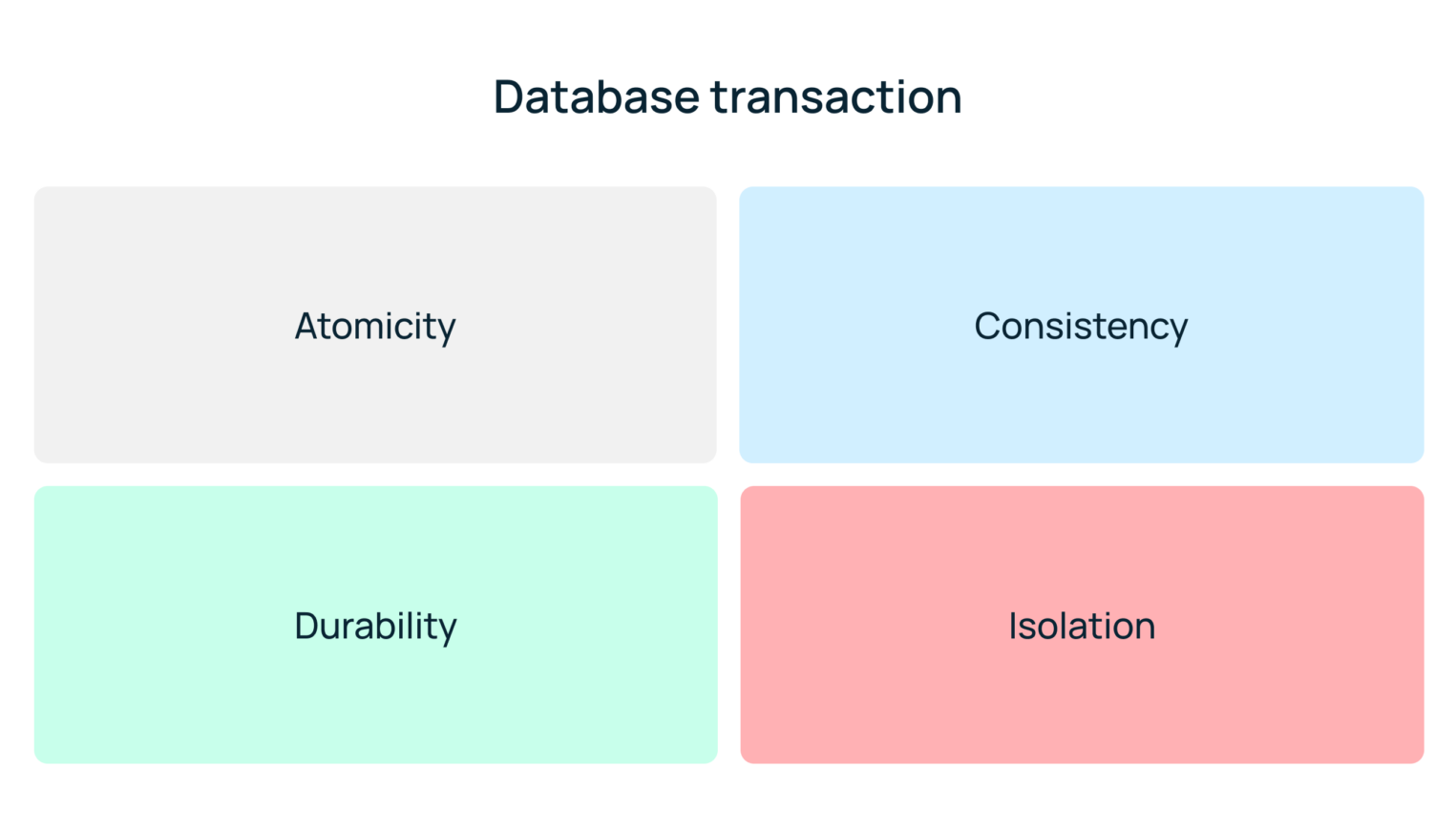
Atomicity
Iceberg использует модель на основе снимков состояния (снапшотов), обеспечивая принцип «все или ничего». В процессе записи данных создается новый снимок состояния таблицы, но эти изменения становятся видимыми для всех потребителей только в один момент — когда происходит атомарное обновление указателя на актуальный файл метаданных. За надежность этого переключения отвечает каталог, но подробнее о его роли поговорим в следующем разделе.
Consistency
Iceberg гарантирует согласованность чтения (consistency of reads / snapshot isolation): каждый читатель всегда видит консистентный снимок данных, даже при параллельных записях. Грязное чтение (dirty reads) и чтение незавершенных изменений исключены.
Важно это отличать от Consistency в классических СУБД (например, PostgreSQL), где речь идет о соблюдении ограничений схемы и бизнес-правил (например constraints, foreign keys). В Iceberg такие проверки не встроены: здесь Consistency отвечает за корректность параллельного доступа и непротиворечивость данных в рамках снимка (снапшота), а не за их бизнес-валидацию.
Isolation
Используется Optimistic Concurrency Control. Iceberg исходит из предположения, что конфликты редки. Если два процесса пытаются одновременно обновить таблицу, то первый закоммитит изменения, а второй — проверит, не затронул ли первый те же данные. Если пересечений нет, второй процесс просто создаст новый снапшот поверх первого. Если конфликт есть — операция отклонится.
Durability
Поскольку Iceberg работает поверх надежных файловых систем или объектных хранилищ (S3, HDFS), данные физически записываются в неизменяемые (immutable) файлы. Как только метаданные обновились (вернулся HTTP 200 OK), результат операции считается завершенным. Даже если в следующую секунду вычислительный кластер (Trino/Spark) полностью упадет, данные останутся доступными для чтения.
Time Travel (путешествие во времени)
Функциональность Time Travel появляется из особенностей реализации Isolation и Atomicity. В классических СУБД старые версии строк со временем вычищаются процессом VACUUM, чтобы не занимать место. В Iceberg же старые снапшоты сохраняются до тех пор, пока вы их не удалите явно.
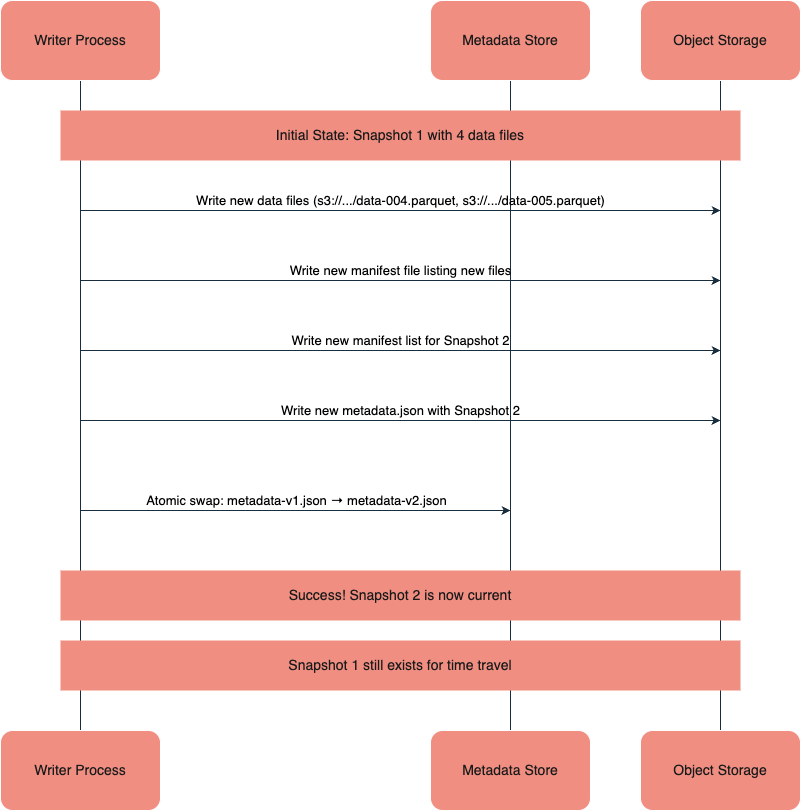
Поскольку Iceberg — это снапшот-ориентированная система, каждая операция записи создает новый снимок состояния таблицы. По умолчанию движок читает актуальный снимок, но можно обратиться к предыдущим версиям, указав snapshot-id или timestamp. Это позволяет откатываться к предыдущим состояниям после ошибок в пайплайнах и обеспечивать воспроизводимость аналитических отчетов. Срок хранения снимков управляется через политики retention, которые могут учитывать как глобальные настройки, так и отдельные ветки (main, branch, tag).
-- Чтение конкретного снапшота по ID
SELECT * FROM table_name FOR SYSTEM_VERSION AS OF snapshot_id;
-- Чтение по timestamp
SELECT * FROM table_name FOR SYSTEM_TIME AS OF '2026-04-01 10:00:00';
-- Чтение конкретной ветки
SELECT * FROM table_name FOR SYSTEM_VERSION AS OF 'branch_name';
Schema Evolution (Эволюция схем)
Как упоминалось выше, одна из ключевых проблем старых форматов (например, Hive) заключалась в сопоставлении колонок по именам. Если вы переименовывали колонку user_id в uid, старые данные «исчезали» (становились NULL), так как движок не мог найти соответствие.
Вместо того, чтобы переписывать все данные, которые, например, лежали в Parquet-файлах, Iceberg просто обновляет текстовый файл манифеста. Достигается это благодаря идентификатору field-id. Например:
Snapshot 1. В метаданных записано:
field-id: 1, name: user_id, type: string
Далее — переименовываем колонку в uid.
Snapshot 2 в Iceberg. В новом файле метаданных меняется строчка:
field-id: 1, name: uid, type: string
Данные доступны. ✅
Snapshot 2 в Hive:
Данные пропали. ❌
-- Переименование поля, которое не поломает данные
ALTER TABLE users RENAME COLUMN user_id TO uid;
-- Можно даже изменить тип партиционирования — например, перейти с дневного на часовое, без поломки существующих данных
ALTER TABLE events ADD PARTITION FIELD hours(event_time);
Hidden Partitioning
В классических Data Lake партиционирование напрямую связано с физической структурой директорий (например, /day=2026-03-26/). Чтобы использовать его эффективно, пользователь должен явно учитывать это в запросах.
Iceberg скрывает эту деталь. Пользователь работает с логическими колонками, а преобразования применяются автоматически. Например:
SELECT * FROM events
WHERE event_time = '2026-03-26 10:00:00';
Iceberg автоматически применяет трансформацию — например, day(event_time), обрежет все партиции, кроме day=’2026-03-26′ и возвращает результат без участия аналитика.
Новые возможности с версии v3 (актуально в 2025-2026 гг.)
В новых версиях Iceberg и связанных движков расширяется поддержка сложных типов данных. Например, появляются типы для работы с геоданными (GEOMETRY, GEOGRAPHY) и полуструктурированными данными. Это позволяет эффективно хранить координаты и полигоны, используя стандартные пространственные индексы для ускорения ГИС-запросов.
CREATE TABLE logistics.orders (
id BIGINT,
delivery_region GEOGRAPHY, -- границы регионов
pickup_point GEOMETRY -- точка на карте
);
Также добавилась возможность хранить JSON в таблицах. Для этого можно использовать VARIANT:
CREATE TABLE events (
id BIGINT,
metadata VARIANT, -- JSON-like формат
timestamp TIMESTAMP WITH TIME ZONE
);
Архитектура метаданных
Одно из ключевых отличий Iceberg от классических Data Lake — способ доступа к данным. Вместо сканирования директорий в S3 или HDFS он использует иерархию метаданных, которая позволяет находить нужные файлы без полного перебора.
Движок (Trino, Spark и др.) не «ищет» данные, а последовательно проходит по цепочке ссылок. Благодаря этому количество обращений к хранилищу остается ограниченным и не зависит линейно от числа файлов или партиций.
Рассмотрим эту иерархию сверху вниз.
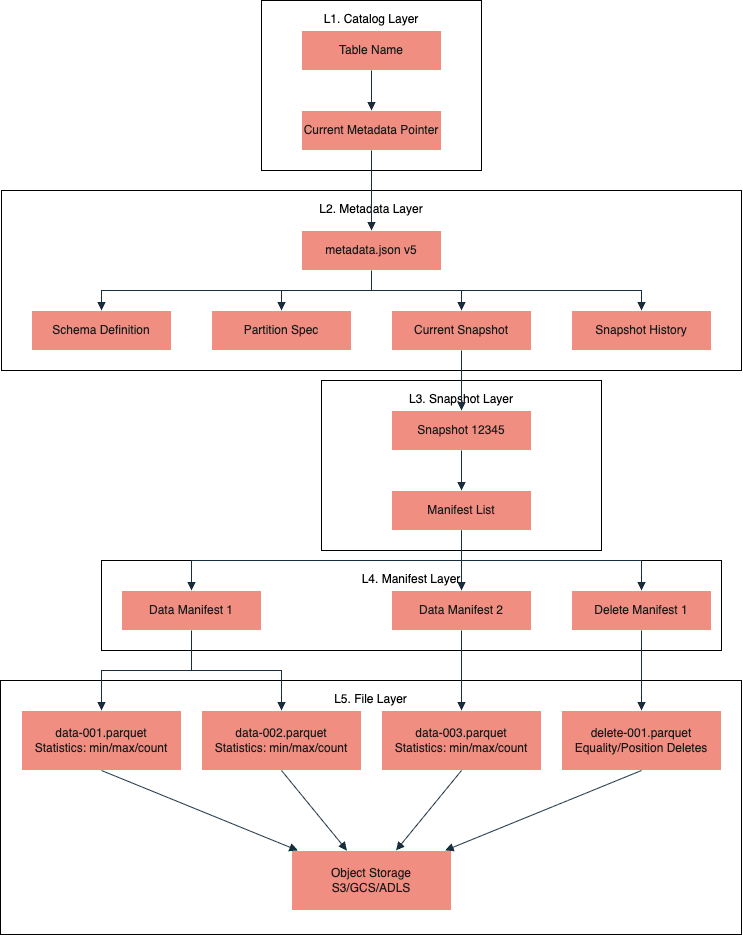
Уровень 1: Каталог (источник истины)
Каталог хранит Metadata Pointer — ссылку на самый актуальный файл метаданных. Это единственный изменяемый узел в структуре. Как только указатель переключился на новый файл — транзакция завершена.
Уровень 2: Metadata File (корневой JSON)
Содержит описание текущего состояния таблицы:
- актуальную и предыдущие схемы (schema evolution);
- спецификацию партиционирования;
- список снимков (snapshots);
- ссылку на manifest list для каждого снимка.
Уровень 3: Manifest List (список манифестов)
Manifest List — бинарный файл (Avro), который группирует манифест-файлы. Он хранит границы данных (min/max) для целых групп файлов. Это позволяет движку отсеивать 90% данных еще на этапе планирования запроса, даже не заглядывая в глубокие слои метаданных.
Уровень 4: Manifest File (список файлов)
Manifest File — это список конкретных файлов данных (Parquet/ORC). Для каждого файла Iceberg знает:
- нижние и верхние границы значений в колонках,
- количество строк и null-значений,
- статус (добавлен или удален в рамках снапшота).
Дополнительные компоненты
Puffin Files — специальный формат для «тяжелой» статистики. Сюда входят, например, Bloom-фильтры или оценки количества уникальных значений — NDV. Они помогают оптимизатору запросов выбирать лучший план соединения таблиц.
Metadata Tables — системные таблицы — например, table.snapshots, которые позволяют заглянуть внутрь архитектуры с помощью классического SELECT.
Sort Order — описание порядка глобальной сортировки. Помогает эффективно использовать Z-Ordering и ускорять поиск.
Интеграция с экосистемой
Одна из ключевых сильных сторон Iceberg — единая спецификация таблиц, которая позволяет разным движкам работать с одними и теми же данными без конфликтов и дублирования. Благодаря этому Data Lake перестает быть набором изолированных пайплайнов и превращается в общую платформу для данных. Рассмотрим, как это выглядит на практике
Apache Spark
Использует Iceberg для надежной записи данных. Даже если задача прерывается во время выполнения, атомарный коммит гарантирует, что таблица останется в консистентном состоянии без частично записанных данных.
Кроме того, Iceberg используется и на чтение для формирования регулярной бизнес-отчетности. Наличие снапшотов позволяет запросам работать со стабильной версией данных, даже если в этот момент происходит спил (spill) промежуточных состояний тяжелой операции на диск — на консистентность финального отчета это не окажет влияния.
Trino
Позволяет аналитикам выполнять интерактивные ad-hoc SQL-запросы к Data Lake со скоростью классических хранилищ, используя продвинутое отсечение данных (pruning) по метаданным.
Apache Flink
Iceberg превращает Data Lake в полноценный приемник для потоков. Поддержка CDC (Change Data Capture) позволяет Flink эффективно записывать только измененные строки.
Kafka
Интегрируется через коннекторы, позволяя доставлять события из очередей в Iceberg-таблицы с минимальной задержкой и без промежуточных слоев хранения.
Особого внимания заслуживает Amazon S3 Tables — первое нативное хранилище от AWS, специально созданное для Apache Iceberg. Оно объединяет хранение и каталог в одном сервисе и берет на себя часть операционных задач:
- управление метаданными,
- оптимизацию структуры данных,
- снижение нагрузки на операции чтения метаданных.
Также упрощается управление доступом за счет механизма временных учетных данных (vended credentials).
Важно понимать, что это не обязательный компонент Iceberg, а один из вариантов его managed-использования.
Заключение
Iceberg решает ключевую проблему Data Lake — отсутствие управляемости табличных данных. Он добавляет слой транзакционности, версионирования и управления схемой поверх объектного хранилища, сохраняя при этом его масштабируемость и стоимость.
В результате получается «управляемое озеро данных», Data Lakehouse — архитектура, которая сочетает гибкость файлового хранения и удобство работы, привычное для СУБД, без привязки к конкретному инструменту или вендору. В следующей части проверим это на практике и соберем минимальную платформу данных на базе Iceberg.




